����Ŀ¼
AWS Glue ʵ��
Glue Job ����
ps:IAM��Ȩ����������������,Ȩ���ϻ�����ȱɶ��ɶ,���ֻ����Ϊ����,ֱ�Ӹ����е�Ȩ��(action��resource����*)�Ϳ���һ��������
Job Pramater
| Key | Value |
|---|---|
| �Cconf | spark.serializer=org.apache.spark.serializer.KryoSerializer |
| �Cenable-glue-datacatalog |
Dependent jars path
s3://gavin-test2/dependency_jars/hudi/spark-avro_2.11-2.4.3.jar,s3://gavin-test2/dependency_jars/hudi/hudi-spark-bundle_2.11-0.8.0.jar
jar ������·��:
| Jar�� | �������� |
|---|---|
| hudi-spark-bundle_2.11-0.8.0.jar | https://search.maven.org/remotecontent?filepath=org/apache/hudi/hudi-spark-bundle_2.11/0.8.0/hudi-spark-bundle_2.11-0.8.0.jar |
| spark-avro_2.11-2.4.3.jar | https://search.maven.org/remotecontent?filepath=org/apache/spark/spark-avro_2.11/2.4.3/spark-avro_2.11-2.4.3.jar |
�洢Ϊ�Ƿ�����
Python Code
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.types import *
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
basePath = 's3://gavin-test2/tables/hudi/table1/'
table_name = 'table1'
database = 'default'
data = [('Alice', 1, '2022/02/28'), ('Jhone', 2, '2022/03/01')]
rdd = sc.parallelize(data)
schema = StructType(
[
StructField("name", StringType(), True),
StructField("age", IntegerType(), True),
StructField("partitioin_path", StringType(), True),
]
)
src_df = spark.createDataFrame(rdd, schema)
hudi_options = {
'hoodie.table.name': table_name,
'hoodie.datasource.write.operation': 'insert',
'hoodie.datasource.write.recordkey.field': 'name',
