作者简介: 田逸飞(义博):OceanBase高级开发工程师
一、SQL 执行流程
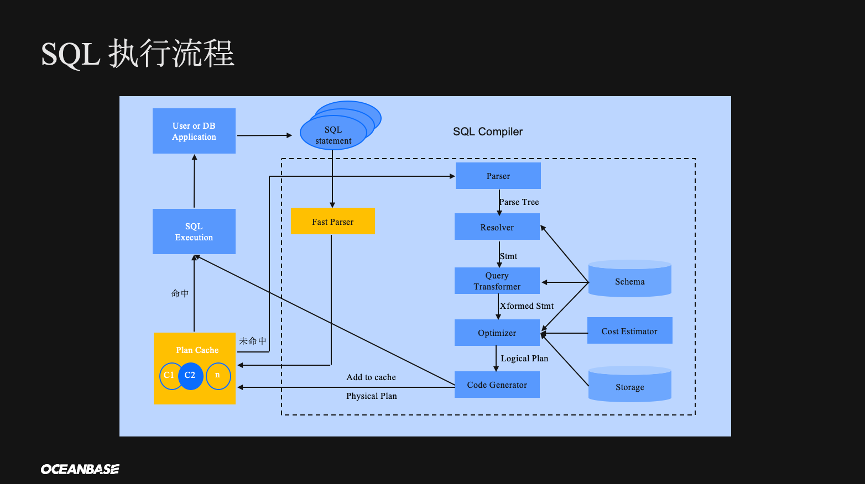
SQL?发送到?OBServer?后,会先由 OBServer 对其进行快速参数化,参数化后的?SQL?进入 Plan Cache 尝试命中计划缓存。
如果找到一个可以使用的计划,则直接将计划交由 SQL?的执行引擎去执行,并将执行完成后的结果返回给用户;如果没有找到可以使用的计划,则会重新为此 SQL?生成计划,完整地执行?SQL?的?Parser、Resolver、Transformer、Optimizer、Code Generator 流程,然后生成一个可用的物理计划,并交由执行引擎执行,同时此计划会被加入到计划缓存,以便后续的?SQL?重新使用。

流程中的 Parser 主要负责语法词法的解析,它会将用户输入的 SQL?基于?lax?和?yacc?生成一个Parse Node Tree,如上图右侧所示,它将用户的?SQL?拆成了一个树状结构,同时做了一些语法解析。使用?OB?时候的语法报错通常就是在?Parser层。
?Resolver?负责对 Parse Node Tree 做语义的分析,主要包括语句的解析、中缀表达式的生成、表达式的类型推导等,并最终将其转化成?OB?在代码中更易于操作的数据结构。

Transformer 负责在确保执行结果相同且正确的情况下,对?SQL 做等价的变换,将其转化成一个对于数据库来说更友好的?SQL?。
举个例子,假设用户写了一个外连接为?L LEFT JOIN R ON L.ID=R.ID ,同时在?R.C2 列上有一个过滤条件 R.C2=XXX。对于外连接来说,如果左侧的一行没能连接到右侧的任意一行,则会输出左侧的一行,并且在右侧列上补 NULL 。
但是因为?where?里面的过滤条件,所有补 NULL 产生的 R 全部会被过滤掉,所以它的效果等价于 inner join?。因此,在这种场景下,Transformer?会把外连接改成内连接。上述全部改动都是基于OB statement?结构做的,而不是直接去改用户的?SQL?。
当?Transformer?将statement?进行了等价的变换之后,statement?会被交给 Optimizer?做查询的优化。Optimizer?优化器主要负责为?SQL?生成一组可选的逻辑计划,并从中选出一个优化器认为最优的计划。生成计划的过程会涉及到路径的选择、连接顺序的选择、连接算法的选择,以及一些分布式计划的生成等。

选出最优计划之后,即得到了一个逻辑计划。但是逻辑计划是无法直接用来执行的,而是需要一个?Code Generator?模块将其翻译成执行引擎能够识别执行的物理计划。Code Generator 会遍历整个逻辑计划,将其中的每一个逻辑算子翻译成物理算[MOU1]?子,最后物理计划会被交给执行引擎实际执行。
OceanBase 的执行引擎使用的是火山模型,它是数据库系统里面一个非常经典且成熟的执行模型。
二、计划缓存
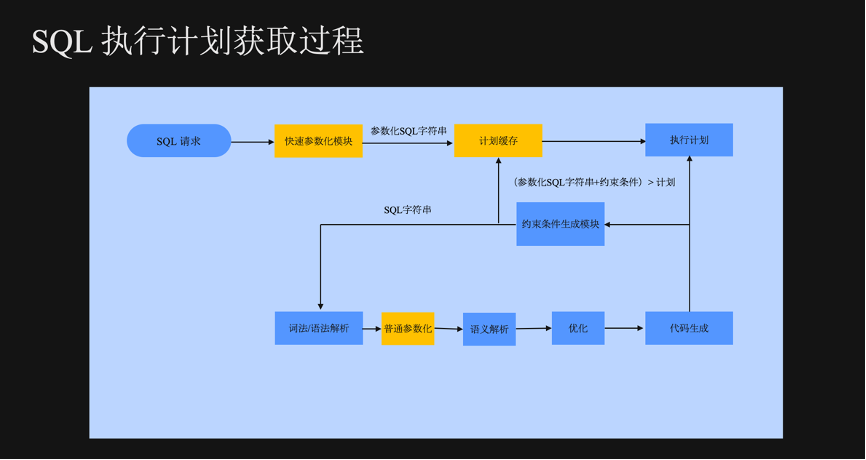
上图是 SQL?计划的获取过程。
前文提到,SQL 会尝试去命中计划缓存,如果能够命中,则直接执行;否则,需要执行一系列流程去生成一个最终的执行计划。
而这一系列流程比较耗时,大概需要毫秒级甚至更久。但是如果走计划缓存,耗时只需要几十到几百微秒。大多数场景下,一条?SQL 完整地执行下来只需要几毫秒,而如果生成计划就已经占了几毫秒,对业务来说是完全无法接受的。
因此,减少这一部分的开销至关重要。

