MySQL��ʹ��
���ݿ�����ṹ
- ��ν��װMysql���ݿ�,������������װһ�����ݿ����ϵͳ(DBMS),�������������Թ���������ݿ�.DBMS(database manage system)
- һ�����ݿ��п��Դ��������,�Ա�������.
- ���ݿ����ϵͳ(DBMS),���ݿ�ͱ��Ĺ�ϵ��ͼ��ʾ:
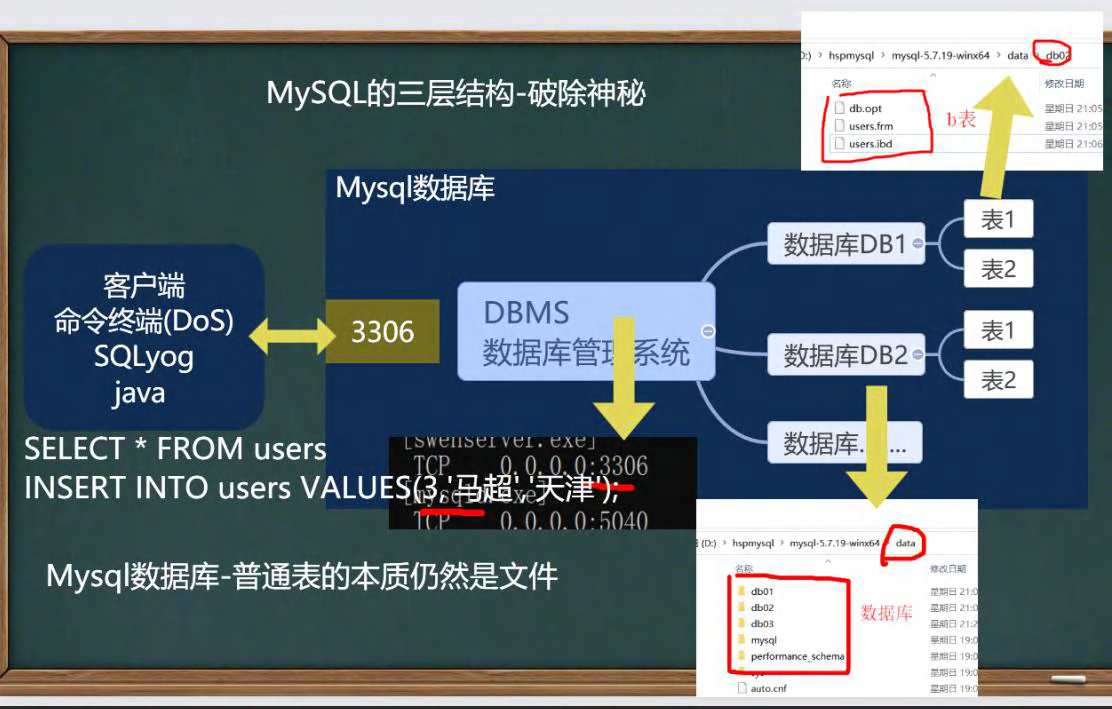
���������ݿ��еĴ洢��ʽ

SQL������
- DDL: ���ݶ������ [CREATE ��,�⡭]
- DML: ���ݲ������ [���� insert,�� update,ɾ�� delete]
- DQL: ���ݲ�ѯ��� [select]
- DCL: ���ݿ������ [�������ݿ�:�����û�Ȩ�� grant revoke]
�������ݿ�

CREATE DATABASE db01;
#Ĭ�ϲ����ִ�Сд
CREATE DATABASE db02 CHARACTER SET utf8
#ָ�����ִ�Сд
CREATE DATABASE db03 CHARACTER SET utf8 COLLATE utf8_bin
�鿴,ɾ�����ݿ�

SHOW DATABASES
#CREATE DATABASE `db01` /*!40100 DEFAULT CHARACTER SET utf8 */
#/*!40100 */��ʾ���ݿ�汾��4����
#�ڴ������ݿ�,����ʱ��,Ϊ�˹�ܹؼ���,����ʹ�÷����Ž��
SHOW CREATE DATABASE db01
#ɾ��
DROP DATABASE db01
���ݻָ����ݿ�
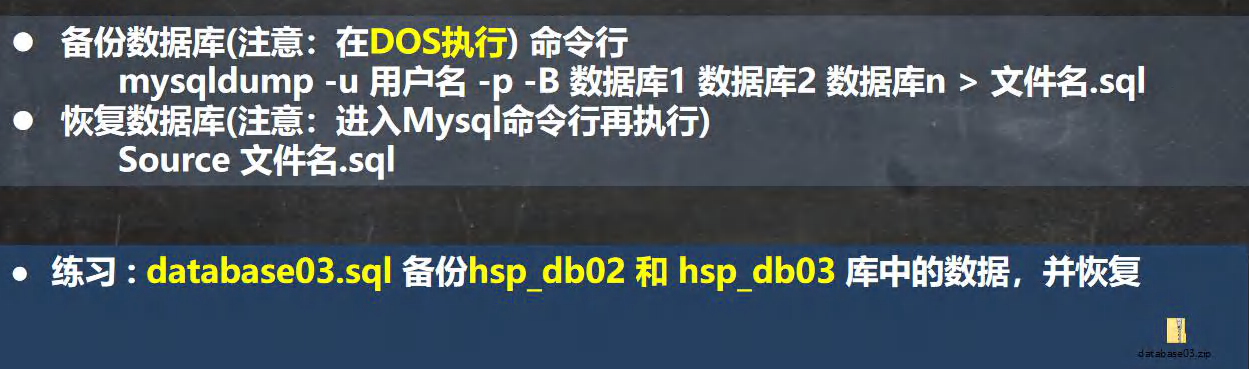
# ����ָ�����ݿָ���ļ�·��(��DOSִ��)
mysqldump -u root -p -B db02 db03 > F:\zxkworkspace\mysql\bak.sql
# ����ָ���ı�
# -u �û��� -p���� ���ݿ� ��1 ��2 >�ļ�·��
mysqldump -u -root -p db02 t1 > f:\zxkworkspace\mysql\bak1.sql
#�ָ�(Ҳ���Խ����ݵ��ļ�����ճ������ѯ��ȫ��ִ��)
mysql -u root -p
source F:\zxkworkspace\mysql\bak.sql
quit#�˳�
������
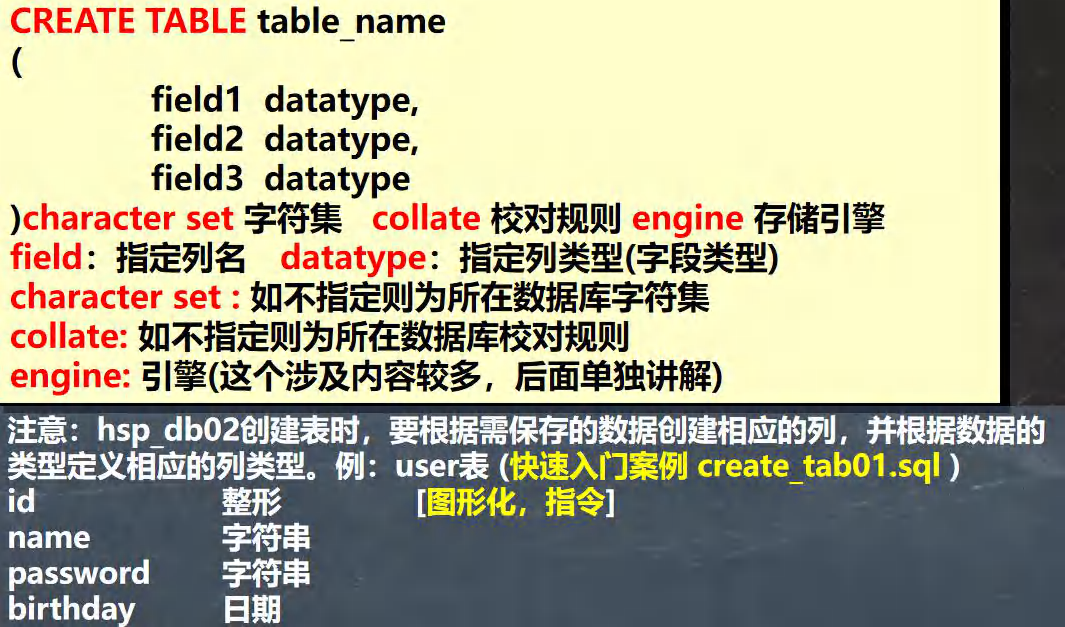
#ָ�����
#ע��:hsp_db02������ʱ,Ҫ�����豣������ݴ�����Ӧ����.
#id ���� [ͼ�λ�,ָ��]
#name �ַ���
#password �ַ���
#birthday ����
CREATE TABLE `user` (
id INT,
`name` VARCHAR(255),
`password` VARCHAR(255),
`birthday` DATE)
CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;#���� ENGINE MYISAM
Mysql������������(������)

��ֵ��(����)�Ļ���ʹ��

#ʹ��tinyint ����ʾ��Χ �з��� -128 ~ 127 ���û�з��� 0-255
#˵��: �����ַ���,У�����, �洢����,��ʦʹ��Ĭ��
#1. ���û��ָ�� unsinged , ��TINYINT�����з���
#2. ���ָ�� unsinged , ��TINYINT�������� 0-255
CREATE TABLE t3(
id TINYINT);
INSERT INTO t3 VALUES(-128);
SELECT * FROM t3
CREATE TABLE t4(
id TINYINT UNSIGNED);
INSERT INTO t4 VALUES(1);
INSERT INTO t4 VALUES(-5);
SELECT * FROM t4
��ֵ��(bit)��ʹ��

#��ʾbit���͵�ʹ��
#bit(m) m �� 1-64
#�������ݵķ�Χ���������λ����ȷ��,����m=8��ʾһ���ֽ�0~255
#��ʾ����bit
#��ѯʱ,��Ȼ������������ѯ
CREATE TABLE t05(num BIT(8));
INSERT INTO t05 VALUES(255);
SELECT * FROM t05;
SELECT * FROM t05 WHERE num=255;
��ֵ��(С��)�Ļ���ʹ��

#��ʾdecimal����.float.doubleʹ��
#������
CREATE TABLE t06(
num1 FLOAT,
num2 DOUBLE,
num3 DECIMAL(30,20));
#��������
INSERT INTO t06 VALUES(88.12345678912345,88.12345678912345,88.12345678912345);
SELECT * FROM t06;
CREATE TABLE t07(num DECIMAL(65));
INSERT INTO t07 VALUES(8999999933338388388383838838383009338388383838383838383);
SELECT * FROM t07;
CREATE TABLE t08(num BIGINT);
INSERT INTO t08 VALUES(8999999933338388388383838838383009338388383838383838383);
SELECT * FROM t08;#Out of range value for column 'num' at row 1
�ַ����Ļ���ʹ��
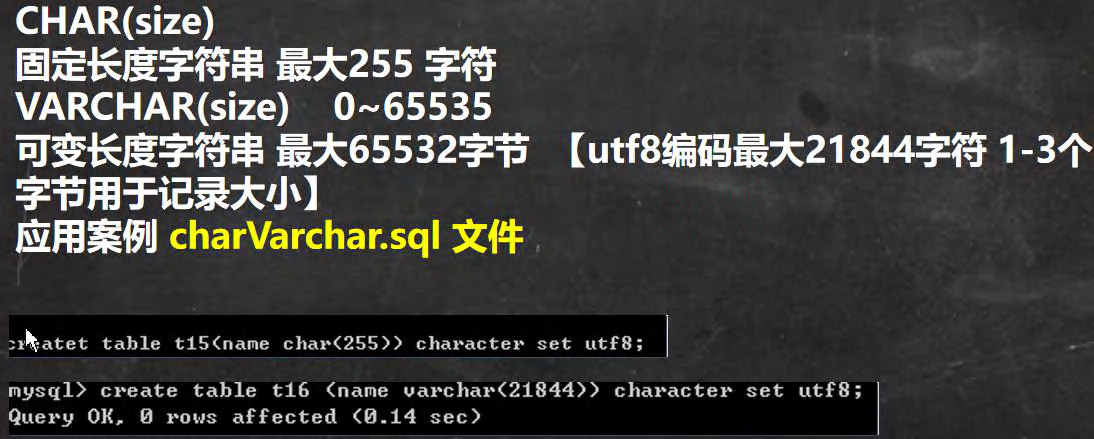
#��ʾ�ַ�������ʹ��char varchar
#ע�͵Ŀ�ݼ� shift+ctrl+c , ע��ע�� shift+ctrl+r
-- CHAR(size)
-- �̶������ַ��� ���255 �ַ�
-- VARCHAR(size) 0~65535�ֽ�
-- �ɱ䳤���ַ��� ���65532�ֽ� ��utf8�������21844�ַ� 1-3���ֽ����ڼ�¼��С��
-- ������ı����� utf8 varchar(size) size = (65535-3) / 3 = 21844
-- ������ı����� gbk varchar(size) size = (65535-3) / 2 = 32766
CREATE TABLE t09(`name` CHAR(255));
CREATE TABLE t10(`name` VARCHAR(21844));
CREATE TABLE t10(`name` VARCHAR(32766)) CHARSET gbk;
DROP TABLE t10;
ʹ��ϸ��:



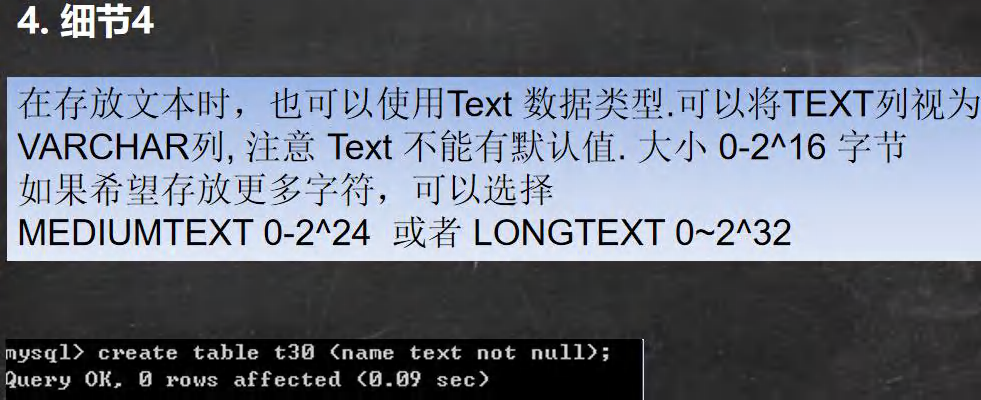
#��ʾ�ַ������͵�ʹ��ϸ��
#char(4) �� varchar(4) ���4��ʾ�����ַ�,�������ֽ�, �������ַ��Ǻ��ֻ�����ĸ
CREATE TABLE t11(`name` CHAR(4));
INSERT INTO t11 VALUES('����');#����4���ַ����ڴ�
SELECT * FROM t11;
CREATE TABLE t12(`name` VARCHAR(4));
INSERT INTO t12 VALUES('����');#����2���ַ����ڴ�
SELECT * FROM t12;
#���varchar ������,���Կ���ʹ��mediumtext ����longtext,
#������,����ʹ��ֱ��ʹ��text
CREATE TABLE t13(content TEXT ,content2 MEDIUMTEXT,content3 LONGTEXT);
INSERT INTO t13 VALUES('��˳ƽ����', '��˳ƽ����100', '��˳ƽ����1000~~');
SELECT * FROM t13;
�������͵Ļ���ʹ��

CREATE TABLE t14 (
birthday DATE,
job_time DATETIME,
login_time TIMESTAMP
NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP);
SELECT * FROM t14;
INSERT INTO t14(birthday,job_time)
VALUES('2022-11-11','2022-11-11 10:10:10');
���������
������
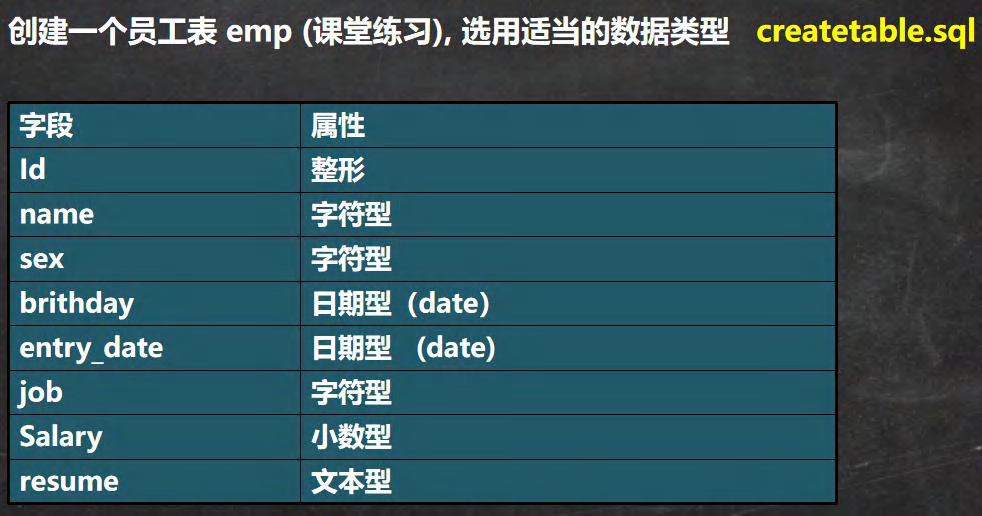
CREATE TABLE `emp`(
id INT,
`name` VARCHAR(32),
sex CHAR(1),
birthday DATE,
entry_date DATE,
job VARCHAR(32),
salary DOUBLE,
resume TEXT) CHARSET utf8 COLLATE utf8_bin ENGINE INNODB;
DROP TABLE `emp`;
SELECT * FROM `emp`;
INSERT INTO `emp`
VALUES(100,'����','��','2000-11-11',
'2010-11-10 11:11:11','Ѳɽ',3000,'����������Ѳɽ');
�ı�

��ʾ:ALTER���Ϊ�ı��ṹ�����,��ֱ�Ӳ���ijһ�еļ�¼
#�ı�
#��rusume��������һ����
ALTER TABLE `emp`
ADD image VARCHAR(32) NOT NULL DEFAULT '' AFTER RESUME
DESC emp -- ��ʾ���ṹ,���Բ鿴����������
#�ı�
#��job��,ʹ�䳤��Ϊ60
ALTER TABLE emp
MODIFY job VARCHAR(60) NOT NULL DEFAULT ''-- Ĭ��ֵ����Ϊ��,Ĭ����''�ַ�
#ɾ����
ALTER TABLE emp
DROP sex
#�ı���
RENAME TABLE emp TO employee
#���ַ���
ALTER TABLE employee CHARACTER SET utf8
#������
ALTER TABLE employee
CHANGE `name` user_name VARCHAR(32) NOT NULL DEFAULT ''
DESC employee
���ݿ� CRUD���
C[create]R[read]U[update]D[delete]����Ӧ:
- Insert��� (��������)
- Update��� (��������)
- Delete��� (ɾ������)
- Select��� (��������)
Insert���
ʹ�� INSERT �������в�������

#��ϰINSERT���
CREATE TABLE `goods`(id INT,goods_name VARCHAR(10),price DOUBLE);
-- ��������
INSERT INTO `goods`(id,goods_name,price)
VALUES(10,'��Ϊ�ֻ�',2000);
SELECT * FROM goods;
#��ϰ
DESC employee;
INSERT INTO employee VALUES(200,'����','1999-10-10','2000-11-11 11:11:11','����',10000000,'����ȥѲɽ','�ʰ�');
SELECT * FROM employee;
ϸ��˵��:
#˵��insert ����ϸ��
-- 1.���������Ӧ���ֶε�����������ͬ��
-- ���� �� 'abc' ���ӵ� int ���ͻ����
DESC goods;
SELECT * FROM goods;
INSERT INTO goods (id,goods_name,price)
VALUES('��˳ƽ','С���ֻ�',2000);-- wrong
-- 2. ���ݵij���Ӧ���еĹ涨��Χ��,����:���ܽ�һ������Ϊ80���ַ������뵽����Ϊ40�����С�
INSERT INTO goods (id,goods_name,price)
VALUES('��˳ƽ','С���ֻ�С���ֻ�С���ֻ�С���ֻ�',2000);-- wrong
-- 3. ��values���г�������λ�ñ����뱻������е�����λ�����Ӧ��
INSERT INTO goods(id,goods_name,price)
VALUES('vivo�ֻ�',40,3000);-- wrong
INSERT INTO goods(goods_name,id,price)
VALUES('vivo�ֻ�',40,3000);-- true
-- 4. �ַ�������������Ӧ�����ڵ������С�
INSERT INTO goods(id,goods_name,price)
VALUES(40,vivo�ֻ�,3000);-- wrong
INSERT INTO goods(id,goods_name,price)
VALUES('50','vivo�ֻ�',3000);-- true:int�����ַ������Զ�תint��
-- 5. �п��Բ����ֵ[ǰ���Ǹ��ֶ�����Ϊ��],insert into table value(null)
INSERT INTO goods(id,goods_name,price)
VALUES(40,'vovo�ֻ�',null);
-- 6. insert into tab_name (����..) values (),(),() ��ʽ���Ӷ�����¼
INSERT INTO `goods` (id,goods_name,price)
VALUES(50,'�����ֻ�',2000),(60,'�����ֻ�',3000);
-- 7. ����Ǹ����е������ֶ���������,���Բ�дǰ����ֶ�����
INSERT INTO goods VALUES(70,'IBM�ֻ�',5000);-- ʡ��д������ʹ��Ĭ��ֵ����
-- 8. Ĭ��ֵ��ʹ��,������ij���ֶ�ֵʱ,�����Ĭ��ֵ�ͻ�����Ĭ��ֵ,����
-- ���ij���� û��ָ�� not null ,��ô����������ʱ,û�и���ֵ,���Ĭ�ϸ�null
-- �������ϣ��ָ��ij���е�Ĭ��ֵ,�����ڴ�����ʱָ��
-- ����Ĭ��ֵ
ALTER TABLE goods
MODIFY price DOUBLE NULL DEFAULT 500;
INSERT INTO goods(id,goods_name)
VALUES(80,'�����ֻ�');
Update���
ʹ�� update ����ı�������

#��ʾupdate���
#�ı��еļ�¼û��where �����м�¼
SELECT * FROM employee;
UPDATE employee SET salary =5000;
UPDATE employee SET salary =3000 WHERE user_name='����';
UPDATE employee SET salary =salary+1000 WHERE user_name='����';
#�����Ķ����
UPDATE employee SET salary=salary+1000,job='������'
WHERE user_name='����';
ϸ��˵��:

Delete���
ʹ�� delete ���ɾ����������
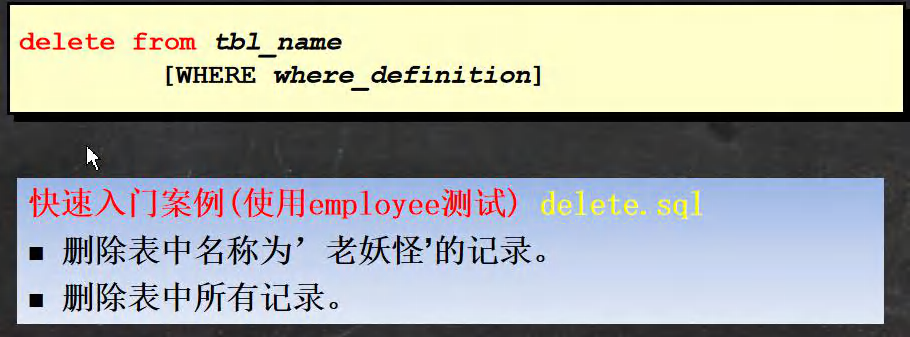
-- delete���û��where��ɾ����������
DELETE FROM employee
WHERE user_name='����';
INSERT INTO employee VALUES(200,'����','1999-10-10','2000-11-11 11:11:11','����',10000000,'����ȥѲɽ','�ʰ�');
SELECT * FROM employee;
-- ɾ����������
DELETE FROM employee;
-- ɾ�����
DROP TABLE employee;
ϸ��˵��:

Select���


-- ****�����µı�(student)********
create table student(
id int not null default 1,
name varchar(20) not null default '',
chinese float not null default 0.0,
english float not null default 0.0,
math float not null default 0.0
);
insert into student(id,name,chinese,english,math) values(1,'��˳ƽ',89,78,90);
insert into student(id,name,chinese,english,math) values(2,'�ŷ�',67,98,56);
insert into student(id,name,chinese,english,math) values(3,'�ν�',87,78,77);
insert into student(id,name,chinese,english,math) values(4,'����',88,98,90);
insert into student(id,name,chinese,english,math) values(5,'����',82,84,67);
insert into student(id,name,chinese,english,math) values(6,'ŷ����',55,85,45);
insert into student(id,name,chinese,english,math) values(7,'����',75,65,30);
DELETE FROM student
WHERE id=5;
-- ��ѯ��������ѧ������Ϣ��
SELECT * FROM student;
-- ��ѯ��������ѧ���������Ͷ�Ӧ��Ӣ��ɼ���
SELECT `name`,english FROM student;
-- ���˱����ظ����� distinct ��
SELECT DISTINCT * FROM student;
-- Ҫ��ѯ�ļ�¼,ÿ���ֶζ���ͬ,�Ż�ȥ��
SELECT DISTINCT math FROM student;
ʹ�ñ���ʽ��AS���


-- select ����ʹ��
SELECT * FROM student;
-- ͳ��ÿ��ѧ���ܷ�
SELECT `name`,(chinese+english+math) FROM student;
-- �������ܷ��ϼ�10��
SELECT `name`,(chinese+english+math+10) FROM student;
-- ���ܷ�ȡ����
SELECT `name` AS '����',(chinese+english+math+10) AS total_score FROM student;
where���˲�ѯ
�� where �Ӿ��о���ʹ�õ������
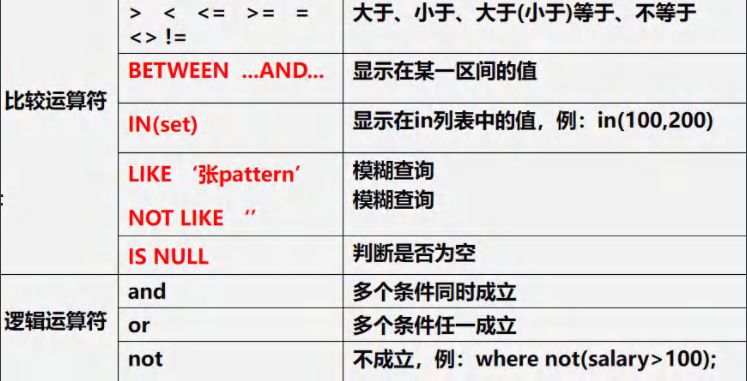
��ϰ:

#ʹ��WHERE�Ӿ���й��˲�ѯ
SELECT * FROM student;
SELECT `name`,(chinese+math+english) `sum`
FROM student;-- as����ʡ��
SELECT * FROM student WHERE `name`='����';
SELECT * FROM student WHERE english>90;
SELECT * FROM student
WHERE (chinese+math+english)>200;
-- exercise
-- ��ѯmath����60 ����(and) id����4��ѧ���ɼ�
SELECT * FROM student WHERE math>60 AND id>4;
-- ��ѯӢ��ɼ��������ijɼ���ͬѧ
SELECT * FROM student WHERE english>chinese;
-- ��ѯ�ִܷ���200�� ���� ��ѧ�ɼ�С�����ijɼ�,�����Ե�ѧ��.
-- ��% ��ʾ �����Ժ���ͷ�ľͿ���
SELECT * FROM student
WHERE (chinese+math+english)>200 AND math<chinese AND `name` LIKE '��%';
-- ��ѯӢ������� 80-90֮���ͬѧ��
SELECT * FROM student WHERE english BETWEEN 80 AND 90;
-- between .. and .. �� ������
-- ��ѯ��ѧ����Ϊ89,90,91��ͬѧ��
SELECT * FROM student WHERE math=89 OR math=90 OR math=91;
SELECT * FROM student WHERE math IN (89,90,91);
-- ��ѯ���������ѧ���ɼ���
SELECT * FROM student WHERE `name` LIKE '��%';
-- ��ѯ��ѧ��>80,���ķ�>80��ͬѧ
order by �Ӿ�
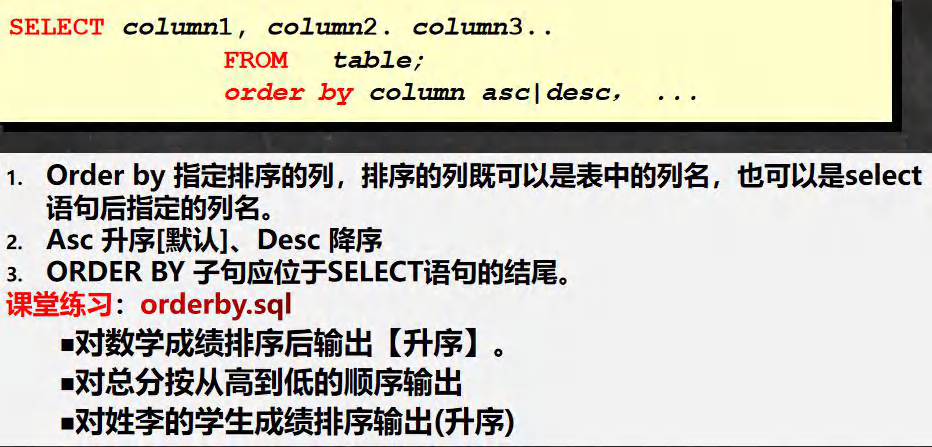
SELECT * FROM student;
INSERT INTO student VALUES(8,'���',45,65,99);
-- ��ʾorder byʹ��
-- ����ѧ�ɼ���������
SELECT * FROM student ORDER BY math;
SELECT * FROM student ORDER BY math DESC;
-- ���ֽܷ������
SELECT `name`,(chinese+math+english) total_score FROM student ORDER BY (chinese+math+english) DESC;
-- �������ѧ���ɼ��������
SELECT *, (chinese+math+english) total_score FROM student WHERE `name` LIKE '��%' ORDER BY total_score;
����
�ϼ�/�ۺ�/ͳ�ƺ���
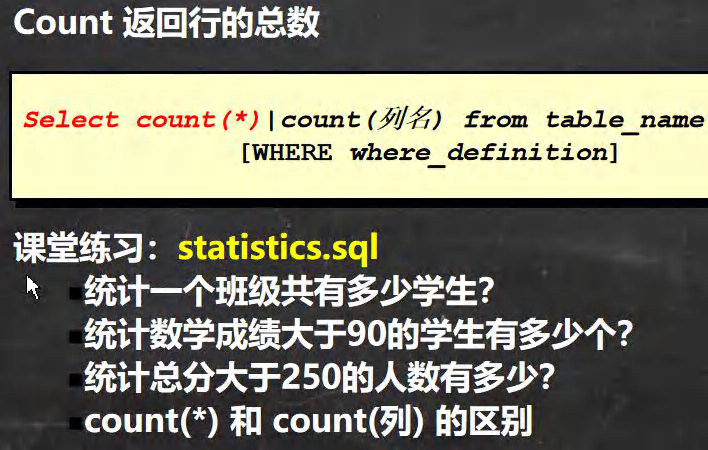


