线上故障之-redis锁处理幂等性失效和幂等性问题解决方案
redis锁处理幂等性失效
@Override
@Transactional(rollbackFor = Exception.class)
public void addError(User user) {
log.info("add user params user:{}", JSON.toJSONString(user));
Assert.isTrue(StringUtils.isNotBlank(user.getIdCard()), "身份证号不允许null");
String key = "key";
RLock lock = redissonClient.getLock(key);
lock.lock();
try {
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
.eq(User::getIdCard, user.getIdCard());
long count = userMapper.selectCount(wrapper);
if (count == 0) {
userMapper.insert(user);
}
} catch (Exception e) {
log.error("add user error", e);
} finally {
lock.unlock();
}
System.out.println("并发执行,同时插入了两条");
}
以上代码问题:
1:对事物的理解使用有问题,幂等设计bug
2:redis锁使用有问题(单独案例讲述)
详细解释:
锁是在事务内,多线程进来是不同的事务,到System.out.println("并发执行,同时插入了两条");事务还未提交,所以查不到数据,但锁却释放了。
优化
@Override
@Transactional(rollbackFor = Exception.class)
public void addOk(User user) {
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
.eq(User::getIdCard, user.getIdCard());
long count = userMapper.selectCount(wrapper);
if (count == 0) {
userMapper.insert(user);
}
}
//正例
@Test
public void addTest() {
User user = new User();
user.setName("张三");
user.setIdCard("1000");
String key = "key";
RLock lock = redissonClient.getLock(key);
lock.lock();
try {
userService.addOk(user);
} catch (Exception e) {
e.printStackTrace();
}finally {
lock.unlock();
}
}
拆开后,锁的时候把整个事务都锁住。
扩展:
事务在生产实践中经常犯的错误:
事务范围:应该加入事务的代码未加入到事务中
下图是另一个真实生产当中的事故-仅供参考:
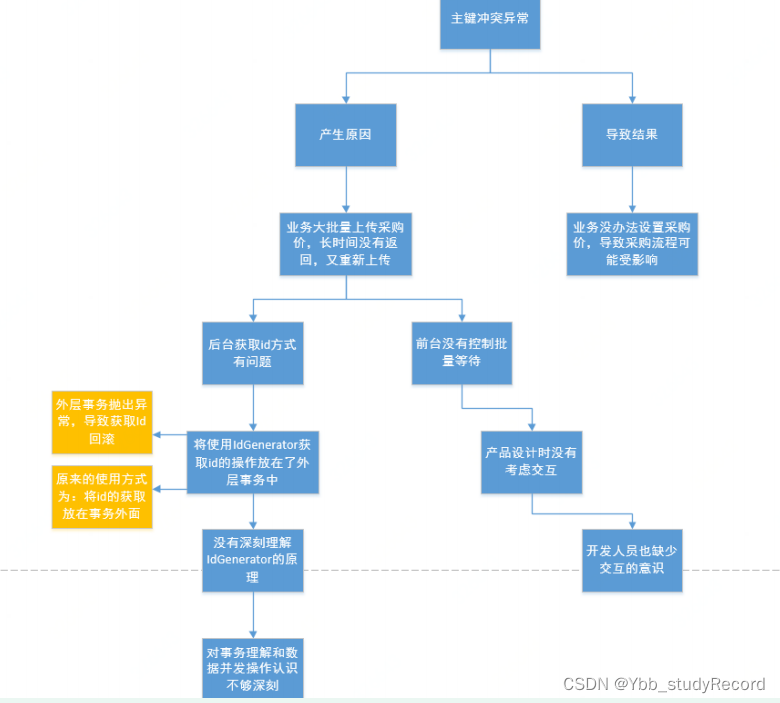
事务大小:事务过大,是否有必要拆解小事务(如何优化),拆解后一致性问题。
传播范围(异常标注):
多线程中不可传播
多个方法内如果异常被捕获将要被标记为异常事务,不可以再次提交(虽然不影响数据,但是有报错信息)
事务传播bug
try bug
@Override
@Transactional(rollbackFor = Exception.class)
public void b() {
User user = new User();
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
.eq(User::getIdCard, "1000");
User user1 = userMapper.selectOne(wrapper);
user1.setName("lisi");
userMapper.updateById(user1);
System.out.println(1 / 0);
}
@Override
@Transactional(rollbackFor = Exception.class)
public void a() {
/* try {
userServiceB.b();
} catch (Exception e) {
e.printStackTrace();
}*/
User user = new User();
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
.eq(User::getIdCard, "1000");
User user1 = userMapper.selectOne(wrapper);
user1.setName("zhangsan");
userMapper.updateById(user1);
userServiceB.b();
}
这种就是正常的提交
2022-03-04 15:43:05 INFO - [ main] debug.idempotent.moduler.UserServiceTest. logStarted 61 : Started UserServiceTest in 14.13 seconds (JVM running for 15.681)
2022-03-04 15:43:06 DEBUG - [ main] work.jdbc.support.JdbcTransactionManager.etTransaction 370 : Creating new transaction with name [com.mashibing.debug.idempotent.moduler.service.impl.UserServiceImpl.addError]: PROPAGATION_REQUIRED,ISOLATION_DEFAULT,-java.lang.Exception
2022-03-04 15:43:06 INFO - [ main] com.zaxxer.hikari.HikariDataSource .getConnection 110 : HikariPool-1 - Starting...
