

redis所有的key都是字符串。
redis是用C语言实现的
redis底层的数据结构和hashMap类似,用的数组+链表+红黑树
解决哈希冲突,用的链表,用next指针指向下一个节点(头插法)
1.高并发场景下对库存扣减,会出现重复扣减问题,用synchronized解决不了。如下代码
synchronized (this){ int stock=Integer.parseInt(stringRedisTemplate.opsForValue().get("stock")); if(stock>0){ int realStock=stock-1; stringRedisTemplate.opsForValue().set("stock",realStock+""); System.out.println("扣减成功,剩余库存:"+realStock); }else{ System.out.println("扣减失败,库存不足"); } }
开启两个服务。在application.yml把端口号改一下,然后把config的允许同时运行的勾打上
然后用nginx配置两个服务的访问路径,最后用Jmeter多个线程请求执行
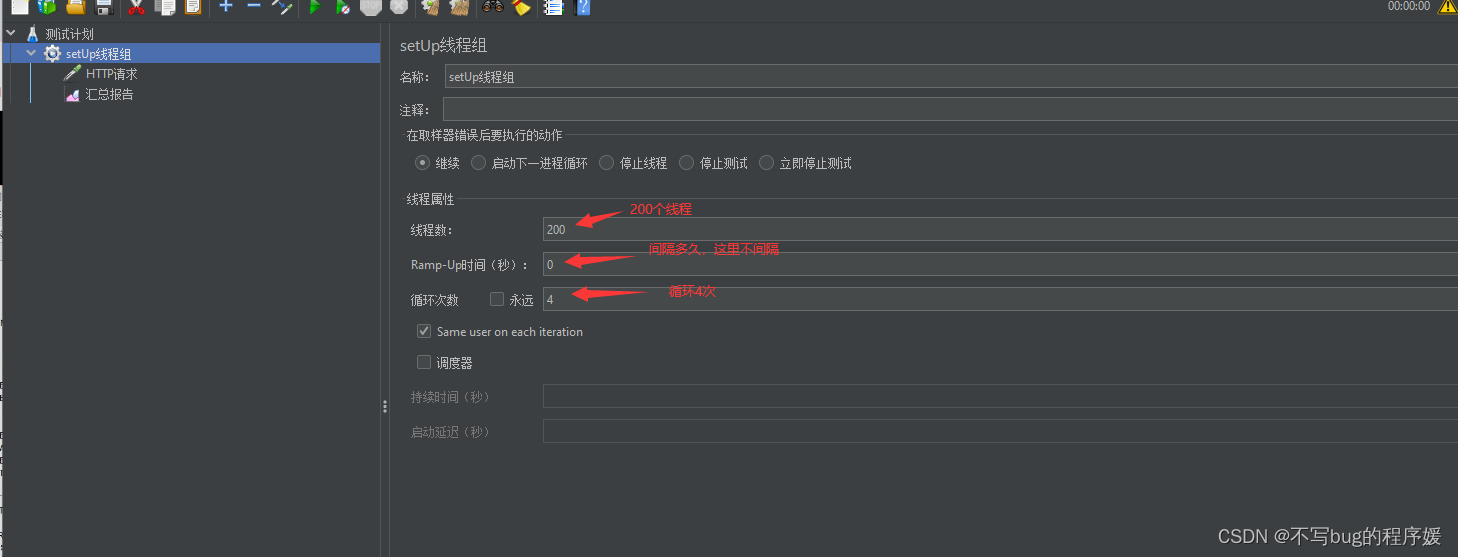
保存汇总报告:
压测OK
两台服务器会有重复扣减的情况(这里我不想在配置nginx了,所以没有演示)
用redis 的 setnx加锁:
pom.xml加入redis:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
在yml里加上
spring:
redis:
host: 127.0.0.1
port: 6379
password: 123456
# 连接超时时间(毫秒)
timeout: 10000
pool:
# 连接池中的最大空闲连接
max-idle: 8
# 连接池中的最小空闲连接
min-idle: 10
# 连接池最大连接数(使用负值表示没有限制)
max-active: 100
# 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: -1
String lockKey="product_101";
//jedis.setnx(s,v) 设置30秒的过期
Boolean result=stringRedisTemplate.opsForValue().setIfAbsent(lockKey,"lock",10, TimeUnit.SECONDS);
if(!result){ //没拿到锁直接返回错误提示
return "error_code";
}
try{
//拿到锁之后 进行减库存
int stock=Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock>0){
int realStock=stock-1;
stringRedisTemplate.opsForValue().set("stock",realStock+"");
System.out.println("扣减成功,剩余库存:"+realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}catch (Exception e){
e.printStackTrace();
}finally {
stringRedisTemplate.delete(lockKey); //这个线程执行完把锁删除
}
return "end";
以上代码会出现问题,如果A线程进来加了锁,但是他执行了15秒,在10秒的时候锁失效了,然后第二个线程进来执行了8秒,第一个线程执行过了五秒后执行了delete锁,这时候删除的是线程二的锁。然后第三个线程进来执行,线程二在执行了3秒后又执行了delete()锁把线程三的锁删除了。怎么确保只删除当前线程的锁?如下代码。用uuid作为key的值,get(key)==uuid那就是当前线程的锁
String lockKey="product_101";
String clientId= UUID.randomUUID().toString();
//jedis.setnx(s,v)
Boolean result=stringRedisTemplate.opsForValue().setIfAbsent(lockKey,clientId,10, TimeUnit.SECONDS);
if(!result){
return "error_code";
}
try{
int stock=Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock>0){
int realStock=stock-1;
stringRedisTemplate.opsForValue().set("stock",realStock+"");
System.out.println("扣减成功,剩余库存:"+realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}finally {
//如果这个锁里的uuid等于当前的uuid 那代表是当前线程的锁
if(clientId.equals(stringRedisTemplate.opsForValue().get(lockKey))){
stringRedisTemplate.delete(lockKey);
}
}
上述代码如果在判断是否是当前uuid时,进来if但是这时间系统延迟了,然后原有线程过期了,第二个线程已经在执行了,那就又导致删除了线程二的锁。解决方案是 另外开启一个线程,设置一个定时任务,查现在是否过期,快过期了就加大过期时间。
redission客户端 把这些都封装了:
redission代码如下:
pom.xml加入jar包:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.6.5</version>
</dependency>
redisson客户端类:
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Bean
public Redisson redisson(){
Config config=new Config();
config.useSingleServer().setAddress("redis://36.138.166.210:6379").setDatabase(0);
return (Redisson) Redisson.create(config);
}
}
用redisson加锁代码:
String lockKey="product_101";
//相当于执行了 setIfAbsent(lockKey,clientId,10, TimeUnit.SECONDS);
RLock redissonLock = redisson.getLock(lockKey);
try{
redissonLock.lock();
//拿到锁之后 进行减库存
int stock=Integer.parseInt(stringRedisTemplate.opsForValue().get("stock"));
if(stock>0){
int realStock=stock-1;
stringRedisTemplate.opsForValue().set("stock",realStock+"");
System.out.println("扣减成功,剩余库存:"+realStock);
}else{
System.out.println("扣减失败,库存不足");
}
}catch (Exception e){
e.printStackTrace();
}finally {
redissonLock.unlock();
}
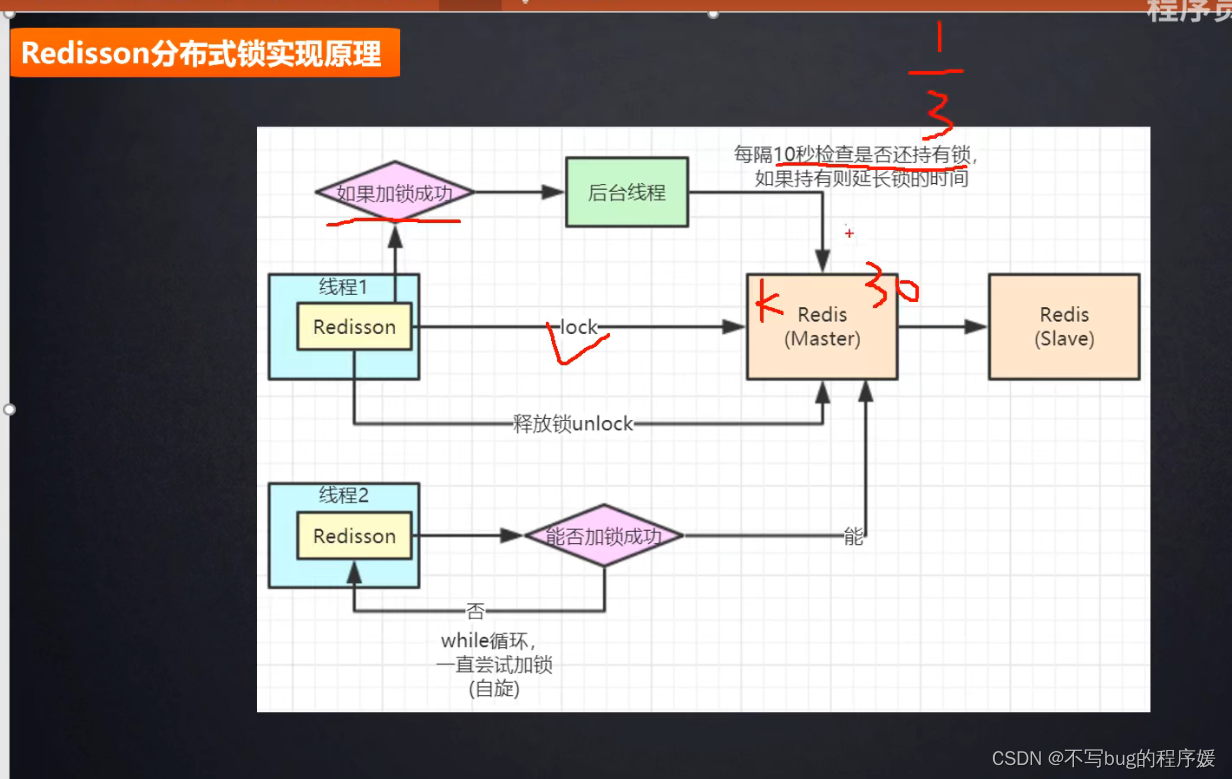
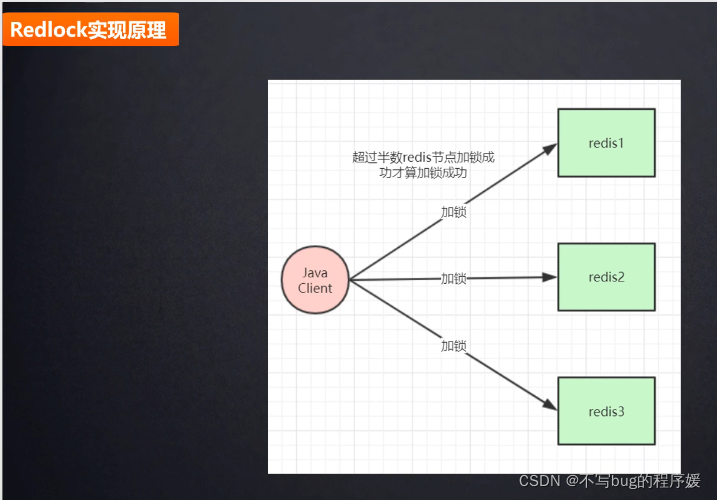
分布式锁实现原理:
线程1加锁成功,执行了lock,后台会有一个线程,每隔10秒(根据设置的过期时间,是过期时间的1/3三分之一,比如30秒)检查是否还持有锁,如果持有则延长锁的时间。
线程二进来,会一直while循环尝试加锁(自旋锁)
redisson底层是用lun 脚本:lun脚本是具有原子性的:
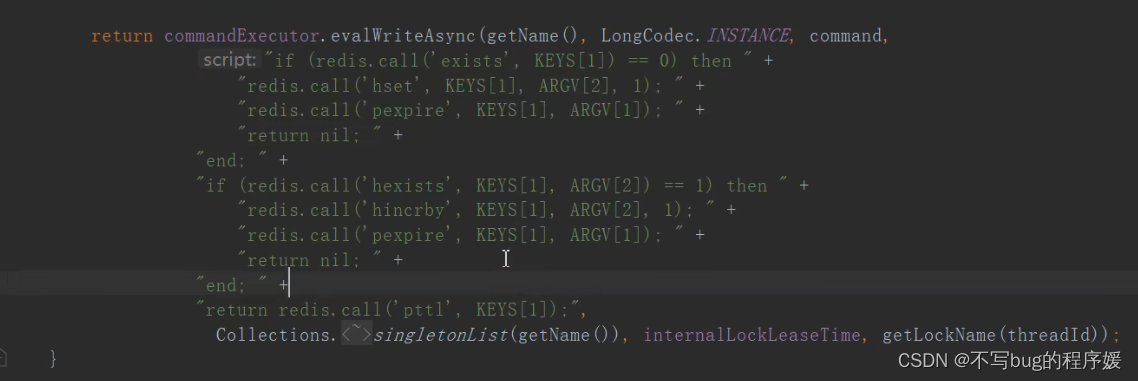
lun脚本:
第一行:keys[1]就是singletonList(getName())的getName()参数,就是
String lockKey=“product_101”;
RLock redissonLock = redisson.getLock(lockKey);里的product_101值
第二行: 如果该key不存在就设置(hset)一个锁,锁的值是getLockName(threadId)就是线程ID(可能还做了些封装)
第三行:设置超时时间,参数是internalLockLeaseTime
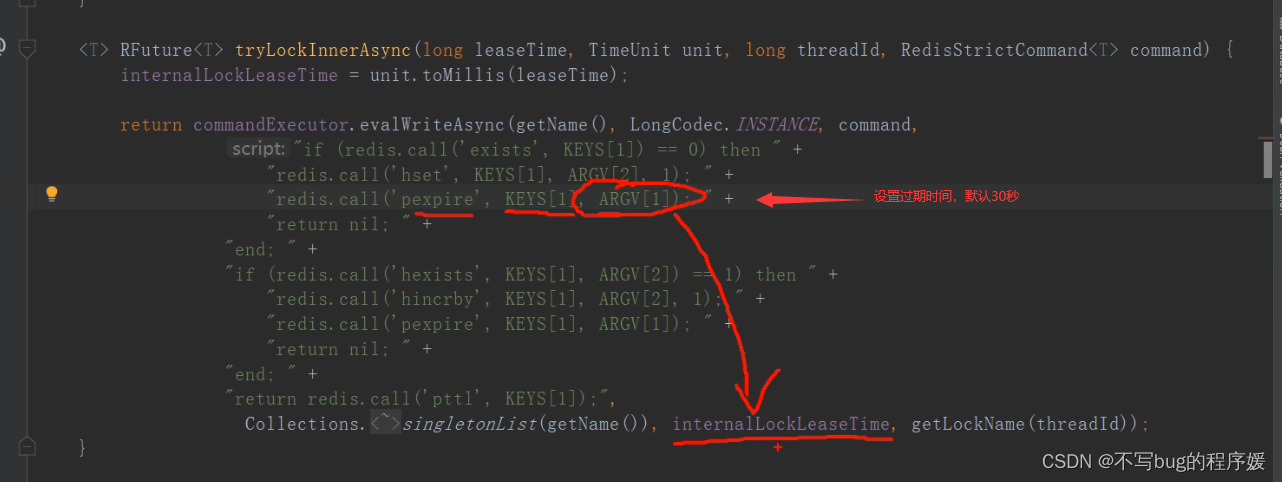

后台定任务的逻辑:
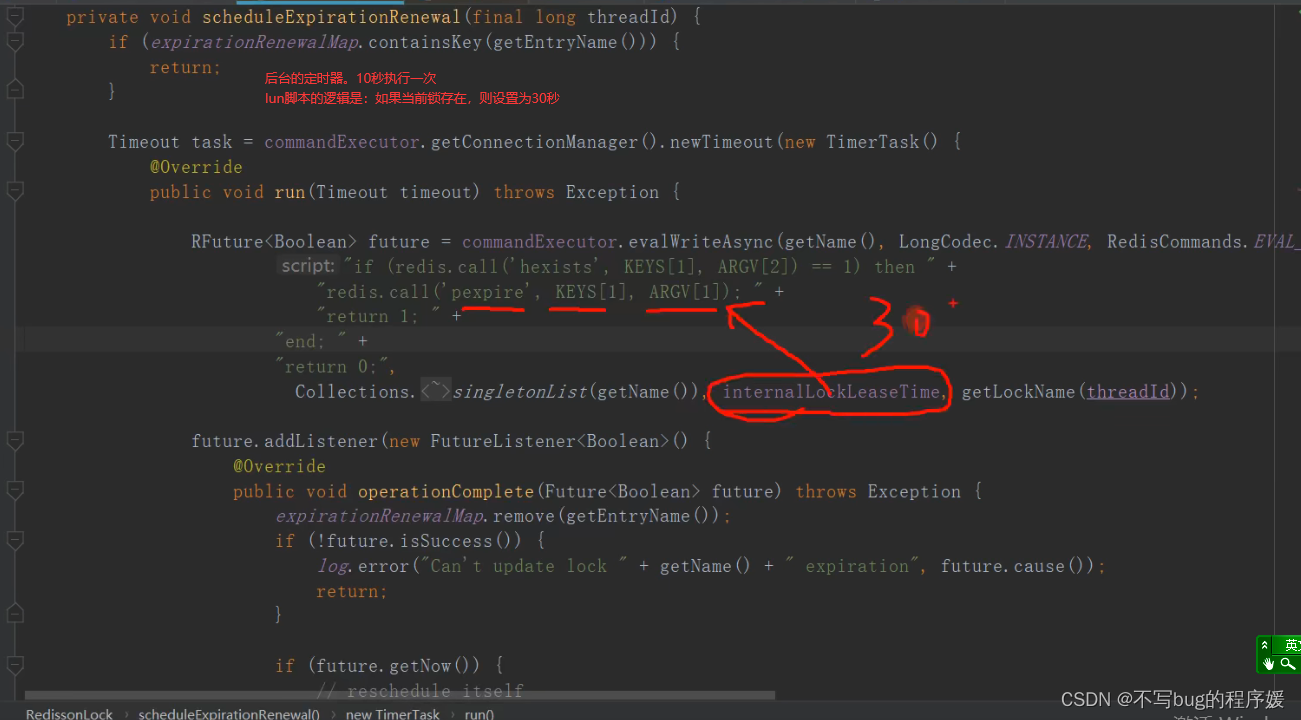
定时任务是30/3=10秒执行一次,用方法嵌套实现的
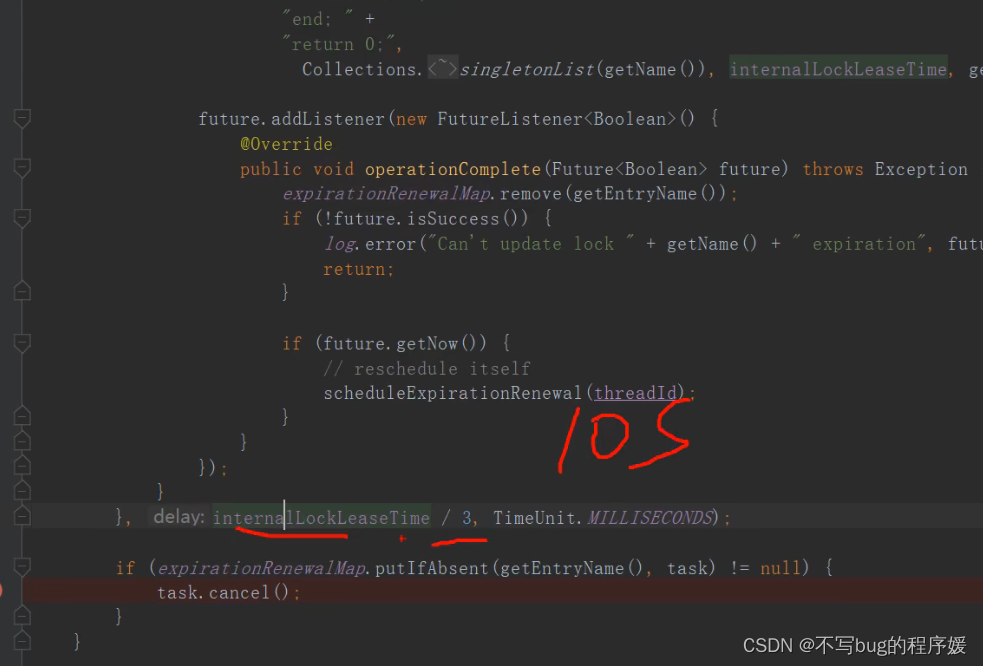
数据双写不一致问题:
??先操作缓存,在写数据库成功之前,如果有读请求发生,可能导致旧数据入缓存,引发数据不一致。
??在分布式环境下,数据的读写都是并发的,上游有多个应用,通过一个服务的多个部署(为了保证可用性,一定是部署多份的),对同一个数据进行读写,在数据库层面并发的读写并不能保证完成顺序,也就是说后发出的读请求很可能先完成(读出脏数据)。
在这里插入图片描述
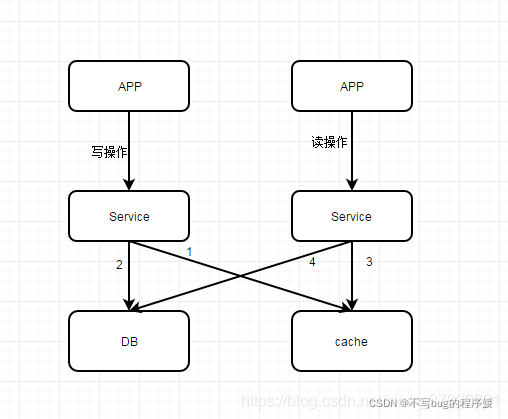
上图解析: 写操作先执行1,删除缓存,再执行2,更新db;而读操作先执行3,读取cache数据,未找到数据时执行4,查询db。
问题所在: 写操作2没执行完时,读操作4执行了,则读到了脏数据到cache中,造成了cache和db的数据不一致问题
方案1:Redis设置key的过期时间。
方案2:采用延时双删策略。
(1)先淘汰缓存
(2)再写数据库(这两步和原来一样)
(3)休眠1秒,再次淘汰缓存
这么做,可以将1秒内所造成的缓存脏数据,再次删除。(为何是1秒?需要评估自己的项目的读数据业务逻辑的耗时。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。当然这种策略还要考虑redis和数据库主从同步的耗时。)
方案三:读写锁,在线程1写操作的时候不可以读和写是互斥的,线程2就不会读到脏数据,读的时候可以多个线程一起读。一般系统都是读多写少
redis的过期策略:

hash的一些命令:
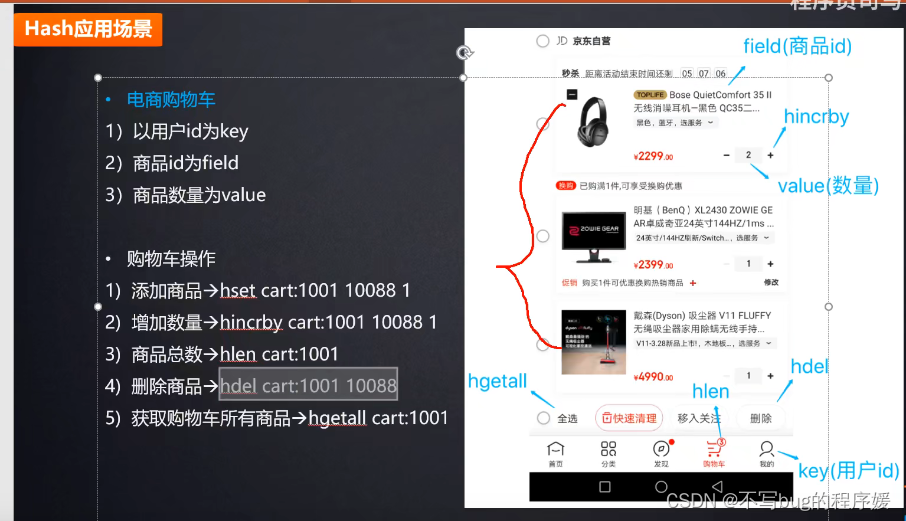
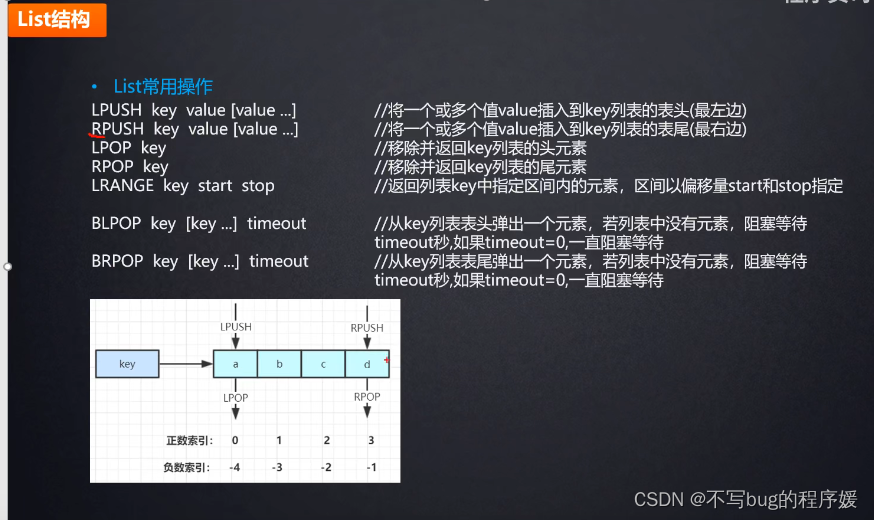

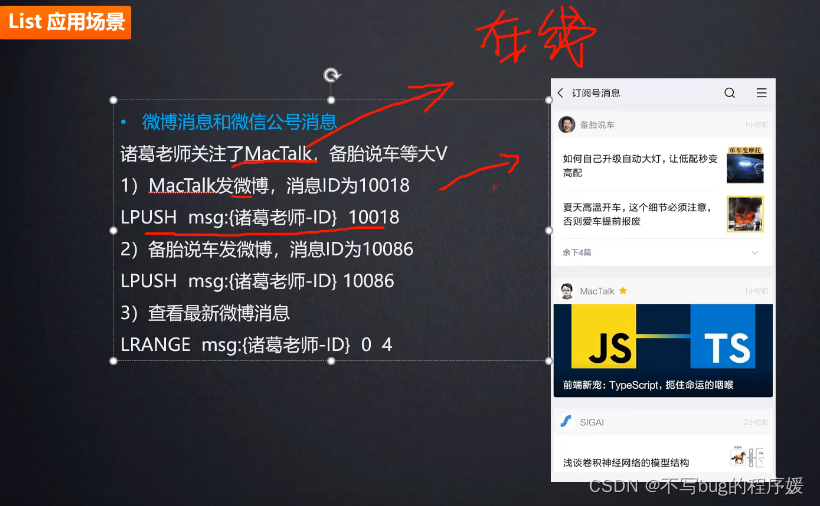
list可以做公众号发消息时显示:
例如我关注了很多个公众号,该公众号发文章的时候会给关注该公众号的用户都执行一条redis命令lpush msg:{用户ID,消息Id}

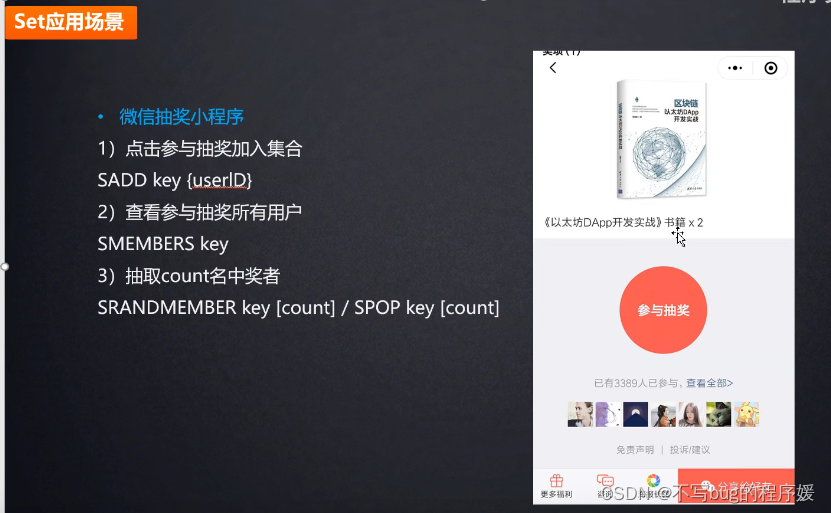
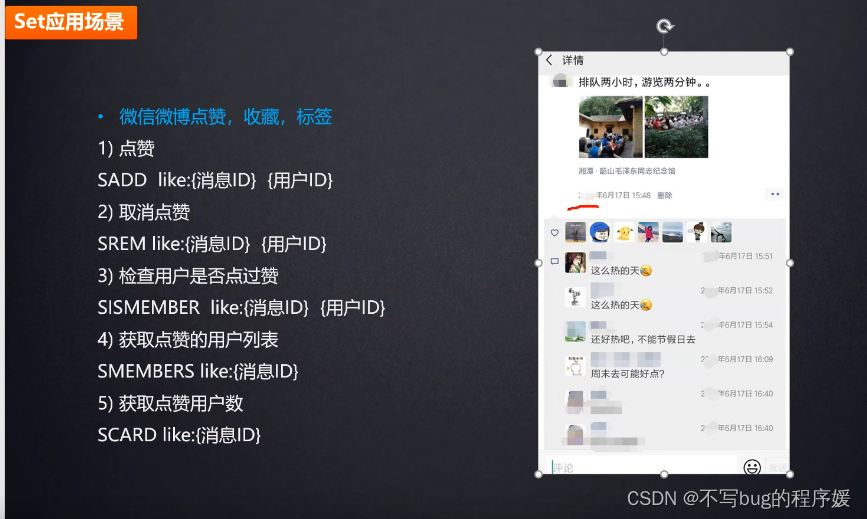
共同朋友点 赞和评论可以用set 的 交集

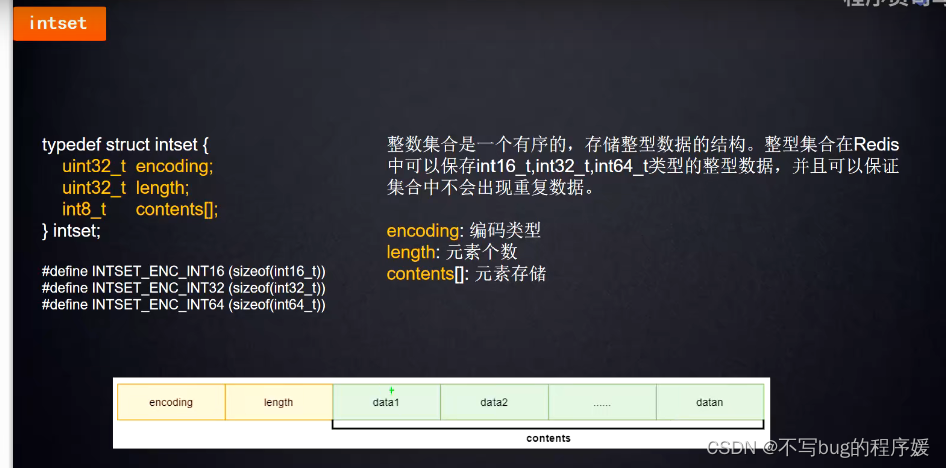
跳表,就是把一个有序的链表改造成二分查找的跳表(解决链表查找慢问题)
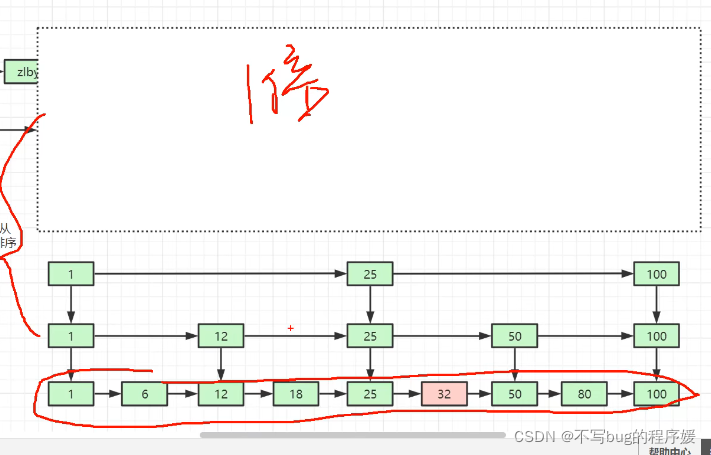
zset 超过128个元素自动转成跳表






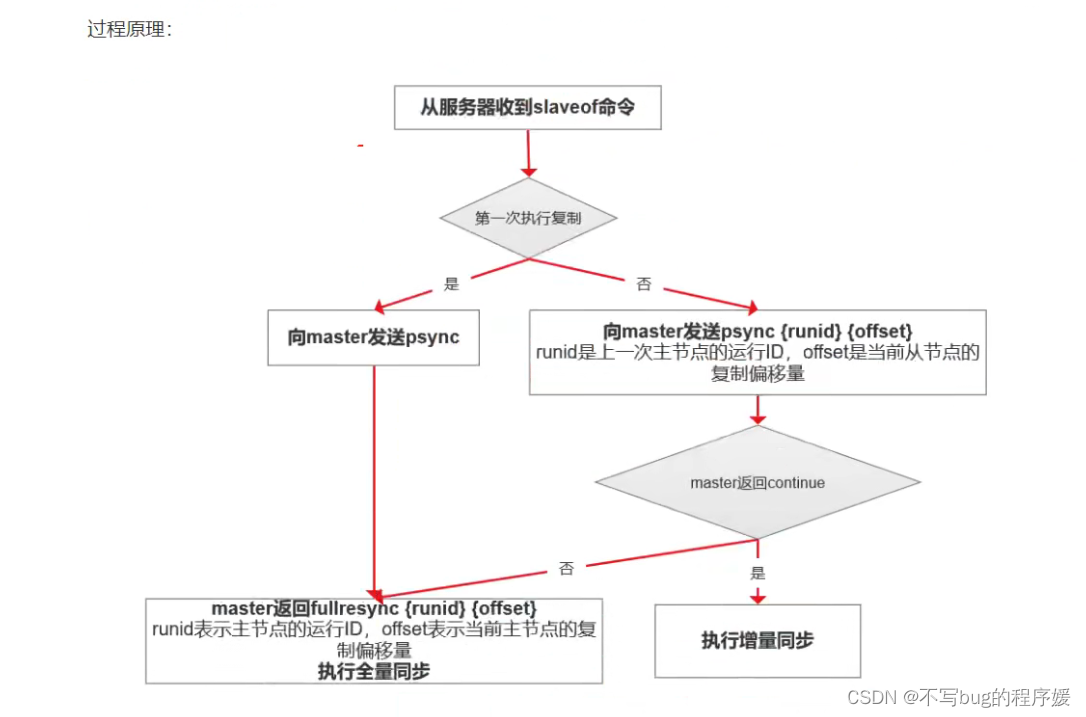
主从复制 :





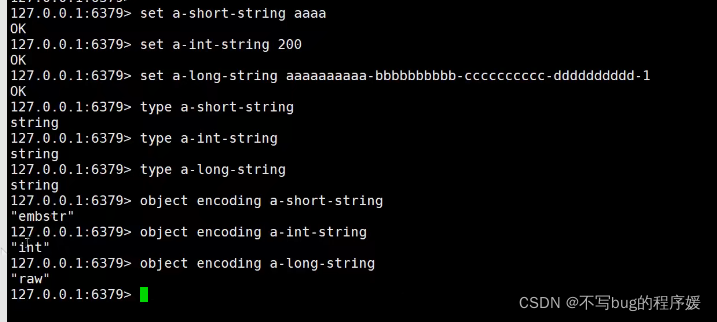
object encoding key值 就是查看该key在redis中真实存储的类型
type key值 都是string
集群模式(分片):redis cluster
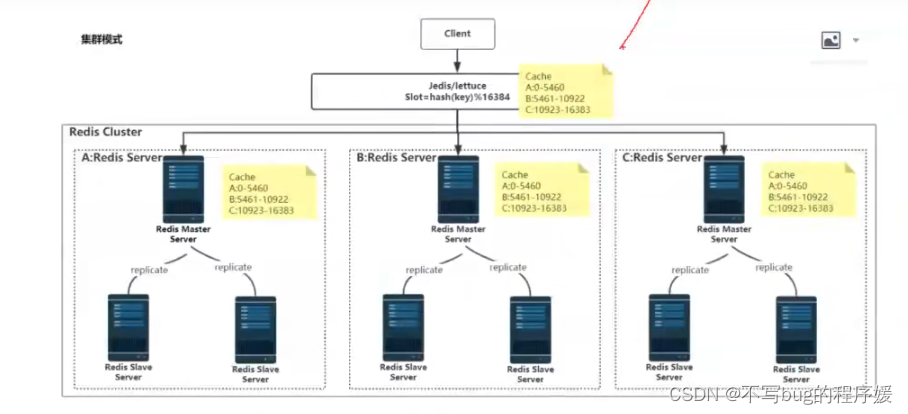
对key进行hash然后%16384就是存和取第几个集群
A: 0-5460
B: 5461-10922
C: 10923-16383
能提供多少个集群,就看有多少个主节点,对外提供服务的都是主节点,一般是1000个,理论上有多少个哈希槽就有多少个,可以有16384个,但是集群越多(因为各个节点要通信)网络带宽会受不了