?OceanBase 的计划缓存有两种匹配模式。
①???Force 模式,也是?OB?默认的匹配模式。?
????Force 模式下,首先会对 SQL 里面的常量进行参数化,再对参数化后的计划进行匹配。
????什么是参数化呢?如上图右侧SQL语句,?select c1,c2 from t1 where c1=1,这里的1?是一个常量。参数化就是将常量替换成一个通配符“?”。所以参数化之后,这条 SQL 就变成了 select c1,c2 from t1 where c1=?。
参数化之后,文本与此条 SQL 一样的 SQL 都可以共享一个计划。比如这里?where C1=1、C1=2、C1=3的语句都可以共用同一个执行计划。但它的不足之处在于?SQL?命中的计划可能并不是一个最优的执行计划。
依然以上述 SQL 为例,假设对于 t1 中,c1=1?的值占了1%,c1=0?的值占了99%,即表里的c1?只有?1?和?0?两个取值。
假设一开始计划缓存是空,先来了一个?c1=1?的?SQL,就会用这条?SQL?去生成计划。如果c1=1?的过滤性非常好的,则会选一个走?c1?索引的计划,相当于在?c1?的索引上做一次扫描,然后做索引回表,并将计划缓存到计划缓存中。但是如果之后来了一个?c1=0?的?SQL,那么它就会命中刚刚生成的计划走索引扫描。但是对于?c1=0的条件,索引其实不是最优的,
因为它不能过滤掉大量数据。索引扫描完成后它还有?99%?的数据要做索引回表。在这种场景下,索引往往不如基表扫描快。
②???Exact?模式。
Exact模式下,做计划匹配的时候不会做参数化,而是直接用原始的?SQL?去做匹配,匹配的时候要求?SQL?的文本完全相同。比如大小写、空格的数量以及参数都要相同才能共享计划。
它的优点在于不同的参数都能选到自己最优的计划。不足之处也非常明显――计划的命中率非常低。比如通过主键去查找表里某一行具体的数据,主键在表中的每一个值都是不同的,也就意味着它们都无法共享计划,每一个主键值都要重新生成一次计划,这就导致计划的命中率非常低。而且大量的计划会导致计划缓存的内存会大幅膨胀。
因此,一般情况下,推荐使用?force?模式。
可以通过设置系统变量 cursor_sharing=exact/force?来控制选择哪个模式,也可以通过 Hint:/*CURSOR_SHARING_EXACT*/ 去强制某一个?SQL 使用 exact?模式。

上图展示了一些计划共享的例子。
第一组?SQL 参数化之后都会变成?select c1,c2 from t1 where c1=? and c2 =?。它们参数化后的?SQL 文本是相同的,因此可以共享计划。
第二组?SQL 参数化之后变成了select c1,c2 from t1 where c1=??order by??。
但实际上它们的语义是不一样的,第一条?order by 1,意味着要对?select?里的第一列做排序,而第二条意味着要对 select?里的第二列做排序。如果它们共享计划,两个结果一定会出现问题。
为了防止这样错误的共享计划,OceanBase 提供了一个添加约束的方式。比如对于第一条 SQL ,要求?order by=1?的时候才能使用它生成的计划,同理对于第二条 SQL 会要求 order by=2?的时候才能使用它生成的计划。
第三组?SQL 参数化之后会变成select c1,c2 from t1 where c1=? and?? = ?。而它在?OB?中也是无法共享计划的。因为1 = 1是一个恒true的条件,而?1 = 2?是一个恒?false?的条件。对于这种恒true、恒false?的条件,OB在改写优化的过程中会对其做一些特殊处理,简化这些计划的生成过程和生成的计划。一旦不同的恒true、恒false条件共享了计划,也会导致一些结果错误。
对于上述场景,?OceanBase 也会抽取出约束。比如对于第一条 SQL,它会要求第二个参数等于第三个参数的计算结果是?true?的时候才能共享这条 SQL 产生生成的计划;对于第二条SQL,它会要求第二个参数等于第三个参数的计算结果是?false?的时候才能共享第二条?SQL 产生的计划。
第四组?SQL 的问题在于 select 的大小写不同,因此也不能共享计划。

在数据库中,数据是不断地发生变化的,计划也不可能永远一成不变,某一个时间生点生成的计划也不一定永远是最好的计划。因此要在合适的时机对原有的一些缓存中的计划进行淘汰,并重新生成计划。
目前?OceanBase 在以下场景中会执行一些计划淘汰:
①???执行计划依赖的对象的?schema?版本发生变化。比如做了任意的?DDL?操作,会导致表的?schema version?被推高,因此需要将所有依赖于表的执行计划全部淘汰掉,并重新生成计划。
②???统计信息发生改变。目前?OceanBase 的统计信息发生改变的时机主要有两个,一是 Major 合并或用户手动执行了?major Freeze,存储层会执行数据的合并,并收集一些统计信息;二是用户手动执行了?Analyze?命令,然后数据库主动地去收集统计信息。
③???计划自动/手动淘汰机制。计划的自动淘汰主要与计划缓存的内存管理有关,比如计划缓存的内存占用到了高水位线,就会执行自动淘汰,使内存使用保持在低水位线。手动淘汰指通过人工运维的方式,去手动地清掉一些计划。
三、SQL 诊断????
????使用数据库的时候,用户需要知道数据库里一些运行着的?SQL?的数据,比如分布式数据库这么多机器,SQL 请求的流量是否均匀?比如想找到某一段时间内消耗?CPU?比较多的?SQL,看一看有没有优化空间?或者 SQL 数据库在正常运行突然发生抖动,是由哪些?SQL 引起的?基于诸如此类的种种需求,OceanBase 提供了 SQL 诊断视图。

首先,最常用的视图是?[G]V$SQL_AUDIT?视图,它记录了每一次?SQL?请求的来源、执行状态以及统计信息。每个机器的每个租户各自独立管理?SQL_AUDIT?记录。
其中 GV$SQL_AUDIT?的含义是查出每一台机器上的?SQL_AUDIT 记录,而 V$SQL_AUDIT?是查出连接的这台?server?的?SQL_AUDIT?记录。
使用?OB server?的时候往往不是直接访连接到?OBserver,而是通过?OBproxy?连接。
如果是查询?V$SQL_AUDIT?,无法确定请求会被路由到哪一台机器上。所以如果想查询某一台机器上的?SQL_AUDIT 记录,一定要直连到要这台机器,或者查询?GV$SQL_AUDIT?然后通过指定机器的?IP?与端口号来访问具体机器的记录。
?SQL_AUDIT?是维护在内存中的,因此它的数据不可能无限地存放。所以当内存到达一定限制的时候,会触发一些淘汰机制,以保证新的记录能够写进去。SQL_AUDIT 采用先进先出的自动淘汰机制,内存到达高水位线(90%)的时候会自动触发淘汰,直至内存达到低水位线(50%)。
除了基于内存水位线的淘汰,SQL_AUDIT 还有一个淘汰策略,当?SQL_AUDIT?的记录达到?900?万条的时候会触发淘汰,一直淘汰到记录剩?500?万条为止。此限制与编码的实现有关,后续如果改进一些内部结构,可能会把限制去掉。
此外,SQL_AUDIT 提供了一个集群级的配置项?enable_sql_audit 和一个租户级的配置项 ob_enable_sql_audit,只有这两个配置项都为?true?的时候,SQL_AUDIT?才会生效,否则为关闭状态。

上图是 SQL_AUDIT 里的重要字段及含义。
l???SVR_IP、SVR_PORT 表示数据库的?IP?与端口号。
l???SID?表示当前SQL?所在的?session?的?ID。通过?session ID?可以查出所有从 某个session?上发出的请求。
l???TRACE_ID?表示SQL?的?trace_id,它是?OB?里用来跟踪一条?SQL?执行过程的唯一?ID?。比如可以使用trace_id?从?OB?的日志中找到所有与SQL?执行相关的记录,也可以通过它去其他视图中关联一些想要的结果。
l???SQL_ID?表示SQL的?ID, 它是一条?SQL?的唯一标识符。需要注意的是,SQL_ID?的生成是基于参数化之后的?SQL?,因此只要两条?SQL?参数化之后的文本相同,则它的?SQL_ID?也相同。?
l???QUERY_SQL?表示SQL?的原始文本,即没有经过参数化的SQL。
l???PLAN_ID?表示SQL?使用的计划的?ID?,可以通过它去查询一些计划相关的信息。
l???IS_HIT_PLAN?表示?SQL?的执行是否命中了计划缓存。
l???EVENT表示SQL执行过程中最长的等待事件的名称。
l???TOTAL_WAIT_TIME_MICRO?表示执行过程中所有等待事件的总时间。
l???RPC_COUNT?表示SQL?执行过程中发送的?RPC?数量。
l???IS_EXECTOR_RPC?表示当前的请求是否是一个?RPC?请求。一条?SQL?在执行的时候,会在?SQL_AUDIT?里记录很多条记录。而?SQL?执行过程中可能会触发一些?RPC?操作,执行每个?RPC?可能都会记一条SQL_AUDIT?的日志。此外,在并行执行的过程中,每一个并行执行的线程也会在?SQL_AUDIT?里记一条记录。这些通过?RPC?执行的记录的IS_EXECTOR_RPC会标记成1,而用户SQL的IS_EXECTOR_RPC会标记成0。所以如果只想查询用户执行的?SQL,只需要指定?IS_EXECTOR_RPC=0?即可。
l???REQUEST_TIME表示数据库接收到这条?SQL?请求的时间点。它是一个时间戳,并不是?data?的格式,可以使用usec_to_time?函数对其进行格式化。?
l???ELAPSED_TIME表示数据库收到请求到执行结束的总耗时。
l???QUEUE_TIME?表示从数据库接收到请求,到请求真正被数据库处理的耗时。
l???GET_PLAN_TIME?表示从数据库开始去处理一条?SQL到获得到?SQL计划所用的时间。
l???EXCUTE_TIME?表示执行SQL计划消耗的时间。QUEUE_TIME + GET_PLAN_TIME + EXCUTE_TIME大致等于ELAPSED_TIME。
l???RETRY_COUNT表示执行这条?SQL?的时候是否发生过重试?如果发生了重试,这里会显示重试的次数。?
l???MEMSTORE_READ_ROW_COUNT和SSSTORE_ READ_ROW_COUNT?表示SQL?执行过程中,从?MEMSTORE和SSSTORE中读的行数。读的数据越多,就表示SQL?的扫描量越大。
l???TABLE_SCAN表示SQL?请求是否涉及到了全表扫描。
接下来以几个实际实例来表述上述字段的具体使用方法。

示例1:如何查看集群?SQL?的请求量是否均匀??OceanBase 是分布式数据库,集群上分布了很多台机器。我们希望能够将所有机器的资源都利用起来,让每一台机器承担一些?SQL?流量。
那么如何查询?SQL?流量是否均匀呢?可以去查?SQL_AUDIT, 找出某个时间段内所有执行的用户?SQL, 然后在?server IP?的维度上做聚合,最后求出每一个?server IP?的分组里面,此时间段内有多少?SQL?,就可以大概得出每一个?server?上的流量。
如上图SQL语句,查询了过去一秒每台机器上有多少个用户的请求,可以看到底下两台?server?的请求量是比较高的,而上面两台的请求量比较少。因此,这里就可以尝试做一些调整使得请求量更加均衡。
案例2:如何获取业务模型?在做一些?SQL?诊断的时候,用户往往想要了解业务的模型是怎么样的,但是业务比较复杂,也很难彻底了解清楚。
SQL_AUDIT 提供的方案如下:首先从?SQL_AUDIT?里查出一条业务的?SQL?,获取到?SID?,再通过 SID?从?SQL_AUDIT?找出对应 session?发过来的所有?SQL,并按照请求时间排序,即可获取到按顺序执行的?SQL?,也可以由此进行一些业务逻辑的分析。
通过?SID?查询业务逻辑,要求只需要用一个?session?来发送?SQL就能完成业务。而很多时候,一个业务可能需要调用很多库,这些不同的库又用了不同的?session?,这种场景下应该怎么处理?
首先可以把?SQL_AUDIT?里的数据全部清理掉,并尽可能地让业务用单线程的方式去运行业务程序。业务程序运行完成之后,立即关闭?SQL_AUDIT?,这样新来的?SQL?就不会再被记录到?SQL_AUDIT?里,而老的记录也不会被清除掉。可以直接查询老的记录,按其执行时间排序,即可从这些?SQL?的执行顺序上大概推断出业务的逻辑模型和业务的逻辑。

案例3:如何找到消耗?CPU?最多的?SQL?。
首先查出某一个时间段内所有执行的用户?SQL, 然后在?SQL_ID?维度上做聚合,求出每一个?SQL_ID?总的执行时间。这里的执行时间 = ELAPSED_TIME - QUEUE_TIME ,因为在队列里等待的时间并没有消耗?CPU?,实际消耗?CPU?的就是获取和执行计划的时间。最终可以基于这些消耗 CPU 最多的?SQL?做一些性能分析、性能调优之类的工作。

案例4:如何查询某个时间段内的请求次数排在?TOP N?的?SQL 。
首先查出某个时间段的?SQL?,然后按照?SQL_ID?聚合,求得总的请求次数,最终按照执行次数排序,取TOP N。
案例5:如何分析?RT?突然抖动的?SQL?。
在此场景下,可以在抖动出现后立即将?SQL_AUDIT?关闭,保证产生抖动的?SQL?能够在?SQL_AUDIT?中找到。然后找到抖动时间点的执行时间是?top 10的?SQL?去做分析。主要可以考虑从以下场景去做分析:
①??查看?retry?次数。如果很多,则可以考虑是否存在锁冲突或切主等情况 。
②??查看queue time是否很大。如果产生了抖动,那些?QUEUE_TIME?非常大但是EXCUTE_TIME?并不长的SQL?,往往是受抖动影响的?SQL?,而不是引起抖动的?SQL?。因为产生抖动的原因一般都是某条?SQL?执行的时间很长,导致其他SQL不能及时得到?CPU?来执行,只能一直在队列里排队。
③??查看获取执行计划时间(GET_PLAN_TIME)是否很长。如果是,往往说明此SQL?没有命中计划而是重新去走了一次完整的生成计划流程,一般会伴随IS_HIT_PLAN=0。
④??查看EXCUTE_TIME是否很长。如果很长,则可以分为以下三个方向来判断:
a.??查看是否有很长耗时的等待事件。比如发现此?SQL?的等待事件耗费了很长时间在等?IO?,那么可以查看抖动时间点的磁盘状态是否正常。
b.??查看访问的行数是否非常的多。可以查看?MEMSTORE_READ_ROW_COUNT和SSSTORE_ READ_ROW_COUNT两个字段,如果字段值比较大,可以考虑是否是存在大小账号的场景导致抖动。
c.??查看执行计划是否合理。
????
此外,如果?SQL_AUDIT?没有及时发现抖动,抖动的请求数据已经被淘汰,则需要查看?OBsever?的日志里是否有慢查询日志。如果有,则分析此日志。

SQL 诊断常用的第二种视图是 [G]V$PLAN_CACHE_PLAN_STAT ,它记录了每一个计划的具体信息以及一些执行的统计信息。
每一个计划缓存中保存的计划,在视图里都有记录。
上图列出了视图里常见的字段。需要注意的是?QUERY_SQL字段,它记录的是第一次生成计划时候对应的原始?SQL 语句。因为计划缓存是对参数化后的?SQL?去共享计划的,而不同的参数会命中同一个计划。所以如果想了解计划是怎么生成的,就需要得到第一次生成计划用的参数。因此,需要记录第一次生成计划时候对应的一个原始?SQL。
AVG_EXE_TIME?表示计划的平均执行时间。它只记录了执行成功的?SQL?的平均执行时间,没有执行成功的计划不会被计入。
CPU_TIME 表示所有计划执行消耗的 CPU?开销。
OUTLINT_ID 表示计划生成过程中使用了哪个outline?。如果值是?-1?则表示没有使用任何?outline?去生成计划;否则,表示使用了某一个?outline?指导了计划的生成。

上图是使用[G]V$PLAN_CACHE_PLAN_STAT 视图查询某一个 SQL?计划的生成时间/平均执行时间。
此外,[G]V$PLAN_CACHE_PLAN_STAT 视图还提供了查询?CPU?消耗最多的?SQL?的另一种方式,通过查询 CPU_TIME?并对所有执行时间做聚合来实现的。
但是它只能找到计划缓存里面还存在的计划在所有时间维度上聚合的CPU开销,无法查询某个具体时间段内CPU?消耗比较高的SQL。

[G]V$PLAN_CACHE_PLAN_EXPLAIN 视图记录了一条?SQL 在计划缓存中具体的物理执行计划。查询时必须给出它的?ip、port、tenant_id?和?plan_id,少了任意字段都会导致返回一个空的结果。以上四个字段可以在?gv$plan_cache_plan_stat或gv$sql_audit里查到。
上图展示了此视图的常用字段。

关于 [G]V$PLAN_CACHE_PLAN_EXPLAIN 的使用,举个例子如上图,上面是从 PLAN_CACHE_PLAN_EXPLAIN?查出的实际执行计划,下面是直接?explain?得到的逻辑计划。可以看到物理计划和逻辑计划基本一致,仅有的区别是物理计划的算子名称都是以?PHY_?开头,以及它少了?output?与?filters?等信息。所以去通过?plan explain?其实能看到一个计划的一个大体的形状的。
那么 [G]V$PLAN_CACHE_PLAN_EXPLAIN 视图一般在什么情况下使用呢?比如线上发现一条 SQL 执行得比较慢,但是直接对其进行?explain 后,发现它的计划是相对较优的。因此,此时还需要查看它实际的执行计划,确定是否因为计划共享导致它使用了一个其他参数生成的计划。
四、SQL 优化
1、索引调优
索引调优本质上就是为数据查询建立一个合适的索引。

OceanBase 的索引有一个特点,会在索引键后面自动补上主表的主键。因为在使用索引的时候,需要通过表的逻辑主键去关联索引中的某一行与主表中的某一行。也就意味着索引中需要表的主键才能去反向查找定位主表中的具体某一行,因此需要把主表的主键加到索引里面。
比如上图的 SQL 语句,虽然是在?B?列上建的索引,但由于?A?是表的主键,因此最终索引是建立在?B、A?这两列上。
索引相对于主表有三个优势:
①??可以根据索引列的条件去快速定位数据,来减少数据的扫描量。
②??索引列是有序的,可以利用此特性消掉一些排序操作,
③??索引一般比主表小。但这会引入回表的问题,其实也是索引的一个劣势。

索引的第一个优势是快速定位数据。可以将索引列上的过滤条件转化成索引扫描的开始位置和结束位置。在实际扫描的时候,只需要从开始位置一直扫描到结束位置,两个位置之间的数据就是满足索引列上的过滤条件的数据。扫描的开始位置到结束位置称为?query range。
举个例子如上图,在?test?表上有个索引?b、c, 按照前文提到的索引方式,其实它是?b、c、a?的索引,因为?a?是主键。
第一条?SQL?有一个?b=1?的查询条件,对应的query range?是(1,min,min;1,max,max)。即要从?b=1,c=min,a=min?向量点开始,一直扫到b=1,?c=max,a=max?向量点。这两个向量点之间所有数据都满足?b=1条件,不需要再使用?b=1?过滤条件去过滤。
第三条SQL是?b=1,c>1,对应的query range是(1,1,max;1,max,max)。
第四条?SQL是b>1,c>1。query range?在索引上抽?range?的时候,只能抽到第一个范围谓词为止。比如说这里b>1,c>1,发现索引的第一列就是一个范围谓词,那么往后再出现任何的等值条件或范围条件,都不能再抽取range。因此,此?SQL?对应的query range是(1,max,max;max,max,max)。因为这里是用向量点去描述起始和结束位置,然而向量点是无法精确地描述出两个范围条件的。

索引的第二个优势有序,在一些场景下,可以利用此特性来消除一些排序。
举个例子如上图。?
第一条?SQL?的查询条件是?b=1??order by c。 这条?SQL 扫描了索引?bcd?,但是扫描完后没有做排序的。因为索引是按照?bcda?有序,但在扫描结果中,b是一个常量1。虽然是按照?bcda?有序,但是所有数据里的?b都是同一个值,那么数据其实就是按照?cda?有序的,则?order by c?自然也就不需要排序了。
第二条?SQL?是需要排序的。因为这里的?b?不是一个常量了,索引只能按照?bcda?有序。
第三条?SQL?与第一条类似,同理,也不需要排序。
最后一条?SQL?里的?c?是一个常量,索引实际上是按照?bda?有序的。因此,要求按照?bd?去排序,自然也就不需要排序。

索引的最后一个优势是索引一般比主表小。索引一般只会包含基表中的其中几列,因此在相同行数的情况下,索引中包含了更少的数据列,只需要使用更少的数据块就能存储同样的行数。因此,扫描所有数据的时候,索引会比主表需要扫描的数据块更少。
比如?select count(*) from t1,只需要知道?t1?中有多少行,可以选择一个列数最少的索引,这样只需要扫描最少的数据块就可以得到?t1?中的行数。?
然而,索引比主表小,也存在一些劣势,索引往往需要回表才能拿到所有数据。因为实际情况下,过滤条件可能只有几列,但是需要查询很多的列。此时如果走索引扫描,即只能查询到索引上的列,而其他的列就需要去反查主表做索引回表来获得。
比如上图下方的例子,索引是?bc,第一条?SQL?要求查的是d。这里通过一个?hint?强制其走了索引查询。因此,它需要去索引中查出所有的数据,再从主表中查出?d?。可以看到上图中is index back=true,意味着索引扫描做了回表的操作。
而第二条?SQL?则不需要做索引回表,因为所有的?abc?都在索引里面。

建索引的一般策略是,要将所有等值条件的列放在索引前面,将存在范围条件的列放在索引后面。有多个列上都存在范围条件时,要把过滤性强的列放在前面。
为什么要把过滤性强的放在前面?因为抽取range的时候只能抽到第一个非等值条件,把过滤性强的放在前面,可以减少range扫描的数据量。
举个例子:一条?SQL?上存在三个过滤条件,分别是?a=1,?b>0,c between 1 and 12。这里假设?b>0?可以过滤掉?30%?的数据,c between 1 and 12可以过滤掉?90%?的数据。那么按照上述策略,可以在(a,c,b)上建一个索引进行优化。
在大多数场景下,用一般策略就能够建出一个优秀的索引了。但是在一些特殊场景下,也需要做出一些权衡。
比如要考虑是避免排序还是减少扫描?举个例子,过滤条件是 a=1 and(b=1 or b=2) order by c,那去怎么去建索引呢?如果建一个 (a,b,c) 的索引,可以通过?a,b?上的过滤条件快速定位到要扫描的所有数据。但因为?b?并不是一个常量,所以还是需要做一个排序操作。如果建一个 (a,c,b) 的索引,那么只能对a=1?的条件去抽?range?,然后在?range?扫描结果之上再用?b=1 or b=2?去过滤。但因为?a?是一个常量,所以这里的(a,c,b)索引相当于按照c,b?是有序的,?order by c?无须进行排序。
因此在使用的时候需要根据实际情况进行权衡。比如当b=1 or b=2?谓词的过滤性非常高的场景下,可以考虑用它去抽取range;如果?b=1 or b=2??谓词的过滤性非常差,则考虑建一个 (a,c,b) 的索引消掉排序。
再比如,需要考虑建一个全覆盖索引还是部分索引?比如?SQL?要查?abcd ef,但是过滤条件只给了?a=1 and b>10。可以建一个(a,b,c,d,e,f)?的索引,这样直接扫描后,cdef?也能从索引中获取到,不需要去做索引回表;也可以建一个 (a,b) 的索引,这样可以快速定位到目标数据,但是因为?cdef?四列在索引中不存在,所以必须通过回表才能获取到需要的数据。
全覆盖索引会导致索引中存在很多冗余的列,会占用很大的空间,也会导致索引扫描的速度变慢。因此,使用的时候也需要结合实际场景做权衡。
2、连接调优

目前在 OceanBase 中,有三种连接算法:?Nested-Loop Join、?Merge Join以及?Hash Join。
Nested-Loop Join:首先把 join?左侧的数据扫描出来,然后用左侧的每一行去遍历一次右表的数据,从里面找到所有能连接上的数据行做连接。它的代价=左表扫描的代价+左表的行数*左表每一行遍历右表的代价。
Merge Join:分别对左右表进行扫描,并对左表和右表的连接键分别排序,最后用类似移动指针的方式不断地调整指针,找到匹配行做连接。它的代价=左右表扫描的代价+左右表排序的代价。
Hash Join:扫描左表并对每一行建哈希表,扫描右表并哈希表中做探测,匹配并连接。它的代价=扫描左表的代价+左表的行数*每一行建哈希表的代价+扫描右表的代价+右表的行数*每一行探测哈希表的代价。
OceanBase 里的 Nested-Loop Join 有两种执行方式,分别为条件下压的 Nested-Loop Join 和非条件下压的 Nested-Loop Join。
条件下压的Nested-Loop Join :?如上图右侧,可以看到t1.c1在?outputs&filters?的?nl_params?里面。意味着会首先扫描join的左侧,将?t1?的数据扫描出来。然后获取?t1每一行的?c1?具体的值并放入过滤条件,也就是?t2.d1?等于某一个具体值的条件。当d2.t1?上有索引或?d2.t1?是?t2?表的主键的时候,就可以通过?d1?等于某一个具体值的条件,走索引或主表去快速定位到?t2?中的某几行。简单来说,Nested-Loop Join非条件下压流程相当于每次拿出一行t1,从?t2?中扫描出一行或几行数据,且可能每次在?t2?里面扫的数据都不一样。
非条件下压的Nested-Loop Join:t2上没有合适的索引可用,它也不是主键,就需要先扫描全部t2的数据,然后通过?material?算子将它物化到内存里。意味着?t1?的每一行都要完整地遍历?t2?的所有行,相当于做了笛卡尔积。因此,它的性能非常差。
因此在?OceanBase 中,一般情况下都会选择条件下压的 Nested-Loop Join。除非没有等值连接条件,并且 Nested-Loop Join 也没有合适的索引可用,才会考虑生成非条件下压的 Nested-Loop Join。

上图是?Hash Join?与?Nested_Loop Join 的性能对比。
在实际的执行过程中,相比于基表扫描,建哈希和做哈希探测的代价都是可以忽略不计的。因此 Nested_Loop?的扫描代价可以近似地简化为索引回表代价。而索引回表代价相比于直接做基表扫描或者索引扫描会低一些。
最终的结论如下:当右表需要扫描的行数/左表需要扫描的行数超过20的时候,建议选择?Nested_Loop Join。
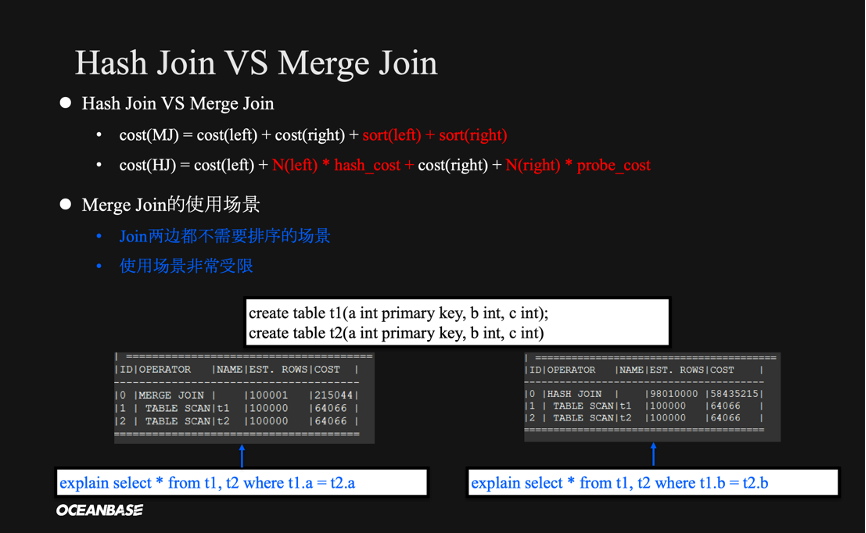
上图是?Hash Join?与?Merge Join 的对比。
它们都需要完整地扫描左表和右表,区别在于?Merge Join?要分别对两侧在连接键上排序,而哈希则是对左侧建哈希表、对右侧做哈希探测。相比于哈希来说,做排序的代价会更高。因此,在正常情况下,一定是Hash Join?优于?Merge Join。
只有在一些非常特殊的场景下,才会选择?Merge Join?。比如两侧都不需要排序。举个例子,t1 t2两个表都是以?A?作为主键,假设它们的连接条件就是?a。在此场景下,?t1做基表扫描后的结果本身就是按照?a?有序,t2?也如此。因此,在?a?上做连接可以省略按?a?排序的步骤,此时 Merge Join 的性能要比 Hash Join更好。

SQL?语句调优要求根据?SQL?执行计划分析出此?SQL?的性能瓶颈,并对其做优化。可以将完整的?SQL?拆分为几个步骤,分别执行这些步骤,去查看性能的瓶颈点。此外也可以利用一些已有的脚本或工具来帮助简化这些分析过程。
优化方式主要有以下几个方面:
①??比如创建合适的索引或调整连接算法。
②??尝试调整连接顺序。比如有?t1,t2,t3?三个表做连接, 假设?OB?的优化器认为?t1,t2?两个表先做连接,再与?t3?做连接,是一个比较好的计划。但是实际可能是?t1?,t3?先做连接,再于?t2?做连接更优。此时可以通过?hint?告诉优化器正确的连接顺序来优化?SQL?的性能。但是此方式难度较大,在一些复杂场景下,需要丰富的经验支持才能完成。
③??检查?OB?是否做了错误的改写或缺少了某些改写机制导致最后生成的执行计划不优。这要求使用者对于OB?已经支持的一些改写机制非常了解才能做出正确的判断,难度比较大。
④??开启并行执行机制。比如一个线程执行不出来,可以尝试多给几个线程,看是否能够加速执行速度。
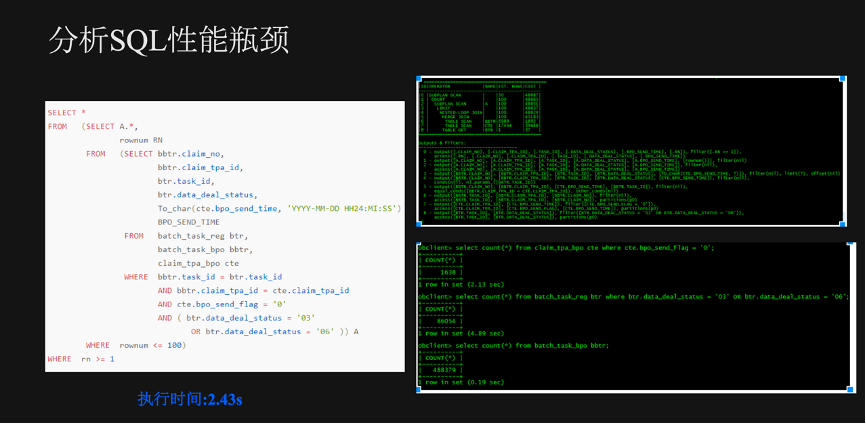
上图为一个实际的?SQL?性能分析和优化的例子。优化器生成计划是让?bbtr?表先与?cte?表做连接,再与?btr?表做Nested_Loop Join。
对其进行分析,首先要查看每个表的数据量,cte?表的数据量是?1000?多行,扫描耗时两秒多;
?btr?表的数据是?8?万多行,扫描耗时?4?秒多;
?bbtr?表的数据量是?40?多万,扫描耗费?0.19?秒。这里扫描耗时最高的是?btr?表,但它是作为?Nested_Loop Join的右表。
条件下压Nested_Loop Join每次都是用左表的某一行通过索引或主键去精确定位到某几行的,因此它的执行时间可以缩短。
执行耗时第二高的是?cte?表,它作为?Merge Join?的左表,完整地扫描了整个表。它的耗时是?2.13?秒,而计划总的执行时间是?2.43?秒。因此可以确定,此?SQL?的瓶颈点就是?cte?表的扫描。可以看到?cte?表上有一个过滤条件,则可以通过在此列上建一个索引来优化它的执行性能。
当然了,如果?cte?表的扫描不是瓶颈,应该做进一步的分析,可以尝试去单独去执行?bbtr?和?cte?两个表的连接,查看它的执行结果的行数。如果执行结果为几万行,则意味着选择Hash Join的方式更优。那么可以尝试修改?4?号算子的连接方式,将Nested_Loop Join改成Hash Join。

此外,如果SQL?能够成功执行,也可以通过一些脚本来辅助分析过程。
OceanBase 提供了一个 GV$SQL_PLAN_MONITOR 视图,记录了执行过程中每一个算子的吐行以及执行时间等信息。
它的输出展示格式不够清晰直接,所以?OceanBase 内部对此提供了一个格式化的工具,能够将输出信息转换成可视化的图形界面,使开发人员能够快速找到计划中耗时比较长的算子。

HINT是一种机制,可以通过?hint 控制优化器的行为。比如有一个两表连接,默认走 Hash Join。可以通过使用?use_nl hint?来告诉优化器,如果?t1?或 t2?作为连接的右表,就走 Nested_Loop Join。
????OceanBase 提供了很多?hint,比如有?index_hint,可以指定扫描使用什么索引,有use_nl、?use_merge?、use_hash[MOU1]?来指定连接方式,以及一些控制改写行为的hin[MOU2]?t。
具体可以参考开源社区的文档:
https://open.oceanbase.com/docs/community/oceanbase-database/V3.1.1/optimizer-hint-1

在业务使用的时候,用 hint去改写?SQL 是比较麻烦的,往往会涉及到业务的发版、测试,修改的周期也会比较长。
因此,OceanBase 提供了?outline?机制,方便用户在不修改接口的情况下,通过在数据库里建一个?outline?来控制计划生成的行为。
举个例子如上图,
在?SQL_ID?是?5f5be的SQl?上建了一个?outline ,?告诉优化器如果要给此?SQL 生成计划,要使用?index hint。
那么?outline要如何生效呢?
数据库收到一条?SQL?之后,首先会对它进行快速参数化,然后用参数化后的文本去生成, 并用?SQL_ID?去?outline?里查找有没有给此?SQL_ID?使用的outline。如果有,则把 outline?里的?hint?取出,重建?SQL 并把 hint 拼到用户写的?SQL?里,再用此?SQL?去生成计划,即可得到使用了指定?hint?的计划。
与此同时,在创建了outline之后,还需要验证它是否真正生效了。验证方法就是查看 PLAN_CACHE_PLAN_STATE?表里的?outline_id?字段,如果不是1,则说明已经成功使用了?outline。
――――――――――――――――
附录:
练习题:
实践练习一(必选):OceanBase Docker 体验?
实践练习三(可选):使用OBD 部署一个 三副本OceanBase 集群?
实践练习四(必选):迁移 MySQL 数据到 OceanBase 集群?
还没交作业的小伙伴要抓紧啦!
可以免费带走 OBCP 考试券喔~~
方法一:完成四道必选练习
方法二:任意一道练习题 ? 结业考试超过80分
已经有很多同学抢先答题了,
加入钉钉群(群号3582 5151),和大家一起学习、交流~~
进群二维码:
