mysql的事务
1.什么是事务
事务是用户定义的一个操作序列,这些操作要么全部成功要么全部失败,是一个不可分割的工作单位(构成单一逻辑工作单元的操作集合)。如果某一事务成功,则在该事务中进行的所有更改均会提交,成为数据库中的永久组成部分。如果事务遇到错误且必须取消或者回滚,则所有更改均被清除。
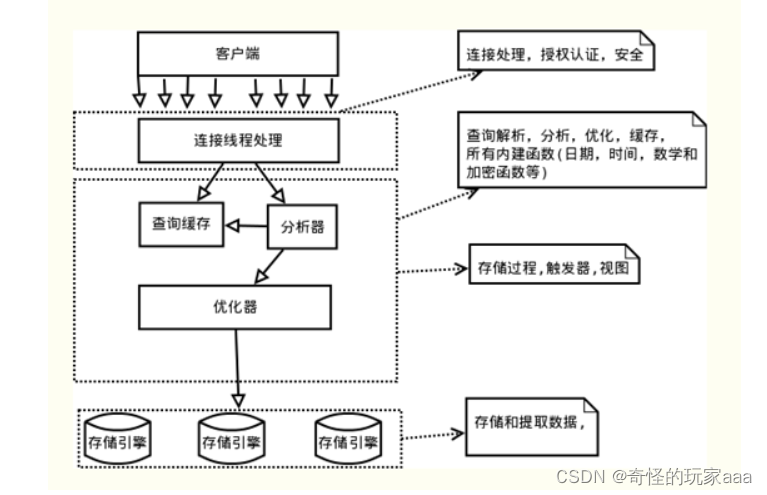
mysql服务器逻辑架构从上往下可以分为3层:
第一层:处理客户端连接,授权认证。
第二层:服务器层,负责查询语句的解析,优化,缓存以及内置函数的实现,存储过程等。
第三层:存储引擎,负责mysql中数据的存储和提取。
mysql中服务器层不管理事务,事务是由存储引擎实现的。mysql支持事务的存储引擎有InnoDB,NDB Cluster等,其中InnoDB的使用最为广泛;其他存储引擎不支持事务,如Mylsam,Memory等。
2.事务操作
2.1 基本命令
START TRANSACTION
[transaction_characteristic [, transaction_characteristic] ...]
transaction_characteristic: {
WITH CONSISTENT SNAPSHOT
| READ WRITE
| READ ONLY
}
BEGIN [WORK]
COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE]
SET autocommit = {0 | 1}
命令使用说明:
START TRANSACTION 或 BEGIN开始新的事务
COMMIT提交当前事务,使其更改永久化
ROLLBACK回滚当前事务,取消其更改
SET autocommit 禁用或启用当前会话的默认自动提交模式
2.2 执行流程
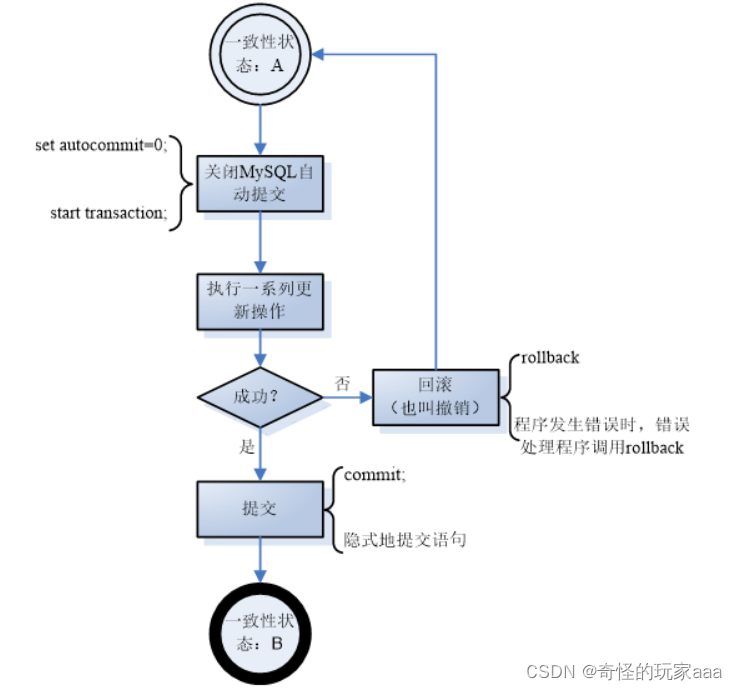
2.3回滚事务
ROLLBACK TRANSACTION:
回滚事务后,事务结束,放弃事务期间所做的任何修改,事务结束。该语句将显式事务或隐性事务回滚到事务的起点或者某个保存点。
ROLLBACK { TRAN | TRANSACTION }
[ transaction_name | @tran_name_variable
| savepoint_name | @savepoint_variable ]
