1��Hadoop����
�汾��Ϣ:hadoop-3.1.0
1.1��Ⱥ����
NameNode �� SecondaryNameNode ��Ҫװ��ͬһ̨������
ResourceManagerҲ�ܺ��ڴ治Ҫ��NameNode SecondaryNameNode������һ̨������
�����ļ�˵��
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- ָ�� NameNode �ĵ�ַ -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- ָ�� hadoop ���ݵĴ洢Ŀ¼ -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- ���� HDFS ��ҳ��¼ʹ�õľ�̬�û�Ϊ root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web �˷��ʵ�ַ-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web �˷��ʵ�ַ-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- ָ�� MR �� shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ָ�� ResourceManager �ĵ�ַ-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- ���������ļ̳� -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
apred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- ָ�� MapReduce ���������� Yarn �� -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
��ʽ��
��һ��������Ҫ��ʽ�� hdfs namenode -format
���ö˿�
| �˿����� | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode �ڴ�˿� | 8020/9000 | 8020/9000/9820 |
| HDFS NameNode ���û��IJ�ѯ�˿� | 50070 | 9870 |
| MapReduce Yarn����˿� | 8088 | 8088 |
| ��ʷ������ | 19888 | 19888 |
���������ļ�
? 2.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers
? MapReduce ����+��Դ����
? HDFS ���ݴ洢
? Common ��������
? 3.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml salve
? MapReduce ����
? Yarn ��Դ����
? HDFS ���ݴ洢
? Common ��������
������ʷ������
vim mapred-site.xml
<!-- ��ʷ�������˵�ַ -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- ��ʷ������ web �˵�ַ -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
������־����
vim yarn-site.xml
<!-- ������־�ۼ����� -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- ������־�ۼ���������ַ -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- ������־����ʱ��Ϊ 7 �� -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
��Ⱥʱ��ͬ��
����������ڹ�������(����������),���Բ����ü�Ⱥʱ��ͬ��,��Ϊ�������ᶨ�� ����ʱ�����У;
�������������������,����Ҫ���ü�Ⱥʱ��ͬ��,����ʱ�����,�����ʱ��ƫ��, ���¼�Ⱥִ������ʱ�䲻ͬ����
2��HDFS
2.1����
HDFS(Hadoop Distributed File System),����һ���ļ�ϵͳ,���ڴ洢�ļ�,ͨ��Ŀ ¼������λ�ļ�;���,���Ƿֲ�ʽ��,�ɺܶ��������������ʵ���书��,��Ⱥ�еķ��� ���и��ԵĽ�ɫ��
2.1.2 HDFS ��ȱ��
�ŵ�
- ���ݴ���,�Զ�����������
- �ʺϴ���������
ȱ��
- ���ʺϵ���ʱ���ݷ���
- ���Ը���С�ļ����д洢
HDFS ��ɼܹ�
-
NameNode:����Master
- ����HDFS�����ƿռ�
- ���ø�������
- �������ݿ�(Block)ӳ����Ϣ
- �����ͻ��˶�д����
-
DataNode:salve
- NameNode�´�����slaveִ��
- �洢ʵ�ʵ����ݿ�
- ִ�����ݿ�Ķ�/д����
-
Secondary NameNode:��NameNode�ҵ��������NameNode
- ����NameNode �ֵ�������
- �����ָ�NameNode(����)
-
Client:�ͻ���
- �ļ��з֡��ļ��ϴ�HDFS��ʱ��,Client���ļ��зֳ�һ��һ����Block,Ȼ������ϴ�;
- ��NameNode����,��ȡ�ļ���λ����Ϣ;
- ��DataNode����,��ȡ����д������;
- Client�ṩһЩ����������HDFS,����NameNode��ʽ��;
- Client����ͨ��һЩ����������HDFS,�����HDFS��ɾ��IJ���;
2.1.3HDFS �ļ����С(�����ص�)
HDFS�ļ����С: Ĭ��128M
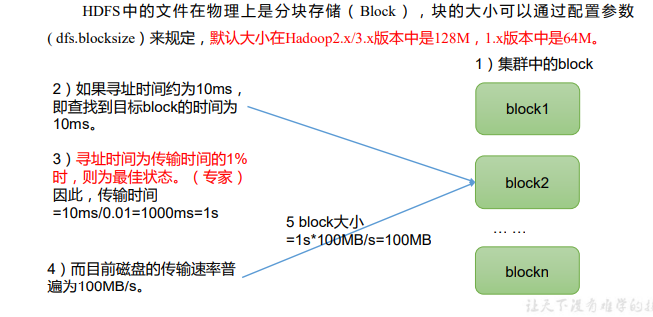
��Ĵ�С��������̫С,Ҳ��������̫��
- ̫С,������Ѱַʱ��,����һֱ���ҿ�Ŀ�ʼλ��;
- ̫��,�Ӵ��̴������ݵ�ʱ������Դ��ڶ�λ����鿪 ʼλ�������ʱ�䡣���³����ڴ����������ʱ,��dz�����
HDFS��Ĵ�С������Ҫȡ���ڴ��̴�������
2.2HDFS �� Shell ����(�����ص�)
2.2.1�����
hadoop fs �������� OR hdfs dfs �������� ��������ȫ��ͬ�ġ�
��Linux����������,ֻ��Ҫ�Ӹ�-
�ϴ�
1.moveFromLocal:�ӱ��ؼ���ճ���� HDFS
hadoop fs -moveFromLocal ./shuguo.txt
/sanguo
2.copyFromLocal:�ӱ����ļ�ϵͳ�п����ļ��� HDFS ·��ȥ ��ͬ��-put
hadoop fs -copyFromLocal weiguo.txt
/sanguo
3.-appendToFile:��һ���ļ����Ѿ����ڵ��ļ�ĩβ
hadoop fs -appendToFile liubei.txt
/sanguo/shuguo.txt
����
1.-copyToLocal==-get:�� HDFS ����������
hadoop fs -copyToLocal
/sanguo/shuguo.txt ./
2.3HDFS �� API ����
�ҵ����ϰ�·���µ� Windows �����ļ���,���� hadoop-3.1.0 ��������·��
���� Path ����������
�� IDEA �д���һ�� Maven ���� HdfsClientDemo,��������Ӧ����������+��־����
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
����Ŀ�� src/main/resources Ŀ¼��,�½�һ���ļ�,����Ϊ��log4j.properties��,���ļ� ������
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
�ͻ���ȥ���� HDFS ʱ,����һ���û����ݵġ�Ĭ�������,HDFS �ͻ��� API ��Ӳ� �� Windows Ĭ���û����� HDFS,�ᱨȨ���쳣���������ڷ��� HDFS ʱ,һ��Ҫ���� �û���
org.apache.hadoop.security.AccessControlException: Permission denied:
user=56576, access=WRITE,
inode="/xiyou/huaguoshan":atguigu:supergroup:drwxr-xr-x
�������ȼ�
(1)�ͻ��˴��������õ�ֵ >(2)ClassPath �µ��û��Զ��������� �� >(3)Ȼ���Ƿ��������Զ�������(xxx-site.xml)>(4)��������Ĭ������(xxx-default.xml)
2.4HDFS �Ķ�д����
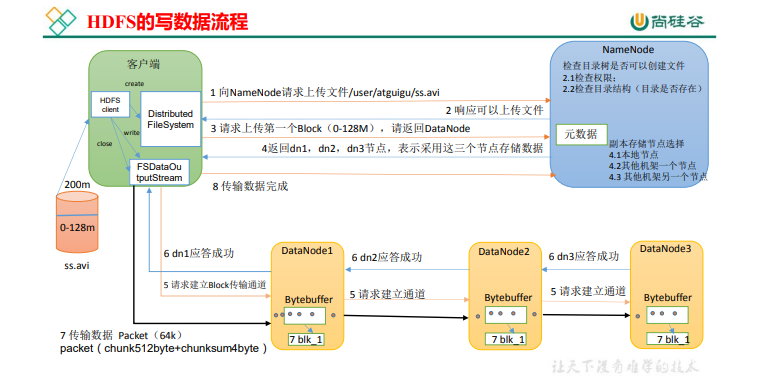
(1)�ͻ���ͨ�� Distributed FileSystem ģ���� NameNode �����ϴ��ļ�,NameNode ���Ŀ���ļ��Ƿ��Ѵ���,��Ŀ¼�Ƿ���ڡ�(2)NameNode �����Ƿ�����ϴ���
(3)�ͻ��������һ�� Block �ϴ����ļ��� DataNode �������ϡ�
(4)NameNode ���� 3 �� DataNode �ڵ�,�ֱ�Ϊ dn1��dn2��dn3��
(5)�ͻ���ͨ�� FSDataOutputStream ģ������ dn1 �ϴ�����,dn1 �յ�������������dn2,Ȼ�� dn2 ���� dn3,�����ͨ�Źܵ�������ɡ�
(6)dn1��dn2��dn3 ��Ӧ��ͻ��ˡ�
(7)�ͻ��˿�ʼ�� dn1 �ϴ���һ�� Block(�ȴӴ��̶�ȡ���ݷŵ�һ�������ڴ滺��),
�� Packet Ϊ��λ,dn1 �յ�һ�� Packet �ͻᴫ�� dn2,dn2 ���� dn3;dn1 ÿ��һ�� packet
�����һ��Ӧ����еȴ�Ӧ��
(8)��һ�� Block �������֮��,�ͻ����ٴ����� NameNode �ϴ��ڶ��� Block �ķ�������(�ظ�ִ�� 3-7 ��)��
2.5NNode �� SNNode ��������
NameNode �е�Ԫ�����Ǵ洢�������?
������ڴ���,�ڴ����б���Ԫ���ݵ� FsImage��
�����ڴ��е�Ԫ���ݸ���ʱ,���ͬʱ���� FsImage,�ͻᵼ ��Ч�ʹ���,�����������,�ͻᷢ��һ��������,һ�� NameNode �ڵ�ϵ�,�ͻ������ �ݶ�ʧ
���� Edits �ļ�(ֻ�����Ӳ���,Ч�ʺܸ�)
ÿ��Ԫ�����и��»����� ��Ԫ����ʱ,���ڴ��е�Ԫ���ݲ��ӵ� Edits �С�����,һ�� NameNode �ڵ�ϵ�,�� ��ͨ�� FsImage �� Edits �ĺϲ�,�ϳ�Ԫ���ݡ�
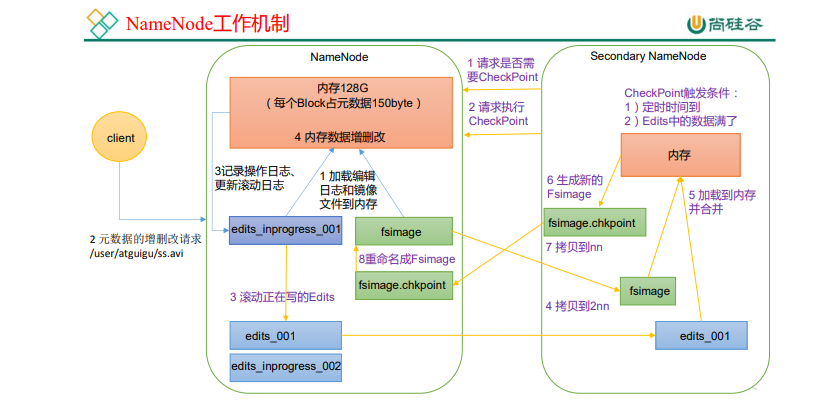
��һ��:NameNode ����
-
��һ������ NameNode ��ʽ����,���� Fsimage �� Edits �ļ���������ǵ�һ������,ֱ�Ӽ��ر༭��־�;����ļ����ڴ档
-
�ͻ��˶�Ԫ���ݽ�����ɾ�ĵ�����
-
NameNode ��¼������־,���¹�����־��
-
NameNode ���ڴ��ж�Ԫ���ݽ�����ɾ�ġ�
�ڶ���:Secondary NameNode ����
(1)Secondary NameNode ѯ�� NameNode �Ƿ���Ҫ CheckPoint��ֱ�Ӵ��� NameNode �Ƿ�������
(2)Secondary NameNode ����ִ�� CheckPoint��
(3)NameNode ��������д�� Edits ��־��
(4)������ǰ�ı༭��־�;����ļ������� Secondary NameNode��
(5)Secondary NameNode ���ر༭��־�;����ļ����ڴ�,���ϲ���
(6)�����µľ����ļ� fsimage.chkpoint��
(7)���� fsimage.chkpoint �� NameNode��
(8)NameNode �� fsimage.chkpoint ���������� fsimage��
CheckPoint ʱ������
- ͨ�������,SecondaryNameNode ÿ��һСʱִ��һ�Ρ�
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
- һ���Ӽ��һ�β�������,�����������ﵽ 1 ����ʱ,SecondaryNameNode ִ��һ����
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>������������</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
<description> 1 ���Ӽ��һ�β�������</description>
</property>
2.6DataNode
DataNode ��������
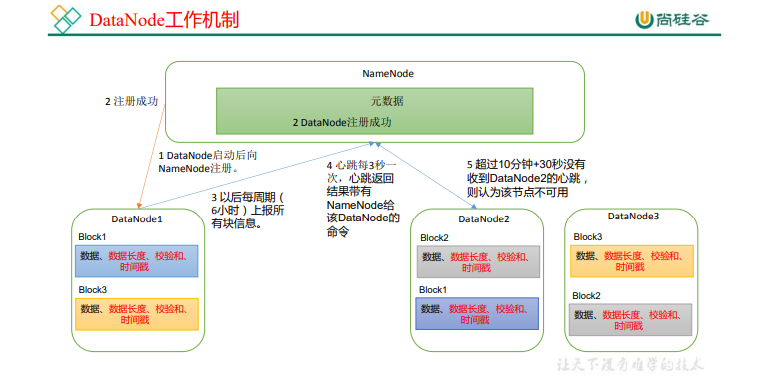
(1)һ�����ݿ��� DataNode �����ļ���ʽ�洢�ڴ�����,���������ļ�,һ�������� ����,һ����Ԫ���ݰ������ݿ�ij���,�����ݵ�У���,�Լ�ʱ�����
(2)DataNode �������� NameNode ע��,ͨ����,������(6 Сʱ)���� NameNode �� �����еĿ���Ϣ��
- DN �� NN �㱨��ǰ�����Ϣ��ʱ����,Ĭ�� 6 Сʱ;
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value>
<description>Determines block reporting interval in
milliseconds.</description>
</property>
DATanode ÿ��6Сʱ��NameNode�ϴ�����Ϣ�Ƿ����� ÿ��3��ظ�Datanode������� ����10min30s���㱨����ΪDatanode�ҵ�
������ crc32
����ʱ��
���ڵ����� hdfs --daemon start datanode
����������
(1)�� DataNode ��ȡ Block ��ʱ��,������� CheckSum��
(2)��������� CheckSum,�� Block ����ʱֵ��һ��,˵�� Block �Ѿ���
(3)Client ��ȡ���� DataNode �ϵ� Block��
(4)������У���㷨 crc(32),md5(128),sha1(160)
(5)DataNode �����ļ�������������֤ CheckSum��

����ʱ��������
TimeOut = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval��
��Ĭ�ϵ�dfs.namenode.heartbeat.recheck-interval ��СΪ5����,dfs.heartbeat.intervalĬ��Ϊ3�롣
��Ҫע����� hdfs-site.xml �����ļ��е� heartbeat.recheck.interval �ĵ�λΪ����, dfs.heartbeat.interval �ĵ�λΪ�롣
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
3��MapReduce
3.1MapReduce ����
MapReduce ����:�Լ�����ҵ����ش��� + ����Ĭ�ϴ���
MapReduce ��һ���ֲ�ʽ�������ı�̿��,���û����������� Hadoop �����ݷ���Ӧ�á��ĺ��Ŀ�ܡ�
MapReduce ���Ĺ����ǽ��û���д��ҵ����������Դ�Ĭ��������ϳ�һ�������ķֲ�ʽ�������,����������һ�� Hadoop ��Ⱥ�ϡ�
�ŵ�:
���ڱ��
������չ��:���Զ�̬���ӷ�����,���������Դ����������
���ݴ���:�κ�һ̨�����ҵ�,���Խ�����ת�Ƶ������ڵ�
�ʺϺ������ݼ���(TB/PB)��ǧ̨��������ͬ����
ȱ��:
���ó�ʵʱ����
���ó���ʽ����
���ó�DAG������ͼ����(�൱��һ��һ���ڵ�����������)
MapReduce ����˼��: Map������ Reduce����ͳ��
MrAppMaster:������������Ĺ��̵��ȼ�״̬Э��
MapTask:����Map�������������������
ReduceTask:��Reduce�ε��������ݴ�������
| Java ���� | Hadoop Writable ���� |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| int | IntWritable |
| Float | FloatWritable |
| Double | DoubleWritable |
| Long | LongWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
3.2MapReduce ��̹淶
�û���д�ij���ֳ���������:Mapper��Reducer �� Driver��
1.Mapper��
(1)�û��Զ����MapperҪ�̳��Լ��ĸ���
(2)Mapper������������KV�Ե���ʽ(KV�����Ϳ��Զ���)
(3)Mapper�е�ҵ����д��map()������
(4)Mapper�����������KV�Ե���ʽ(KV�����Ϳ��Զ���)
(5)map()����(MapTask����)��ÿһ��<K,V>����һ��
2.Reducer��
(2)Reducer�������������Ͷ�ӦMapper�������������,Ҳ��KV
(3)Reducer��ҵ����д��reduce()������
(4)ReduceTask���̶�ÿһ����ͬk��<k,v>�����һ��reduce()����
3.Driver��
�൱��YARN��Ⱥ�Ŀͻ���,�����ύ������������YARN��Ⱥ,�ύ����
��װ��MapReduce����������в�����job����
//1 ��ȡ job ����
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2 ������ Driver ��
job.setJarByClass(FlowDriver.class);
//3 ���� Mapper �� Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4 ���� Map ����� KV ����
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5 ������������� KV ����
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//6 ���ó�����������·��
FileInputFormat.setInputPaths(job, new Path("D:\\inputflow"));
FileOutputFormat.setOutputPath(job, new Path("D:\\flowoutput"));
//7 �ύ Job
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
3.3hadoop���л�
��һ̨������ڴ洫�䵽��һ̨����� û�а취ֱ�Ӵ�
���������л�:���ڴ�����תΪ�ֽ��� �ٽ��ֽ��봫��
�Զ��� bean ����ʵ�����л��ӿ�:
����ҵ�������������õĻ������л����Ͳ���������������,������ Hadoop ����ڲ�
����һ�� bean ����,��ô�ö������Ҫʵ�����л��ӿڡ�
(1)����ʵ�� Writable �ӿ�
(2)�����л�ʱ,��Ҫ������ÿղι��캯��,���Ա����пղι���
(3)��д���л��뷴���л����� ��˳�������ͬ ��д����ȷ����л�
(6)Ҫ��ѽ����ʾ���ļ���,��Ҫ��д toString(),����"\t"�ֿ�,��������á�
(7)�����Ҫ���Զ���� bean ���� key �д���,����Ҫʵ�� Comparable �ӿ�,��Ϊ
MapReduce ���е� Shuffle ����Ҫ��� key ����������
Maven�������
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
�й�ȴ����ݼ���֮ Hadoop(MapReduce)
����������������������������������������������������������
���� Java �C������ �Cǰ�� �Cpython �˹�������������,�ɰٶȷ���:�й�ȹ���
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
3.4MapReduce ���ԭ��
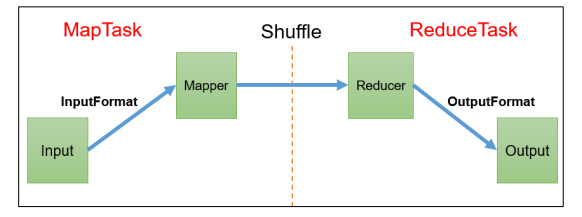
InputFormat ��������
��Ƭ�� MapTask ���жȾ�������
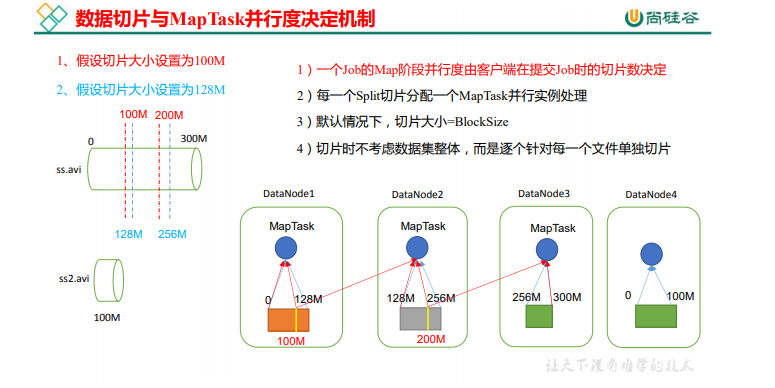
1G ������,���� 8 �� MapTask,�������Ⱥ�IJ���������������ô 1K ���� ��,Ҳ���� 8 �� MapTask,�����Ⱥ������?MapTask ���������Ƿ�Խ��Խ����?��Щ�� ��Ӱ���� MapTask ���ж�?
**���ݿ�:**Block �� HDFS �����ϰ����ݷֳ�һ��һ�顣���ݿ��� HDFS �洢���ݵ�λ��
**������Ƭ:**������Ƭֻ�������϶�������з�Ƭ,�������ڴ����Ͻ����зֳ�Ƭ���� �洢��������Ƭ�� MapReduce ��������������ݵĵ�λ,һ����Ƭ���Ӧ����һ�� MapTask
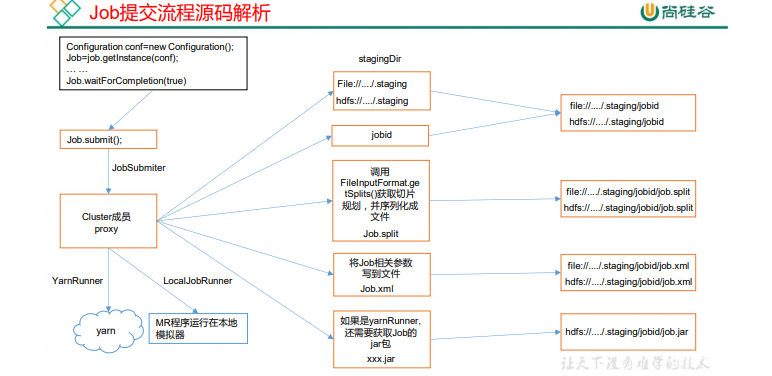
Job �ύ����Դ�����ƬԴ�����(�Ժ�)
waitForCompletion()
submit();
// 1 ��������
connect();
// 1)�����ύ Job �Ĵ���
new Cluster(getConfiguration());
// (1)�ж��DZ������л������� yarn ��Ⱥ���л���
initialize(jobTrackAddr, conf);
// 2 �ύ job
submitter.submitJobInternal(Job.this, cluster)
// 1)��������Ⱥ�ύ���ݵ� Stag ·��
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)��ȡ jobid ,������ Job ·��
JobID jobId = submitClient.getNewJobID();
// 3)���� jar ������Ⱥ
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)������Ƭ,������Ƭ�滮�ļ�
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)�� Stag ·��д XML �����ļ�
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)�ύ Job,�����ύ״̬
status = submitClient.submitJob(jobId, submitJobDir.toString(),job.getCredentials());
FileInputFormat ��ƬԴ�����(input.getSplits(job))
(1)�������ҵ������ݴ洢��Ŀ¼��
(2)��ʼ��������(�滮��Ƭ)Ŀ¼�µ�ÿһ���ļ�
(3)������һ���ļ�ss.txt
a)��ȡ�ļ���Сfs.sizeOf(ss.txt)
b)������Ƭ��С
computeSplitSize(Math.max(minSize 1,Math.min(maxSize ,blocksize)))=blocksize=128M = Long.MAXValue
c)Ĭ�������,��Ƭ��С=blocksize 32M 128M
d)��ʼ��,�γɵ�1����Ƭ:ss.txt��0:128M ��2����Ƭss.txt��128:256M ��3����Ƭss.txt��256M:300M
(ÿ����Ƭʱ,��Ҫ�ж�����ʣ�µIJ����Ƿ���ڿ��1.1��,������1.1���ͻ���һ����Ƭ)
e)����Ƭ��Ϣд��һ����Ƭ�滮�ļ���
f)������Ƭ�ĺ��Ĺ�����getSplit()���������
g)InputSplitֻ��¼����Ƭ��Ԫ������Ϣ,������ʼλ�á������Լ����ڵĽڵ��б��ȡ�
(4)�ύ��Ƭ�滮�ļ���YARN��,YARN�ϵ�MrAppMaster�Ϳ��Ը�����Ƭ�滮�ļ����㿪��MapTask������
FileInputFormat �����Ľӿ�ʵ�������:TextInputFormat��KeyValueTextInputFormat��
NLineInputFormat��CombineTextInputFormat ���Զ��� InputFormat �ȡ� TextInputFormat ��Ĭ�ϵ� FileInputFormat ʵ���ࡣ���ж�ȡÿ����¼
CombineTextInputFormat ��Ƭ����
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
TextInputFormat FileInputFormat ʵ����
������ MapReduce ����ʱ,������ļ���ʽ����:�����е���־�ļ��������� ��ʽ�ļ������ݿ���ȡ���ô,��Բ�ͬ����������,MapReduce ����ζ�ȡ��Щ���ݵ���?
FileInputFormat �����Ľӿ�ʵ�������:TextInputFormat��KeyValueTextInputFormat�� NLineInputFormat��CombineTextInputFormat ���Զ��� InputFormat �ȡ�
TextInputFormat(ÿ���ļ�����һ����Ƭ)
TextInputFormat ��Ĭ�ϵ� FileInputFormat ʵ���ࡣ���ж�ȡÿ����¼�����Ǵ洢�����������ļ��е���ʼ�ֽ�ƫ����, LongWritable ���͡�ֵ�����е�����,�������κ�����ֹ ��(���з��ͻس���),Text ���͡�
CombineTextInputFormat ��Ƭ����
���Ĭ�ϵ� TextInputFormat ��Ƭ�����Ƕ������ļ��滮��Ƭ,�����ļ���С,���� ��һ����������Ƭ,���ύ��һ�� MapTask,��������д���С�ļ�,�ͻ���������� MapTask,����Ч�ʼ�����¡�
Ӧ�ó���:
CombineTextInputFormat ����С�ļ�����ij���,�����Խ����С�ļ������Ϲ滮�� һ����Ƭ��,����,���С�ļ��Ϳ��Խ���һ�� MapTask ������
����洢��Ƭ���ֵ����
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
ע��:����洢��Ƭ���ֵ������ø���ʵ�ʵ�С�ļ���С��������þ����ֵ��

(1)����洢����: ������Ŀ¼�������ļ���С,���κ����õ� setMaxInputSplitSize ֵ�Ƚ�,����� �������õ����ֵ,���ϻ���һ���顣��������ļ��������õ����ֵ�Ҵ�������, ��ô�����ֵ�и�һ��;��ʣ�����ݴ�С�������õ����ֵ�Ҳ��������ֵ 2 ��,��ʱ ���ļ����ֳ� 2 ������洢��(��ֹ����̫С��Ƭ)��
���� setMaxInputSplitSize ֵΪ 4M,�����ļ���СΪ 8.02M,�������Ϸֳ�һ�� 4M��ʣ��Ĵ�СΪ 4.02M,������� 4M ������,�ͻ���� 0.02M ��С������洢 �ļ�,���Խ�ʣ��� 4.02M �ļ��зֳ�(2.01M �� 2.01M)�����ļ���
(2)��Ƭ����:
(a)�ж�����洢���ļ���С�Ƿ���� setMaxInputSplitSize ֵ,���ڵ����� �γ�һ����Ƭ�� (b)��������������һ������洢�ļ����кϲ�,��ͬ�γ�һ����Ƭ��
// ��������� InputFormat,��Ĭ���õ��� TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//����洢��Ƭ���ֵ���� 20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
MapReduce ��������
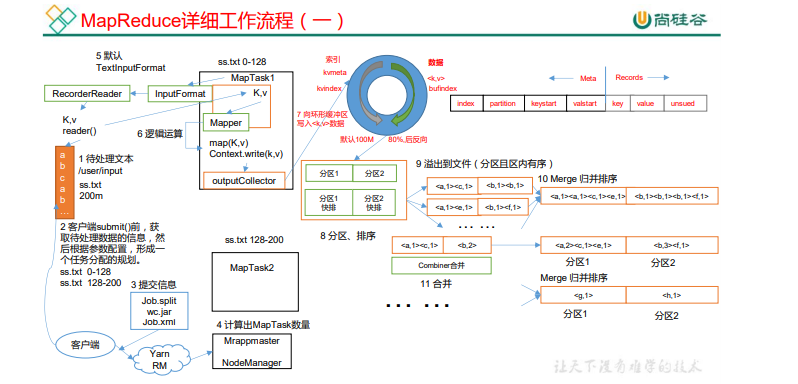
ע��:
(1)Shuffle �еĻ�������С��Ӱ�쵽 MapReduce �����ִ��Ч��,ԭ����˵,������ Խ��,���� io �Ĵ���Խ��,ִ���ٶȾ�Խ�졣
(2)�������Ĵ�С����ͨ����������,����:mapreduce.task.io.sort.mb Ĭ�� 100M��
Shuffle ����
Map ����֮��,Reduce ����֮ǰ�����ݴ������̳�֮Ϊ Shuffle��
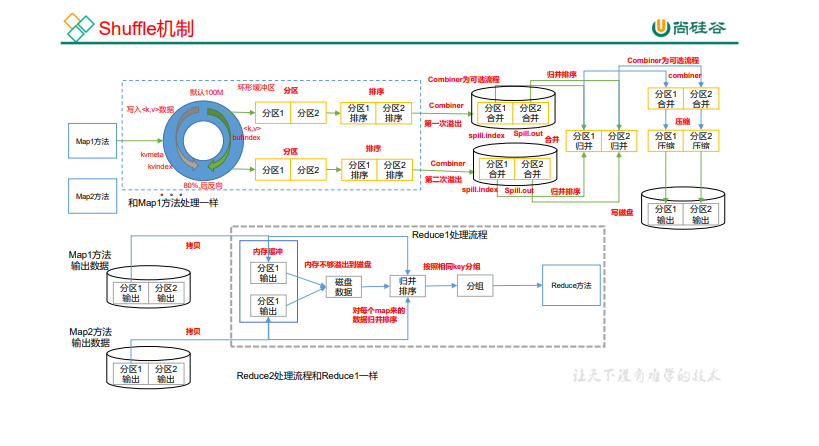
�ȱ�Ƿ������뻷�λ�����(Ĭ��100M) ���ݵ���80%��д ���֮ǰ������(����) ����������
��д���������ļ� 1.���� 2.����
CombinerΪ��ѡ���̻�ۺ�����<at,(1,1)> ��>�����ϲ� -->ѹ��д���� --�ȴ�Reduce��ȥ
��ȥ���ȳ��Է��ڴ� �ڴ治���Ŵ��� --> �������
Partition ����
setNumReduceTasks(n); ����Reduce����
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
Ĭ�Ϸ����Ǹ���key��hashCode��ReduceTasks����ȡģ�õ��ġ��û�û�������ĸ� key�洢���ĸ�������
(1)�Զ�����̳�Partitioner,��дgetPartition()����
(2)��Job������,�����Զ���Partitione job.setPartitionerClass(CustomPartitioner.class)
(3)�Զ���Partition��,Ҫ�����Զ���Partitioner����������Ӧ������ReduceTask job.setNumReduceTasks(5);
�������NumTask�������� ��������ڿ��ļ� �˷���Դ
���˵Ļ���IO�쳣 �ж��ٷ������ж���Reducer
WritableComparable ����
MapTask��ReduceTask��������ݰ� ��key(key��������ֱ�ӱ���,Ĭ���ֵ��ſ���)�������ò�������
Hadoop��Ĭ����Ϊ���κ�Ӧ�ó����е����ݾ��ᱻ����,�����������Ƿ���Ҫ��
Ĭ�������ǰ����ֵ�˳������,��ʵ�ָ�����ķ�������������
����MApTask������������ �����λ�������ֵ�ﵽ��Ž�������
����ReduceTask,����ÿ��MapTask��Զ�̿�����Ӧ�������ļ�,����ļ��� С����һ����ֵ,����д������,����洢���ڴ��С�����������ļ���Ŀ�ﵽ һ����ֵ,�����һ�ι鲢����������һ�������ļ�;����ڴ����ļ���С���� ��Ŀ����һ����ֵ,�����һ�κϲ���������д�������ϡ����������ݿ����� �Ϻ�,ReduceTaskͳһ���ڴ�ʹ����ϵ��������ݽ���һ�ι鲢����
1.��������(sort by)
�������ļ���������
2.ȫ���� (order by)
������ֻ��һ���ļ� Ч�ʵ� ��������
3.��������:(GroupingComparator����)
��Reduce�˶�key���з��顣Ӧ����:�ڽ��յ�keyΪbean����ʱ,����һ�����ֶ���ͬ(ȫ���ֶαȽϲ���ͬ)��key���뵽ͬһ��reduce����ʱ,���Բ��÷�������
4.��������
���Զ������������,���compareTo�е��ж�����Ϊ������Ϊ��������
�Զ������� WritableComparable
ԭ������ bean ������Ϊ key ����,��Ҫʵ�� WritableComparable �ӿ���д compareTo ����,�Ϳ� ��ʵ������
Combiner �ϲ�
ǰ���Dz�Ӱ���������� map�����н��������б
(1)Combiner��MR������Mapper��Reducer֮���һ�������
(2)Combiner����ĸ������Reducer��
(3)Combiner��Reducer�������������е�λ��
Combiner����ÿһ��MapTask���ڵĽڵ�����; Reducer�ǽ���ȫ������Mapper��������;
(4)Combiner��������Ƕ�ÿһ��MapTask��������оֲ�����,�Լ�С���紫����
(5)Combiner�ܹ�Ӧ�õ�ǰ���Dz���Ӱ�����յ�ҵ����,����,Combiner�����kvӦ�ø�Reducer������kv����Ҫ��Ӧ������
����һ�� WordCountCombiner ��̳� Reducer
public class WordCountCombiner extends Reducer<Text, IntWritable, Text,
IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context
context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
//��װ outKV
outV.set(sum)
�� WordcountDriver ��������ָ�� Combiner
// ָ����Ҫʹ�� combiner,�Լ����ĸ�����Ϊ combiner ����
job.setCombinerClass(WordCountCombiner.class);
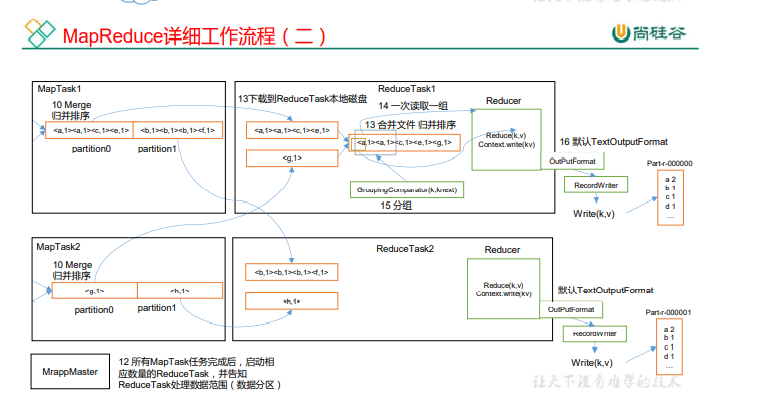
Reduce��������
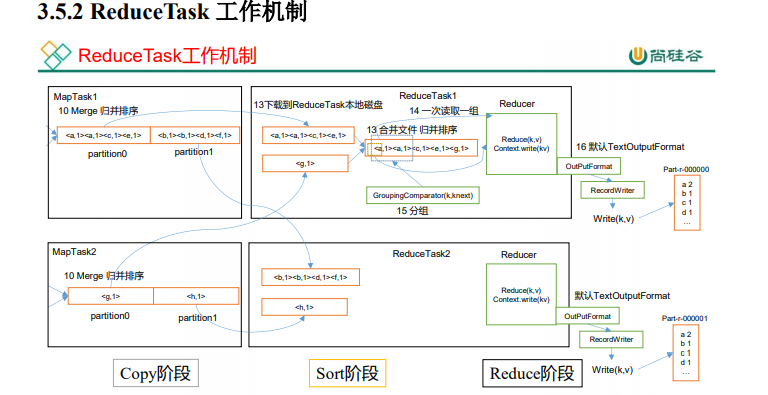
(1)Copy ��:ReduceTask �Ӹ��� MapTask ��Զ�̿���һƬ����,�����ijһƬ�� ��,������С����һ����ֵ,��д��������,����ֱ�ӷŵ��ڴ��С�
2)Sort ��:��Զ�̿������ݵ�ͬʱ,ReduceTask ������������̨�̶߳��ڴ�ʹ� ���ϵ��ļ����кϲ�,�Է�ֹ�ڴ�ʹ�ù����������ļ����ࡣ���� MapReduce ����,�� ����д reduce()�������������ǰ� key ���оۼ���һ�����ݡ�Ϊ�˽� key ��ͬ�����ݾ���һ ��,Hadoop �����˻�������IJ��ԡ����ڸ��� MapTask �Ѿ�ʵ�ֶ��Լ��Ĵ������������ �ֲ�����,���,ReduceTask ֻ����������ݽ���һ�ι鲢���ɡ�
(3)Reduce ��:reduce()������������д�� HDFS �ϡ�
MapTask & ReduceTask Դ�����
������ϴETL
Map Join
Map Join ������һ�ű�ʮ��С��һ�ű��ܴ�ij�����
��ǰ����ҵ����,�������� Map ��ҵ��,���� Reduce ���� �ݵ�ѹ��,�����ܵļ���������б��
�����к���ҵ�� MapReduce ����֮ǰ,����Ҫ�ȶ����ݽ�����ϴ,�������������û� Ҫ������ݡ������Ĺ�������ֻ��Ҫ���� Mapper ����,����Ҫ���� Reduce ����
�������ӿ�:
Mapper �û�����ҵ������ʵ��������������:map() setup() cleanup ()
- setup(),�˷�����MapReduce��ܽ���ִ��һ��,��ִ��Map����ǰ,������ر���������Դ�ļ��г�ʼ�����������ǽ���Դ��ʼ���������ڷ���map()��,����Mapper�����ڽ���ÿһ������ʱ���������Դ��ʼ������,�����ظ�,��������Ч�ʲ���!
- cleanup(),�˷�����MapReduce��ܽ���ִ��һ��,��ִ�����Map�����,������ر�������Դ���ͷŹ��������ǽ��ͷ���Դ�������뷽��map()��,Ҳ�ᵼ��Mapper�����ڽ���������ÿһ���ı����ͷ���Դ,��������һ���ı�����ǰ��Ҫ�ظ���ʼ��,���·����ظ�,��������Ч�ʲ���!
Comparable ����
(1)���������Զ���Ķ�����Ϊ key �����ʱ,�ͱ���Ҫʵ�� WritableComparable �� ��,��д���е� compareTo()������
(2)��������:�����������ÿһ���ļ������ڲ�����
(3)ȫ����:���������ݽ�������,ͨ��ֻ��һ�� Reduce��
(4)��������:�����������������
�������ӿ�:
Reducer �û�����ҵ������ʵ��������������:reduce() setup() cleanup ()
������ݽӿ�:OutputFormat
(1)Ĭ��ʵ������ TextOutputFormat,��������:��ÿһ�� KV ��,��Ŀ���ı��ļ� ���һ�С�
(2)�û��������Զ��� OutputFormat��
4��Hadoop ����ѹ��
����
ѹ���ĺô��ͻ���
ѹ�����ŵ�:�Լ��ٴ��� IO�����ٴ��̴洢�ռ䡣
ѹ����ȱ��:���� CPU ������
ѹ��ԭ��
(1)�����ܼ��͵� Job,����ѹ��
(2)IO �ܼ��͵� Job,����ѹ��
MR ֧�ֵ�ѹ������
| ѹ����ʽ | Hadoop �Դ�? | �㷨 | �ļ���չ �� | �Ƿ�� ��Ƭ | ����ѹ����ʽ��,ԭ���� �����Ƿ���Ҫ�� |
|---|---|---|---|---|---|
| DEFLATE | �� | DEFLATE | .deflate | �� | ���ı�����һ��,����Ҫ �� |
| Gzip | �� | DEFLATE | .gz | �� | ���ı�����һ��,����Ҫ �� |
| bzip2 | �� | bzip2 | .bz2 | �� | ���ı�����һ��,����Ҫ �� |
| LZO | �� | LZO | .lzo | �� | ��Ҫ������,����Ҫָ�� �����ʽ |
| Snappy | �� | Snappy | .snappy | �� | ���ı�����һ��,����Ҫ �� |
ѹ������
| ѹ���㷨 | ԭʼ�ļ���С | ѹ���ļ���С | ѹ���ٶ� | ��ѹ�ٶ� |
|---|---|---|---|---|
| gzip | 8.3GB | 1.8GB | 17.5MB/s | 58MB/s |
| bzip2 | 8.3GB | 1.1GB | 2.4MB/s | 9.5MB/s |
| LZO | 8.3GB | 2.9GB | 49.3MB/s | 74.6MB/s |
ѹ����ʽѡ��
ѹ����ʽѡ��ʱ�ص㿼��:ѹ��/��ѹ���ٶȡ�ѹ����(ѹ����洢��С)��ѹ�����Ƿ� ����֧����Ƭ��
Gzip ѹ��
�ŵ�:ѹ���ʱȽϸ�; ȱ��:��֧�� Split;ѹ��/��ѹ�ٶ�һ��;
Bzip2 ѹ��
�ŵ�:ѹ���ʸ�;֧�� Split; ȱ��:ѹ��/��ѹ�ٶ�����
Lzo ѹ��
�ŵ�:ѹ��/��ѹ�ٶȱȽϿ�;֧�� Split; ȱ��:ѹ����һ��;��֧����Ƭ��Ҫ���ⴴ��������
Snappy ѹ��
�ŵ�:ѹ���ͽ�ѹ���ٶȿ�; ȱ��:��֧�� Split;ѹ����һ��; ѹ��λ��ѡ��
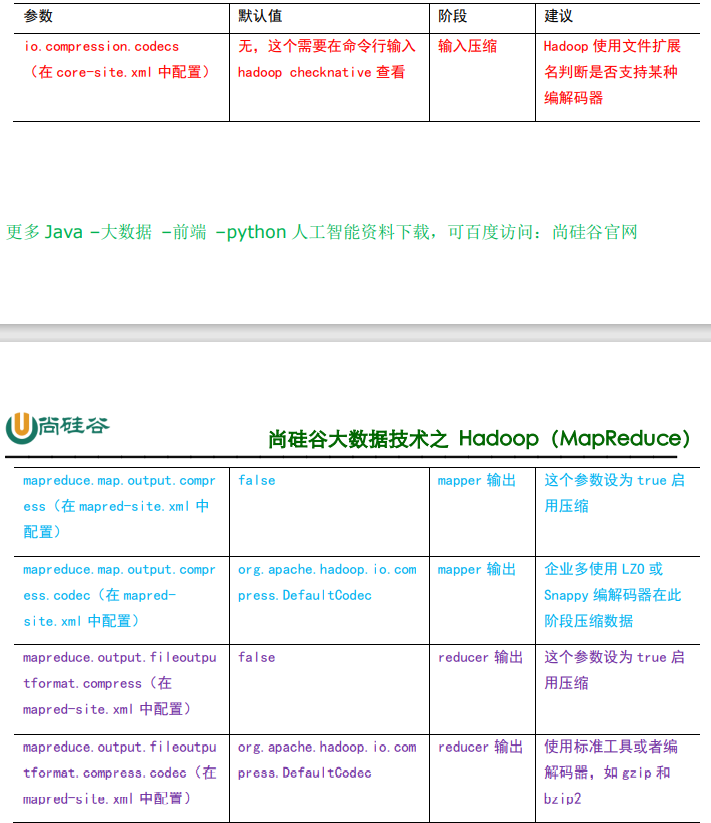
ѹ�������� MapReduce ���õ���������á�
Ҫ�� Hadoop ������ѹ��,��Ҫ�������²���
5��YARN
YARN ��Ҫ�� ResourceManager��NodeManager��ApplicationMaster �� Container ���������
Yarn ��������
ResourceManager(RM)��Ҫ��������
(1)�����ͻ�������
(3)��������ApplicationMaster
(2)���NodeManager
(4)��Դ�ķ��������
**NodeManager(NM)**��Ҫ��������
(1)���������ڵ��ϵ���Դ
(2)��������ResourceManager������
(3)��������ApplicationMaster������
**ApplicationMaster(AM)**��������
(2)����ļ�����ݴ�
(1)ΪӦ�ó���������Դ�������ڲ�������
Container:
Container��Yarn�е���Դ����,����װ��ij���ڵ��ϵĶ�ά����Դ,���ڴ�CPU��������
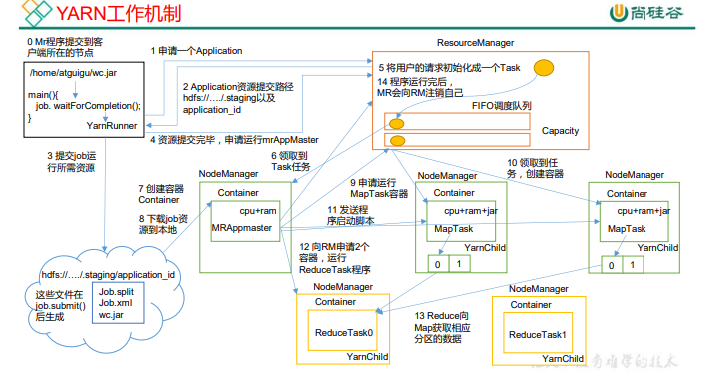
(1)MR �����ύ���ͻ������ڵĽڵ㡣
(2)YarnRunner �� ResourceManager ����һ�� Application��
(3)RM ����Ӧ�ó������Դ·�����ظ� YarnRunner��
(4)�ó�������������Դ�ύ�� HDFS �ϡ�
(5)������Դ�ύ��Ϻ�,�������� mrAppMaster��
(6)RM ���û��������ʼ����һ�� Task��
(7)����һ�� NodeManager ��ȡ�� Task ����
(8)�� NodeManager �������� Container,������ MRAppmaster
(9)Container �� HDFS �Ͽ�����Դ�����ء�
(10)MRAppmaster �� RM �������� MapTask ��Դ��
(11)RM ������ MapTask ���������������� NodeManager,������ NodeManager �� ����ȡ������������
(12)MR ���������յ������ NodeManager ���ͳ��������ű�,������ NodeManager �ֱ����� MapTask,MapTask �����ݷ�������
(13)MrAppMaster �ȴ����� MapTask ������Ϻ�,�� RM ��������,���� ReduceTask��
(14)ReduceTask �� MapTask ��ȡ��Ӧ���������ݡ�
(15)����������Ϻ�,MR ���� RM ����ע���Լ���
Yarn �������͵����㷨
Ŀǰ,Hadoop ��ҵ��������Ҫ������:FIFO������(Capacity Scheduler)��ƽ(Fair Scheduler)��Apache Hadoop3.1.3 Ĭ�ϵ���Դ�������� Capacity Scheduler�� CDH ���Ĭ�ϵ������� Fair Scheduler�� �����������:yarn-default.xml �ļ�
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
�Ƚ��ȳ�������(FIFO)
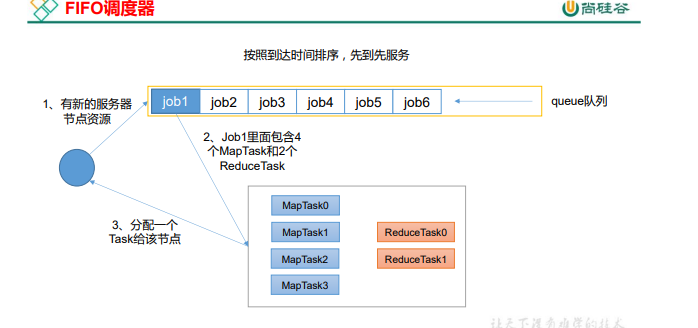
�ŵ�:����;
ȱ��:��֧�ֶ����,������������ʹ��;
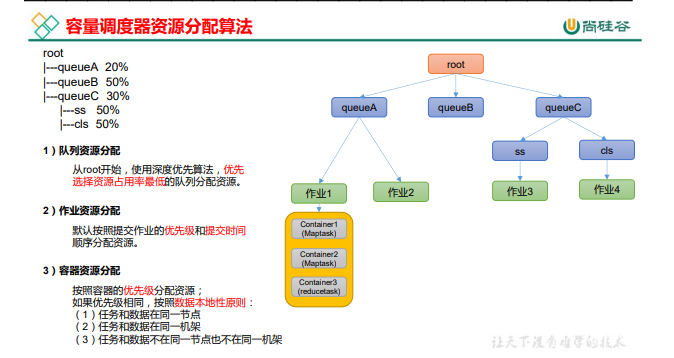
����������(Capacity Scheduler)

��ƽ������(Fair Scheduler)

��ƽ������������Դ���䷽ʽ
FIFO����
��ƽ������ÿ��������Դ����������ѡ��FIFO�Ļ�,��ʱ��ƽ�������൱�����潲����������������
Fair����
Fair ����(Ĭ��)��һ�ֻ��������С��ƽ�㷨ʵ�ֵ���Դ��·���÷�ʽ,Ĭ�������,ÿ�������ڲ����ø÷�ʽ������Դ������ζ��,���һ��������������Ӧ�ó���ͬʱ����,��ÿ��Ӧ�ó���ɵõ�1/2����Դ;�������Ӧ�ó���ͬʱ����,��ÿ��Ӧ�ó���ɵõ�1/3����Դ��
������Դ�������̺�����������һ��;
(1)ѡ�����
(2)ѡ����ҵ
(3)ѡ������
DRF����
DRF(Dominant Resource Fairness),����֮ǰ˵����Դ,���ǵ�һ��,����ֻ�����ڴ�(Ҳ��YarnĬ�ϵ����)�����Ǻܶ�ʱ��������Դ�кܶ���,�����ڴ�,CPU,���������,�������Ǻ��Ѻ�������Ӧ��Ӧ�÷������Դ������
Yarn ��������
yarn application �鿴����
����� Application
yarn application -list
���� Application ״̬����:yarn application -list -appStates (����״̬:ALL��NEW�� NEW_SAVING��SUBMITTED��ACCEPTED��RUNNING��FINISHED��FAILED��KILLED)
yarn application -list -appStates FINISHED
Kill �� Application
yarn application -kill
application_1612577921195_0001
yarn logs
��ѯ Application ��־:yarn logs -applicationId
yarn logs -applicationId application_1612577921195_0001
��ѯ Container ��־:yarn logs -applicationId -containerId
yarn logs -applicationId
application_1612577921195_0001 -containerId
container_1612577921195_0001_01_000001
yarn applicationattempt �鿴�������е�����
�г����� Application ���Ե��б�:yarn applicationattempt -list
yarn applicationattempt -list
application_1612577921195_0001
��ӡ ApplicationAttemp ״̬:yarn applicationattempt -status
yarn applicationattempt -status
appattempt_1612577921195_0001_000001
yarn container �鿴����
����� Container:yarn container -list
yarn container -list appattempt_1612577921195_0001_000001
��ӡ Container ״̬:yarn container -status
yarn container -status container_1612577921195_0001_01_000001
ע:ֻ���������ܵ�;�в��ܿ��� container ��״̬
yarn node �鿴�ڵ�״̬
�г����нڵ�:yarn node -list -all
yarn rmadmin ��������
���ض�������:yarn rmadmin -refreshQueues
yarn queue �鿴����
��ӡ������Ϣ:yarn queue -status
Yarn �����������IJ�������
ע:�������в���֮ǰ�������� Linux ����,��������İ���,����Ҫ��д����Ⱥ��
1)����:�� 1G ������,ͳ��ÿ�����ʳ��ִ����������� 3 ̨,ÿ̨���� 4G �ڴ�,4 �� CPU,4 �̡߳�
2)�������: 1G / 128m = 8 �� MapTask;1 �� ReduceTask;1 �� mrAppMaster ƽ��ÿ���ڵ����� 10 �� / 3 ̨ �� 3 ������(4 3 3)
�� yarn-site.xml ��������:
<!-- ѡ�������,Ĭ������ -->
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capaci
ty.CapacityScheduler</value>
</property>
<!-- ResourceManager ����������������߳�����,Ĭ�� 50;����ύ������������ 50,����
���Ӹ�ֵ,���Dz��ܳ��� 3 ̨ * 4 �߳� = 12 �߳�(ȥ������Ӧ�ó���ʵ�ʲ��ܳ��� 8) -->
<property>
<description>Number of threads to handle scheduler
interface.</description>
<name>yarn.resourcemanager.scheduler.client.thread-count</name>
<value>8</value>
</property>
<!-- �Ƿ��� yarn �Զ����Ӳ����������,Ĭ���� false,����ýڵ��кܶ�����Ӧ�ó���,����
�ֶ����á�����ýڵ�û������Ӧ�ó���,���Բ����Զ� -->
<property>
<description>Enable auto-detection of node capabilities such as
memory and CPU.
</description>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>false</value>
</property>
<!-- �Ƿ������������ CPU ����,Ĭ���� false,�������� CPU ���� -->
<property>
<description>Flag to determine if logical processors(such as
hyperthreads) should be counted as cores. Only applicable on Linux
when yarn.nodemanager.resource.cpu-vcores is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true.
</description>
<name>yarn.nodemanager.resource.count-logical-processors-ascores</name>
<value>false</value>
</property>
<!-- ���������������������,Ĭ���� 1.0 -->
<property>
<description>Multiplier to determine how to convert phyiscal cores to
vcores. This value is used if yarn.nodemanager.resource.cpu-vcores
is set to -1(which implies auto-calculate vcores) and
yarn.nodemanager.resource.detect-hardware-capabilities is set to true.
The number of vcores will be calculated as number of CPUs * multiplier.
</description>
<name>yarn.nodemanager.resource.pcores-vcores-multiplier</name>
<value>1.0</value>
</property>
<!-- NodeManager ʹ���ڴ���,Ĭ�� 8G,��Ϊ 4G �ڴ� -->
<property>
<description>Amount of physical memory, in MB, that can be allocated
for containers. If set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically calculated(in case of Windows and Linux).
In other cases, the default is 8192MB.
</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- nodemanager �� CPU ����,������Ӳ�������Զ��趨ʱĬ���� 8 ��,��Ϊ 4 �� -->
<property>
<description>Number of vcores that can be allocated
for containers. This is used by the RM scheduler when allocating
resources for containers. This is not used to limit the number of
CPUs used by YARN containers. If it is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically determined from the hardware in case of Windows and Linux.
In other cases, number of vcores is 8 by default.</description>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- ������С�ڴ�,Ĭ�� 1G -->
<property>
<description>The minimum allocation for every container request at the
RM in MBs. Memory requests lower than this will be set to the value of
this property. Additionally, a node manager that is configured to have
less memory than this value will be shut down by the resource manager.
</description>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- ��������ڴ�,Ĭ�� 8G,��Ϊ 2G -->
<property>
<description>The maximum allocation for every container request at the
RM in MBs. Memory requests higher than this will throw an
InvalidResourceRequestException.
</description>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- ������С CPU ����,Ĭ�� 1 �� -->
<property>
<description>The minimum allocation for every container request at the
RM in terms of virtual CPU cores. Requests lower than this will be set to
the value of this property. Additionally, a node manager that is configured
to have fewer virtual cores than this value will be shut down by the
resource manager.
</description>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<!-- ������� CPU ����,Ĭ�� 4 ��,��Ϊ 2 �� -->
<property>
<description>The maximum allocation for every container request at the
RM in terms of virtual CPU cores. Requests higher than this will throw an
InvalidResourceRequestException.</description>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>2</value>
</property>
<!-- �����ڴ���,Ĭ�ϴ�,��Ϊ�ر� -->
<property>
<description>Whether virtual memory limits will be enforced for
containers.</description>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- �����ڴ�������ڴ����ñ���,Ĭ�� 2.1 -->
<property>
<description>Ratio between virtual memory to physical memory when
setting memory limits for containers. Container allocations are
expressed in terms of physical memory, and virtual memory usage is
allowed to exceed this allocation by this ratio.
</description>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>