
ЫцзХ 8.0 ЕФЗЂВМ,Elastic КмИпаЫФмЙЛНЋ PyTorch ЛњЦїбЇЯАФЃаЭЩЯДЋЕН Elasticsearch жа,вддк Elastic Stack жаЬсЙЉЯжДњздШЛгябдДІРэ (NLP)ЁЃ Яждк,Elasticsearch гУЛЇФмЙЛМЏГЩгУгкЙЙНЈ NLP ФЃаЭЕФзюСїааЕФИёЪНжЎвЛ,ВЂНЋетаЉФЃаЭзїЮЊ NLP Ъ§ОнЙмЕРЕФвЛВПЗжЭЈЙ§ЮвУЧЕФ Inference processor ећКЯЕН Elasticsearch жаЁЃ ЬэМг PyTorch ФЃаЭвдМАаТЕФ ANN ЫбЫї APIЕФФмСІЮЊ Elastic Enterprise Search ЬэМгСЫвЛИіШЋаТЕФЯђСП(ЫЋЙигя)ЁЃ
NLP дк Elastic Stack 7.x КЭ 8.0 жаЕФЧјБ№
Elasticsearch вЛжБЪЧНјаа NLP ЕФКУЕиЗН,ЕЋДгРњЪЗЩЯПД,ЫќашвЊдк Elasticsearch жЎЭтНјаавЛаЉДІРэ,ЛђепБраДвЛаЉЗЧГЃИДдгЕФВхМўЁЃ Ншжњ 8.0,гУЛЇЯждкПЩвддк Elasticsearch жаИќжБНгЕижДааУќУћЪЕЬхЪЖБ№ЁЂЧщИаЗжЮіЁЂЮФБОЗжРрЕШВйзїЁЊЁЊЮоашЖюЭтЕФзщМўЛђБрТыЁЃ ВЛНідк Elasticsearch жаБОЕиМЦЫуКЭДДНЈЯђСПдкЫЎЦНПЩРЉеЙадЗНУцЪЧЁАЪЄРћЁБ(ЭЈЙ§дкЗўЮёЦїМЏШКжаЗжВММЦЫу)ЁЊЁЊетвЛБфЛЏЛЙЮЊ Elasticsearch гУЛЇНкЪЁСЫДѓСПЪБМфКЭОЋСІЁЃ
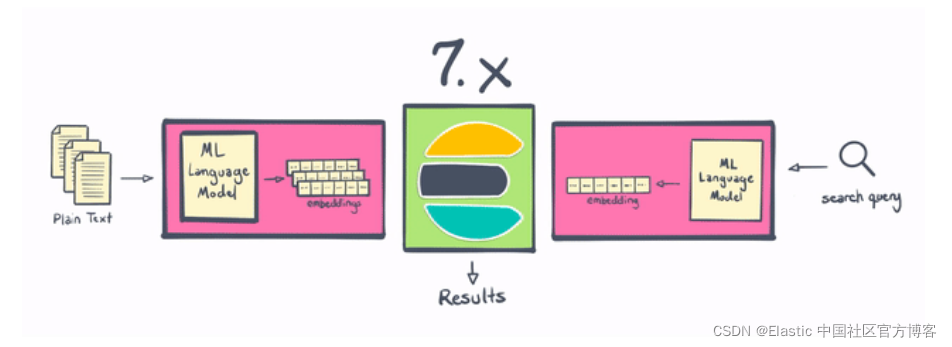
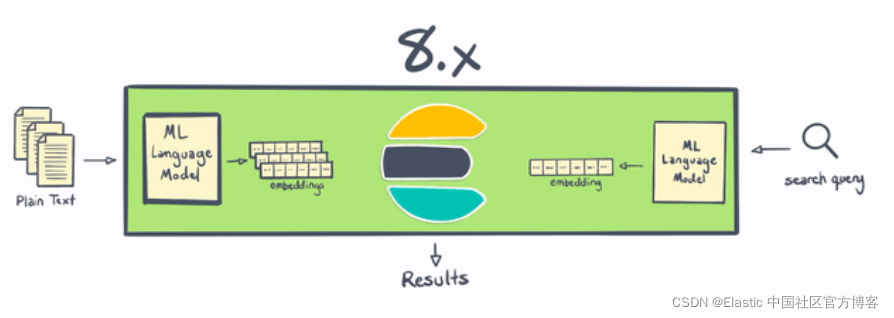
Ншжњ Elastic 8.0,гУЛЇПЩвджБНгдк Elasticsearch жаЪЙгУ PyTorch ЛњЦїбЇЯАФЃаЭ(Р§Шч BERT),ВЂдк Elasticsearch жаЪЙгУетаЉФЃаЭНјааЭЦРэЁЃ етаЉФЃаЭПЩвдЪЧФуздМКЕФздЖЈвхФЃаЭ,вВПЩвдЪЧдк Hugging Face ЕШДцДЂПтжаЗЂВМЕНЩчЧјЕФФЃаЭЁЃ
?ЭЈЙ§ЪЙгУЛЇФмЙЛжБНгдк Elasticsearch жажДааЭЦРэ,НЋЯжДњ NLP ЕФЧПДѓЙІФмМЏГЩЕНЫбЫїгІгУГЬађКЭЬхбщ(ЯыЯы:ЮоашБрТы)ЁЂБОжЪЩЯИќИпаЇ(ЕУвцгк Elasticsearch ЕФЗжВМЪНМЦЫуФмСІ)КЭ NLP БОЩэБШвдЭљШЮКЮЪБКђЖМИќШнвз БфЕУИќПь,вђЮЊФуВЛашвЊНЋЪ§ОнвЦГіЕНЕЅЖРЕФНјГЬЛђЯЕЭГжаЁЃ
ЪВУДЪЧздШЛгябдДІРэ?
NLP ЪЧжИЮвУЧПЩвдЪЙгУШэМўРДВйзїКЭРэНтПкгяЛђЪщУцЮФБОЛђздШЛгябдЕФЗНЪНЁЃ 2018 Фъ,Google ПЊдДСЫвЛжжгУгк NLP дЄбЕСЗЕФаТММЪѕ,ГЦЮЊРДзд Transformers ЕФЫЋЯђБрТыЦїГЪЯж,Лђ BERTЁЃ BERT ЭЈЙ§дкУЛгаШЮКЮШЫЙЄВЮгыЕФЧщПіЯТЖдЛЅСЊЭјДѓаЁЕФЪ§ОнМЏ(Р§Шч,ЯыЯыЫљгаЕФЮЌЛљАйПЦКЭЪ§зжЪщМЎ)НјаабЕСЗРДРћгУ ЁАtransfer learningЁБЁЃ
Transfer learning дЪаэЖд BERT ФЃаЭНјаадЄбЕСЗвдНјааЭЈгУгябдРэНтЁЃвЛЕЉФЃаЭжЛОЙ§вЛДЮдЄбЕСЗ,ЫќОЭПЩвдБЛжигУВЂеыЖдИќОпЬхЕФШЮЮёНјааЮЂЕї,вдСЫНтгябдЕФЪЙгУЗНЪНЁЃ
ЮЊСЫжЇГжРр BERT ФЃаЭ(ЪЙгУгы BERT ЯрЭЌЕФБъМЧЦїЕФФЃаЭ),Elasticsearch НЋЪзЯШЭЈЙ§ PyTorch ФЃаЭжЇГжжЇГжДѓЖрЪ§зюГЃМћЕФ NLP ШЮЮёЁЃ PyTorch ЪЧзюЪмЛЖгЕФЯжДњЛњЦїбЇЯАПтжЎвЛ,гЕгаДѓСПЛюдОгУЛЇ,ЫќЪЧвЛИіжЇГжЩюЖШЩёОЭјТчЕФПт,Р§Шч BERT ЪЙгУЕФ Transformer МмЙЙЁЃ
вдЯТЪЧвЛаЉЪОР§ NLP ШЮЮё:
- ЧщаїЗжЮі:гУгкЪЖБ№е§УцгыИКУцГТЪіЕФЖўдЊЗжРр
- УќУћЪЕЬхЪЖБ№ (NER):ДгЗЧНсЙЙЛЏЮФБОЙЙНЈНсЙЙ,ГЂЪдЬсШЁУћГЦЁЂЮЛжУЛђзщжЏЕШЯИНк
- ЮФБОЗжРр:СубљБОЗжРрдЪаэФуИљОнФубЁдёЕФРрЖдЮФБОНјааЗжРр,ЖјЮоашНјаадЄбЕСЗЁЃ
- ЮФБОЧЖШы:гУгк k НќСк (kNN) ЫбЫї
Elastic Stack NLP ФмзіЪВУД?
Elastic Stack NLP 1_пйСЈпйСЈ_bilibili
Elasticsearch жаЕФздШЛгябдДІРэ
дкНЋ NLP ФЃаЭМЏГЩЕН Elastic ЦНЬЈЪБ,ЮвУЧЯЃЭћЮЊЩЯДЋКЭЙмРэФЃаЭЬсЙЉГіЩЋЕФгУЛЇЬхбщЁЃЪЙгУгУгкЩЯДЋ PyTorch ФЃаЭЕФ Eland ПЭЛЇЖЫКЭгУгкЙмРэ Elasticsearch МЏШКЩЯФЃаЭЕФ Kibana ЕФ ML ФЃаЭЙмРэгУЛЇНчУц,гУЛЇПЩвдГЂЪдВЛЭЌЕФФЃаЭВЂКмКУЕиСЫНтЫќУЧдкЪ§ОнЩЯЕФБэЯжЁЃЮвУЧЛЙЯЃЭћЪЙЦфПЩПчМЏШКжаЕФЖрИіПЩгУНкЕуНјааРЉеЙ,ВЂЬсЙЉСМКУЕФЭЦРэЭЬЭТСПадФмЁЃ
Elastic Stack NLP ЙЄзїСїГЬ
Elastic Stack NLP 2_пйСЈпйСЈ_bilibili
ЮЊСЫЪЙетвЛЧаГЩЮЊПЩФм,ЮвУЧашвЊвЛИіЛњЦїбЇЯАПтРДжДааЭЦРэЁЃдк Elasticsearch жаЬэМгЖд PyTorch ЕФжЇГжашвЊЪЙгУдЩњПт libtorch,ЫќжЇГж PyTorch,ВЂЧвНіжЇГжвбЕМГіЛђБЃДцЮЊ TorchScript БэЪОЕФ PyTorch ФЃаЭЁЃетЪЧ libtorch ашвЊЕФФЃаЭЕФБэЪО,ЫќНЋдЪаэ Elasticsearch БмУтдЫаа Python НтЪЭЦїЁЃ
ЭЈЙ§гыдк PyTorch ФЃаЭжаЙЙНЈ NLP ФЃаЭЕФзюСїааЕФИёЪНжЎвЛМЏГЩ,Elasticsearch ПЩвдЬсЙЉвЛИіЦНЬЈ,ИУЦНЬЈПЩДІРэДѓСП NLP ШЮЮёКЭгУР§ЁЃаэЖргХауЕФПтПЩгУгкбЕСЗ NLP ФЃаЭ,вђДЫЮвУЧднЪБНЋЦфСєИјЦфЫћЙЄОпЁЃЮоТлФуЪЧЪЙгУ PyTorch NLPЁЂHugging Face Transformers ЛЙЪЧ Facebook ЕФ fairseq ЕШПтРДбЕСЗФЃаЭ,ФуЖМПЩвдНЋФЃаЭЕМШы Elasticsearch ВЂЖдетаЉФЃаЭНјааЭЦРэЁЃ Elasticsearch ЭЦРэзюГѕНЋНідкЩуШЁЪБНјаа,ЮДРДЛЙПЩвдРЉеЙвддкВщбЏЪБв§ШыЭЦРэЁЃ
ЕНФПЧАЮЊжЙ,вбОгавЛаЉЗНЗЈПЩвдЭЈЙ§ API ЕїгУКЭВхМўвдМАЦфЫћбЁЯюНЋ NLP ФЃаЭМЏГЩЕН Elasticsearch КЭ Elasticsearch жЎМфЁЃЕЋЪЧЭЈЙ§дкФуЕФ Elasticsearch Ъ§ОнЙмЕРжаМЏГЩ NLP ФЃаЭ,ФуПЩвдЛёЕУвдЯТКУДІ:
- ЮЇШЦФуЕФ NLP ФЃаЭЙЙНЈИќКУЕФЛљДЁМмЙЙ
- РЉеЙФуЕФ NLP ФЃаЭЭЦРэ
- ЮЌЛЄФуЕФЪ§ОнАВШЋКЭвўЫН
NLP ФЃаЭПЩвдМЏжаЙмРэ,ВЂЧвПЩвдаЕїМгдиКЭЗжЗЂетаЉФЃаЭЁЃ
Жд PyTorch ФЃаЭЕФЭЦРэЕїгУПЩвдЗжВМдкМЏШКжмЮЇ,ВЂЧвПЩвддЪаэгУЛЇдкЮДРДИљОнИКдиНјааРЉеЙЁЃЭЈЙ§ВЛвЦЖЏЪ§ОнВЂеыЖдЛљгк CPU ЕФЭЦРэгХЛЏдЦащФтЛњ,ПЩвдЬсИпадФмЁЃЭЈЙ§дк Elasticsearch жаећКЯ NLP ФЃаЭ,ЮвУЧПЩвдНЋЪ§ОнБЃДцдквЛИіећЬхМЏжаЁЂАВШЋЕФЭјТчжа,ЭЌЪБПМТЧЕНЪ§ОнвўЫНКЭКЯЙцадЁЃЭЈгУЛљДЁЩшЪЉЁЂВщбЏадФмКЭЪ§ОнвўЫНЖМПЩвдЭЈЙ§дк Elasticsearch жаећКЯ NLP ФЃаЭЕУЕНдіЧПЁЃ
еЙЪО
дкНгЯТРДЕФЛЗНкжа,ЮвУЧНЋЪЙгУвЛИіМђЕЅЕФР§згРДеЙЪОШчКЮЪЙгУ Elastic NLPЁЃШчЙћвЊдкМЏШКжажДааздШЛгябдДІРэШЮЮё,дђБиаыВПЪ№ЪЪЕБЕФбЕСЗФЃаЭЁЃ Eland КЭ Kibana ЬсЙЉЙЄОпжЇГж,ПЩАяжњФузМБИКЭЙмРэФЃаЭЁЃ
