Ŀ¼
1. ����
- �����з���Ա����,��Ҫ��עmysql��������SQL�Ż������������ֿ�ֱ�,��������һ����DBA�ɵĻ
2. MySQL�ļܹ�
3. �洢����
3.1 ����
- �о���¼��ô�洢,��ô��֯���ݡ�
3.2 Pageҳ
-
mysql�����ݴ�������?mysql�����ݴ洢�ڴ����С������Ǵ洢��һ������Page�����,Page��mysql��һ���洢��Ԫ,������潻���Ļ�����Ԫ,ÿ��Page��С16k��Page���Ե�����һ��������ݽṹ��Page�Ǽ��ص��ڴ���ʹ�õ�,mysql���ݼ��صĵ�λ��Page��������һ��Page��ʾ��ͼ��

-
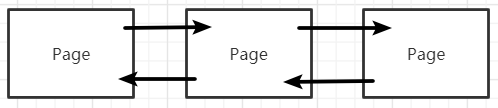
Page Header:ҳͷ����¼һЩͳ����Ϣ,56�ֽڡ�����ҳ�������ֵ�ָ����ҳ�ռ�ʹ������ȡ����е�Page����һ��˫��������
-
���¼:һ��Page�д洢�ļ�¼����С���¼��������¼֮�䡣
������¼:��ҳ�������������;��С���¼:��ҳ����С������С; -
��¼��:��ż�¼����Ϊ��Ч��¼����ɾ����¼���֡����б�ɾ���ļ�¼(��ͼ��ɫ)�ᱻ��������,��ɾ���ļ�¼�����ɿռ����������������ɿռ�����������ɾ����¼���ɵ������� -
δ����ռ�:Page��δʹ�õĴ洢�ռ�,�����¼�¼��������š���ʼʱһ��Page����δ����ռ�û�м�¼��,���ż�¼��д��,���ϲ�����¼�ѡ�
-
Slot��:(��ͼ��ɫ����)��mysqlҳ�ڲ����йء�(�����ġ�ҳ�ڲ��ҡ�) -
Page Tailer:βҳ��ҳ������,��Ҫ�洢ҳ���У����Ϣ,8�ֽڡ�
3.2 ҳ�ڼ�¼ά��
3.2.1 innodb���������ݽṹ
-
innodb�������ݽṹ��ͼ1

-
innodb�������ݽṹ��ͼ2

ע������ҳ(Ҷ�ӽڵ�)������ҳ(��Ҷ�ӽڵ�)����˫�������� -
innodb����Ҷ�ӽڵ����ݽṹ��ͼ

![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-TVRlNwVw-1645261083092)(mysql01.assets/image-20220219152954077.png)]](https://img-blog.csdnimg.cn/940159f5b8964657b06c9fffb3634fe5.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbG9jYWxob3N0NjU1MzU=,size_20,color_FFFFFF,t_70,g_se,x_16)
-
ҳ�ڲ��Ҽ�ͼ

ҳ��ҳ֮����˫������,ҳ���ǵ�������
3.2.2 ˳��֤
- ����:���ݵĴ洢�ǰ�������˳����ô���˳������α�֤��?��������?������?
- ʲô����������:ÿ������Ԫ��������ַ�������������顣�ŵ��Dz�ѯ��,����ʹ�ö��ֲ��ҡ�ȱ������ɾ��,��������Ԫ����Ҫ�ƶ���������Ԫ�ء�
- ʲô��������:Ԫ��֮���ڴ��ַ��������������������ɾ��;��ѯ��,ֻ�ܱ�����
- ��Ȼmysql����������ômysql�IJ�ѯֻ�ܱ�����?�϶�����,��ômysql�Ľ��������ʲô?����ҳ�ڲ��ҡ�
3.2.3 �������
- �о�������θ�Ч����Page�ռ䡣
- ����ʹ�����ɿռ�����,��ʹ��δ����ռ䡣 ��������ʱ�������ɿռ�����,������ɿռ������нڵ�,�ͽ����ݴ��ȥ;������ɿռ�����û�нڵ�,����δ����ռ�������һ���������ݴ��ȥ��
- ��¼�п��ܷŲ���ȥ���������ɿռ��������Ľڵ���1k,�����²������������2k��������ɿռ������нڵ�治�������������,����δ����ռ�������һ��ռ佫���ݴ洢��ȥ��
- �п��ܴ��ڴ��̿ն�(������Ƭ)���������ɿռ�������С�Ľڵ���1k,�����²��������������0.9k,��ôʣ�µ�0.1k�ռ�ͼ������ᱻ�õ��ˡ�
- ����˵,���ݿ��þ����ܻ���ڴ�����Ƭ,��Ҫ��������,���������,���ݿ����ܾͻ��½�����ô����:һ��һ��,ɾ���ӿ�,�ӿ����´�����������,�ӿ�����֮��ɾ������,�����ٴӴӿ�����ȡ����(�ܲٵ�������Ч�ķ���)��
3.2.4 ҳ�ڲ���
-
����˵��,ҳ֮��˫������,ҳ�ڵ���������
-
����ֻ�ܱ���,������Ϊ���ݿ�,��ѯ����ֻ����,������Զ���д�ٵ�ҵ��,mysql���ڲ�����һ���Ż��������Ż������ؼ�����Slot����,ʹ�õ����ݽṹ��
������ʹ�õIJ�ѯ�㷨�����ֲ���+������

- �����Slot��,����һ�������Ŀռ�,һ��Slot��8�ֽڡ�ÿ��slotָ�������е�һ���ڵ�,��һ��slotָ������ͷ,Ҳ������С���¼,���һ��slotָ������β,Ҳ����������¼�������൱�ڽ�Page������ֳɶ������������ѯ��¼����slot����
���ֲ���,�ҵ�slot֮������������������������ͼ�������ݽṹ����������
- �����Slot��,����һ�������Ŀռ�,һ��Slot��8�ֽڡ�ÿ��slotָ�������е�һ���ڵ�,��һ��slotָ������ͷ,Ҳ������С���¼,���һ��slotָ������β,Ҳ����������¼�������൱�ڽ�Page������ֳɶ������������ѯ��¼����slot����
3.3 InnoDB�洢����Ĵ��̡��ڴ�����漰���ļ�����
3.3.1 ����
-
innodb�Ĵ����ڴ�����漰�����������漼��
Ԥ�����ڴ�(Buffer Pool Ԥ�����ڴ��)- Page�����ڴ���,ʹ�ñ����ȼ��ص��ڴ档��c������,ʹ���ڴ������롣�����ݿ��в�����ô��,Ч�ʵ�,��˻�Ԥ������һ���ڴ�ռ��Ա��洢�����м��ص�Page��
���ݼ��ص�λ(Page��Buffer Pool����С��λ,Ҳ��ҳ����ص���С��λ)- ��PageΪ��λ���ش������ݡ���һ��io����һ��Page,һ�μ���16k��
- һ��Page����һ����¼,һ�μ���һ��Page��Ϊ�����ioЧ�ʡ�����һ����¼,���������¼��������,��ô������¼���ߵļ�¼Ҳ������������,��ôͨ��Pageһ���Լ��ص��ڴ�������ioЧ�ʡ�
��������潻��- �ڴ�ռ�С�ڴ��̿ռ�,����ڴ����Ѿ�������Page,��ô��Ҫ�����µ�Page����Ǻ�?����漰��innodb���ڴ����,�ڴ�ʹ��̵����ݽ������ԡ�
-
��������潻��ʾ��ͼ

- �漰����
- Free list:����Page��ɵ�������
- Flush list:��ҳ�б���ֱ��Ϊˢ���б���
- Page hash��:ά���ڴ�Page�ʹ����ļ�Page��ӳ���ϵ��
- LRU:һ��������̭�㷨;����mysql�ڴ�������̭��
- �漰����
3.3.2 Ԥ�����ڴ�(�ڴ��)
- ����ȷ���һ����ڴ�ռ�����װ�����ݡ�
3.3.3 ���ݼ��ص�λ(�ڴ�ҳ�����)
- ��ô����Page��?ͨ��ҳ��ӳ���ҳ�����ݹ�����
- ҳ��ӳ��
- ָ���Ǵ�����Page���ڴ���Page��ӳ���ϵ,���Ǵ����е�ij��Page�÷ŵ��ڴ��е��ĸ��������ӳ�䲻�Ǽ��������,����Ǽ��������,��ô�����е�ij��PageӦ�÷ŵ��ڴ��е��Ŀ�����̶�����,�ڴ�ԭ���ͱȴ���С,�����������10000��Page,�ڴ�ֻ�����1000��Page,���һ��һӳ��̶���,��ô������ʣ��9000��Page��Զ�����ص��ڴ�,�����Dzٵ��ˡ�����ҳ��ӳ��IJ������ڴ������п���,innodb�ͽ������е�Page���ص��Ķ�,�����̺��ڴ��Pageӳ���Ƕ�̬�ġ�
- ҳ��ӳ���ϵ��Ҫά���á�������Page����Ҫд���ڴ�,�ڴ��е�Page�����д������(�����ļ�¼ʱ)��
- ҳ�����ݹ���
- �ڴ���Page���ֻ�Ƕ�,�Ͳ���Ҫ��д������;����ļ�¼,�ڴ���Page����Ҫ��д�����̡���Щ��������ҳ�����ݹ�����
3.3.4 ��������潻��(������̭)
- �ڴ��������Page,��ô�����µ�Page��?ͨ��������̭��
3.3.5 ҳ�����
-
�漰����
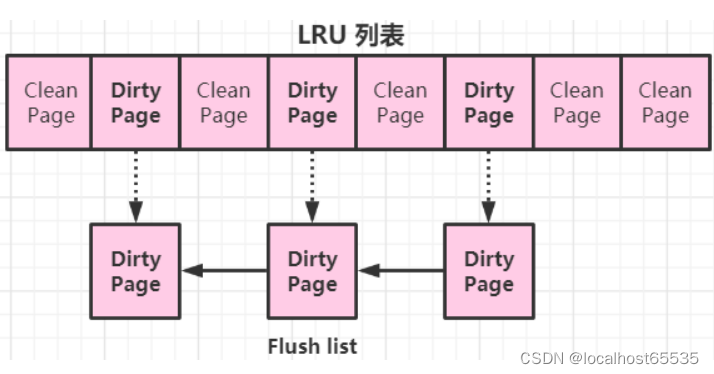
����ҳ:Ԥ�����ڴ���δ��ʹ�õIJ��֡�������ͼ��Ԥ�����ڴ��еĿհ��ӡ�- ����ҳ
Clean Page:�ڴ���Page�ʹ�����Page��ȫ��ͬ��������ͼPage1��Dirty Page (��ҳ):�ڴ���Page���м�¼����,��ô��Page��Ҫ��ˢ����̡�������ͼPage2�������ڴ��з������µ�Page��

-
��������Page����֯����,����InnodbҪ���������֮һ��
3.3.6 �ڴ���� �C �ڴ�ҳ����̭
- һ����̭����ʹ��LRU,mysqlҲ�ǡ�
LRU:��̭���δ��ʹ�õ�����,�������ݱ���,��������̭��- ���㷨��˼����һ������ͷ����������,β����������,ɾ��β�����ݡ�ʵ��ԭ���Ƿ����ĸ�����,�ͽ������ݷŵ���ͷ��
- �Ӵ��̼�����Pageʱ���ڴ���LRU������β����ɾ��,�����ݷŵ�����β��
- ע��:�����С�Ķ�mysql����ȫ��ɨ��,��ô���е����ݶ�����ѯ�ŵ�LRU��ͷ,���LRU�зŵĿ϶��DZ�����������,�����ݾͱ���̭�ˡ���α������������ݱ���̭?�ҿ����뵽����˼·:
- ����ʱ��+����Ƶ��(LFU)��LFU��Redis�еġ�(Redis��ʹ��)
- ����URL��:�������ݷŵ��ڶ���LRU����,��ȫ��ɨ�跢���ڵ�һ��LRU���С�(mysqlʹ��)
3.3.7 MySQL��LRU
-
mysql��������̭������LRU��mysql�Ľ������ʹ�õ���һ��LRU���������ȷ���,��������Ϊʹ�õ�������LRU������

-
ҳ��װ��(���ڴ�)�Լ�ҳ��(���ڴ�)��̭

������Pageװ�ص��ڴ�IJ���:�ȴ�free list���ҵ�һ������ҳ => Ȼ���¼���̵��ڴ��Page��ӳ���ϵ => Page����LRU_old��
��װ�ص�Page�϶����ȵ���������,��������PageҪô����̭,Ҫô���ƶ�������������
Page��������������headд��,Page������������̭��tail��̭��
Page�����������ƶ�������������д�뵽����������head,Page������������̭�����������tailд������������head��

װ��Page��ʱ����ȥ�ҿ���ҳ,���û�п���ҳ,�ͻ�����̭oldβ����Page => �ٽ����̵�Pageװ�ص�lodβ�� => �ٽ�β����Page�ƶ���old��ͷ��
LRU old��β����Page������ڱ���,��ôPage���м�¼������,��ʱβ����Page�Ͳ��ܱ���̭��LRU����������ҳ,��ô����ҳ�Ͱ���clean page��dirty page,LRU�����е�dirty page���һ��Flush list�����LRU oldβ����Page������̭,��ô�ͻ��LRU Flush list�н���һ��dirty pageˢ�̲��ͷ�,��ʱ��鱻�ͷŵ��ڴ�Ϳ������������µ������ˡ����������:��ˢ��(����ҳд�ش���) => ��ҳ�ƶ���LRU oldβ�� => ��̭LRU(��LRUβ����Page����Free listͷ��)=> ��Free list���ҿ���ҳ => ��������IJ�����,��ҳ���ƶ���LRUβ�����Ƕ����,��Ϊ�ŵ�β����Ŀ������̭��,������mysql5.2֮��ò��Ƴ�,ֱ����̭��
-
λ���ƶ�
-
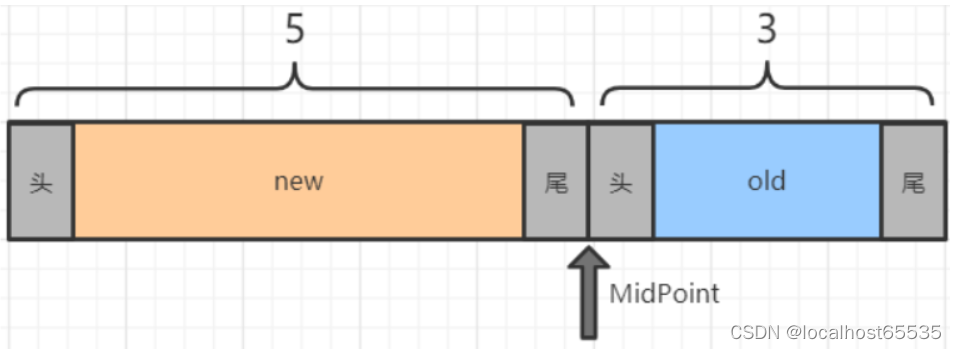
old��new

- old����Page�ƶ���new����������ʱ��:innodb_old_blocks_time����,����Page��old���Ĵ��ʱ��,���old��Page���ʱ����ڸò���ֵ,���л������new����
-
new��old������������ȵ��������������ȵ�,���Դ�new tail�ƶ���old head��

- new���������ƶ���old�����������ƶ���ʽ:������new tail�е�Page�ƶ���old head,����Midpointָ���λ������һPage��
-
-
LRU_new�IJ���

- ������ɾ��Ч�ʺܸ�,Page�з��ʾ��ƶ�����ͷò�ƺܺ���������mysql����Ҫ������Lock���ƶ���Ҫ����,Ϊ�˼��ټ�������,mysql�����˼·������Page�ƶ�������������漰����������:freed_page_clock(Buffer Pool ��̭��Page��)��LRU_new���ȵ�1/4��
- ÿ����һ��Page��̭,freed_page_clock��ֵ�ͻ�+1,����һ��ȫ�ּ�������
- ��ǰʱ�̵�freed_page_clock - �ϴθ�Page�ƶ���LRU_new headerʱ��freed_page_clock�� > LRU_new ���ȵ�1/4�� ��ʱ,Page�Ż��ƶ���