һ���洢����
1.1���洢���̵Ľ���
? ? �洢����(Stored Procedure)���ڴ������ݿ�ϵͳ��,һ��Ϊ������ض����ܵ�SQL ��伯,�������ֱ�Ӵ洢�����ݿ���,�û�����ָ���洢���̵����ֺʹ��ݶ�Ӧ�IJ���(����ô洢���̴��в���)��ִ�������洢���������ݿ��е�һ����Ҫ����,�κ�һ��������õ����ݿ�Ӧ�ó��߱��洢���̡�
1.2���洢���̵��ŵ�Ͳ���
| ��� | �洢���̡�Stored Produce�����ŵ� |
| 1 | �洢���̿���ʹ�ó���ִ��Ч�ʸ��ߡ���ȫ�Ը���,��Ϊ���̽�������֮������Ѿ����벢�Ҵ��浽���ݿ��е�,��ֱ�ӱ�дsql�������Ҫ��ͨ����������������ִ����˹���Ч�ʸ���,����ֱ�ӱ�ддsql�����ܻ����һЩ��ȫ������,��:sqlע�� �� |
| 2 | �����洢���̶�ϵͳ��Դ�����IJ���(������Ϊ�洢����ֻ���ڵ���ʱ�Ż�ִ��) |
| 3 | �洢���̿������ڽ�����������(������Ϊ�洢���̵Ĵ�����ֱ�Ӵ洢�����ݿⱾ��,ֱ�ӵ��þ���,�����ñ�д������sql���Ĵ���) |
| 4 | �洢����ʹ���ܹ���ǿ��ִ�мƻ����ظ�ʹ�� |
| 5 | ��ά���Ը�(������Ϊ���´洢����ͨ���ȸ��ġ������Լ����²�������Ѹ��ٵ�ʱ��;���) |
| 6 | ���뾫��һ��(һ���洢���̿�������Ӧ�ó������IJ�ͬλ��) |
| 7 | ��ǿ��ȫ��( ��ͨ�����û�����Դ洢����(�����ǻ��ڱ�)�ķ���Ȩ��,���ǿ����ṩ���ض����ݵķ���; ����ߴ��밲ȫ,��ֹ SQLע��; ��SqlParameter ��ָ���洢���̲�������������,��Ϊ���η����Բ��Ե�һ����,������֤�û��ṩ��ֵ����) |
| ��� | �洢���̡�Stored Produce���IJ��� |
| 1 | ������ʹ�ô洢����,��Է�������ɺܴ��ѹ�� |
1.3���洢���̵Ĵ����
| ���? ?? | ��������˵�� |
| 1 | IN �Dz�����Ĭ��ģʽ,����ģʽ�����ڳ������е�ʱ���Ѿ�����ֵ,�ڳ�������ֵ����ı� |
| 2 | OUT ģʽ����IJ���ֻ���ڹ������ڲ���ֵ,��ʾ�ò������Խ�ij��ֵ���ݻص������Ĺ��� |
| 3 | IN OUT ��ʾ�ò���������ù����д���ֵ,Ҳ���Խ�ij��ֵ����ȥ |
//�����
create [or replace] procedure �洢��������
(������ in|out ��������,������ in|out ��������) is|as
- - ������������
begin
- - ҵ��������
end;
//��ϸ�����
create [or replace] procedure �洢��������
(param1 in type,param2 out type) is|as
����1 ����(ֵ��Χ);
����2 ����(ֵ��Χ);
begin
select count(*) into ����1 from ��A where����=param1;
if (�����) then
select ���� into ����2 from ��A where����=param1;
dbms_output.Put_line('��ӡ��Ϣ');
elsif (�����) then
dbms_output.Put_line('��ӡ��Ϣ');
else
raise �쳣��(NO_DATA_FOUND);
end if;
exception
when others then
rollback;
end;1.4��ִ�д洢���̵��
?����һ:
//ִ�д洢�����1
CALL �洢��������(����1,����2);
//ִ�д洢����ʾ��
CALL CACULATESALARY(1,5000);������:
//ִ�д洢�����2
BEGIN
�洢��������(����1,����2);
END;
//ִ�д洢����ʾ��
BEGIN
caculatesalary(1,5000);
END;1.5���洢���̵�ʾ��
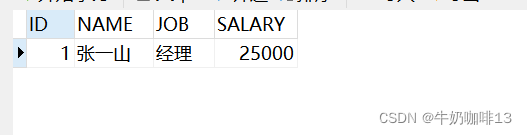
? ? ʾ��1:ʵ�������Ա�ı�ź���н�ʵ��������Dz鿴ԭн��;Ȼ���Ǹ��¸ù�Ա��н��,Ȼ���ӡ�����鿴;����������ʧ������Ҫ�ع���
������������:
?
