һ��������
����Ⱥ����
����:ʹ��Oracle VM VirtualBox��������̨�����,ʹ��ϵͳCentos(2009)
192.168.1.11 bigdata1
192.168.1.12 bigdata2
192.168.1.13 bigdata3
192.168.1.14 bigdata4
192.168.1.15 bigdata5
ssh���¼������
��ÿ̨�����Ϸֱ�ִ��ssh-keygen -t rsa,һֱ��ס�س�����
��bigdata 192.168.1.11�Ļ����Ͻ��й�Կ���Ӳ���? cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
���������������ɵĹ�Կ������192.168.1.11��~/.sshĿ¼,����id_rsa.pub12��15���ļ�
scp -r ~/.ssh/id_rsa.pub root@192.168.1.11:~/.ssh/id_rsa.pub12?
scp -r ~/.ssh/id_rsa.pub root@192.168.1.11:~/.ssh/id_rsa.pub13
scp -r ~/.ssh/id_rsa.pub root@192.168.1.11:~/.ssh/id_rsa.pub14
scp -r ~/.ssh/id_rsa.pub root@192.168.1.11:~/.ssh/id_rsa.pub15
ִ�������������bigdata1��~/.sshĿ¼��ls,�ɿ��������ļ�
?������ļ��ӵ�authorized_keys��,�ٽ��зַ���
cat id_rsa.pub12 >> authorized_keys
cat id_rsa.pub13?>> authorized_keys
cat id_rsa.pub14?>> authorized_keys
cat id_rsa.pub15?>> authorized_keys
chmod 600 authorized_keys (���ö�д��Ȩ��)
���зַ��IJ���
scp -r ~/.ssh/authorized_keys root@192.168.1.12:~/.ssh
scp -r ~/.ssh/authorized_keys root@192.168.1.13:~/.ssh
scp -r ~/.ssh/authorized_keys root@192.168.1.14:~/.ssh
scp -r ~/.ssh/authorized_keys root@192.168.1.15:~/.ssh
Ϊÿ̨�������� /etc/hosts����
127.0.0.1 ? localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 ? ? ? ? localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.11 bigdata1
192.168.1.12 bigdata2
192.168.1.13 bigdata3
192.168.1.14 bigdata4
192.168.1.15 bigdata5
������װ����
��װJDK����
ÿ̨�����ϰ�װJDK����,JDK�İ汾��jdk8
rpm -ivh jdk-8u321-linux-x64.rpm
���û�������
��ÿ̨������ִ��vim /etc/profile
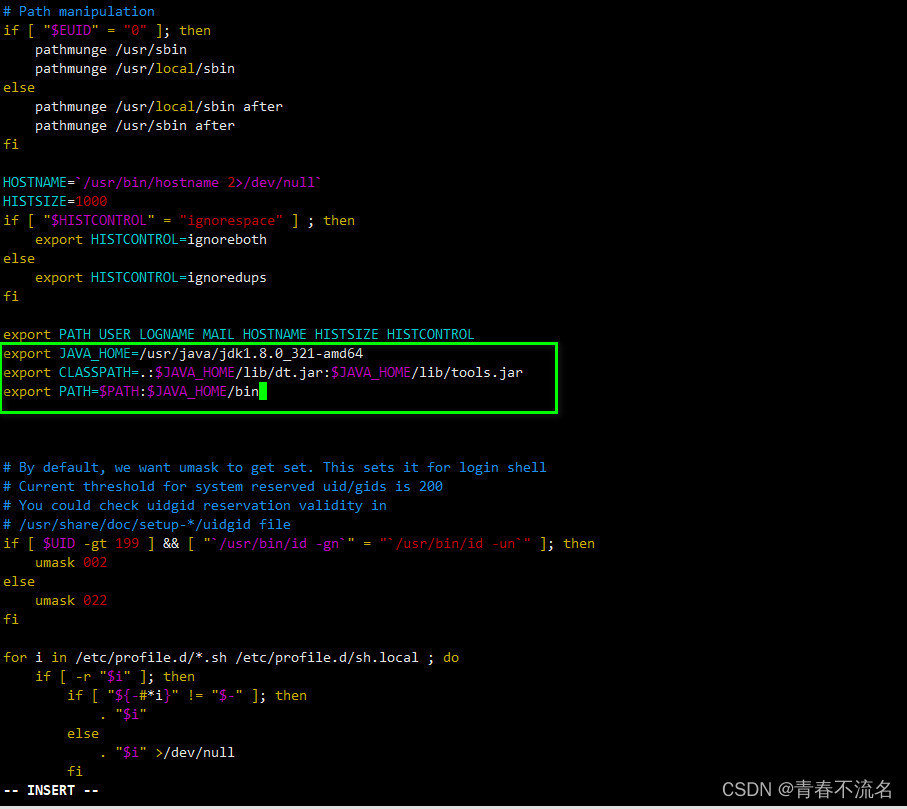
export JAVA_HOME=/usr/java/jdk1.8.0_321-amd64
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
ʹ������Ч
source /etc/profile
��װzookeeper��Ⱥ
��װĿ¼ /home/bigdata
����Zookeeper����װ����
���������ļ�
cp -r /home/bigdata/zookeeper/conf/zoo_sample.cfg /home/bigdata/zookeeper/conf/zoo.cfg
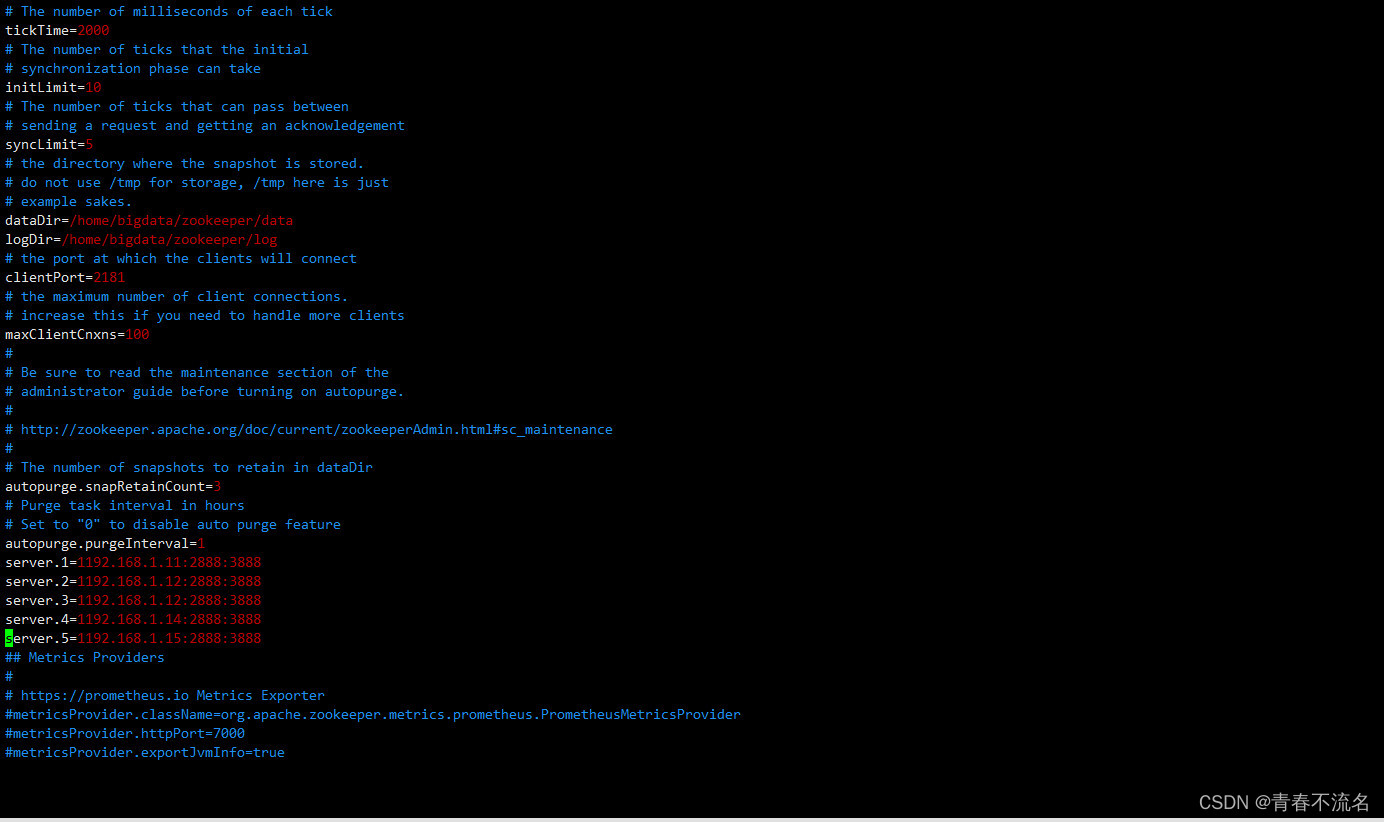
?zoo.cfg������
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial?
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between?
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just?
# example sakes.
dataDir=/home/bigdata/zookeeper/data
dataLogDir=/home/bigdata/zookeeper/logs
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
maxClientCnxns=100
#
# Be sure to read the maintenance section of the?
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
server.1=192.168.1.11:2888:3888
server.2=192.168.1.12:2888:3888
server.3=192.168.1.12:2888:3888
