MySQL集群架构
一、集群架构设计
1、架构设计理念
在集群架构设计时,主要遵从下面三个维度:
可用性
扩展性
一致性
2、可用性设计
站点高可用,冗余站点
服务高可用,冗余服务
数据高可用,冗余数据
保证高可用的方法是冗余。但是数据冗余带来的问题是数据一致性问题。
实现高可用的方案有以下几种架构模式:
主从模式
简单灵活,能满足多种需求。比较主流的用法,但是写操作高可用需要自行处理。
双主模式
互为主从,有双主双写、双主单写两种方式,建议使用双主单写
3、扩展性设计
扩展性主要围绕着读操作扩展和写操作扩展展开。
如何扩展以提高读性能
加从库
简单易操作,方案成熟。
从库过多会引发主库性能损耗。建议不要作为长期的扩充方案,应该设法用良好的设计避免持续加从库来缓解读性能问题。
分库分表
可以分为垂直拆分和水平拆分,垂直拆分可以缓解部分压力,水平拆分理论上可以无限扩展。
如何扩展以提高写性能
分库分表
4、一致性设计
一致性主要考虑集群中各数据库数据同步以及同步延迟问题。可以采用的方案如下:
不使用从库
扩展读性能问题需要单独考虑,否则容易出现系统瓶颈。
增加访问路由层
可以先得到主从同步最长时间t,在数据发生修改后的t时间内,先访问主库。
MySQL的主从复制:
1、MySQL主从复制的原理:
Slave从Master获取binlog二进制日志文件,然后再将日志文件解析成相应的SQL语句在从服务器上重新执行一遍主服务器的操作,通过这种方式来保证数据的一致性。由于主从复制的过程是异步复制的,因此Slave和Master之间的数据有可能存在延迟的现象,只能保证数据最终的一致性。在master和slave之间实现整个复制过程主要由三个线程来完成:
(1)Slave SQL thread线程:创建用于读取relay log中继日志并执行日志中包含的更新,位于slave端
(2)Slave I/O thread线程:读取 master 服务器Binlog Dump线程发送的内容并保存到slave服务器的relay log中继
日志中,位于slave端:
(3)Binlog dump thread线程(也称为IO线程):将bin-log二进制日志中的内容发送到slave服务器,位于master端
注意:如果一台主服务器配两台从服务器那主服务器上就会有两个Binlog dump 线程,而每个从服务器上各自有两个线程;
2、主从复制流程
(1)master服务器在执行SQL语句之后,记录在binlog二进制文件中;
(2)slave端的IO线程连接上master端,并请求从指定bin log日志文件的指定pos节点位置(或者从最开始的日志)开始复制之后的日志内容。
(3)master端在接收到来自slave端的IO线程请求后,通知负责复制进程的IO线程,根据slave端IO线程的请求信息,读取指定binlog日志指定pos节点位置之后的日志信息,然后返回给slave端的IO线程。该返回信息中除了binlog日志所包含的信息之外,还包括本次返回的信息在master端的binlog文件名以及在该binlog日志中的pos节点位置。
(4)slave端的IO线程在接收到master端IO返回的信息后,将接收到的binlog日志内容依次写入到slave端的relay log文件的最末端,并将读取到的master端的binlog文件名和pos节点位置记录到master-info文件中(该文件存slave端),以便在下一次同步的候能够告诉master从哪个位置开始进行数据同步;
(5)slave端的SQL线程在检测到relay log文件中新增内容后,就马上解析该relay log文件中的内容,然后还原成在master端真实执行的那些SQL语句,再按顺序依次执行这些SQL语句,从而到达master端和slave端的数据一致性;
3、主从复制的好处
(1)读写分离,通过动态增加从服务器来提高数据库的性能,在主服务器上执行写入和更新,在从服务器上执行读功能。
(2)提高数据安全,因为数据已复制到从服务器,从服务器可以终止复制进程,所以,可以在从服务器上备份而不破坏主服务器相应数据。
(3)在主服务器上生成实时数据,而在从服务器上分析这些数据,从而提高主服务器的性能。
4、主从部署必要条件:
从库服务器能连通主库
主库开启binlog日志(设置log-bin参数)
主从server-id不同
linux系统下主从复制的搭建测试
1.安装mysql
2.开始搭建主从复制环境
2.1主机区 修改my.cnf文件,开启bin-log日志
