系列文章目录
hadoop大数据-HDFS分布式文件系统hadoop大数据-HDFS分布式文件系统
一、hadoop简介
大数据主要两个点:分布式存储以及分布式计算,基本上计算的调度跟着存储走,因为迁移存储的成本高于计算
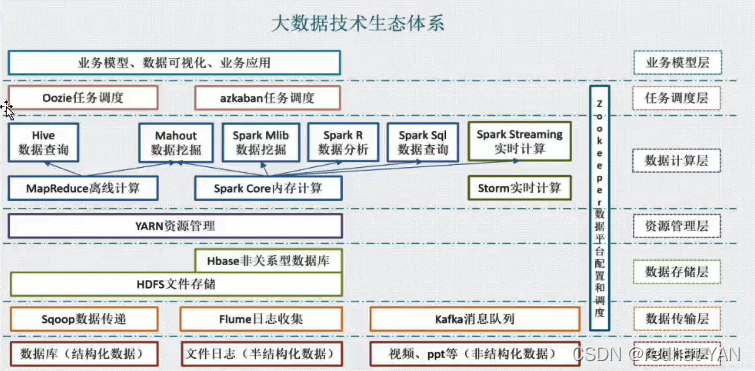
大数据是个生态,本次学习Hadoop的HDFS分布式文件系统
MapReduce离线计算
GFS演变成最底层的HDFS,整个上层的生态应用都是连得HDFS

CDH和HDP对于软件的兼容性和稳定性以及图形化的管理(帮你找到组件最优的搭配)
纯原生Apache,组件很多,你可能找不到最合适的组件搭配方法

分布式计算就是对海量数据的数据挖掘,从海量数据之间找到它们之间的联系,将有用的数据过滤出来存到关系型数据库中
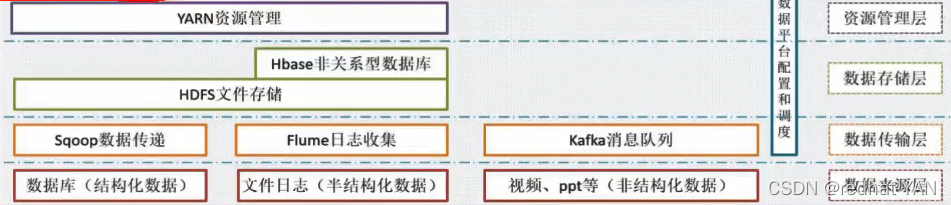
Hadoop YARN 模块:整个分布式集群Hadoop大数据平台,开发人员提交计算任务,这些计算任务如何调度、监控、管理由该模块来处理(调度资源的模块)
集群的性能与管理器有着非常大的关系


运维主要在这块负责业务,上面模块主要是开发负责
整个生态由运维来维护
hadoop用法与Mfs不一样,它是通过api的方式来使用的
二、Hadoop的搭建
官网:hadoop.apache.org
 用普通用户部署
用普通用户部署


做软链接方便,升级也方便,直接修改软链接就行
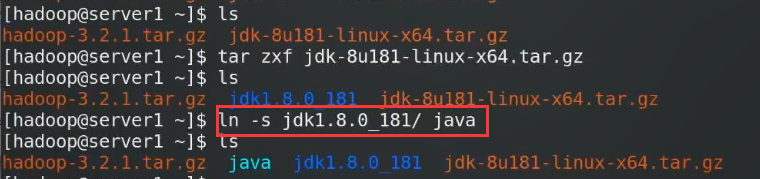


进入这个路径

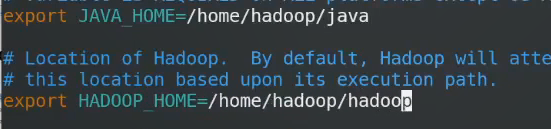
修改hadoop的环境变量

告诉其java_home和hadoop_home的位置
hadoop部署分为3种:
本地独立模式
伪分布式模式
全分布式模式
2.1本地独立模式

启动hadoop

input存放准备录入的数据

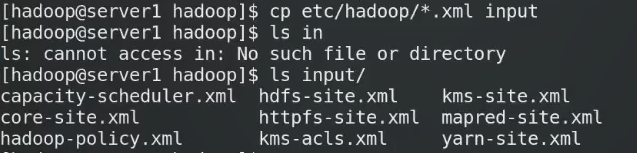
output是输出目录,input目录提前创建,但是Output不要提前创建

2.1伪分布式模式的搭建
伪分布式模式:节点只有一个,运作方式是分布式的

首先需要配置免密,因为通过免密登录work结点启动hadoop相应的进程



在这个路径下
里面定义的是Master

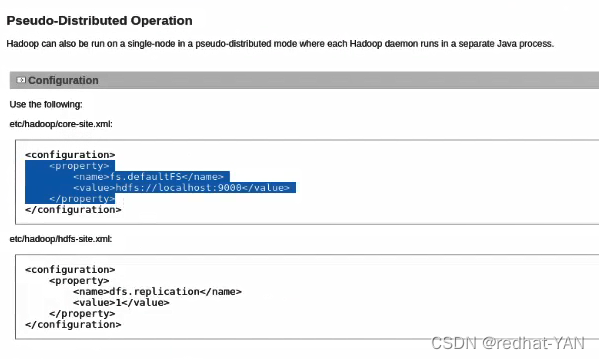
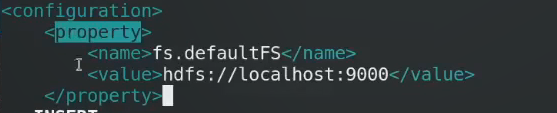
Localhost是master,这块地址时HDFS的master地址
ssh localhost ssh server1 都需要免密

在这个路径下
master和worker在一个节点上面

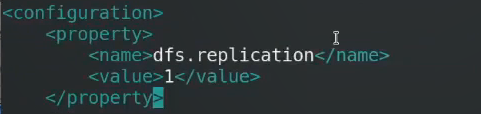
修改其副本数,默认情况下是3个

本地只有1个结点,所以副本数只能设置为1
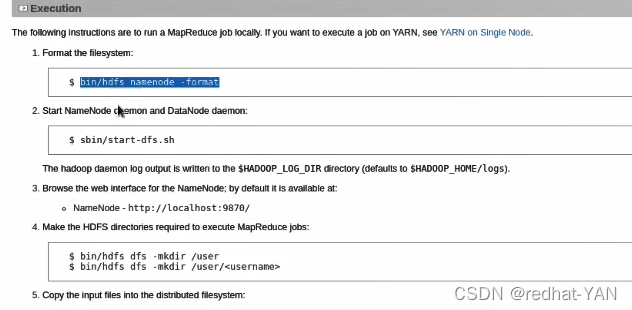
做格式化在二进制命令那块

如果没有指定,默认的数据目录

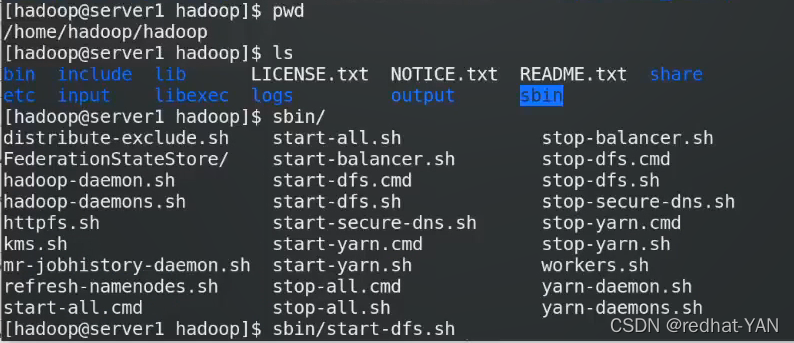
启动脚本,该路径放了很多脚本,该脚本dfs.sh只启动HDFS相关的脚本
java的进程


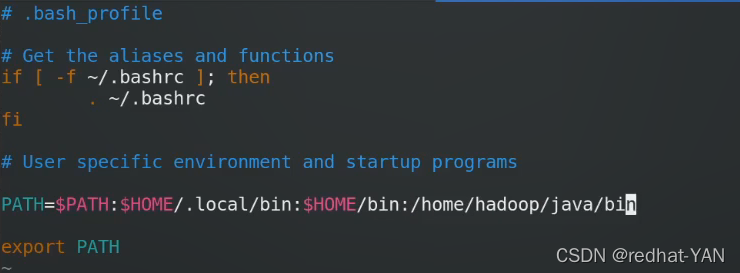

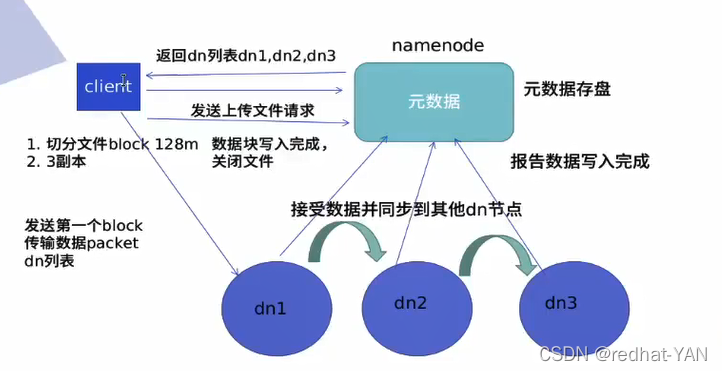
HDFS分布式,NAMENODE就是master,secondarynamenode是主节点故障后接管(可以帮主节点定期做元数据日志的合并,生成新的镜像文件),所有数据结点上的进程就叫datanode
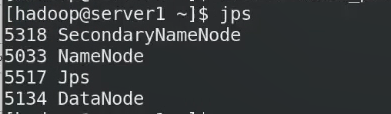

自带图形化的接口
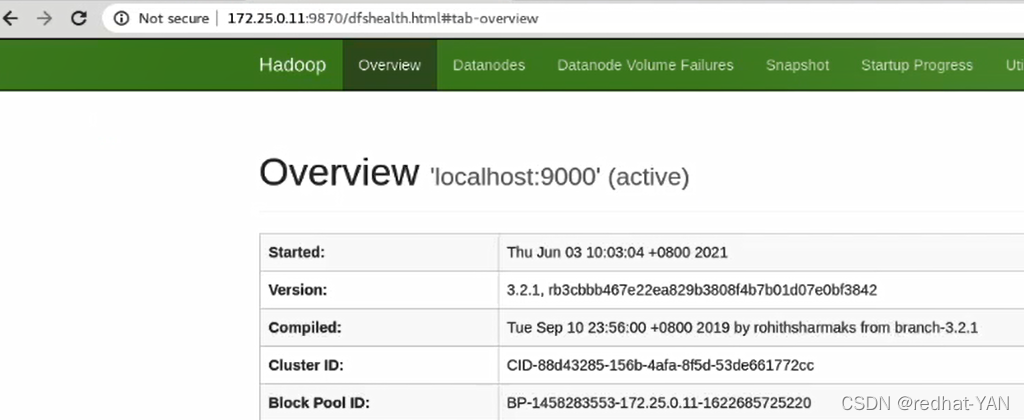
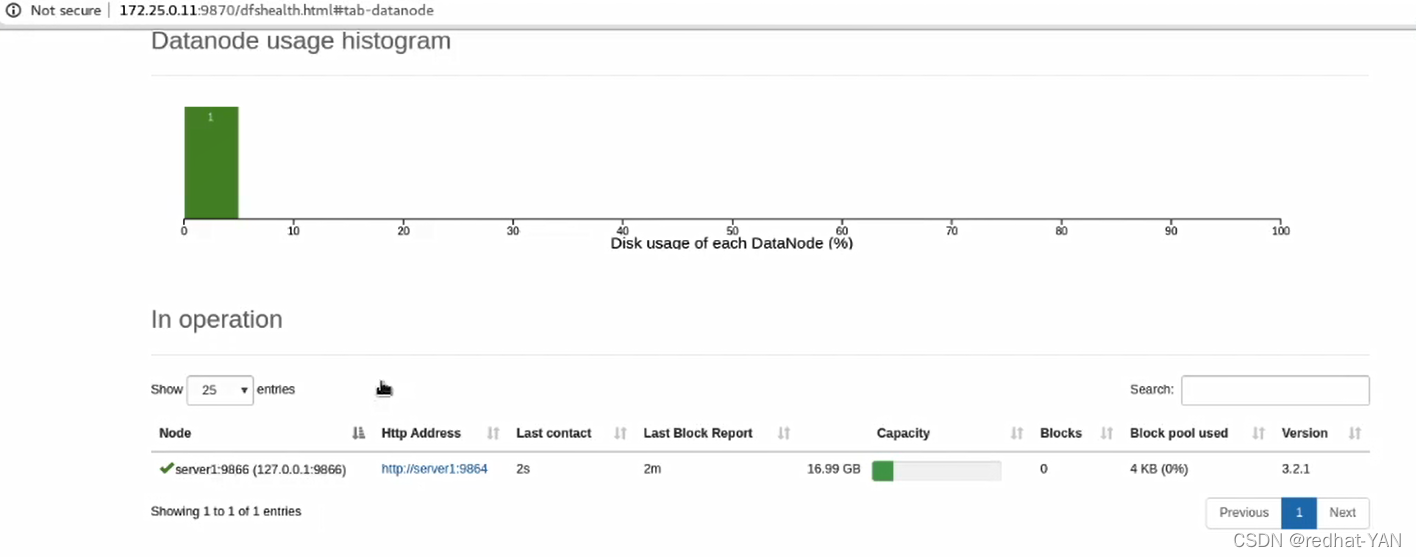
指令的用法

查看分布式文件系统的概况

默认情况下,没有家目录


该目录创建在分布式文件系统中
上传input目录

一旦称为分布式后,数据来源,存是分布式系统存,取也是分布式系统取,所有Input和output目录没有用了
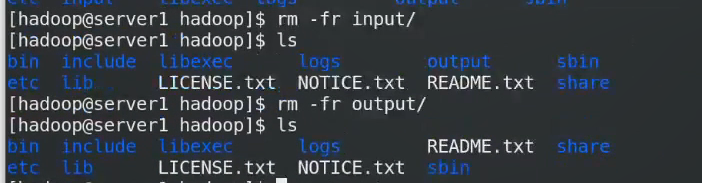
统计input里面的词频输出到output,input ouput已经删掉了,所以它们读取的时候都是读取的分布式文件系统里面的

没有存到本机output,因为整个运作都是分布式的

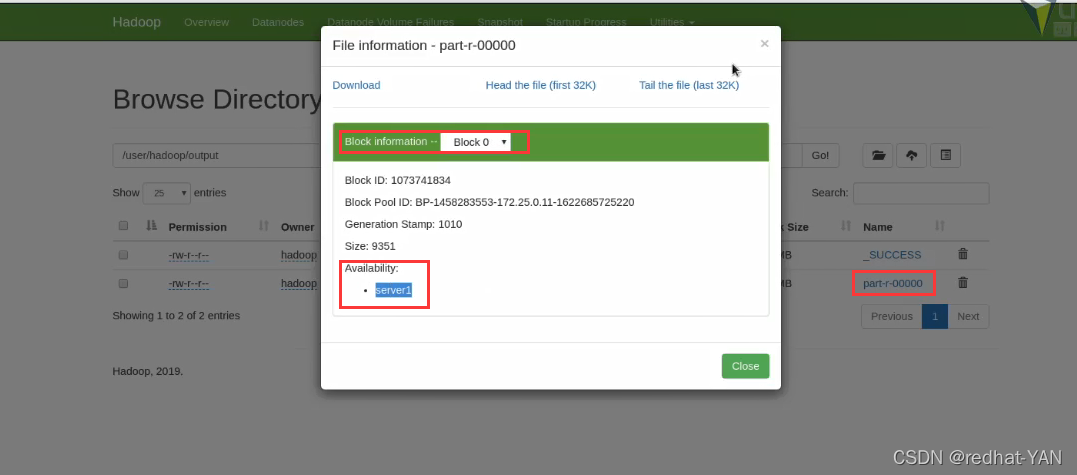
Replication副本数
block size 是可以设定的
存在block0,在结点1上面


将output从分布式文件系统下载出来
 还原环境:
还原环境:

三、完成分布式的搭建
完全分布式的环境搭建
分布式文件系统一定要全平台一致
需要3个虚拟机,server1为master,server2\3是worker结点
所有结点的配置要一样
如何实现同步?nfs共享
通过该方式都不需要配置java hadoop环境变量都一样
在server1\2\3安装这个nfs套件



将所有往里面写的都映射成为1000,这样保证所有结点的权限是一致的


server2/3都要创建这个用户,都是第一个用户,所以都是1000,id一定要一致,全平台一致

在结点2和3都挂载这个目录


而且结点1/2/3免密,因为把这个用户目录挂载过去了,公钥私钥都一样

避免冲突将原先的数据删掉

完全分布式的配置
进入这个路径

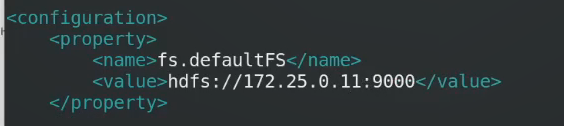
写主机名字必须有解析

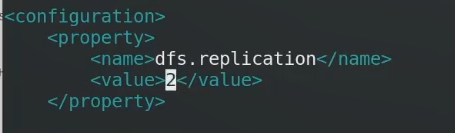
两个数据结点,副本可以设置为2

格式化


启动服务
在1启动namenode在2/3通过免密启动相应的进程


上传数据默认会传入用户主目录/user/hadoop


 比单机版伪分布式快,因为有2个结点
比单机版伪分布式快,因为有2个结点

四、hadoop结点扩容
再开启一个虚拟机4



进入这个路径


下线在配置文件加入这个参数

文件名自己指定

宿主机要加解析
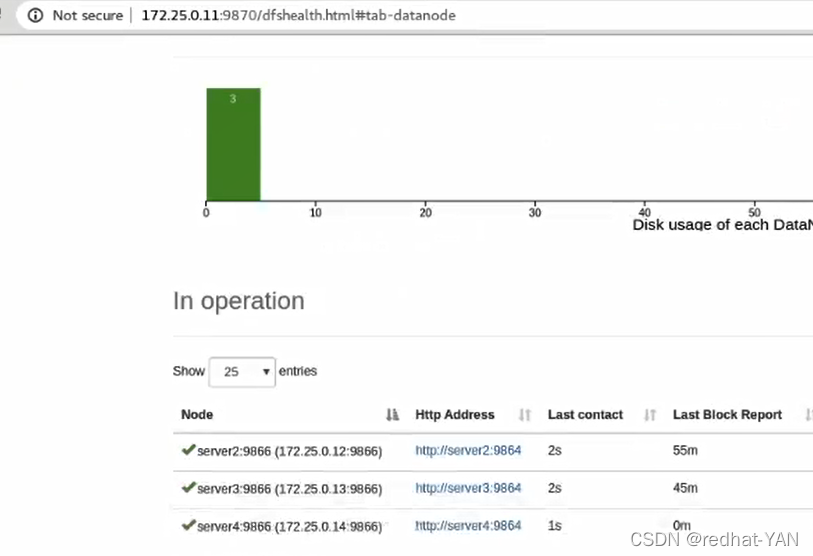
刷新结点

server2将数据迁移到其他结点并且下线
强制server2下线

五、HDFS工作原理
CS结构
集群默认是3个副本
由于HDFS block大些所以小文件适合Mfs,大文件适合HDFS,内存的占用和文件数量有关和大小无关,小文件多的话会造成内存负担大
HDFS不适合随时更改文件
mfs适合随时更改,挂载上去,随时都可以改


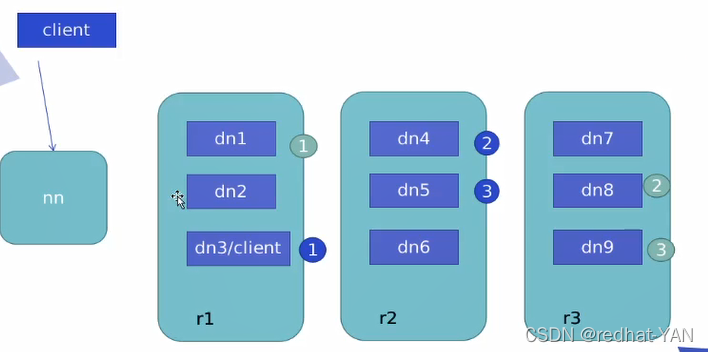
副本会存入离主机最近的地方
 列表顺序:
列表顺序:
客户端和dn不在同一节点,hadoop有机架感应机制,第一个副本随机存入一个机架,第二个第三个副本存入不是第一个副本的机架的不同dn上面
客户端和dn在同一节点,第一个副本存在本机,第二个第三存在不同第一个机架的不同dn上面
根据顺序发挥列表
漫画图解原理:https://cloud.tencent.com/developer/article/1481758
六、hadoop分布式计算
重启server2作为dn

进入这个路径

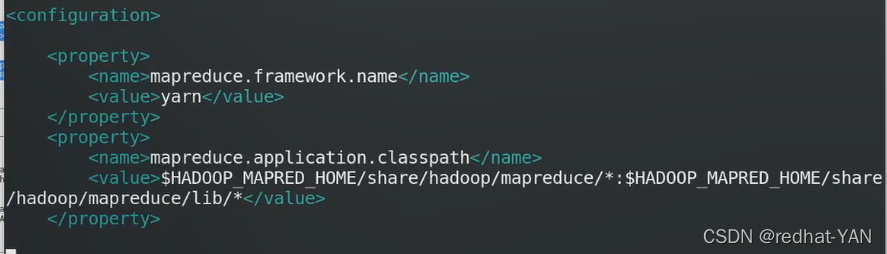

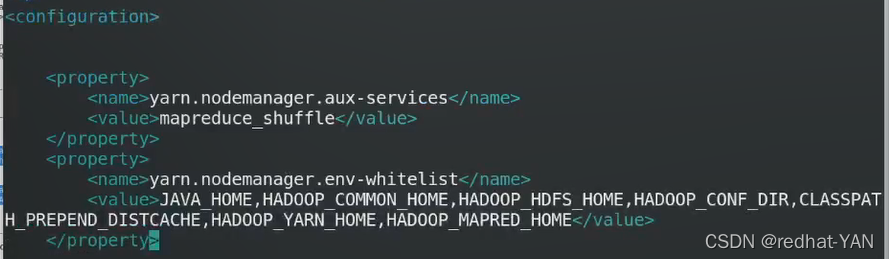
启动脚本
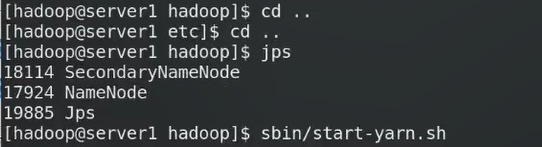
RM资源管理器,NN上开启RM
NM结点管理器,所有dn都会开启NM
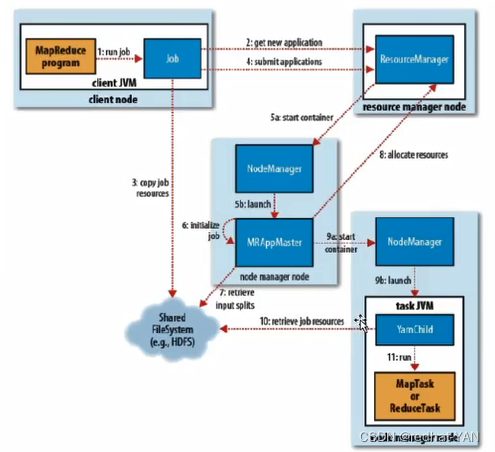
客户端就是开发人员所用的开发工具
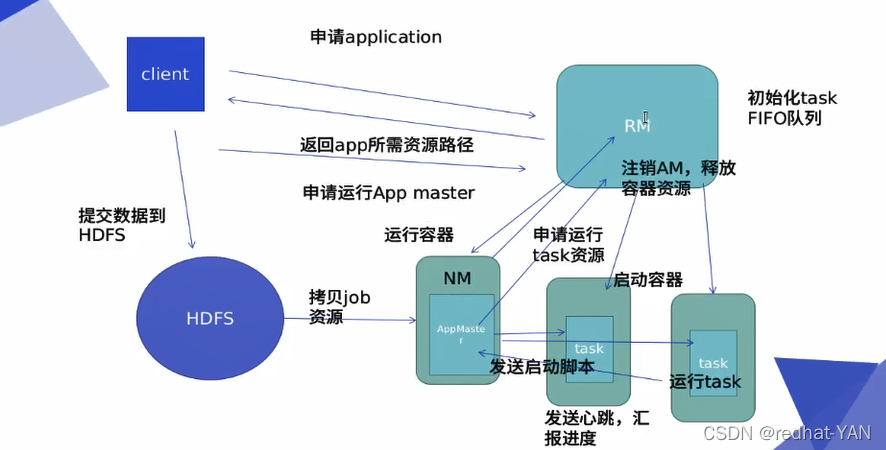
七、hadoop高可用部署
7.1hadoop高可用部署条件及原理
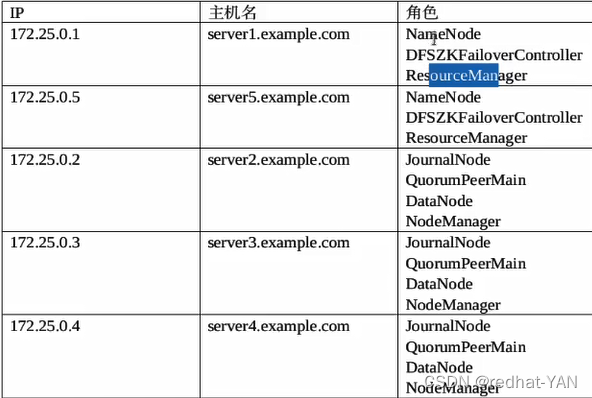
需要5台虚拟机
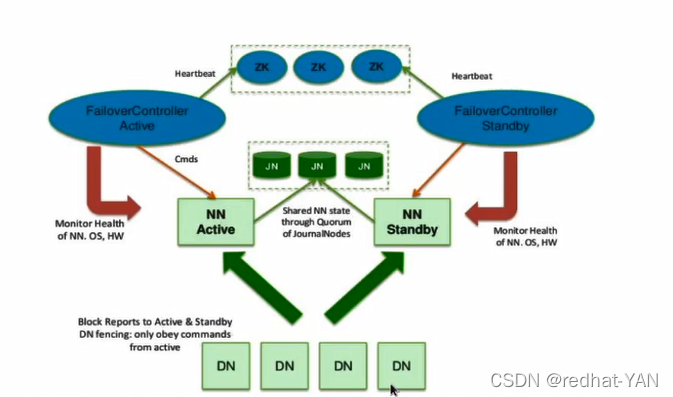
NN和RS都是单点,NN挂了(所有原数据记录),hadoop就挂了
hadoop官方自带的hadoop高可用套件
启动高可用后,SN就不再启动了
网上的文档下载到本地

底下的hadoop

实际生产NN和RM不在同一机器上,都是资源消耗多的
7.2hadoop高可用部署环境
环境:
停用所有相关进程


全部停掉

不要当前的数据对以后的集群造成影响








在server1上面做,因为server1是NFS输出端,其它结点做还是会回传回来,慢
1和5做高可用,234做zookeeper集群jn日志结点dn和NM
7.3zookeeper集群的部署
所有结点必须有解析
首先部署3台zookeeper

主配置文件zoo.cfg


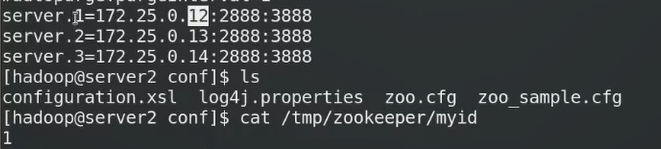
.1.2.3是服务器的编号

第一个端口号是Leader和follower通信,Leader是随机选举的

在结点2/3/4都这样做,id对应2/3/4


id同步
启动服务

同理2/3/4




监听端口2181

7.4hadoop的配置
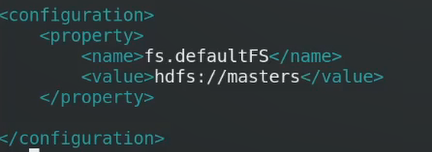
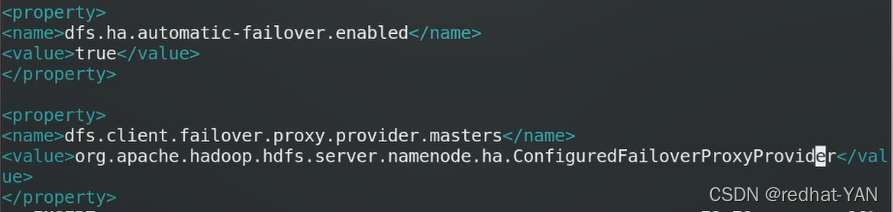
hadoop集群只能有一个master

进入这个路径

不能写一个固定的Ip,要写一个浮动的
谁是当前的master是由zk集群确定的


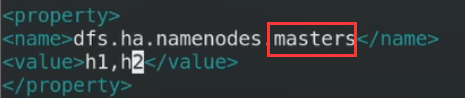
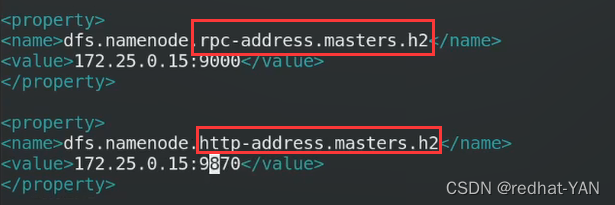
这个masters和刚才修改的NN的名字保持一致,masters


Msater的机器叫h1h2,这个可以自己定义,都是masters要注意


图形化接口9870

IP


NN共享存储,但是是分布式的

日志结点2/3/4端口8485




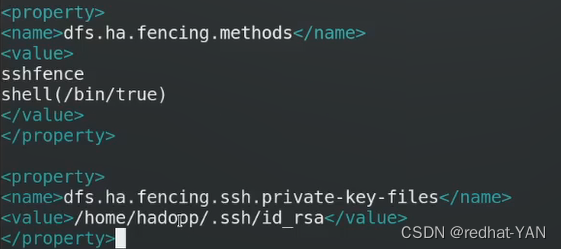



在server2/3/4

启动成功
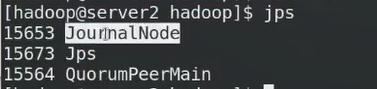





格式化zk

通过免密也启动5

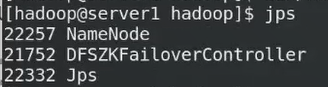
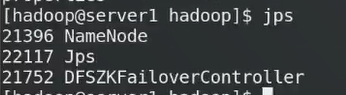
21752是故障切换器
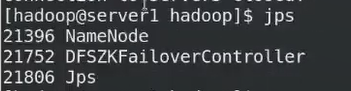
Leader查看谁是master(原数据)

谁先向zk注册谁是active master
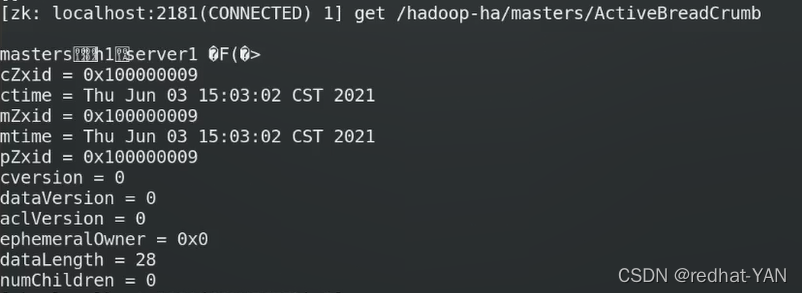
7.5高可用测试
主机
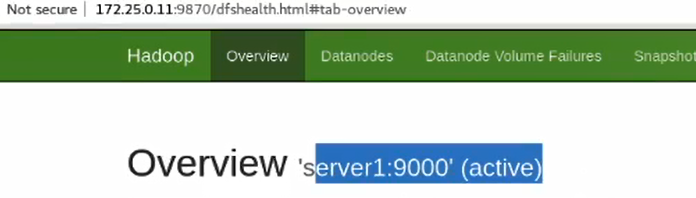
备机
 热备机制完成
热备机制完成
用法和之前一样

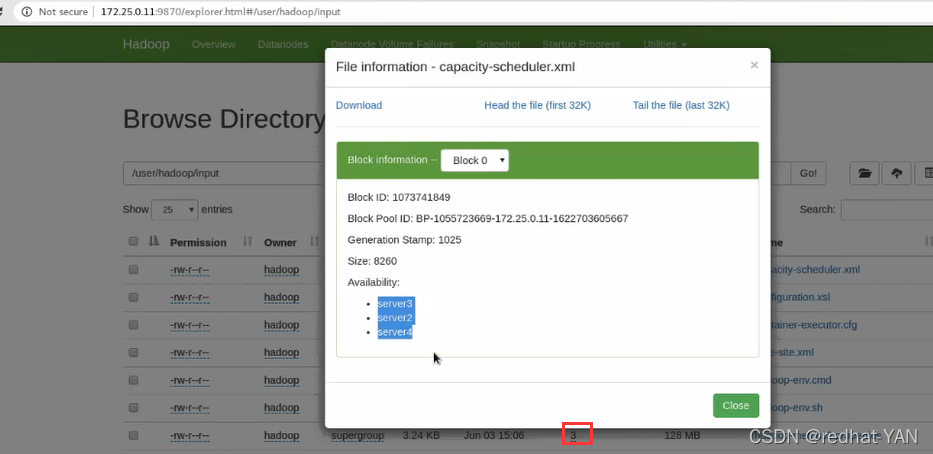

部分截图

部分截图
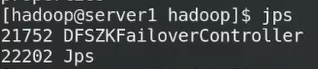
高可用部署成功
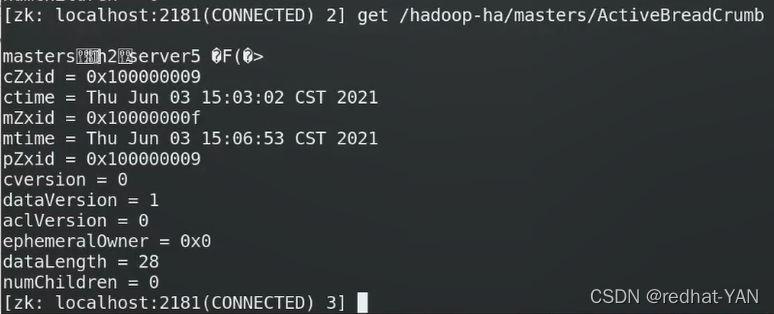
恢复