-- ��ʾmysql��ͳ�ƺ���(�ۺϺ���)��ʹ��
-- ͳ��һ�����е�ѧ��
SELECT COUNT(*) FROM student;
-- ͳ����ѧ�ɼ�����90 ��ѧ��
SELECT COUNT(*) FROM student WHERE math>90;
-- ͳ����������250������
SELECT COUNT(*) FROM student WHERE (chinese+math+english>250);
-- count(*) ��count(��)������
CREATE TABLE t15(
`name` VARCHAR(20));
INSERT INTO t15 VALUES('tom');
INSERT INTO t15 VALUES('jack');
INSERT INTO t15 VALUES('mary');
INSERT INTO t15 VALUES(NULL);
SELECT COUNT(*) FROM t15;-- ����������4
SELECT COUNT(`name`) FROM t15;-- ���ظ��ֶβ�Ϊnull������3
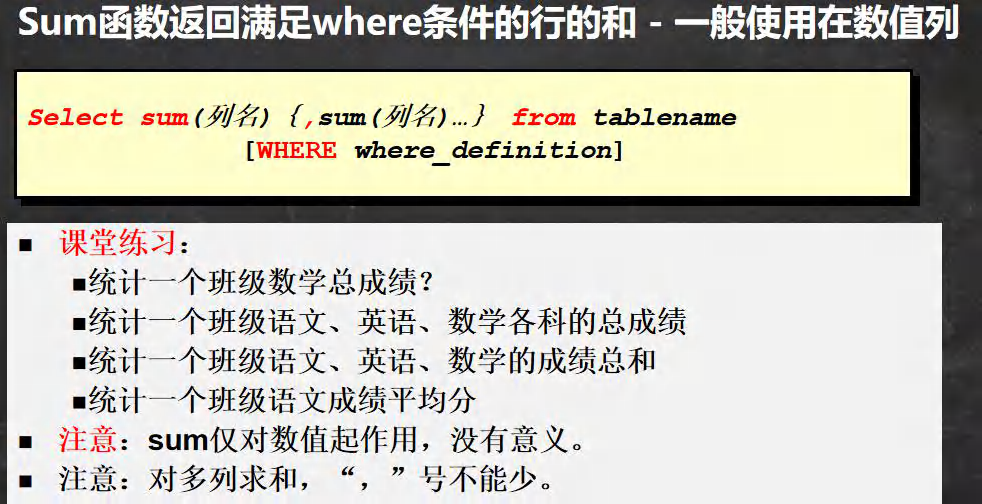
-- ��ʾsum������ʹ��
-- ͳ��һ������ѧ�ܳɼ�
SELECT SUM(math) FROM student;
-- �����ܳɼ�
SELECT SUM(math),SUM(chinese),SUM(english) FROM student;
-- ���Ƴɼ��ܺ�
SELECT SUM(chinese+math+english) FROM student;
-- ���ijɼ�ƽ����
SELECT SUM(chinese)/COUNT(*) FROM student;
-- ��ʾavg��ʹ��
SELECT AVG(chinese) FROM student;
-- �ܷ�ƽ����
SELECT AVG(chinese+math+english) FROM student;
-- ��ʾmax��min��ʹ��
SELECT MAX(chinese+math+english),MIN(chinese+math+english) FROM student;
��� group by ,having �Ӿ�ʹ��



CREATE TABLE dept( /*���ű�*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
);
INSERT INTO dept VALUES(10, 'ACCOUNTING', 'NEW YORK'), (20, 'RESEARCH', 'DALLAS'), (30, 'SALES', 'CHICAGO'), (40, 'OPERATIONS', 'BOSTON');
#������EMP��Ա
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*���*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*����*/
job VARCHAR(9) NOT NULL DEFAULT "",/*����*/
mgr MEDIUMINT UNSIGNED ,/*�ϼ����*/
hiredate DATE NOT NULL,/*��ְʱ��*/
sal DECIMAL(7,2) NOT NULL,/*нˮ*/
comm DECIMAL(7,2) ,/*����*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*���ű��*/
);
INSERT INTO emp VALUES(7369, 'SMITH', 'CLERK', 7902, '1990-12-17', 800.00,NULL , 20),
(7499, 'ALLEN', 'SALESMAN', 7698, '1991-2-20', 1600.00, 300.00, 30),
(7521, 'WARD', 'SALESMAN', 7698, '1991-2-22', 1250.00, 500.00, 30),
(7566, 'JONES', 'MANAGER', 7839, '1991-4-2', 2975.00,NULL,20),
(7654, 'MARTIN', 'SALESMAN', 7698, '1991-9-28',1250.00,1400.00,30),
(7698, 'BLAKE','MANAGER', 7839,'1991-5-1', 2850.00,NULL,30),
(7782, 'CLARK','MANAGER', 7839, '1991-6-9',2450.00,NULL,10),
(7788, 'SCOTT','ANALYST',7566, '1997-4-19',3000.00,NULL,20),
(7839, 'KING','PRESIDENT',NULL,'1991-11-17',5000.00,NULL,10),
(7844, 'TURNER', 'SALESMAN',7698, '1991-9-8', 1500.00, NULL,30),
(7900, 'JAMES','CLERK',7698, '1991-12-3',950.00,NULL,30),
(7902, 'FORD', 'ANALYST',7566,'1991-12-3',3000.00, NULL,20),
(7934,'MILLER','CLERK',7782,'1992-1-23', 1300.00, NULL,10);
#���ʼ����
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,-- ���ʼ���
losal DECIMAL(17,2) NOT NULL,-- �ü��������
hisal DECIMAL(17,2) NOT NULL-- �ü�����߹���
);
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
SELECT * FROM dept;
SELECT * FROM emp;
SELECT * FROM salgrade;
#��ʾgroup by+having
-- ÿ�����ŵ�ƽ�����ʺ���߹���
SELECT AVG(sal),MAX(sal),deptno FROM emp GROUP BY deptno;
SELECT sal FROM emp GROUP BY deptno;
-- ÿ�����ŵ�ÿ�ָ�λ��ƽ�����ʺ������
-- ?��ʾÿ�����ŵ�ÿ�ָ�λ��ƽ�����ʺ������
-- ��ʦ���� 1. ��ʾÿ�����ŵ�ƽ�����ʺ������
-- 2. ��ʾÿ�����ŵ�ÿ�ָ�λ��ƽ�����ʺ������
SELECT AVG(sal),MIN(sal),deptno,job FROM emp GROUP BY deptno,job;
-- ��ʾƽ�����ʵ���2000�IJ��źź�����ƽ������
SELECT deptno,AVG(sal) AS `avg` FROM emp GROUP BY deptno HAVING `avg` <=2000 ;
�ַ�����غ���
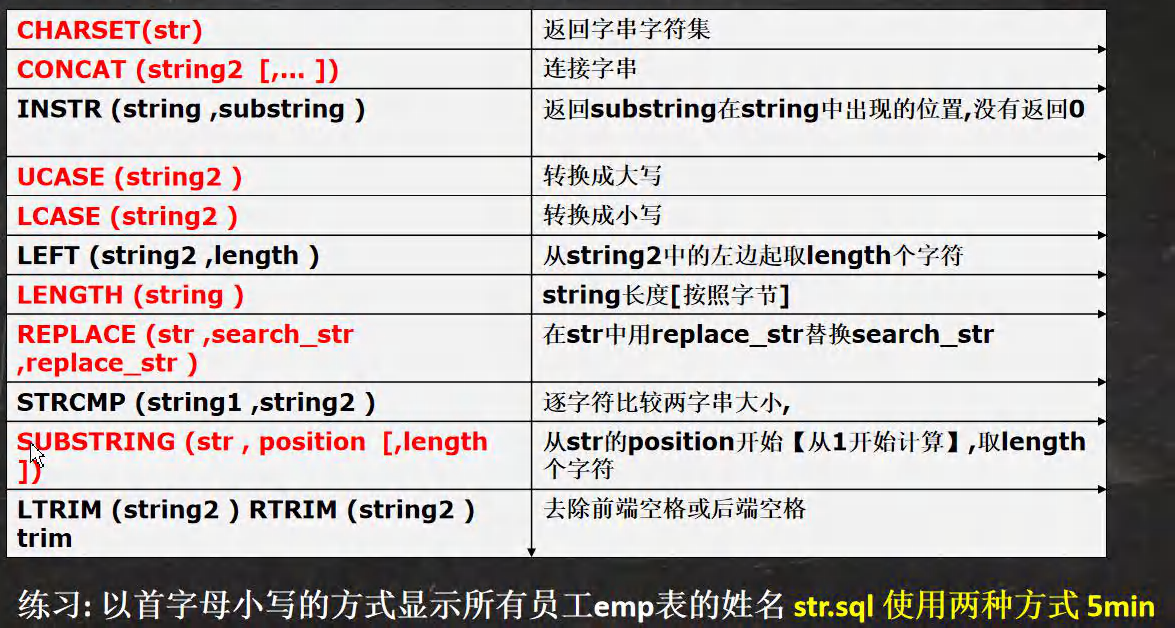
-- ��ʾ�ַ�����غ���
SELECT * FROM emp;
-- CHARSET(str) �����ִ��ַ���
SELECT CHARSET(`ename`) FROM emp;
-- CONCAT (string2 [,... ]) �����ִ�, �������ƴ�ӳ�һ��
SELECT CONCAT(ename,'������',job) FROM emp;
-- INSTR (string ,substring ) ����substring��string�г��ֵ�λ��,û�з���0
-- dual ��Ԫ��, ϵͳ�� ������Ϊ���Ա�ʹ��
SELECT INSTR('zxkedu','edu') FROM DUAL;
-- UCASE (string2 ) ת���ɴ�д
SELECT UCASE(ename) FROM emp;
-- LCASE (string2 ) ת����Сд
SELECT LCASE(ename) FROM emp;
-- LEFT (string2 ,length ) ��string2�е������ȡlength���ַ�
-- RIGHT (string2 ,length ) ��string2�е��ұ���ȡlength���ַ�
SELECT LEFT(ename,2) FROM emp;
SELECT RIGHT(ename,2) FROM emp;
-- LENGTH (string ) string����[�����ֽ�]
SELECT LENGTH(ename) FROM emp;
-- REPLACE (str ,search_str ,replace_str )
-- ��str����replace_str�滻search_str
-- �����manager ���滻�� ����(���ִ�Сд)
SELECT ename,REPLACE(job,'MANAGER','����') FROM emp;
-- STRCMP (string1 ,string2 ) ���ַ��Ƚ����ִ���С
SELECT STRCMP('zk','zxk') FROM DUAL;
-- SUBSTRING (str , position [,length ])
-- ��str��position��ʼ����1��ʼ���㡿,ȡlength���ַ�
-- ��ename �еĵ�һ��λ�ÿ�ʼȡ��2���ַ�
SELECT SUBSTRING(ename,2) FROM emp;
-- LTRIM (string2 ) RTRIM (string2 ) TRIM(string)
-- ȥ��ǰ�˿ո���˿ո�
SELECT LTRIM(' zxk') FROM DUAL;
SELECT RTRIM('zxk ') FROM DUAL;
SELECT TRIM(' zxk ') FROM DUAL;
-- ��ϰ: ������ĸСд�ķ�ʽ��ʾ����Ա��emp��������
-- ����1
-- ˼·��ȡ��ename �ĵ�һ���ַ�,ת��Сд��
-- �����ͺ�����ַ�������ƴ���������
-- method01
SELECT CONCAT(LCASE(LEFT(ename,1) ),SUBSTRING(ename,2) ) newname1 FROM emp;
-- method02
SELECT CONCAT(LCASE(SUBSTRING(ename,1,1) ),SUBSTRING(ename,2) ) newname2 FROM emp;
��ѧ��غ���
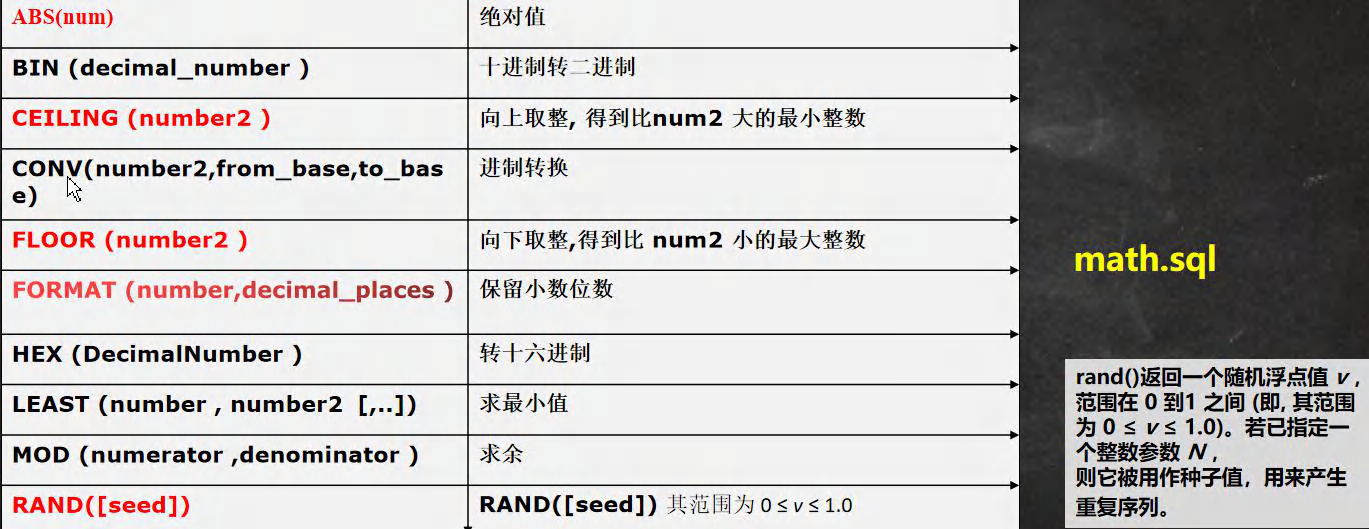
-- ��ʾ��ѧ��غ���
-- ABS(num) ����ֵ
SELECT ABS(-15) FROM DUAL;
-- BIN (decimal_number )ʮ����ת������
SELECT BIN(10) FROM DUAL;
-- CEILING (number2 ) ����ȡ��, �õ���num2 �����С����
SELECT CEILING(1.1) FROM DUAL;
-- CONV(number2,from_base,to_base) ����ת��
-- ����ĺ����� 8 ��ʮ���Ƶ�8, ת�� 2�������
SELECT CONV(16,16,10) FROM DUAL;
-- ����ĺ����� 8 ��16���Ƶ�8, ת�� 2�������
-- FLOOR (number2 ) ����ȡ��,�õ��� num2 С���������
SELECT FLOOR(-1.1) FROM DUAL;
-- FORMAT (number,decimal_places ) ����С��λ��(��������)
SELECT FORMAT(78.125458,2) FROM DUAL;
-- HEX (DecimalNumber ) תʮ������
SELECT CONV(32,10,16) FROM DUAL;
-- LEAST (number , number2 [,..]) ����Сֵ
SELECT LEAST(0,1,-10,4) FROM DUAL;
-- MOD (numerator ,denominator ) ����
SELECT MOD(10,3) FROM DUAL;
-- RAND([seed]) RAND([seed]) ��������� �䷶ΧΪ 0 �� v �� 1.0
-- �Ϻ�˵��
-- 1. ���ʹ�� rand() ÿ�η��ز�ͬ������� ,�� 0 �� v �� 1.0
-- 2. ���ʹ�� rand(seed) ���������, ��Χ 0 �� v �� 1.0, ���seed����,
-- �������Ҳ������
SELECT RAND() FROM DUAL;
SELECT RAND(3) FROM DUAL;
SELECT CURRENT_TIMESTAMP() FROM DUAL;
ʱ��������غ���
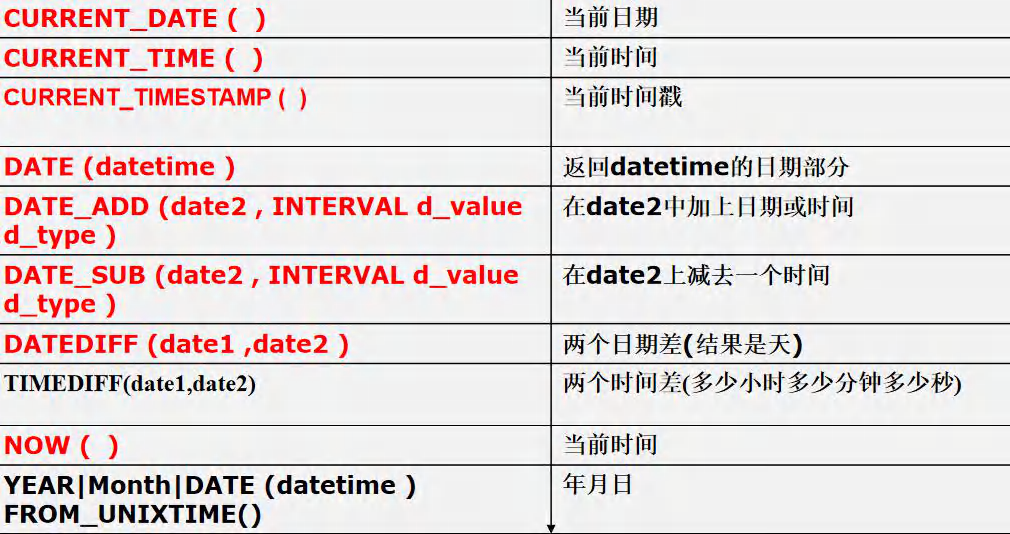
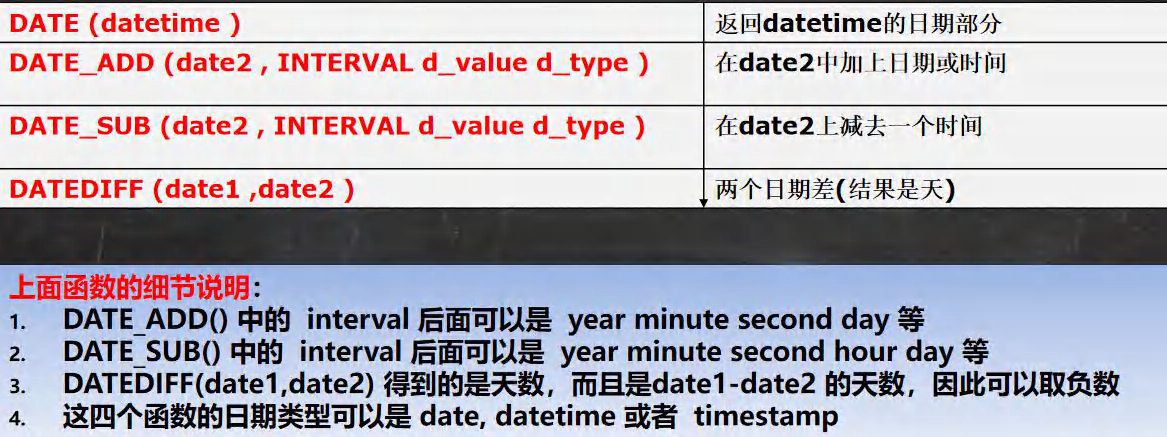

-- ����ʱ����غ���
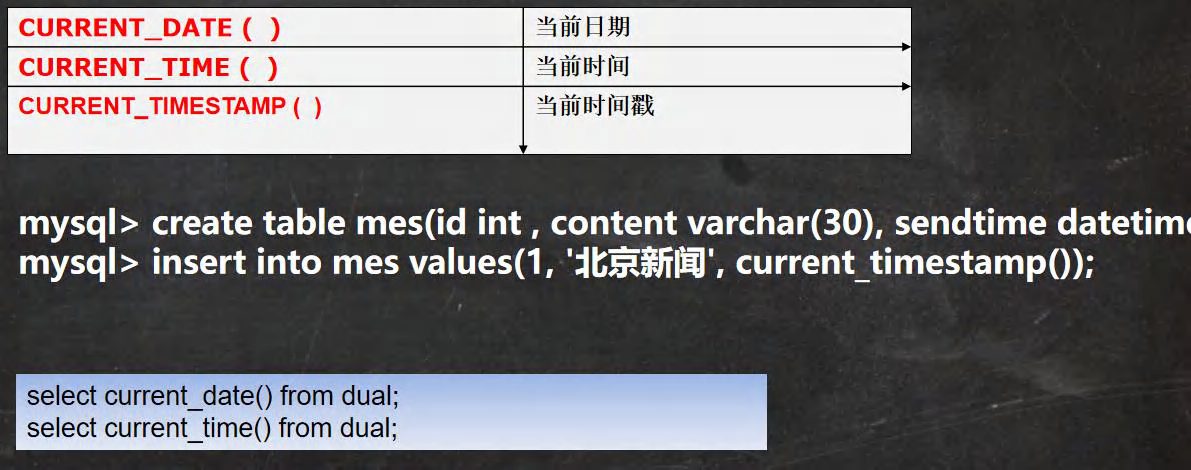
-- CURRENT_DATE ( ) ��ǰ����
SELECT CURRENT_DATE() FROM DUAL;
-- CURRENT_TIME ( ) ��ǰʱ��
SELECT CURRENT_TIME() FROM DUAL;
-- CURRENT_TIMESTAMP ( ) ��ǰʱ���
SELECT CURRENT_TIMESTAMP() FROM DUAL;
-- �������Ա� ��Ϣ��
CREATE TABLE mes(
id INT ,
content VARCHAR(30),
send_time DATETIME);
-- ����һ����¼
INSERT INTO mes
VALUES(1, '��������', CURRENT_TIMESTAMP());
INSERT INTO mes VALUES(2, '�Ϻ�����', NOW());
INSERT INTO mes VALUES(3, '��������', NOW());
UPDATE mes SET send_time=NOW() WHERE id=2;-- update
SELECT * FROM mes ORDER BY send_time;
SELECT * FROM mes;
SELECT NOW() FROM DUAL;
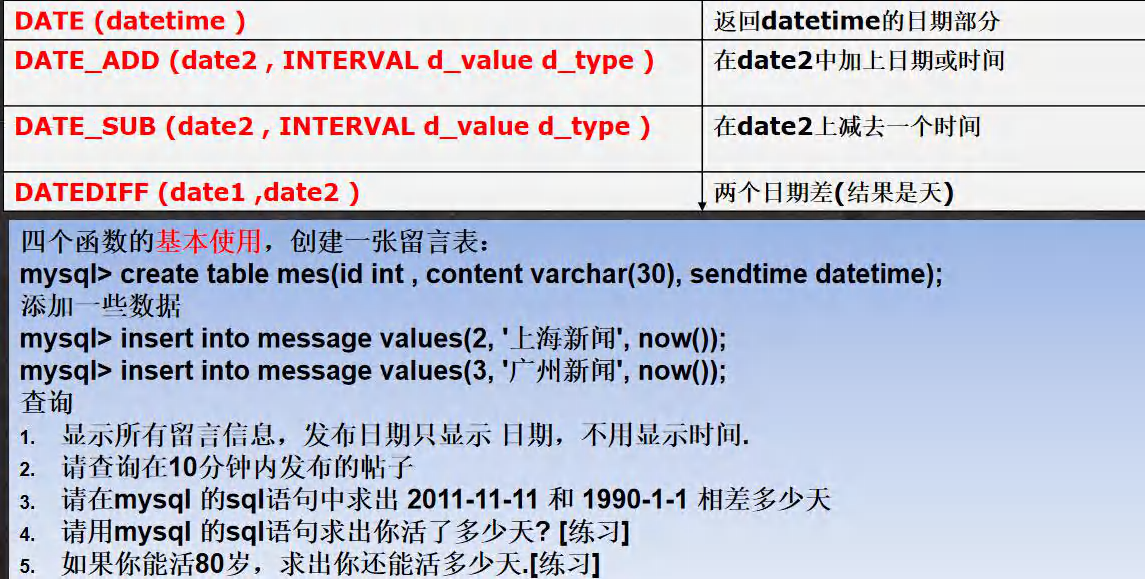
-- ��Ӧ��ʵ��
-- ��ʾ����������Ϣ,��������ֻ��ʾ ����,������ʾʱ��.
SELECT id,content,DATE(send_time) FROM mes;
-- ���ѯ��10�����ڷ���������, ˼·һ��Ҫ����һ��.
SELECT * FROM mes WHERE send_time>DATE_SUB(NOW(),INTERVAL 10 MINUTE);
SELECT * FROM mes WHERE DATE_ADD(send_time,INTERVAL 10 MINUTE)>NOW();
-- ����mysql ��sql�������� 2011-11-11 �� 1990-1-1 ��������
SELECT DATEDIFF('2011-11-11','1990-1-1') FROM DUAL;
-- ����mysql ��sql����������˶�����? [��ϰ] 1986-11-11 ����
SELECT DATEDIFF(CURRENT_DATE,'1998-07-29') FROM DUAL;
-- ������ܻ�80��,����㻹�ܻ������.[��ϰ] 1986-11-11 ����
-- �������80�� ʱ, ��ʲô���� X
-- Ȼ����ʹ�� datediff(x, now()); 1986-11-11->datetime
-- INTERVAL 80 YEAR : YEAR ������ ������,ʱ����
-- '1986-11-11' ����date,datetime timestamp
SELECT DATE_ADD('1998-07-29',INTERVAL 80 YEAR) FROM DUAL;
SELECT DATEDIFF('2078-07-29',NOW()) FROM DUAL;
SELECT DATEDIFF(DATE_ADD('1998-07-29',INTERVAL 80 YEAR),NOW()) FROM DUAL;
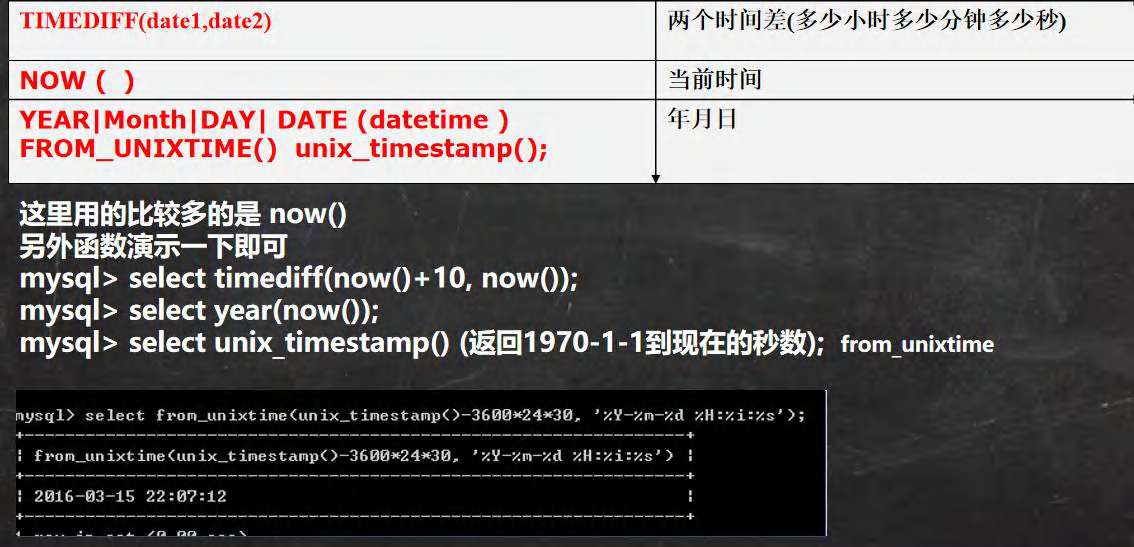
SELECT TIMEDIFF('10:11:11','04:10:10') FROM DUAL;
-- YEAR|Month|DAY| DATE (datetime )
SELECT YEAR(NOW()) FROM DUAL;
-- unix_timestamp() : ���ص���1970-1-1 �����ڵ�����
SELECT unix_timestamp() FROM DUAL;
-- FROM_UNIXTIME() : ����һ��unix_timestamp ����[ʱ���],ת��ָ����ʽ������
-- %Y-%m-%d ��ʽ�ǹ涨�õ�,��ʾ������
-- ����:�ڿ�����,���Դ��һ������,Ȼ���ʾʱ��,ͨ��FROM_UNIXTIMEת��
--
SELECT FROM_UNIXTIME(1644769696,'%Y-%m-%d') FROM DUAL;
SELECT FROM_UNIXTIME(1644769696,'%Y-%m-%d %H-%i-%s') FROM DUAL;
SELECT FROM_UNIXTIME(unix_timestamp()) FROM DUAL;
SELECT * FROM mysql.user \G
���ܺ�ϵͳ����
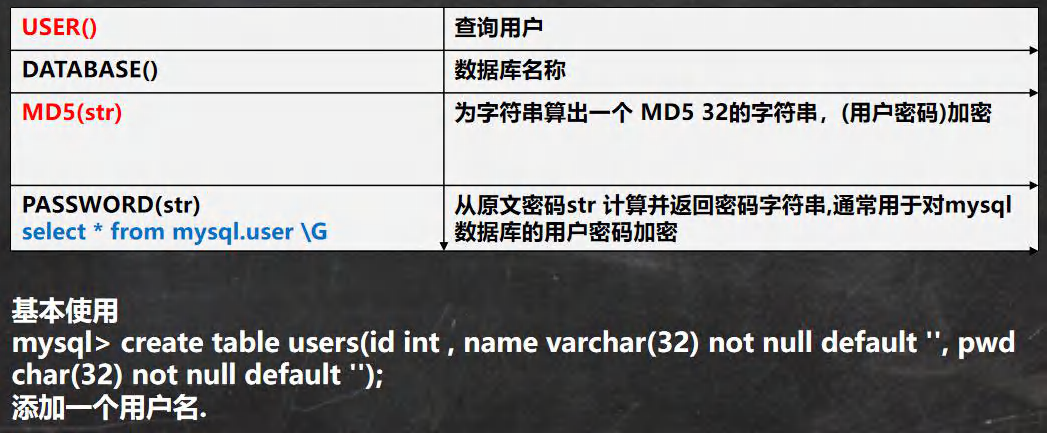
-- ��ʾ���ܺ�����ϵͳ����
-- USER() ��ѯ�û�
-- ���Բ鿴��¼��mysql������Щ�û�,�Լ���¼��IP
SELECT USER() FROM DUAL;-- root@localhost
-- DATABASE() ��ѯ��ǰʹ�����ݿ�����
SELECT DATABASE();
-- MD5(str) Ϊ�ַ������һ�� MD5 32���ַ���,����(�û�����)����
-- root ������ hsp -> ����md5 -> �����ݿ��д�ŵ��Ǽ��ܺ������
SELECT MD5('root') FROM DUAL;
SELECT LENGTH(MD5('root')) FROM DUAL;
-- ��ʾ�û���,�������ʱ,��md5
CREATE TABLE hsp_user
(id INT ,
`name` VARCHAR(32) NOT NULL DEFAULT '',
pwd CHAR(32) NOT NULL DEFAULT '');
INSERT INTO hsp_user
VALUES(100, '��˳ƽ', MD5('hsp'));
SELECT * FROM hsp_user; -- csdn
SELECT * FROM hsp_user -- SQLע������
WHERE `name`='��˳ƽ' AND pwd = MD5('hsp');
-- PASSWORD(str) -- ���ܺ���, MySQL���ݿ���û�������� PASSWORD��������
SELECT PASSWORD('root') FROM DUAL;-- ���ݿ�� *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B
-- select * from mysql.user \G ��ԭ������str ���㲢���������ַ���
-- ͨ�����ڶ�mysql���ݿ���û��������
-- mysql.user ��ʾ ���ݿ�.��
SELECT * FROM mysql.user;
���̿��ƺ���
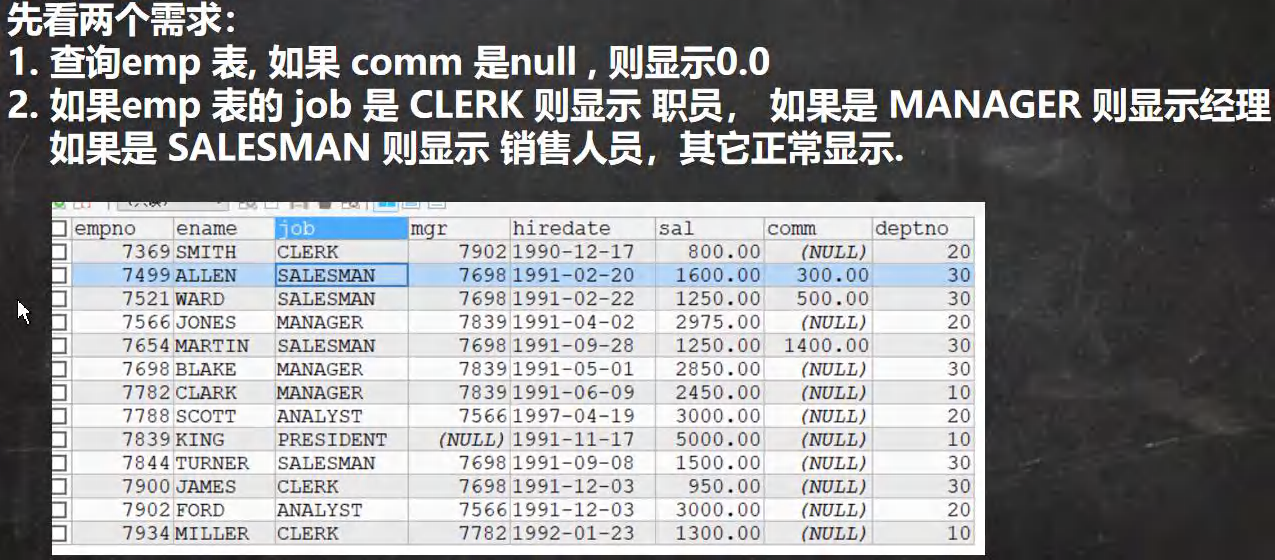
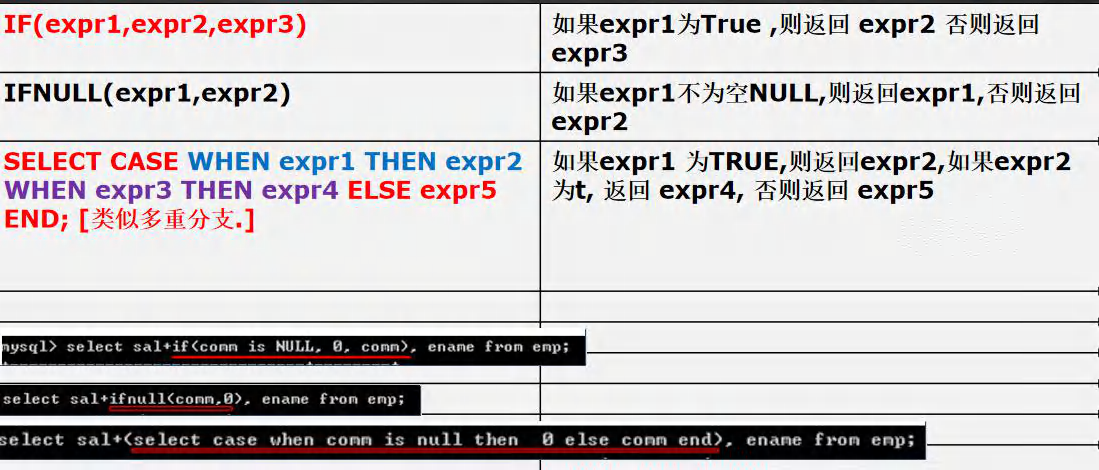
SELECT * FROM emp;
# ��ʾ���̿������
# IF(expr1,expr2,expr3) ���expr1ΪTrue ,�� expr2 ���� expr3
SELECT IF(TRUE, '����', '�Ϻ�') FROM DUAL;
# IFNULL(expr1,expr2) ���expr1����NULL,��expr1,����expr2
SELECT IFNULL( NULL, '��˳ƽ����') FROM DUAL;
# SELECT CASE WHEN expr1 THEN expr2 WHEN expr3 THEN expr4 ELSE expr5 END; [���ƶ��ط�֧.]
# ���expr1 ΪTRUE,��expr2,���expr2 Ϊt, ���� expr4, ���� expr5
#˭�ȶ����˭
SELECT CASE
WHEN TRUE THEN 'jack' -- jack
WHEN FALSE THEN 'tom'
ELSE 'mary' END
-- 1. ��ѯemp ��, ��� comm ��null , ����ʾ0.0
-- ��ʦ˵��,�ж��Ƿ�Ϊnull Ҫʹ�� is null, �жϲ�Ϊ�� ʹ�� is not
SELECT ename,job,IF(comm IS NULL,0.0,comm) FROM emp;
SELECT ename,job,IFNULL(comm,0.0) FROM emp;
SELECT ename,job,CASE
WHEN comm IS NULL THEN 0.0
ELSE comm END
FROM emp;
-- 2. ���emp ���� job �� CLERK ����ʾ ְԱ, ����� MANAGER ����ʾ����
-- ����� SALESMAN ����ʾ ������Ա,����������ʾ
SELECT ename,(SELECT CASE -- ����CASE��SELECT����ʡ��
WHEN job ='CLERK' THEN 'ְԱ'
WHEN job ='MANAGER' THEN '����'
WHEN job ='SALESMAN' THEN '������Ա'
ELSE job END)AS 'job'
FROM emp;
mysql����ѯ�C��ǿ
��ϰ:


-- ��ѯ��ǿ
-- �� ʹ��where�Ӿ�
-- ?��β���1992.1.1����ְ��Ա��
-- ��ʦ˵��: ��mysql��,�������Ϳ���ֱ�ӱȽ�, ��Ҫע���ʽ
DESC emp;
SELECT * FROM emp WHERE hiredate>'1992-01-01';
-- �� ���ʹ��like������(ģ��)
-- %: ��ʾ0����������ַ� _: ��ʾ���������ַ�
-- ?�����ʾ���ַ�ΪS��Ա����������
SELECT ename,sal FROM emp WHERE ename LIKE 's%';
-- ?�����ʾ�������ַ�Ϊ��дO������Ա������������
SELECT ename,sal FROM emp WHERE ename LIKE '__O%';
-- �� �����ʾû���ϼ��Ĺ�Ա�����
SELECT * FROM emp WHERE mgr IS NULL;
-- �� ��ѯ���ṹ
DESC emp;
-- ʹ��order by�Ӿ�
-- ?��ΰ��չ��ʵĴӵ͵��ߵ�˳��[����],��ʾ��Ա����Ϣ
SELECT * FROM emp ORDER BY sal;
-- ?���ղ��ź��������Ա�Ĺ��ʽ������� , ��ʾ��Ա��Ϣ
SELECT * FROM emp ORDER BY deptno ASC ,sal DESC;
SELECT * FROM emp GROUP BY deptno ,sal ;
��ҳ��ѯ
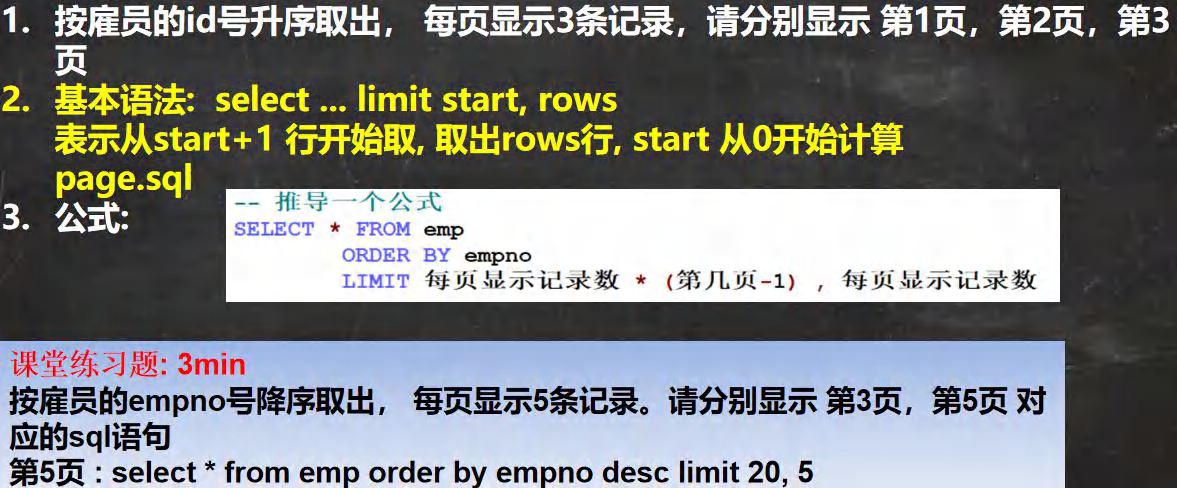
-- ��ҳ��ѯ
-- ����Ա��id������ȡ��, ÿҳ��ʾ3����¼,��ֱ���ʾ ��1ҳ,��2ҳ,��3ҳ
-- ��1ҳ
SELECT * FROM emp
ORDER BY empno
LIMIT 0, 3;
-- ��2ҳ
SELECT * FROM emp
ORDER BY empno
LIMIT 3, 3;
-- ��3ҳ
SELECT * FROM emp
ORDER BY empno
LIMIT 6, 3;
SELECT * FROM emp;
SELECT * FROM emp ORDER BY empno DESC LIMIT 10,5;
-- �Ƶ�һ����ʽ
SELECT * FROM emp
ORDER BY empno
LIMIT ÿҳ��ʾ��¼�� * (�ڼ�ҳ-1) , ÿҳ��ʾ��¼��
���麯���ͷ����Ӿ� group by
-- ��ǿgroup by ��ʹ��
SELECT * FROM emp;
-- (1) ��ʾÿ�ָ�λ�Ĺ�Ա������ƽ�����ʡ�
SELECT COUNT(*),AVG(sal) ,job FROM emp GROUP BY job;
-- (2) ��ʾ��Ա����,�Լ���ò����Ĺ�Ա����
-- ˼·: ��ò����Ĺ�Ա�� ���� comm ��Ϊ��null, ����count(��),������е�ֵΪnull, ��
-- ����ͳ�� , SQL �dz����,��Ҫ���Ƕ��Խ�.
SELECT COUNT(*),COUNT(comm) FROM emp;
-- ��ʦ����չҪ��:ͳ��û�л�ò����Ĺ�Ա��
SELECT COUNT(IF(comm IS NULL,1,NULL)) FROM emp;
SELECT COUNT(*)-COUNT(comm) FROM emp;
-- (3) ��ʾ�����ߵ���������С����:����д->��->����[��ȷ��]
SELECT COUNT(DISTINCT mgr) FROM emp;
-- (4) ��ʾ��Ա���ʵ�����
-- ˼·: max(sal) - min(sal)
SELECT MAX(sal)-MIN(sal) FROM emp;
-- Ӧ�ð���:��ͳ�Ƹ�������group by ��ƽ������ avg,
-- �����Ǵ���1000�� having,���Ұ���ƽ�����ʴӸߵ�������, order by
-- ȡ��ǰ���м�¼ limit 0, 2
SELECT AVG(sal) sal_avg FROM emp GROUP BY deptno HAVING sal_avg>1000 ORDER BY sal_avg DESC LIMIT 0,2;
���ݷ���ȵ��ܽ�
-
GROUP BY��ʹ��˳��:WHERE �Ƚ�����/������=0/1 GROUP BY �ֶ�1,�ֶ�2 HAVING �Ƚ�����/������
����ǰ����+����+��������
��ÿ���ֶ�1�е��ֶ�2��ѯ:GROUP BY �ֶ�1,�ֶ�2ע��:���ݷ������ȷ�˳��:WHERE+GROUP BY+HAVING+ORDER BY+LIMIT
-
ORDER BY������˳��ͬGROUP BY,���ֶ�1������������ֶ�2�����ѯ:ORDER BY �ֶ�1 ASC,�ֶ�2 DESC
-
GROUP BY ��ORDER BY�ķ�������:
�ӽ���Ͽ�:�������Ὣ ����� ͬ���Ҳ��ٷ� ���оۺ�Ϊһ��,
������ ����� �� -
����ʱ����:
-
'1991-01-02��ʡ����01��0�������ַ�����Ƚϻ����:
��1991-10-10��>��1991-2-10��=0��,���������ͱȽ�ӦΪ�� -
DATE�����ڿ��Ժ��ַ��������ڱȽ�
�����ѯ


SELECT * FROM dept;
SELECT * FROM salgrade;
SELECT * FROM emp;
-- �����ѯ
-- ?��ʾ��Ա��,��Ա���ʼ����ڲ��ŵ����� ���ѿ�������
/*
�Ϻ�����
1. ��Ա��,��Ա���� ���� emp��
2. ���ŵ����� ���� dept��
3. ����� emp �� dept��ѯ ename,sal,dname,deptno
4. ��������Ҫָ����ʾij����������,��Ҫ ��.����
*/
SELECT ename ,sal,dname,emp.deptno FROM emp , dept WHERE emp.deptno=dept.deptno;
-- �Ϻ�С����:�����ѯ�������������� ���ĸ���-1, �������ֵѿ�����
-- ?�����ʾ���ź�Ϊ10�IJ�������Ա��������
SELECT ename ,sal,dname,emp.deptno FROM emp , dept WHERE emp.deptno=dept.deptno AND emp.deptno=10;
-- ?��ʾ����Ա��������,����,���乤�ʵļ���
-- ˼· ����,���� ���� emp 13
-- ���ʼ��� salgrade 5
-- дsql , ��дһ����,Ȼ������������...
SELECT ename,sal,grade FROM emp,salgrade WHERE sal BETWEEN losal AND hisal;
������

-- �����ѯ�� ������
-- ˼����: ��ʾ��˾Ա�����ֺ������ϼ�������
-- �Ϻ�����: Ա������ ��emp, �ϼ������ֵ����� emp
-- Ա�����ϼ���ͨ�� emp���� mgr �й���
-- ������ʦС��:
-- �����ӵ��ص� 1. ��ͬһ�ű��������ű�ʹ��
-- 2. ��Ҫ����ȡ���� ���� ������
-- 3. ��������ȷ,����ָ���еı��� ���� as �еı���
SELECT * FROM emp;
SELECT emp.ename emp,boss.ename boss FROM emp,emp AS boss WHERE emp.mgr=boss.empno;
�Ӳ�ѯ(Ƕ�ײ�ѯ)
�����Ӳ�ѯ
�����Ӳ�ѯ��ָֻ����һ�����ݵ��Ӳ�ѯ���
�����Ӳ�ѯ(in)
�����Ӳ�ѯָ���ض������ݵ��Ӳ�ѯ ʹ�ùؼ��� in

-- �Ӳ�ѯ����ʾ
-- ��˼��:�����ʾ��SMITHͬһ���ŵ�����Ա��?
/*
1. �Ȳ�ѯ�� SMITH�IJ��źŵõ�
2. �������select ��䵱��һ���Ӳ�ѯ��ʹ��
*/
SELECT deptno FROM emp WHERE ename='SMITH';
SELECT *
FROM emp
WHERE deptno=(
SELECT deptno
FROM emp
WHERE ename='SMITH'
);
-- ������ϰ:��β�ѯ�Ͳ���10�Ĺ�����ͬ�Ĺ�Ա��
-- ���֡���λ�����ʡ����ź�, ���Dz���10�Ų����Լ��Ĺ�Ա.
/*
1. ��ѯ��10�Ų�������Щ����
2. �������ѯ�Ľ�������Ӳ�ѯʹ��
*/
SELECT DISTINCT job
FROM emp
WHERE deptno =10;
SELECT ename,job,sal,deptno
FROM emp
WHERE job in(
SELECT DISTINCT job
FROM emp
WHERE deptno =10
) AND deptno <>10;
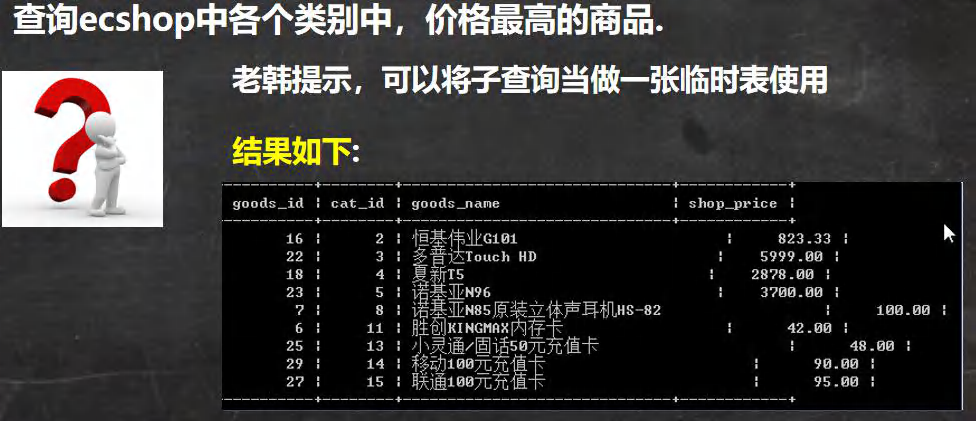
-- ��ѯecshop�и��������,�۸���ߵ���Ʒ
-- ��ѯ ��Ʒ��
-- �ȵõ� ���������,�۸���ߵ���Ʒ max + group by cat_id, ������ʱ��
-- ���Ӳ�ѯ����һ����ʱ�����Խ���ܶ�ܶิ�ӵIJ�ѯ
-- δ���˵ı�
SELECT goods_id,cat_id,goods_name,shop_price FROM ecs_goods;
-- ��ʱ��
SELECT cat_id,MAX(shop_price) AS hi_price
FROM ecs_goods
GROUP BY cat_id;
-- ��
SELECT goods_id,ecs_goods.cat_id,goods_name,shop_price
FROM(
SELECT cat_id,MAX(shop_price) AS hi_price
FROM ecs_goods
GROUP BY cat_id
) temp,ecs_goods
WHERE temp.cat_id=ecs_goods.cat_id
AND hi_price=shop_price;
all&any

-- all �� any��ʹ��
-- ��˼��:��ʾ���ʱȲ���30������Ա���Ĺ��ʸߵ�Ա�������������ʺͲ��ź�
SELECT ename,sal,deptno
FROM emp
WHERE sal>ALL(
SELECT sal FROM emp WHERE deptno=30
);
-- method
SELECT ename,sal,deptno
FROM emp
WHERE sal>(
SELECT MAX(sal) FROM emp WHERE deptno=30
);
-- ��˼��:�����ʾ���ʱȲ���30������һ��Ա���Ĺ��ʸߵ�Ա�������������ʺͲ��ź�
SELECT ename,sal,deptno
FROM emp
WHERE sal>ANY(
SELECT sal FROM emp WHERE deptno=30
);
-- method
SELECT ename,sal,deptno
FROM emp
WHERE sal>(
SELECT MIN(sal) FROM emp WHERE deptno=30
);
�����Ӳ�ѯ

-- �����Ӳ�ѯ
-- ��ѯ��Allan�IJ��ź�λ��ȫ��ͬ�����й�Ա(��������)
SELECT * FROM emp;
SELECT deptno ,job FROM emp WHERE ename='ALLEN';
-- ����: 2 ������IJ�ѯ�����Ӳ�ѯ��ʹ��,����ʹ�ö����Ӳ�ѯ�������ƥ��
SELECT *
FROM emp
WHERE (deptno,job) =(
SELECT deptno ,job
FROM emp
WHERE ename='ALLEN'
)AND ename <>'ALLEN';
-- ���ѯ ���ν���ѧ,Ӣ��,����
-- �ɼ� ��ȫ��ͬ��ѧ��
SELECT * FROM student;
SELECT chinese,math,english FROM student WHERE `name` ='�ν�';
SELECT *
FROM student
WHERE (chinese,math,english)=(
SELECT chinese,math,english
FROM student
WHERE `name` ='�ν�'
)AND `name` <>'�ν�';
from �Ӿ���ʹ���Ӳ�ѯ

-- �Ӳ�ѯ��ϰ
-- ��ѯÿ�����Ź��ʸ��ڱ�����ƽ�����ʵ���
-- �Ӳ�ѯ
SELECT deptno,AVG(sal) FROM emp GROUP BY deptno;
-- �����ѯ
SELECT ename,sal,sal_avg,emp.deptno
FROM emp,(
SELECT deptno,AVG(sal) AS sal_avg
FROM emp
GROUP BY deptno
) temp
WHERE emp.deptno=temp.deptno
AND sal>sal_avg;
-- ��ѯÿ�����Ź�������˵���ϸ��Ϣ
-- �Ӳ�ѯ:������߹���
SELECT deptno,MAX(sal) FROM emp GROUP BY deptno;
-- 1)�����Ӳ�ѯ
SELECT * FROM emp WHERE (deptno,sal) IN (SELECT deptno,MAX(sal) FROM emp GROUP BY deptno);
-- 2)�����ѯ
SELECT ename,sal,sal_max,emp.deptno
FROM emp,(
SELECT deptno,MAX(sal) AS sal_max
FROM emp
GROUP BY deptno
) temp
WHERE emp.deptno=temp.deptno
AND sal=sal_max;
-- ��ÿ�����ŵ���Ϣ:������,���,��ַ,����
SELECT * FROM dept;
-- �Ӳ�ѯ
SELECT deptno,COUNT(*) FROM emp GROUP BY deptno;
-- �����ѯ
SELECT dept.*,`count`-- dname,dept.deptno,loc,`count`
FROM dept,(
SELECT deptno,COUNT(*) `count`
FROM emp
GROUP BY deptno
) temp
WHERE dept.deptno=temp.deptno;
������
���Ҹ�������(��渴��)


-- ���ĸ���
-- Ϊ�˶�ij��sql������Ч�ʲ���,������Ҫ��������ʱ,����ʹ�ô˷�Ϊ��������������
-- ������
CREATE TABLE mytab_01
(id INT ,
`name` VARCHAR(32),
sal DOUBLE ,
job VARCHAR(32),
deptno INT );
DESC mytab_01;
SELECT * FROM mytab_01;
-- ��emp�������ֶ�ֵ
SELECT * FROM emp;
INSERT INTO mytab_01
(id,`name`,sal,job,deptno)
SELECT empno,ename,sal,job,deptno FROM emp;
-- ���Ҹ���
INSERT INTO mytab_01
SELECT * FROM mytab_01;
SELECT COUNT(*) FROM mytab_01;
-- ɾ���ظ���¼5step
-- 1��¼���ظ����Ӳ�ѯ
SELECT DISTINCT * FROM mytab_01;
-- 2���Ʋ��ظ���¼���±�()
CREATE TABLE tmp like mytab_01;-- ���Ʊ��ṹ���±�
SELECT * FROM tmp;
INSERT INTO tmp
SELECT DISTINCT * FROM mytab_01;
-- 3ɾ������
DELETE FROM mytab_01;
-- 4���Ʋ��ظ���¼���ɱ�
INSERT INTO mytab_01
SELECT * FROM tmp;
-- 5ɾ����ʱ��
DROP TABLE tmp;
�ϲ���ѯ


-- �ϲ���ѯ
SELECT ename,sal,job FROM emp WHERE sal>2500; -- 5
SELECT ename,sal,job FROM emp WHERE job='MANAGER' -- 3
-- union all ���ǽ�������ѯ����ϲ�,����ȥ��
SELECT ename,sal,job FROM emp WHERE sal>2500 -- 5
UNION ALL
SELECT ename,sal,job FROM emp WHERE job='MANAGER' -- 3
-- union ���ǽ�������ѯ����ϲ�,��ȥ��
SELECT ename,sal,job FROM emp WHERE sal>2500 -- 5
UNION
SELECT ename,sal,job FROM emp WHERE job='MANAGER' -- 3
������


SELECT * FROM dept;
-- ������
-- ����:�г��������ƺ���Щ���ŵ�Ա�����ƺ���,
-- ͬʱҪ�� ��ʾ����Щû��Ա���IJ��š�
SELECT dname,ename,job,dept.deptno
FROM emp , dept
WHERE emp.deptno=dept.deptno
ORDER BY deptno;
-- �г��������ƺ���Щ���ŵ�Ա����Ϣ(���ֺ���),
-- ͬʱ�г���Щû��Ա���IJ�������5min
-- ʹ����������ʵ��
SELECT dname,ename,job,dept.deptno
FROM emp RIGHT JOIN dept
ON emp.deptno=dept.deptno
ORDER BY deptno;
-- ��������
SELECT dname,ename,job,dept.deptno
FROM dept LEFT JOIN emp
ON emp.deptno=dept.deptno
ORDER BY deptno;
Լ��

����


-- ����ʹ��
-- id name email
CREATE TABLE t17
(id INT PRIMARY KEY, -- ��ʾid��������
`name` VARCHAR(32),
email VARCHAR(32));
-- �����е�ֵ�Dz������ظ�
INSERT INTO t17
VALUES(1,'jack','jack@sohu.com');
INSERT INTO t17
VALUES(2,'mary','mary@sohu.com');
INSERT INTO t17
VALUES(1,'zxk','zxk@sohu.com');
SELECT * FROM t17;
-- ����ʹ�õ�ϸ������
-- primary key�����ظ����Ҳ���Ϊ null��
INSERT INTO t17
VALUES(NULL, 'hsp', 'hsp@sohu.com');
-- һ�ű����ֻ����һ������, �������Ǹ�������(���� id+name)
CREATE TABLE t18
(id INT PRIMARY KEY, -- ��ʾid��������
`name` VARCHAR(32), PRIMARY KEY -- �����
email VARCHAR(32));
-- ��ʾ�������� (id �� name ���ɸ�������)
CREATE TABLE t18
(id INT ,
`name` VARCHAR(32),
email VARCHAR(32),
PRIMARY KEY(id,`name`) -- ������Ǹ�������
);
INSERT INTO t18
VALUES(1, 'tom', 'tom@sohu.com');
INSERT INTO t18
VALUES(1, 'jack', 'jack@sohu.com');
INSERT INTO t18
VALUES(1, 'tom', 'xx@sohu.com'); -- �����Υ���˸�������
SELECT * FROM t18;
-- ������ָ����ʽ ������
-- 1. ֱ�����ֶ�����ָ��:�ֶ��� primakry key
-- 2. �ڱ��������д primary key(����);
CREATE TABLE t19
(id INT ,
`name` VARCHAR(32) PRIMARY KEY,
email VARCHAR(32)
);
CREATE TABLE t20
(id INT,
`name` VARCHAR(32),
email VARCHAR(32),
PRIMARY KEY(`name`)
);
-- ʹ��desc ����,���Կ���primary key�����
DESC t20 -- �鿴 t20���Ľ��,��ʾԼ�������
DESC t18-- ��������
�ǿ�

Ψһ


-- unique��ʹ��
CREATE TABLE t21
(id INT UNIQUE,
`name` VARCHAR(32),
emain VARCHAR(32)
);
INSERT INTO t21
VALUES(1,'jack','jack@sohu.com');
INSERT INTO t21 -- id ���ظ�
VALUES(1,'mary','mary@sohu.com');
-- ʹ��ϸ��
-- 1. ���û��ָ�� not null , �� unique �ֶο����ж��null
-- ���һ����(�ֶ�), �� unique not null ʹ��Ч������ primary key
INSERT INTO t21
VALUES(NULL,'hsp','hsp@sohu.com');
SELECT * FROM t21;
-- 2. һ�ű������ж��unique�ֶ�
CREATE TABLE t22
(id INT UNIQUE NOT NULL,
`name` VARCHAR(32) UNIQUE,
email VARCHAR(32)
);
DESC t22;-- idԼ��Ϊ����
���



-- ��������
CREATE TABLE my_class
(id INT UNIQUE,-- �༶���
nam VARCHAR(32) NOT NULL DEFAULT ''
);
INSERT INTO my_class
VALUES(100,'java'),(200,'web');
DESC my_class;
SELECT * FROM my_class;
-- �����ӱ�
CREATE TABLE my_stu
(id INT ,-- ѧ�����
`name` VARCHAR(32),
class_id INT,-- ѧ�����ڰ༶�ı��
FOREIGN KEY (class_id) REFERENCES my_class(id));-- �������Լ��
INSERT INTO my_stu
VALUES(1,'tom',100);
INSERT INTO my_stu
VALUES(2,'jack',200);
INSERT INTO my_stu
VALUES(1,'tom',100);
INSERT INTO my_stu
VALUES(4,'mary',300);-- �����ʧ��...��Ϊ300�༶������
INSERT INTO my_stu
VALUES(5,'zxk',NULL);-- ͬuniqueԭ��:NULL��ȷ��,���������ֶ�ֵ�����Ƕ��NULL
SELECT * FROM my_stu;
-- ɾ��:һ�������������ϵ,�����ļ�¼�Ͳ�������ɾ��
-- ����û�дӱ��ļ�¼ʹ�ø�����ֶ�:��Ҫ��ɾ���ӱ���ʹ�ø�����ļ�¼������ɾ�������ĸ�����ļ�¼
DELETE FROM my_class WHERE id=100;-- wrong
check

