前言:在利用mongodb进行消息记录存储中有一个相对棘手的问题那就是消息记录日历卡数据如何存。作为存储设计者肯定是希望日历数据能和消息记录存在一起,而不是额外引入一个db或者额外引入一张表。这里所说的日历卡大致如下,就使用体验来说如果发生过聊天就高亮可点击、否则就置灰。

1、整体思路
????????毋庸置疑,消息记录肯定是需要一张专门的表来存的。我们希望日历数据就在这张表的基础上加一个字段(如下表中的day)就能支持,而不是在引入一张表甚至引入其他数据库。关于消息记录的存储就简单理解如下模型即可。
| account1 | |
| account2 | |
| time | |
| dir | |
| msg | |
| day | ?? |
消息记录日历卡思路。
????????思路一:一个自然而然的想法就是对每条消息都带上day字段,用于记录这条消息的天时间戳;当需要的时候限定一个月起止时间的消息进行进行聚合或者distinct操作,即可得到一个月的去重day数据。
????????思路二:我们知道一个账号对一天可能收发很多消息,每条消息都带上day字段其实很没有必要;对思路一进行优化即每个账号对之间每天仅需要一条消息带上day字段记录天时间戳即可。更精确的就认为是每天的第一条数据带上即可。注:至于实现也很简单写消息记录的时候利用下redis缓存,确保每天只有第一条消息带day字段。
? ? ? ? 我们接下来做的事情就是验证distinct能够胜任方案二的拉取功能;以及索引对distinct的影响。
注:我们这里的消息记录日历卡不考虑消息撤回,因为我们业务场景的撤回并不是真正的撤回;对于真正会有消息撤回的场景需要考虑这个问题。
2、造数据脚本
如下为制造测试数据的脚本。
account1的取值范围为 2852000000 ~ 2852000099
account2的取值范围为 726045513175435_0 ~ 726045513175435_99
天时间戳的取值范围为 19000 ~ 19000 + 100
约定考察为期100天的数据;其中每天每个账号对发送100条消息;每条的第一条消息存改天的天时间戳;100条消息的发送间隔是10s一条,依照此频率凌晨就开始发。
?
account1_beg = 2852000000
account1_num = 100
account2_prefix = "726045513175435"
account2_end = 100
day_init = 19000
day_num = 100
day_msg_num = 100
for (var acc1 = account1_beg; acc1 < account1_beg+account1_num; acc1++){
var docs = [];
for (var acc2_index = 0; acc2_index < account2_end; acc2_index++){
account1 = acc1.toString();
account2 = account2_prefix + "_" + acc2_index.toString()
for (var day = day_init; day < day_num + day_init; day ++){
for (var msg_num = 0 ; msg_num < day_msg_num; msg_num++){
time_sec = (86400 * day + 10 * msg_num);
time_usec = time_sec * 1000000;
subkey = time_sec.toString() + "_" + msg_num.toString();
if (msg_num == 0){
docs.push({sacc:account1,bacc:account2,time:time_usec,subkey:subkey,day:day})
}else{
docs.push({sacc:account1,bacc:account2,time:time_usec,subkey:subkey})
}
}
}
}
db.coll0.save(docs)
print("finish ",account1)
}
-------------------------------------------------------------
当然想让各个字段更贴近真实场景的话可以把其他和索引无关的字段也补齐,如下:
-------------------------------------------------------------
account1_beg = 2852000000