2.4保存点
savepoint,保存点是事务中的一点。用于取消部分事务,当结束事务时,会自动删除该事务锁定义的所有保存点。当执行rollback时,通过指定保存点可以回退到指定的点。
3.事务特性
3.1 MySQL日志
InnoDB存储引擎提供了两种事务日志:
- redo log(重做日志):可以理解为是当服务宕机时,重启后强制保持一致
- undo log(回滚日志):可以理解是如果回滚时回滚到之前的某一个状态
其中redo log用于保证事务的持久性。undo log则是事务原子性和隔离性实现的基础。
undo log主要分为两种:
1.insert undo log:代表事务在insert 新纪录时产生的undo log,只在事务回滚时需要,并且在事务提交后可以被立刻丢弃
2.updata undo log:事务在进行updata或者delete时产生的undo log。不仅在事务回滚时需要,在快照读时也需要,所以不能随便删除。只有当快速读或者事务回滚不涉及该日志时,对应的的日志才会被purge线程同一清除。
3.2原子性(Atomic)
原子性是指事务是一个不可分割的工作单位,其中的操作要么都做,要么都不做;如果事务中一个sql语句执行失败,则已经执行的语句也必须回滚,数据库退回到事务前的状态。
实现原理:undo log(回滚日志)。在mysql里数据每次修改前,都会把修改之前的数据作为历史保存到undo log里面,数据里面会记录操作该数据的事务id。当事务执行失败或者调用rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的状态。
3.3 持久性(Durability)
持久性也称永久性,指一个事务一旦提及,它对数据库中数据的改变就应该时永久性的。接下来的其他操作或者故障不应该对其执行结果有任何影响。
刷脏:InnoDB提供了缓存池(Buffer Pool),包含了磁盘中部分数据页的映射。当需要从数据库读取数据时,会首先从缓存池中读取,若缓存池中没有,则从磁盘读取后放到缓存池中。当需要向数据库中添加数据时,会首先写入缓存池中,缓存池中修改的数据就会定期刷新到磁盘中(这一情况称为脏刷)
脏刷引发的问题:Buffer Pool的使用大大提高了读写数据的效率,但也带来了新的问题:如果MySQL宕机,而此时Buffer Pool中修改的数据还没有刷新到磁盘,就会导致数据的丢失,事务的持久性就无法保证。解决这个问题通过重做日志解决。