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.datasource.hive_sync.database': 'default',
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.datasource.hive_sync.table': table_name,
'hoodie.datasource.write.partitionpath.field': '',
'hoodie.datasource.hive_sync.partition_fields': '',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.NonpartitionedKeyGenerator',
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.NonPartitionedExtractor'
}
src_df.write.format("hudi").options(**hudi_options).mode("overwrite").save(basePath)
AWS Glue Catalog
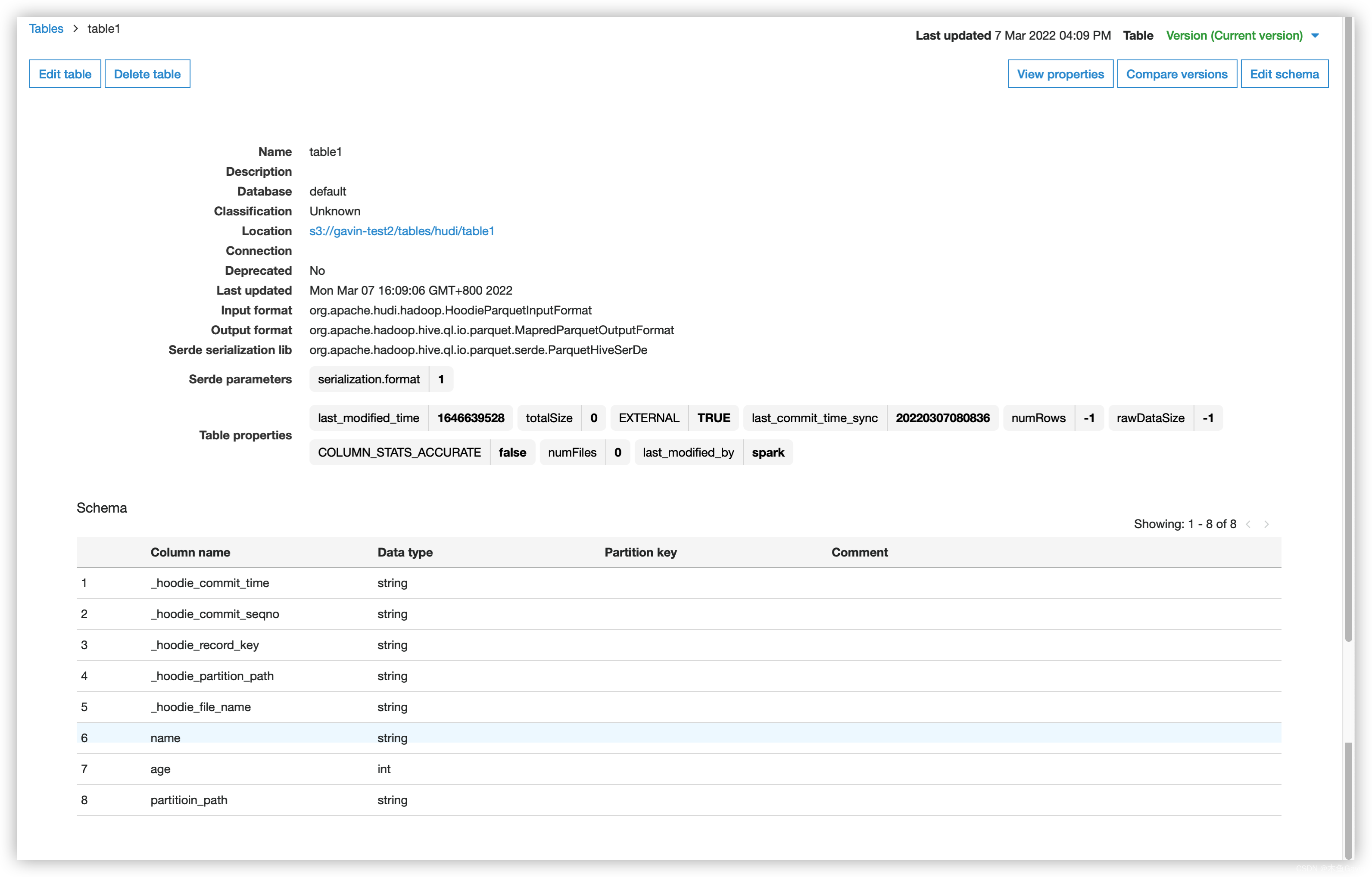
Query in Athena
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-tAUZYAMB-1646662547718)(../../../resources/typora_img/image-20220307161327394.png)]](https://img-blog.csdnimg.cn/ca9e0eda6e0148ca9c66961befe562cc.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5pyo6bG8R2F2aW4=,size_20,color_FFFFFF,t_70,g_se,x_16)
| _hoodie_commit_time | _hoodie_commit_seqno | _hoodie_record_key | _hoodie_partition_path | _hoodie_file_name | name | age | partitioin_path |
|---|---|---|---|---|---|---|---|
| 20220307080836 | 20220307080836_0_1 | Jhone | 8965ef34-4048-4420-8e69-562a478c3989-0_0-13-481_20220307080836.parquet | Jhone | 2 | 2022/03/01 | |
| 20220307080836 | 20220307080836_0_2 | Alice | 8965ef34-4048-4420-8e69-562a478c3989-0_0-13-481_20220307080836.parquet | Alice | 1 | 2022/02/28 |
Files in S3 Bucket
