最近为了准备找工作开始复习一些基础知识,在这里记录一下一些被遗忘的知识。
Buffer Poll 和 Change Buff
首先贴一张InnoDB的架构图:
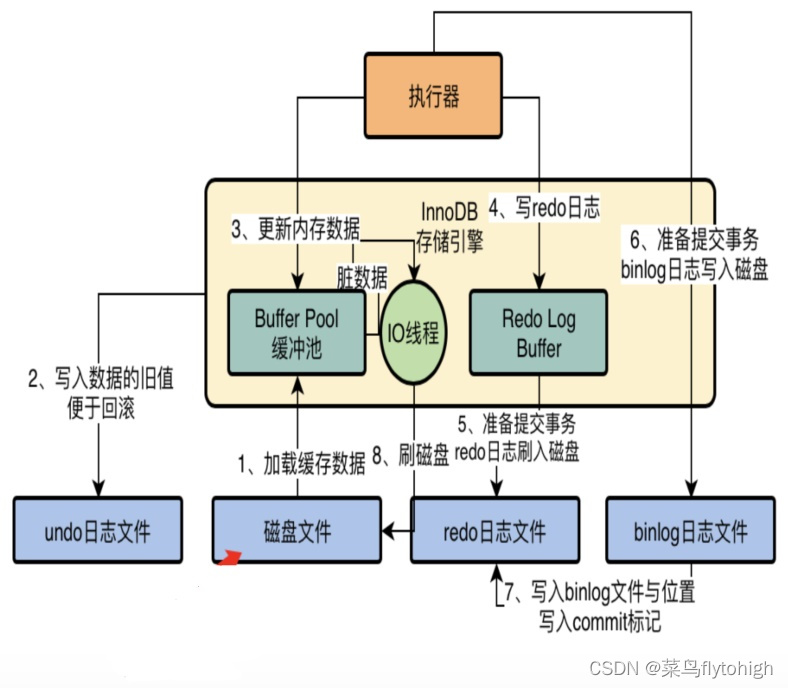
Buffer Pool是InnoDB存储引擎层的缓冲池,不属于MySQL的Server层,跟8.0删掉的“查询缓存”功能不是同一个概念,在内存中以页(page)为单位缓存磁盘数据,是一个链表的数据结构,用LRU来进行管理,减少磁盘IO,提升访问速度缓冲池大小默认128M,独立的MySQL服务器推荐设置缓冲池大小为总内存的80%。主要存储数据页、索引页更新缓冲(change buffer)等。
#查询缓冲池的大小
show variables like '%innodb_buffer_pool_size%';
Buffer Pool有一项特技叫预读,存储引擎的接口在被Server层调用时,会在响应的同时进行预判,将下次可能用到的数据和索引加载到Buffer Pool
预读策略有两种,为线性预读(linear read-ahead)和随机预读(random read-ahead),其中InnoDB默认使用线性预读,随机预读已经基本废弃
线性预读认为如果前面的请求顺序访问当前区(extent)的页,那么接下来的若干请求也会顺序访问下一个区的页,并将下一个区加载到Buffer Pool。在5.4版本以后默认开启,默认值为56,最大不能超过64,表示顺序访问N个页后触发预读(一个页16K,一个区1M,一个区最多64个页,所以最大值64)。
Change Buffer 是InnoDB在Buffer Pool中开辟了一块内存,用来存储变更记录,为了防止异常宕机丢失缓存,当事务提交时会将变更记录持久化到磁盘(redo log),等待时机更新磁盘的数据文件(刷脏),用来缓存写操作的内存,就是Change Buffer。
Change Buffer默认占Buffer Pool的25%,最大设置占用50%
show variables like '%innodb_change_buffer_max_size%'
优化慢查询思路:
分析语句,是否加载了不必要的字段/数据
分析 SQL 执行句话,是否命中索引等
如果 SQL 很复杂,优化 SQL 结构
如果表数据量太大,考虑分表
排查死锁的一般步骤是酱紫:
(1)查看死锁日志 show engine innodb status;
(2)找出死锁Sql
(3)分析sql加锁情况
(4)模拟死锁案发
(5)分析死锁日志
(6)分析死锁结果
MySQL数据库cpu飙升,要怎么处理?
1)使用top 命令观察,确定是mysqld导致还是其他原因。(2)如果是mysqld导致的,show processlist,查看session情况,确定是不是有消耗资源的sql在运行。(3)找出消耗高的 sql,看看执行计划是否准确, 索引是否缺失,数据量是否太大。
处理:
(1)kill 掉这些线程(同时观察 cpu 使用率是否下降), (2)进行相应的调整(比如说加索引、改 sql、改内存参数) (3)重新跑这些 SQL。
其他情况:
也有可能是每个 sql 消耗资源并不多,但是突然之间,有大量的 session 连进来导致 cpu 飙升,这种情况就需要跟应用一起来分析为何连接数会激增,再做出相应的调整,比如说限制连接数等。
简述如何建立出好的索引
最左前缀匹配原则。
这是非常重要、非常重要、非常重要(重要的事情说三遍)的原则,MySQL会一直向右匹配直到遇到范围查询 (>,<,BETWEEN,LIKE)就停止匹配。
尽量选择区分度高的列作为索引
区分度的公式是 COUNT(DISTINCT col)/COUNT(*)。表示字段不重复的比率,比率越大我们扫描的记录数就越少。
索引列不能参与计算,尽量保持列“干净”
比如, FROM_UNIXTIME(create_time)=‘2016-06-06’ 就不能使用索引,原因很简单,B+树中存储的都是数据表中的字段值,但是进行检索时,需要把所有元素都应用函数才能比较,显然这样的代价太大。所以语句要写成 :create_time=UNIX_TIMESTAMP(‘2016-06-06’)。
尽可能的扩展索引,不要新建立索引
比如表中已经有了a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
单个多列组合索引和多个单列索引的检索查询效果不同
因为在执行SQL时,MySQL只能使用一个索引,会从多个单列索引中选择一个限制最为严格的索引(经指正,在MySQL5.0以后的版本中,有“合并索引”的策略,翻看了《高性能MySQL 第三版》,书作者认为:还是应该建立起比较好的索引,而不应该依赖于“合并索引”这么一个策略)。
“合并索引”策略
简单来讲,就是使用多个单列索引,然后将这些结果用“union或者and”来合并起来
关于索引的一点题外话
Hash表在哪些场景比较适合?
答:等值查询的场景,就只有KV(Key,Value)的情况,例如Redis、Memcached等这些NoSQL的中间件。
答:有序数组的数据结构有什么缺点?
序的适合静态数据,因为如果我们新增、删除、修改数据的时候就会改变他的结构。比如你新增一个,那在你新增的位置后面所有的节点都会后移,成本很高。
有序数组的数据结构有什么优点?
答:可以用来做静态存储引擎啊,用来保存静态数据,例如你2019年的支付宝账单,2019年的淘宝购物记录等等都是很合适的,都是不会变动的历史数据。