һ������ػ���
1����������������
Hadoop-2.7.3.tar.gz
Hadoop-2.7.3-winutils.exe.rar

2����Hadoop-2.7.3-winutils.exe.rar��ѹ��,���е������ļ����п���
Hadoop.dll
Wintuils.exe

3����Hadoop-2.7.3.tar.gz��ѹ��,�ҵ�binĿ¼,������������ļ�Hadoop.dll��Wintuils.exe��������ǰλ��

4������Hadoop�Ļ�������

5���ҵ�Hadoop�е���־�ļ�log4j.properties�����������½���Eclipse�е�Maven��Ŀ��,�����־�ļ��Ƿ�������ʹ�õ�,����Ҫд̫�������,ֱ�ӽ���Hadoop���ļ�����,Ҳ�����Լ���������־�ļ�,��д��������ݡ�
(1)Hadoop����־�ļ���λ��

(2)������Eclipse����Ŀ��λ��

���������д
1����дMapper

2����дReduce

3�������

4�����в���,���������ȴ�һ��JAR��


5���ҵ�����������Ŀ����

6�������ϴ������ǵ��������

7���ϴ����ǵIJ����ļ�,�����ļ����ı��ṹ����,�����Լ���д,�м�ʹ�ÿո�����ġ�
hello everyone
hello hadoop
hello hadoop
hello hive
go home
come on

8����������һ��


9�����Dz鿴һ�������,���к�Ľ��

10����������鿴һ���ı�����

��������ͳ������
(һ)����
1������ͳ�Ƶ���ͳ��һ���ļ��е��ʳ��ֵĴ���,�������������Դ

2������,���ճ��ֵĴ������Ӧ�����������ʾ

(��)��ô��MapReduce�и���α�д���벢�������ս��?
�������ǰ��ļ��ϴ���HDFS��(hdfs dfs �Cput ��)
��������:data.txt,����size��2G
(��)��һ������
1��������������ʾ�������ݴ�ŵĿ�

2��Ȼ������data.txt����map��,����<K,V>(KV��)����ʽ����,K��ʾ����:ÿ������ĸ������ļ�ͷ���ֽ�ƫ����,V��ʾ����ÿһ�е��ı���

3����ô�ҿ�����ͼ��ʾ:��ɫ����Բ���ʾһ��map,��������ݿ��ڽ���map�ε�ʱ��,���ݵ���ʽΪ��ߺ�ɫ��<K,V>(KV��)����ʽ

4������map����,����String.split(����),��һ�δ���,���ݻ��ڲ�ͬ�ĺ�������ݿ��б�Ϊ�����KV��ʽ


5������������Hadoop��ʱ�������reduce������,����������reduce
Mapִ��������ݻ�ŵ���Ӧ��reduce��,����ͼ

6������ط���һ����ԭ������
Job.setNumReduce������reduce������
��HashPartioner��������� key.hashcode % reduce�Ľ��,����ͬ��map������뵽��ͬ��reduce��,����a-e��ͷ�ķŵ�һ���ط�,e-z��ͷ�ķŵ�һ���ط�,��ô