server.4=192.168.1.14:2888:3888
server.5=192.168.1.15:2888:3888
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
�������õ�zookeeperĿ¼���зַ�
scp -r /home/bigdata/zookeeper/ root@192.168.1.12:/home/bigdata/
scp -r /home/bigdata/zookeeper/ root@192.168.1.13:/home/bigdata/
scp -r /home/bigdata/zookeeper/ root@192.168.1.14:/home/bigdata/
scp -r /home/bigdata/zookeeper/ root@192.168.1.15:/home/bigdata/
Ϊÿ̨�����ֱ�����myidֵ
echo "1" > /home/bigdata/zookeeper/data/myid
echo "2" > /home/bigdata/zookeeper/data/myid
echo "3" > /home/bigdata/zookeeper/data/myid
echo "4" > /home/bigdata/zookeeper/data/myid
echo "5" > /home/bigdata/zookeeper/data/myid
����zookeeper�Ļ�������,��/etc/profile��������
export ZOOKEEPER=/home/bigdata/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER/bin
����zk������,��ÿ̨������ִ��
/home/bigdata/zookeeper/bin/zkServer.sh restart
/home/bigdata/zookeeper/bin/zkServer.sh stop
����Ƿ������ɹ�? ? ps -ef | grep zookeeper
�����������ݱ�ʾ�����ɹ�
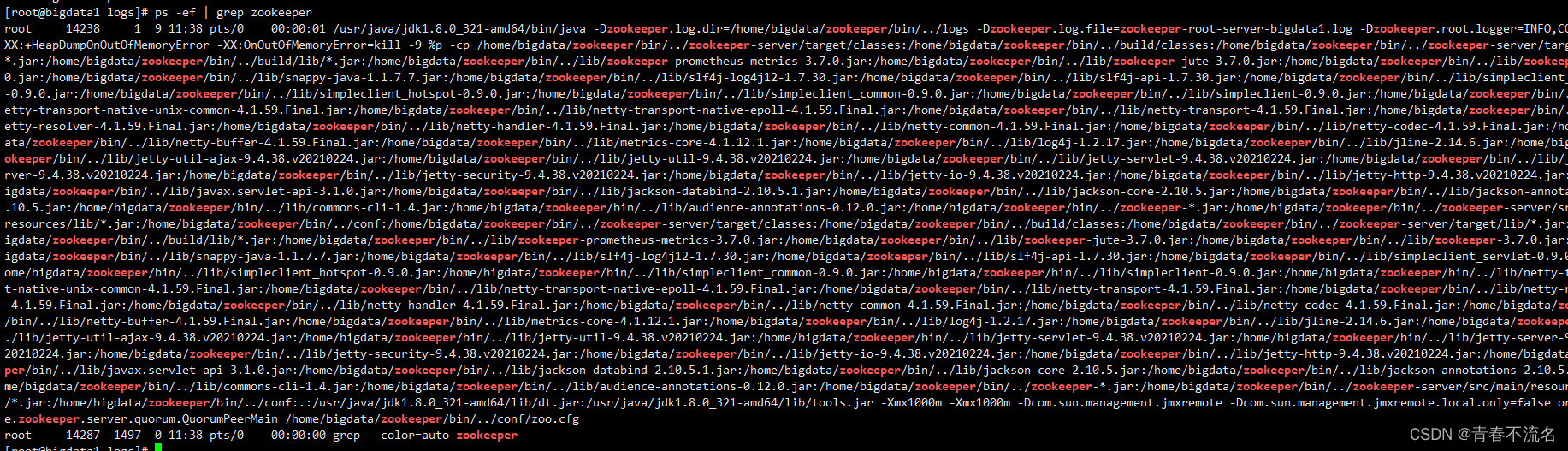
��װhadoop����
������صĻ�������,source /etc/profile
export YARN_NODEMANAGER_USER=root
export YARN_RESOURCEMANAGER_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_NAMENODE_USER=root
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
export JAVA_HOME=/usr/java/jdk1.8.0_321-amd64
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export ZOOKEEPER=/home/bigdata/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER/bin
��ѹhadoop�ļ����������ļ���,ʹ�����µİ汾��3.3.1
tar -zxvf hadoop-3.3.1.tar.gz? && mv hadoop-3.3.1 hadoop
�ٷ�XML�����ļ��ĵ�ַHadoop �C Apache Hadoop 3.3.1
?core-site.xm
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
? Licensed under the Apache License, Version 2.0 (the "License");
? you may not use this file except in compliance with the License.
? You may obtain a copy of the License at
? ? http://www.apache.org/licenses/LICENSE-2.0
? Unless required by applicable law or agreed to in writing, software
? distributed under the License is distributed on an "AS IS" BASIS,
? WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
? See the License for the specific language governing permissions and
? limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<!-- ���������ļ��ĵ�ַ-->
<!-- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml -->
<configuration>
?? ?<property>
?? ??? ?<name>fs.defaultFS</name>
?? ??? ?<value>hdfs://liebe</value>
?? ?</property>
?? ?<property>
?? ??? ?<name>hadoop.tmp.dir</name>
?? ??? ?<value>/home/bigdata/hadoop/tmp</value>
