从迁移方案的落地、迁移前准备、N次迁移演练、回归测试、性能调优整整用了四个月左右的时间(当然在此期间还包括其他项目及日常操作耗费工时)。正式迁移到迁移成功、以及上线开服后性能稳定这些操作已经过去了一个多月时间。由于异构迁移在业界是一个较为困难繁琐的问题,所以经过这么久的沉淀,今天给大家复盘并分享一下整个迁移流程,从前期方案、到最后迁移成功的整个流程,希望给对 ORACLE TO MYSQL 异构迁移流程不清晰的同学,一点思路!
目录
一、迁移原由
二、迁移目标
三、迁移方案落地
1.协同高层确定项目目标
2.制定迁移计划
四、迁移工具选型(含功能实现原理)
(1)SQL LOAD
(2)OGG
(3)KETTLE
(4)DATAX
(5)ADAM STUDIO
(6)DTS
五、对象兼容性改写
1.oracle与mysql数据类型转换详情
2.大小写敏感参数
3.数据库对象不兼容改写方案
(1)view
(2)物化视图
(3)Trigger、存储过程、package
(4)分页语句
(5)JOIN
(6)group by语句
(7)bitmap位图索引
(8)分区表(Partitioned table)
(9)角色
(10)表情和特殊字符
六、全量数据校验方案
1.全量数据验证逻辑流图
2.全量数据验证脚本逻辑
3.数据验证注意事项
七、压力测试
八、迁移演练
九、正式迁移
?重复数据处理方案
1).重复数据出现原因:
2).解决方案
十、迁移后性能调优
1.上线后持续关注目标端数据库性能
2.参数调优
innodb_flush_log_at_trx_commit
sync_binlog
max_allowed_packet
innodb_log_file_size
innodb_log_buffer_size
innodb_buffer_pool_size
innodb_buffer_pool_instances
一、迁移原由
?“去O”,是近些年来一直很火的一个话题。但2019年,也许有着更加特殊的意义。随着国家监管要求、外部环境变化、国产数据库兴起等多种因素,相信今年会是“去O”井喷发展的一年。去O更详细的说是去IOE。
“去IOE”:是阿里巴巴造出的概念。其本意是,在阿里巴巴的IT架构中,去掉IBM的小型机、Oracle数据库、EMC存储设备,代之以自己在开源软件基础上开发的系统。(如公有云厂商产品RDS、CDB等)
二、迁移目标
- 迁移前后结构一致
- 迁移前后数据一致
- 迁移完成上线后――业务运行――性能稳定
- 最终实现oracle数据向mysql数据库的平滑过渡
三、迁移方案落地
1.协同高层确定项目目标
这里需要确定的包括迁移源端(如哪几个oracle数据库)、目标端(如迁移到RDS For MySQL、或者机房自建MySQL)
2.制定迁移计划
这里的迁移计划指的是整个迁移过程的整体排期,包含:
- 前期的迁移工具选型
- 测试环境搭建
- 迁移工具测试
- 对象兼容性统计、对比、改写
- 全量数据校验方案
- 压力测试
- 多次迁移演练、产出迁移方案
- (该方案指的是迁移的详细操作步骤,方案中的操作步骤建议补充到尽可能详细,防止迁移当天由于任何原因出现操作步骤遗忘等任何故障,当然该方案可以留作下次迁移参考,以及经验总结)
- 正式迁移
- 上线后性能调优
那么下面就按照该部分迁移计划中的步骤,叙述详细内容及关键点
四、迁移工具选型(含功能实现原理)
大家再迁移前,可以了解到,迁移涉及到结构迁移和数据迁移,那么在迁移工具选型的时候,需要考虑的几点:
- 该工具可以迁移结构、数据还是二者
- 该工具迁移前后数据库对象的兼容性
- 使用该工具迁移后改写工作量
- 是否可以做全量数据校验
这里简单聊几个目前常见的oracle迁移mysql的工具及与原理:
(1)SQL LOAD
这里使用的是powerdesigner,使用该工具迁移结构,首先在plsql中将oracle数据库中的表结构导出csv/sql,使用powerdesigner加载导出的oracle结构语法转换为mysql结构语法,转换后的结构语法存在大量改写:
-
表注释、列注释全部保留
-
索引数量没有丢失,但是部分唯一索引被修改为普通索引(源库多个索引且全部为唯一索引,这种情况转换后被修改为普通索引)
-
int数据类型全部转换为numeric,float数据类型没有转换,其他同DTS
-
保留了源库的default默认值,没有增加default null
-
分区表全部丢失
-
存储过程全部丢失
-
转换后timestamp类型需要转换其他类型才能导入(测试期间修改为datetime),float没有转换,需要改为double才能导入存在Specified key was too long; max key length is 3072 bytes,需要修改列长度
(2)OGG
Oracle?GoldenGate(OGG)可以在多样化和复杂的?IT?架构中实现实时事务更改数据捕获、转换和发送;其中,数据处理与交换以事务为单位,并支持异构平台,例如:DB2,MSSQL等
- Oracle?GoldenGate?数据复制过程如下:
- 利用抽取进程(Extract?Process)在源端数据库中读取Online?Redo?Log或者Archive?Log,然后进行解析,只提取其中数据的变化信息,比如DML操作――增、删、改操作,将抽取的信息转换为GoldenGate自定义的中间格式存放在队列文件(trail?file)中。再利用传输进程将队列文件(trail?file)通过TCP/IP传送到目标系统。
- 目标端有一个进程叫Server?Collector,这个进程接受了从源端传输过来的数据变化信息,把信息缓存到GoldenGate 队列文件(trail file)当中,等待目标端的复制进程读取数据。
- GoldenGate?复制进程(replicat?process)从队列文件(trail?file)中读取数据变化信息,并创建对应的SQL语句,通过数据库的本地接口执行,提交到目标端数据库,提交成功后更新自己的检查点,记录已经完成复制的位置,数据的复制过程最终完成。

但OGG有一个缺陷,做不到全量数据对比!
(3)KETTLE
Kettle是一款国外开源的ETL工具,可以在Windows、Linux、Unix上运行,纯java编写。该工具使用前需要做代码改造,以适用现有的业务场景。
(4)DATAX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。DataX采用了框架 + 插件 的模式,目前已开源,代码托管在github。
DATAX底层原理:
- DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
(5)ADAM STUDIO
阿里云官方描述:ADAM推出Oracle数据库平滑迁云解决方案,覆盖Oracle迁移的全生命周期,包括数据库与应用评估(兼容性、关联关系、性能、风险点、应用改造点)、转换(转换不兼容点、引擎特征优化转换)、结构迁移、数据迁移、一致性校验、SQL仿真回放、割接、优化。
这里简单聊一下在测试过程中,对该工具的总结:
1.首先该工具需要搭建一套adam环境,部署一套mysql数据库存储迁移数据,迁移操作以web界面的形式呈现,操作相对较为简单
2.ADAM有一个个人认为非常实用的功能,在分析完结构对象在源端与目标端迁移前后兼容性后,会出一份兼容性报告,报告较为详细,包含了所有的对象的个数,不兼容对象的创建语句(如sequence、存储过程、merge into等),甚至包含这些对象的一些兼容性改写方案,对于无法兼容的对象,也有做标记,便于DBA及研发同学核对。
(6)DTS
- 数据传输服务DTS(Data Transmission Service)是阿里云提供的实时数据流服务,支持RDBMS、NoSQL、OLAP等。
- DTS自身可以实现结构迁移和数据迁移,结合迁移改造工作量、数据验证几个方案,测试比对各个迁移工具,最终本次oracle迁移mysql使用了DTS工具。
- DTS工具可以实现数据验证功能,但是DTS仅能含主键或者唯一键约束的表,同时仅验证的是主键这一列的内容一致,DTS即认为数据一致,仍然做不到全量的数据验证
关于DTS同步数据的原理可以类比于OGG,给大家放一张图,如需要深入了解,可以看本人的这篇博客【阿里云DTS原理】
https://blog.csdn.net/qq_44714603/article/details/105205150
这里补充几个在DTS在迁移过程中需要改造的几个点:
- Default 为Sysdate需要转换为now(),(测试期间,改为CURRENT_TIMESTAMP,这两者是一样的。)
- 存在Specified key was too long; max key length is 3072 bytes,需要修改列长度
- 补齐丢失的唯一索引
- 分区表全部不兼容,需要改写
- 存储过程不兼容,需要改写
- 外键约束不兼容,需要改写
- (mysql中数据库对象不如oracle的多,所以针对自家oracle数据库中的对象,如果oracle中的对象在mysql中没有对应的,一般需要改写)
五、对象兼容性改写
对于对象兼容性这部分,大家需要兼顾人员分配。
- 相关数据库对象统计,研发与DBA都可以做,这里建议DBA做,因为DBA对数据库的权限相对较高,建议这里DBA与研发协作,互相比对对象统计结。
- 相关不兼容的数据库对象改写,这里建议研发同学执行,DBA协助技术支持。其实改写SQL是DBA的基本技能,这里建议研发同学改写,DBA同学协助的原因是,在一个项目人员细分较为明确的场景下,往往研发同学对业务更加了解,想存储过程不兼容的改写方案,更加建议研发同学结合真实的业务场景改写SQL,而DBA同学价值更应该体现在校验SQL语法以及SQL性能方面
- 相关迁移改写后SQL执行问题,需要拆分SQL语句中的DDL语句与DML语句,测试环境可以给研发放开数据库权限,但是线上环境务必控制好数据库权限,对于DDL操作及部分DML操作务必要DBA操作,这里主要关系到DBA与研发同学不同职能的问题,一方面方便DBA管理数据库对象,另外DBA更擅长对SQL的性能评估,防止随意操作故障发生!
1.oracle与mysql数据类型转换详情
2.大小写敏感参数
我们较为了解的是表结构大小写敏感参数lower_case_table_names,但是数据内容区分大小写敏感参数(collate)参数使用可能较少,由于oracle默认是区分数据大小写的,为达到迁移前后一致性,所以我们需要对这个参数做显式修改。(该参数非常关键!!)
Collate参数在官方文档中的解释:https://dev.mysql.com/doc/refman/5.7/en/charset-binary-collations.html
由于迁移过程涉及多次数据导入导出,因此使用以下语句可防止乱码
set names utf8 collate utf8_bin;
编码为utf8且校验规则为数据内容大小写敏感
3.数据库对象不兼容改写方案
(1)view
在MySQL里view是不可以嵌套子查询的:
?????? create view v_ceshi?as select * from (select * from test) t;
?????? ERROR 1349 (HY000): View's SELECT contains a subquery in the FROM clause
解决方法就是view的嵌套:
?????? create view v_test as select * from test;
?????? Query OK, 0 rows affected (0.02 sec)
?????? create view v_ceshi?as select * from v_test;
?????? Query OK, 0 rows affected (0.00 sec)
(2)物化视图
物化视图用于预先计算并保存表连接或聚集等耗时较多的操作结果,这样在执行查询时,就可以避免进行这些耗时的操作,而从快速得到结果。但是MySQL里没有这个功能。通过事件调度和存储过程模拟物化视图,实现的难点在于更新物化视图,如果要求实时性高的更新,并且表太大的话,可能会有一些性能问题。
(3)Trigger、存储过程、package
1)Oracle创建触发器时允许or,但是MySQL不允许。所以迁移时如果有需要写两个。
2)两种数据库定义变量的位置不同,而且MySQL里不支持%type。这个在Oracle中用得太频繁了,是个好习惯。
3)elseif的逻辑分支语法不同,并且MySQL里也没有for循环。
4)在MySQL中不可以返回cursor,并且声明时就要赋对象。
5)Oracle用包来把存储过程分门别类,而且在package里可以定义公共的变量/类型,既方便了编程,又减少了服务器的编译开销。可MySQL里根本没有这个概念。所以MySQL的函数也不可以重载。