实现原理:redo log
重做日志是一种基于磁盘的数据结构,用于在崩溃恢复期间纠正不完整事务写入的数据。
3.4一致性(Consistency)
事务操作成功后,数据库所处的状态和它的业余规则是一致的,数据库的完整性约束没有被破坏,事务执行的前后都是合法的数据状态。数据库的完整性约束包括但不限于:实体完整性(如行的主键存在且唯一),列完整性(如字段的类型,大小,长度符合要求),外键约束,用户自定义,用户自定义完整性(如账户前后,两个账户余额的和应该不变)。
一致性是事务追求的最终目标:原子性,持久性和隔离性,都是为了摆正数据库状态的一致性。
3.5 隔离性(lsolation)
隔离性是指事务内部的操作与其他事务是隔离的,并发执行的各个事务之间不能互相干扰。与原子性,持久性侧重于研究事务本身不同,隔离性研究的是不同事务之间的相互影响。
隔离性主要考虑最简单的读操作和写操作。
隔离性的探讨,主要可以分为两个方面:
- (一个事务)写操作对(另一个事务)读操作的影响:MVCC保证隔离性
- (一个事务)写操作对(另一个事务)写操作的影响:锁机制保证隔离性
3.5.1 事务的并发
取钱场景:老公去在 ATM 上取钱,老婆在柜台存钱,假设这个账户中有 1000 元:
- 老公首先执行查询操作,查询到账户余额为 1000 此时程序 将 1000 拿到内存中,老公取了 200 元,程序就执行了更新操作将账户余额改为 800。
- 但是当老公的程序没有 commit 的时候,老婆查询账户,此时账户余额还是 1000 元,老婆存入 200 元,程序执行了更新操作将账户余额改为 1200
- 然后老公将更新语句提交,接着老婆也将更新语句提交。
- 最后导致的结果就是该账户的余额为 1200,这就是更新丢失的问题。
- 引发更新丢失的根源就是查询上,因为双方都是根据从数据库查询到的数据再 对数据库中的数据进行更新的。
并发情况下,读操作可能存在的三大类型:
- 脏读
- 不可重复读
- 幻读
3.5.2脏读:
当前事务(A)中可以读到其他事务(B)为提交的数据(脏数据),这种现象是脏读。
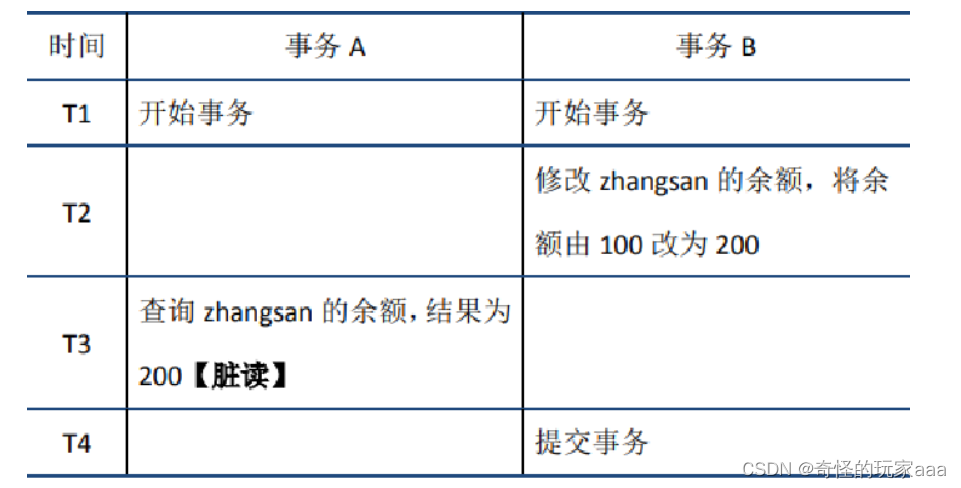
3.5.3 不可重复读:
在事务A中先后两次读取同一个数据,两次读取的结果不一样,这种现象成为不可重复读