?? ?</property>
?? ?<!--webUIչʾʱ���û�-->
? ? <property>?
? ? ? ? <name>hadoop.http.staticuser.user</name> ? ? ? ? ? ?
? ? ? ? <value>root</value>?
? ? </property>
?? ? <!-- ָ��zookeeper��ַ -->
?? ?<property>
?? ??? ?<name>ha.zookeeper.quorum</name>
?? ??? ?<value>bigdata1:2181,bigdata2:2181,bigdata3:2181,bigdata4:2181,bigdata5:2181</value>
?? ?</property>
?? ?<!-- NN ���� JN ���Դ���,Ĭ���� 10 �� -->
? ? <property>
? ? ? ? <name>ipc.client.connect.max.retries</name>
? ? ? ? <value>20</value>
? ? </property>
? ? <!-- ����ʱ����,Ĭ�� 1s -->
? ? <property>
? ? ? ? <name>ipc.client.connect.retry.interval</name>
? ? ? ? <value>2000</value>
? ? </property>
?? ?<!-- hadoop����zookeeper�ij�ʱʱ������ -->
? ? ?<property>
? ? ? ? ?<name>ha.zookeeper.session-timeout.ms</name>
? ? ? ? ?<value>30000</value>
? ? ? ? ?<description>ms</description>
? ? ?</property>
? ? <property>
? ? ? ? <name>fs.trash.interval</name>
? ? ? ? <value>1440</value>
? ? </property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
? Licensed under the Apache License, Version 2.0 (the "License");
? you may not use this file except in compliance with the License.
? You may obtain a copy of the License at
? ? http://www.apache.org/licenses/LICENSE-2.0
? Unless required by applicable law or agreed to in writing, software
? distributed under the License is distributed on an "AS IS" BASIS,
? WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
? See the License for the specific language governing permissions and
? limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<!-- ���������ļ��ĵ�ַ-->
<!-- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml -->
<configuration>
? <property>
? ? <!-- Ϊnamenode��Ⱥ����һ��services name -->
? ? <name>dfs.nameservices</name>
? ? <value>liebe</value>
? </property>
? <property>
? ? <!-- nameservice ������Щnamenode,Ϊ����namenode���� -->
? ? <name>dfs.ha.namenodes.liebe</name>
? ? <value>cc1,cc2,cc3</value>
? </property>
? <property>
? ? <!-- ?��Ϊcc1��namenode ��rpc��ַ�Ͷ˿ں�,rpc������datanodeͨѶ -->
? ? <name>dfs.namenode.rpc-address.liebe.cc1</name>
? ? <value>bigdata1:8020</value>
? </property>
? <property>
? ? <!-- ��Ϊcc2��namenode ��rpc��ַ�Ͷ˿ں�,rpc������datanodeͨѶ ?-->
? ? <name>dfs.namenode.rpc-address.liebe.cc2</name>
? ? <value>bigdata2:8020</value>
? </property>
? <property>
? ? <!-- ��Ϊcc3��namenode ��rpc��ַ�Ͷ˿ں�,rpc������datanodeͨѶ ?-->
? ? <name>dfs.namenode.rpc-address.liebe.cc3</name>
? ? <value>bigdata3:8020</value>
? </property> ?