2022-03-04 15:43:06 WARN - [ main] com.zaxxer.hikari.util.DriverDataSource . <init> 70 : Registered driver with driverClassName=com.mysql.jdbc.Driver was not found, trying direct instantiation.
2022-03-04 15:43:07 INFO - [ main] com.zaxxer.hikari.HikariDataSource .getConnection 123 : HikariPool-1 - Start completed.
2022-03-04 15:43:07 DEBUG - [ main] work.jdbc.support.JdbcTransactionManager. doBegin 267 : Acquired Connection [HikariProxyConnection@553629909 wrapping com.mysql.cj.jdbc.ConnectionImpl@307c59ea] for JDBC transaction
2022-03-04 15:43:07 DEBUG - [ main] work.jdbc.support.JdbcTransactionManager. doBegin 285 : Switching JDBC Connection [HikariProxyConnection@553629909 wrapping com.mysql.cj.jdbc.ConnectionImpl@307c59ea] to manual commit
2022-03-04 15:43:08 INFO - [ main] ent.moduler.service.impl.UserServiceImpl. addError 36 : add user params user:{"idCard":"1000","name":"张三"}
2022-03-04 15:43:08 DEBUG - [ main] nt.moduler.mapper.UserMapper.selectCount. debug 137 : ==> Preparing: SELECT COUNT( * ) FROM user WHERE is_delete=0 AND (id_card = ?)
2022-03-04 15:43:08 DEBUG - [ main] nt.moduler.mapper.UserMapper.selectCount. debug 137 : ==> Parameters: 1000(String)
2022-03-04 15:43:08 DEBUG - [ main] nt.moduler.mapper.UserMapper.selectCount. debug 137 : <== Total: 1
并发执行,同时插入了两条
2022-03-04 15:43:08 DEBUG - [ main] work.jdbc.support.JdbcTransactionManager.processCommit 740 : Initiating transaction commit
2022-03-04 15:43:08 DEBUG - [ main] work.jdbc.support.JdbcTransactionManager. doCommit 330 : Committing JDBC transaction on Connection [HikariProxyConnection@553629909 wrapping com.mysql.cj.jdbc.ConnectionImpl@307c59ea]
2022-03-04 15:43:08 DEBUG - [ main] work.jdbc.support.JdbcTransactionManager.terCompletion 389 : Releasing JDBC Connection [HikariProxyConnection@553629909 wrapping com.mysql.cj.jdbc.ConnectionImpl@307c59ea] after transaction
2022-03-04 15:43:08 INFO - [onShutdownHook] com.zaxxer.hikari.HikariDataSource . close 350 : HikariPool-1 - Shutdown initiated...
2022-03-04 15:43:08 INFO - [onShutdownHook] com.zaxxer.hikari.HikariDataSource . close 352 : HikariPool-1 - Shutdown completed.