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-4qoRZ2nv-1646662547719)(../../../resources/typora_img/image-20220307163056583.png)]](https://img-blog.csdnimg.cn/54a0674d3ca643d29a71f71d5c7cac4b.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5pyo6bG8R2F2aW4=,size_20,color_FFFFFF,t_70,g_se,x_16)
�洢Ϊ������
����������ѡ��ʱ���ֶ���Ϊ�����ֶ�,Ҳ����ѡ���ʱ���ֶ���Ϊ�����ֶ�,����ʹ�����硸yyyy/mm/dd����ʱ���ַ�����Ϊ�����ֶ�;
Python Code
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.sql.types import *
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
basePath = 's3://gavin-test2/tables/hudi/table2/'
table_name = 'table2'
database = 'default'
data = [('Alice', 1, '2022/02/28'), ('Jhone', 2, '2022/03/01')]
rdd = sc.parallelize(data)
schema = StructType(
[
StructField("name", StringType(), True),
StructField("age", IntegerType(), True),
StructField("partitioin_path", StringType(), True),
]
)
src_df = spark.createDataFrame(rdd, schema)
hudi_options = {
'hoodie.table.name': table_name,
'hoodie.datasource.write.operation': 'insert',
'hoodie.datasource.write.recordkey.field': 'name',
'hoodie.datasource.write.table.name': table_name,
'hoodie.datasource.hive_sync.enable': 'true',
'hoodie.datasource.hive_sync.database': 'default',
'hoodie.datasource.hive_sync.use_jdbc': 'false',
'hoodie.datasource.hive_sync.table': table_name,
'hoodie.datasource.write.partitionpath.field': 'partitioin_path',
'hoodie.datasource.hive_sync.partition_fields': 'partitioin_path',
'hoodie.datasource.write.keygenerator.class': 'org.apache.hudi.keygen.SimpleKeyGenerator',