? <property>
? ? <!--��Ϊcc1��namenode ��http��ַ�Ͷ˿ں�,web�ͻ��� -->
? ? <name>dfs.namenode.http-address.liebe.cc1</name>
? ? <value>bigdata1:9870</value>
? </property>
? <property>
? ? <!--��Ϊcc2��namenode ��http��ַ�Ͷ˿ں�,web�ͻ��� -->
? ? <name>dfs.namenode.http-address.liebe.cc2</name>
? ? <value>bigdata2:9870</value>
? </property>
? ?<property>
? ? <!--��Ϊcc3��namenode ��http��ַ�Ͷ˿ں�,web�ͻ��� -->
? ? <name>dfs.namenode.http-address.liebe.cc3</name>
? ? <value>bigdata3:9870</value>
? </property>
? <property>
? ? <!-- ?namenode�����ڹ����༭��־��journal�ڵ��б� -->
? ? <!-- ָ��NameNode��editsԪ���ݵĹ����洢λ�á�Ҳ����JournalNode�б�
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ��url�����ø�ʽ:qjournal://host1:port1;host2:port2;host3:port3/journalId
? ? ? ? journalId�Ƽ�ʹ��nameservice,Ĭ�϶˿ں���:8485 -->
? ? <name>dfs.namenode.shared.edits.dir</name>
? ? <value>qjournal://bigdata1:8485;bigdata2:8485;bigdata3:8485/liebe</value>
? </property>
? <property>
? ? <!-- ?journalnode �����ڴ��edits��־��Ŀ¼ -->
? ? <name>dfs.journalnode.edits.dir</name>
? ? <value>${hadoop.tmp.dir}/jn</value>
? </property>
? <property>
? ? <!-- ?�ͻ������ӿ���״̬��NameNode���õĴ����� -->
? ? <name>dfs.client.failover.proxy.provider.liebe</name>
? ? <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
? </property>
? <property>
? ? <!-- ���ø�����Ʒ���,��������û��зָ�,��ÿ����������һ�� -->
? ? <name>dfs.ha.fencing.methods</name>
? ? <value>
? ? ? ? ? ?sshfence
? ? ? ? ? ?shell(/bin/true)
? ? </value>
? </property>
? <!-- ʹ�ø������ʱ��Ҫ ssh ��Կ��¼-->
? ? <property>
? ? ? ? <name>dfs.ha.fencing.ssh.private-key-files</name>
? ? ? ? <value>/home/root/.ssh/id_rsa</value>
? ? </property> ?
? ?<!-- journalnode��Ⱥ֮��ͨ�ŵij�ʱʱ�� -->
? <property>
? ? <name>dfs.qjournal.start-segment.timeout.ms</name>
? ? <value>60000</value>
? </property>
? <!-- ָ�������� -->
? ? <property>
? ? ? ? <name>dfs.replication</name>
? ? ? ? <value>3</value>
? ? </property>
? <!--namenode·��-->
? <property>
? ? ? ? <name>dfs.namenode.name.dir</name>
? ? ? ?<value>file://${hadoop.tmp.dir}/name</value>
? ? </property>
? <!--datanode·��-->
? ? <property>
? ? ? ? <name>dfs.datanode.data.dir</name>
? ? ? ?<value>file://${hadoop.tmp.dir}/data</value>
? ? </property>
? ? <!-- ����NameNodeʧ���Զ��л� -->
? ? <property>
? ? ? ? <name>dfs.ha.automatic-failover.enabled</name>
? ? ? ? <value>true</value>
? ? </property>
? ? <!-- A switch to turn on/off tracking DataNode peer statistics. -->
? ? <property>
? ? ? ? <name>dfs.datanode.peer.stats.enabled</name>
? ? ? ? <value>true</value>
? ? </property>
? ? <!-- The timeout in seconds of calling rollEdits RPC on Active NN. -->
? ? <property>
? ? ? ? <name>dfs.ha.tail-edits.rolledits.timeout</name>
? ? ? ? <value>120</value>
? ? </property>
</configuration>
?
yarn-site.xml
<?xml version="1.0"?>
<!--
? Licensed under the Apache License, Version 2.0 (the "License");
? you may not use this file except in compliance with the License.
? You may obtain a copy of the License at
? ? http://www.apache.org/licenses/LICENSE-2.0
? Unless required by applicable law or agreed to in writing, software
? distributed under the License is distributed on an "AS IS" BASIS,
? WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
? See the License for the specific language governing permissions and
? limitations under the License. See accompanying LICENSE file.
-->
<configuration>
? <property>
? ? <name>yarn.nodemanager.aux-services</name>
?? ?<value>mapreduce_shuffle</value>
? </property>
? <property>
? ? <name>yarn.resourcemanager.auto-update.containers</name>
?? ?<value>true</value>
? </property>
? <property>
? ? <name>yarn.webapp.api-service.enable</name>
?? ?<value>true</value>
? </property>
? ??
? <property>
? ? <name>yarn.log-aggregation-enable</name>
? ? <value>true</value>
? </property>
? <property>
? ? <name>yarn.log-aggregation.retain-seconds</name>
? ? <value>106800</value>
? </property>
? <property>
? ? <!-- ?����resourcemanager��ha���� -->
? ? <name>yarn.resourcemanager.ha.enabled</name>
? ? <value>true</value>
? </property>
? <property>
? ? <!-- ?Ϊresourcemanage ha ��Ⱥ���id -->
? ? <name>yarn.resourcemanager.cluster-id</name>
? ? <value>yarn-liebe</value>
? </property>
? <property>
? ? <!-- ?ָ��resourcemanger ha ����Щ�ڵ��� -->
? ? <name>yarn.resourcemanager.ha.rm-ids</name>
? ? <value>rm1,rm2,rm3</value>
? </property>
? <!-- ========== rm1 ������ ========== -->
? ? <!-- ָ�� rm1 �������� -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.hostname.rm1</name>
? ? ? ? <value>bigdata1</value>
? ? </property>
? ? <!-- ָ�� rm1 �� web �˵�ַ -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.webapp.address.rm1</name>
? ? ? ? <value>bigdata1:8088</value>
? ? </property>
? ? <!-- ָ�� rm1 ���ڲ�ͨ�ŵ�ַ -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.address.rm1</name>
? ? ? ? <value>bigdata1:8032</value>
? ? </property>
? ? <!-- ָ�� AM �� rm1 ������Դ�ĵ�ַ -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.scheduler.address.rm1</name>
? ? ? ? <value>bigdata1:8030</value>
? ? </property>
? ? <!-- ָ���� NM ���ӵĵ�ַ -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.resource-tracker.address.rm1</name>
? ? ? ? <value>bigdata1:8031</value>
? ? </property>
? ? <!-- ========== rm2 ������ ========== -->
? ? <!-- ָ�� rm2 �������� -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.hostname.rm2</name>
? ? ? ? <value>bigdata2</value>
? ? </property>
? ? <property>
? ? ? ? <name>yarn.resourcemanager.webapp.address.rm2</name>
? ? ? ? <value>bigdata2:8088</value>
? ? </property>
? ? <property>
? ? ? ? <name>yarn.resourcemanager.address.rm2</name>
? ? ? ? <value>bigdata2:8032</value>
? ? </property>
? ? <property>
? ? ? ? <name>yarn.resourcemanager.scheduler.address.rm2</name>
? ? ? ? <value>bigdata2:8030</value>
? ? </property>
? ? <property>
? ? ? ? <name>yarn.resourcemanager.resource-tracker.address.rm2</name>
? ? ? ? <value>bigdata2:8031</value>
? ? </property>
? ? <!-- ========== rm3 ������ ========== -->
? ? <!-- ָ�� rm1 �������� -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.hostname.rm3</name>
? ? ? ? <value>bigdata3</value>
? ? </property>
? ? <!-- ָ�� rm1 �� web �˵�ַ -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.webapp.address.rm3</name>
? ? ? ? <value>bigdata3:8088</value>
? ? </property>
? ? <!-- ָ�� rm1 ���ڲ�ͨ�ŵ�ַ -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.address.rm3</name>
? ? ? ? <value>bigdata3:8032</value>
? ? </property>
? ? <!-- ָ�� AM �� rm1 ������Դ�ĵ�ַ -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.scheduler.address.rm3</name>
? ? ? ? <value>bigdata3:8030</value>
? ? </property>
? ? <!-- ָ���� NM ���ӵĵ�ַ -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.resource-tracker.address.rm3</name>
? ? ? ? <value>bigdata3:8031</value>
? ? </property>
? ? <property>
? ? <!-- ?ָ��resourcemanger ha ���õ�zookeeper �ڵ� -->
? ? ? ? <name>yarn.resourcemanager.zk-address</name>
? ? ? ? <value>bigdata1:2181,bigdata2:2181,bigdata3:2181,bigdata4:2181,bigdata5:2181</value>
? ? </property>
? ? <property>
? ? <!-- ?-->
? ? ? ? <name>yarn.resourcemanager.recovery.enabled</name>
? ? ? ? <value>true</value>
? ? </property>
? ? <!-- �ƶ�resourcemanager��״̬��Ϣ�洢��zookeeper��Ⱥ�� -->
? ? <property>
? ? ? ? <name>yarn.resourcemanager.store.class</name>
? ? ? ? <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
? ? </property>
? ? <property>
? ? ? <name>yarn.log.server.url</name>
? ? ? <value>http://bigdata1:19888/jobhistory/logs/</value>
? ? </property>
? ? <!-- ���������ļ̳� -->
? ? <property>
? ? ? <name>yarn.nodemanager.env-whitelist</name>
? ? ? <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLAS
SPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
? ? </property>
? ? <property>
? ? ? <name>yarn.resourcemanager.am.max-attempts</name>
? ? ? <value>5</value>
? ? </property>
? ? <!--
? ? <property>
? ? ? <name>yarn.nodemanager.recovery.enabled</name>
? ? ? <value>true</value>
? ? </property>
? ? <property>
? ? ? <name>yarn.nodemanager.recovery.dir</name>
? ? ? <value>${hadoop.tmp.dir}/yarn-nm-recovery</value>
? ? </property>
? ? <property>
? ? ? <name>yarn.nodemanager.address</name>
? ? ? <value>192.168.1.11</value>
? ? </property>
? ? <property>
? ? ? <name>yarn.nodemanager.hostname</name>
? ? ? <value>bigdata1</value>
? ? </property>
? ? -->
</configuration>
?
workers
bigdata1
bigdata2
bigdata3
bigdata4
bigdata5
?
mapre-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
?? ?<!-- ���� MapReduce Applications -->
?? ?<property>
?? ??? ?<name>mapreduce.framework.name</name>
?? ??? ?<value>yarn</value>
?? ?</property>
?? ?<!-- JobHistory Server ============================================================== -->
?? ?<!-- ���� MapReduce JobHistory Server ��ַ ,Ĭ�϶˿�10020 -->
?? ?<property>
?? ??? ?<name>mapreduce.jobhistory.address</name>
?? ??? ?<value>bigdata1:10020</value>
?? ?</property>
?? ?<!-- ���� MapReduce JobHistory Server web ui ��ַ, Ĭ�϶˿�19888 -->
?? ?<property>
?? ??? ?<name>mapreduce.jobhistory.webapp.address</name>
?? ??? ?<value>bigdata1:19888</value>
?? ?</property>
?
? ? <!-- ���� Map�������ѹ��,snappy-->
? ? <property>
? ? ? ? <name>mapreduce.map.output.compress</name>?
? ? ? ? <value>true</value>
? ? </property>? ? ? ? ? ? ??