@Override
@Transactional(rollbackFor = Exception.class)
public void a() {
try {
userServiceB.b();
} catch (Exception e) {
e.printStackTrace();
}
User user = new User();
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
.eq(User::getIdCard, "1000");
User user1 = userMapper.selectOne(wrapper);
user1.setName("zhangsan");
userMapper.updateById(user1);
}
如果try住了,会出现下面sql执行完后,无法提交的情况。最后事务是既没有提交也没有回滚,出现报错。
总结:事务在提交的时候检查了事务状态码,这个时候发现事务被标记为已回滚,结果还是在提交。
Global transaction is marked as rollback-only but transactional code requested commit
org.springframework.transaction.UnexpectedRollbackException: Transaction rolled back because it has been marked as rollback-only
幂等性设计方法
幂等性设计:
- 有时我们在填写某些 form表单 时,保存按钮不小心快速点了两次,表中竟然产生了两条重复的数据,只是id不一样。
- 我们在项目中为了解决 接口超时 问题,通常会引入了 重试机制 。第一次请求接口超时了,请求方没能及时获取返回结果(此时有可能已经成功了),为了避免返回错误的结果(这种情况不可能直接返回失败吧?),于是会对该请求重试几次,这样也会产生重复的数据。
- mq消费者在读取消息时,有时候会读取到 重复消息 ,如果处理不好,也会产生重复的数据。
前端是防不住的
接口幂等性 是指用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。
这类问题多发于接口的:
insert 操作,这种情况下多次请求,可能会产生重复数据。
update 操作,如果只是单纯的更新数据,比如: update user set status=1 where id=1 ,是没有问题的。如果还有计算,比如: update user set status=status+1 where id=1 ,这种情况下多次请求,可能会导致数据错误。
那么我们要如何保证接口幂等性?本课程将会告诉你答案。
1. insert前先select
通常情况下,在保存数据的接口中,我们为了防止产生重复数据,一般会在 insert 前,先根据 name 或 code 字段 select 一下数据。如果该数据已存在,则执行 update 操作,如果不存在,才执行 insert 操作。
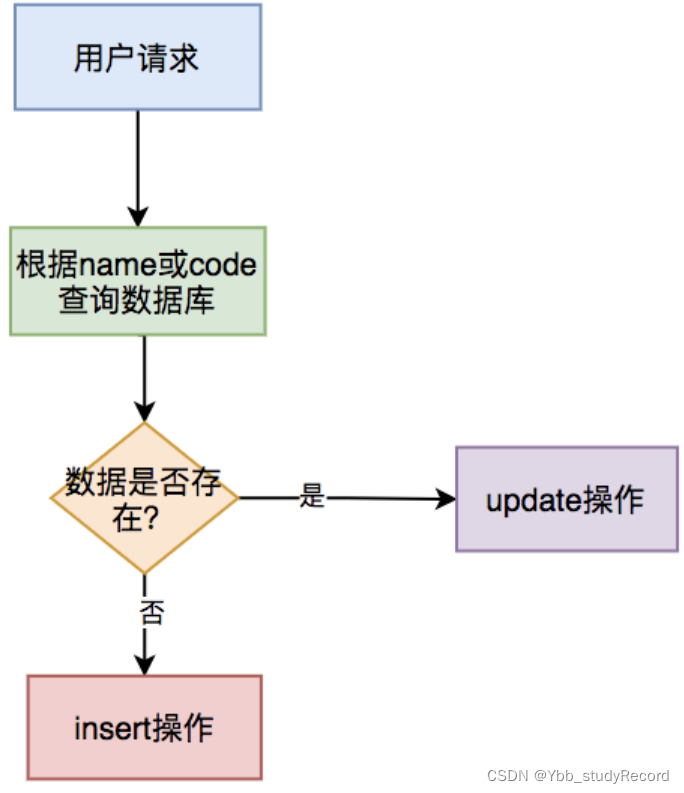
该方案可能是我们平时在防止产生重复数据时,使用最多的方案。但是该方案不适用于并发场景,在并发场景中,要配合其他方案一起使用,否则同样会产生重复数据。
2. 加悲观锁
1)支付场景在加减库存场景中,用户A的账号余额有150元,想转出100元,正常情况下用户A的余额只剩50元。一般情况下,sql是这样的:
update user amount = amount-100 where id=123;
如果出现多次相同的请求,可能会导致用户A的余额变成负数。这种情况,用户A来可能要哭了。于此同时,系统开发人员可能也要哭了,因为这是很严重的系统bug。
为了解决这个问题,可以加悲观锁,将用户A的那行数据锁住,在同一时刻只允许一个请求获得锁,更新数据,其他的请求则等待。
通常情况下通过如下sql锁住单行数据:
select * from user id=123 for update;
条件:数据库引擎为innoDB
操作位于事务中
具体流程如下:
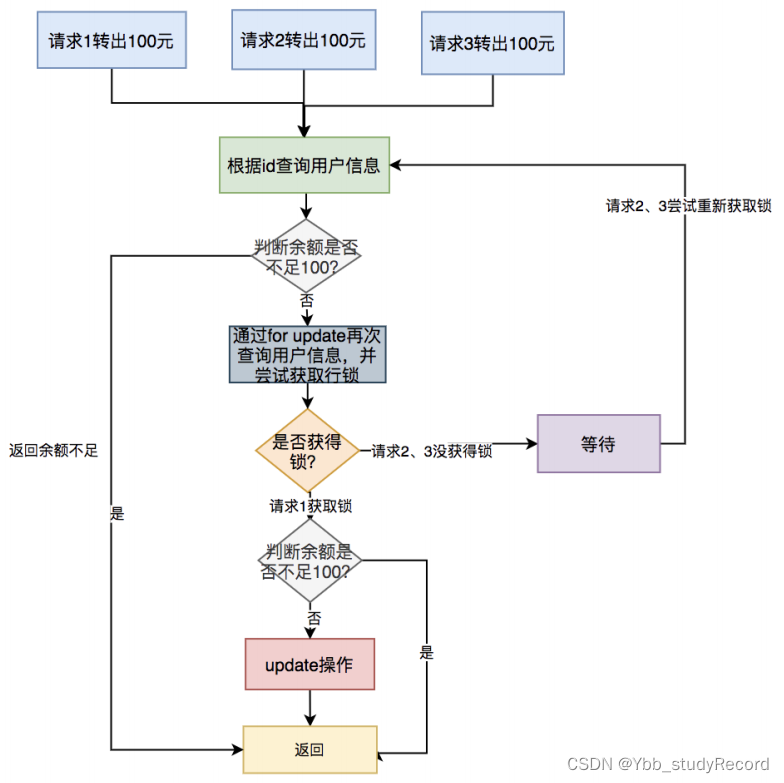
具体步骤:
- 多个请求同时根据id查询用户信息。
- 判断余额是否不足100,如果余额不足,则直接返回余额不足。
- 如果余额充足,则通过for update再次查询用户信息,并且尝试获取锁。
- 只有第一个请求能获取到行锁,其余没有获取锁的请求,则等待下一次获取锁的机会。
- 第一个请求获取到锁之后,判断余额是否不足100,如果余额足够,则进行update操作。
