本文致力于写一篇非技术人员也能看懂的kafka术语介绍。
1.术语列表overview
本文将要介绍的术语有:
- server相关
| 术语 | 中文释义 | 解释位置 |
|---|---|---|
| broker | 理解为服务器即可 | 2.kafka架构 |
| topic | 主题 | 3.kafka消息模型 |
| partition | 分区 | 3.2 kafka保障伸缩性的机制 |
| offset | 位移 | 3.2 kafka保障伸缩性的机制 |
| replica | 副本 | 3.1 kafka保证高可用性的机制 |
| leader replica | 主副本 | 3.1 kafka保证高可用性的机制 |
| follower replica | 从副本 | 3.1 kafka保证高可用性的机制 |
- client相关
| 术语 | 中文释义 | 解释位置 |
|---|---|---|
| producer | 发送者 | 2.kafka架构 |
| consumer | 消费者 | 2.kafka架构 |
| consumer group | 消费者组 | 3.kafka消息模型 |
2. Kafka架构
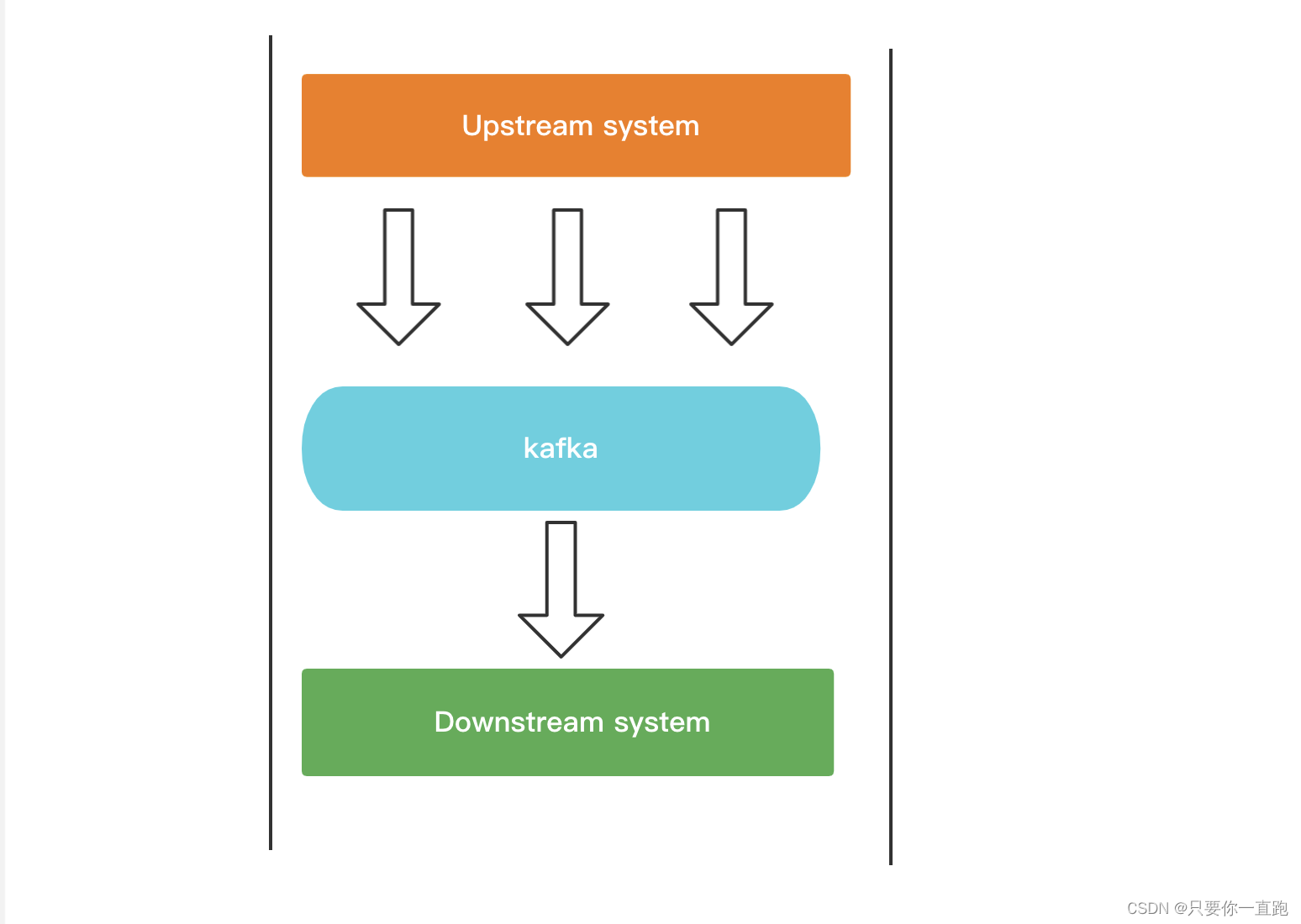
kafka是一个消息引擎系统,它可以传递消息,也具有转换消息的能力,对于今天的主题来说,我们关注传递消息的能力就够了。
如果系统和系统之间需要通信,我们有很多种选择,kafka这样的消息引擎是其中一种,相比其他的方式,它的好处主要有两个,一个是缓冲流量,另一个是松耦合。
-
缓冲流量:
上游的消息传递到下游,如果这个量很大很突然,下游系统一下子又处理不了这么多的数据,那么这些高发流量,可能会让脆弱的下游系统崩溃,此时引入消息引擎做一个缓冲,下游系统可以按自己的能力去消费消息,这有点像大坝能蓄水防洪的功能。