бЁдёвЛИібЕСЗКУЕФФЃаЭБрМ
ИљОнИХЪі,ФуПЩвдЭЈЙ§ЖржжЗНЪНдк Elastic Stack жаЪЙгУ NLP ЙІФмЁЃ дкШЗЖЈвЊжДааФФжжРраЭЕФ NLP ШЮЮёКѓ,ФуБиаыбЁдёКЯЪЪЕФбЕСЗФЃаЭЁЃ
зюМђЕЅЕФЗНЗЈЪЧЪЙгУвбОеыЖдФувЊжДааЕФЗжЮіРраЭНјааСЫЮЂЕїЕФФЃаЭЁЃ Р§Шч,Hugging Face ЩЯгаПЩгУгкЬиЖЈ NLP ШЮЮёЕФФЃаЭКЭЪ§ОнМЏЁЃ етаЉЫЕУїМйЖЈФуе§дкЪЙгУЦфжавЛжжФЃаЭ,ВЂЧвВЛУшЪіШчКЮДДНЈаТФЃаЭЁЃ гаЙижЇГжЕФФЃаЭМмЙЙЕФЕБЧАСаБэ,ЧыВЮдФЕкШ§ЗН NLP ФЃаЭЁЃ
ШчЙћФубЁдёЪЙгУМЏШКжаЬсЙЉЕФ lang_ident_model_1 жДаагябдЪЖБ№,дђВЛашвЊНјвЛВНЕФВНжшРДЕМШыЛђВПЪ№ФЃаЭЁЃ ФуПЩвдЬјЕНдкЩуШЁЙмЕРжаЪЙгУФЃаЭЁЃ
ЕМШыбЕСЗКУЕФФЃаЭКЭДЪЛу
бЁдёФЃаЭКѓ,ФуБиаыНЋЦфМАЦфБъМЧЦїДЪЛуБэЕМШыМЏШКЁЃ ЕМШыФЃаЭЪБ,гЩгкЦфДѓаЁ,БиаыНЋЦфЗжПщВЂвЛДЮЕМШывЛИіПщ,вдБуЗжЖЮДцДЂЁЃ
ОЙ§бЕСЗЕФФЃаЭБиаыВЩгУ TorchScript БэЪО,ВХФмгы Elastic Stack ЛњЦїбЇЯАЙІФмвЛЦ№ЪЙгУЁЃ
Eland НЋ Hugging Face зЊЛЛЦїФЃаЭЕНЦф TorchScript БэЪОЕФзЊЛЛКЭЗжПщЙ§ГЬЗтзАдквЛИі Python ЗНЗЈжа; вђДЫ,етЪЧЭЦМіЕФЕМШыЗНЗЈЁЃ
- АВзА Eland Python ПЭЛЇЖЫЁЃ
- дЫаа eland_import_hub_model НХБОЁЃ Р§Шч:
eland_import_hub_model --url <clusterUrl> \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner - жИЖЈ URL вдЗУЮЪФуЕФМЏШКЁЃ Р§Шч,https://<user>:<password>@<hostname>:<port>ЁЃ
- дк Hugging Face ФЃаЭжааФжажИЖЈФЃаЭЕФБъЪЖЗћЁЃ
- жИЖЈ NLP ШЮЮёЕФРраЭЁЃ жЇГжЕФжЕЮЊ fill_maskЁЂnerЁЂtext_classificationЁЂtext_embedding КЭ zero_shot_classificationЁЃ
ШчЙћФуЛЙУЛгаАВзАКУздМКЕФ Elastic Stack 8.0,ЧыВЮПМЮвжЎЧАЕФЮФеТ ЁАElastic Stack 8.0 АВзА - БЃЛЄФуЕФ Elastic Stack ЯждкБШвдЭљШЮКЮЪБКђЖММђЕЅЁБЁЃдкНјааЯТУцЕФВйзїжЎЧА,ЮвУЧБиаыЦєЖЏАзН№АцЪдгУ:
?ШчЙћЮвУЧЕФ Elasticsearch ЮЛгк https://192.168.0.3:9200,ФЧУДЮвУЧПЩвдЪЙгУШчЯТЕФУќСюРДжДаа:
python -m pip install elandgit clone https://github.com/elastic/elandЮвУЧНјШыЕНЯТдиЕФДњТыИљФПТМжаЁЃШчЙћФуВПЪ№ЕФ Elasticsearch МЏШКВЛЪЧЪЙгУздЧЉУћЕФ,ФЧУДвЛЯТЕФВНжшФужБНгЬјЙ§ЁЃеыЖдздЧЉУћМЏШК,ФуашвЊаоИФШчЯТЕФЮФМў:
eland/bin/eland_import_hub_model
дк?def main(): ЕФЯТУцЕФЮЛжУ:

дкЩЯУц,ЮвУЧЬэМг verify_certs ЮЊ False,вдМАЩшжУ http_authЁЃдк??http_auth РяЩшжУГЌМЖгУЛЇ elastic ЕФгУЛЇУћМАУмТыЁЃ
ЮвУЧЪЙгУШчЯТЕФУќСюРДДДНЈ docker image:
docker build -t elastic/eland .
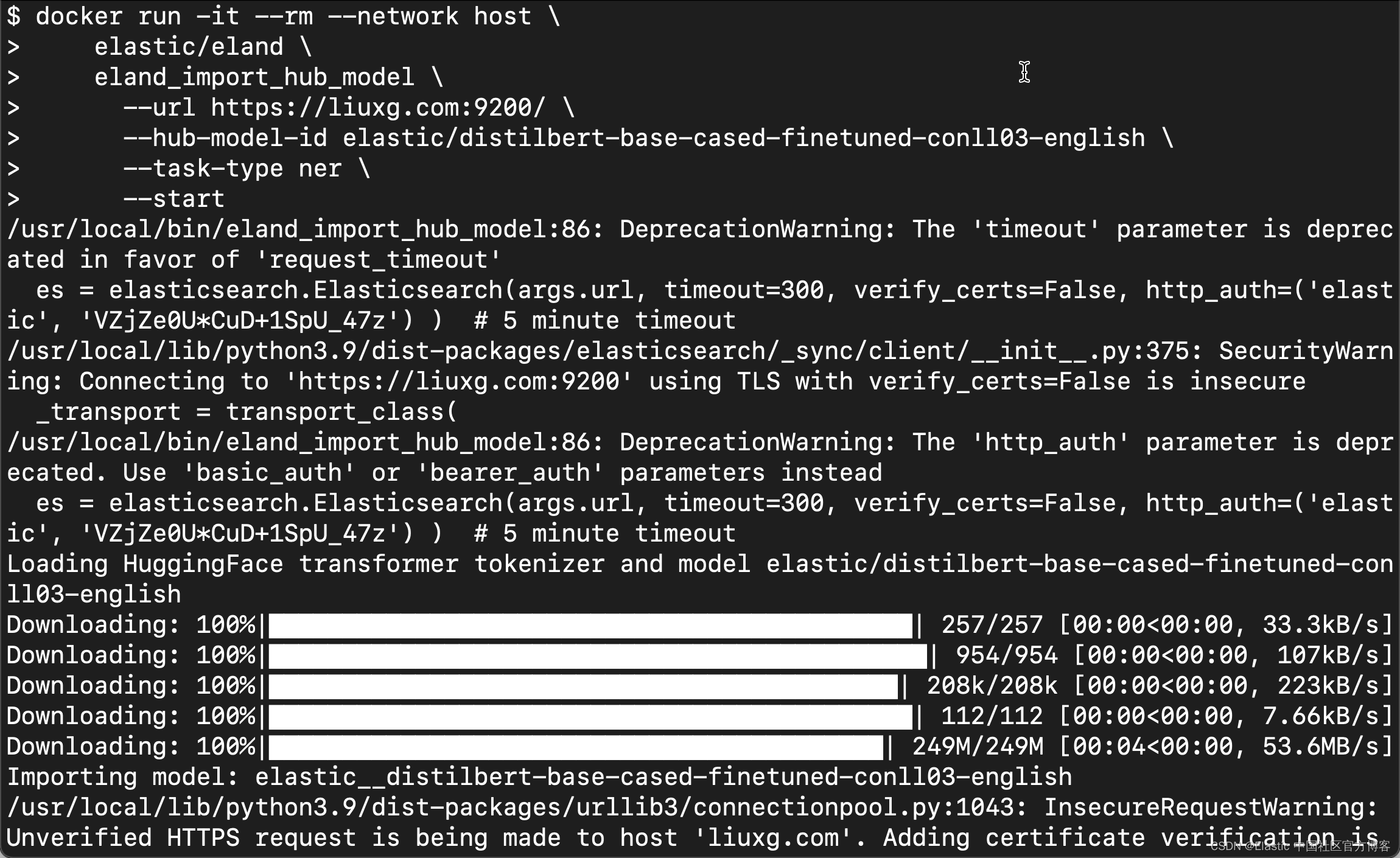
ЮвУЧНгзХЪЙгУШчЯТЕФЗНЗЈРДЩЯДЋФЃаЭ:
docker run -it --rm --network host \
elastic/eland \
eland_import_hub_model \
--url https://liuxg.com:9200/ \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner \
--startдкетРя,ЧызЂвтЮвУЧБиаыЪЙгУЕБЧАЕчФдЕФ hostname,ЗёдђЮвУЧНЋНЈСЂВЛЦ№РДСЌНгЁЃдкЮвЕФЕчФдЩЯ:
$ ping liuxg.com
PING liuxg.com (192.168.0.3): 56 data bytes
64 bytes from 192.168.0.3: icmp_seq=0 ttl=64 time=0.076 ms
64 bytes from 192.168.0.3: icmp_seq=1 ttl=64 time=0.268 msЮвУЧашвЊдк /etc/hosts РяНјааЩшжУЁЃ
дЫааЩЯУцЕФУќСю:
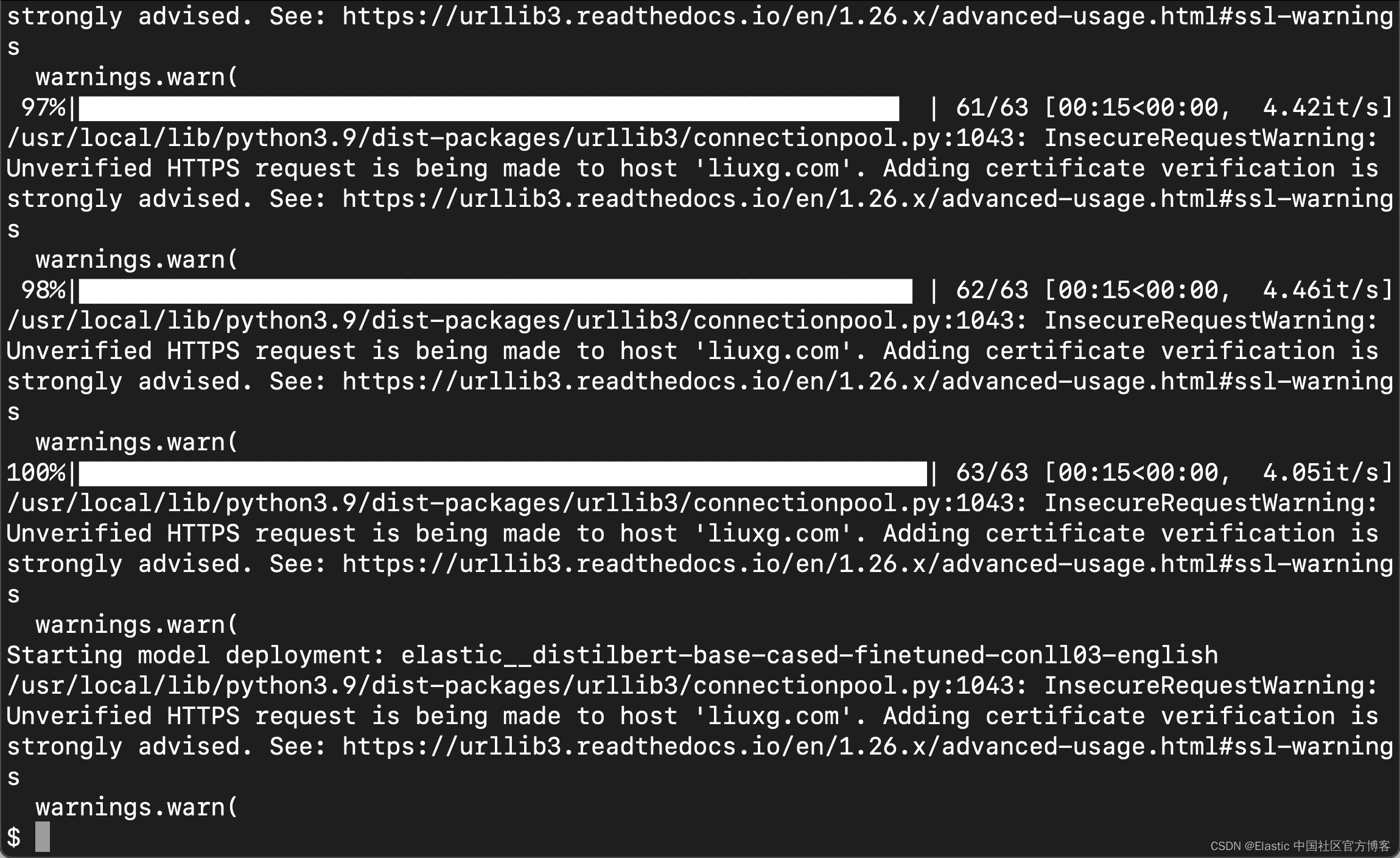
ЕШЩЯЪіЕФУќСюЭъГЩКѓ,ЮвУЧдк Kinana жаНјааВщПД:

ДгЩЯУцЕФНчУцжа,ЮвУЧПЩвдПДГівЛИіаТдѕНВЕФФЃаЭЁЃЯждкЮвУЧвбОГЩЙІЕиАбФЃаЭЩЯДЋЕН Elasticsearch жаЁЃ
ВтЪдФЃаЭ
ЕБФЃаЭВПЪ№дкМЏШКжаЕФжСЩйвЛИіНкЕуЩЯЪБ,ФуОЭПЩвдПЊЪМжДааЭЦРэСЫЁЃ ЭЦРэЪЧвЛжжЛњЦїбЇЯАЙІФм,ПЩШУФуЪЙгУОЙ§бЕСЗЕФФЃаЭЖдДЋШыЪ§ОнжДаа NLP ШЮЮё(Р§ШчЮФБОЬсШЁЁЂЗжРрЛђЧЖШы)ЁЃ
еыЖдаТЪ§ОнВтЪдФЃаЭЕФзюМђЕЅЗНЗЈЪЧЪЙгУЭЦРэбЕСЗФЃаЭВПЪ№ APIЁЃЛЙМЧЕУЮвУЧжЎЧАдкЦєЖЏ docker ЪБгавЛИібЁЯюЮЊ ner,вВМДУќУћЪЕЬхЪЖБ№ЁЃ?Р§Шч,вЊГЂЪдУќУћЪЕЬхЪЖБ№ШЮЮё,ЧыЬсЙЉвЛаЉЪОР§ЮФБО:
POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/deployment/_infer
{
"docs": {
"text_field": "Sasha bought 300 shares of Acme Corp in 2022."
}
}ЩЯУцЕФУќСюЗЕЛиЕФНсЙћЮЊ:
{
"predicted_value" : "[Sasha](PER&Sasha) bought 300 shares of [Acme Corp](ORG&Acme+Corp) in 2022.",
"entities" : [
{
"entity" : "Sasha",
"class_name" : "PER",
"class_probability" : 0.9953193610539933,
"start_pos" : 0,
"end_pos" : 5
},
{
"entity" : "Acme Corp",
"class_name" : "ORG",
"class_probability" : 0.9996392196076958,
"start_pos" : 27,
"end_pos" : 36
}
]
}ДгЩЯУцЕФЗЕЛиНсЙћжа,ЮвУЧПЩвдПДГіРДга 99.5% ЕФПЩФмадХаЖЈ?Sasha ЪЧвЛИіШЫУћ,Жјга 99.96% ЕФПЩФмадХаЖЈ?Acme Corp ЮЊвЛИі ORG,МДвЛИіЙЋЫОЛђзщжЏЁЃ
ЮвУЧРДГЂЪдСэЭтвЛИіР§зг:
POST /_ml/trained_models/elastic__distilbert-base-cased-finetuned-conll03-english/deployment/_infer
{
"docs": {
"text_field": "Xiaoguo said that Elastic was a great company in the world"