- 如果余额不足,说明是重复请求,则直接返回成功。
2)操作库存场景
select* from stock_info where goods_id=12312 and storage_id=1 for update;
具体流程:
a:单件货品操作流程
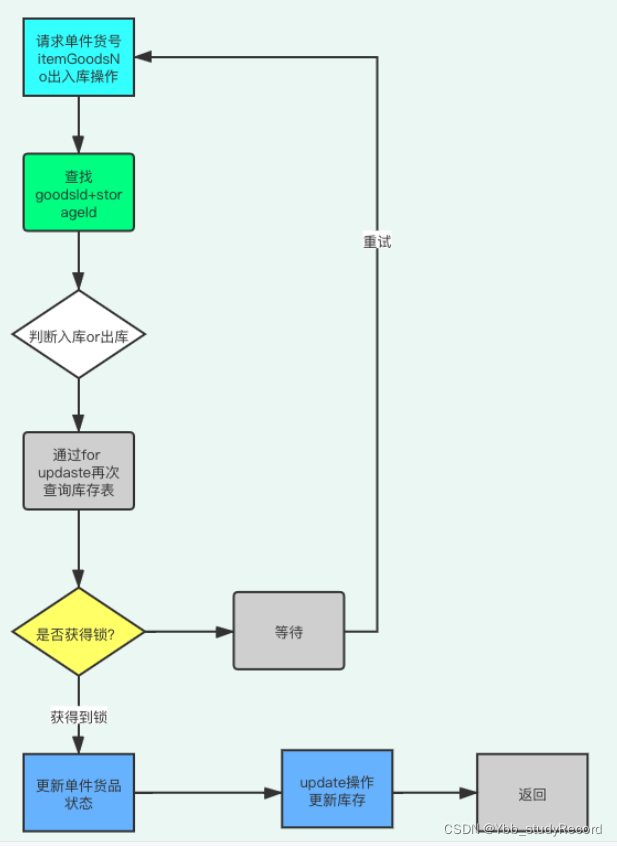
b:(同一个goodsId)多个单件货品,批量操作出库流程

具体步骤: - 多个请求同时根据goodsId和storageId操作货品的上下架,或者其他渠道订单批量下架操
作 - 判断当前货品是否有仓库货品
- 如果货品库存充足,则通过for update再次查询货品库存信息,并且尝试获取锁。
- 只有第一个请求能获取到行锁,其余没有获取锁的请求,则等待下一次获取锁的机会。
- 第一个请求获取到锁之后,进行货品单件明细状态变更,成功后操作,则进行update操作
加减库存。 - 如果库存不足或者单件不满足操作,则直接返回成功或者幂等状态。
需要特别注意的是:如果使用的是mysql数据库,存储引擎必须用innodb,因为它才支持事
务。此外,这里id字段一定要是主键或者唯一索引,不然会锁住整张表。
悲观锁需要在同一个事务操作过程中锁住一行数据,如果事务耗时比较长,会造成大量的请求等待,影响接口性能。此外,每次请求接口很难保证都有相同的返回值,所以不适合幂等性设计场景,但是在防重场景中是可以的使用的。在这里顺便说一下, 防重设计 和 幂等设计 ,其实是有区别的。防重设计主要为了避免产生重复数据,对接口返回没有太多要求。而幂等设计除了避免产生重复数据之外,还要求每次请求都返回一样的结果。
3. 加乐观锁
既然悲观锁有性能问题,为了提升接口性能,我们可以使用乐观锁。需要在表中增加一个
timestamp 或者 version 字段,这里以 version 字段为例。
在更新数据之前先查询一下数据:
如果数据存在,假设查到的 version 等于 1 ,再使用 id 和 version 字段作为查询条件更新数据:
更新数据的同时 version+1 ,然后判断本次 update 操作的影响行数,如果大于0,则说明本次更新成功,如果等于0,则说明本次更新没有让数据变更。
由于第一次请求 version 等于 1 是可以成功的,操作成功后 version 变成 2 了。这时如果并发的请求过来,再执行相同的sql:
该 update 操作不会真正更新数据,最终sql的执行结果影响行数是 0 ,因为 version 已经变成 2了, where 中的 version=1 肯定无法满足条件。但为了保证接口幂等性,接口可以直接返回成功,因为 version 值已经修改了,那么前面必定已经成功过一次,后面都是重复的请求。
具体流程如下:

具体步骤:
- 先根据id查询用户信息,包含version字段
- 根据id和version字段值作为where条件的参数,更新用户信息,同时version+1
- 判断操作影响行数,如果影响1行,则说明是一次请求,可以做其他数据操作。
- 如果影响0行,说明是重复请求,则直接返回成功。
4. 加唯一索引(最简单和稳定)
绝大数情况下,为了防止重复数据的产生,我们都会在表中加唯一索引,这是一个非常简单,并且有效的方案。
alter table `order` add UNIQUE KEY `un_code` (`code`);
加了唯一索引之后,第一次请求数据可以插入成功。但后面的相同请求,插入数据时会报
Duplicate entry ‘002’ for key 'order.un_code 异常,表示唯一索引有冲突。
虽说抛异常对数据来说没有影响,不会造成错误数据。但是为了保证接口幂等性,我们需要对该异常进行捕获,然后返回成功。
如果是 java 程序需要捕获: DuplicateKeyException 异常,如果使用了 spring 框架还需要捕获: MySQLIntegrityConstraintViolationException 异常。
具体流程图如下:
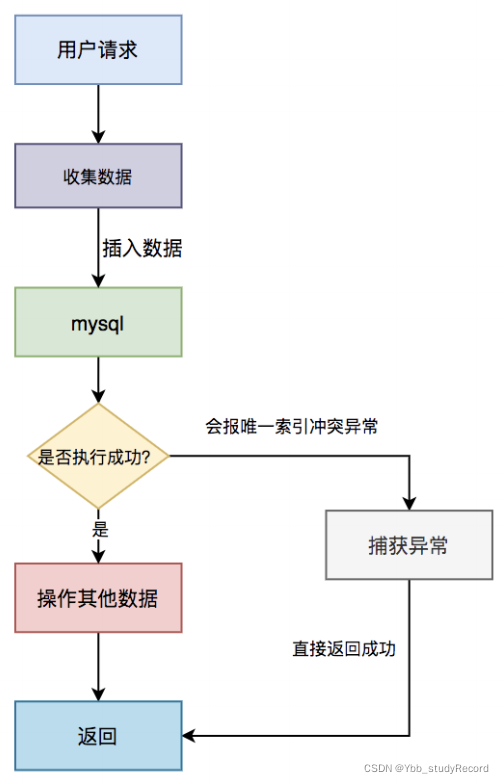
具体步骤:
- 用户通过浏览器发起请求,服务端收集数据。
- 将该数据插入mysql
- 判断是否执行成功,如果成功,则操作其他数据(可能还有其他的业务逻辑)。
- 如果执行失败,捕获唯一索引冲突异常,直接返回成功。
思考:
在很多业务场景中,都使用“软删除”即使用flag或is_deleted等字段表示记录是否被删除,这种方式能很好地保存“历史记录”,但由于”历史记录”的存在,导致无法在表上建立唯一索引,
需要通过程序来控制”数据唯一性”,其中一种程序实现逻辑就是“先尝试更新,更新失败则插
入”,该方式在高并发下死锁频发。(select for update ;为什么?你能复现么?如何免?)