account1_num = 10
account2_prefix = "726045513175435"
account2_end = 10
day_init = 19000
day_num = 100
day_msg_num = 100
types = "{\"class\":3,\"type\":1}\n"
msg = "CpYBEpMBCpABCo0B5a+55LiN6LW377yM5oiR5LiN5aSq5piO55m95oKo55qE5oSP5oCdfiDmgqjlj6/ku6Xlj5HpgIHmloflrZfigJzovazkurrlt6XigJ3ovazmjqXoh7Pkurrlt6XlrqLmnI3vvIzkurrlt6XlrqLmiLflnKjnur/ml7bpl7TvvJowOTowMCAtIDIxOjAw"
cont = "对不起,我不太明白您的意思~ 您可以发送文字“转人工”转接至人工客服,人工客户在线时间:09:00 - 21:00"
dir = 1
bkf = 0
skf = 2852199668
sort = 1
chan = 4
for (var acc1 = account1_beg; acc1 < account1_beg+account1_num; acc1++){
for (var acc2_index = 0; acc2_index < account2_end; acc2_index++){
var docs = [];
account1 = acc1.toString();
account2 = account2_prefix + "_" + acc2_index.toString()
for (var day = day_init; day < day_num + day_init; day ++){
for (var msg_num = 0 ; msg_num < day_msg_num; msg_num++){
time_sec = (86400 * day + 10 * msg_num);
time_usec = time_sec * 1000000;
subkey = time_sec.toString() + "_" + msg_num.toString();
if (msg_num == 0){
docs.push({sacc:account1,bacc:account2,time:time_usec,subkey:subkey,types:types,msg:msg,cont:cont,dir:dir,bkf:bkf,skf:skf,sort:sort,chan:chan,day:day})
}else{
docs.push({sacc:account1,bacc:account2,time:time_usec,subkey:subkey,types:types,msg:msg,cont:cont,dir:dir,bkf:bkf,skf:skf,sort:sort,chan:chan})
}
}
}
db.coll1.save(docs)
print("finish ",account1," ",account2)
}
}
3、验证指令及distinct操作
将上述脚本二的acc1和acc2数量分别调成10插入即100万条数据。对于每个固定的账号对数据组成和前面描述的完全一致。
(1)默认没有索引的执行情况
#2022-01-08 08:00:00 1641600000
#2022-02-01 08:00:00 1643673600
db.coll1.distinct("day",{"$and":[{time:{$gt:1641600000000000}},{time:{$lt:1643673600000000}},{sacc:"2852000005"},{bacc:"726045513175435_2"}]})
db.coll1.explain("executionStats").distinct("day",{"$and":[{time:{$gt:1641600000000000}},{time:{$lt:1643673600000000}},{sacc:"2852000005"},{bacc:"726045513175435_2"}]})
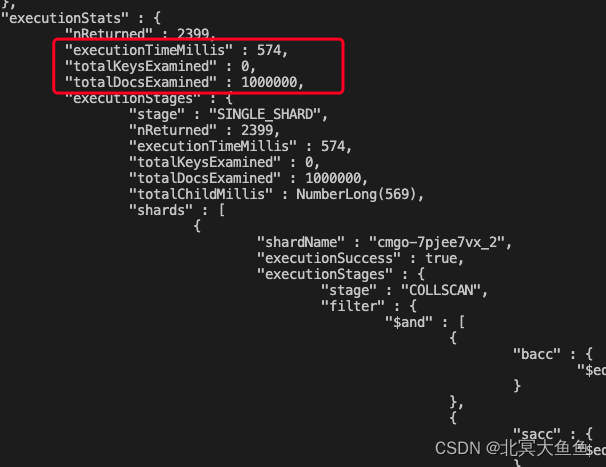
数据结果如下左图完全符合预期,但是能够感觉到明显的延迟。
执行explain可以看到其执行过程如下右图。即mongodb遍历了所有的100万条数据整个过程耗时574ms,显然这个性能是无法接受的。
 ?
?
(2) 接下来尝试对数据集建立索引然后看看执行效果。索引该怎么建呢??
思路一:建立{sacc:1,bacc:1,time:1}的索引 ―― 预计遍历的数据会降低至一个账号对的目标时间范围内的数据,而不再是全部的100万条数据了。
db.coll1.createIndex({sacc:1,bacc:1,time:1})
db.coll1.distinct("day",{"$and":[{time:{$gt:1641600000000000}},{time:{$lt:1643673600000000}},{sacc:"2852000005"},{bacc:"726045513175435_2"}]})
db.coll1.explain("executionStats").distinct("day",{"$and":[{time:{$gte:1641600000000000}},{time:{$lte:1643673600000000}},{sacc:"2852000005"},{bacc:"726045513175435_2"}]})
?效果如下:完全符合预期。一个账号对一条100条消息,这里总共有24天;所以有2400条消息。
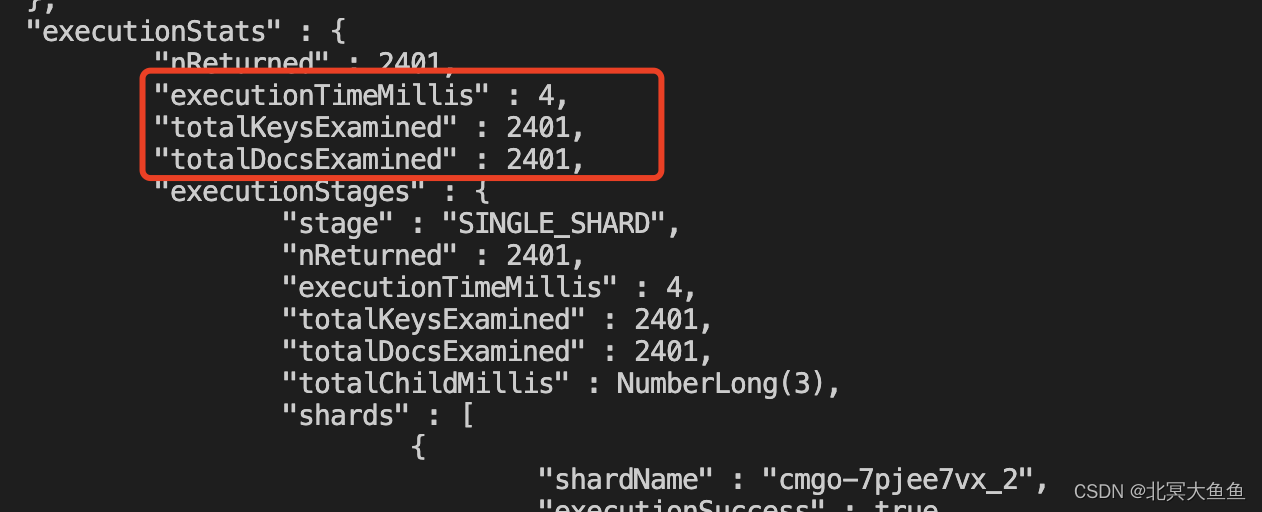
?
思路二:在上一步的基础上再加一个day字段看看会不会有更好的效果,即建立{sacc:1,bacc:1,time:1,day:1}的索引;或者{sacc:1,bacc:1,day:1}看看效果。
#删除前面建的index
db.coll1.dropIndex("sacc_1_bacc_1_time_1")
#建立包含day字段的索引
db.coll1.createIndex({sacc:1,bacc:1,time:1,day:1})
效果如下。看起来好像有效果,因为在仅有{sacc:1,bacc:1,time:1,day:1}的情况下确实也命中这个索引了。但总体感觉还是对目标数据的遍历,这一点没有任何改变;既然这样的话也就意义不大了。

另外也验证下仅有?{sacc:1,bacc:1,day:1}索引。不出意外的话就是在所有满足sacc和bacc的数据里面遍历。
#删除前面建的index
db.coll1.dropIndex("sacc_1_bacc_1_time_1_day_1")
#建立包含day字段的索引
db.coll1.createIndex({sacc:1,bacc:1,day:1})?效果如下,完全符合预期。10000就是一个账号对的全部数据量。

?
三、结论
对被distinct的字段建立索引是没有作用的。我们能做的只是对前面的条件建立索引,让mongodb遍历的数据集尽可能的减少,仅此而已。