-
松耦合
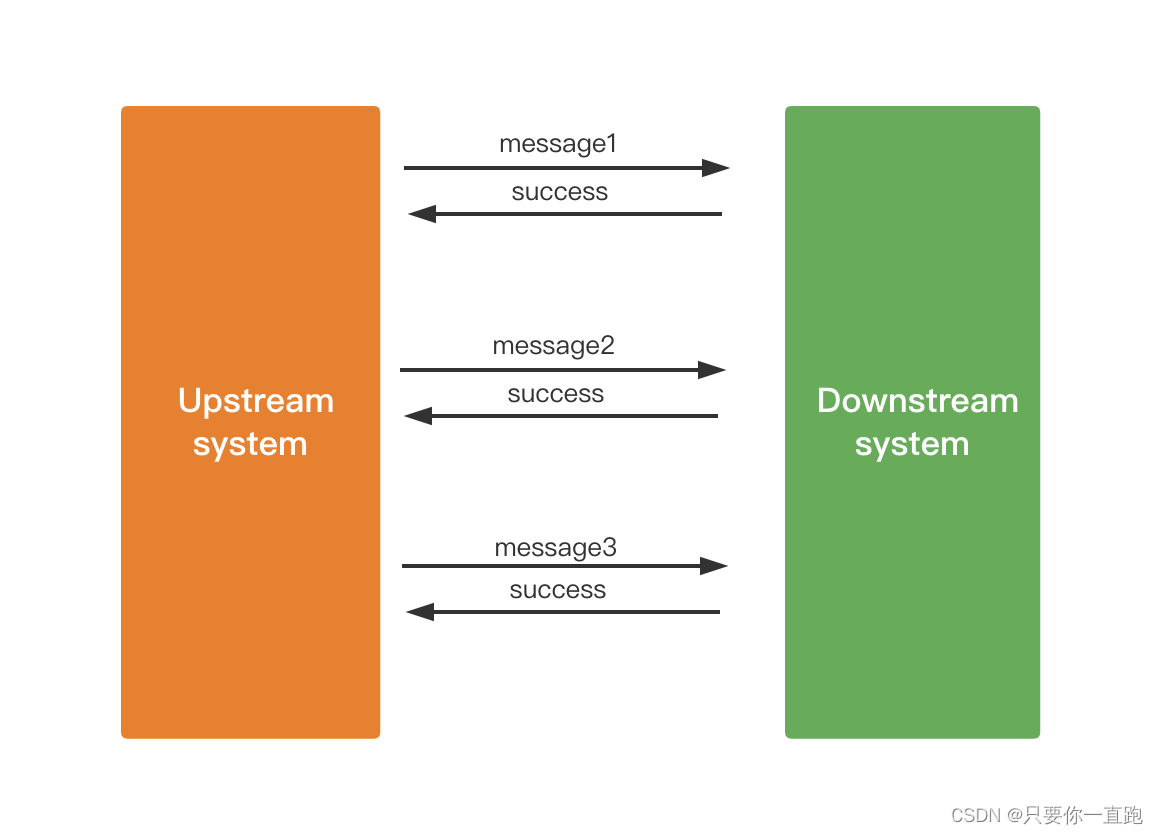
松耦合是因为kafka提供异步的传输方式,简单介绍一下异步传输的概念。
同步传输指上游给下游发消息,下游处理完消息后将结果返回给上游,然后上游再继续发消息。所以这种方式是需要下游马上去处理的,上游是要等待的(被阻塞了)。
而异步方式就不一样,上游给kafka发完消息,下游可以稍后再去消费和处理这个消息。
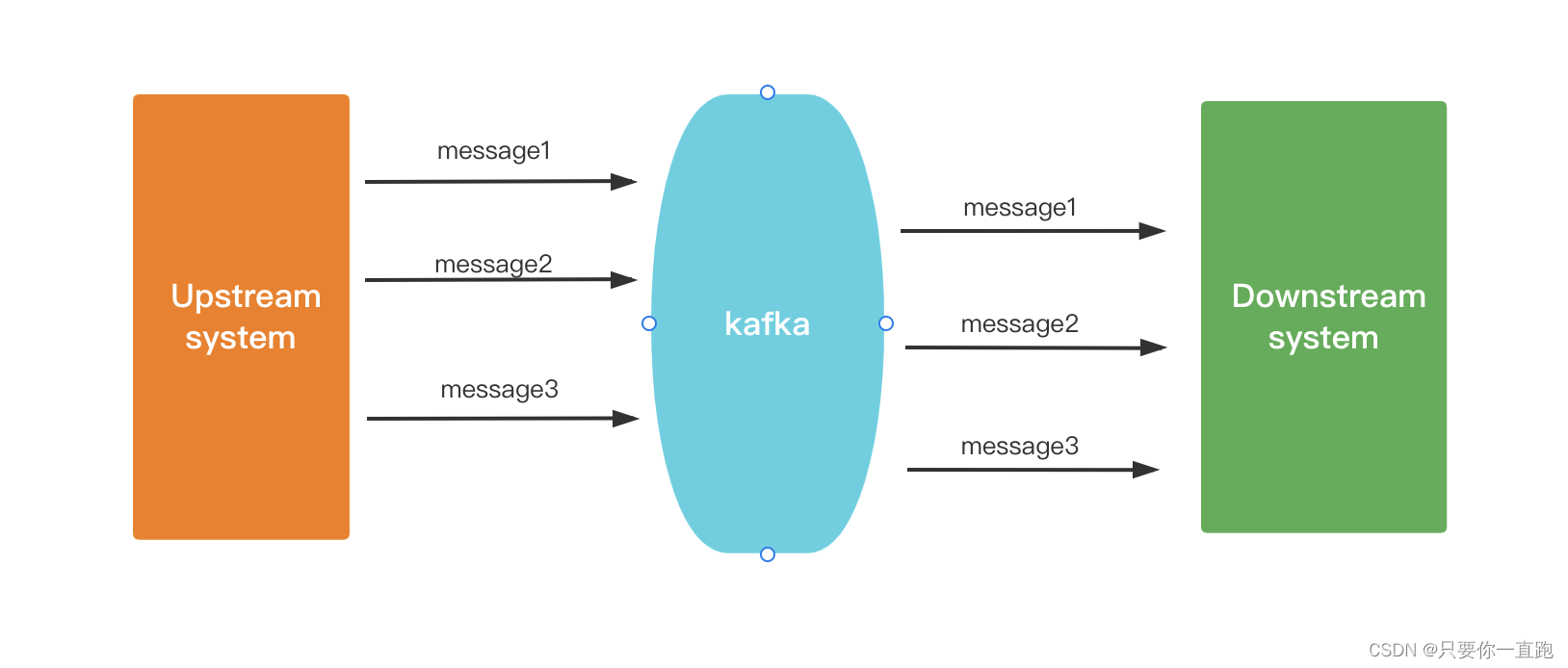
这样的上游生产者的逻辑就不会直接依赖下游消费者的逻辑了,因此上下游系统的代码不会直接依赖了,这就是松耦合。所以在微服务架构中,消息引擎经常被用来做服务的解耦。
此时我们引入几个概念:

broker就是kafka的服务器(server),而发送消息的上游系统被叫做producer(生产者),接收消息的下游系统被叫做consumer(消费者),consumer和producer都被统称成客户端(client),这一下又回到我们熟悉的客户端服务器模式(CS模式)了。
3.kafka消息模型
消息引擎常见的消息模型有两种,一种是点对点模型,另一种是发布者/订阅者模式
-
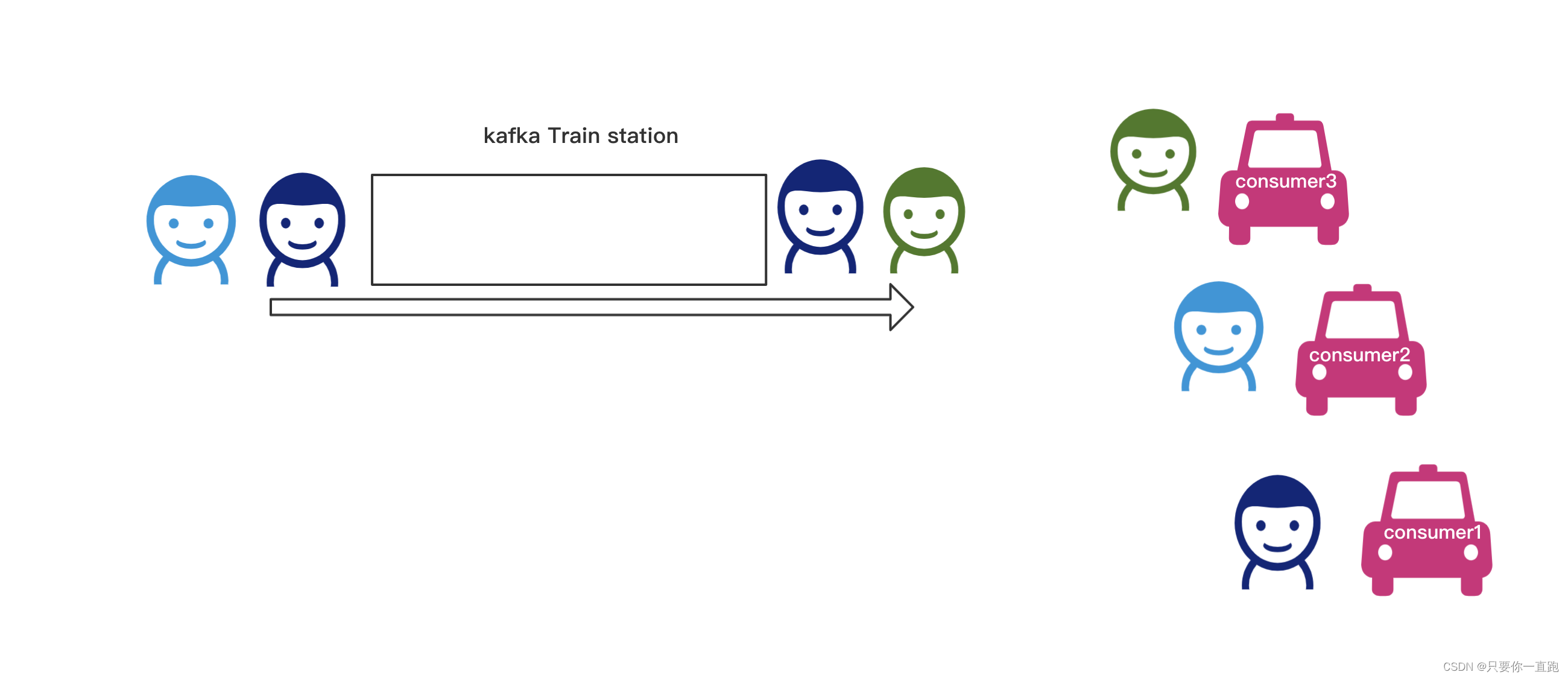
点对点模型
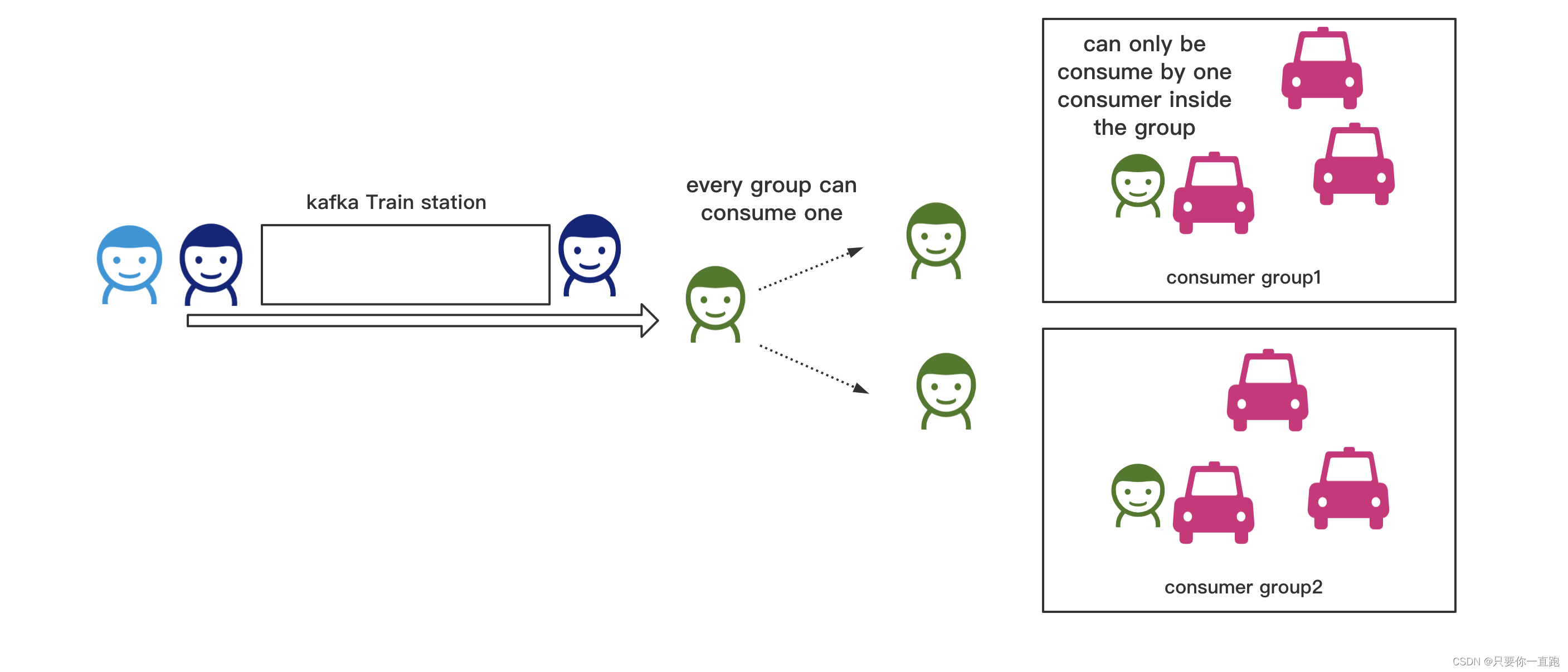
发送者将消息发送到消息队列中,消费者去消费,如果消费者有多个,他们会竞争地消费,也就是说对于某一条消息,只有一个消费者能“抢“到它。类似于火车站门口的出租车抢客的场景。
-
发布/订阅者模型