'hoodie.datasource.hive_sync.partition_extractor_class': 'org.apache.hudi.hive.SlashEncodedDayPartitionValueExtractor'
}
src_df.write.format("hudi").options(**hudi_options).mode("overwrite").save(basePath)
AWS Glue Catalog
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-SbY2OJRi-1646662547720)(../../../resources/typora_img/image-20220307165709937.png)]](https://img-blog.csdnimg.cn/0571c876a319405da4ae2d8e9ec2f0a9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5pyo6bG8R2F2aW4=,size_20,color_FFFFFF,t_70,g_se,x_16)
Query in Athena
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-qfXh6Rq7-1646662547720)(../../../resources/typora_img/image-20220307165818410.png)]](https://img-blog.csdnimg.cn/4527597d8c4445e1acc0f3d0c12b8b61.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5pyo6bG8R2F2aW4=,size_20,color_FFFFFF,t_70,g_se,x_16)
| _hoodie_commit_time | _hoodie_commit_seqno | _hoodie_record_key | _hoodie_partition_path | _hoodie_file_name | name | age | partitioin_path |
|---|---|---|---|---|---|---|---|
| 20220307084134 | 20220307084134_0_1 | Jhone | 2022/03/01 | afb8d8e3-5f3e-4420-b390-1eeb20a59165-0_0-8-322_20220307084134.parquet | Jhone | 2 | 2022-03-01 |
| 20220307084134 | 20220307084134_1_1 | Alice | 2022/02/28 | 351c3c19-3c69-4661-8051-11a90c031112-0_1-8-323_20220307084134.parquet | Alice | 1 | 2022-02-28 |
Files in S3 Bucket
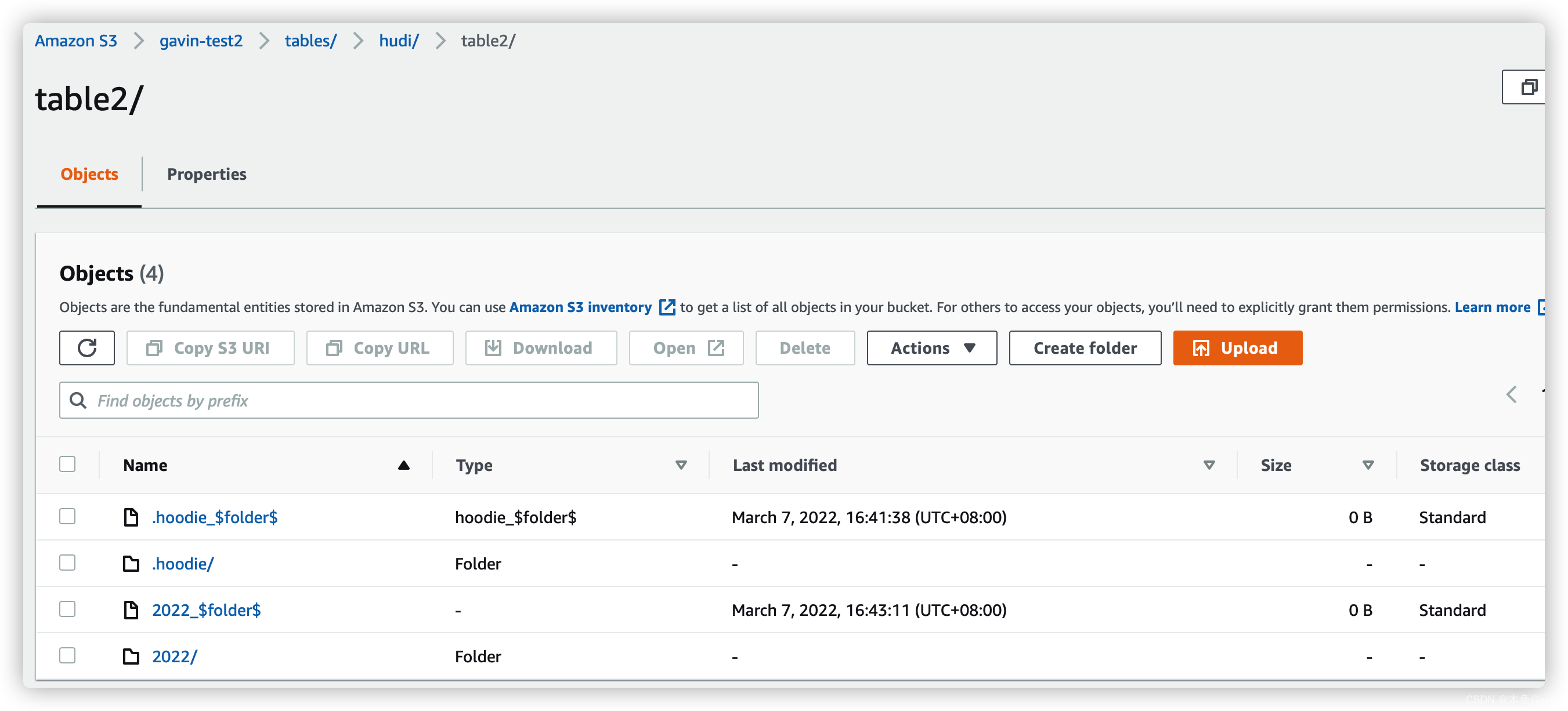
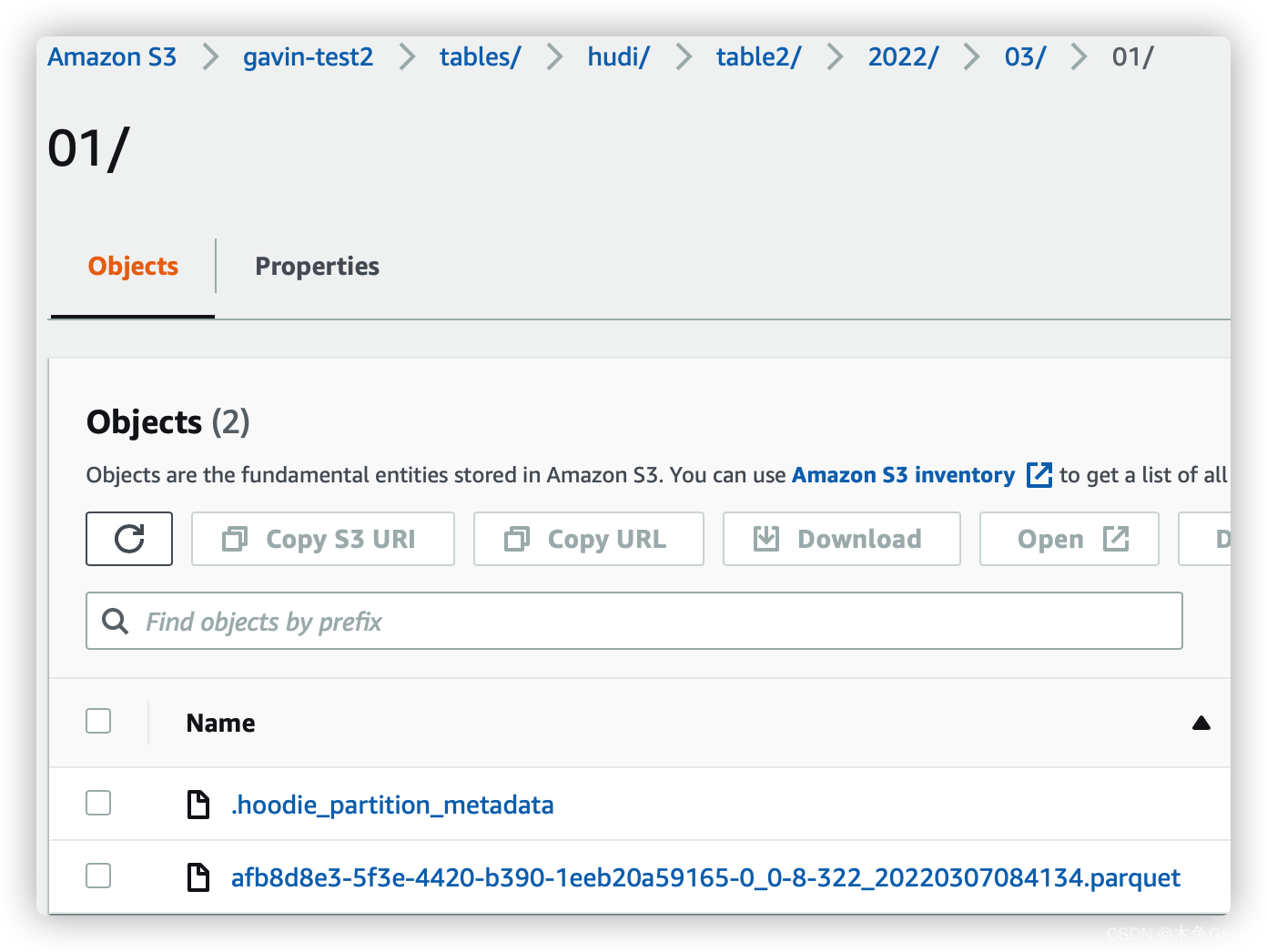
FAQ