尽管可以通过程序来控制”数据唯一性”,但仍建议使用数据库级别的唯一约束来确保数据在表级别的”唯一”,对于”硬删除”方式,直接在唯一索引列上建立为唯一索引即可,对于”软删
除”方式,可以通过复合索引方式来处理。
假设当前有订单相关的表tb_order_worker,表中有order_id字段需要唯一约束,使用is_delete字段来标识记 录是否被”软删除”,is_delete=1时表示记录被删除,is_delete=0时表示记录未被删除,需要控制满足 is_delete=0时的记录中order_id唯一,如果对(order_id,is_delete)的建唯一索引,那么当同一订单被多次” 软删除”时就会出现唯一索引冲突的问题
解决方式一:提升is_delete列的取值范围,当is_delete=0时表示记录有效,当is_delete>0时表示记录被删除,在删除记录时将is_delete值设置为不同数值,只要确保相同order_id的记录使用不同数值即可(很多表都使用自增主键,可以取自增主键的值来作为is_delete值)。
解决方式二:新增列order_rid来保持方式一中is_delete的原有取值范围,当is_delete时设置order_rid=0, 当is_delete=1时设置order_rid为任意非0值,只要确保相同order_id的记录使用不同值即可(同样建议参照自 增主键值来设置),然后对(order_id,yn,order_rid)建唯一索引
mysql死锁,会自动释放
唯一索引和普通索引的区别?
查询
select * from t_user where id_card =1000;
对于普通索引来说,查找到满足条件的第一个记录(1,1000)后,需要查找下一个记录,直到碰到第一个不满足id_card=1000条件的 记录。
对于唯一索引来说,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索。
性能差距微乎其微,因为mysql 数据是按照数据页为单位的,也就是说,当读取一条数据的时候,会将当前数据所在页都读入到内存,普通索引无非多了一次判断是否等于 的操作,相当于指针的寻找和一次计算,当然,如果该页码上,id_card=1000是最后一个数据,那么就需要取下一个页了,但是这种概率并不大。
总结说,查询上,普通索引和唯一索引性能是没什么差异的
更新
当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致 性的前提下,InooDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了。在下次查询 需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。通过这种方式就能保证 这个数据逻辑的正确性。
这个change buffer通常被称为InnoDB的写缓冲?
在MySQL5.5之前,叫插入缓冲(insert buffer),只针对insert做了优化;现在对delete和update也有效,叫做写缓冲(change buffer)。
它是一种应用在非唯一普通索引页(non-unique secondary index page)不在缓冲池中,对页进行了写操作,并不会立刻将磁盘页加载到缓冲池,而仅仅记录缓冲变更(buffer changes),等未来数据被读取时,再将数据合并(merge)恢复到缓冲池中的技术。
写缓冲的目的是降低写操作的磁盘IO,提升数据库性能。