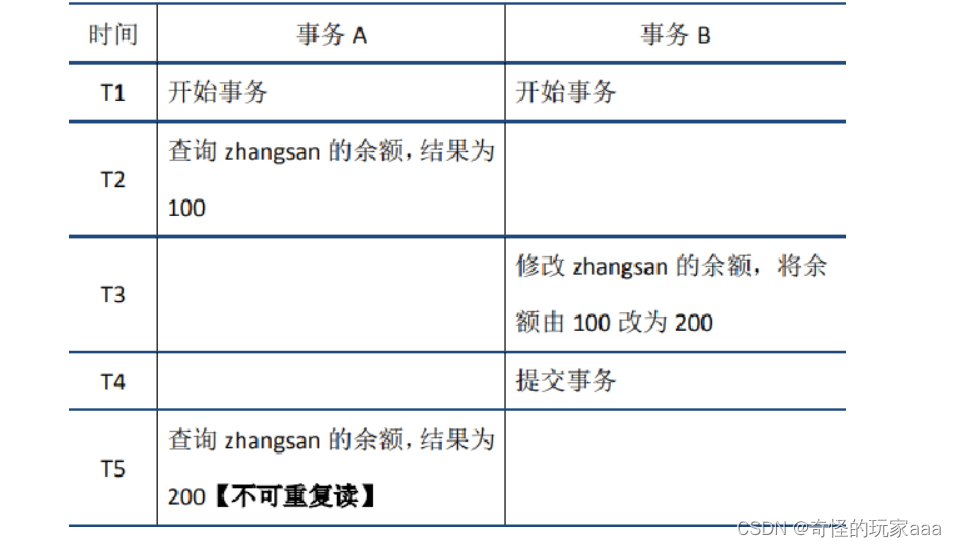
3.5.4 幻读
在事务A中按照某个条件先后两次查询数据库,两次查询结果的条数不同,这种现象称为幻读。
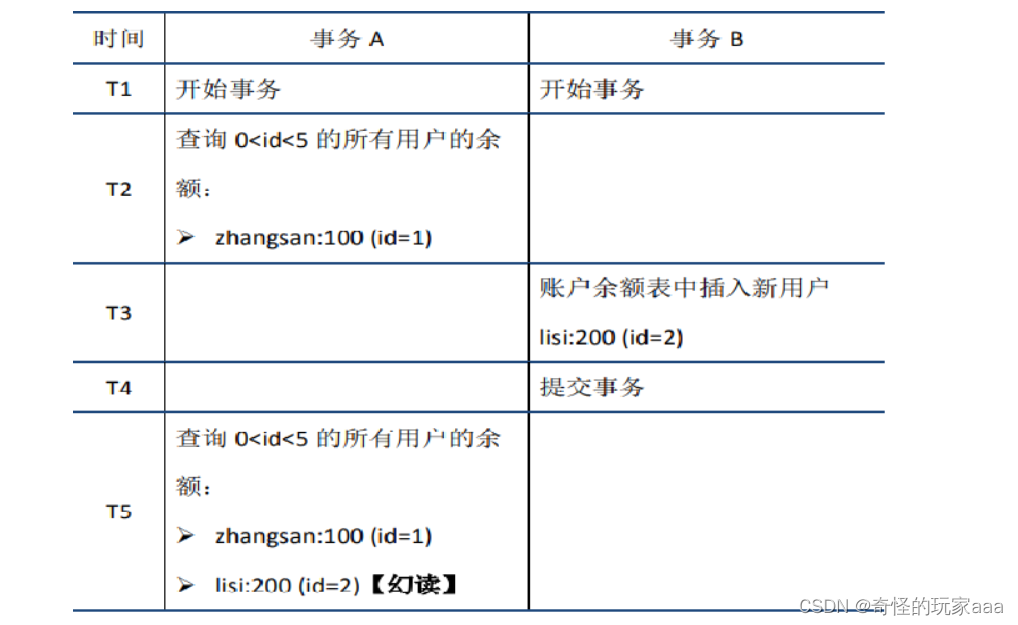
3.6 事务的隔离级别
sql标准中定义了四种隔离级别,并规定了每种隔离级别下上述几个问题是否存在。一般来说,隔离级别越低,系统开销越低,可支持的并发越高,但隔离性也越差。
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 可能 |
| 可串行化 | 不可能 | 不可能 | 不可能 |
读未提交在并发是会导致很多问题,而性能相当于其他隔离级别提高却很有限,因此使用较少。
可串行化强制事务串行,并发效率很低,只有当对数据一致性要求极高且可以接收没有并发时使用,因此使用也较少。
在大多数数据库系统中,默认的隔离级别是读已提交(如Oracle)或可重复读,InnoDB默认的隔离级别就是RR。
4.MVCC
在sql标准中,可重复读是无法避免幻读问题的
InnoDB实现可重复读取(RR)解决了脏读,不可重复读,幻读等问题,使用了MVCC。
MVCC是多版本的并发控制协议,MVCC的目的是多版本并发控制,在数据库实现,就是为了解决读写冲突。
4.1 相关概念
当前读
像共享锁,排他锁这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。
快照读
像不加锁的SELECT操作就是当前读,即不加锁的的非阻塞读;快照读的前提是隔离级别不是串行级别,串行级别的快照读会退化成当前读;之所以出现快照读的情况,是基于提高并发性能的卡考虑。快照读的实现是基于多版本并发控制器,即MVCC。但它在很多情况下,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的不一定是数据的最新版本,而有可能是之前的历史版本。
4.2 MVCC的实现原理
MVCC是为了实现读-写冲突不加锁,而这个读指的是快照读,而非当前读,当前读实际上是一种加锁的操作,是悲观锁的实现。
MVCC实现原理主要是依赖记录中的三个隐式字段,undo日志,Read Viev来实现。
4.2.1隐式字段
InnoDB存储引擎在每行数据的后面添加了三个隐藏字段
- DB_TRX_ID(6字节):表示最近一次对本记录行做修改(insert/update)的事务ID
- DB_ROLL_PTR(7字节):回滚指针,指向当前记录行的undo log信息
- DB_ROW_ID(6字节):随着新插入而单调递增的行ID

DB_ROW_ID:当表没有主键或唯一非空索引时,innoDB就回使用这个行id自动产生聚簇索引。如果表有主键或者唯一非空索引,聚簇索引就不会包含这个行id了。
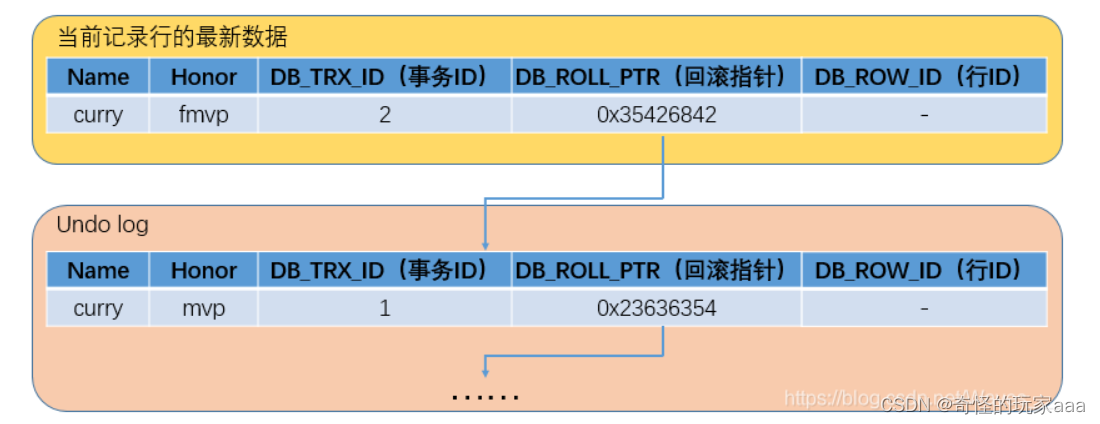
4.2.2记录行修改的具体流程
事务A(事务id为2)对该记录做出了修改,将Honor列内容改为“FMVP”:
1.事务A先对改行加排他锁
2.将改行数据加入undo log中,当作旧版本
3.修改数据,并且修改DB_TRX_ID为2,将回滚指针指向拷贝到undo log的旧版本
4.事务提交,释放排他锁。
4.2.3 Read View
Read View 是事务进行快照读操作的时候生产的读视图 (Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的 ID 。Read View 主要是用来做可见性判断的,把生成的读视图 (Read View)当作条件用来判断当前事务能够看到哪个版本的数据,既可能是当前最新的数据,也有可能是该行记录的undo log里面的某个版本的数据。
Read View遵循一个可见性算法,主要是将要被修改的数据的最新记录中的 DB_TRX_ID(即当前事务 ID )取出来,与系统当前其他活跃事务的 ID 去对比(由 Read View 维护)。当每个事务开启时,都会被分配一个 ID , 这个 ID 是递增的,所以最新的事务,ID 值越大.
假设当前列表里的事务id为[80,100]。
1.如果你要访问的记录版本的事务id为50,比当前列表最小的id80小,那说明这个事务在之前就提交了,所以对当前活动的事务来说是可访问的。
2.如果你要访问的记录版本的事务id为90,发现此事务在列表id最大值和最小值之间,那就再判断一下是否在列表内,如果在那就说明此事务还未提交,所以版本不能被访问。如果不在那说明事务已经提交,所以版本可以被访问。
3.如果你要访问的记录版本的事务id为110,那比事务列表最大id100都大,那说明这个版本是在ReadView生成之后才发生的,所以不能被访问。