ClassNotFoundException: org.apache.calcite.rel.type.RelDataTypeSystem
Error Info
��Hudi��������:DataSourceWriteOptions.HIVE_USE_JDBC_OPT_KEY -> ��false��,�������Ϊ:
java.lang.ClassNotFoundException: org.apache.calcite.rel.type.RelDataTypeSystem
��������Hiv3/Spark3�Ƴ��˶���calcite�������������
Solution:
��͵�˸���,��spark �İ汾����2.X
IllegalArgumentException: Partition path default is not in the form yyyy/mm/dd
Error Info
Caused by: java.lang.IllegalArgumentException: Partition path default is not in the form yyyy/mm/dd
at org.apache.hudi.hive.SlashEncodedDayPartitionValueExtractor.extractPartitionValuesInPath(SlashEncodedDayPartitionValueExtractor.java:55)
at org.apache.hudi.hive.HoodieHiveClient.getPartitionEvents(HoodieHiveClient.java:220)
at org.apache.hudi.hive.HiveSyncTool.syncPartitions(HiveSyncTool.java:221)
... 42 more
Solution
��������'hoodie.datasource.hive_sync.partition_extractor_class':'org.apache.hudi.hive.SlashEncodedDayPartitionValueExtractor', ��org.apache.hudi.hive.SlashEncodedDayPartitionValueExtractor ��Ҫ��ʱ���ʽ�������������
org.apache.hudi.hive.SlashEncodedDayPartitionValueExtractor#extractPartitionValuesInPath
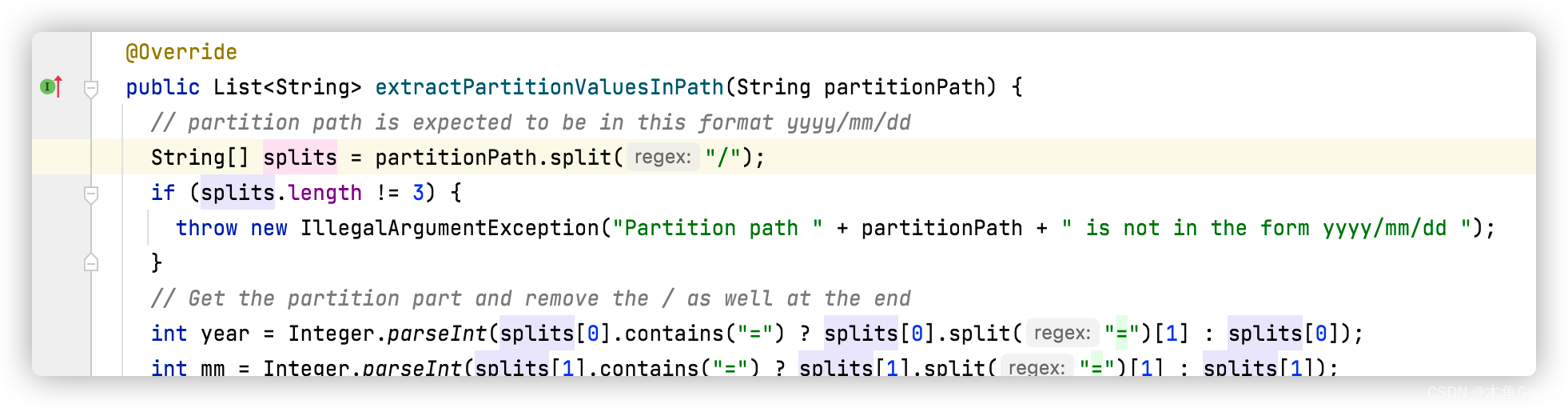
�ο�
[1] Hudi ʵ�� | �� AWS Glue ��ʹ�� Apache Hudi: https://jishuin.proginn.com/p/763bfbd56de6
[2] ���Apache Hudi������ø������ͷ���: https://www.cnblogs.com/leesf456/p/13521694.html
[3] EMR + Hudi��ClassNotFoundException: RelDataTypeSystem����Ľ������: https://blog.csdn.net/bluishglc/article/details/117441071