7�����������ݽ���ͻ���


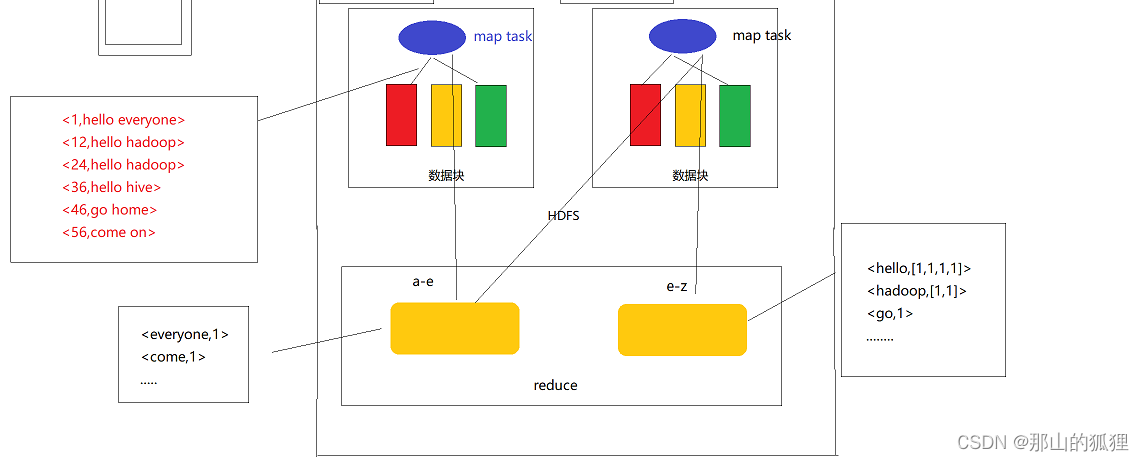
���ճ���������Ҫ�Ľ��,ͳ�����
�ġ���ϰ
1����������:data.txt���ı�����:
hello everyone
hello hadoop
hello hadoop
hello hive
go home
come on
2����Ŀ���õ�pom�ļ�
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
? xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
? <modelVersion>4.0.0</modelVersion>
? <groupId>com.xlglvc.xx.mapredece</groupId>
? <artifactId>wordcount-client</artifactId>
? <version>0.0.1-SNAPSHOT</version>
? <packaging>jar</packaging>
? <name>wordcount-client</name>
? <url>http://maven.apache.org</url>
?<properties>
??? <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
??? <maven.compiler.source>1.7</maven.compiler.source>
??? <maven.compiler.target>1.7</maven.compiler.target>
? </properties>
? <dependencies>
??? <dependency>
????? <groupId>junit</groupId>
????? <artifactId>junit</artifactId>
????? <version>4.11</version>
????? <scope>test</scope>
??? </dependency>
???
??? <dependency>
????? <groupId>org.apache.hadoop</groupId>
????? <artifactId>hadoop-client</artifactId>
????? <version>2.7.3</version>
??? </dependency>
? </dependencies>
? <build>
??? <pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
????? <plugins>
??????? <plugin>
????????? <artifactId>maven-clean-plugin</artifactId>
? ????????<version>3.0.0</version>
??????? </plugin>
??????? <!-- see http://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
??????? <plugin>
????????? <artifactId>maven-resources-plugin</artifactId>
????????? <version>3.0.2</version>
??????? </plugin>
??? ????<plugin>
????????? <artifactId>maven-compiler-plugin</artifactId>
????????? <version>3.7.0</version>
??????? </plugin>
??????? <plugin>
????????? <artifactId>maven-surefire-plugin</artifactId>
????????? <version>2.20.1</version>
??????? </plugin>
???? ???<plugin>
????????? <artifactId>maven-jar-plugin</artifactId>
????????? <version>3.0.2</version>
??????? </plugin>
??????? <plugin>
????????? <artifactId>maven-install-plugin</artifactId>
????????? <version>2.5.2</version>
??????? </plugin>
??????? <plugin>
????????? <artifactId>maven-deploy-plugin</artifactId>
????????? <version>2.8.2</version>
??????? </plugin>
????? </plugins>
??? </pluginManagement>
? </build>
</project>3��Mapper�ļ�
package com.xlglvc.xx.mapredece.wordcount_client;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>
{
? protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
??? throws IOException, InterruptedException
? {
??? Text keyout = new Text();
??? IntWritable valueout = new IntWritable(1);
??? String line = value.toString();
??? String[] words = line.split(" ");
??? for (String word : words) {
????? keyout.set(word);
????? context.write(keyout, valueout);
??? }
? }
}4��Reducer�ļ�:
package com.xlglvc.xx.mapredece.wordcount_client;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>
{
? protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
??? throws IOException, InterruptedException
? {
??? IntWritable valueout = new IntWritable();
??? int count = 0;
??? for (IntWritable value : values)
??? {
????? count += value.get();
??? }
??? valueout.set(count);
??? context.write(key, valueout);
? }
}5����������WordCountDriver
package com.xlglvc.xx.mapredece.wordcount_client;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver
{
? public static void main(String[] args)
??? throws IOException, ClassNotFoundException, InterruptedException
? {
??? Configuration conf = new Configuration();
??? Job job = Job.getInstance(conf);
??? job.setJarByClass(WordCountDriver.class);
??? FileInputFormat.addInputPath(job, new Path(args[0]));
??? FileOutputFormat.setOutputPath(job, new Path(args[1]));
??? job.setMapperClass(WordCountMapper.class);
??? job.setReducerClass(WordCountReducer.class);
??? job.setMapOutputKeyClass(Text.class);
??? job.setMapOutputValueClass(IntWritable.class);
??? job.setOutputKeyClass(Text.class);
??? job.setOutputValueClass(IntWritable.class);
??? boolean result = job.waitForCompletion(true);
??? System.exit(result ? 0 : 1);
? }
}6����������������,������֮ǰ��ͬ��