本文主要讲解了单台虚拟机安装Hadoop的命令行流程(即跳过前期VMstation、Xshell、虚拟机的可视化安装),本机系统为CentOS
1.关闭防火墙
运行以下命令并编写脚本:
vim close.sh
#!/bin/bash
#关闭selinux
setenforce 0
#清除filter表和nat表里的防火墙规则
iptables -F
iptables -t nat -F
#关闭firewalld服务
systemctl stop firewalld.service
#查看脚本运行后本机的状态
echo "当前selinux状态为:"
sestatus
echo "当前防火墙状态为:"
firewall-cmd --state
echo "当前防火墙开放的端口有:"
firewall-cmd --list-all
check:
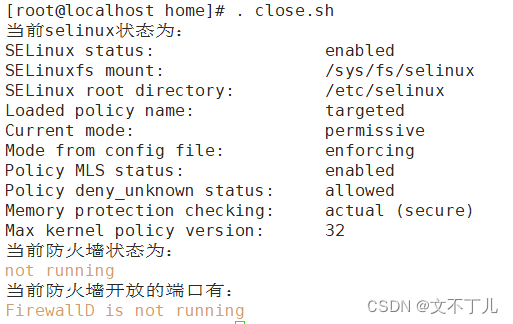
即为成功
2.安装JDK
将jdk的安装包(文件名为jdk-8u171-linux-x64.tar.gz)移入本机,并在该目录下解压安装包:
(本文中jdk安装包的位置为/home/jdk-8u171-linux-x64.tar.gz)
tar -zxvf jdk-8u171-linux-x64.tar.gz
(然后会弹出很多行)
建立JDK软链接,以便复用:
ln -s jdk1.8.0_171/ jdk
设置JDK环境变量
vim ~/.bashrc
在.bashrc文件最末尾添加:
export JAVA_HOME=/home/jdk
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
export PATH=${JAVA_HOME}/bin:$PATH
使环境变量生效:
source ~/.bashrc
check:
java -version
 即为成功
即为成功
3.安装hadoop
(与JDK安装类似)
将Hadoop的安装包(文件名为hadoop-2.7.3.tar.gz)移入本机,并在该目录下解压安装包:
(本文中Hadoop安装包的位置为/home/hadoop-2.7.3.tar.gz)
tar -zxvf hadoop-2.7.3.tar.gz
建立Hadoop软链接,以便复用:
ln -s hadoop-2.7.3 hadoop
设置Hadoop环境变量
vim ~/.bashrc
在.bashrc文件最末尾添加:
export HADOOP_HOME=/home/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使环境变量生效:
source ~/.bashrc
check:
whereis hdfs
whereis start-all.sh

即为成功
如在安装过程中发现bug,请及时指正,欢迎交流!

(参考书籍《Hadoop大数据技术与应用》)