Mysql基础知识
我们要了解mysql,那就从最常见的流程开始,我们在cilent端输入一条sql,究竟会经历哪些步骤? 可以思考30s …
一条SQL查询语句执行流程
select * from table where Id=4
要弄懂这条语句做的事情,我们先看下mysql整个架构涉及的
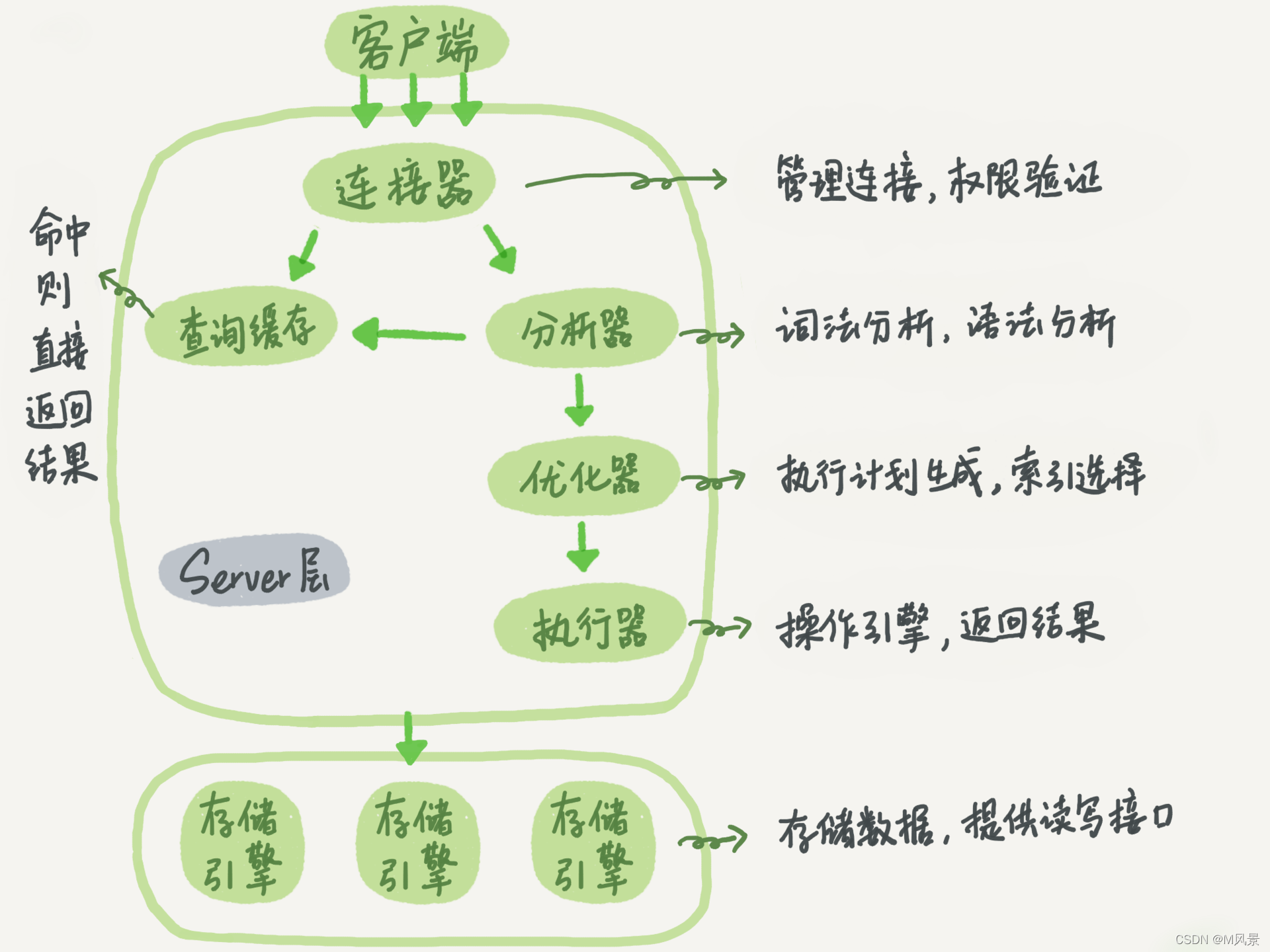
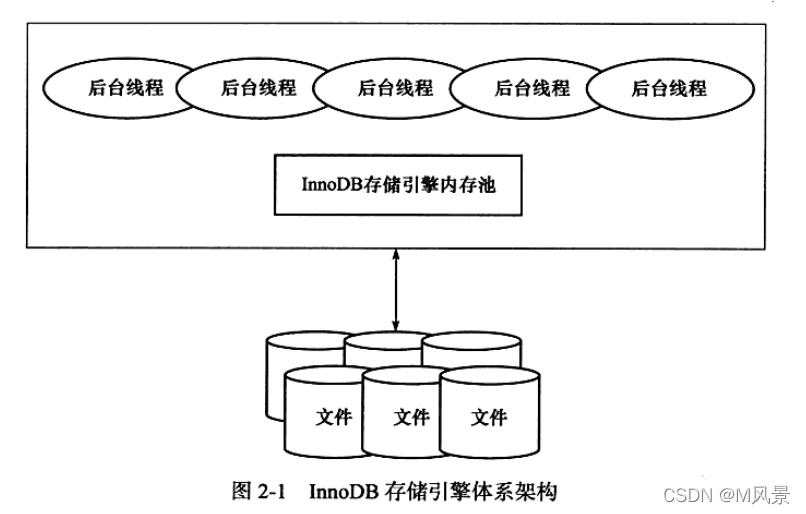
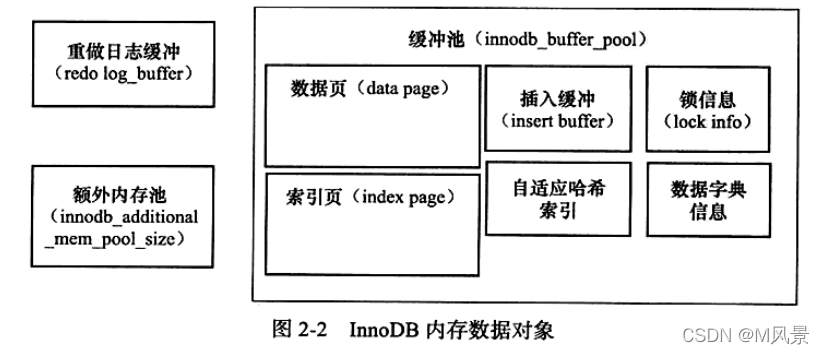
分为客户端,server端以及存储引擎,存储引擎层负责数据的存储和提取,其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。
-
首先要和server端建立连接,通过命令 mysql -h i p ? P ip -P ip?Pport -u$user -p来进行三次握手,建立连接,建立好的连接可以通过命令 show processlist 来查看
-
分析器进行sql的词法和语法分析,如果表字段不存在,是在分析器阶段就提示 “Unknown column ‘k’ in ‘where clause’”,这个设计也是受oracle的影响
-
下一步是优化器,主要是进行索引的选择,以及执行方法逻辑的选择,比如你查询 select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20; 可以先根据t1条件查出数据,再根据t2过滤
-
确定好执行方式后,执行器会先判断是否有权限进行数据查询,如果有权限,则调用引擎的表接口进行查询
例如 select * from T where ID=10; 执行器的执行逻辑是这样的:
a. 调用innodb的引擎接口取这个表的第一行,判断ID的值是不是10,如果不是则跳过,如果是,那将数据存到结果集
b. 调用引擎接口查询下一行,重复相同的逻辑,直到最后一行数据
c. 执行器将结果集的数据返回给客户端
如果ID上面有索引,那么查询a执行的是查询符合条件的数据,在explain 执行语句的时候,rows_examined字段就代表查询的数据次数
一条SQL更新语句执行流程
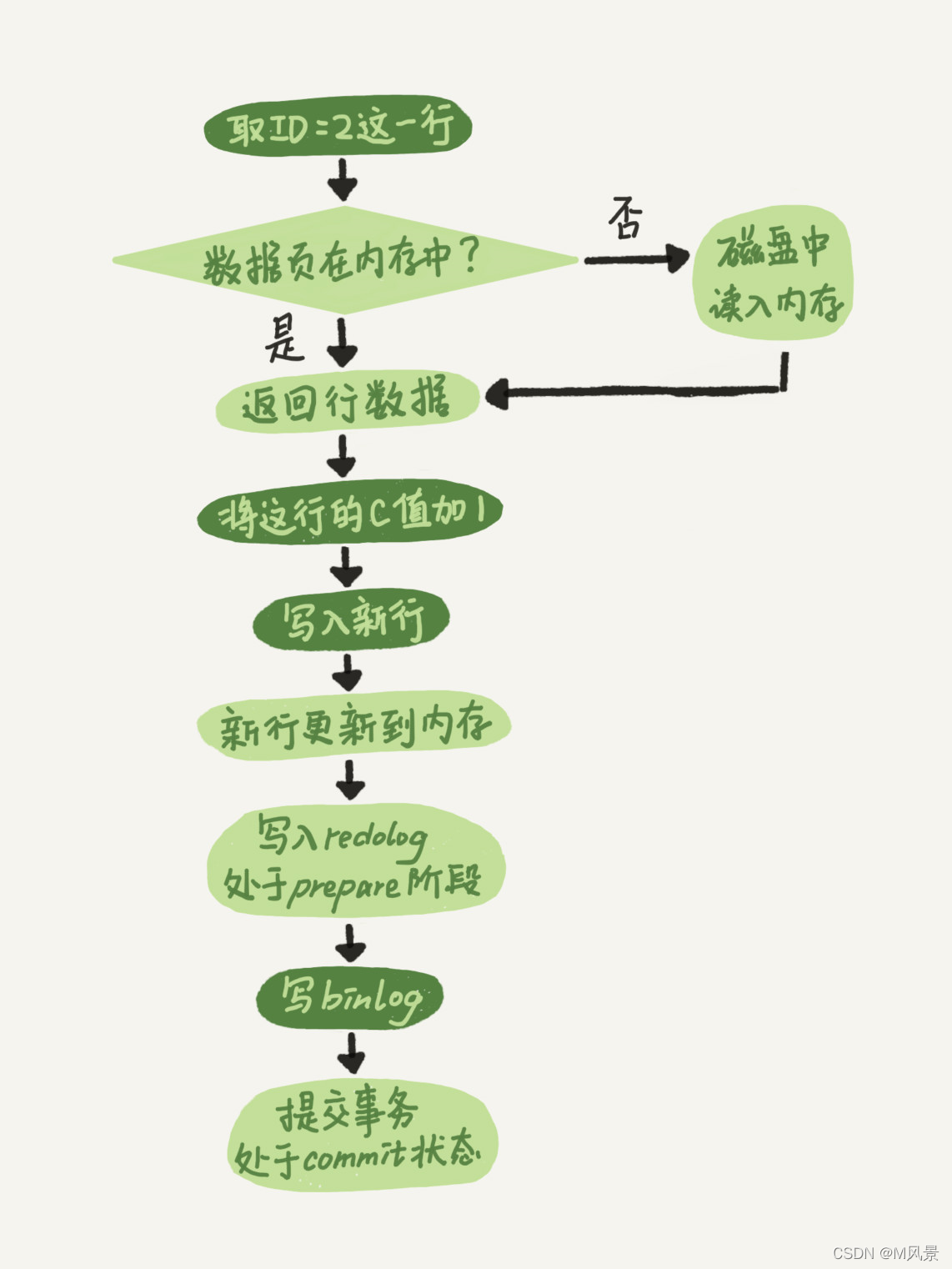
update table set a=‘xxx’ where Id=4
更新语句前几个步骤和查询语句是一样的,分析器知道这是一条更新语句,优化器决定使用ID这个索引,执行器执行更新,更新流程还涉及重要的两个日志模块,redo log和bin log
redo log
-
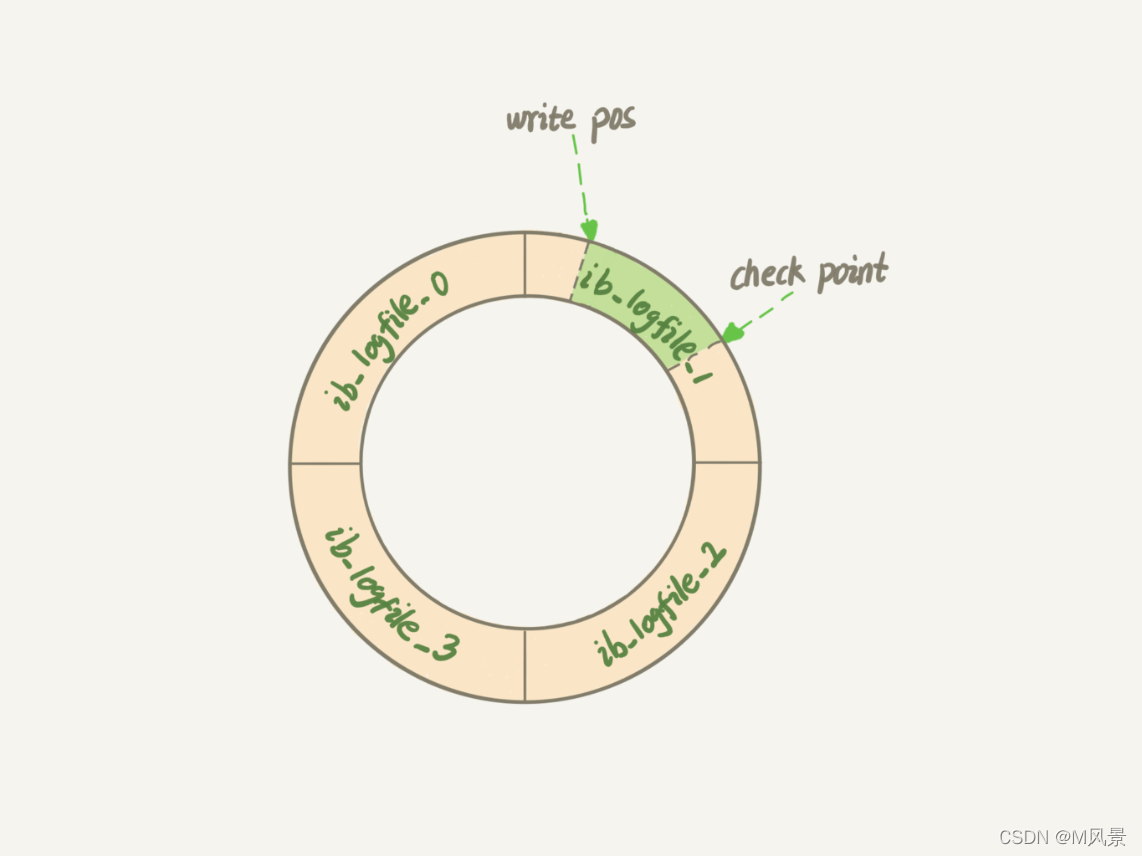
innoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做
-
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB
-
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”
binlog
bin log是server端都有的,用于实现 crash-safe 能力。
binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”
索引原理
索引的常见实现方式: 哈希表、有序数组和搜索树
哈希表
哈希表是一种以键 - 值(key-value)存储数据的结构,我们只要输入待查找的键即 key,就可以找到其对应的值即 Value。哈希的思路很简单,把值放在数组里,用一个哈希函数把 key 换算成一个确定的位置,然后把 value 放在数组的这个位置。 可以类比hashMap的实现原理,链条过长还可以用红黑树进行优化
哈希表适合等值查询,做区间查询很慢
有序数组
有序数组在等值查询和范围查询场景中的性能就都非常优秀,适用于静态存储引擎,因为数组更新效率很慢。静态数据查询效率可以到O(Log(N))
搜索树
父节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值
插入数据维持平衡树,效率是O(log(N))。查询也是O(log(N))。
索引实战:
create table T(id int primary key, k int not null, name varchar(16),index (k))engine=InnoDB;
表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树的示例示意图如下。
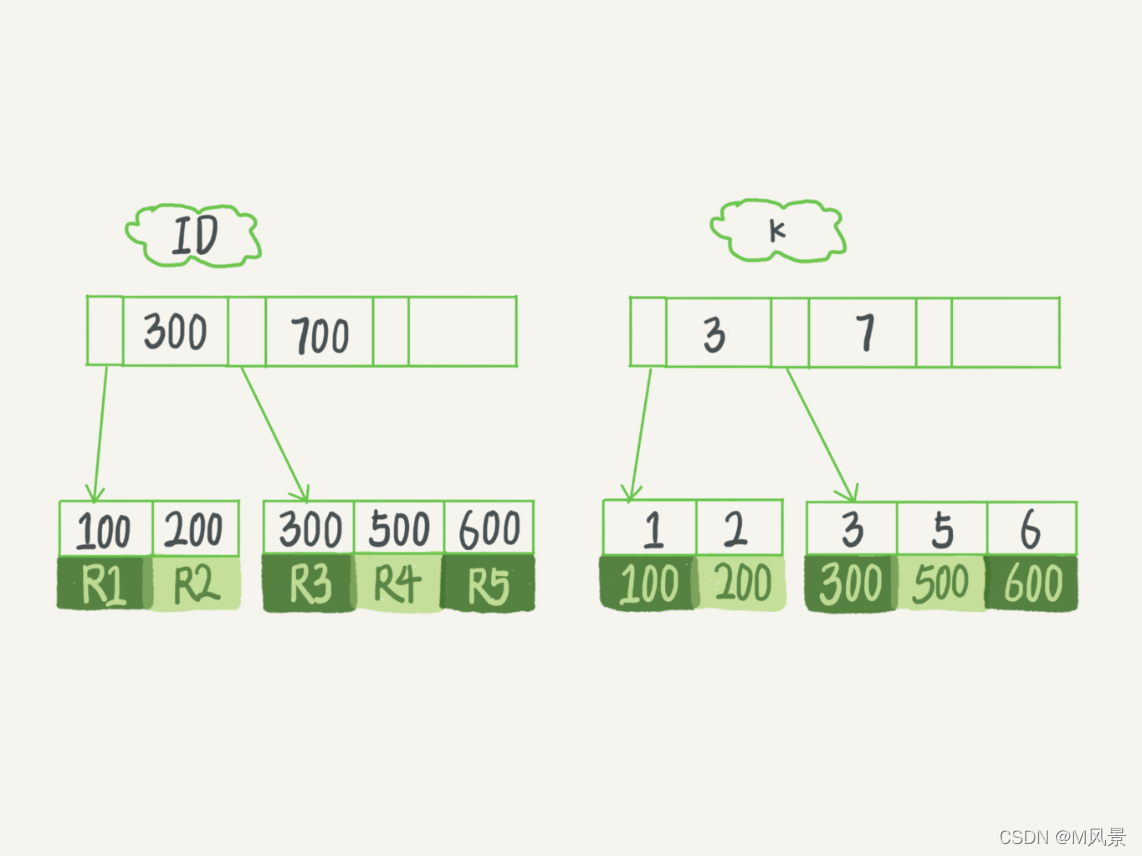
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
如果语句是 select * from T where ID=500,即主键查询方式,则只需要搜索 ID 这棵 B+ 树;
如果语句是 select * from T where k=5,即普通索引查询方式,则需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
索引维护:
B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。以上面这个图为例,如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。如果新插入的 ID 值为 400,就相对麻烦了,需要逻辑上挪动后面的数据,空出位置。而更糟的情况是,如果 R5 所在的数据页已经满了,根据 B+ 树的算法,这时候需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。当然有分裂就有合并。当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。合并的过程,可以认为是分裂过程的逆过程。
要求建表语句里一定要有自增主键,大家知道原因了吧? 还有建议直接用主键进行搜索,
数据页
常见索引优化
1、count(*) 和count(1),count(id), count(表字段) 区别以及建议使用方式
效率:count(字段)<count(主键id)<count(1)≈count(*)
https://mp.weixin.qq.com/s/p6MCW1O3y53b5pajY_MvAg
2、索引覆盖,最左匹配原则,回表,索引下推
索引重建
索引下推:
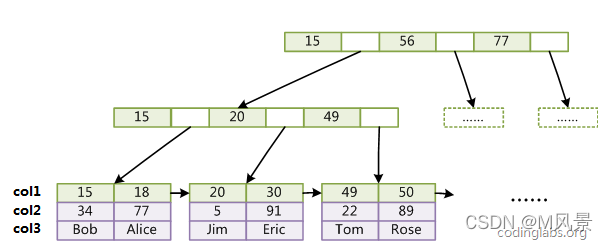
3、联合索引的存储结构是什么样的?
4、 CBO(基于成本的优化),RBO(基于规则的优化) 是什么? 优化器的原理,对于联合索引 (a,b), 当查询条件为 where b=xxx and a=xxxx 是否会命中索引?
给表加字段的逻辑
慢sql排查思路
- Mysql慢查询如何排查
#查看所有处理线程
show processlist;
查看占用时长的线程
select * from information_schema.processlist where Command != ‘Sleep’ order by Time desc;
#查看所有的字段
show full columns from table_name;
#查看索引
show index from table_name;
explain 具体sql查看是否命中索引等,具体的索引字段
索引失效的情况
https://zhuanlan.zhihu.com/p/166247445
慢sql查看process的state状态
一直处于sending data状态原因
https://blog.csdn.net/yunhua_lee/article/details/8573621
show processlist详解
https://zhuanlan.zhihu.com/p/30743094
#查看profile是否打开
show variables like ‘profiling’;
SET profiling=on;
SET profiling=off;
show profiles;
show profile for query all;
事务以及隔离级别,MVCC
事务基本特性(ACID)
原子性 aotmic
一致性 consistent
隔离性 cnstraint
持久性 duriation
原子性由 undo log来保证
一致性一般由代码来保证
隔离性 通过MVCC机制进行保证
隔离级别有四种
read uncommit 会有脏读问题
read commit
repeat read 会有幻读问题
serialized
如何解决幻读
mvcc +间隙锁
间隙锁是什么?
