1. зМБИжЊЪЖ
дкЩЯЦкЯЕСаЮФеТжа(ЩюШыЧГГіЬиеїЙЄГЬ ЈC Лљгк OpenMLDB ЕФЪЕМљжИФЯ(ЩЯ)),ЮвУЧНщЩмСЫЬиеїЙЄГЬЕФЛљДЁИХФюЁЂЪЕМљЙЄОп,вдМАЛљБОЕФЛљгкЕЅБэЕФЬиеїНХБОПЊЗЂЁЃдкБОЦЊЮФеТжа,ЮвУЧНЋЛљгкжїБэКЭИББэ,ШЅеЙПЊЯъЯИНщЩмИќМгИДдгКЭЧПДѓЕФЛљгкЖрБэЕФЬиеїНХБОПЊЗЂЁЃЭЌЪБ,ЮвУЧвРШЛвРЭа OpenMLDB ЫљЬсЙЉЕФ SQL гяЗЈНјааЬиеїЙЄГЬНХБОЪОР§,Йигк OpenMLDB ЕФИќЖраХЯЂПЩвдЗУЮЪЮвУЧЕФ GitHub repo,вдМАЮФЕЕЭјеОЁЃ
OpenMLDB GitHub repo
OpenMLDB ЮФЕЕ ЁЄ ПДдЦ
ШчЙћФуЯыдЫааБОЦЊНЬГЬЫљОйР§ЕФ SQL,ЧыАДеевдЯТСНИіВНжшзізМБИ:
- ЭЦМіЪЙгУ OpenMLDB docker ОЕЯёдкЕЅЛњАцЯТдЫааБОНЬГЬ,дЫааЗНЪНВЮПМ OpenMLDB ПьЫйЩЯЪжЁЃШчЙћЪЙгУМЏШКАц,ЧыЪЙгУРыЯпФЃЪН(SET @@execute_mode=ЁЎofflineЁЏ )ЁЃМЏШКАцЦеЭЈЯпЩЯФЃЪННіжЇГжМђЕЅЕФЪ§ОндЄРРЙІФм,вђДЫЮоЗЈдЫааНЬГЬжаДѓВПЗжЕФ SQLЁЃ
- БОНЬГЬЯрЙиЕФЫљгаЪ§ОнвдМАЕМШыВйзїНХБОПЩвддкетРяЯТдиЁЃ
дкБОЦЊЮФеТжа,ЮвУЧНЋЛсЪЙгУЕНжїБэКЭИББэ,НјааОйР§ЫЕУїЁЃЮвУЧвРШЛЪЙгУЩЯЦЊЕФЗДЦлеЉНЛвзЕФбљР§Ъ§Он,АќКЌвЛеХжїБэгУЛЇНЛвзБэ(БэвЛ t1)КЭвЛеХИББэЩЬЛЇСїЫЎБэ(БэЖў t2)ЁЃашвЊЖрБэЬиеїЙЄГЬЕФБГОА,ЪЧдкЙиЯЕЪ§ОнПтЩшМЦжа,ЮЊСЫБмУтЪ§ОнШпгрКЭвЛжТад,вЛАуЖМЛсАДеевЛЖЈЕФЩшМЦддђ(Ъ§ОнПтЩшМЦЗЖЪН),АбЪ§ОнДцШыЖрИіЪ§ОнБэжаЁЃдкЬиеїЙЄГЬжа,ЮЊСЫЛёЕУзуЙЛЕФгааЇаХЯЂ,ашвЊдкЖрИіБэжаШЁГіЪ§Он,вђДЫашвЊЛљгкЖрБэНјааЬиеїЙЄГЬЁЃ
БэвЛ:жїБэ,гУЛЇНЛвзБэ t1
| Field | Type | Description |
|---|---|---|
| id | BIGINT | бљБОID,УПвЛЬѕбљБОгЕгаЮЈвЛID |
| uid | STRING | гУЛЇID |
| mid | STRING | ЩЬЛЇID |
| cardno | STRING | ПЈКХ |
| trans_time | TIMESTAMP | НЛвзЪБМф |
| trans_amt | DOUBLE | НЛвзН№Жю |
| trans_type | STRING | НЛвзРраЭ |
| province | STRING | ЪЁЗн |
| city | STRING | ГЧЪа |
| label | BOOL | бљБОlabel, true |
ИББэ:БэЖў,ЩЬЛЇСїЫЎБэ t2
| Field | Type | Description |
|---|---|---|
| mid | STRING | ЩЬЛЇID |
| card | STRING | ПЈКХ |
| purchase_time | TIMESTAMP | ЯћЗбЪБМф |
| purchase_amt | DOUBLE | ЯћЗбН№Жю |
| purchase_type | STRING | ЯћЗбРраЭ:ЯжН№ЁЂаХгУПЈ |
дкДЋЭГЙиЯЕЪ§ОнПтжа,ЮЊСЫШЁЕУЖрБэЕФаХЯЂ,зюГЃгУЕФЗНЪНЪЧЪЙгУ join НјааЦДНгЁЃЕЋЪЧЖдгкЬиеїЙЄГЬЕФашЧѓРДЫЕ,Ъ§ОнПтЕФ join ВЂВЛФмЗЧГЃИпаЇЕФТњзуашЧѓЁЃзюжївЊЕФдвђЪЧЮвУЧЕФжїБэбљБОБэгавЛИігУгкФЃаЭбЕСЗЕФ label Са,ЦфУПвЛИіжЕжЛФмЖдгІвЛааЪ§ОнМЧТМЁЃЫљвдЪЕМЪжаЮвУЧЯЃЭћдк join вдКѓ,НсЙћБэИёЕФааЪ§ашвЊКЭжїБэЕФааЪ§БЃГжвЛжТЁЃ
2. ИББэЕЅааЬиеї
2.1 LAST JOIN
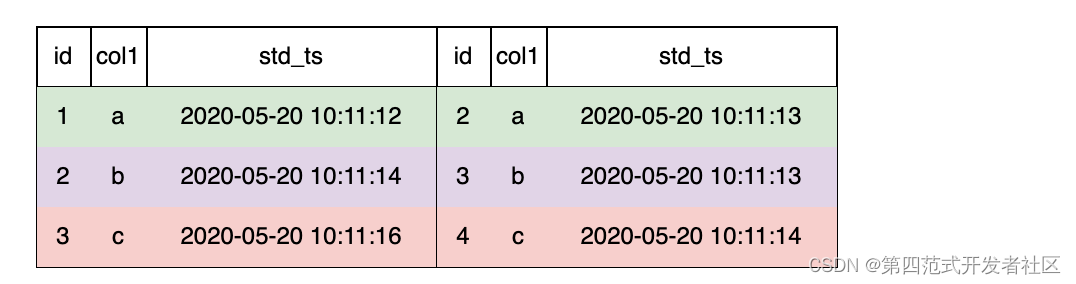
OpenMLDB ФПЧАжЇГжLAST JOINРДНјааРрЫЦЪ§ОнПтЕФ join ВйзїЁЃLAST JOIN ПЩвдПДзївЛжжЬиЪтЕФ LEFT JOINЁЃдкТњзу JOIN ЬѕМўЕФЧАЬсЯТ,зѓБэЕФУПвЛааЦДШЁвЛЬѕЗћКЯЬѕМўЕФзюКѓвЛааЁЃLAST JOINЗжЮЊЮоађЦДНг,КЭгаађЦДНгЁЃЮвУЧгУИќМђЕЅЕФБэЮЊР§,МйЩшБэ s1,s2 ЕФ schema ОљЮЊ
(id int, col1 string, std_ts timestamp)
ФЧУД,ЮвУЧПЩвдзіетбљЕФjoinВйзї:
-- des c: Лљгк ORDER BY ЕФгаађ LAST JOIN ЦДНг
SELECT * FROM s1 LAST JOIN s2 ORDER BY s2.std_ts ON s1.col1 = s2.col1;
ШчЯТЭМ, LAST JOINЪБХфжУ ORDER BY,дђгвБэАД std_ts ХХађ,ЦДНгзюКѓвЛЬѕУќжаЕФЪ§ОнааЁЃвдзѓБэЕкЖўааЮЊР§,ЗћКЯЬѕМўЕФгвБэга 2 Ьѕ,АД std_tsХХађКѓ,бЁдёзюКѓвЛЬѕ 3, b, 2020-05-20 10:11:13 ЁЃ
 ? LAST JOIN Й§ГЬЪОР§
? LAST JOIN Й§ГЬЪОР§
? LAST JOIN ЦДНгНсЙћ
3. ИББэЖрааОлКЯЬиеї
OpenMLDB еыЖдИББэЦДНгГЁОА,РЉеЙСЫБъзМЕФ WINDOW гяЗЈ,аТдіСЫ WINDOW UNION ЕФЬиад,жЇГжДгИББэЦДНгЖрЬѕЪ§ОнаЮГЩИББэДАПкЁЃдкИББэЦДНгДАПкЕФЛљДЁЩЯ,ПЩвдЗНБуЙЙНЈИББэЖрааОлКЯЬиеїЁЃЭЌбљЕи,ЙЙдьИББэЖрааОлКЯЬиеївВашвЊЭъГЩСНИіВНжш:
- ВНжшвЛ:ЖЈвхИББэЦДНгДАПкЁЃ
- ВНжшЖў:дкИББэЦДНгДАПкЩЯЙЙдьИББэЖрааОлКЯЬиеїЁЃ
3.1 ВНжшвЛ: ЖЈвхИББэЦДНгДАПк
жїБэЕФУПвЛИібљБОааЖМПЩвдДгИББэжаАДФГСаЦДНгЖрааЪ§Он,ВЂдЪаэЖЈвхЦДНгЪ§ОнЕФЪБМфЧјМфЛђепЬѕЪ§ЧјМфЁЃЮвУЧЭЈЙ§ЬиЪтЕФДАПкгяЗЈ WINDOW UNION РДЖЈвхИББэЦДНгЬѕМўКЭЧјМфЗЖЮЇЁЃЮЊСЫЗНБуРэНт,ЮвУЧНЋетжжЕФДАПкЮвУЧГЦжЎЮЊИББэЦДНгДАПкЁЃ
ИББэЦДНгДАПкЕФгяЗЈЖЈвхЮЊ:
window window_name as (UNION other_table PARTITION BY key_col ORDER BY order_col ROWS_RANGE|ROWS BETWEEN StartFrameBound AND EndFrameBound)
Цфжа,зюЛљБОЕФВЛПЩЛђШБЕФгяЗЈдЊЫиАќРЈ:
-
UNION other_table:other_tableЪЧжИНјаа WINDOW UNION ЕФИББэЁЃ
жїБэКЭИББэашвЊБЃГжschemaвЛжТЁЃДѓВПЗжЧщПіЯТ,жїБэКЭИББэЕФschemaЖМЪЧВЛЭЌЕФЁЃвђДЫ,ЮвУЧПЩвдЭЈЙ§ЖджїБэКЭИББэНјааСаЩИбЁКЭФЌШЯСаХфжУРДБЃжЄВЮгыДАПкМЦЫуЕФжїБэКЭИББэschemaвЛжТЁЃСаЩИбЁЛЙПЩвдШЅЕєЮогУСа,жЛдкЙиМќСаЩЯзі
WINDOW UNION КЭОлКЯЁЃ -
PARTITION BY key_col: БэЪОАДСаkey_colДгИББэЦДНгЦЅХфЪ§ОнЁЃ -
ORDER BY order_col:БэЪОИББэЦДНгЪ§ОнМЏАДееorder_colСаНјааХХађ -
ROWS_RANGE BETWEEN StartFrameBound AND EndFrameBound: БэЪОИББэЦДНгДАПкЕФЪБМфЧјМф -
StartFrameBoundБэЪОИУДАПкЕФЩЯНчUNBOUNDED PRECEDING: ЮоЩЯНчЁЃtime_expression PRECEDING: ШчЙћЪЧЪБМфЧјМф,ПЩвдЖЈвхЪБМфЦЋвЦ,Шч30d precedingБэЪОДАПкЩЯНчЮЊЕБЧАааЕФЪБМф-30ЬьЁЃEndFrameBoundБэЪОИУЪБМфДАПкЕФЯТНчЁЃCURRENT ROW: ЕБЧАаа time_expressionPRECEDING: ШчЙћЪЧЪБМфЧјМф,ПЩвдЖЈвхЪБМфЦЋвЦ,Шч1d PRECEDINGЁЃетБэЪОДАПкЯТНчЮЊЕБЧАааЕФЪБМф-1ЬьЁЃ
-
ROWS BETWEEN StartFrameBound AND EndFrameBound: БэЪОИББэЦДНгДАПкЕФЪБМфЧјМф -
StartFrameBoundБэЪОИУДАПкЕФЩЯНчЁЃUNBOUNDED PRECEDING: ЮоЩЯНчЁЃnumber PRECEDING: ШчЙћЪЧЬѕЪ§ЧјМф,ПЩвдЖЈвхЪБМфЬѕЪ§ЁЃШч,100 PRECEDINGБэЪОДАПкЩЯНчЮЊЕФЕБЧАааЕФЧА100ааЁЃ
-
EndFrameBoundБэЪОИУЪБМфДАПкЕФЯТНчЁЃCURRENT ROW: ЕБЧАааnumber PRECEDING: ШчЙћЪЧЬѕЪ§ДАПк,ПЩвдЖЈвхЪБМфЬѕЪ§ЁЃШч,1 PRECEDINGБэЪОДАПкЩЯНчЮЊЕФЕБЧАааЕФЧА1ааЁЃ
-
ХфжУДАПкЧјМфНчЪБ,ЧызЂвт:
- OpenMLDB ФПЧАЮоЗЈжЇГжЕБЧАаавдКѓЕФЪБМфзїЮЊЩЯНчКЭЯТНчЁЃШч
1d FOLLOWINGЁЃЛЛбджЎ,ЮвУЧжЛФмДІРэРњЪЗЪБМфДАПкЁЃетвВЛљБОТњзуДѓВПЗжЕФЬиеїЙЄГЬЕФгІгУГЁОАЁЃ - OpenMLDBЕФЯТНчЪБМфБиаы>=ЩЯНчЪБМф
- OpenMLDB ЕФЯТНчЕФЬѕЪ§Биаы<=ЩЯНчЬѕЪ§
- OpenMLDB ФПЧАЮоЗЈжЇГжЕБЧАаавдКѓЕФЪБМфзїЮЊЩЯНчКЭЯТНчЁЃШч
-
INSTANCE_NOT_IN_WINDOW:БъМЧЮЊИББэЦДНгДАПкЁЃжїБэГ§СЫЕБЧАаавдЭт,ЦфЫћЪ§ОнВЛНјШыДАПкЁЃ
ИќЖргяЗЈКЭЬиадПЩвдВЮПМ OpenMLDBДАПкUNIONВЮПМЪжВсЁЃ
вдЯТЭЈЙ§ОпЬхР§згРДУшЪі WINDOW UNION ЕФЦДНгДАПкЖЈвхВйзїЁЃЖдгкЧАУцЫљЪіЮЊгУЛЇНЛвзБэ t1,ЮвУЧашвЊЖЈвхЩЬЛЇСїЫЎБэ t2 ЕФИББэЩЯЦДНгДАПк,ИУЦДНгЪЧЛљгк mid НјааЁЃгЩгк t1 КЭ t2 ЕФschemaВЛЭЌ,ЫљвдЮвУЧЪзЯШЗжБ№Дг t1 КЭ t2 ГщШЁЯрЭЌЕФСа,ЖдгкВЛДцдкЕФСа,ПЩвдХфжУШБЪЁжЕЁЃЦфжа, mid СагУгкСНИіБэЕФЦДНг,ЫљвдЪЧБиаыЕФ;ЦфДЮ,ЪБМфДСЕФСа(t1 жаЕФ trans_time,t2 жаЕФ purchase_time)АќКЌЪБађаХЯЂ,дкЖЈвхЪБМфДАПкЪБКђвВЪЧБиаыЕФ;ЦфгрСаАДееОлКЯКЏЪ§ашвЊ,НјааБивЊЕФЩИбЁБЃСєЁЃ
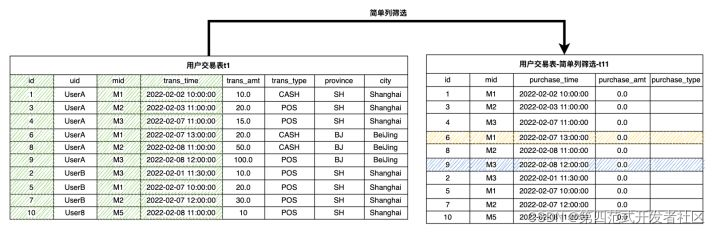
вдЯТ SQL КЭЪОвтЭМЮЊДг t1 ГщШЁБивЊСа,ЩњГЩ t11ЁЃ
(select id, mid, trans_time as purchase_time, 0.0 as purchase_amt, "" as purchase_type from t1) as t11
? Дг t1 ГщШЁБивЊСа,ЩњГЩ t11
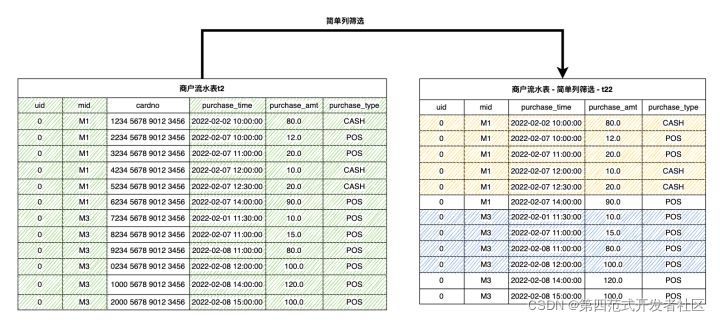
вдЯТ SQL КЭЪОвтЭМЮЊДг t2 ГщШЁБивЊСа,ЩњГЩ t22ЁЃ
(select 0L as id, mid, purchase_time, purchase_amt, purchase_type from t2) as t22
? Дг t2 ГщШЁБивЊСа,ЩњГЩ t22
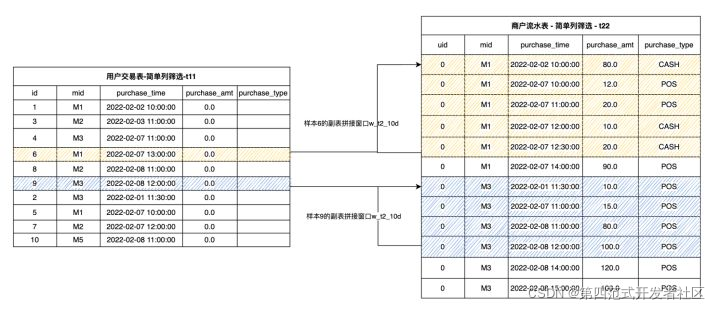
ПЩвдПДЕН,ЗжБ№ЭъГЩГщШЁвдКѓЩњГЩЕФБэИё t11 КЭ t22,вбООпгаСЫЯрЭЌЕФ schema,СНепПЩвдНјааТпМЩЯЕФ UNION ВйзїЁЃЕЋЪЧдк OpenMLDB жа,WINDOW UNION ВЂВЛЪЧецЕФЮЊСЫНјааДЋЭГЪ§ОнПтжаЕФ UNION Вйзї,ЖјЪЧЮЊСЫЖдгк t11 жаЕФУПвЛИібљБОаа,ШЅЙЙНЈИББэ t22 ЩЯЕФЪБМфДАПкЁЃЮвУЧАДееЩЬЛЇID mid ,Жд t11 жаЕФУПвЛааЪ§Он,Дг t22 жаЛёШЁЖдгІЕФЦДНгЪ§Он,ШЛКѓАДЯћЗбЪБМф(purchase_time) ХХађ,ЙЙдьИББэЦДНгДАПкЁЃБШШчЮвУЧЖЈвхвЛИі w_t2_10d ЕФДАПк:ВЛАќКЌжїБэГ§СЫЕБЧАаавдЭтЕФЪ§Онаа,МгЩЯИББэЭЈЙ§ mid ЦДНгЩЯЕФЪЎЬьвдФкЕФЪ§Он,ЪОвтЭМШчЯТЫљЪОЁЃПЩвдПДЕН,ЛЦЩЋКЭРЖЩЋвѕгАВПЗж,ЗжБ№ЖЈвхСЫбљБО 6 КЭбљБО 9 ЕФИББэЦДНгДАПкЁЃ
?
? ИББэЦДНгДАПкЪОР§
ИУДАПкЖЈвхЙ§ГЬЕФ SQL НХБОШчЯТЫљЪО(зЂвт,етЛЙВЛЪЧвЛИіЭъећЕФ SQL):
(SELECT id, mid, trans_time as purchase_time, 0.0 as purchase_amt, "" as purchage_type FROM t1) as t11
window w_t2_10d as (
UNION (SELECT 0L as id, mid, purchase_time, purchase_amt, purchase_type FROM t2) as t22
PARTITION BY mid ORDER BY purchase_time
ROWS_RANGE BETWEEN 10d PRECEDING AND 1 PRECEDING INSTANCE_NOT_IN_WINDOW)
3.2 ВНжшЖў:ЙЙНЈИББэЖрааОлКЯЬиеї
ЖдгкИББэЦДНгДАПкНјааЖрааОлКЯКЏЪ§МгЙЄ,ЙЙдьЖрааИББэОлКЯЬиеї,ЪЙЕУзюКѓЩњГЩЕФааЪ§КЭжїБэЯрЭЌЁЃвдМђЕЅОлКЯКЏЪ§ЮЊР§,ЮвУЧПЩвдЙЙдьбљБОЕФИББэЦДНгЬиеї:ЩЬЛЇЕФзюНќ10ЬьЕФСуЪлзмЖю w10d_merchant_purchase_amt_sum,ЩЬЛЇЕФзюНќ10ЬьЯћЗбзмДЮЪ§ w10d_merchant_purchase_countЁЃвдЯТ SQL ЛљгкЩЯУц 3.1 жаЫљЖЈвхЕФИББэЦДНгДАПк,ЙЙНЈЖрааОлКЯЬиеїЁЃ
SELECT
id,
-- бљБОЩЬЛЇзюНќ10ЬьСуЪлзмЖю
sum(purchase_amt) over w_t2_10d as w10d_merchant_purchase_amt_sum,
-- бљБОЩЬЛЇзюНќ10ЬьНЛвзДЮЪ§
count(purchase_amt) over w_t2_10d as w10d_merchant_purchase_count
FROM
(SELECT id, mid, trans_time as purchase_time, 0.0 as purchase_amt, "" as purchase_type FROM t1) as t11
window w_t2_10d as (
UNION (SELECT 0L as id, mid, purchase_time, purchase_amt, purchase_type FROM t2) as t22
PARTITION BY mid ORDER BY purchase_time
ROWS_RANGE BETWEEN 10d PRECEDING AND 1 PRECEDING INSTANCE_NOT_IN_WINDOW)
4. ЬиеїзщЙЙНЈ
вЛАуЖјбд,вЛИіЭъећЬиеїГщШЁНХБОНЋГщШЁМИЪЎЁЂЩЯАй,ЩѕжСМИАйИіЬиеїЁЃЮвУЧПЩвдИљОнЬиеїРраЭЁЂЬиеїЙиСЊЕФБэКЭДАПкНЋетаЉЬиеїЗжГЩШєИЩзщ,ШЛКѓНЋУПвЛзщЬиеїЗХжУЕНВЛЭЌЕФSQLзгВщбЏРя;зюКѓНЋетаЉзгВщбЏАДжїБэIDЦДНгдквЛЦ№ЁЃБОНк,ЮвУЧНЋГаНгЧАУцЕФР§зг,бнЪОШчЙћНЋИїжжЬиеїЦДНгдквЛЦ№аЮГЩвЛИіЬиеїДѓПэБэЁЃ
ЪзЯШ,ЮвУЧНЋЬиеїЗжГЩ3зщ:
| Ьиеїзщ | ЬиеїзщУшЪі |
|---|---|
| 1 | бљБОгУЛЇ(жїБэ)КЭбљБОЩЬЛЇ(ИББэ)ЕЅааЬиеї |
| 2 | бљБОгУЛЇ(жїБэ)зюНќ30ЬьДАПкОлКЯЬиеївдМАзюНќгУЛЇ7ЬьДАПкОлКЯЬиеї |
| 3 | бљБОЩЬЛЇ(ИББэ)зюНќ30ЬьЕФОлКЯЬиеї |
ШЛКѓ,ЮвУЧЪЙгУOpenMLDB SQLНЋЭЌвЛзщЬиеїЙЙНЈдкЭЌвЛИізгВщбЏжа:
- Ьиеїзщ 1
-- жїБэЕЅааЬиеї
SELECT
-- СажБШЁ
id, uid, trans_type,
-- ЕЅааЪБМфЬиеї:day of week
dayofweek(trans_time) as f_trans_day_of_week,
-- ЕЅааЪБМфЬиеї:НЛвзШе
day(trans_time) as f_trans_day,
-- ЕЅааЪБМфЬиеї:НЛвзаЁЪБ
hour(trans_time) as f_trans_hour,
-- ЕЅааЪБМфЬиеї:НЛвзЗжжг
minute(trans_time),
-- ЕЅааЪ§бЇЬиеї:НЛвзЖюЯђЩЯШЁећКѓШЁЖдЪ§
log(ceiling(trans_amt)) as f_trans_amt_log,
-- ЕЅаазжЗћДЎЬиеї:ПЈКХЧАЫФЮЛ
substr(cardno, 1, 4),
-- ИББэЬиеї
t2.purchase_time as f_purchase_time,
t2.purchase_amt as f_purchase_amt,
t2.purchase_type as f_purchase_type
FROM t1 LAST JOIN t2 ORDER BY t2.purchase_time ON t1.mid = t2.mid
- Ьиеїзщ 2
-- жїБэДАПкЬиеї
SELECT
id as out2id,
-- зюНќ30ЬьPOSНЛвззмН№Жю
sum_where(trans_amt, trans_type = "POS") over w30d as w30d_sum_pos_trans_amt,
-- зюНќ30ЬьЕФзюДѓPOSНЛвзН№Жю
max_where(trans_amt, trans_type = "POS") over w30d as w30d_max_pos_trans_amt,
-- зюНќ30ЬьЕФЕЅДЮЦНОљPOSНЛвзН№Жю
avg_where(trans_amt, trans_type = "POS") over w30d as w30d_avg_pos_trans_amt,
-- зюНќ30ЬьЕФPOSНЛвззмДЮЪ§
count_where(trans_amt, trans_type = "POS") over w30d as w30d_count_pos_trans_amt,
-- зюНќвЛжмзмНЛвзН№ЖюзмЖю
sum(trans_amt) over w7d as w7d_sum_trans_amt,
-- зюНќвЛжмЕФзмНЛвзДЮЪ§
count(trans_amt) over w7d as w7d_count_trans_amt,
from t1
-- зюНќ30ЬьЕФДАПк
window w30d as (PARTITION BY uid ORDER BY trans_time ROWS_RANGE BETWEEN 30d PRECEDING AND CURRENT ROW),
-- зюНќвЛжмЕФДАПк
w7d as (PARTITION BY uid ORDER BY trans_time ROWS_RANGE BETWEEN 7d PRECEDING AND CURRENT ROW)
- Ьиеїзщ 3
-- ИББэОлКЯЬиеї
SELECT
id as out3id,
-- бљБОЩЬЛЇзюНќвЛжмСуЪлзмЖю
sum(purchase_amt) over w7d_merchant as w7d_merchant_purchase_amt_sum,
-- бљБОЩЬЛЇзюНќвЛжмНЛвзДЮЪ§
count(purchase_amt) over w7d_merchant as w7d_merchant_purchase_count,
-- жїБэЩЬЛЇзюНќвЛжмЕФСїЫЎ
FROM (select id, mid, cardno as card, trans_time as purchase_time, 0.0 as purchase_amt, "" as purchase_type from t1) as t11
window w7d_merchant as (UNION (select 0L as id, mid, card, purchase_time, purchase_amt, purchase_type from t2) as t22 PARTITION BY mid ORDER BY purchase_time ROWS_RANGE BETWEEN 30d PRECEDING AND 1 PRECEDING INSTANCE_NOT_IN_WINDOW)
зюКѓ,НЋетШ§зщЬиеї,АДжїБэIDЦДНгдквЛЦ№:
SELECT * FROM
-- Ьиеїзщ1
(
-- жїБэЕЅааЬиеї
SELECT
-- СажБШЁ
id, uid, trans_type,
-- ЕЅааЪБМфЬиеї:day of week
dayofweek(trans_time) as f_trans_day_of_week,
-- ЕЅааЪБМфЬиеї:НЛвзШе
day(trans_time) as f_trans_day,
-- ЕЅааЪБМфЬиеї:НЛвзаЁЪБ
hour(trans_time) as f_trans_hour,
-- ЕЅааЪБМфЬиеї:НЛвзЗжжг
minute(trans_time),
-- ЕЅааЪ§бЇЬиеї:НЛвзЖюЯђЩЯШЁећКѓШЁЖдЪ§
log(ceiling(trans_amt)) as f_trans_amt_log,
-- ЕЅаазжЗћДЎЬиеї:ПЈКХЧАЫФЮЛ
substr(cardno, 1, 4),
-- ИББэЬиеї
t2.purchase_time as f_purchase_time,
t2.purchase_amt as f_purchase_amt,
t2.purchase_type as f_purchase_type
FROM t1 LAST JOIN t2 ORDER BY t2.purchase_time ON t1.mid = t2.mid
) as out1 LAST JOIN
-- Ьиеїзщ2
(
-- жїБэДАПкЬиеї
SELECT
id as out2id,
-- зюНќ30ЬьPOSНЛвззмН№Жю
sum_where(trans_amt, trans_type = "POS") over w30d as w30d_sum_pos_trans_amt,
-- зюНќ30ЬьЕФзюДѓPOSНЛвзН№Жю
max_where(trans_amt, trans_type = "POS") over w30d as w30d_max_pos_trans_amt,
-- зюНќ30ЬьЕФЕЅДЮЦНОљPOSНЛвзН№Жю
avg_where(trans_amt, trans_type = "POS") over w30d as w30d_avg_pos_trans_amt,
-- зюНќ30ЬьЕФPOSНЛвззмДЮЪ§
count_where(trans_amt, trans_type = "POS") over w30d as w30d_count_pos_trans_amt,
-- зюНќвЛжмзмНЛвзН№ЖюзмЖю
sum(trans_amt) over w7d as w7d_sum_trans_amt,
-- зюНќвЛжмЕФзмНЛвзДЮЪ§
count(trans_amt) over w7d as w7d_count_trans_amt
from t1
-- зюНќ30ЬьЕФДАПк
window w30d as (PARTITION BY uid ORDER BY trans_time ROWS_RANGE BETWEEN 30d PRECEDING AND CURRENT ROW),
-- зюНќвЛжмЕФДАПк
w7d as (PARTITION BY uid ORDER BY trans_time ROWS_RANGE BETWEEN 7d PRECEDING AND CURRENT ROW)
) as out2 ON out1.id = out2.out2id LAST JOIN
-- Ьиеїзщ3
(
-- ИББэОлКЯЬиеї
SELECT
id as out3id,
-- бљБОЩЬЛЇзюНќвЛжмСуЪлзмЖю
sum(purchase_amt) over w7d_merchant as w7d_merchant_purchase_amt_sum,
-- бљБОЩЬЛЇзюНќвЛжмНЛвзДЮЪ§
count(purchase_amt) over w7d_merchant as w7d_merchant_purchase_count
-- жїБэЩЬЛЇзюНќвЛжмЕФСїЫЎ
FROM (select id, mid, cardno as card, trans_time as purchase_time, 0.0 as purchase_amt, "" as purchase_type from t1) as t11
window w7d_merchant as (UNION (select 0L as id, mid, card, purchase_time, purchase_amt, purchase_type from t2) as t22 PARTITION BY mid ORDER BY purchase_time ROWS_RANGE BETWEEN 30d PRECEDING AND 1 PRECEDING INSTANCE_NOT_IN_WINDOW)
) as out3 ON out1.id = out3.out3id;
5. РЉеЙдФЖС
ПЊдДЛњЦїбЇЯАЪ§ОнПтOpenMLDB v0.4.0ВњЦЗНщЩм
ЯыПьЫйЪдгУ OpenMLDB РДПЊЪМаДЬиеїМЦЫуНХБО?ПьРДПДвЛЯТ OpenMLDB ПьЫйЩЯЪж
ЭъећЕФ SQL гяЗЈВЮПМЮФЕЕ:жаЙњОЕЯёеОЕу,ЙњМЪеОЕу
БОЯЕСаНЬГЬЩЯЦЊ:4PDПЊЗЂепЩчЧј:ЩюШыЧГГіЬиеїЙЄГЬ ЈC Лљгк OpenMLDB ЕФЪЕМљжИФЯ(ЩЯ)