6)预定义函数。MySQL里没有to_char() to_date()之类的函数,也并不是所有的Oracle都是好的,就像substring()和load_file()这样的函数,MySQL有,Oracle却没有。
7)MySQL里可以使用set和=号给变量赋值,但不可以使用:=。 而且在MySQL里没 || 来拼接字符串。
?8)MySQL的注释必须要求-- 和内容之间有一个空格。
9)MySQL存储过程中只能使用leave退出当前存储过程,不可以使用return。
10)MySQL异常对象不同,MySQL同样的可以定义和处理异常,但对象名字不一样。
业务SQL中如果有下面的函数使用,需要改写成mysql支持的:对于mysql不建议使用存储过程
oracle与mysql之常用函数的区别:
nvl(xx, 0) ==> coalesce(xx, 0)
说明:返回第一个非空值。
to_char(xx) ==> cast(xx as char)
说明:转换为char类型
to_char(xx,'yyyymmdd') ==> date_format(xx, '%Y%m%d')
说明:日期格式化,date_format具体参数查询文档
to_char(xx,'yyyyq') ==> concat(date_format(xx, '%Y'), quarter(xx))
说明:mysql date_format无法格式化季度,需要借助quarter函数
to_number(xx) ==> cast(xx as unsigned integer)
说明:转换为数字类类型,unsigned integer为无符号整数
sysdate ==> now()或者用current_timestamp代替,由于oracle在TIMESTAMP是有时区信息,这块改成mysql后不带时区的,所以对于高精度这块mysql不能完全解决。
说明:获取当前时间
decode(cond, val1, res1, default) ==> case when cond = val1 then res1 else default end
说明:根据cond的值返回不同结果
trunc(xx, 2) ==> convert(xx, decimal(6,2))
说明:保留2位小数
wm_concat(xx) ==> group_concat(xx)
说明:列转行
over() ==> 无
说明: mysql没有开窗函数,需要代码实现
oracle与mysql之语法的区别:
connect by…start with ==> 无
说明: mysql没有递归查询,需要代码实现
rownum ==> limit
说明:分页
'a'||'b' ==> concat('a', 'b')
说明:字符串拼接
select xx from (select xx from a) ==> select xx from (select xx from a) t1
说明:from后的子查询必须有别名
nulls last ==> 无
说明:mysql排序时,认为null是最小值,升序时排在最前面,降序时排在末尾
group by (a, b) ==> group by a, b
说明:mysql group by 字段不能加括号
begin end; ==> begin; commit;
说明:mysql事务控制begin后需要加分号执行,提交使用commit。P.S.禁止在sql中进行事务控制
select 1, 1 from dual
union
select 1, 1 from dual
==>
select 1 as a, 1 as b from dual
union
select 1 as a, 1 as b from dual
说明:mysql的union查询的每个字段名必须不同
null值在oracle和mysql中的差异
说明:在oracle和mysql中null都表示为空的意思,但是两者之间还是有差异的,oracle中null与''是等价的,但是在mysql中null与''则不是等价的,在不同的数据库中,''与null是有差异的。oracle中的''与 null是等价的,但是我们在写sql时不能使用''=null这种方式,只能是'' is null这种方式;而在mysql中''与not null是等价的,同理我们在写sql时不能使用'' <> null这种方式,只能用'' is not null。
Oracle中date类型对应 MySQL 时间类型以及空值的处理
Oracle数据库的date类型和mysql的date类型是不一样的,Oracle为yyyy-mm-dd hh:mi:ss和mysql中的datetime类型匹配, 而mysql 为 yyyy-mm 。当在存在空值的时候,mysql的time 类型可以使用0零来插入,而date,datetime,timestamp可以使用null 来插入,但是timestamp即使为null,也会默认插入当前时间戳。
(4)分页语句
MySQL中使用的是limit关键字,但在Oracle中使用的是rownum关键字。所以每有的和分页相关的语句都要进行调整。
(5)JOIN
如果你的SQL里有大量的(+),这绝对是一个很头疼的问题。需要改写。
(6)group by语句
Oracle里在查询字段出现的列一定要出现在group by后面,而MySQL里却不用。只是这样出来的结果可能并不是预期的结果。造成MySQL这种奇怪的特性的归因于sql_mode的设置,一会会详细说一下sql_mode。不过从Oracle迁移到MySQL的过程中,group by语句不会有跑不通的情况,反过来迁移可能就需要很长的时间来调整了。
(7)bitmap位图索引
在Oracle里可以利用bitmap来实现布隆过滤,进行一些查询的优化,同时这一特性也为Oracle一些数据仓库相关的操作提供了很好的支持,但在MySQL里没有这种索引,所以以前在Oracle里利于bitmap进行优化的SQL可能在MySQL会有很大的性能问题。
目前也没有什么较好的解决方案,可以尝试着建btree的索引看是否能解决问题。要求MySQL提供bitmap索引在MySQL的bug库里被人当作一个中级的问题提交了上去,不过至今还是没有解决。
(8)分区表(Partitioned table)
需要特殊处理,与Oracle的做法不同,MySQL会将分区键视作主键和唯一键的一部分。为确保不对应用逻辑和查询产生影响,必须用恰当的分区键重新定义目标架构。
(9)角色
MySQL8.0以前也没有role的对象。在迁移过程中如果遇到的角色则是需要拼SQL来重新赋权。不过MySQL更好的一点是MySQL的用户与主机有关。
(10)表情和特殊字符
在Oracle里我们一般都选择AL32UTF8的字符集,已经可以支付生僻字和emoji的表情了,因为在迁移的时候有的表包含了大量的表情字符,在MySQL里设置了为utf8却不行,导过去之后所有的都是问号,后来改成了utf8mb4才解决问题,所以推荐默认就把所有的DB都装成utf8mb4吧。
Oracle和MySQL差异远远不止这些,像闪回、AWR这些有很多,这里只谈一些和迁移工作相关的。
六、全量数据校验方案
前面我们在迁移工具选型的时候,就了解到,目前很多迁移工具是做不到数据校验的,甚至少部分可以校验的迁移工具也仅仅是做针对约束列的数据校验,所以,我们这里采用开发自主脚本实现全量的数据校验
1.全量数据验证逻辑流图

2.全量数据验证脚本逻辑
- 利用sqluldr2和mysqluldr2工具,按照主键列排序导出数据(不含主键的表,按照唯一值最多的几列排序),对比文件MD5
- 由于第一次导出数据文件制定字符集是utf8,可能会出现数据截断现象,所以对于第一次MD5不一致的表,重新导出,再次验证MD5
- 两次MD5都不一致,diff文件内容,批处理由于排序问题导致diff不一致的结果,互相循环过滤diff结果中的“>”和“<”行,行数是否大于1,如果大于1,意味该行在表中存在完全重复的行,则校验该行内容在oracle和mysql数据文件中的行数是否一致,最终脚本输出为数据不一致的表,以及表中不一致的行内容。
从上面的脚本逻辑中可以看到,该自主研发脚本是做不到动态验证数据的,所以要求必须在停服后,导出静态数据,对比两端,所以为了节省更多的时间,数据验证脚本这步可以采用并行导出数据的方案。
3.数据验证注意事项
迁移前后全量数据的一致性是迁移的基本原则,也是难点,请读者务必关注这部分,本次迁移过程中,过于考虑数据验证逻辑是否有疏漏而忽略了少部分的代码执行结果是否与预期一致(代码体现为grep配合awk出现数据截断,导致不一致的数据未验证出来),后期项目主备负责人验证代码时修复,否则将酿成大错,此处需要特别注意!