发送者将消息发送到一个topic(主题),消费者去消费这个主题。消费者之间是独立的,不会互相竞争,如果消费者有多个,他们都可以消费到同一条消息。有点像报社发布报纸和民众买报纸的场景
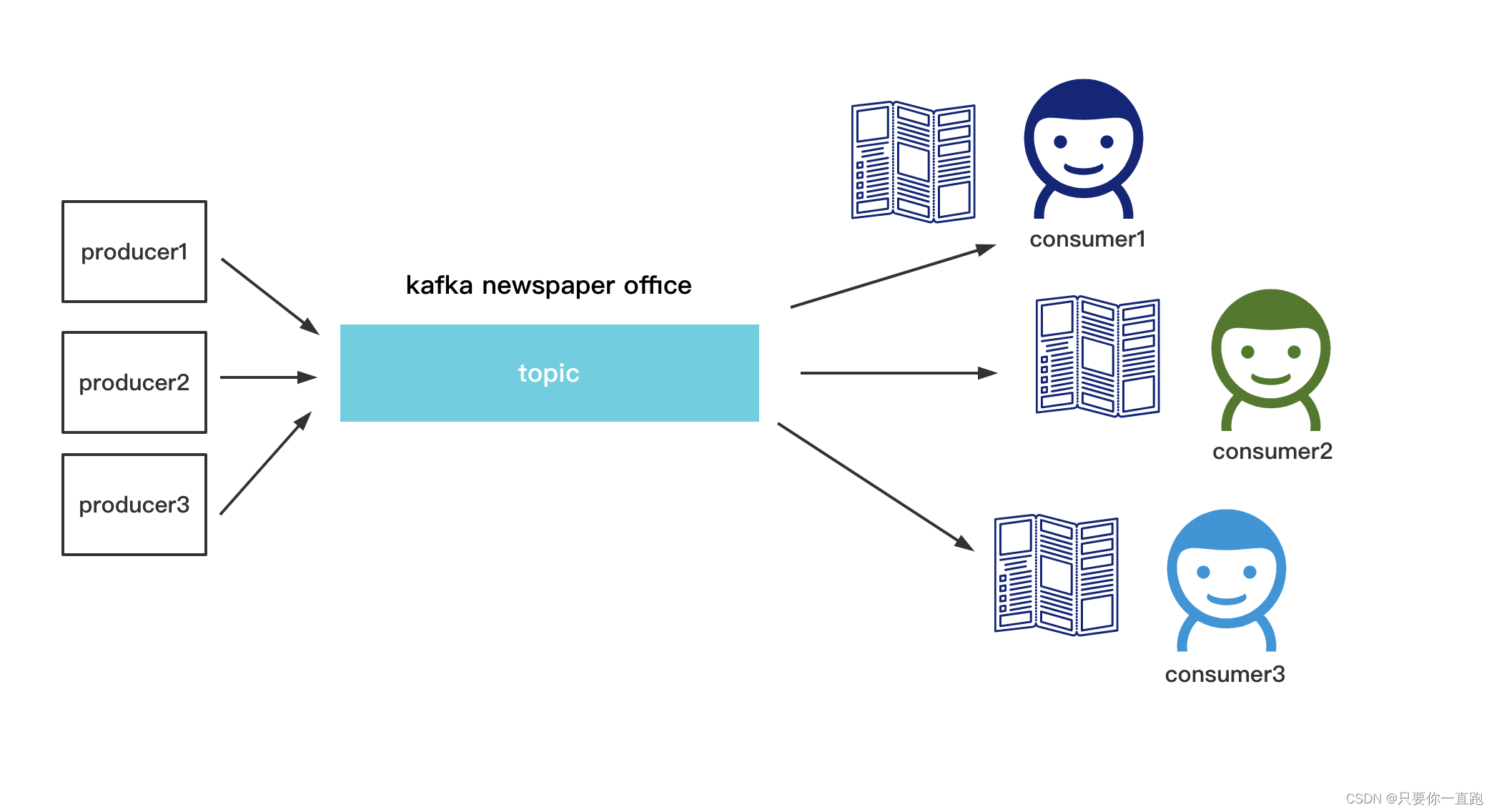
kafka支持以上的两种模型,在发布/订阅者模式中,发布和订阅的对象是topic,我们可以为每个应用或者每类数据创建专门的topic。向topic发送消息的客户端应用叫做producer,producer可以向多个topic发送消息。相应的,消费topic消息的客户端应用叫做consumer,comsumer也可以同时接受多个topic的消息。
为了提高发布/订阅者模型中消费者的消费能力,kafka引入了consumer group(消费者组)的机制,多个消费者组成一个consumer group来共同消费topic的消息。
对于topic的一条消息,每个消费者组都可以消费,但是消费者组内只有一个消费者能消费。消费者组和消费者组之间是独立的,没有竞争关系,消费者组内部有竞争关系,这有点像点对点模型和发布/订阅者模型的结合。
介绍了客户端的概念,我们再来介绍服务器的概念。kafka的服务器被称作broker,(broker直接翻译可以是中间商或者经纪人的意思)。broker接受和处理客户端的请求,也可以把消息存下来。
3.1 kafka保证高可用性的机制
一般来说,我们不会只部署一台broker,因为万一这台机器挂掉了,服务就不能提供服务了。我们一般会部署一堆broker来保证服务的高可用性,同时我们也不会把多个broker部署在同一台机器上,否则一台机器挂掉会影响几个broker服务进程。
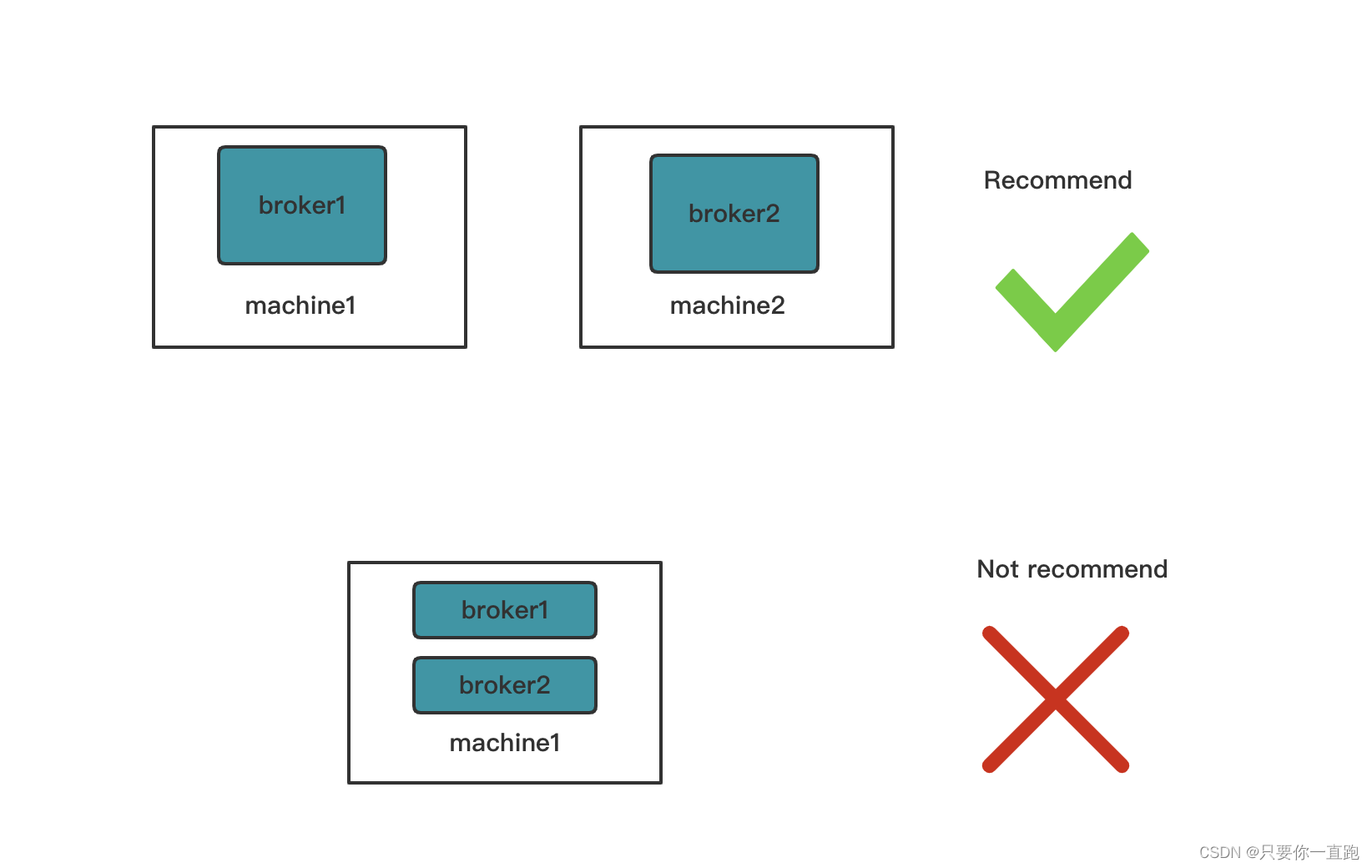
一堆broker组成了kafka集群。而集群是需要管理的,它借助zookeeper来管理的,这也就是为什么kafka依赖于zookeeper的原因。
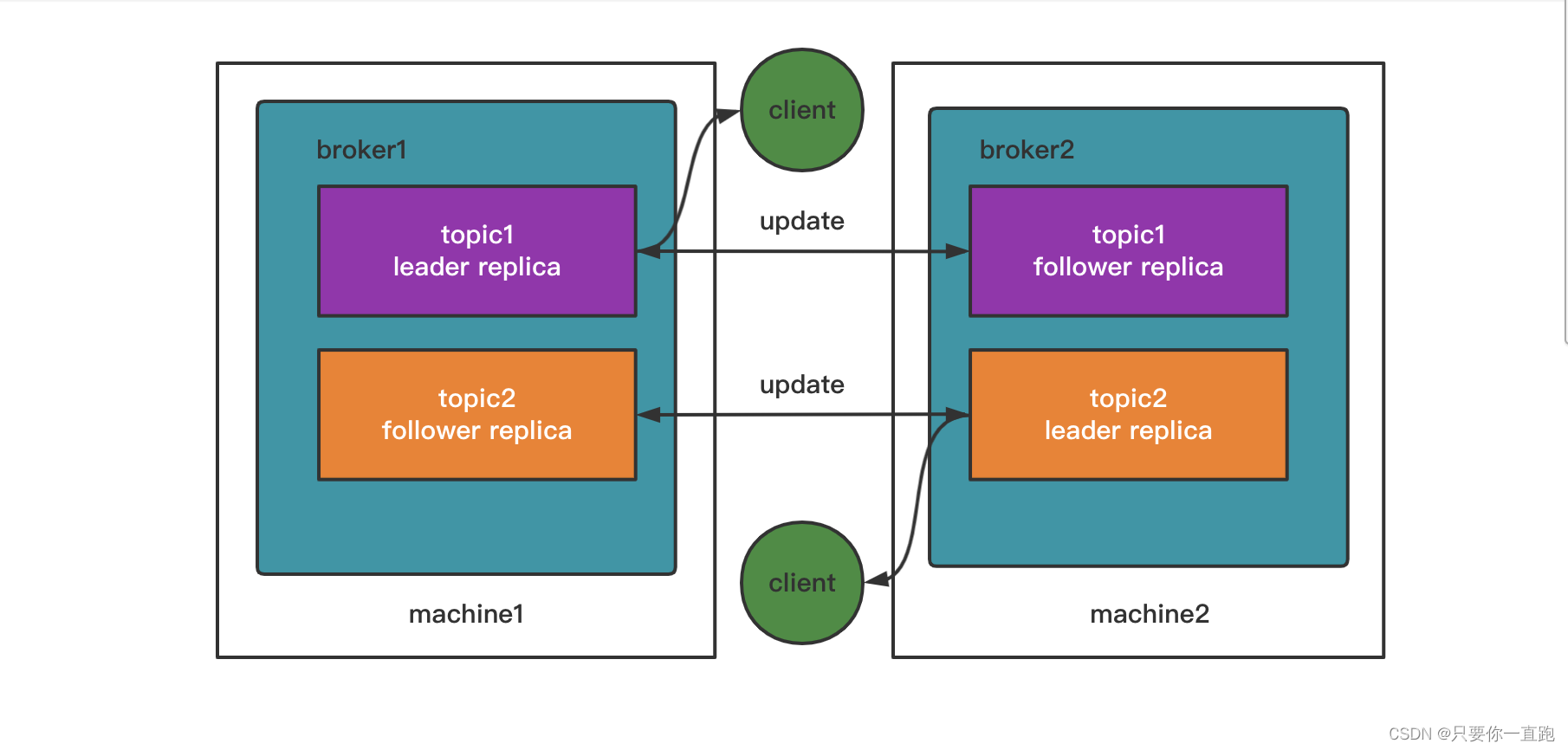
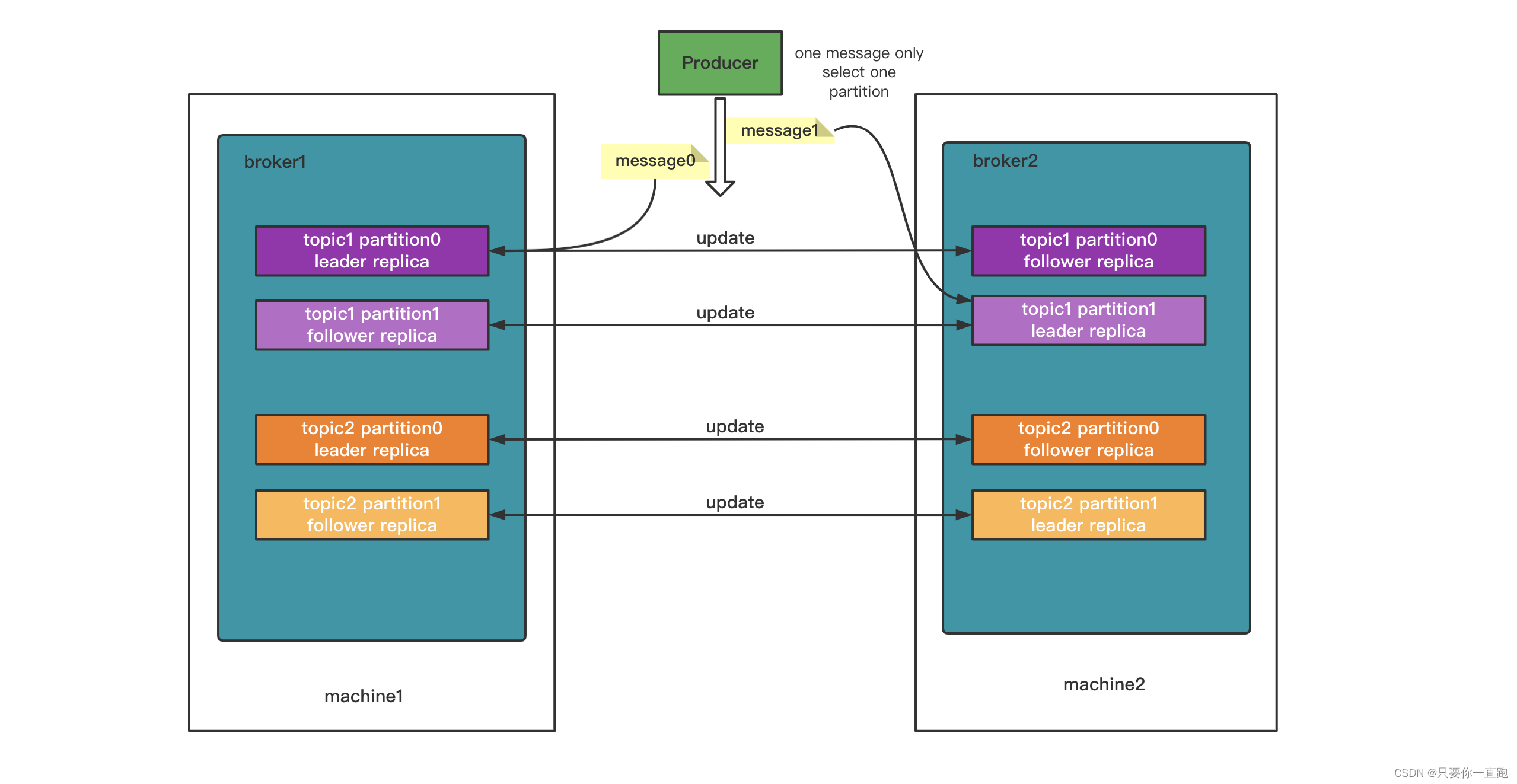
实现高可用性还有一个机制:备份机制。kafka拷贝相同的数据到不同的机器上,这样如果一台机器挂了,还有备份数据在。备份的副本叫做replica,副本的数量是可以配置的。
备份可以分为leader replica(领导者副本)和follower replica(跟随者副本),leader replica只有一个,它跟客户端进行交互,follower replica负责同步leader replica的状态,不客户端进行交互。
3.2 kafka保障伸缩性的机制
有了备份机制,kakfa可以保证对数据的持久话不会丢失。但是面临着一个问题,leader replica的数据太多了超过了单台broker的容纳能力了怎么办?kafka的解决办法是分割这些数据,把它们分到不同的broker里。这个机制叫做分区机制(partitioning)。
kafka将每个topic分成多个partition(分区),每个partition是一个有序的队列,produer的消息只会进入到一个partition。这个消息在partition中的位置叫做offset(位移),offset往往从0开始计数。
而刚刚提到的replica是对partitiond的replica,而不是对于topic的replica。所以最后的结构是这样的:
正文到此结束,希望大家喜欢,也欢迎大家一起交流和提出建议。
参考资料:
- 极客时间《kafka核心技术与实战系列》
- 分布式消息队列详解:10min搞懂同步和异步架构等问题