目录
0 前言
???????? SQL语言在数据处理、数据分析领域具有重要意义,往往要求开发者具有结构化的思维方式,能将二维表进行各种方式的转换,以达到输出最终结果的目的。这就要求数据开发者必须掌握一些核心的变换操作,如关联、和UNION操作,其中关联的意义在于联合查询,获取更多的行数据信息及逻辑判断的特征信息(让行粒度的数据变得更丰富),UNION的意义是为了分治处理,将不同特征的数据分开处理并进行合并,这两种操作是处理数据变化的基础操作和基本思维。而窗口函数的出现,让SQL应对复杂场景的问题变得简单,他以数据集(窗口)的形式对数据进行变换,并针对窗口内每一行数据利用分析函数进行计算,生成一个辅助计算值,我们往往借助于窗口函数进行辅助计算或生成标签值,窗口函数的出现让SQL处理复杂业务场景问题变得简单,使得SQL语言在数据处理、数据分析领域显得尤为重要,因而学好SQL语言对数据开发者来讲至关重要。在面对各种多变、复杂的业务场景处理时,我们往往需要以怎样的思维进行切入,以什么样的手段、方式进行化解复杂业务场景问题,这是本文需要探讨的,本文给出了一种以水位线思想分析复杂场景问题的方法和手段,并以实际业务场景为例,层层深入,最终引出本文的观点和方法,巧用sum(xxx) over(order by ts)解决数据随时间变化的发生拐点问题,利用这一函数进行分组处理使问题变得简单、逻辑性更强、通用性和可扩展性更高。
1 场景描述
水位线的思想处理问题,我们先根据实际场景需要解决的问题来引出这一话题,例如有下面的场景:
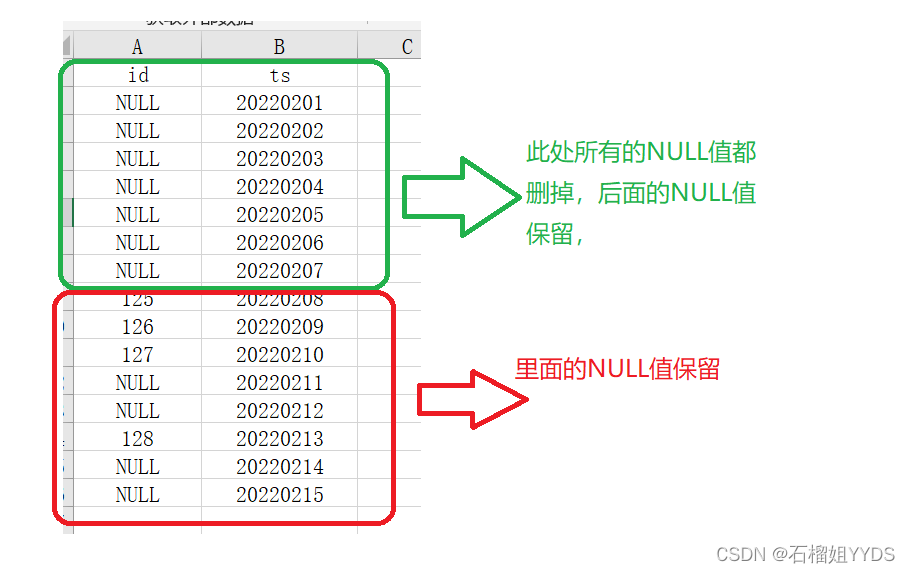
我们希望删除某id中存在NULL值的所有行,但是保留第一次出现不为NULL值的以下所有存在NULL值的行。具体如下图所示:
2 数据准备
(1)数据
| id | ts |
| NULL | 20220201 |
| NULL | 20220202 |
| NULL | 20220203 |
| NULL | 20220204 |
| NULL | 20220205 |
| NULL | 20220206 |
| NULL | 20220207 |
| 125 | 20220208 |
| 126 | 20220209 |
| 127 | 20220210 |
| NULL | 20220211 |
| NULL | 20220212 |
| 128 | 20220213 |
| NULL | 20220214 |
| NULL | 20220215 |
(2)创建表
drop table if exists test01 CREATE TABLE test01 ( id string, ts string ) ROW format delimited FIELDS TERMINATED BY "\t";
(3)? 导入数据
load data local inpath "/home/test/test01.txt" into table test01;
(4)查询数据
+------------+------------+ | test01.id | test01.ts | +------------+------------+ | id | ts | | NULL | 20220201 | | NULL | 20220202 | | NULL | 20220203 | | NULL | 20220204 | | NULL | 20220205 | | NULL | 20220206 | | NULL | 20220207 | | 125 | 20220208 | | 126 | 20220209 | | 127 | 20220210 | | NULL | 20220211 | | NULL | 20220212 | | 128 | 20220213 | | NULL | 20220214 | | NULL | 20220215 | +------------+------------+
3 水位线思想分析研究
? 水位线思想:
???? 数据分析的本质就是抓取数据特征,具备结构化化思维模式。我们考虑到如果直接按照过滤NULL的方法会将所有NULL值行都会删除掉,显示不是我们想要的,对于此种类型的个性化删除,我们往往采用打标签的形式进行删除,因此解决该问题的本质是如何给需要删除的数据打上标签,打标签的思维方法我们往往都是借助窗口函数进行辅助计算(窗口函数的本质:辅助计算)。
????? 我们观察数据可以发现,在id为125之前id字段中所有的数据都没有发生变化,在id等于125之后id字段中的值开始变化,直到id字段值为127之后穿插了两行又开始不变,这样来来回回总是在变化和不变化之中徘徊,如果我们把数据这种动态变化的过程,看成实时流式数据,有一个蓄水池,蓄水池的特点就是,水在一段时间内是持续增长的,在一段时间内保持平衡不再增长,而不再增长的这条基线我们把它称为水位线,整个过程反应如下图所示:
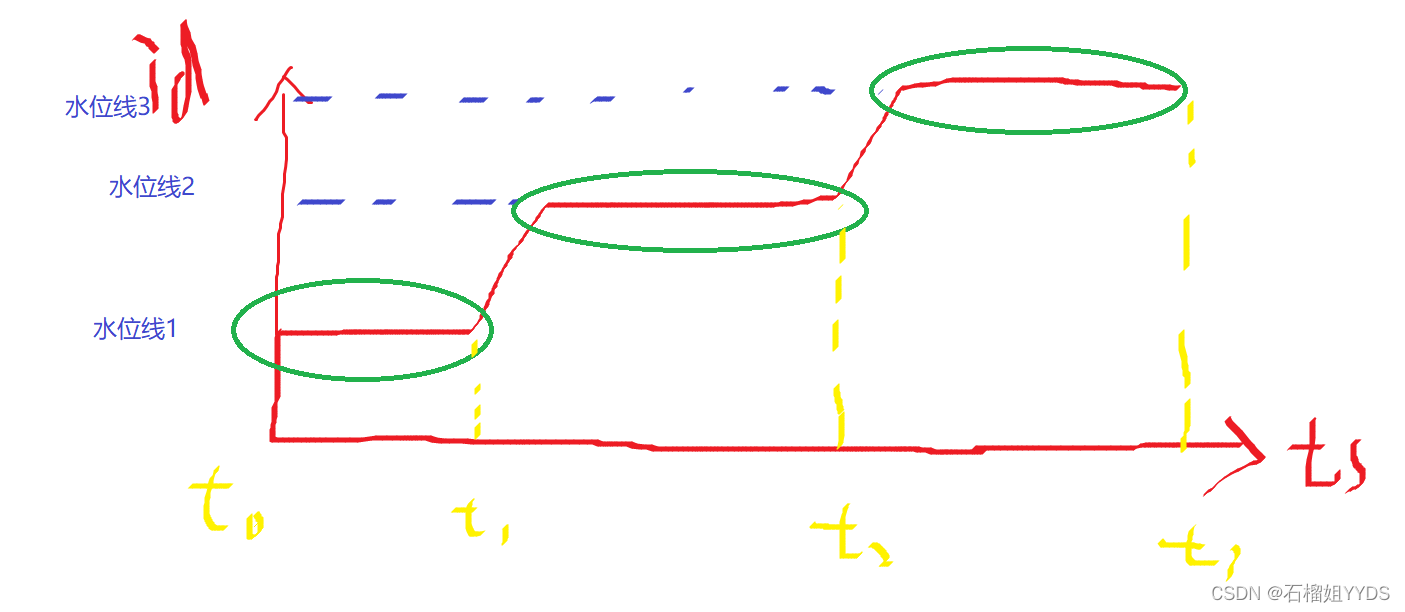
????? 那么我们如何求出上述过程中的水位呢?我们观察到t0-t1时刻,水位保持一个平衡值,t1->t2时刻的水位保持一个平衡值,t2->t3时刻水位保持一个平衡值,可以看出水位是随时间在不断变化的,而水位的值是一直增长的,因此把横坐标和纵坐标综合起来看,其实每一次的水位就是随着时间的变化的累加值,当这个值不再变化时候,此时就是水位。那么我们如何用SQL语言来描述这一过程呢?