?�洢��������:
CREATE OR REPLACE PROCEDURE CaculateSalary
(peopleNumber in NUMBER,needIncreaseSalaryNumber in NUMBER)
AS
TotalSalary NUMBER:=0;
BEGIN
--��ȡ����ǰ�Ĺ���
SELECT SALARY INTO TotalSalary from PEOPLE WHERE PEOPLE.ID=peopleNumber;
--�����н��ǰ�Ĺ���
dbms_output.put_line('��нǰ������:'||TotalSalary);
--�ǹ��ʺ�Ĺ���
UPDATE PEOPLE SET SALARY=(TotalSalary+needIncreaseSalaryNumber) WHERE ID=peopleNumber;
--�����н�ʺ�Ĺ���
dbms_output.put_line('�������:'||(TotalSalary+needIncreaseSalaryNumber));
--�ύ����
commit;
--�쳣��ع�
EXCEPTION
WHEN OTHERS THEN
rollback;
dbms_output.put_line('��н�쳣ִ�лع�����');
END;?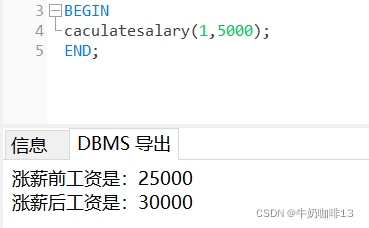
?ʾ��2:��Ҫ�������,Ȼ����ͨ���ò����������ݳ�ȥ
CREATE OR REPLACE procedure testInuptOutput
(message in out varchar2)
--������Я��ֵ����,����Я��ֵ��ȥ,������in out
as
begin
dbms_output.put_line('��ǰ���������Ϊ:'||message); --�����ΪЯ��������ֵ
message:='���Ǿ����������ֵ'||998;
end;?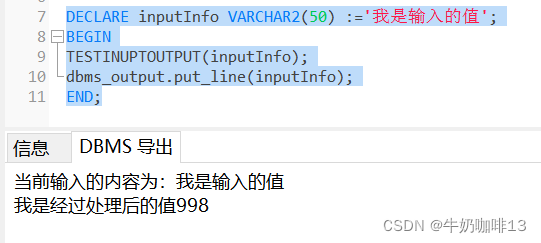
�����洢����
2.1���洢��������
? ? �洢����(Stored Function)�Ǵ���֮�������ݿ���,�ҷ�װ��oracle�������е�һ���Ѿ���ɵ�plsql����Ƭ�Ρ�
2.2���洢�������ص�
| ��� | �洢�������ص� |
| 1 | �����ݿ�����ʱ�Զ����� |
| 2 | ����û�в����������֮�� |
| 3 | ���������з���ֵ |
| 4 | ���ú���ʱ����ʹ�����ķ���ֵ |
| 5 | �洢������������sql �����ʹ��,Ҳ������plsql��ʹ�� |
2.3���洢�����Ĵ����
| ���? ?? | ��������˵�� |
| 1 | IN �Dz�����Ĭ��ģʽ,����ģʽ�����ڳ������е�ʱ���Ѿ�����ֵ,�ڳ�������ֵ����ı� |
| 2 | OUT ģʽ����IJ���ֻ���ڹ������ڲ���ֵ,��ʾ�ò������Խ�ij��ֵ���ݻص������Ĺ��� |
| 3 | IN OUT ��ʾ�ò���������ù����д���ֵ,Ҳ���Խ�ij��ֵ����ȥ |
//�洢�����Ļ����
create [for replace] function �洢����������(������ in|out ��������,������ in|out ��������)
return ��������
is | as
begin
end;
//�洢��������ϸ�
Create [or replace] function ��������(�������� in|out ��������,�������� in|out ��������,...)