-- ��ʾcheck��ʹ��
-- mysql5.7Ŀǰ����֧��check ,ֻ���У��,��������Ч
-- �˽�
-- ѧϰ oracle, sql server, ���������ݿ��������Ч.
-- ����
CREATE TABLE t23(
id INT PRIMARY KEY,
`name` VARCHAR(32),
sex CHAR(6) CHECK (sex IN('man','woman')),
sal DOUBLE CHECK (sal>1000 AND sal<2000)
);
-- ��������
INSERT INTO t23
VALUES(1,'hsp','mid',1);
SELECT * FROM t23;
��ϰ

-- ��Ʒ��Ϣ
CREATE TABLE goods
(goods_id INT PRIMARY KEY,
goods_name VARCHAR(64) NOT NULL DEFAULT '',
unitprice DECIMAL(10,2) NOT NULL DEFAULT 0 CHECK (unitprice>=1.0 AND unitprice<=9999.99),
category INT NOT NULL DEFAULT 0,
provider VARCHAR(64) NOT NULL DEFAULT ''
);
-- �ͻ���Ϣ
CREATE TABLE customer
(customer_id CHAR(8) PRIMARY KEY,
`name` VARCHAR(10) NOT NULL DEFAULT '',
address VARCHAR(64) NOT NULL DEFAULT '',
email VARCHAR(64) UNIQUE NOT NULL DEFAULT '',
sex ENUM('��','Ů') NOT NULL,
card_Id CHAR(18)
);
-- ������Ϣ
CREATE TABLE purchase
(order_id INT UNSIGNED PRIMARY KEY,
customer_id CHAR(8) NOT NULL DEFAULT '',-- ���Լ��
goods_id INT NOT NULL DEFAULT 0,-- ���Լ��
nums INT NOT NULL DEFAULT 0,
FOREIGN KEY (customer_id) REFERENCES customer(customer_id),
FOREIGN KEY (goods_id) REFERENCES goods(goods_id)
);
������


-- ������
CREATE TABLE t24
(id INT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(32) NOT NULL DEFAULT '',
`name` VARCHAR(32) NOT NULL DEFAULT ''
);
DESC t24;
INSERT INTO t24(id,email,`name`)
VALUES(NULL,'hsp.com','hsp');
INSERT INTO t24(email,`name`)
VALUES('sohu.com','sohu');
INSERT INTO t24
VALUES(NULL,'zxk.com','zxk');
SELECT * FROM t24;
-- ��Ĭ�ϵ���������ʼֵ1
INSERT INTO t24
VALUES(666,'zxk.com','zxk');
INSERT INTO t24(email,`name`)
VALUES('sohu.com','sohu');
-- ��Ĭ�ϵ���������ʼֵ2
CREATE TABLE t25
(id INT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(32) NOT NULL DEFAULT '',
`name` VARCHAR(32) NOT NULL DEFAULT ''
);
ALTER TABLE t25 AUTO_INCREMENT=100;
INSERT INTO t25(id,email,`name`)
VALUES(NULL,'hsp.com','hsp');
SELECT * FROM t25;
����
����

CREATE TABLE dept( /*���ű�*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ;
#������EMP��Ա
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*���*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*����*/
job VARCHAR(9) NOT NULL DEFAULT "",/*����*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*�ϼ����*/
hiredate DATE NOT NULL,/*��ְʱ��*/
sal DECIMAL(7,2) NOT NULL,/*нˮ*/
comm DECIMAL(7,2) NOT NULL,/*����*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*���ű��*/
) ;
#���ʼ����
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);
#��������
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
delimiter $$
#����һ������,���� rand_string,�������������ָ���ĸ����ַ���
create function rand_string(n INT)
returns varchar(255) #�ú����᷵��һ���ַ���
begin
#������һ������ chars_str, ���� varchar(100)
#Ĭ�ϸ� chars_str ��ʼֵ 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
# concat ���� : ���Ӻ���mysql����
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
#�����������Զ���һ������,����һ������IJ��ź�
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
#����һ���洢����, �������ӹ�Ա
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 ��autocommit���ó�0
#autocommit = 0 ����: ��Ҫ�Զ��ύ
set autocommit = 0; #Ĭ�ϲ��ύsql���
repeat
set i = i + 1;
#ͨ��ǰ��д�ĺ�����������ַ����Ͳ��ű��,Ȼ����뵽emp��
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
#commit�����ύ����sql���,���Ч��
commit;
end $$
#����8000000����
call insert_emp(100001,8000000)$$
#���������,����������Ϊ;
delimiter ;
SELECT COUNT(*) FROM emp;
SELECT * FROM emp WHERE empno=1234567;
-- ʹ���������Ż�һ��, ����������ţ
-- ��û�д�������ǰ , emp.ibd �ļ���С �� 524m
-- ���������� emp.ibd �ļ���С �� 655m [��������Ҳ��ռ�ÿռ�.]
-- ����ename������,emp.ibd �ļ���С �� 827m
-- empno_index ��������
-- ON emp (empno) : ��ʾ�� emp���� empno�д�������
CREATE INDEX empno_index ON emp(empno);
-- ����������,ֻ�Դ���������������Ч
SELECT * FROM emp WHERE ename='PjDlwy';
CREATE INDEX ename_index ON emp(ename);
ԭ��

����
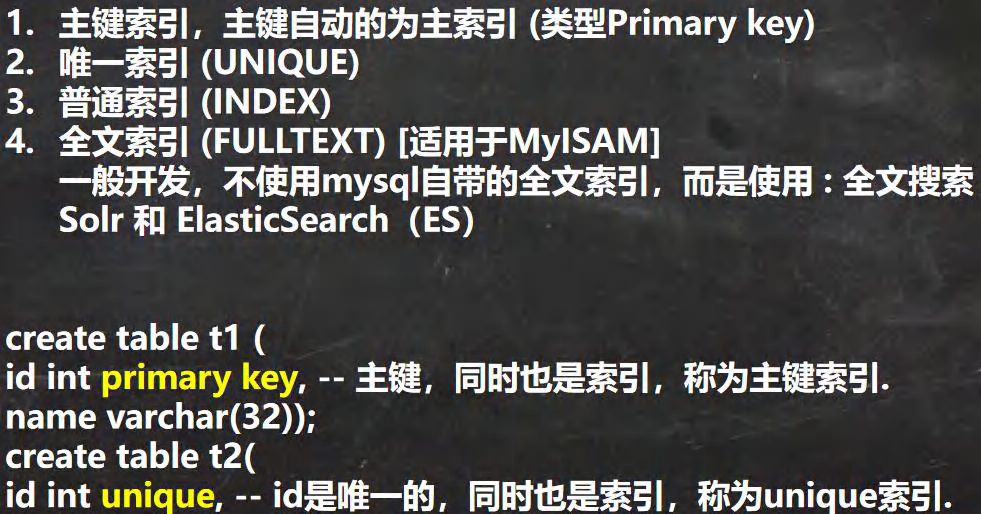
ʹ��


-- ��ʾmysql��������ʹ��
-- ��������
CREATE TABLE t25
(id INT,
ic INT,
`name` VARCHAR(32));
DESC t25;
SHOW INDEXES FROM t25;
-- ����Ψһ����
CREATE UNIQUE INDEX ic_index ON t25(ic);
--
ALTER TABLE t25
ADD UNIQUE INDEX (ic);
-- ������ͨ����
CREATE INDEX name_index ON t25(`name`);
--
ALTER TABLE t25
ADD INDEX (`name`);
-- ������������
ALTER TABLE t25
ADD PRIMARY KEY (id);
-- ɾ������
DROP INDEX ic_index ON t25;
ALTER TABLE t25 DROP INDEX name_index;
ALTER TABLE t25 DROP PRIMARY KEY;
-- ��ѯ����
SHOW INDEX FROM t25;
SHOW INDEXES FROM t25;
SHOW KEY FROM t25;
DESC t25;
ʹ��С��

����
����

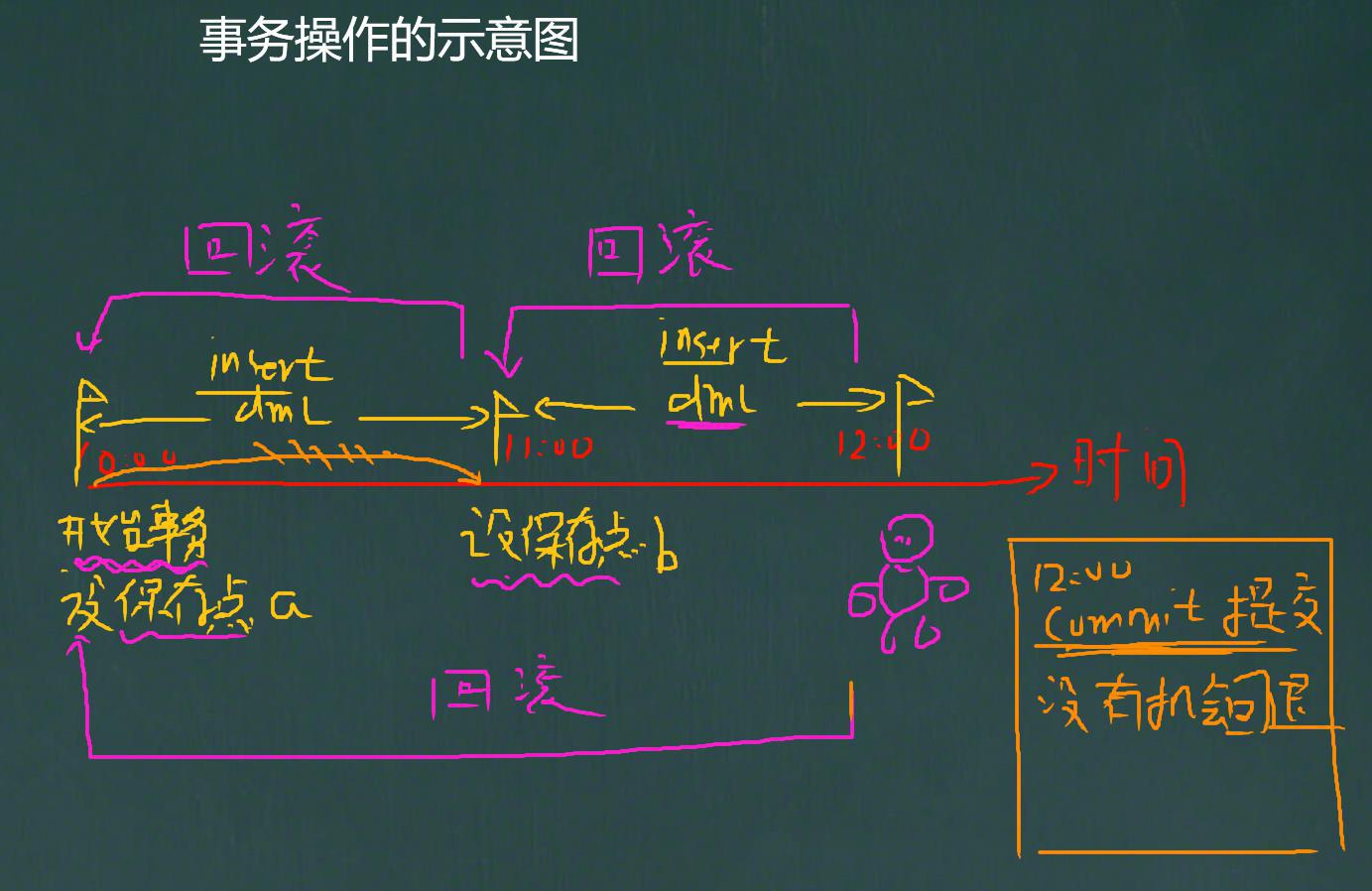

-- ����ļ�����Ҫ����;������
-- �������Ա�
CREATE TABLE t27
(id INT ,
`name` VARCHAR(32));
-- ��ʼ����
START TRANSACTION;
-- 3. �����
SAVEPOINT a;
-- ִ��dml ����
INSERT INTO t27
VALUES(100,'jack');
-- 3. �����
SAVEPOINT b;
-- ִ��dml ����
INSERT INTO t27
VALUES(200,'mary');
SELECT * FROM t27;
-- ���˵� b
ROLLBACK TO b;
-- �������� a
ROLLBACK TO a;
-- �������, ��ʾֱ�ӻ��˵�����ʼ��״̬.
ROLLBACK;
-- �ύ
COMMIT;
��������

�ύ����

ϸ��

-- ���� ����ϸ��
-- 1. �������ʼ����,Ĭ�������,dml�������Զ��ύ��,���ܻع�
SELECT * FROM t27;
INSERT INTO t27
VALUES(300,'zxk');
-- 2. �����ʼһ������,��û�д��������. �����ִ�� rollback,
-- Ĭ�Ͼ��ǻ��˵�������ʼ��״̬
START TRANSACTION;
INSERT INTO t27
VALUES(400,'smith'),(500,'hsp');
ROLLBACK;-- ��ʾֱ�ӻ��˵�����ʼ�ĵ�״̬
COMMIT;
-- 3. ��Ҳ���������������(��û���ύʱ), ������������.����: savepoint aaa;
-- ִ�� dml , savepoint bbb
-- 4. �����������û���ύǰ,ѡ����˵��ĸ������
-- 5. InnoDB �洢����֧������ , MyISAM ��֧��
-- 6. ��ʼһ������ start transaction, set autocommit=off;
������뼶��


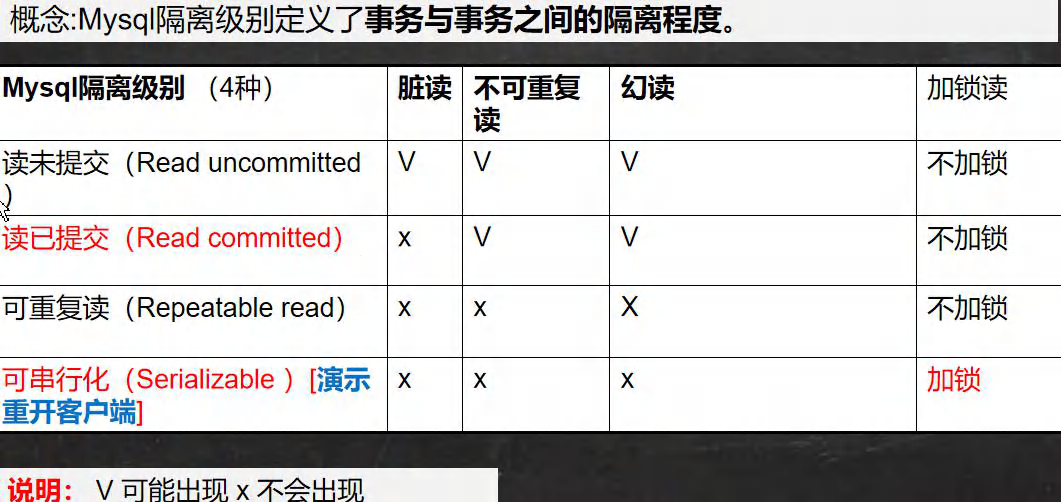
����:
����������뼶��


-- ��ʾmysql��������뼶��
-- 1. ��������mysql�Ŀ���̨
-- 2. �鿴��ǰmysql�ĸ��뼶��
SELECT @@tx_isolation;
-- mysql> SELECT @@tx_isolation;
-- +-----------------+
-- | @@tx_isolation |
-- +-----------------+
-- | REPEATABLE-READ |
-- +-----------------+
-- 3.������һ������̨�ĸ��뼶������ Read uncommitted
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
-- 4. ������
CREATE TABLE `account`(
id INT,
`name` VARCHAR(32),
money INT);
-- �鿴��ǰ�Ự���뼶��
SELECT @@tx_isolation
-- �鿴ϵͳ��ǰ���뼶��
SELECT @@global.tx_isolation
-- ���õ�ǰ�Ự���뼶��
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
-- ����ϵͳ��ǰ���뼶��
SET GLOBAL TRANSACTION ISOLATION LEVEL [�����õļ���]
-- mysqlĬ�ϵ�������뼶���ǿ��ظ���repeatable read
-- ��Ĭ�ϸ��뼶��:mysqlĿ¼��my.ini�������
transaction-isolation=READ-UNCOMMITTED
-- ������dos:net stop mysql->net start mysql
���� ACID
����� acid ����

�����ͺʹ洢����
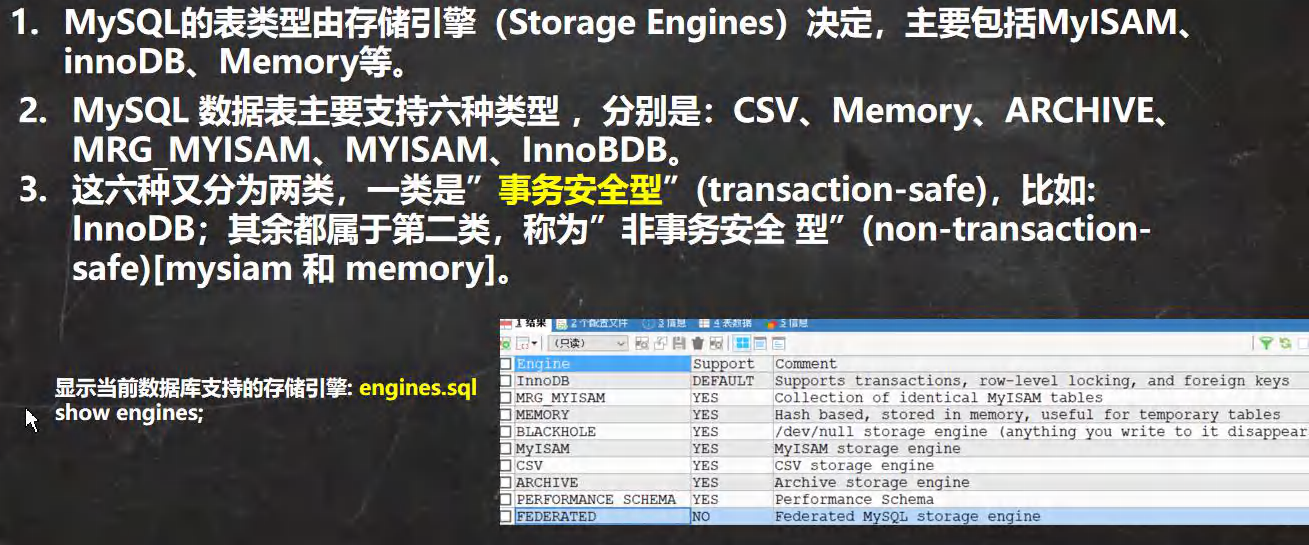
��Ҫ�Ĵ洢����/�������ص�
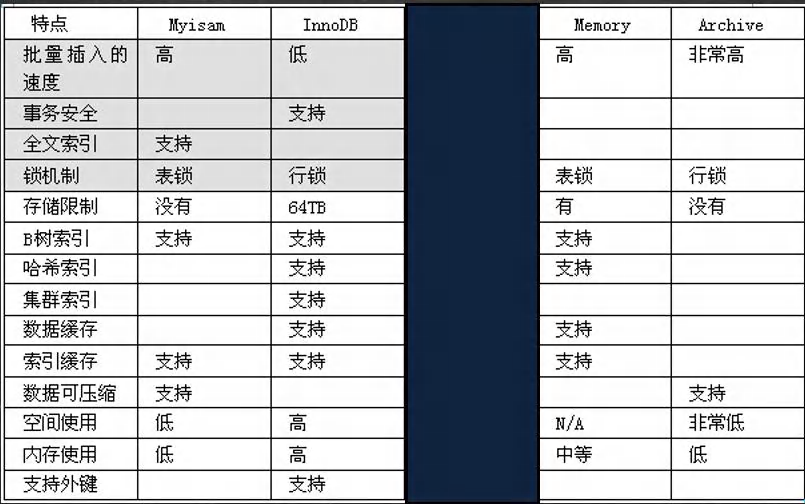
ϸ��˵��

ʹ�ð���
-- �����ͺʹ洢����
-- �鿴���еĴ洢����
SHOW ENGINES;
-- innodb �洢����,��ǰ��ʹ�ù�.
-- 1. ֧������ 2. ֧����� 3. ֧���м���
-- myisam �洢����
CREATE TABLE t28
(id INT,
`name` VARCHAR(32)) ENGINE MYISAM;
-- 1. �����ٶȿ� 2. ��֧����������� 3. ֧�ֱ�����
START TRANSACTION;
SAVEPOINT a;
INSERT INTO t28 VALUES(1,'jack');
SELECT * FROM t28;
ROLLBACK TO a;
-- memory �洢����
-- 1. ���ݴ洢���ڴ���[�ر���Mysql����,���ݶ�ʧ, ���DZ��ṹ����]
-- 2. ִ���ٶȺܿ�(û��IO��д) 3. Ĭ��֧������(hash��)
CREATE TABLE t29
(id INT,
`name` VARCHAR(32)) ENGINE MEMORY;
DESC t29;
INSERT INTO t29 VALUES(1,'tom'),(2,'mary'),(3,'scott');
SELECT * FROM t29;
-- �Ĵ洢����
ALTER TABLE t29 ENGINE=INNODB;
���ѡ��

�Ĵ洢����

��ͼ

����


����ʹ��

����
-- ��ͼ��ʹ��
-- ����һ����ͼemp_view01,ֻ�ܲ�ѯemp����(empno��ename, job �� deptno ) ��Ϣ
-- ������ͼ
CREATE VIEW emp_view01
AS
SELECT empno,ename,job,deptno FROM emp;
-- �鿴��ͼ
DESC emp_view01;
SELECT * FROM emp_view01;
SELECT empno,job FROM emp_view01;
-- �鿴������ͼ��ָ��
SHOW CREATE VIEW emp_view01;
-- ɾ����ͼ
DROP VIEW emp_view01;
-- ��ͼ��ϸ��
-- 1. ������ͼ��,�����ݿ�ȥ��,��Ӧ��ͼֻ��һ����ͼ�ṹ�ļ�(��ʽ: ��ͼ��.frm) û�������ļ�.ibd
-- 2. ��ͼ�����ݱ仯��Ӱ�쵽����,���������ݱ仯Ҳ��Ӱ�쵽��ͼ[insert update delete ]
-- ����ͼ ��Ӱ�쵽����
UPDATE emp_view01 SET job='MANAGER' WHERE empno=7369;
SELECT * FROM emp; -- ��ѯ����
SELECT * FROM emp_view01;
-- �Ļ�����, ��Ӱ�쵽��ͼ
UPDATE emp SET job='SALESMAN' WHERE empno=7369;
-- 3. ��ͼ�п�����ʹ����ͼ , �����emp_view01 ��ͼ��,ѡ��empno,��ename��������ͼ
DESC emp_view01;
CREATE VIEW emp_view02
AS
SELECT empno,ename FROM emp_view01;
SELECT * FROM emp_view02;
��ͼϸ������

��ͼ���ʵ��

��ϰ

-- ��ͼ�Ŀ�����ϰ
-- ��� emp ,dept , �� salgrade ������.����һ����ͼ emp_view03,
-- ������ʾ��Ա���,��Ա��,��Ա�������ƺ� нˮ����[��ʹ�����ű�,����һ����ͼ]
/*
����: ʹ���������ϲ�ѯ,�õ����
���õ��Ľ��,��������ͼ
*/
-- �������ű�
SELECT * FROM emp,dept,salgrade;
-- ������������ͼ
CREATE VIEW emp_view03
AS
SELECT empno,ename,dname,grade
FROM emp,dept,salgrade
WHERE emp.deptno=dept.deptno
AND (sal BETWEEN losal AND hisal);
DROP VIEW emp_view03;
DESC emp_view03;
SELECT * FROM emp_view03;
����
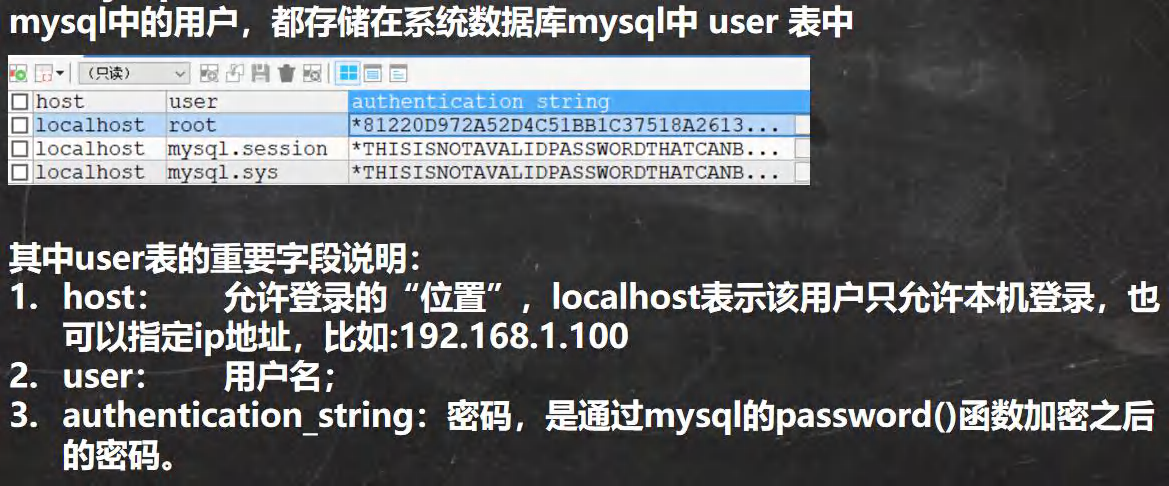
�����û�

ɾ���û�

�û�������

Ȩ��
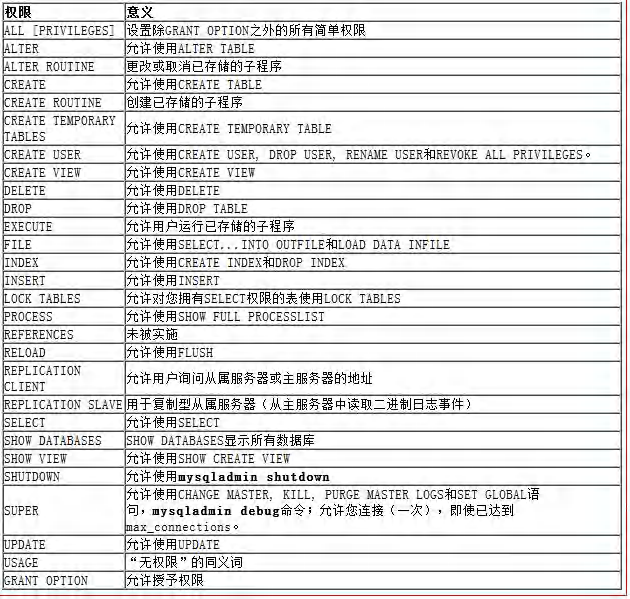
���û���Ȩ

�����û���Ȩ

Ȩ����Чָ��

��ϰ

SELECT * FROM `user`;
SELECT PASSWORD('123456') FROM DUAL;
*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9
-- ��ʾ �û�Ȩ�Ĺ���
-- �����û� shunping ���� 123 , �ӱ��ص�¼
CREATE USER 'zxk'@'localhost' IDENTIFIED BY '123';
-- ʹ��root �û����� testdb ,�� news
CREATE DATABASE testdb;
CREATE TABLE news
(id INT,
content VARCHAR(32));
INSERT INTO news VALUES(100,'��������');
-- �� shunping ����鿴 news ���� ����news��Ȩ��
GRANT SELECT,INSERT ON testdb.news TO 'zxk'@'localhost' ;
-- ��������updateȨ��
GRANT UPDATE ON testdb.news TO 'zxk'@'localhost' ;
-- �� shunping������Ϊ abc
SET PASSWORD FOR 'zxk'@'localhost'=PASSWORD('abc');
-- ���� shunping �û��� testdb.news ��������Ȩ��
REVOKE SELECT,INSERT,UPDATE ON testdb.news FROM 'zxk'@'localhost';
REVOKE ALL ON testdb.news FROM 'zxk'@'localhost';
-- ɾ�� shunping
DROP USER 'zxk'@'localhost';
ϸ��˵��
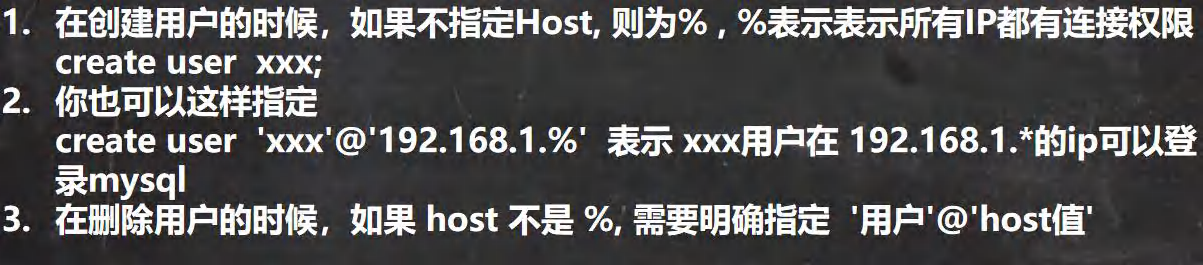
-- ˵�� �û�������ϸ��
-- �ڴ����û���ʱ��,�����ָ��Host, ��Ϊ% , %��ʾ��ʾ����IP��������Ȩ��
-- create user xxx;
CREATE USER jack;
SELECT * FROM `user`;
SELECT `host`,`user` FROM mysql.user;
-- ��Ҳ��������ָ��
-- create user 'xxx'@'192.168.1.%' ��ʾ xxx�û��� 192.168.1.*��ip���Ե�¼mysql
CREATE USER 'mary'@'192.168.1.%';
-- ��ɾ���û���ʱ��,��� host ���� %, ��Ҫ��ȷָ�� '�û�'@'hostֵ'
DROP USER jack;-- Ĭ�Ͼ��� DROP USER 'jack'@'%'
DROP USER 'mary'@'192.168.1.%';