对于唯一索引来说,所有的更新操作都要先判断这个操作是否违反唯一性约束。比如,要插入(1,1000)这个记录,就要先判 断现在表中是否已经存在id_card=1000的记录,而这必须要将数据页读入内存才能判断。如果都已经读入到内存了,那直接更新内 存会更快,就没必要使用change buffer了。 因此,唯一索引的更新就不能使用change buffer,实际上也只有普通索引可以使用。
接着分析InnoDB更新流程
第一种情况是,该记录要更新的目标页在内存中。
处理流程如下:
对于唯一索引来说,找到999和1001之间的位置,判断到没有冲突,插入这个值,语句执行结束;
对于普通索引来说,找到999和1001之间的位置,插入这个值,语句执行结束。
这样看来,普通索引和唯一索引对更新语句性能影响的差别,只是一个判断,只会耗费微小的CPU时间。
真正影响性能的是第二种情况是,这个记录要更新的目标页不在内存中。处理流程如下:
对于唯一索引来说,需要将数据页读入内存,判断到没有冲突,插入这个值,语句执行结束;对于普通索引来说,则是将更新记录在change buffer,语句执行就结束了。
总结
将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一。change buffer因为减少了随机磁盘访问, 所以对更新性能的提升是会很明显的。
因此,对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时change buffer的使用效果最好。
这种 业务模型常见的就是账单类、日志类的系统。
反过来,假设一个业务的更新模式是写入之后马上会做查询,那么即使满足了条件,将更新先记录在change buffer,但之 后由于马上要访问这个数据页,会立即触发merge过程。这样随机访问IO的次数不会减少,反而增加了change buffer的维 护代价。所以,对于这种业务模式来说,change buffer反而起到了副作用。
redo log 主要节省的是随机写磁盘的IO消耗(转成 顺序写),而change buffer主要节省的则是随机读磁盘的IO消耗。
5. 建防重表
有时候表中并非所有的场景都不允许产生重复的数据,只有某些特定场景才不允许。这时候,直接在表中加唯一索引,显然是不太合适的。
针对这种情况,我们可以通过 建防重表 来解决问题。
该表可以只包含两个字段: id 和 唯一索引 ,唯一索引可以是多个字段比如:name、code等组合起来的唯一标识,例如:pauipai_0001。
具体流程图如下:
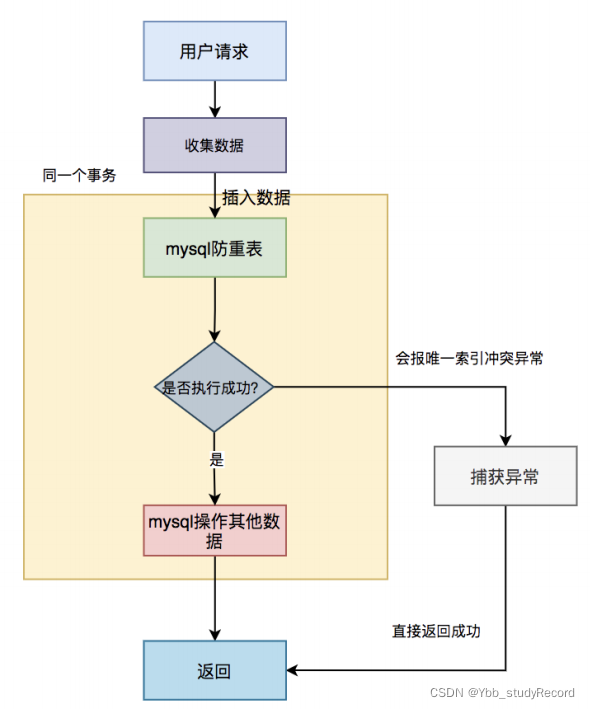
具体步骤:
- 用户通过浏览器发起请求,服务端收集数据。
- 将该数据插入mysql防重表
- 判断是否执行成功,如果成功,则做mysql其他的数据操作(可能还有其他的业务逻辑)。
- 如果执行失败,捕获唯一索引冲突异常,直接返回成功。
需要特别注意的是:防重表和业务表必须在同一个数据库中,并且操作要在同一个事务中。
6. 根据状态机
很多时候业务表是有状态的,比如订单表中有:1-下单、2-已支付、3-完成、4-撤销等状态。如果这些状态的值是有规律的,按照业务节点正好是从小到大,我们就能通过它来保证接口的幂等性。
假如id=123的订单状态是 已支付 ,现在要变成 完成 状态。
update `order` set status=3 where id=123 and status=2;
第一次请求时,该订单的状态是 已支付 ,值是 2 ,所以该 update 语句可以正常更新数据,sql执行结果的影响行数是 1 ,订单状态变成了 3 。
后面有相同的请求过来,再执行相同的sql时,由于订单状态变成了 3 ,再用 status=2 作为条件,无法查询出需要更新的数据,所以最终sql执行结果的影响行数是 0 ,即不会真正的更新数据。但为了保证接口幂等性,影响行数是 0 时,接口也可以直接返回成功。
具体流程图如下:

具体步骤:
- 用户通过浏览器发起请求,服务端收集数据。
- 根据id和当前状态作为条件,更新成下一个状态
- 判断操作影响行数,如果影响了1行,说明当前操作成功,可以进行其他数据操作。
- 如果影响了0行,说明是重复请求,直接返回成功。
主要特别注意的是,该方案仅限于要更新的 表有状态字段 ,并且刚好要更新 状态字段 的这种特殊情况,并非所有场景都适用。
7. 加分布式锁
其实前面介绍过的 加唯一索引 或者 加防重表 ,本质是使用了 数据库 的 分布式锁 ,也属于分布式锁的一种。但由于 数据库分布式锁 的性能不太好,我们可以改用: redis 或 zookeeper 。
我们以 redis 为例介绍分布式锁。
目前主要有三种方式实现redis的分布式锁:
- setNx命令
- set命令
- Redission框架
具体流程图如下:
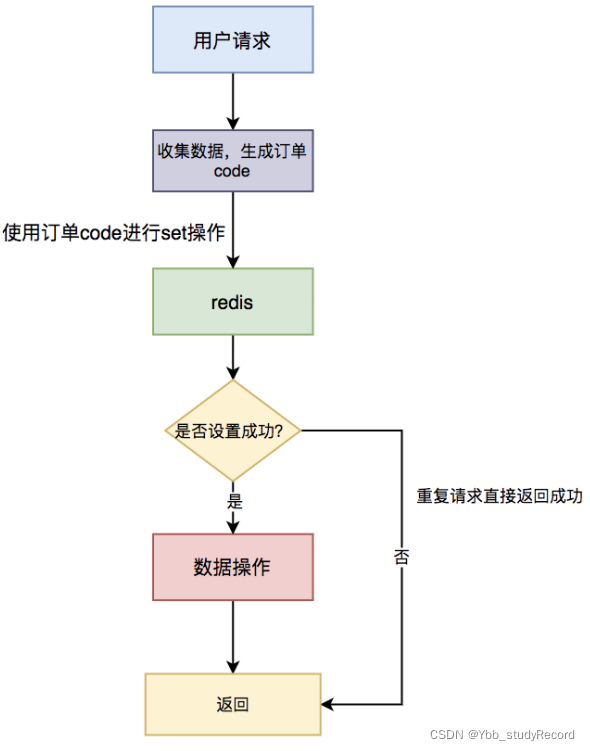
具体步骤: - 用户通过浏览器发起请求,服务端会收集数据,并且生成订单号code作为唯一业务字段。
- 使用redis的set命令,将该订单code设置到redis中,同时设置超时时间。
- 判断是否设置成功,如果设置成功,说明是第一次请求,则进行数据操作。
- 如果设置失败,说明是重复请求,则直接返回成功。
需要特别注意的是:分布式锁一定要设置一个合理的过期时间,如果设置过短,无法有效的防止重复请求。如果设置过长,可能会浪费 redis 的存储空间,需要根据实际业务情况而定。
8. 获取token
除了上述方案之外,还有最后一种使用 token 的方案。该方案跟之前的所有方案都有点不一样,需要两次请求才能完成一次业务操作。
- 第一次请求获取 token 2. 第二次请求带着这个 token ,完成业务操作。
具体流程图如下:
第一步,先获取token。
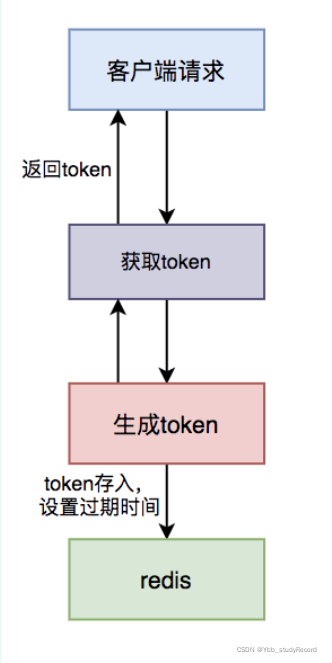
第二步,做具体业务操作。
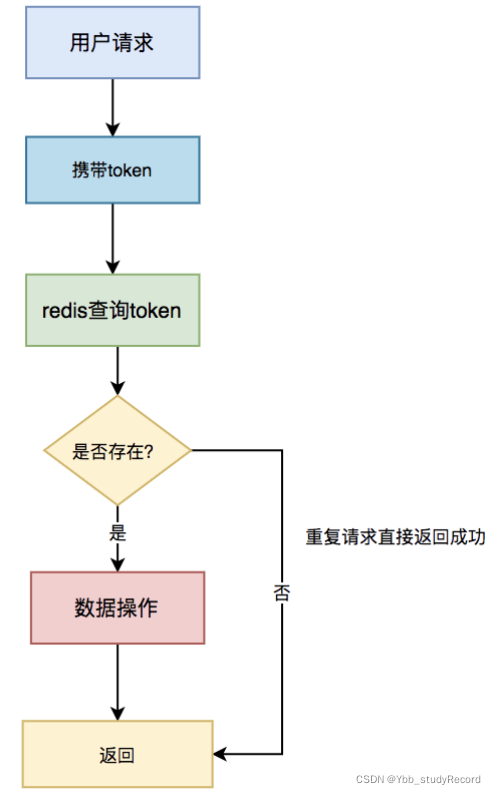
具体步骤: - 用户访问页面时,浏览器自动发起获取token请求。
- 服务端生成token,保存到redis中,然后返回给浏览器。
- 用户通过浏览器发起请求时,携带该token。
- 在redis中查询该token是否存在,如果不存在,说明是第一次请求,做则后续的数据操作。
- 如果存在,说明是重复请求,则直接返回成功。
- 在redis中token会在过期时间之后,被自动删除。
以上方案是针对幂等设计的。
如果是防重设计,流程图要改改:
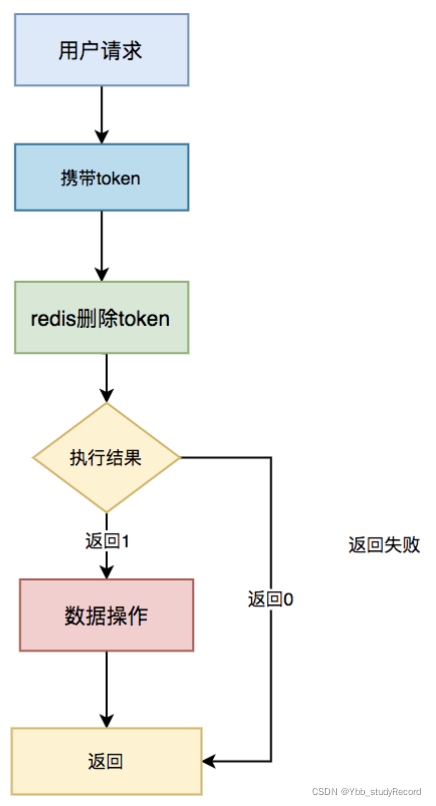
需要特别注意的是:token必须是全局唯一的。
事务 案例
自动还款业务 事故 案例
事故名称
自动还款业务事故
事故描述
事故发生时间:201x-0x-18 0x:15:00
事故响应时间:201x-0x-20 0x:18:00
事故解决时间:201x-0x-20 0x:28:00
事故现象:
自动扣款,出现扣款重复,同一用户在当天扣款多次.
事故造成影响
重复给n个用户扣款,重复扣款的多支付金额部分已退款给用户。
事故发生原因
1.自动还款的防重有问题,当出现并发进行消费MQ时,通过读库的防重是不起作用的。
事故解决过程描述
1、0x:15左右:收到运营人员的反馈,自动扣款有几笔在x.18号进行重复扣款.
2、0x:18左右:进行线上排查,在数据库里发现同一笔用户在当天有多笔的扣款数据信息,并且时间上都是同一时间内。
3、0x:20左右:调取线上的相关日志,分析 MQ在同一秒内推送了3~5条一样的消息进来,走查代码发现防重是通过uuid来查询数据库,如果查询没有数据信息,则insert一条新数据。
4、0x:25左右:排查线上数据库对uuid的唯一性约束,发现线上没有做uuid的唯一性约束.
5、0x:28左右 : 提工单将uuid做成唯一性约束.
6、201x-0x-21 8:00 左右,验证线上数据,没有重复扣款的记录信息,扣款正常。
事故总结教训
1、 强化对于防重技术的实现,防重通过读是解决不了的(并发情况也需要考虑),通过写防重是更好的解决办法
2、 针对于数据库表字段的唯一性的字段的处理,检查是否增加唯一性的约束条件。
3、 消费MQ消息必做防重处理。
4、加强业务逻辑上的监控,针对于同一用户在当天执行多次扣款进行监控告警处理
金融场景幂等性思考
重复出款特指代付或者转账场景下,服务消费者A重复向服务提供者B发起的重复交易,导致资金
损失;后续特指各类重复金融性交易导致的资金损失。出错的原因如下:
1、程序逻辑错误:
1)状态控制出错:由于程序、网络和系统异常等原因,A未得到B答复,A发起了新交易。
2)未做幂等性设计:由于A未收到B明确响应,A发起重试交易,B未做幂等性处理,重复交易。
2、跨会计日场景
1)由于A发起交易为T日,而B处理交易为T+1日,所以A未收到T日的结果,可能再次发起交易。
2)有些系统没有会计日,是按照机器时间为准,A和B的交易时间不一致,导致重复出款
**3、多任务并发:**通常是指定时任务中,同一个定时任务并发处理的资源导致。
**4、提交并发:**也就是防重复提交指引提到的。
**5、服务器异常:**由于服务异常崩溃,消息或者缓存信息丢失,等服务器重启后,可能导致。
设计原则:
- 先扣款,再生成处理订单,宁可长款也不能短款,宽进严出。
- 数据校验:设置校验规则,同一时间段,同一客户,相同金额的交易发起记录;如果是客户
发起,提示客户确认;如系统发起(例如代付),建议转人工处理。 - 状态控制:交易状态为,成功、失败、未知(或处理中),对于未知状态,不能再重复自动
发起。 - 时间控制:对于未实现24小时服务的应用,尽可能避免在23点30后做出款处理。
- 提交并发控制:审核提交等做防重复提交控制。
- 定时并发控制:禁止提交同一个文件给多个定时任务。
- 对账及差错处理:要对交易进行对账,并对差错交易进行差错处理。
相关阅读
支付系统的防重设计
服务间超时处理
在一个很普遍的场景中,涉及到双端通信的情况下,不论是传统的单机服务,还是现在的微服务,甚至事异步通信技术(进程内,进程与进程),一直都存在着三态的问题,即成功,失败,超时。
如下图两个服务间:

成功失败具有明确的业务语义和边界,正常处理即可。最复杂的就是超时,因为网络通信原因,双端都不总是确定,到底哪个环节超时。
1-同步调用超时

超时点:
1-请求超时
2-服务端内部处理超时:比如操作耗时的资源,调用第三方系统等造成客户端请求整体超时而主动断开连接
3-服务端处理正常,但响应结果阶段超时
处理:
客户端:无论那个阶段,客户端都不确定请求是否被应答,即服务端处理的结果,客户端不知道是否成功。客户端此时能做的,有两种方法:
1-重试,客户端需要主动做好重试方案,比如类似mq的重试队列(1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h),主要的技术,spring-retry框组件,将请求扔到自产自销的mq,依靠mq的重试队列主动重试,或者建立定时任务表重试。不管哪种方式,需要服务端接口具备幂等性
2-主动查询结果:超时后客户端主动查询,查询的时机类似重试机制,因为快速的查询,并不总是有效,当发生网络抖动的时候,很大概率就地查询,也是网络抖动阶段。
服务端
服务端不存在请求超时和响应超时,但存在自身超时的情况,解决方案:
1-自身rt值需要优化,比如慢sql等
2-以来三方接口的时候,跟第三方接口又形成了一个客户端-服务端模式,根据具体场景或者快速失败,或者做好容错措施,必要的时候,还会有比如金融领域的冲正操作。
2-异步调用超时
异步调用,类似ajax,客户端同步请求,服务端异步响应

超时点:
1-请求超时
2-服务端内部处理超时:比如操作耗时的资源,调用第三方系统等造成客户端请求整体超时而主动断开连接
3-服务端处理正常,但响应结果阶段超时
4-异步响应超时
客户端
参考同步-客户端
服务端
服务端不存在请求超时和同步响应超时,对于内部处理超时,同同步情况一样。那么就只剩下异步响应超时了。
比较有代表性的就是支付结果通知,可参考:支付结果通知
存在此问题就是服务端通知客户端的时候(客户端需要同步提供响应服务端结果通知的接口),未接受到客户端的响应。
3-MQ超时

在此处讨论的超时,其实相当于另外一个话题,如何保证mq不丢消息,无论是kafka和RocketMQ,都支持ack的机制,用以确认消息的发送和接受的成功