====================第一步,修改my.cnf开启bin-log =========================
#查询配置文件并修改开启log-bin=mysql-bin
find / -name '*my.cnf' #/usr/my.cnf
vim /usr/my.cnf
#开启二进制日志
log-bin=mysql-bin
#设置主服务器唯一标识ID
server_id=100
====================第二步,master主机重启mysq服务,查看状态,新增salve访问账户并赋权===============
#重启mysql,查看状态
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 120 | | | |
#代表文件开启
+------------------+----------+--------------+------------------+-------------------+
#在master主机192.168.95.100中创建一个192.168.95.103从机中可以访问的MySQL用户
mysql> CREATE USER '‘mysql103’'@'192.168.95.103' IDENTIFIED BY '123456';
#给用户赋权 replication slave
mysql> grant replication slave on *.* to '‘mysql103’' @'192.168.95.103' identified by '123456';
mysql> flush privileges;
====================第三步,salve主机启动mysq服务,告知二进制文件名与位置===============
#设置从服务器ID
vim /usr/my.cnf
#设置主服务器唯一标识ID
server_id=103
#进入设置主机信息
mysql> CHANGE MASTER TO
-> MASTER_HOST='192.168.95.100',
-> MASTER_USER='mysql103',
-> MASTER_PASSWORD='123456',
-> MASTER_LOG_FILE='mysql-bin.000002',
-> MASTER_LOG_POS=120;
#开启复制
mysql> start slave;
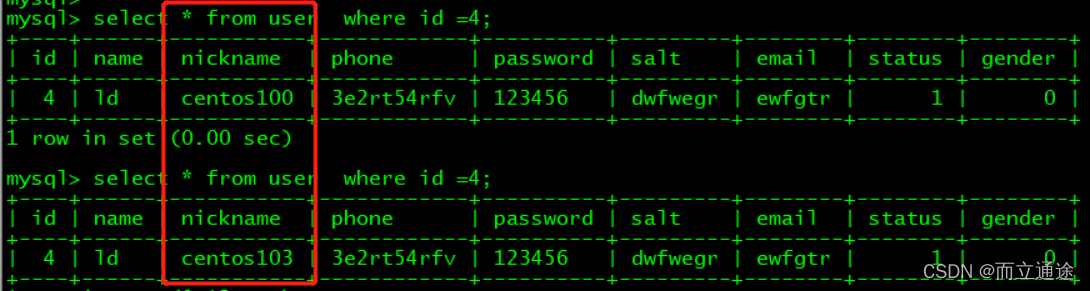
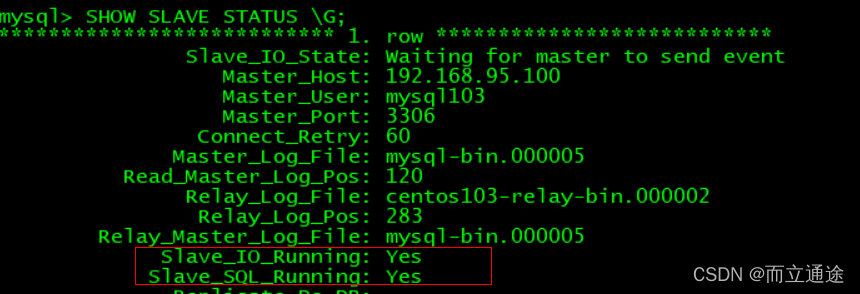
mysql>SHOW SLAVE STATUS \G; #查看主从复制是否配置成功
MySQL的主主复制:
主主模式:
主主模式=互为主备: 即 机器1是机器2的master, 机器2也是机器1的master。设置同上
读写分离落地
读写路由分配机制是实现读写分离架构最关键的一个环节,就是控制何时去主库写,何时去从库读。目前较为常见的实现方案分为以下两种:
(1)基于编程和配置实现(应用端)
程序员在代码中封装数据库的操作,代码中可以根据操作类型进行路由分配,增删改时操作主库,查询时操作从库。这类方法也是目前生产环境下应用最广泛的。优点是实现简单,因为程序在代码中实现,不需要增加额外的硬件开支,缺点是需要开发人员来实现,运维人员无从下手,如果其中一个数据库宕机了,就需要修改配置重启项目。
(2)基于服务器端代理实现(服务器端)
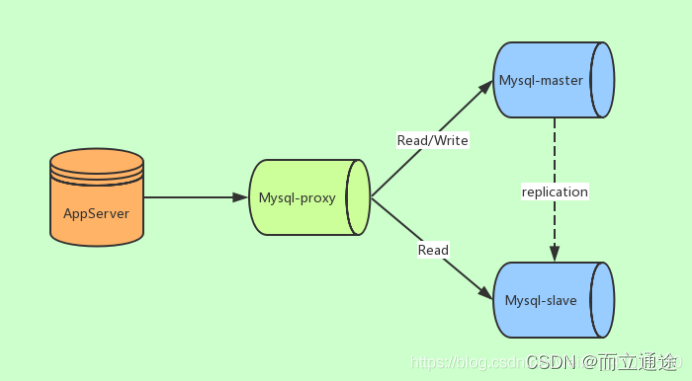
中间件代理一般介于应用服务器和数据库服务器之间,从图中可以看到,应用服务器并不直接进入到master数据库或者slave数据库,而是进入MySQL proxy代理服务器。代理服务器接收到应用服务器的请求后,先进行判断然后转发到后端master和slave数据库。
目前有很多性能不错的数据库中间件,常用的有MySQL Proxy、MyCat以及Shardingsphere等等。
MySQL Proxy:是官方提供的MySQL中间件产品可以实现负载平衡、读写分离等。
MyCat:MyCat是一款基于阿里开源产品Cobar而研发的,基于 Java 语言编写的开源数据库中间件。
ShardingSphere:ShardingSphere是一套开源的分布式数据库中间件解决方案,它由ShardingJDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。已经在2020年4月16日从Apache孵化器毕业,成为Apache顶级项目。
Atlas:Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个数据库中间件。
Amoeba:变形虫,该开源框架于2008年开始发布一款 Amoeba for MySQL软件。
二、基于一主一从的mycat
====================安装mycat===============
#解压到/usr/local/mycat目录
tar -xvf Mycat-server-1.4-release-20151019230038-linux.tar.gz -C /usr/local/
#修改配置文件 server.xml schema.xml
cd /usr/local/mycat/conf/
#修改server.xml 添加用户
<user name="mycat-test">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
#修改schema.xml 设置逻库
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="host-1" database="learn" />
<!-- dataHost标签的 balance 属性: 生产中一般1或者3,不能为2
0: 不开启读写分离
1:全部的readHost 与stand by writeHost(太子,只有一台正主写主机) 都要参与select语句的负载均衡 (至少4台,双主双从)
2:所有的select语句在writeHost、readHost 随机分发
3:所有的select语句随机分发到readHost, writeHost不参与 (主从模式)
-->
<dataHost name="host-1" maxCon="1000" minCon="10" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可以写多个主从复制的 写主机 -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- 该写主机下的多个从读机 -->
<readHost host="readM1" url="192.168.95.103:3306" user="likang"
password="123456"></readHost>
</writeHost>
<!-- <writeHost host="hostM2" url="192.168.95.102:3316" user="likang"
password="123456" /> -->
<readHost host="readS2" url="192.168.95.104:3306" user="likang" password="123456">
</readHost>
</writeHost> -->
</dataHost>
#修改开启服务
cd /usr/local/mycat/bin
./mycat console
#登录
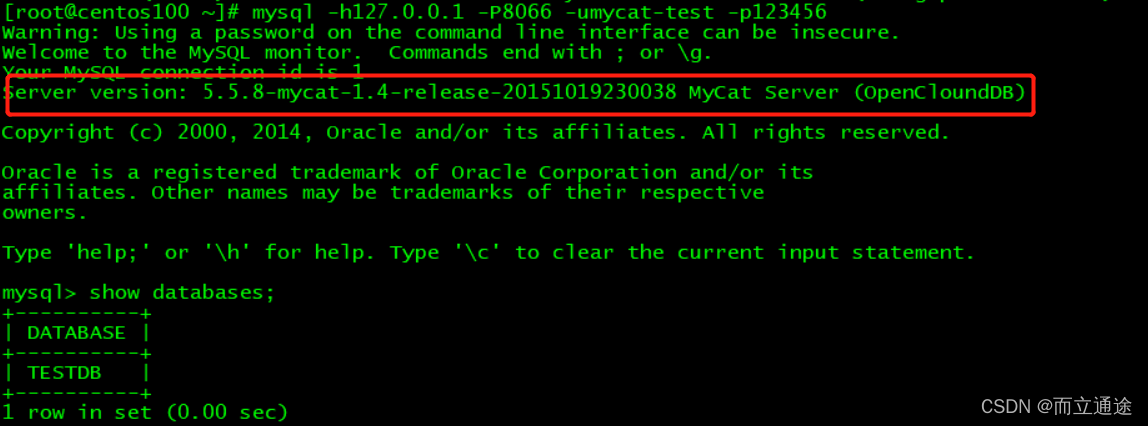
mysql -h127.0.0.1 -P8066 -umycat-test -p123456
#查看数据逻辑库
mysql> show databases;
+----------+
| DATABASE |
+----------+
| TESTDB |
+----------+
1 row in set (0.00 sec)
mysql> use TESTDB;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+-----------------+
| Tables_in_learn |
+-----------------+
| user |
+-----------------+
1 row in set (0.00 sec)
登录成功如图:
dataHost标签的 balance 属性: 生产中一般1或者3,不能为2
0: 不开启读写分离
1:全部的readHost 与stand by writeHost(太子,只有一台正主写主机) 都要参与select语句的负载均衡 (至少4台,双主双从)
2:所有的select语句在writeHost、readHost 随机分发
3:所有的select语句随机分发到readHost, writeHost不参与
效果演示: