ǰ��
�þ�û�и��� ���á� ������,���ĺܹ��ⲻȥ,��ô�����ô����,����������
����,������ݺ��ĸ�����һ����Ϳ,�ر��� Hudi , �� Flink �Ľ��Խ��Խ��,����˵ Flink + Hudi ����δ��������,�ⲻ,�Ҿ�������,�� ��С�ס�������·��,��֪ʶ���������,�Ͼ���Ҳ�Ǵ�С���ű��˵����¹�����


Hudi
����
Apache Hudi (���:Hudi) ʹ��������hadoop���ݵĴ洢֮�ϴ洢��������,ͬʱ�����ṩ����ԭ��,ʹ�ó��˾����������֮��,�����������ݺ��Ͻ��������� ,�ֱ��� :Update/Delete �� �����
���ǹٷ���Hudi���������ķ���
����˵,���ǹ����ڷֲ�ʽ�洢ϵͳ�ϵ�һ������,����ʵ�ֶԵײ�洢ϵͳ���ݵ���������
��ʱ��϶����±�,HDFS���Dz�֧��update������,�ǵ�,��֮ǰ,������Ҫ����HDFS����洢������,������һ���ֶε�ֵ,���Ƕ�ֻ��ʹ������Hive�����Ĺ���,�Ա������ݽ��и�д(overwrite)������ʵ�����ݵĸ���,���Ծ�������HDFS������,һ��д��,��ζ�ȡ ����������ʱ���ķ�չ , HDFS�ľ����Ծͳ����� , Flink �������־�� ������ ����δ�� , ��������HDFS���֮������Ϊ����������ݳ����Ĵ洢,�Ͳ���ȥӭ��������,������,ҵ��ķ�չ��ٽ������ĵ���,��ȻHDFS����ȥӭ��������,�ǻ���HDFS���ϲ���������?����Hive , HBase ? ��ʵҲ�Dz��е� ,Hive ������ʹ��MR�� Spark ��ʵ������ ��д�����ļ����ﵽ���ݸ��µ�Ч��,�������ַ�ʽʱЧ��Ҳ�Dz��е�,HBase��Ȼ����������RowKey���,�����ò�ѯЧ�ʻ�����,���Dz����ʺ���Flink����������������Խ�,����Ҳ���ʺ�OLAP�ķ����ij�����So ,������������,Hudi��һЩ���ԾͲ�����!
���� , ������Ҫһ�����HDFS�ij���,��ΪHDFS�ķֲ�ʽ�洢��Hadoop�ĺ��� ,Ȼ��Ҫ֧����ʽд��,������ʵʱ�����ܶԽ�,��ô����д���,���û���˵,Ӧ����һ��ʲô���ı�����ʽ�� ? û��,���DZ� ,����Կ�SQL!��ô��Ȼ��һ�ű���,��Ӧ��ʵ�ֶԱ���CRUD����,���һ�Ҫ֧������,ȷ������д����;�������Իع�,��ô��Ȼ���Իع�,�Ϳ����а汾����,֧��MVCC,��Ȼ���˰汾����,��ô�ڶ�ȡ���ݵ�ʱ��,Ҳ�п����в�ͬ����ʽ��
��ʵ���ڿ���,Hudi�����IJ�Ʒ���ֵij���һ�����ֱ�Ȼ,��Ϊ���ij��ֲ�ȫ���ֽ�ʵʱ���̵�һ��ƴͼ
��ôHudi���������ȥʵ�ֱ���CRUD�Լ��汾������?������һ̽������!

���ԭ��
��ʽ��/д:Hudi��������ݿ���Ƶ�ԭ��,�������,Ӧ���ڴ������ݼ���¼��������������Ϊ��,Hudi�ṩ������ʵ��,���Խ���¼�ļ�����ӳ�䵽�����ڵ��ļ�λ�á�ͬ��,������ʽ�������,Hudiͨ�������������Ӳ����ټ�¼����Ԫ����,�Ӷ������ṩ���з�������ľ�ȷ������
�Թ���: Hudiע��û����ܶ��������ʶ�(д�Ѻ�)���ѯ����(��/��ѯ�Ѻ�)�в�ͬ������,��֧�������ֲ�ѯ����,��Щ�����ṩʵʱ����,�������Լ�����Ĵ������ݡ���ÿһ��,Hudi��Ŭ���������ҹ���(�����Զ��Ż���д����IJ�����,�����ļ���С)��������(����:�Զ��ع�ʧ�ܵ��ύ),��ʹ������������������ʱ�ɱ�(����:���ڴ��л������������ѷ�����������)�����û����Щ���õIJ����ܸ�/���ҹ�������,��Щ������ˮ�ߵ���Ӫ�ɱ�ͨ���ᷭ��
�����־: Hudi������ append only���������Ѻõ����,�����ʵ������־�ṹ���洢ϵͳ��ԭ��,����������������ṩ�̵�����
��-ֵ����ģ��: ��д����,Hudi������ģΪ��ֵ�����ݼ�,����ÿ����¼����һ��Ψһ�ļ�¼��������,һ����¼��������������·��,�ڸ�·����,���ԶԼ�¼���з����ʹ洢����ͨ�������ڼ���������ѯ�������ռ�

�����
�˽���Hudi��Ŀ�Ĺؼ�����������,���������Ǹ�������о�Hudiϵͳ��������ơ��ڽϸߵIJ����,����дHudi�������ʹ����һ����֧�ֵķ�ʽǶ�뵽Apache Spark��ҵ��,������֧��DFS�Ĵ洢�����ɴ���Hudi����һ���ļ���Ȼ��,�ھ���һ����֤�������,����Apache Spark��Presto��Apache Hive֮��IJ�ѯ������Բ�ѯ�ñ�
Hudi����������Ҫ���:
1)�����ʱ����Ԫ����:���������ݿ�������־
2)�ֲ㲼�ֵ������ļ�:ʵ��д����е����ݡ�
3)����(����ʵ�ַ�ʽ):ӳ�����ָ����¼�����ݼ�
Hudi�ṩ�����¹������Ի������ݽ���д�롢��ѯ,��ʹ���Ϊ�������ݺ�����Ҫģ��:
1)֧�ֿ���,�ɲ��������upsert()
2)��Ч��ֻɨ�������ݵ�������ѯ
3)ԭ���Ե����ݷ����ͻع�,֧�ָֻ���Savepoint
4)ʹ��mvcc(��汾��������)�����ƵĶ���д���ո���
5)ʹ��ͳ����Ϣ�����ļ���С
6)���м�¼update/delta���Թ���ѹ��
7)��������ĵ�ʱ����Ԫ����
8)����GDPR(ͨ�����ݱ�������)������ɾ������
ʱ����
�������,Hudiά����һ�������ڲ�ͬ�ļ�ʱʱ��(instant time)�����ݼ���������instant������timeline,�Ӷ��ṩ���ļ�ʱ��ͼ,ͬʱ����Ч֧�ְ�����˳��������ݼ���
ʱ�������������ݿ��redo/transaction��־,��һ��ʱ����ʵ�����
Hudi��֤��ʱ������ִ�еIJ�����ԭ���Ժͻ��ڼ�ʱʱ���ʱ����һ����
ʱ���ᱻʵ��Ϊ������·����.hoodieԪ�����ļ����µ�һ���ļ���������˵,���µ�instant������Ϊ�����ļ�,���Ͼɵ�instant���浵��ʱ����鵵�ļ�����,������writers��queries�г����ļ�����
һ��Hudi ʱ����instant�����漸���������:
1)��������:�����ݼ�ִ�еIJ�������
2)��ʱʱ��:��ʱʱ��ͨ����һ��ʱ���(����:20190117010349),��ʱ�����������ʼʱ���˳������
3)��ʱ״̬:instant�ĵ�ǰ״̬;ÿ��instant����avro����json��ʽ��Ԫ������Ϣ,��ϸ�������˸ò�����״̬�Լ������ʱʱ��instant��״̬
�ؼ���Instant����������:
1)COMMIT:һ���ύ��ʾ��һ���¼ԭ��д�뵽���ݼ���
2)CLEAN: ɾ�����ݼ��в�����Ҫ�ľ��ļ��汾�ĺ�̨�
3)DELTA_COMMIT:��һ����¼ԭ��д�뵽MergeOnRead�洢���͵����ݼ���,����һЩ/�������ݶ�����ֻд��������־��
4)COMPACTION: Э��Hudi�в������ݽṹ�ĺ�̨�,����:�����´ӻ����е���־�ļ�����и�ʽ�����ڲ�,ѹ������Ϊʱ�����ϵ������ύ
5)ROLLBACK: ��ʾ�ύ/�����ύ���ɹ����ѻع�,ɾ����д������в��������в����ļ�;
6)SAVEPOINT: ��ijЩ�ļ�����Ϊ"�ѱ���",�Ա��������Ὣ��ɾ����
�ڷ�������/���ݻָ��������,�������ڽ����ݼ���ԭ��ʱ�����ϵ�ij����;�κθ����ļ�ʱ���ᴦ������״̬֮һ:
a)REQUESTED:��ʾ�ѵ��ȵ���δ��ʼ��
b)INFLIGHT: ��ʾ��ǰ����ִ�иò���
c)COMPLETED: ��ʾ��ʱ����������˸ò���.

�����ļ�
Hudi������֯��DFS�ϻ���·���µ��ļ��нṹ��
������Ƿ�����,���ڻ���·���»����������ķ���,��Щ�����ǰ����÷������ݵ��ļ���,��Hive���dz�����
ÿ��������������ڻ���·���ķ���·��Ψһ��ʶ
��ÿ��������,�ļ�����֯���ļ���,���ļ�IDΨһ��ʶ������ÿ����Ƭ������ij���ύ/ѹ����ʱʱ�����ɵĻ������ļ�(*.parquet)�Լ�һ����־�ļ�(*.log*),���ļ����������ɻ����ļ������Ի����ļ��IJ���/���¡�
Hudi������MVCC���,ѹ�������Ὣ��־�ͻ����ļ��ϲ��Բ����µ��ļ�Ƭ,������������δʹ�õ�/�Ͼɵ��ļ�Ƭɾ���Ի���DFS�ϵĿռ�
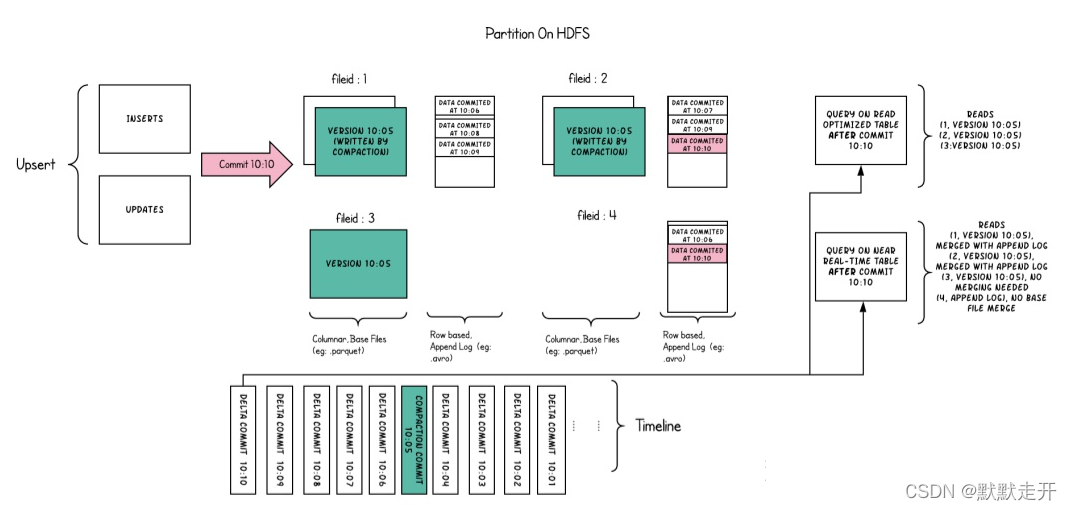
����
Hudiͨ�����������ṩ��Ч��upsert����,�û��ƻὫһ����¼��+����·�����һ���Ե�ӳ�䵽һ���ļ�ID.�����¼�����ļ���/�ļ�ID֮���ӳ���Լ�¼��д���ļ��鿪ʼ�Ͳ����ٸı�
�����֮,���ӳ���ļ��������һ���ļ������а汾
Hudi��ǰ�ṩ��3������ʵ��(HBaseIndex,��HoodieBloomIndex(HoodieGlobalBloomIndex)��InMemoryHashIndex)��ӳ��һ����¼���������ü�¼���ļ�ID
�⽫ʹ��������ɨ����е�ÿ����¼,�Ϳ��������upsert�ٶȡ�
Hudi�������Ը������ѯ������¼���������з���:
1)ȫ������:����Ҫ������Ϣ���ɲ�ѯ��¼��ӳ����ļ�ID������,д������Դ���null�����κ��ַ�����Ϊ����·��(partitionPath),��������Ȼ����ҵ��ü�¼��λ�á�ȫ�������ڼ�¼�������ű��б�֤Ψһ������·dz�����,���Dz�ѯ���������ű��Ĵ�С�ʺ���ʽ����
2)��ȫ������:��ȫ��������ͬ,��ȫ��������������·��(partitionPath),���ڸ����ļ�¼��,��ֻ���ڸ�������·���²��Ҹü�¼����Ƚ��ʺ�����ͬʱ���ɷ���·���ͼ�¼���ij���,ͬʱ�������ܵ����õ���չ��,��Ϊ��ѯ����������ֻ��д�뵽�÷��������ݼ���С�й�ϵ
������
Copy On Write
COW��д��ʱ������ֱ��д��basefile,(parquet)��дlog�ļ�������COW�����ļ�Ƭֻ����basefile(һ��parquet�ļ�����һ���ļ�Ƭ)�����ֵĴ洢��ʽ��Spark DAG��Լ��ؼ�Ŀ������ʹ��partitioner��tagged Hudi��¼RDD(��ν��tagged��ָ�Ѿ�ͨ��������ѯ,���ÿ�������¼�ڱ��е�λ��)�ֳ�һЩ�е�updates��inserts.Ϊ��ά���ļ���С,�����ȶ�������в���,���һ����������profile,���profile��¼�������¼��insert��update���Լ��ڷ����еķֲ�����Ϣ�������ݴ��´��,����:
1)����updates, ���ļ�ID�����°汾��������дһ��,���������Ѹ��ĵļ�¼ʹ����ֵ
2)����inserts,��¼���ȴ����ÿ������·���е���С�ļ���,ֱ���ﵽ���õ�����С��֮�������ʣ���¼���ٴδ�����µ��ļ���,�µ��ļ���Ҳ����������ļ���СҪ��
Merge On Read
MOR��д����ʱ,��¼���Ȼᱻ���ٵ�д����־�ļ�,�Ժ��ʹ��ʱ�����ϵ�ѹ����������������ļ��ϲ������ݲ�ѯ�Ƕ�ȡ��־�еĺϲ����������DZ����,���ǽ���ȡδ�ϲ��Ļ����ļ�,MOR��֧�ֶ��ֲ�ѯ���͡��ڸ߲����,MOR writer�ڶ�ȡ����ʱ�ᾭ����COW writer ��ͬ�ĽΡ���Щ���½��ӵ������ļ�ƪ��������־�ļ���,������ϲ���
����insert,Hudi֧������ģʽ:
1)���뵽��־�ļ�:�п�������־�ļ��ı���ִ�д˲���(HBase����)
2)����parquet�ļ�:û�������ļ��ı�(���粼¡����)��дʱ����(COW)һ��,���ѱ��λ�õ������¼���з���,�Ա㽫���з�����ͬ�ļ�id��upsert�ֵ�һ�顣����upsert����Ϊһ��������־��д����־�ļ���Hudi�����ͻ��˿�����־�ļ���С������дʱ����(COW)�Ͷ�ʱ�ϲ�(MOR)writer��˵,Hudi��WriteClient����ͬ�ġ��������ݵ�д�뽫���ۻ�һ��������־�ļ�����Щ��־�ļ��������parquet�ļ�(����)һ��һ���ļ�Ƭ,������ļ�Ƭ�������ļ���һ�������汾�����ֱ�����;��㡢����ı���Ϊд(����ָ����ͬ��ѹ������,����ͻ��д����)�Ͳ�ѯ(����Ȩ�����ݵ����ʶȺͲ�ѯ����)�ṩ�˺ܴ������ԡ�ͬʱ������һ��ѧϰ����,�Ա��ڲ������ƿ���
��
���
�˽�Hudi����Դ����deltastreamer�����ṩ��3�ֲ�ͬд�����Լ������õ��������ǿ��ܻ�������������Щ���������ڶ����ݼ�������ÿ��commit/delta commit�н���ѡ��/����
1)upsert����:����Ĭ�ϲ���,�ڸò�����,����ͨ����ѯ���������ݼ�¼���Ϊ��������,Ȼ����������̽��ȷ�������õؽ����Ǵ�����洢,�Զ��ļ���С�����Ż�,���ս���¼д�롣�����������ݿ���IJ���֮�������,���������뼸���϶��������µ������ʹ�ô˲���
2)insert����:��upsert���,insert����Ҳ��������̽��ȷ�������ʽ,�Ż��ļ���С,������ȫ����������ѯ����˶���������־�ظ�����ɾ��(��������ᵽ�Ĺ����ظ���ѡ��)����������,����upsert���ٶȿ�öࡣ��Ҳ���������ݼ����������ظ���,��ֻ��ҪHudi����������д/������ȡ/�洢�������ܵ�����
3)bulk insert����:upsert ��insert�������Ὣ�����¼�������ڴ���,�Լӿ�洢����ʽ�����ٶ�,��˶����������/����Hudi���ݼ����������Կ��ܻ���鷳��Bulk insert�ṩ����insert��ͬ������,ͬʱʵ���˻������������д���㷨,���㷨���Ժܺõ���չ����TB�ij�ʼ���ء�������ֻ���ڵ����ļ���С������е����Ŭ��,��������insert/update������֤�ļ���С
ѹ��
ѹ����һ�� instant����,����һ���ļ�Ƭ��Ϊ����,��ÿ���ļ���Ƭ�е�������־�ļ�����basefile�ļ�(parquet�ļ�)�ϲ�,�������µ�ѹ���ļ�Ƭ,��дΪʱ�����ϵ�һ��commit��ѹ���������ڶ�ʱ�ϲ�(MOR)������,������ѹ������(Ĭ��ѡ��������δѹ����־���ļ�Ƭ)����ѡ��Ҫ����ѹ�����ļ�Ƭ�����ѹ�����Ի���ÿ��д����֮��������
�Ӹ߲���Ͻ�,ѹ�������ַ�ʽ:
1)ͬ��ѹ��:�����ѹ����д������̱�����ÿ��д��֮��ͬ��ִ�е�,��ֱ��ѹ����ɺ���ܿ�ʼ��һ��д�������Ͳ�������,��������,��Ϊ���谲�ŵ�����ѹ������,����֤���������ʶ���͡�����,���������ÿ��д������ѹ�����µı�����,ͬʱ�����ӳٳٵ�/�Ͼɷ�����ѹ��,���ַ�ʽ��Ȼ�dz����á�
2)�첽ѹ��:ʹ�����ַ�ʽ,ѹ�����̿��������д����ͬʱ�첽���С������������Եĺô�,��ѹ������������һ������д��,�Ӷ�������ʵʱ���������ʶȡ�Hudi DeltaStreamer֮��Ĺ���֧�ֱ߽������ģʽ,���е�ѹ����д��������������ַ�ʽ�ڵ���Spark����ʱ��Ⱥ�н��е�
����
������һ������ļ�ʱ����,��ִ�е�Ŀ����ɾ���ɵ��ļ�Ƭ,�����Ʊ�ռ�õĴ洢�ռ䡣��������ÿ��д����֮���Զ�ִ��,������ʱ����������ϻ����ʱ����Ԫ����������ɨ������������������ʱ����
Hudi֧������������ʽ:
1)��commits / deltacommits����:����������ѯ������ұ���ʹ�õ�ģʽ�������ַ�ʽ,Cleaner�ᱣ�����N��commit/delta commit�ύ��д��������ļ���Ƭ,�Ӷ���Ч�ṩ���κμ�ʱ��Χ�ڽ���������ѯ�����������������������ѯ���а���,�����ڱ��������÷�Χ�����а汾���ļ�Ƭ,���,��ijЩ��д�븺�صij����¿�����Ҫ����Ĵ洢�ռ�
2)���������ļ�Ƭ����:����һ�ָ�Ϊ��������ʽ,�������ǽ�����ÿ���ļ����е����N���ļ�Ƭ������Apache Hive֮���ijЩ��ѯ����ᴦ���dz���IJ�ѯ,��Щ��ѯ������Ҫ����Сʱ�������,�����������,��N����Ϊ�㹻�������ڲ���ɾ����ѯ��Ȼ���Է��ʵ��ļ�Ƭ�Ǻ����õġ�����,���������ᱣ֤ÿ���ļ��������һֱֻ��һ���ļ�Ƭ(���µ�һƬ)
DFS�����Ż�
Hudi���Ա��д洢������ִ���˼�����Կ�洢�������ܡ���DFS�ϴ洢���ݵĹؼ��ǹ����ļ���С�ͼ����Լ����մ洢�ռ䡣����,HDFS�ڴ���С�ļ������ϳ��������C��NameNode��ʩ���ڴ�/RPCѹ��,�����ƻ�������Ⱥ���ȶ��ԡ�ͨ��,��ѯ��������ʵ���С�����ļ����ṩ���õ�����,��Ϊ���ǿ�����Ч��̯����ȡ��ͳ����Ϣ�ȵijɱ�����ʹ��ijЩ�����ݴ洢��,�г���������С�ļ���Ŀ¼Ҳ������ɱ���
������һЩHudi��Чд,�������ݴ洢�ķ���:
1)С�ļ��������Ի���������Ĺ�������,�������ݷ��䵽���е��ļ���,�����Ǵ������ļ���(��ᵼ������С�ļ�)
2)��writer��ʹ��һ��ʱ���Ỻ��,����ֻҪSpark��Ⱥ��ÿ�ζ�����,������д�����Ͳ���Ҫ�г�DFSĿ¼����ȡָ������·���µ��ļ�Ƭ�б�
3)�û������Ե��������ļ�����־�ļ���С֮��ı�ֵϵ���Լ�������ѹ����,�Ա㽫�㹻������insert�ֵ�ͳһ�ļ���,�Ӷ����ɴ�С���ʵĻ����ļ�
4)���ܵ���bulk insert���ж�,�����ٴε�����С���ʵij�ʼ�ļ��顣ʵ����,��ȷִ�д˲����dz��ؼ�,��Ϊ�ļ���һ�������Ͳ��ܱ�ɾ��,��ֻ����ǰ���������������չ
��ѯ
������������ȫ������ݲ��ֺͷḻ��ʱ����,Hudi�ܹ�֧�����ֲ�ͬ�IJ�ѯ����ʽ,����ȡ���ڱ������͡���ѯ����COW/MOR���ղ�ѯ,��ѯ�ڸ�������������������ļ�Ƭ�е����»����ļ���ִ��,���鿴�������ύ�ļ�¼��ͨ��������������������е������ļ���Ƭ�����µĻ����ļ�������־�ļ�����ִ�в�ѯ,���������µ�delta-commit����д��ĵļ�¼��������ѯ�ڸ����Ŀ�ʼ,������ʱʱ�䷶Χ��,�����µĻ����ļ�ִ�в�ѯ(��Ϊ������ѯ����),ͬʱ��ʹ��Hudiָ��������ȡ�ڴ˴�����д��ļ�¼����ѯ����������ѯ�����ж����µ��ļ�Ƭִ�е�,����ȡ���ڴ��ڱ���,��ȡ���������־���ж�ȡ��¼����ϡ����Ż���ѯ�Ϳ��ղ�ѯ��ͬ�����ʻ����ļ�,�ṩ�����ļ�Ƭ���ϴ�ִ��ѹ���������������ݡ�ͨ����ѯ���ݵ����³̶ȵı�֤ȡ����ѹ������
a)���ղ�ѯ
�ɲ鿴����delta commit����commit��ʱ������������¿��ա��ڶ�ʱ�ϲ�(MOR)���������,��ͨ����ʱ�ϲ������ļ�Ƭ�Ļ����ļ��������ļ����ṩ��ʵʱ��(������)������дʱ����(COW),������������е�parquet��(����ͬ�����ļ����͵ı�),ͬʱ�ṩupsert/delete������д�뷽��Ĺ���
b)������ѯ
�ɲ鿴�Ը���commit/delta commit��ʱ����������д������ݡ���Ч���ṩ������������������ݹܵ�
c)���Ż���ѯ
�ɲ鿴������commit/compact��ʱ�����ı������¿��ա����������ļ�Ƭ�Ļ���/���ļ���¶����ѯ,����֤���Hudi����ͬ���в�ѯ���ܡ�ָ����Ż���ѯ���ղ�ѯ�����ӳٸߵͲ�ѯ�ӳٵ