目录
一、布隆过滤器
1. 概念
布隆过滤器是由一个很长的二进制向量和一系列的哈希函数组成。
布隆过滤器可以用于查询一个元素是否存在于一个集合当中,查询结果为以下二者之一:
-
这个元素可能存在于这个集合当中。
-
这个元素一定不存在于这个集合当中。
2. 原理
利用哈希表这个数据结构,通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点(每个点只能表示0或者1),这样一来,我们只要看看这个点是不是1就知道在集合中有没有它了。 这就是Bloom Filter的基本思想。
但是在哈希冲突的情况下,我们无法使用一个哈希函数来判断一个元素是否存在于集合之中,解决方法也简单,就是使用多个哈希函数。
因此,如果其中有一个哈希函数判断该元素不在集合中(元素经过Hash之后映射在位阵列中的点为0),那肯定就不在。如果所有的哈希函数都判断存在,虽然有一定的误判性,也就是元素可能会存在,但比一次校验可靠的多。 这也就是查询结果会是这两种结果的原因。
3. 优缺点
优点
- 节省大量的内存空间、时间复杂度,节省内存空间是因为一个二进制向量。时间复杂度是根据映射函数查询,假设有K个映射函数,那么时间复杂度就是O(K)。
- 比较安全,因为存的不是元素本身,而是二进制向量
缺点
- 存在一定的误判。
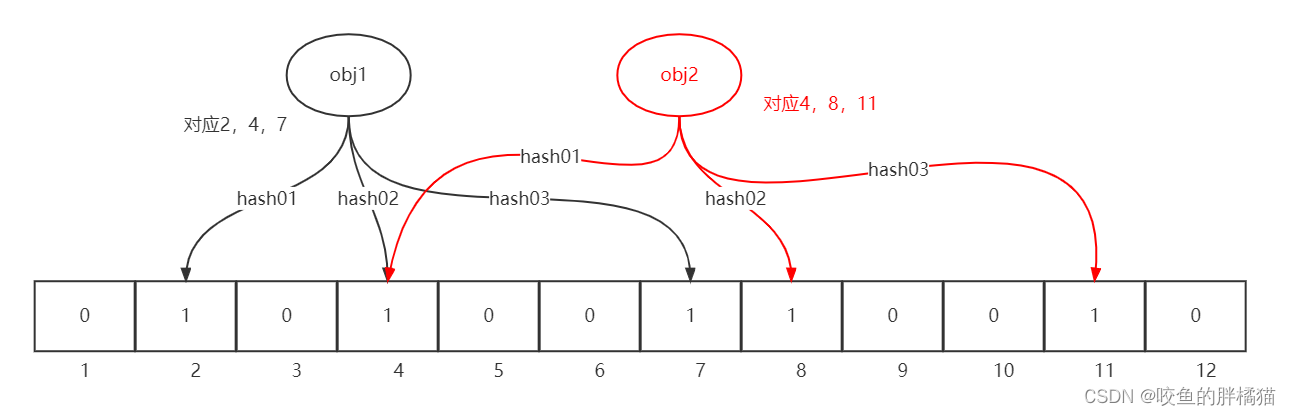
- 不能删除布隆过滤器里的元素。,比如删除obj1,那么2,4,7会置0,判断obj2是否存在时就会导致因为映射点4是0,结果判断obj2是不存在的,结果出错。
4.误判率(FPP)
误判率 fpp 的值越小,匹配的精度越高。当减少误判率 fpp 的值,需要的存储空间也越大,所以在实际使用过程中需要在误判率和存储空间之间做个权衡。
二、代码实践
2.1 guava 实现:数据放在本地内存中
导入依赖
<!--借助guava的布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
测试类
@Test
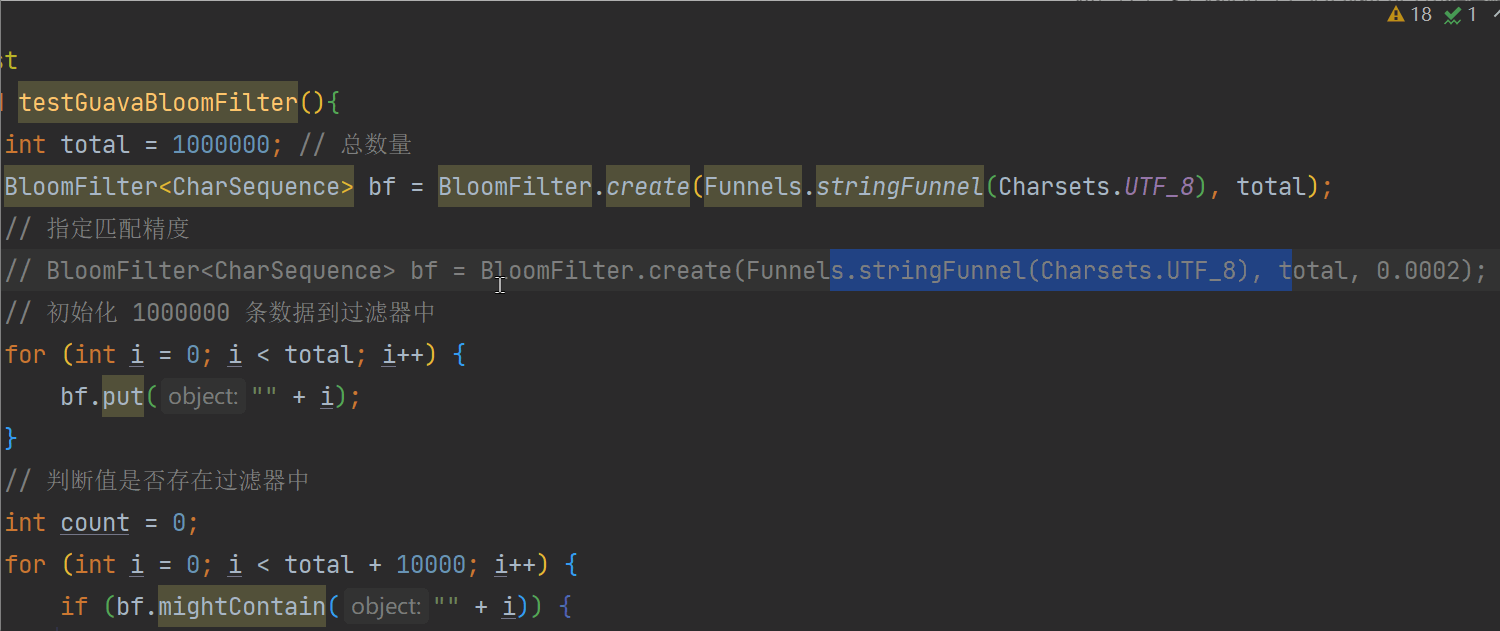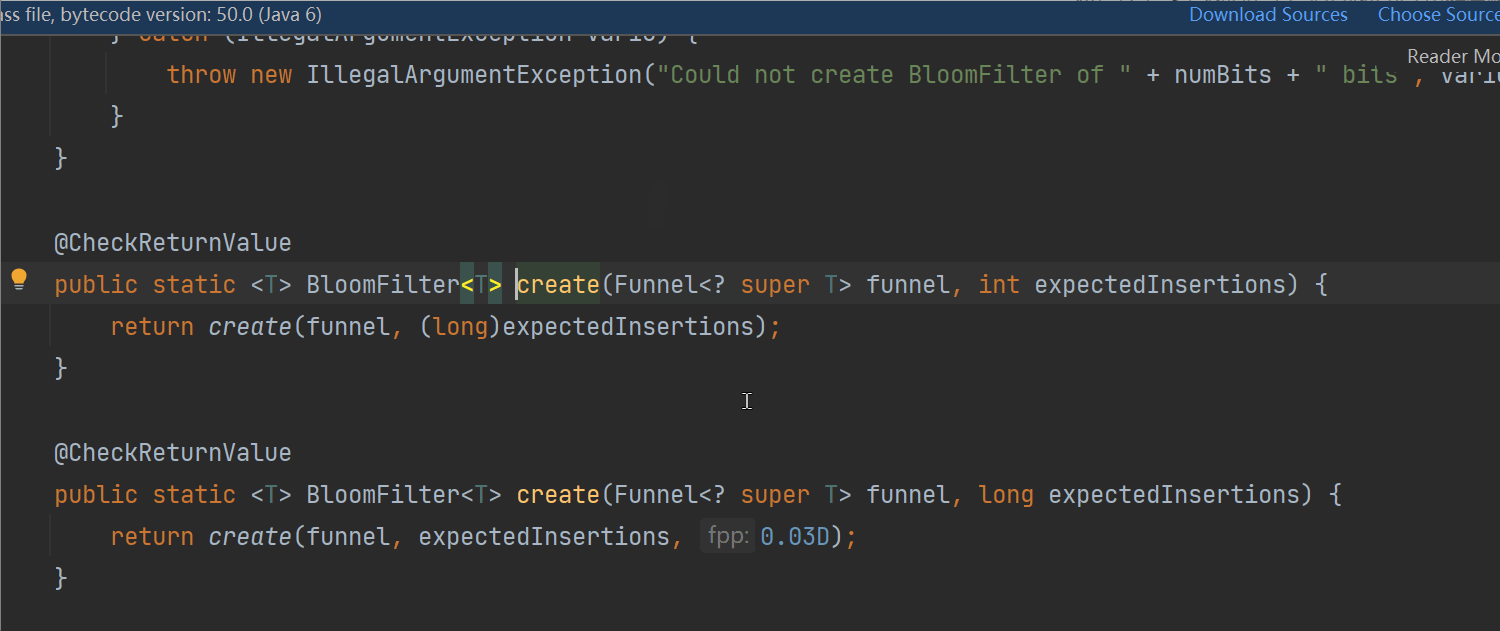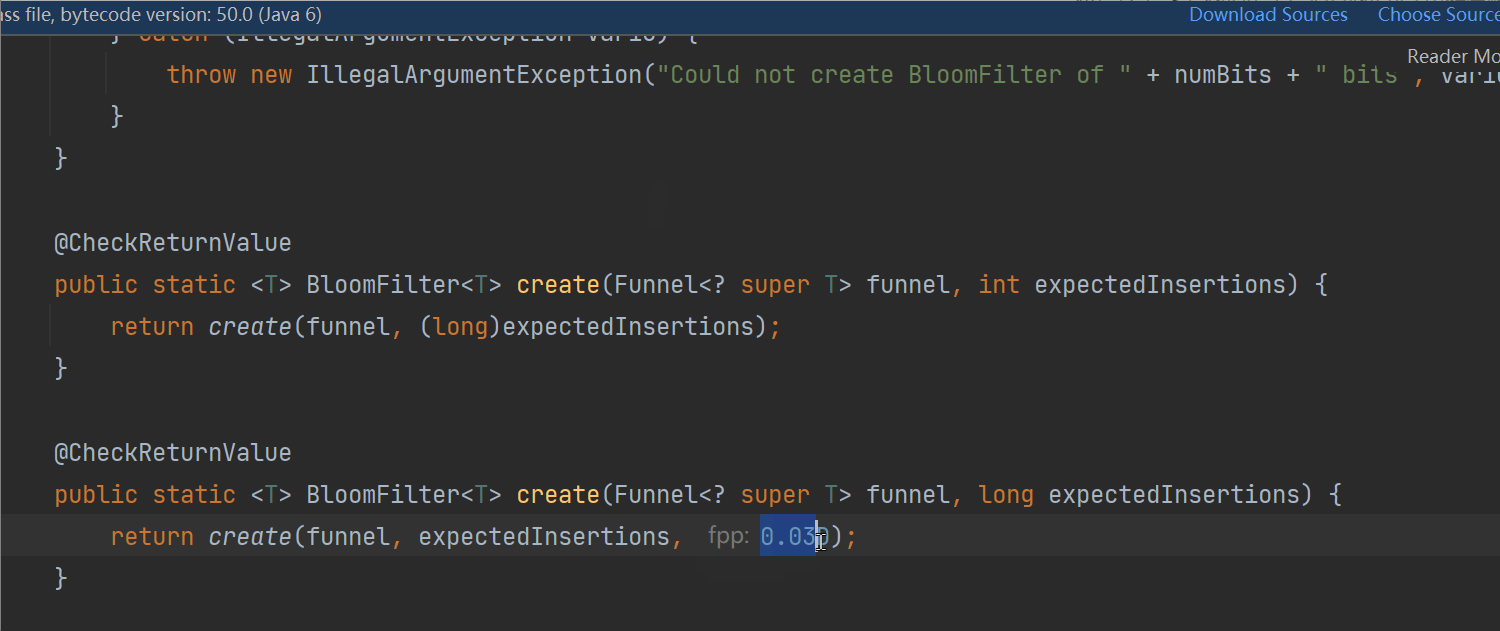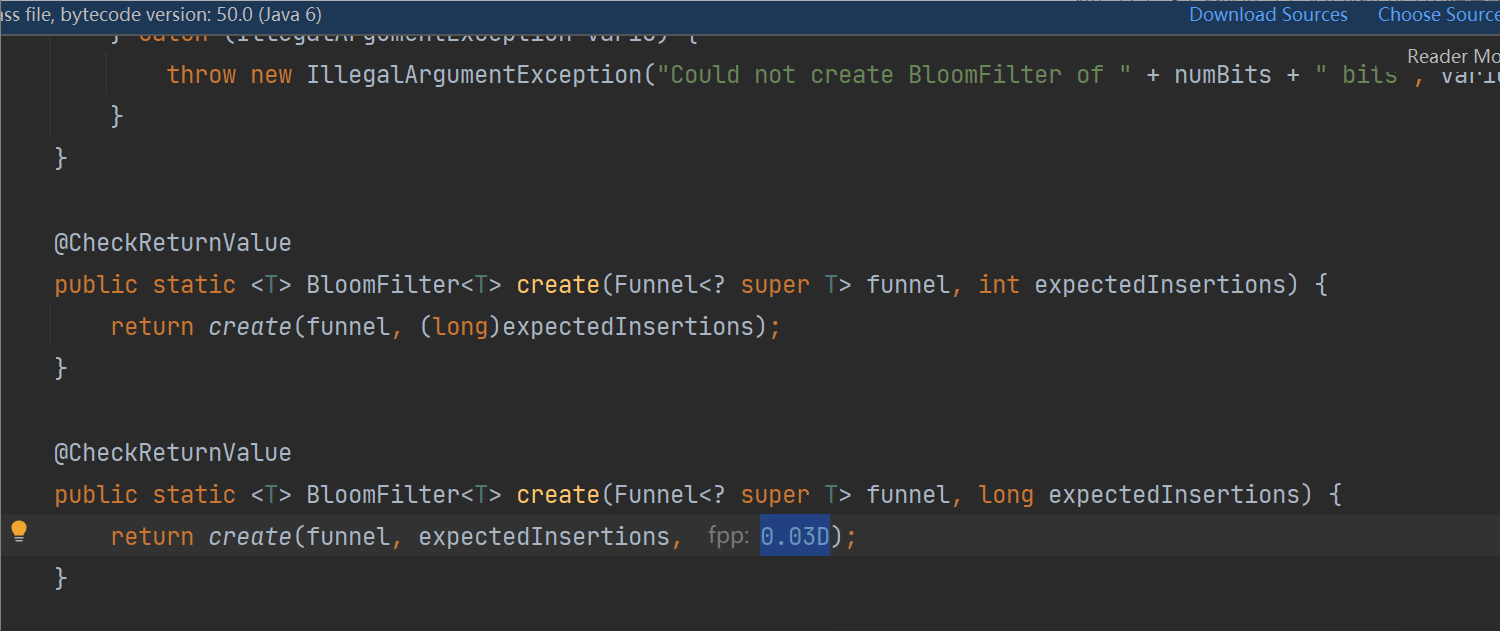
void testGuavaBloomFilter(){
int total = 1000000; // 总数量
BloomFilter<CharSequence> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), total);
// 指定匹配精度
// BloomFilter<CharSequence> bf = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8), total, 0.0002);
// 初始化 1000000 条数据到过滤器中
for (int i = 0; i < total; i++) {
bf.put("" + i);
}
// 判断值是否存在过滤器中
int count = 0;
for (int i = 0; i < total + 10000; i++) {
if (bf.mightContain("" + i)) {
count++;
}
}
System.out.println("已匹配数量 " + count); // 已匹配数量 1000309
}
在guava中,BloomFilter默认的 误判率(FPP)的默认值是 0.03:
2.2 redis 实现:
1. Redission的BloomFilter
依赖
<!-- 借助Redission的布隆过滤器 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.15.0</version>
</dependency>
Redission配置类
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
RedissonClient client = Redisson.create(config);
return client;
}
}
测试类
@SpringBootTest
@Slf4j
class Redis02SpringbootApplicationTest {
@Autowired
private RedissonClient redissonClient;
@Test
void testRedissionBloomFilter() {
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("user");
//尝试初始化,预计元素55,期望误判率0.03
bloomFilter.tryInit(55L, 0.03);
//添加元素到布隆过滤器中
bloomFilter.add("tom");
bloomFilter.add("mike");
bloomFilter.add("rose");
bloomFilter.add("blue");
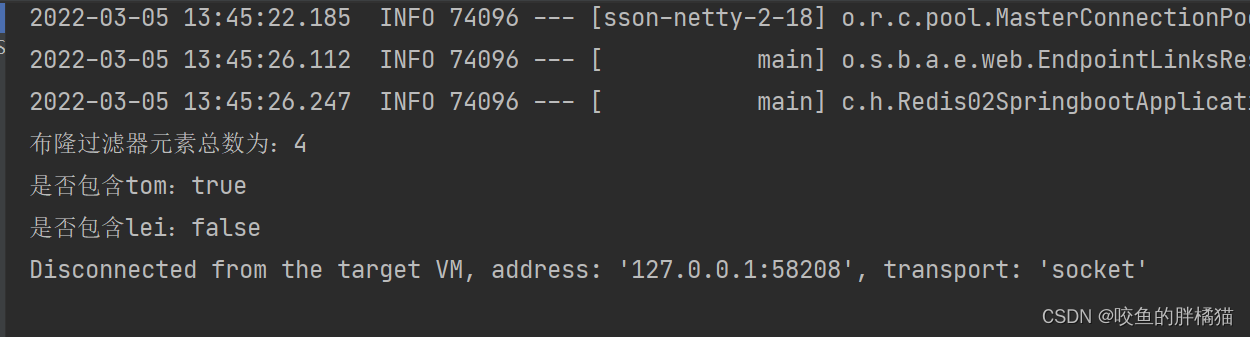
System.out.println("布隆过滤器元素总数为:" + bloomFilter.count());//布隆过滤器元素总数为:4
System.out.println("是否包含tom:" + bloomFilter.contains("tom"));//是否包含tom:true
System.out.println("是否包含lei:" + bloomFilter.contains("lei"));//是否包含lei:false
redissonClient.shutdown();
}
控制台输出结果:
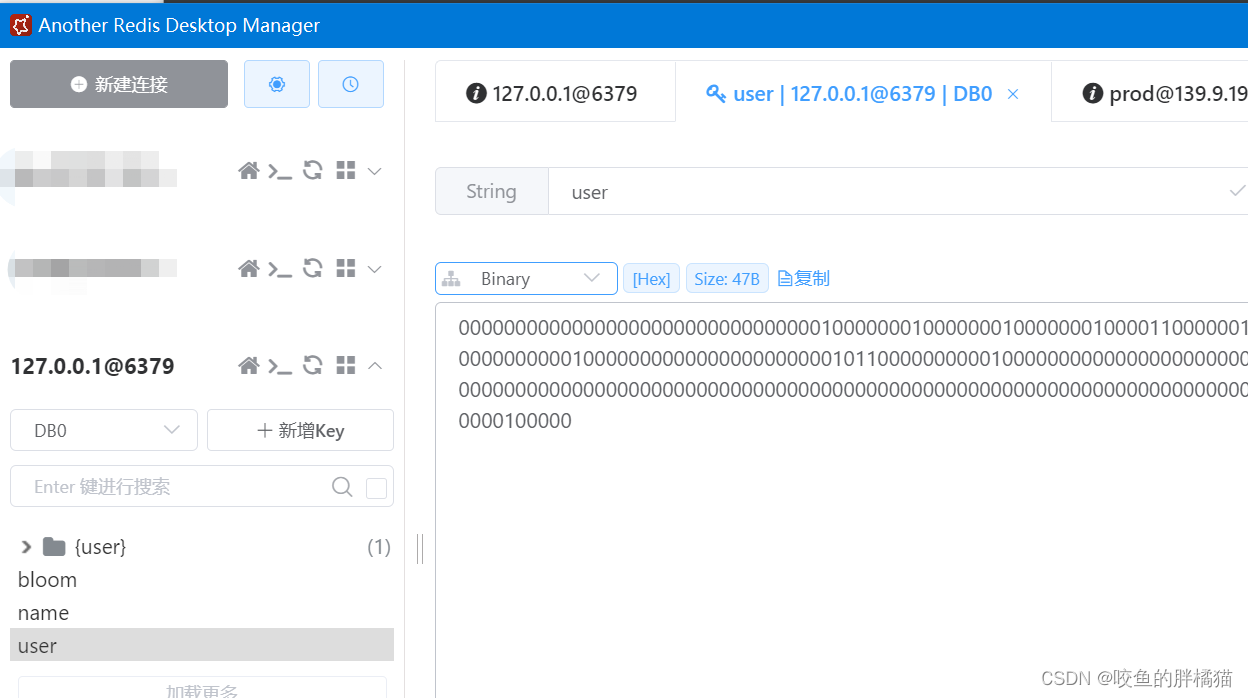
Redis可视化工具:
3. RedisTemplate操作布隆过滤器
依赖
<!--借助guava的布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
布隆过滤器核心类
public class BloomFilterHelper<T> {
private int numHashFunctions;
private int bitSize;
private Funnel<T> funnel;
public BloomFilterHelper(int expectedInsertions) {
this.funnel = (Funnel<T>) Funnels.stringFunnel(Charset.defaultCharset());
bitSize = optimalNumOfBits(expectedInsertions, 0.03);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public BloomFilterHelper(Funnel<T> funnel, int expectedInsertions, double fpp) {
this.funnel = funnel;
bitSize = optimalNumOfBits(expectedInsertions, fpp);
numHashFunctions = optimalNumOfHashFunctions(expectedInsertions, bitSize);
}
public int[] murmurHashOffset(T value) {
int[] offset = new int[numHashFunctions];
long hash64 = Hashing.murmur3_128().hashObject(value, funnel).asLong();
int hash1 = (int) hash64;
int hash2 = (int) (hash64 >>> 32);
for (int i = 1; i <= numHashFunctions; i++) {
int nextHash = hash1 + i * hash2;
if (nextHash < 0) {
nextHash = ~nextHash;
}
offset[i - 1] = nextHash % bitSize;
}
return offset;
}
/**
* 计算bit数组长度
*/
private int optimalNumOfBits(long n, double p) {
if (p == 0) {
p = Double.MIN_VALUE;
}
return (int) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 计算hash方法执行次数
*/
private int optimalNumOfHashFunctions(long n, long m) {
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}
redis操作布隆过滤器工具类
@Component
public class RedisBloomFilterUtil<T> {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 根据给定的布隆过滤器添加值,在添加一个元素的时候使用,批量添加的性能差
*
* @param bloomFilterHelper 布隆过滤器对象
* @param key KEY
* @param value 值
* @param <T> 泛型,可以传入任何类型的value
*/
public <T> void add(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
redisTemplate.opsForValue().setBit(key, i, true);
}
}
/**
* 根据给定的布隆过滤器添加值,在添加一批元素的时候使用,批量添加的性能好,使用pipeline方式(如果是集群下,请使用优化后RedisPipeline的操作)
*
* @param bloomFilterHelper 布隆过滤器对象
* @param key KEY
* @param valueList 值,列表
*/
public void addList(BloomFilterHelper<CharSequence> bloomFilterHelper, String key, List<String> valueList) {
redisTemplate.executePipelined(new RedisCallback<Long>() {
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
connection.openPipeline();
for (String value : valueList) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
connection.setBit(key.getBytes(), i, true);
}
}
return null;
}
});
}
/**
* 根据给定的布隆过滤器判断值是否存在
*
* @param bloomFilterHelper 布隆过滤器对象
* @param key KEY
* @param value 值
* @param <T> 泛型,可以传入任何类型的value
* @return 是否存在
*/
public <T> boolean contains(BloomFilterHelper<T> bloomFilterHelper, String key, T value) {
int[] offset = bloomFilterHelper.murmurHashOffset(value);
for (int i : offset) {
if (!redisTemplate.opsForValue().getBit(key, i)) {
return false;
}
}
return true;
}
}
测试类
@SpringBootTest
@Slf4j
class Redis02SpringbootApplicationTest {
@Autowired
private RedisBloomFilterUtil<?> redisBloomFilterUtil;
@Test
void testRedisBloomFilter(){
// 预计插入的元素总数
int expectedInsertions = 1000;
// 期望误判率
double fpp = 0.1;
if (redisUtil.hasKey("bloom")){
redisUtil.del("bloom");
}
BloomFilterHelper<CharSequence> bloomFilterHelper = new BloomFilterHelper<>(Funnels.stringFunnel(Charset.defaultCharset()), expectedInsertions, fpp);
int j = 0;
// 添加100个元素
List<String> valueList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
valueList.add(i + "");
}
long beginTime = System.currentTimeMillis();
redisBloomFilterUtil.addList(bloomFilterHelper, "bloom", valueList);
long costMs = System.currentTimeMillis() - beginTime;
log.info("-----------------------------------------------------------------");
log.info("布隆过滤器添加{}个值,耗时:{}ms", 100, costMs);
log.info("测试查看1千条数据");
beginTime = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
boolean result = redisBloomFilterUtil.contains(bloomFilterHelper, "bloom", i + "");
if (!result) {
j++;
}
}
log.info("漏掉了{}个,验证结果耗时:{}ms", j, System.currentTimeMillis() - beginTime);
}
}
控制台结果:

Redis可视化工具: