数据准备
创建表格
学生表
CREATE TABLE IF NOT EXISTS `student`(
id INT AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL,
age INT NOT NULL,
sex VARCHAR(50) NOT NULL,
PRIMARY KEY (id)
)
注意自增的必须为主键
插入数据
INSERT INTO student(`name`,age,sex)VALUES('孙悟空',18,'male');
INSERT INTO student(`name`,age,sex)VALUES('唐僧',20,'male');
INSERT INTO student(`name`,age,sex)VALUES('沙和尚',30,'male');
INSERT INTO student(`name`,age,sex)VALUES('猪八戒',30,'male');
INSERT INTO student(`name`,age,sex)VALUES('女儿国王',20,'female');
INSERT INTO student(`name`,age,sex)VALUES('白骨精',18,'female');
创建的表格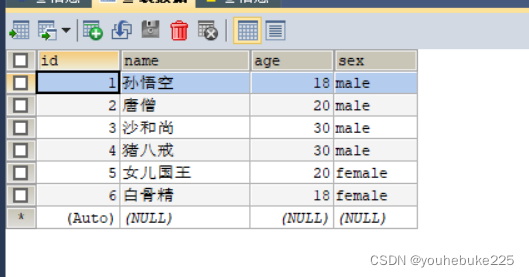
语法
一般认为分组有去重的效果,但是分组不仅仅是去重,一般可以这样想
- 按照某个字段进行分组,那么这个字段具有相同的值的都会放到一个几个中
- 一旦分组,表格(集合)
1. 简单的分组
SELECT * FROM 表 GROUP BY 字段
如我们执行下面语句
SELECT * FROM student GROUP BY age;
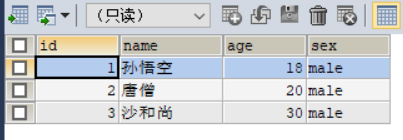
我们看到的是每组只显示一个数据,这个数据就是表中比较位置比较靠前的数据
报错处理
如果出现一下报错Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'studydb.student.id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by,请点击
2. 与聚合函数一起使用
SELECT 字段名,聚合函数(字段名) FROM 表 GROUP BY 字段名
常见聚合函数
count,sum,avg,max,min
我们执行下面的sql
SELECT age,count(age) FROM student GROUP BY age;
查询结果如下
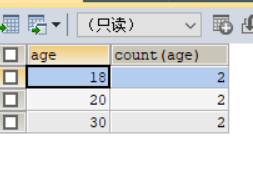
我们可以清楚的看到age为18的有2个,age为20的有2个,age为30的有2个
group_concat
倘若我们想要知道,age为18的有哪两个,这个时候就会用到
group_concat函数
执行下面的sql语句
SELECT age,COUNT(age) AS 个数, GROUP_CONCAT(`name`) AS 名字 FROM student GROUP BY age;
得到如下结果
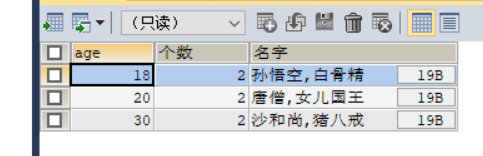
3. 条件
select 字段 from 表
GROUP BY 字段
HAVING 条件;
使用HAVING来进行条件的查询
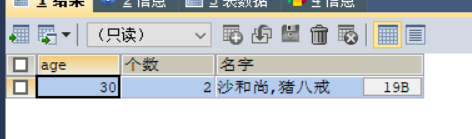
SELECT age,COUNT(age) AS 个数, GROUP_CONCAT(`name`) AS 名字
FROM student
GROUP BY age
HAVING age > 20;
他一般是将组分号之后,再进行筛选,比如筛选出年龄大于20的人的个数
与where的区别
- where一般用于在分组之前的查询,便是能用where查询的就用where查询
- having一般用于分组之后的查询,结合着聚合函数进行查询(where一般不可以)
4. group by + 多字段
如果group by 后面是多个字段,那么最终所得的结果应该是每个字段的排列组合
例子
SELECT age AS 年龄,sex AS 性别,GROUP_CONCAT(`name`) AS 名字,COUNT(age) AS 个数
FROM student
GROUP BY age ,sex;
结果如下
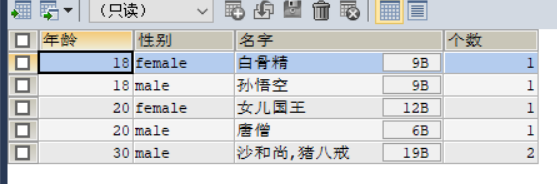
- 使用年龄进行分组,在我们的表中能分三组, 18 ,20,30
- 使用性别进行分组,在我们的表中能分为两组, female,male
- group by跟多个字段,那么两个分组进行排列组合,会分成六组,但是因为有一组没有数据,所以就没有数据