??? 上述分析过程已经给出了关键词:累加,随时间变化,因而我们很容易相当窗口函数
sum(id) over(order by ts)
?利用上述公式当值保持一个恒定值的时候,此时这个值就是水位。
????? 分析了半天这个水位有什么作用呢?其实他可以将数据进行分类,变化和不变化的数据,体现数据的关键特征信息,我们往往利用水位这一特征对数据进行分组处理,找出分组id,这也体现了我们在一开始就强调数据分析的本质是抓特征处理的思想。我们利用这一分组id可以将某一时间段内不变的数据放在一起,可以解决实际场景的一些峰值问题,也可以利用这个特征去除一些无用的数据、也可以解决持续、连续性等问题,因为他们的本质都是一样变化和不变化。
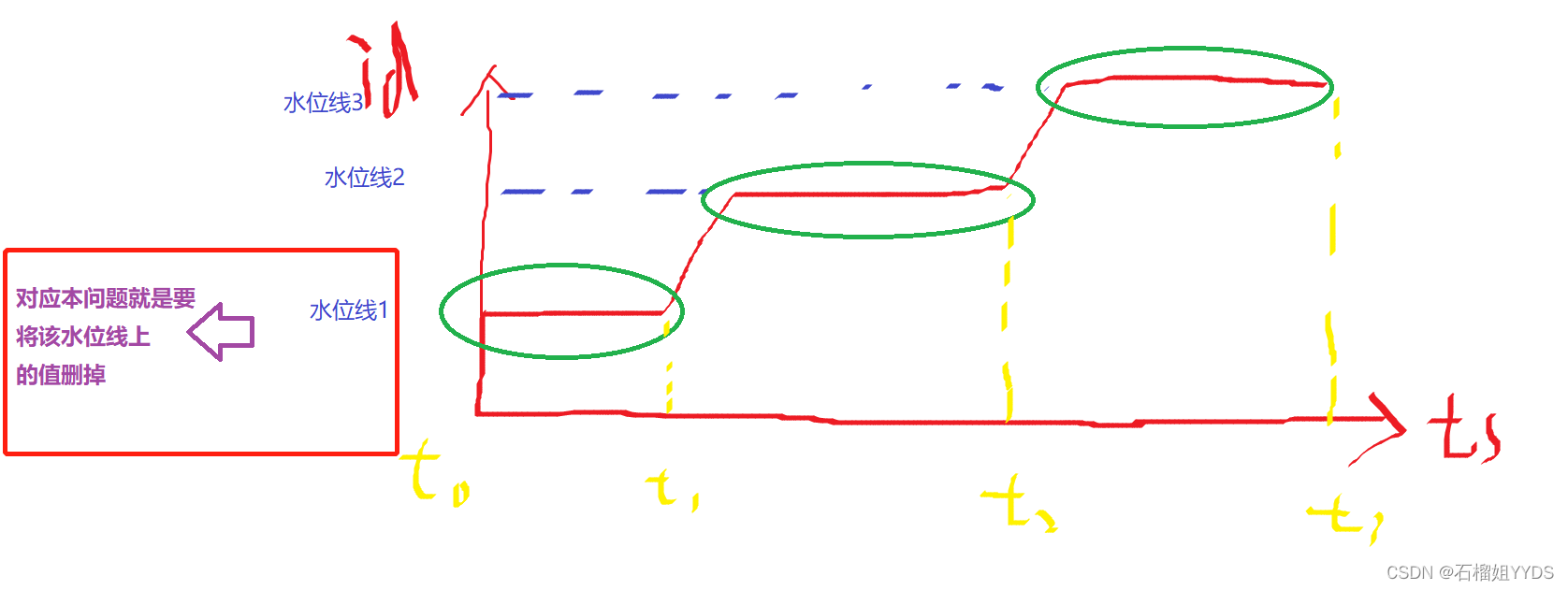
????? 再来看本文所提到的问题,有了水位线思想的铺垫,相信你很快能找到答案,该场景中所要删除的数据就是我们上图中第一条水位线上的值。
?????? 对于本问题具体sql怎么写呢?首先需要将NULL值进行转换,利用colesce()函数将NULL值转换为0,然后再累加找出第一条数为线值,过滤掉即可。
中间数据变化过程如下:
select *
,sum(coalesce(id,0)) over(order by ts) as water_mark
from test01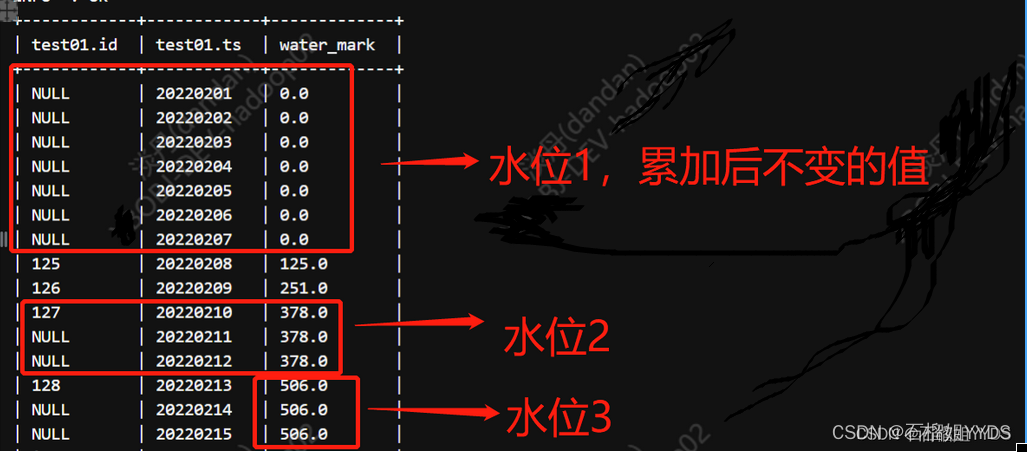
过滤掉水位1的数据就是我们需要的数据:最终SQL如下
select * from (select * ,sum(coalesce(id,0)) over(order by ts) as water_mark from test01 ) t where water_mark !=0
去掉水位1的数据:
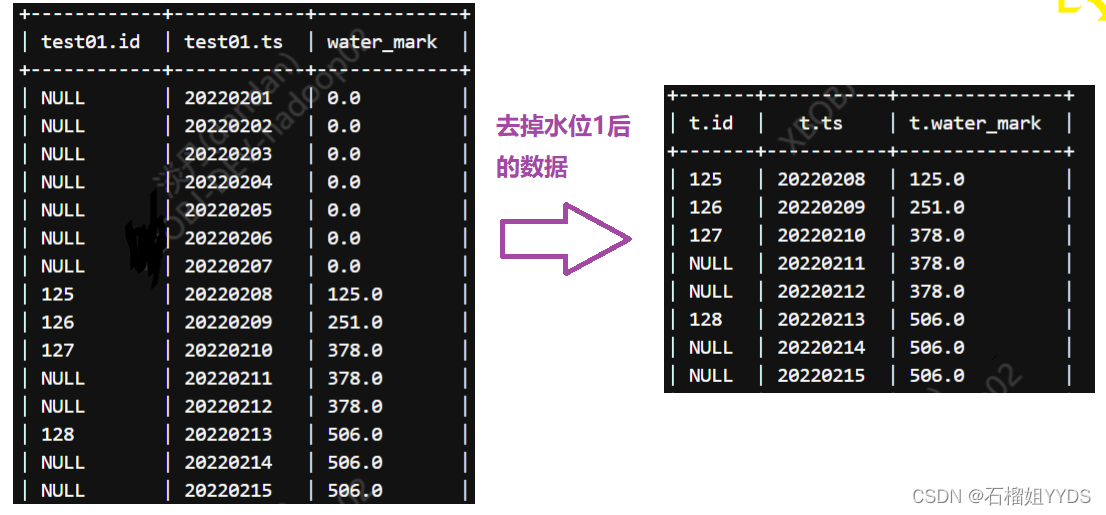
?????? 鉴于本题的特殊性,我们只需要去掉水位线为0,也就是第一次出现水位线的时候的数据即可,那么有同学会问,我要是过滤掉第二次水位线上不为NULL值的所有数据呢,如本题378水位线,此时不就多过滤数据了吗?事实上我们解决实际问题,往往不像本题所提供的这么简单,但都需要根据此思想去做变化,利用条件判断语句等构造满足业务场景的水位线,而不是真实的水位线,这样才能满足各种需求,本文只是给出了一种通用的思想。
??? 针对上述同学提出的问题,要过滤第二次水位线上不为NULL值的数据,我们可以做如下变化
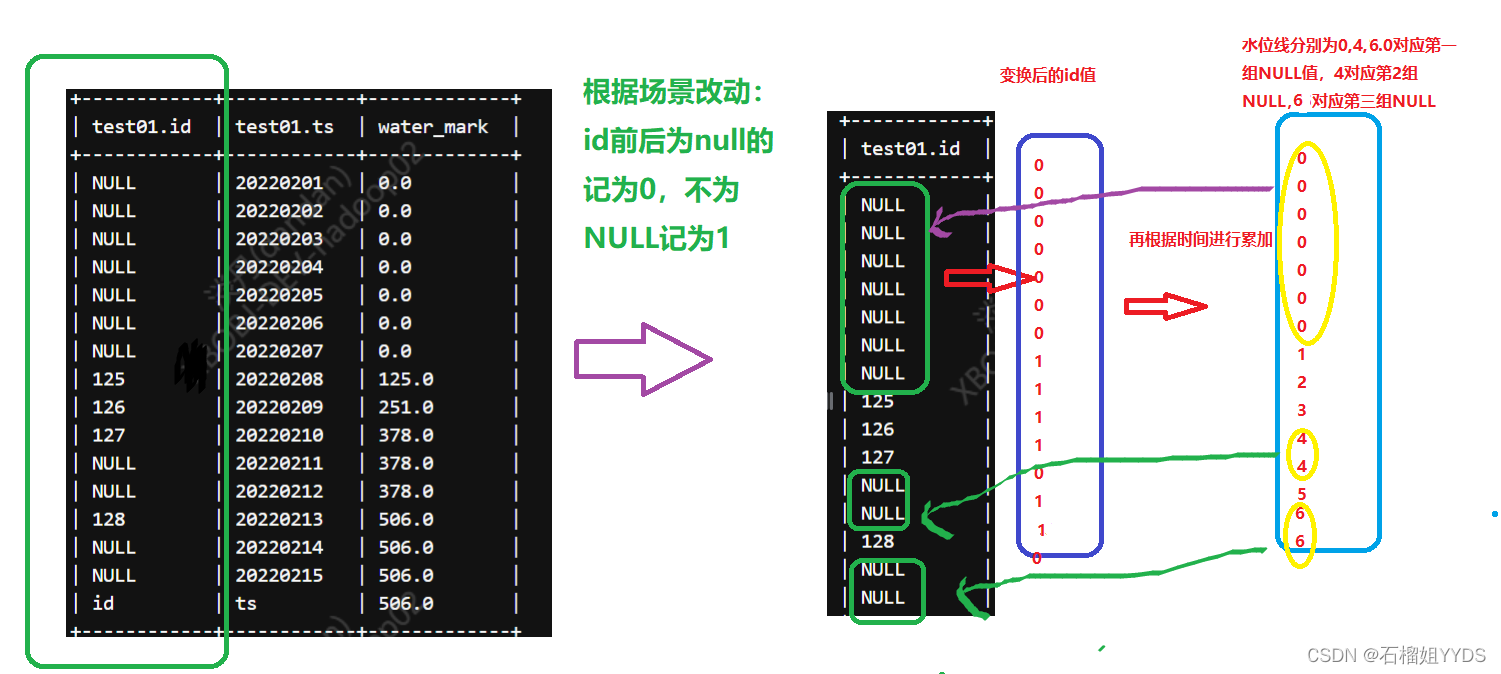
????? 通过上述方法我们便可以过滤出中间第二次水位线上不为NULL值的数据,但前提是要知道水位值,由于水位值是实际数据中累加的一个结果值,这种方法并不通用,如果我要过滤第三次、第四次水位线上不为NULL值的值呢?也就是说问题转换为求水位线的顺序id,代表他第几次水位,然后再通过传入的水位的顺序id去寻找对应的水位值去过滤,问题就好解决了。那么如何求水位的顺序id 呢?我们对上图再做变换:
核心思想:采用分而治之的思想,将水位的值放在一组,非水位的值放在一组,水位的值进行顺序排序,非水位的值不排序。分而治之一般采用UNION ALL
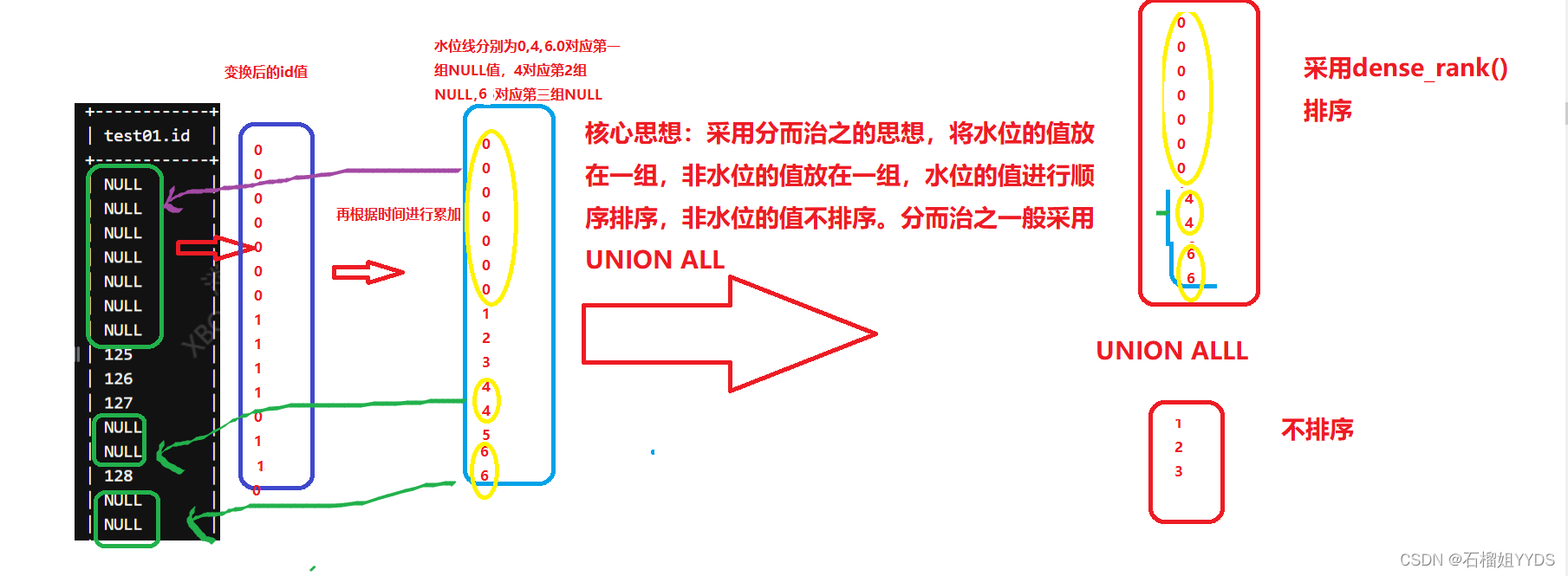
? ?? 那么问题来了,如何将水位值放在一起呢?水位值就是前后值相等的值,我们利用这一特性,将数据进行标记。对应的SQL就是利用case when 判断前后值是否相等,相等则为1,不等则为0,这样标记后就将水位值放在一组里。具体SQL如下:
select * ,sum(if(id = 'NULL' and lag_id = 'NULL',0,1)) over(order by ts) as water_mark from( select * ,lag(id,1,id) over(order by ts) as lag_id from test01 ) t
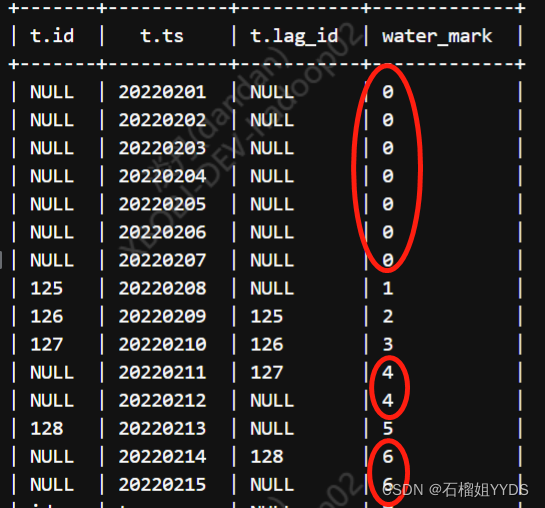
将水位值进行标记SQL如下:
select * ,case when water_mark=lag_water_mark then 1 else 0 end as water_mark_flg --将水位值标记 from( select * ,lag(water_mark,1,water_mark) over(order by ts) as lag_water_mark from( select * ,sum(if(id = 'NULL' and lag_id = 'NULL',0,1)) over(order by ts) as water_mark from( select * ,lag(id,1,id) over(order by ts) as lag_id from test01 ) t ) t )t
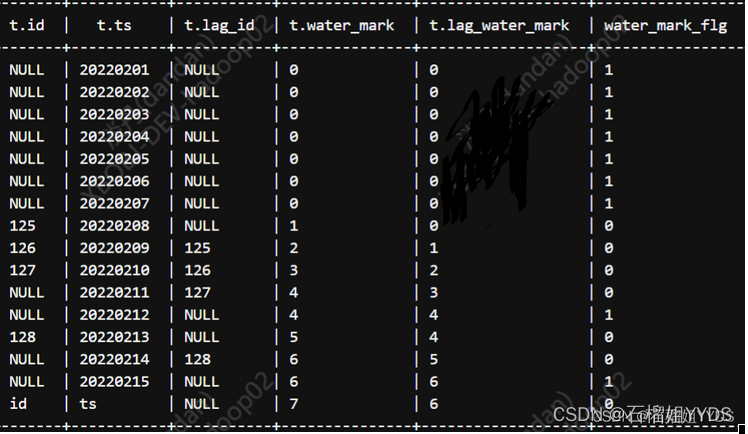
利用UNION ALL,生成水位的顺序id,SQL如下,对于水位进行dense_rank()生成顺序id,对于非数为默认为NULL。采用dense_rank()目的是对重复值去重排名。
select * ,DENSE_RANK() over(order by water_mark) as num --注意此处是对水位进行排名,所以order by后是water_mark而不是ts from( select * ,case when water_mark=lag_water_mark then 1 else 0 end as water_mark_flg --将水位值标记 from( select * ,lag(water_mark,1,water_mark) over(order by ts) as lag_water_mark from( select * ,sum(if(id = 'NULL' and lag_id = 'NULL',0,1)) over(order by ts) as water_mark from( select * ,lag(id,1,id) over(order by ts) as lag_id from test01 ) t ) t )t ) t where water_mark_flg=1 UNION ALL select * ,NULL as num --对于非水位值不进行排名,置为NULL就可以。这就是分而知之的思想 from( select * ,case when water_mark=lag_water_mark then 1 else 0 end as water_mark_flg --将水位值标记 from( select * ,lag(water_mark,1,water_mark) over(order by ts) as lag_water_mark from( select * ,sum(if(id = 'NULL' and lag_id = 'NULL',0,1)) over(order by ts) as water_mark from( select * ,lag(id,1,id) over(order by ts) as lag_id from test01 ) t ) t )t ) t where water_mark_flg=0
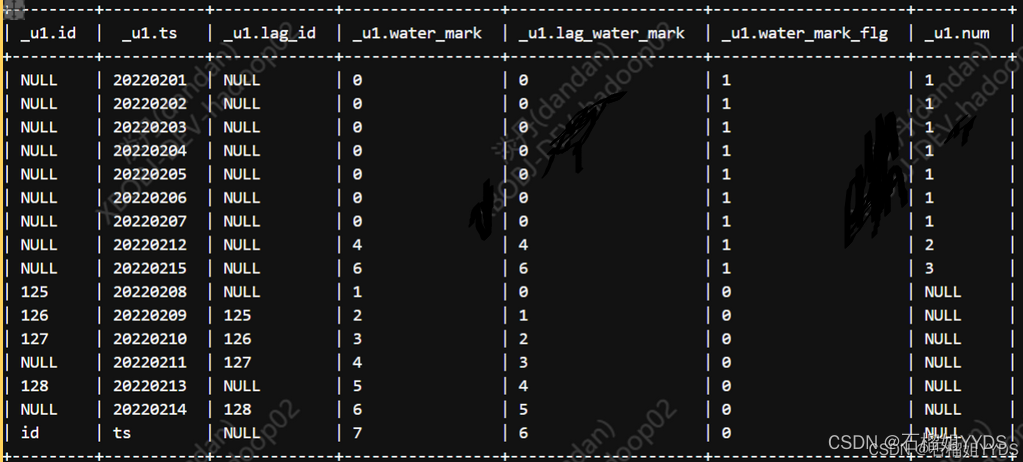
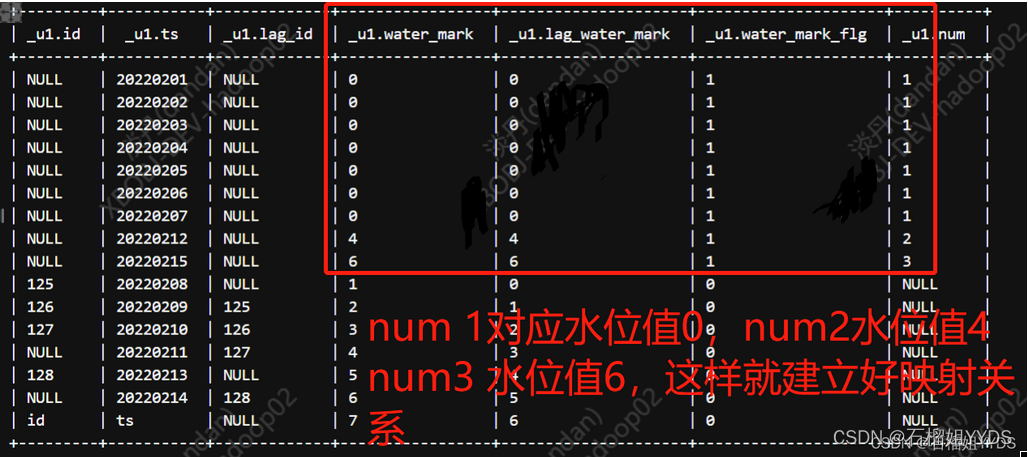
?根据传入的水位线的次数,生成水位的删除标记值:利用max()获取唯一值,作为过滤值。
select * ,max(if(num=3,water_mark,null)) over() as water_mark_del --根据传入的次数找出要删除的水位值,利用max()函数获取唯一值 from( select * ,DENSE_RANK() over(order by water_mark) as num --注意此处是对水位进行排名,所以order by后是water_mark而不是ts from( select * ,case when water_mark=lag_water_mark then 1 else 0 end as water_mark_flg --将水位值标记 from( select * ,lag(water_mark,1,water_mark) over(order by ts) as lag_water_mark from( select * ,sum(if(id = 'NULL' and lag_id = 'NULL',0,1)) over(order by ts) as water_mark from( select * ,lag(id,1,id) over(order by ts) as lag_id from test01 ) t ) t )t ) t where water_mark_flg=1 UNION ALL select * ,NULL as num --对于非水位值不进行排名,置为NULL就可以。这就是分而知之的思想 from( select * ,case when water_mark=lag_water_mark then 1 else 0 end as water_mark_flg --将水位值标记 from( select * ,lag(water_mark,1,water_mark) over(order by ts) as lag_water_mark from( select * ,sum(if(id = 'NULL' and lag_id = 'NULL',0,1)) over(order by ts) as water_mark from( select * ,lag(id,1,id) over(order by ts) as lag_id from test01 ) t ) t )t ) t where water_mark_flg=0 ) t
生成结果如下:
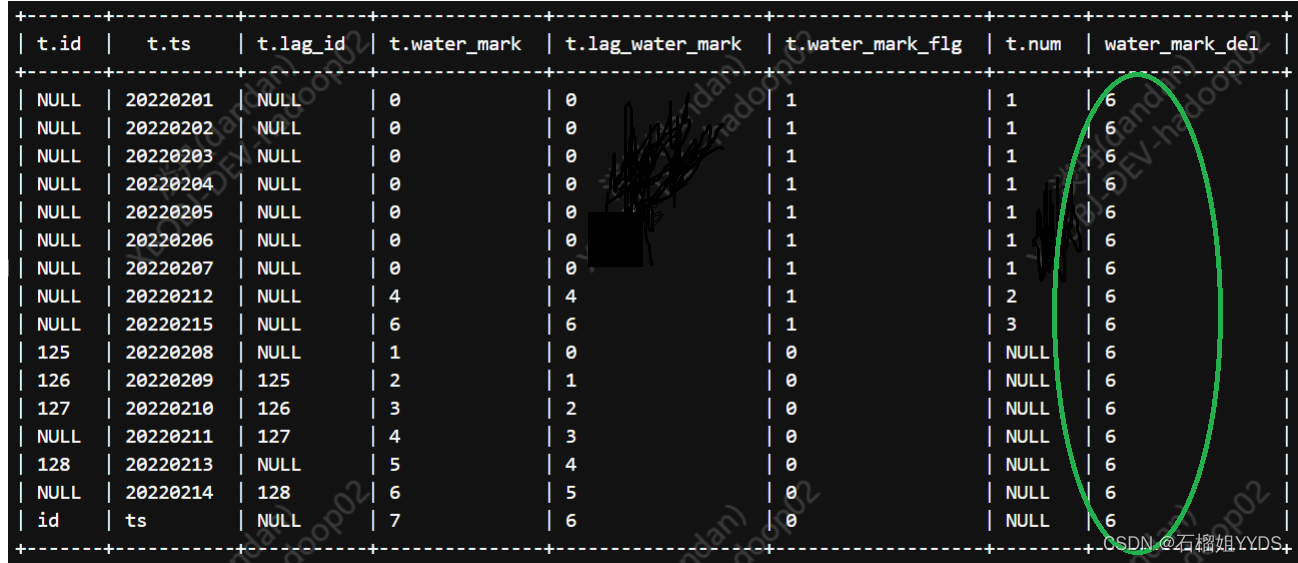
?根据删除标记值,过滤出需要的值:最终SQL如下
select id,ts from( select * ,max(if(num=3,water_mark,null)) over() as water_mark_del --根据传入的次数找出要删除的水位值,利用max()函数获取唯一值 from( select * ,DENSE_RANK() over(order by water_mark) as num --注意此处是对水位进行排名,所以order by后是water_mark而不是ts from( select * ,case when water_mark=lag_water_mark then 1 else 0 end as water_mark_flg --将水位值标记 from( select * ,lag(water_mark,1,water_mark) over(order by ts) as lag_water_mark from( select * ,sum(if(id = 'NULL' and lag_id = 'NULL',0,1)) over(order by ts) as water_mark from( select * ,lag(id,1,id) over(order by ts) as lag_id from test01 ) t ) t )t ) t where water_mark_flg=1 UNION ALL select * ,NULL as num --对于非水位值不进行排名,置为NULL就可以。这就是分而知之的思想 from( select * ,case when water_mark=lag_water_mark then 1 else 0 end as water_mark_flg --将水位值标记 from( select * ,lag(water_mark,1,water_mark) over(order by ts) as lag_water_mark from( select * ,sum(if(id = 'NULL' and lag_id = 'NULL',0,1)) over(order by ts) as water_mark from( select * ,lag(id,1,id) over(order by ts) as lag_id from test01 ) t ) t )t ) t where water_mark_flg=0 ) t )t where water_mark!=water_mark_del order by ts
最终结果如下:
+------------+------------+ | test01.id | test01.ts | +------------+------------+ | id | ts | | NULL | 20220201 | | NULL | 20220202 | | NULL | 20220203 | | NULL | 20220204 | | NULL | 20220205 | | NULL | 20220206 | | NULL | 20220207 | | 125 | 20220208 | | 126 | 20220209 | | 127 | 20220210 | | NULL | 20220211 | | NULL | 20220212 | | 128 | 20220213 | | NULL | 20220214 | | NULL | 20220215 | +------------+------------+
4 小结
????? 本文给出了一种利用水位线思想来解决SQL复杂场景问题的思路和方法,其本质是对sum(xx)over(order by ts)这一函数背后的思想深究和探讨,该函数反映了数据随时间变化的累积情况,当随时间累积到一稳定值时,我们把该稳定值作为水位线,在sql复杂场景中,往往利用该基准值进行分组处理,处理一些持续性、连续性、或在某一时刻点发生转折(变化)的问题,采用该方法可以提高处理问题的可扩展性和通用性,逻辑性更强,看待问题的观点更高一层。