? ?<property>
? ? ? ?<name>mapreduce.map.output.compress.codec</name>?
? ? ? ?<value>org.apache.hadoop.io.compress.SnappyCodec</value>
? ? </property>
</configuration>
?
vim /home/bigdata/hadoop/etc/hadoop/hadoop-env.sh
��bigdata1��/home/bigdata/hadoop�ļ��н��зַ�����
scp -r /home/bigdata/hadoop/ root@192.168.1.12:/home/bigdata
scp -r /home/bigdata/hadoop/ root@192.168.1.13:/home/bigdata
scp -r /home/bigdata/hadoop/ root@192.168.1.14:/home/bigdata
scp -r /home/bigdata/hadoop/ root@192.168.1.15:/home/bigdata
Hadoop��Ⱥ������
����ʹ����֤
java.io.IOException: NameNode is not formatted.
rm -rf /home/bigdata/hadoop/tmp/data/*
rm -rf /home/bigdata/hadoop/tmp/name/*
rm -rf /home/bigdata/hadoop/tmp/jn/*
rm -rf /home/bigdata/hadoop/tmp/dfs/data/*
rm -rf /home/bigdata/hadoop/tmp/dfs/dn/*
rm -rf /home/bigdata/hadoop/tmp/dfs/name/*
rm -rf /home/bigdata/hadoop/tmp/dfs/jn/*
rm -rf /home/bigdata/hadoop/tmp/dfs/nn/*
/home/bigdata/hadoop/bin/hdfs namenode -format

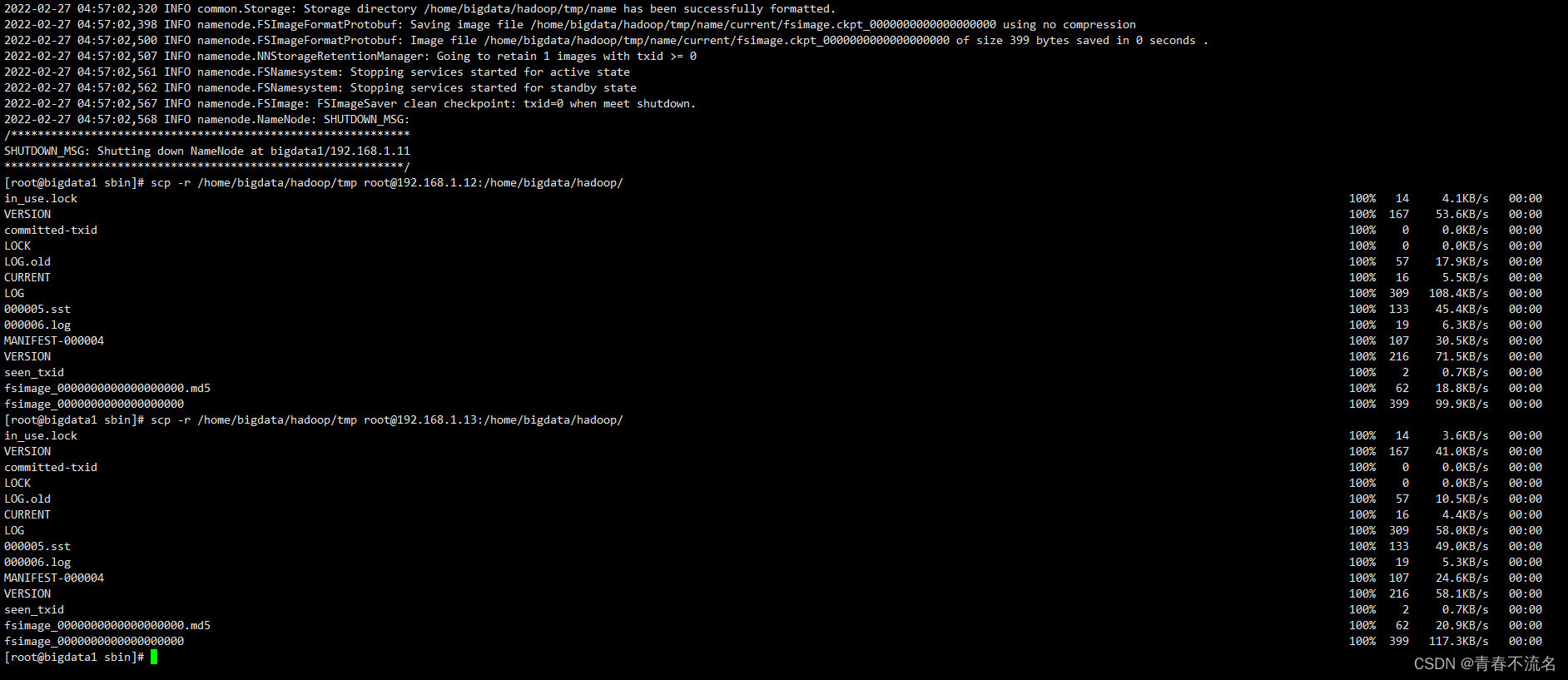
?
?
��װFlink(flink-1.14.3-bin-scala_2.11.tgz)
flink-1.14.3-bin-scala_2.11.tgz ?hadoop ?tool ?zookeeper
�ϴ���װ���ļ������н�ѹ������
��Ҫ���jar�ļ�(9����Ϣ) flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar-Hadoop�ĵ�����Դ-CSDN�Ŀ�
(9����Ϣ) commons-cli-1.5.0.jar-Java�ĵ�����Դ-CSDN�Ŀ�
FLINK��SESSIONģʽ������
/home/bigdata/flink/bin/yarn-session.sh -n 2 -s 2 -jm 512 -tm 512 -nm liebe
�����ļ�flink.conf
################################################################################
# ?Licensed to the Apache Software Foundation (ASF) under one
# ?or more contributor license agreements. ?See the NOTICE file
# ?distributed with this work for additional information
# ?regarding copyright ownership. ?The ASF licenses this file
# ?to you under the Apache License, Version 2.0 (the
# ?"License"); you may not use this file except in compliance
# ?with the License. ?You may obtain a copy of the License at
#
# ? ? ?http://www.apache.org/licenses/LICENSE-2.0
#
# ?Unless required by applicable law or agreed to in writing, software
# ?distributed under the License is distributed on an "AS IS" BASIS,
# ?WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# ?See the License for the specific language governing permissions and
# limitations under the License.
################################################################################
#==============================================================================
# Common
#==============================================================================
# The external address of the host on which the JobManager runs and can be
# reached by the TaskManagers and any clients which want to connect. This setting
# is only used in Standalone mode and may be overwritten on the JobManager side
# by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable.
# In high availability mode, if you use the bin/start-cluster.sh script and setup
# the conf/masters file, this will be taken care of automatically. Yarn
# automatically configure the host name based on the hostname of the node where the
# JobManager runs.
jobmanager.rpc.address: localhost
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The total process memory size for the JobManager.
#
# Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead.
jobmanager.memory.process.size: 1600m
# The total process memory size for the TaskManager.
#
# Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.
taskmanager.memory.process.size: 1728m
# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.
# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
#
taskmanager.memory.flink.size: 1280m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
# The default file system scheme and authority.
#?
# By default file paths without scheme are interpreted relative to the local
# root file system 'file:///'. Use this to override the default and interpret
# relative paths relative to a different file system,
# for example 'hdfs://mynamenode:12345'
#
# fs.default-scheme
#==============================================================================
# High Availability �߿��õ�����
#==============================================================================
# The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
#? ���ø߿���ģʽ,����Ĭ��ѡ�ÿ�����zookeeper
high-availability: zookeeper
# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#?
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)?
# �����ļ�ϵͳ�Ĵ洢,����ʹ�õ�HDFS(��Ҫ��): JobManager Ԫ���ݳ־û����ļ�ϵͳ?high-#availability.storageDir?���õ�·����,������ ZooKeeper ��ֻ����һ��Ŀ¼ָ���λ�á�
high-availability.storageDir: hdfs://liebe/flink/ha/
# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
#?(��Ҫ��):?ZooKeeper quorum?��һ���ṩ�ֲ�ʽЭ������ĸ����顣
high-availability.zookeeper.quorum: bigdata1:2181,bigdata2:2181,bigdata3:2181,bigdata4:2181,bigdata5:2181
ÿ��?addressX:port?ָ����һ�� ZooKeeper ������,�����Ա� Flink �ڸ����ĵ�ַ�Ͷ˿��Ϸ��ʡ�
high-availability.zookeeper.path.root?(�Ƽ���):?ZooKeeper ���ڵ�,��Ⱥ�����нڵ㶼���ڸýڵ��¡�
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id?(�Ƽ���):?ZooKeeper cluster-id �ڵ�,�ڸýڵ��·��ü�Ⱥ�����Э�����ݡ�
high-availability.cluster-id: /default_ns # important: customize per cluster
��Ҫ: �� YARN��ԭ�� Kubernetes ��������Ⱥ������������ʱ,��Ӧ���ֶ����ô�ֵ������Щ�����,���Զ�����һ����Ⱥ ID�������δʹ�ü�Ⱥ�������Ļ��������ж�� Flink �߿��ü�Ⱥ,�����Ϊÿ����Ⱥ�ֶ����õ����ļ�Ⱥ ID(cluster-ids)��
# ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# The default value is "open" and it can be changed to "creator" if ZK security is enabled
#
# high-availability.zookeeper.client.acl: open
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled. Checkpointing is enabled when execution.checkpointing.interval > 0.
#
# Execution checkpointing related parameters. Please refer to CheckpointConfig and ExecutionCheckpointingOptions for more details.
#
# execution.checkpointing.interval: 3min
# execution.checkpointing.externalized-checkpoint-retention: [DELETE_ON_CANCELLATION, RETAIN_ON_CANCELLATION]
# execution.checkpointing.max-concurrent-checkpoints: 1
# execution.checkpointing.min-pause: 0
# execution.checkpointing.mode: [EXACTLY_ONCE, AT_LEAST_ONCE]
# execution.checkpointing.timeout: 10min
# execution.checkpointing.tolerable-failed-checkpoints: 0
# execution.checkpointing.unaligned: false
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#
# state.backend: filesystem
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#
# state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
# Default target directory for savepoints, optional.
#
# state.savepoints.dir: hdfs://namenode-host:port/flink-savepoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).?
#
# state.backend.incremental: false
# The failover strategy, i.e., how the job computation recovers from task failures.
# Only restart tasks that may have been affected by the task failure, which typically includes
# downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption.
jobmanager.execution.failover-strategy: region
#==============================================================================
# Rest & web frontend
#==============================================================================
# The port to which the REST client connects to. If rest.bind-port has
# not been specified, then the server will bind to this port as well.
#
rest.port: 8081
# The address to which the REST client will connect to
#
rest.address: 0.0.0.0
# Port range for the REST and web server to bind to.
#
#rest.bind-port: 8080-8090
# The address that the REST & web server binds to
#
rest.bind-address: 0.0.0.0
# Flag to specify whether job submission is enabled from the web-based
# runtime monitor. Uncomment to disable.
web.submit.enable: true
# Flag to specify whether job cancellation is enabled from the web-based
# runtime monitor. Uncomment to disable.
web.cancel.enable: true
#==============================================================================
# Advanced
#==============================================================================
# Override the directories for temporary files. If not specified, the
# system-specific Java temporary directory (java.io.tmpdir property) is taken.
#
# For framework setups on Yarn, Flink will automatically pick up the
# containers' temp directories without any need for configuration.
#
# Add a delimited list for multiple directories, using the system directory
# delimiter (colon ':' on unix) or a comma, e.g.:
# ? ? /data1/tmp:/data2/tmp:/data3/tmp
#
# Note: Each directory entry is read from and written to by a different I/O
# thread. You can include the same directory multiple times in order to create
# multiple I/O threads against that directory. This is for example relevant for
# high-throughput RAIDs.
#
io.tmp.dirs: /tmp
# The classloading resolve order. Possible values are 'child-first' (Flink's default)
# and 'parent-first' (Java's default).
#
# Child first classloading allows users to use different dependency/library
# versions in their application than those in the classpath. Switching back
# to 'parent-first' may help with debugging dependency issues.
#
# classloader.resolve-order: child-first
# The amount of memory going to the network stack. These numbers usually need?
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, the default max is 1GB.