Return ���������������
Is | as
������������;
Begin
������;
Return �������;
[exception �쳣��������]
End;
ע��:end�����;����ȡ�����������б�����Ĭ������������ in
2.4��ִ�д洢�������
//ִ�д洢��������1(���ڱ���ʽ��)
SELECT ��������(����) FROM dual;
//ִ�д洢��������1ʾ��
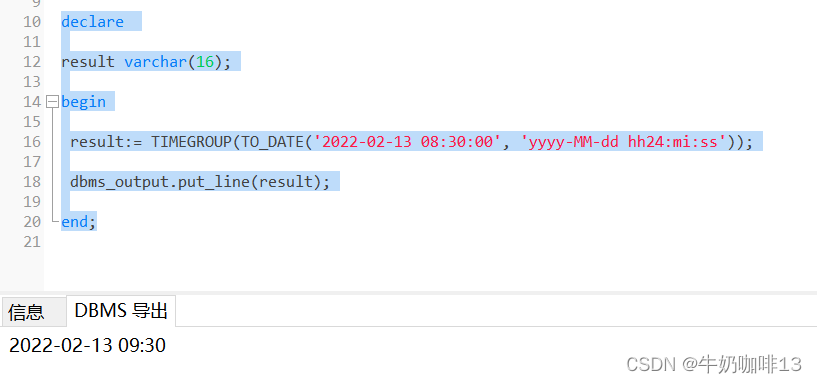
SELECT TIMEGROUP(TO_DATE('2022-02-12 17:30:36', 'yyyy-MM-dd hh24:mi:ss'))handleTime FROM dual;//ִ�д洢��������2
declare
�������� ����;
begin
--��ֵ�洢�������������
��������:=�洢��������
--��ӡ�������
dbms_output.put_line(��������);
end;
//ִ�д洢����2ʾ��
declare
result varchar(16);
begin
result:= TIMEGROUP(TO_DATE('2022-02-12 17:30:36', 'yyyy-MM-dd hh24:mi:ss'));
dbms_output.put_line(result);
end;
2.5���洢����ʾ��
ʾ��:ʵ�ֶ����ڷ���(��:��Сʱ��ʼ���һ��Сʱ��Ϊһ��
�١�����:2022-02-13 07:30:00һֱ��2022-02-13 08:29:59���Ĺ�Ϊ2022-02-13 08:30:00
�ڡ�����:2022-02-13 08:30:00һֱ��2022-02-13 09:29:59���Ĺ�Ϊ2022-02-13 09:30:00)
�洢��������:
CREATE OR REPLACE FUNCTION TimeGroup(inputDate IN DATE) RETURN VARCHAR2
AS
result VARCHAR(16):='';
input_yyyy_MM_dd_hh24 VARCHAR(13):=to_char(inputDate,'yyyy-MM-dd hh24');
tmp_timegroup DATE:=TO_DATE(input_yyyy_MM_dd_hh24||'30:00','yyyy-MM-dd hh24:mi:ss');
BEGIN
IF inputDate>=tmp_timegroup
THEN result:=SUBSTR(TO_CHAR((tmp_timegroup+1/24),'yyyy-MM-dd hh24:mi:ss'),0,16);
ELSE result:=SUBSTR(TO_CHAR((tmp_timegroup),'yyyy-MM-dd hh24:mi:ss'),0,16);
END IF;
RETURN result;
END;

?�����洢���̺ʹ洢��������ͬ�������
| ��� | �洢���̺ʹ洢��������ͬ�� |
| 1 | ������ṹ����,������Я�������������ʹ������� |
| 2 | ����һ�α���,������� |
| 3 | ������ʹ�á�in/ out /in out������ģʽ�IJ��� |
| �洢���� | �洢���� |
| ���������ݿ�������ض��IJ���(������)������һ��ᱻ��Ƴ������ɸ�������,���һϵ�е����ݴ���,��������صĸ��ֲ�����(����:���롢���¡�ɾ���Ȳ���) | �����ض������ݲ�����ֻΪ���һ��ֵ��(����:���ࡢ����) |
| ����ͷ��ʹ�á�Procedure������ | ����ͷ��ʹ�á�Function������ |
| ����ͷ������ʱ����Ҫ�κη������� | ����ͷ������ʱ����������������,���ұ�����PL/SQL���а���һ����Ч��return��� |
| ������Ϊһ��������PL/SQL�����ִ�� | ���ܹ�����ִ��,������Ϊ����ʽ��һ���ֵ��� |
| ����ͨ��out /in out �����������ֵ | ��ͨ��return��䷵��һ��ֵ,�Ҹ÷���ֵ��Ҫ������������һ��; ��Ҳ����ͨ��out���͵IJ����������� |
| SQL���(DML��SELECT)�в��ɵ��ô洢���� | SQL���(DML��SELECT)�пɵ��ô洢���� |
�ġ���������
�ڿ���������Ϊʲô��Ҫд�洢���� - ��լ�� - ���� (cnblogs.com)![]() https://www.cnblogs.com/doudouxiaoye/p/5804467.html�洢������һƪ���� - ֪�� (zhihu.com)
https://www.cnblogs.com/doudouxiaoye/p/5804467.html�洢������һƪ���� - ֪�� (zhihu.com)![]() https://zhuanlan.zhihu.com/p/137896709
https://zhuanlan.zhihu.com/p/137896709
Oracle�洢���̺��Զ��庯�� - ��+���� - ��Ѷ�� (tencent.com)![]() https://cloud.tencent.com/developer/article/1861667
https://cloud.tencent.com/developer/article/1861667
oracle�洢����(һ):������ - i�¶����� - ���� (cnblogs.com)![]() https://www.cnblogs.com/dc-earl/articles/9260111.html?Oracle�Ĵ洢���̻���д�� - �Ҕ��ґ� - ���� (cnblogs.com)
https://www.cnblogs.com/dc-earl/articles/9260111.html?Oracle�Ĵ洢���̻���д�� - �Ҕ��ґ� - ���� (cnblogs.com)![]() https://www.cnblogs.com/joeyJss/p/11458653.html
https://www.cnblogs.com/joeyJss/p/11458653.html
Oracle��plsql�еĴ�����̺ʹ��溯�� (daimajiaoliu.com)![]() https://www.daimajiaoliu.com/daima/479c5f2db100403?
https://www.daimajiaoliu.com/daima/479c5f2db100403?