七、压力测试
这里在压力测试的时候,研发更加熟悉业务,DBA更加擅长数据库性能优化,所以该步骤建议DBA协助研发同学执行测试过程
八、迁移演练
注意事项:
- 在时间允许的情况下,建议尽可能多的做几次迁移演练,多次演练将可能出现的问题全部发掘出来
- 同时将所有的演练问题、解决方案及其他经验输出到文档中,以便后续查阅
- 各个步骤的操作时间需要记录,以便后续结合研发侧需要的时间整合并确定一个停服时间
- 由于使用第三方迁移工具,考虑到数据安全性,这里建议正式迁移当天使用内网专线进行迁移防止脱库!!
九、正式迁移
在DBA迁移演练和研发测试可以验收后,在业务低峰期的范围内确定停服时间进行正式迁移
由于前期迁移演练次数较多,出现的问题尽可能记录在迁移方案中,故迁移当前按照迁移方案执行迁移即可。
这里只简单描述一下正式迁移期间,出现重复数据的处理方案
?重复数据处理方案
1).重复数据出现原因:
迁移工具在重放update时,是delete+insert操作,但是delete操作丢失,insert成功,导出重复数据的出现
2).解决方案
1.添加主键、唯一键
2.Group by或者distinct去重导出临时表,rename原表为test_bak,在rename临时表为test
(1)所有列去重
--distinct
insert into tb_actv_openid_cn_bind(APP,ACTV,VERSION,OPENID,CN,CN_MASTER,ACCESS_DATE,STATUS) select distinct * from tb_actv_openid_cn_bind_bak;--group by
insert into tb_actv_openid_cn_bind(APP,ACTV,VERSION,OPENID,CN,CN_MASTER,ACCESS_DATE,STATUS) select * from tb_actv_openid_cn_bind_bak group by APP,ACTV,VERSION,OPENID,CN,CN_MASTER,ACCESS_DATE,STATUS;(2)部分列去重
--group by
insert into tb_actv_openid_cn_bind(APP,ACTV,VERSION,OPENID,CN,CN_MASTER,ACCESS_DATE,STATUS) select * from tb_actv_openid_cn_bind_bak group by APP,ACTV,VERSION,OPENID,CN,CN_MASTER,ACCESS_DATE,STATUS;
--
select * from table group by col1,col3;对于标准的sql_mode:

对于不标准的sql_mode:
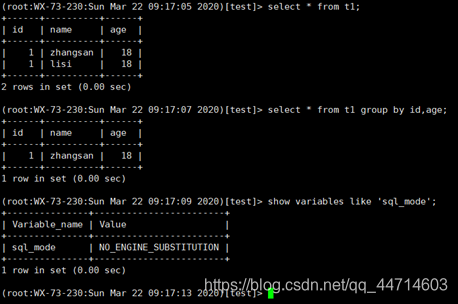
迁移当天:
-- Select count(*) from t1 group by col1,col2,col3;
--Select count(*) from t1 group by col1,col3;二者相等的情况下,说明col1,col3这两列没有重复数据,在阿里云以group by col1,col3导出,再导入到腾讯云(不丢失数据),再建立组合唯一索引
讨论:
?????如果上面情况,二者不等,说明col1,col3这两列有重复数据,如何处理?
??????????????? 1.组合唯一索引增加一列col2,以确定唯一性
??????????????? 2.前提:如果允许删除col1,col3重复,col2不重复的行(保留唯一键重复的首行)
????????????????? (1)那么可以通过增加一列自增主键列,保留重复行主键号最小的一行进行删除(删除效率很低)
delete from sub_dj_enroll_sign
? where (app, actv, version, cn_master, sign_date_str) in
??????? (select *
?????????? from (select app, actv, version, cn_master, sign_date_str
?????????????????? from sub_dj_enroll_sign
????????????????? group by app, actv, version, cn_master, sign_date_str
???????????????? having count(*) > 1) temp1)
??? and id not in
??????? (select *
?????????? from (select min(id)
?????????????????? from sub_dj_enroll_sign
????????????????? group by app, actv, version, cn_master, sign_date_str
???????????????? having count(*) > 1) temp2);???????????????? (2)逻辑上拼主键,having出来的都是重复数据,然后现在有了重复数据的起始主键值a,和重复行数b,要删除的主键值就是(a+1~a+b-1)这个段,然id等于这部分,直接删。(如果重复行,主键号不连续,该方法不可行)
十、迁移后性能调优
DBA在正式迁移完数据后,需要协助研发做最终的回归测试,测试验证通过后,启服上线!
1.上线后持续关注目标端数据库性能
如出现慢查询等导致CPU或IO骤升骤减的情况,请及时优化SQL
2.参数调优
我们可以在导入数据的时候预先的修改一些参数,来获取最大性能的处理,比如可以把自适应hash关掉,Doublewrite关掉,然后调整缓存区,log文件的大小,把能变大的都变大,把能关的都关掉来获取最大的性能,我们接下来说几个常用的:
innodb_flush_log_at_trx_commit
如果innodb_flush_log_at_trx_commit设置为0,log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行。该模式下,在事务提交时,不会主动触发写入磁盘的操作。
如果innodb_flush_log_at_trx_commit设置为1,每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去。
如果innodb_flush_log_at_trx_commit设置为2,每次事务提交时MySQL都会把log buffer的数据写入log file。但是flush(刷到磁盘)的操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。
注意:由于进程调度策略问题,这个“每秒执行一次 flush(刷到磁盘)操作”并不是保证100%的“每秒”。
sync_binlog
sync_binlog 的默认值是0,像操作系统刷其它文件的机制一样,MySQL不会同步到磁盘中去,而是依赖操作系统来刷新binary log。
当sync_binlog =N (N>0) ,MySQL 在每写N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
注:如果启用了autocommit,那么每一个语句statement就会有一次写操作;否则每个事务对应一个写操作。
max_allowed_packet
在导大容量数据特别是CLOB数据时,可能会出现异常:“Packets larger than max_allowed_packet are not allowed”。这是由于MySQL数据库有一个系统参数max_allowed_packet,其默认值为1048576(1M),可以通过如下语句在数据库中查询其值:show VARIABLES like '%max_allowed_packet%';?
修改此参数的方法是在MySQL文件夹找到my.cnf文件,在my.cnf文件[MySQLd]中添加一行:max_allowed_packet=16777216
innodb_log_file_size
InnoDB日志文件太大,会影响MySQL崩溃恢复的时间,太小会增加IO负担,所以我们要调整合适的日志大小。在数据导入时先把这个值调大一点。避免无谓的buffer pool的flush操作。但也不能把 innodb_log_file_size开得太大,会明显增加 InnoDB的log写入操作,而且会造成操作系统需要更多的Disk Cache开销。
innodb_log_buffer_size
InnoDB用于将日志文件写入磁盘时的缓冲区大小字节数。为了实现较高写入吞吐率,可增大该参数的默认值。一个大的log buffer让一个大的事务运行,不需要在事务提交前写日志到磁盘,因此,如果你有事务比如update、insert或者delete 很多的记录,让log buffer 足够大来节约磁盘I/O。
innodb_buffer_pool_size
这个参数主要缓存InnoDB表的索引、数据、插入数据时的缓冲。为InnoDN加速优化首要参数。一般让它等于你所有的innodb_log_buffer_size的大小就可以,
innodb_log_file_size要越大越好。
innodb_buffer_pool_instances
InnoDB缓冲池拆分成的区域数量。对于数GB规模缓冲池的系统,通过减少不同线程读写缓冲页面的争用,将缓冲池拆分为不同实例有助于改善并发性。