}
}ЩЯУцЗЕЛиЕФНсЙћЮЊ:
{
"predicted_value" : "[Xiaoguo](PER&Xiaoguo) said that [Elastic](ORG&Elastic) was a great company in the world",
"entities" : [
{
"entity" : "Xiaoguo",
"class_name" : "PER",
"class_probability" : 0.9977009282482645,
"start_pos" : 0,
"end_pos" : 7
},
{
"entity" : "Elastic",
"class_name" : "ORG",
"class_probability" : 0.9954152045770668,
"start_pos" : 18,
"end_pos" : 25
}
]
}АДееЭЌбљЕФЗНЗЈ,ЮвУЧГЂЪд?fill_mask:
docker run -it --rm --network host \
elastic/eland \
eland_import_hub_model \
--url https://liuxg.com:9200/ \
--hub-model-id bert-base-uncased \
--task-type fill_mask \
--start 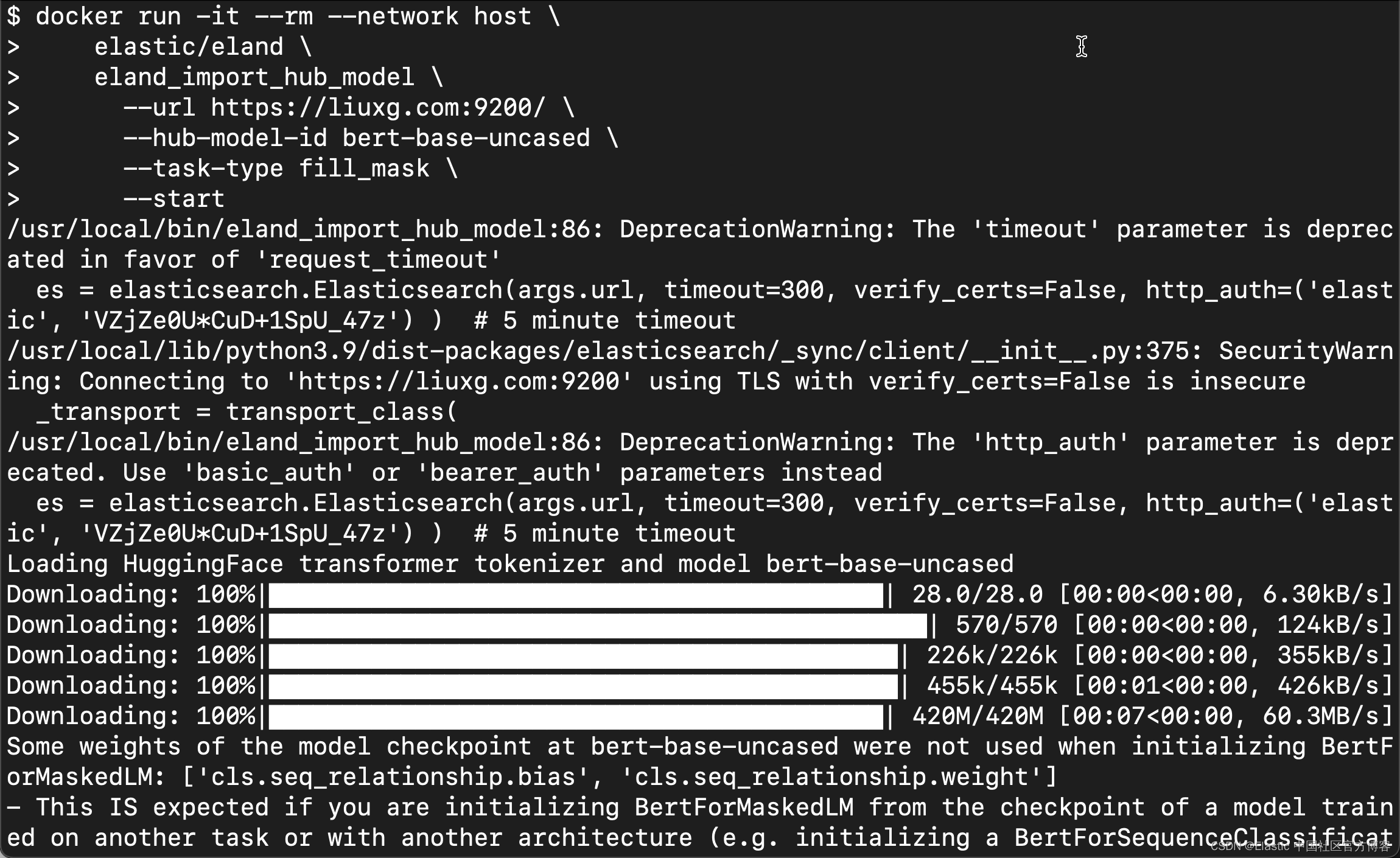
?ЮвУЧдкЛњЦїбЇЯАЕФНчУцПДЕН:

ЮвУЧдк Kibana жаЪЙгУШчЯТЕФВтЪд:
POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Paris is the [MASK] of France"
}
}?ЩЯУцЕФВщбЏЗЕЛиНсЙћ:
{
"predicted_value" : "capital",
"prediction_probability" : 0.9975749159388136,
"predicted_value_sequence" : "Paris is the capital of France"
}ЮвУЧдйзівЛИіВтЪд:
POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Amsterdam is a city in the [MASK]"
}
}ЩЯУцЕФВщбЏЗЕЛиЕФНсЙћЮЊ:
POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Beijing is the [MASK] of China"
}
}{
"predicted_value" : "capital",
"prediction_probability" : 0.9989096738963879,
"predicted_value_sequence" : "Beijing is the capital of China"
}POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Beijing is the capital of [MASK]."
}
}ЗЕЛи:
{
"predicted_value" : "china",
"prediction_probability" : 0.9913708584213007,
"predicted_value_sequence" : "Beijing is the capital of china."
}ЧызЂвт [MASK] КѓУцЕФФЧИіЕуЁЃЫќЗЧГЃживЊ,ЗёдђФуПЩФмЕУВЛЕНФуЯывЊЕФНсЙћЁЃ
POST /_ml/trained_models/bert-base-uncased/deployment/_infer
{
"docs": {
"text_field": "Amsterdam is a city in the [MASK]."
}
}{
"predicted_value" : "netherlands",
"prediction_probability" : 0.9997222917917266,
"predicted_value_sequence" : "Amsterdam is a city in the netherlands."
}