ЮФеТФПТМ
01 в§бд
дкЧАУцЕФНЬГЬ,вбОАбHiveЛЗОГДюНЈЦ№РДСЫ,гааЫШЄЕФЭЌбЇПЩвдВЮдФ:
МШШЛгаСЫhiveЕФЛЗОГ,ДЫЪБДѓМвПЯЖЈЪЎЗжЦШЧаЕФЯыАбhiveгУЦ№РД,ЕЋЪЧгУжЎЧА,ЮвУЧЪЧКмгаБивЊСЫНтhiveЕФМИжжЪ§ОнФЃаЭЕФ,вВОЭЪЧашвЊжЊЕРhiveАбЪ§ОнзюжеДцдкСЫhdfsЕФФФРя?
02 hiveЪ§ОнФЃаЭ
hiveЪ§ОнФЃаЭЙиЯЕЭМШчЯТ:
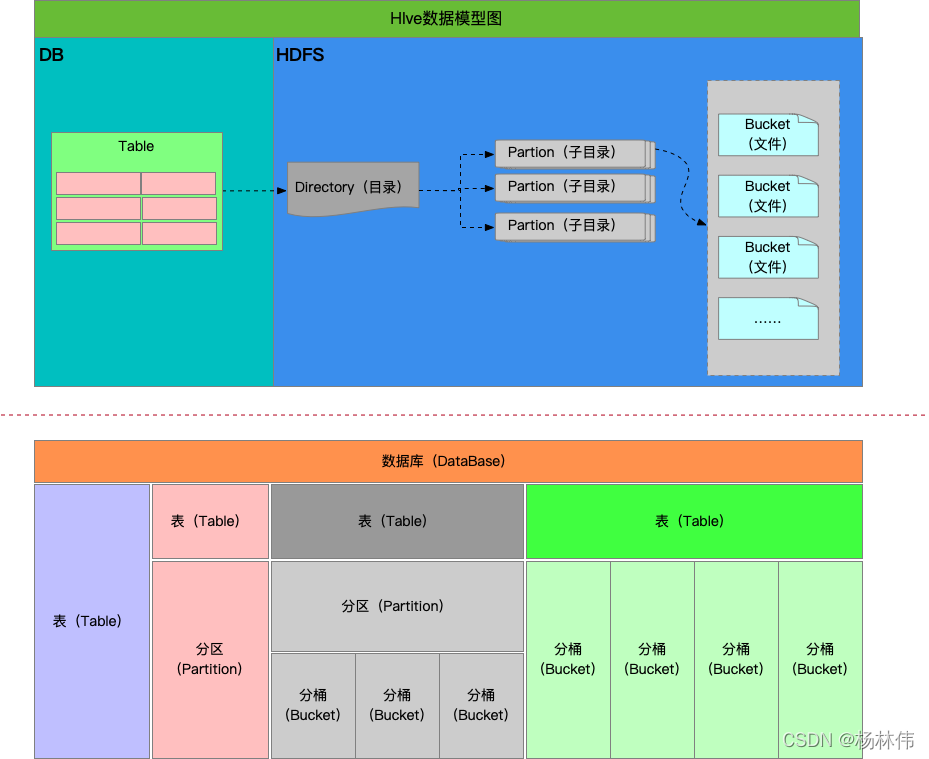
ДгЩЯЭМ,ПЩвдПДЕН hive жївЊгаМИжжЪ§ОнФЃаЭ,ЗжБ№ЪЧ:
- DataBase:Ъ§ОнПт
- Table:Бэ
- Partition:ЗжЧј
- Bucket:ЭА
2.1 DataBaseЪ§ОнПт
DataBaseЪ§ОнПт:ЯрЕБгкЙиЯЕаЭЪ§ОнПтжаЕФУќУћПеМф,зїгУЪЧНЋЪ§ОнПтгІгУИєРыЕНВЛЭЌЕФЪ§ОнПтФЃЪНжа ЁЃ
ЯрЙиЕФУќСю:
create databaseЪ§ОнПтУћuseЪ§ОнПтУћ- вдМА
drop databaseЪ§ОнПтУћЕШгяОф;
2.2 TableБэ
TableБэ:БэЪЧгЩДцДЂЕФЪ§ОнвдМАУшЪіБэЕФвЛаЉдЊЪ§ОнзщГЩЁЃЪ§ОнДцДЂдйЗжВМЪНЮФМўЯЕЭГжа,дЊЪ§ОнДцДЂдкЙиЯЕаЭЪ§ОнПтжа;
hiveБэЗжЫФжж:
- MANGED_TABLE :ФкВПБэ
- EXTERNAL_TABLE:ЭтВПБэ
- INDEX_TABLE:Ыїв§Бэ
- VIRTUAL_VIEW :ЪгЭМБэ
ЯрЙиЕФУќСю(ВщПДБэЕФОпЬхаХЯЂЪЙгУ):
desc tablenamedesc formatted tablename
2.2.1 ФкВПБэ
hive ЛсФЌШЯАбЪ§ОнДцДЂЕН /user/hive/warehouse ФПТМРяУц:
CREATE TABLE managed_table (dummy STRING);
LOAD DATA INPATH '/user/tom/data.txt' INTO table managed_table;
УшЪі: ИљОнЩЯУцЕФДњТы,
hiveЛсАбЮФМўdata.txtЮФМўДцДЂдкmanaged_tableБэЕФwarehouseФПТМЯТ,МДhdfs://user/hive/warehouse/managed_tableФПТМЁЃ
2.2.2 ЭтВПБэ
ЭтВПБэгыФкВПБэЕФааЮЊЩЯгааЉВюБ№ЁЃЮвУЧФмЙЛПижЦЪ§ОнЕФДДНЈКЭЩОГ§ЁЃЩОГ§ЭтВПБэЕФЪБКђ,hiveжЛЛсЩОГ§БэЕФдЊЪ§Он,ВЛЛсЩОГ§БэЪ§Он(Ъ§ОнТЗОЖЪЧдкДДНЈБэЕФЪБКђжИЖЈЕФ):
CREATE EXTERNAL TABLE external_table (dummy STRING)
LOCATION '/user/tom/external_table';
LOAD DATA INPATH '/user/tom/data.txt' INTO TABLE external_table;
УшЪі:РћгУEXTERNALЙиМќзжДДНЈЭтВПБэ,HiveВЛЛсШЅЙмРэБэЪ§Он,ЫљвдЫќВЛЛсАбЪ§ОнвЦЕН/user/hive/warehouseФПТМЯТЁЃ
2.3 PartitionЗжЧј
PartitionЗжЧј:hiveЕФЗжЧјЪЧИљОнФГСаЕФжЕНјааДжТдЕФЛЎЗж,УПИіЗжЧјЖдгІHDFSЩЯЕФвЛИіФПТМЁЃ
ДДНЈЗжЧјБэгяЗЈ:
CREATE TABLE table_name (column1 data_type, column2 data_type)
PARTITIONED BY (partition1 data_type, partition2 data_type,Ё.);
ЗжЧјБэЛљгкЗжЧјМќАбОпгаЯрЭЌЗжЧјМќЕФЪ§ОнДцДЂдквЛИіФПТМЯТ,дкВщбЏФГвЛИіЗжЧјЕФЪ§ОнЕФЪБКђ,жЛашвЊВщбЏЯрЖдгІФПТМЯТЕФЪ§Он,ЖјВЛЛсжДааШЋБэЩЈУш,ЬсИпВщбЏЪ§ОнЕФаЇТЪЁЃвВОЭЪЧЫЕ,
hiveдкВщбЏЕФЪБКђЛсНјааЗжЧјМєВУ ,УПИіБэПЩвдгавЛИіЛђЖрИіЗжЧјМќЁЃ
2.3.1 PartitionЗжЧјРраЭ
2.3.1.1 ОВЬЌЗжЧј
- АбЪфШыЪ§ОнЮФМўЕЅЖРВхШыЗжЧјБэЕФНаОВЬЌЗжЧј;
- ЭЈГЃдкМгдиЮФМў(ДѓЮФМў)ЕН
HiveБэЕФЪБКђ,ЪзЯШбЁдёОВЬЌЗжЧј; - дкМгдиЪ§ОнЪБ,ОВЬЌЗжЧјБШЖЏЬЌЗжЧјИќНкЪЁЪБМф;
- ФуПЩвдЭЈЙ§
alter table add partitionгяОфдкБэжаЬэМгвЛИіЗжЧј,ВЂНЋЮФМўвЦЖЏЕНБэЕФЗжЧјжа; - ЮвУЧПЩвдаоИФОВЬЌЗжЧјжаЕФЗжЧј;
- ФњПЩвдДгЮФМўУћЁЂШеЦкЕШЛёШЁЗжЧјСажЕ,ЖјЮоашЖСШЁећИіДѓЮФМў;
- ШчЙћвЊдк
HiveЪЙгУОВЬЌЗжЧј,ашвЊАбhive.mapred.modeЩшжУЮЊstrict,set hive.mapred.mode=strict; - ОВЬЌЗжЧјЪЧдкбЯИёФЃЪННјааЯТ;
- ФуПЩвддк
HiveЕФФкВПБэКЭЭтВПБэЪЙгУОВЬЌЗжЧјЁЃ
2.3.1.2 ЖЏЬЌЗжЧј
- ЖдЗжЧјБэЕФвЛДЮадВхШыГЦЮЊЖЏЬЌЗжЧјЁЃ
- ЭЈГЃЖЏЬЌЗжЧјБэДгЗЧЗжЧјБэМгдиЪ§ОнЁЃ
- дкМгдиЪ§ОнЕФЪБКђ,ЖЏЬЌЗжЧјБШОВЬЌЗжЧјЛсЯћКФИќЖрЪБМфЁЃ
- ШчЙћашвЊДцДЂЕНБэЕФЪ§ОнСПБШНЯДѓ,ФЧУДЪЪКЯгУЖЏЬЌЗжЧјЁЃ
- МйШчФувЊЖдЖрИіСазіЗжЧј,ЕЋгжВЛжЊЕРгаЖрЩйИіСа,ФЧУДЪЪКЯЪЙгУЖЏЬЌЗжЧјЁЃ
- ЖЏЬЌЗжЧјВЛашвЊ
whereзгОфЪЙгУlimitЁЃ - ВЛФмЖдЖЏЬЌЗжЧјжДаааоИФЁЃ
- ПЩвдЖдФкВПБэКЭЭтВПБэЪЙгУЖЏЬЌЗжЧјЁЃ
- ЪЙгУЖЏЬЌЗжЧјжЎЧА,ашвЊАбФЃЪНаоИФЮЊЗЧбЯИёФЃЪНЁЃ
set hive.mapred.mode=nostrictЁЃ
2.3.2 PartitionЗжЧјР§зг
НшгУДѓЯѓНЬГЬ(https://www.hadoopdoc.com/hive/hive-data-model)РяЕФвЛеХЭМЦЌ:
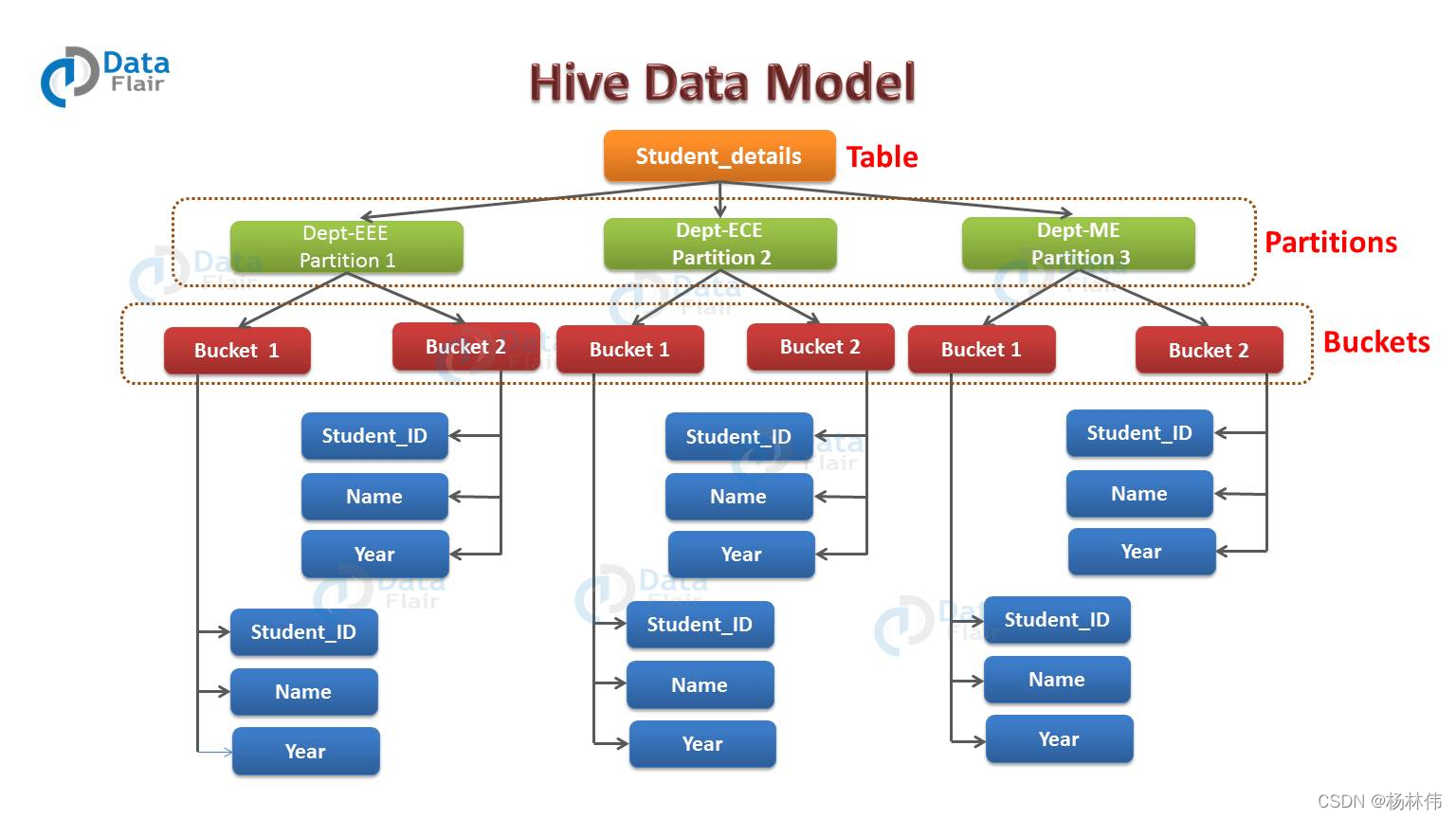
ШчЩЯЭМЫљЪО,МйШчФугавЛИіДцДЂбЇЩњаХЯЂЕФБэ,БэУћЮЊ student_details,СаЗжБ№ЪЧ student_id,name,department,year ЕШЁЃЯждк,ШчЙћФуЯыЛљгк departmentСаЖдЪ§ОнНјааЗжЧјЁЃФЧУДЪєгкЭЌвЛИі departmentЕФбЇЩњНЋЛсБЛЗждкЭЌвЛИіЗжЧјРяУц(дкЮяРэЩЯ,вЛИіЗжЧјЦфЪЕОЭЪЧБэФПТМЯТЕФвЛИізгФПТМ)ЁЃ
МйШчЫљга department = EEE ЕФбЇЩњЪ§ОнБЛДцДЂдк /user/hive/warehouse/student_details/department=EEE ФПТМЯТЁЃФЧУДВщбЏ department ЮЊ EEE ЕФбЇЩњаХЯЂ,жЛашвЊВщбЏ EEE ФПТМЯТЕФЪ§ОнМДПЩ,ВЛашвЊШЋБэЩЈУш,етбљВщбЏЕФаЇТЪОЭБШНЯИпЁЃ
ЖјдкецЪЕЩњВњЛЗОГжа,ФуашвЊДІРэЕФЪ§ОнПЩФмЛсгаМИАй
TB,ШчЙћВЛЗжЧј,дкФужЛашвЊБэЕФЦфжавЛаЁВПЗжЪ§ОнЕФЪБКђ,ФуВЛЕУВЛзпШЋБэЩЈУш,етбљЕФВщбЏНЋЛсЗЧГЃТ§ЖјЧвРЫЗбзЪдД,ПЩФм95%ЕФЪ§ОнИњФуЕФВщбЏгяОфВЂУЛгаЙиЯЕЁЃ
2.4 BucketЗжЭА
BucketЭЈУшЪі:
hiveПЩвдЖдУПвЛИіБэЛђепЪЧЗжЧј,НјвЛВНзщжЏГЩЭА,вВОЭЪЧЫЕЭАЪЧИќЮЊЯИСЃЖШЕФЪ§ОнЗЖЮЇЛЎЗжЁЃhiveЪЧеыЖдБэЕФФГвЛСаНјааЗжЭАЁЃhiveВЩгУЖдБэЕФСажЕНјааЙўЯЃМЦЫу,ШЛКѓГ§вдЭАЕФИіЪ§ЧѓгрЕФЗНЪНОіЖЈИУЬѕМЧТМДцЗХдкФФИіЭАжа(ЗжЭАЕФКУДІЪЧПЩвдЛёЕУИќИпЕФВщбЏДІРэаЇТЪ,ЪЙШЁбљИќИпаЇ)ЁЃ
вЊЪЙгУhiveЕФЗжЭАЙІФм,ЪзЯШашвЊДђПЊhiveЖдЭАЕФПижЦ:
set hive.enforce.bucketing=true;
ЗжЭАБэДДНЈУќСю:
CREATE TABLE table_name
PARTITIONED BY (partition1 data_type, partition2 data_type,Ё.)
CLUSTERED BY (column_name1, column_name2, Ё)
SORTED BY (column_name [ASC|DESC], Ё)]
INTO num_buckets BUCKETS;
УПИіЭАжЛЪЧБэФПТМЛђепЗжЧјФПТМЯТЕФвЛИіЮФМў,ШчЙћБэВЛЪЧЗжЧјБэ,ФЧУДЭАЮФМўЛсДцДЂдкБэФПТМЯТ,ШчЙћБэЪЧЗжЧјБэ,ФЧУДЭАЮФМўЛсДцДЂдкЗжЧјФПТМЯТЁЃЫљвдФуПЩвдбЁдёАбЗжЧјЗжГЩ n ИіЭА,ФЧУДУПИіЗжЧјФПТМЯТОЭЛсга n ИіЮФМўЁЃ
ОйР§:Дг2.3.1 PartitionЗжЧјР§згЭМПЩвдПДЕН,УПИіЗжЧјга 2 ИіЭАЁЃвђДЫУПИіЗжЧјОЭЛсга 2 ИіЮФМў,УПИіЮФМўНЋЛсДцДЂИУЗжЧјЯТЕФЪ§ОнЁЃ
2.4.1 ЗжЭАЬиад
Ъ§ОнЗжЭАдРэЪЧЛљгкЖдЗжЭАСазіЙўЯЃМЦЫу,ШЛКѓЖдЙўЯЃЕФНсЙћКЭЗжЭАЪ§ШЁФЃЁЃЗжЭАЬиадШчЯТ:
- ЙўЯЃКЏЪ§ШЁОігкЗжЭАСаЕФРраЭЁЃ
- ОпгаЯрЭЌЗжЭАСаЕФМЧТМНЋЪМжеДцДЂдкЭЌвЛИіЭАжаЁЃ
- ЪЙгУ
clustered byНЋБэЗжГЩЭАЁЃ - ЭЈГЃ,дкБэФПТМжа,УПИіЭАжЛЪЧвЛИіЮФМў,ВЂЧвЭАЕФБрКХЪЧДг 1 ПЊЪМЕФЁЃ
- ПЩвдЯШЗжЧјдйЗжЭА,вВПЩвджБНгЗжЭАЁЃ
- ДЫЭт,ЗжЭАБэДДНЈЕФЪ§ОнЮФМўДѓаЁМИКѕЪЧвЛбљЕФЁЃ
2.4.2 ЗжЭАКУДІ
- гыЗЧЗжЭАБэЯрБШ,ЗжЭАБэЬсЙЉСЫИпаЇВЩбљЁЃЭЈЙ§ВЩбљ,ЮвУЧПЩвдГЂЪдЖдвЛаЁВПЗжЪ§ОнНјааВщбЏ,вдБудкдЪМЪ§ОнМЏЗЧГЃХгДѓЪБНјааВтЪдКЭЕїЪд;
- гЩгкЪ§ОнЮФМўЕФДѓаЁЪЧМИКѕвЛбљЕФ,
mapЖЫЕФjoinдкЗжЭАБэЩЯжДааЕФЫйЖШЛсБШЗжЧјБэПьКмЖрЁЃдкзіmapЖЫjoinЪБ,ДІРэзѓВрБэЕФmapжЊЕРвЊЦЅХфЕФгвБэЕФаадкЯрЙиЕФЭАжа,вђДЫжЛашвЊМьЫїИУЭАМДПЩ; - ЗжЭАБэВщбЏЫйЖШПьгкЗЧЗжЭАБэ;
- ЗжЭАЕФЛЙЬсЙЉСЫСщЛюад,ПЩвдЪЙУПИіЭАжаЕФМЧТМАДвЛСаЛђЖрСаНјааХХађЁЃ етЪЙЕУ
mapЖЫjoinИќМгИпаЇ,вђЮЊУПИіЭАжЎМфЕФjoinБфЮЊИќМгИпаЇЕФКЯВЂХХађ(merge-sort)ЁЃ
2.5 ЗжЧјгыЗжЭАЕФЧјБ№
ЗжЧјгыЗжЭАЕФЧјБ№:
- ЗжЧјКЭЗжЭАзюДѓЕФЧјБ№ОЭЪЧЗжЭАЫцЛњЗжИюЪ§ОнПт,ЗжЧјЪЧЗЧЫцЛњЗжИюЪ§ОнПт;
- ЗжЧјЪЧЫЎЦНЛЎЗж,БэЕФВПЗжСаЕФМЏКЯ,ПЩвдЮЊЦЕЗБЪЙгУЕФЪ§ОнНЈСЂЗжЧј,етбљВщевЗжЧјжаЕФЪ§ОнЪБОЭВЛашвЊЩЈУшШЋБэ,етЖдгкЬсИпВщеваЇТЪКмгаАяжњ;
- ЗжЭАЪЧДЙжБЛЎЗж,ЭАЪЧЭЈЙ§ЖджИЖЈСаНјааЙўЯЃМЦЫуРДЪЕЯжЕФ,ЭЈЙ§ЙўЯЃжЕНЋвЛИіСаУћЯТЕФЪ§ОнЧаЗжЮЊвЛзщЭА,ВЂЪЙУПИіЭАЖдгІгкИУСаУћЯТЕФвЛИіДцДЂЮФМў;
(hiveЪЙгУЖдЗжЭАЫљгУЕФжЕНјааhash,ВЂгУhashНсЙћГ§вдЭАЕФИіЪ§зіШЁгрдЫЫуЕФЗНЪНРДЗжЭА,БЃжЄСЫУПИіЭАжаЖМгаЪ§Он,ЕЋУПИіЭАжаЕФЪ§ОнЬѕЪ§ВЛвЛЖЈЯрЕШ); - ЗжЭАЪЧДцДЂдкЮФМўжа,ЗжЧјЪЧДцЗХдкЮФМўМажа,ЗжЭАвЊБШЗжЧјВщбЏаЇТЪИпЁЃ
03 ЮФФЉ
БОЮФжївЊНВНтСЫHiveЕФЫФжжЪ§ОнФЃаЭ( DataBaseЪ§ОнПтЁЂTableБэЁЂPartitionЗжЧјЁЂBucketЭА),ШчгавЩЮЪЕФЭЏаЌЛЖгЦРТлЧјСєбд,аЛаЛдФЖС,БОЮФЭъ!