#?
taskmanager.memory.network.fraction: 0.1
taskmanager.memory.network.min: 64mb
taskmanager.memory.network.max: 1gb
#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================
# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL
# The below configure how Kerberos credentials are provided. A keytab will be used instead of
# a ticket cache if the keytab path and principal are set.
# security.kerberos.login.use-ticket-cache: true
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# security.kerberos.login.principal: flink-user
# The configuration below defines which JAAS login contexts
# security.kerberos.login.contexts: Client,KafkaClient
#==============================================================================
# ZK Security Configuration
#==============================================================================
# Below configurations are applicable if ZK ensemble is configured for security
# Override below configuration to provide custom ZK service name if configured
# zookeeper.sasl.service-name: zookeeper
# The configuration below must match one of the values set in "security.kerberos.login.contexts"
# zookeeper.sasl.login-context-name: Client
#==============================================================================
# HistoryServer
#==============================================================================
# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
jobmanager.archive.fs.dir: hdfs://liebe/flink/jobmanager-completed-jobs/
# The address under which the web-based HistoryServer listens.
historyserver.web.address: 0.0.0.0
# The port under which the web-based HistoryServer listens.
historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
historyserver.archive.fs.dir: hdfs://liebe/flink/historyserver-completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
historyserver.archive.fs.refresh-interval: 10000
?
rm -rf /home/bigdata/zookeeper/data/version-2/ /home/bigdata/zookeeper/data/zookeeper_server.pid?
ѡ��Resource��Active�ĵĽڵ�����Yarn Session Flink

/home/bigdata/flink/bin/yarn-session.sh -n 2 -s 2 -jm 512 -tm 512 -nm liebe
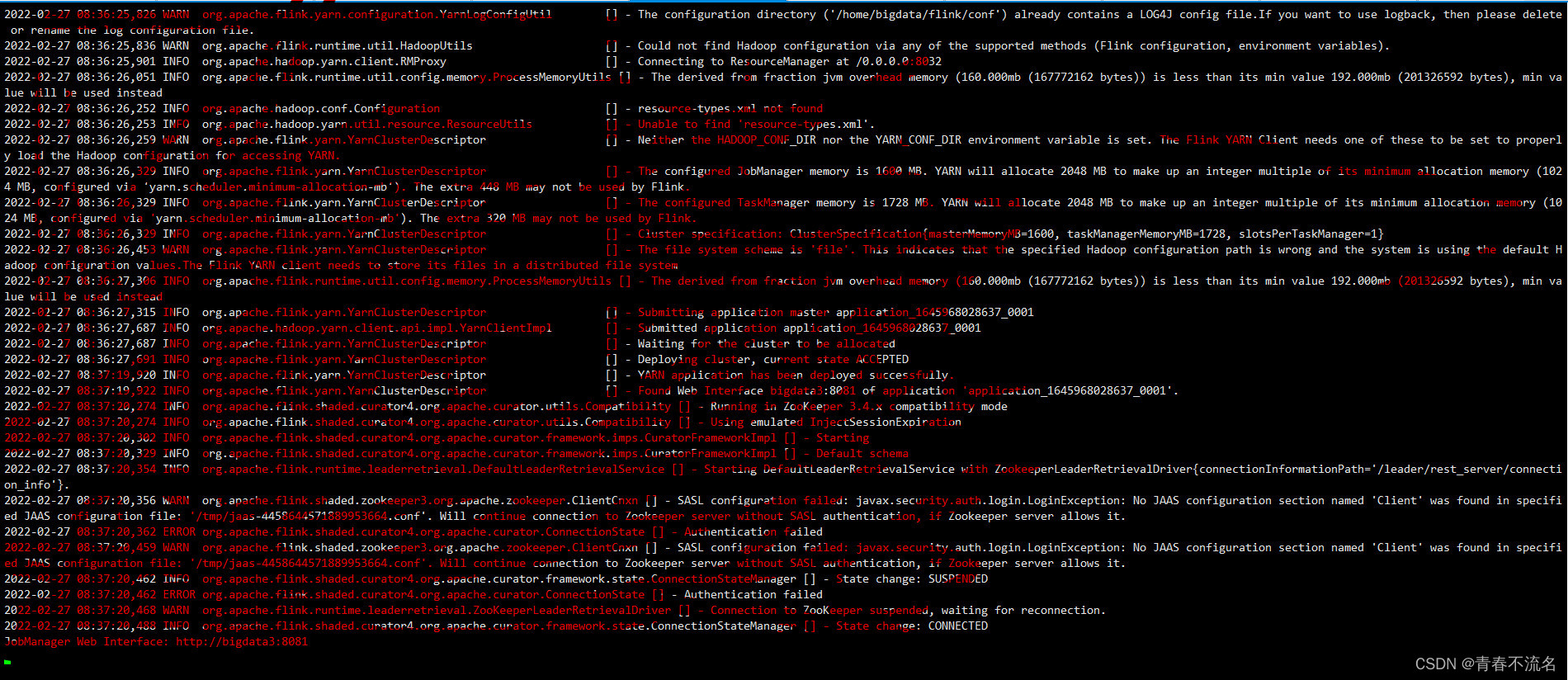
?Flink UI����ҳ��ҳ��