MySQL中 select count(*) 千万级别数据查询
我们在实际开发过程中常常会用遇到查询表中数据总数,或者携带where条件的查询总数,而使用count(*)的时候会很影响查询效率的,
例如
select count(*) from table
select count(*) from table where id = '' and column = ''
在MySQL中不同的存储引擎对于count(*)有不同的实现方式。
- MyISAM 引擎把一个表的总行数存在磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高。
- InnoDB引擎在执行count(*)时,需要把数据一行一行地从引擎中读取出来,然后累计计数。
当然,如果MyISAM后面也加上where条件的话,MyISAM也没有那么快,我们在实际开发中,多数都需要事务,所以建表都会选择InnoDB。
使用count(*) 的时候
1,一定需要走索引,能走辅助索引 (选择表中列较短的创建一个普通索引) 就走辅助索引,不能走也建议创建一个辅助索引。
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
使用索引和不使用索引查询数据真不是一样的。
2,如果使用count(*)建议一定是单表查询,所以建表的时候,希望有所考虑。
3,建议表中取消掉复合索引(组合索引) ,把复合索引拆解成普通索引(单列索引)
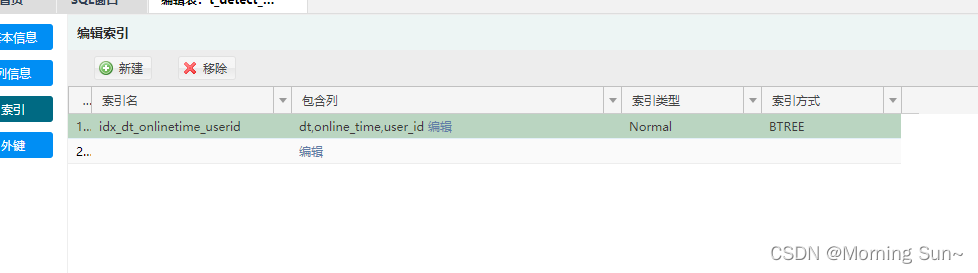
图片中复合索引,可拆解成普通索引,这样做的意义是,count(*) 在MySQL中会被进行优化,会走索引较短的列进行查询,如果是这种复合索引的话,我测试过3200W的数据大概需要120秒,而走单列索引的话只需要3秒。
建议需要使用count(*) 的话,用explain来查看是否走了索引,走了那一个索引,如果是复合索引,请修改成普通索引,在进行查询
explain select count(*) from table
explain select count(*) from table where id = '' and column = ''