左开右闭的一个区间范围
示例:
begin;
select * from user where age=20 for update;
由于20存在记录,所以(10,20],(20,30]区间都被锁定了无法插入、删除
MVCC叫做多版本并发控制,通过建立不同的视图来实现,每一条sql都会有默认的两个字段
create_version和deleteVersion,每个不同的事务执行都会有一个create_version增加
查询数据的时候,只会查询当前事务create_version小于current_version并且delete_version大于current_version或者delete_version为空的数据
持久性通过 redo log和内存来保证的,这里的数据写入参考上面的数据更新逻辑
Mysql主从同步
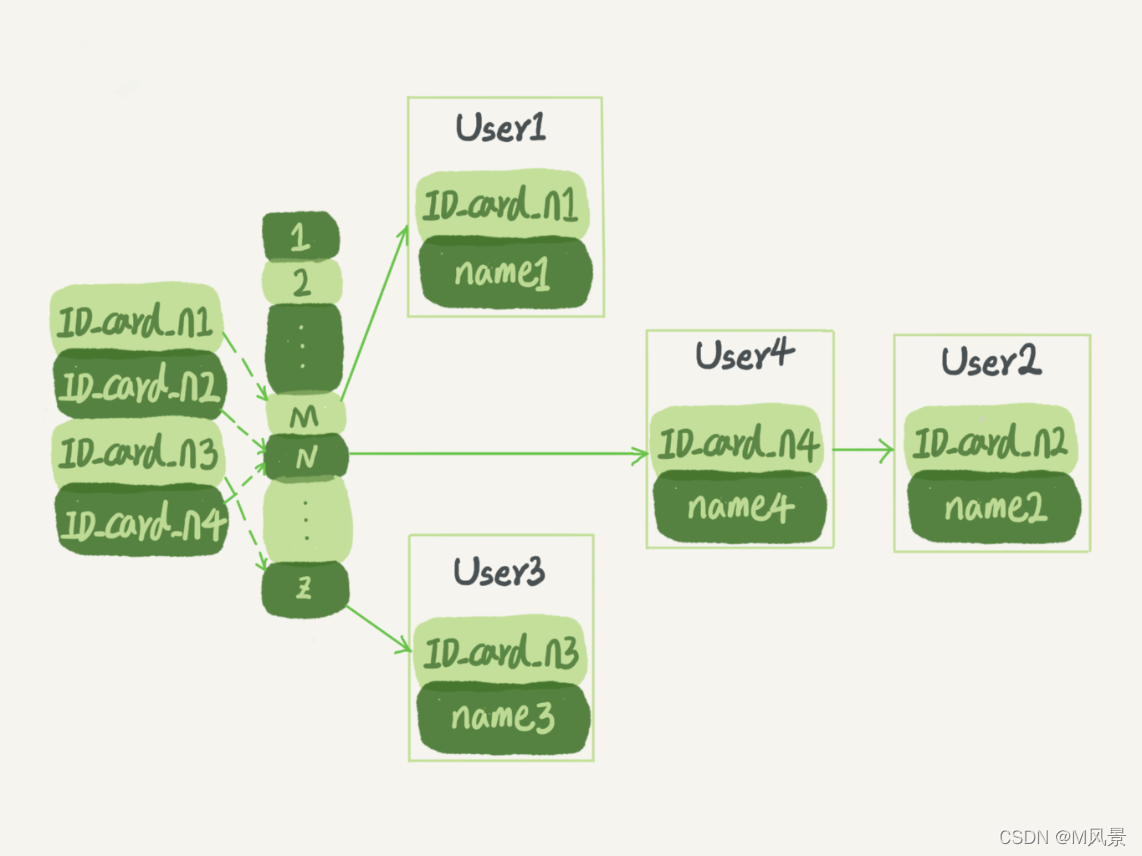
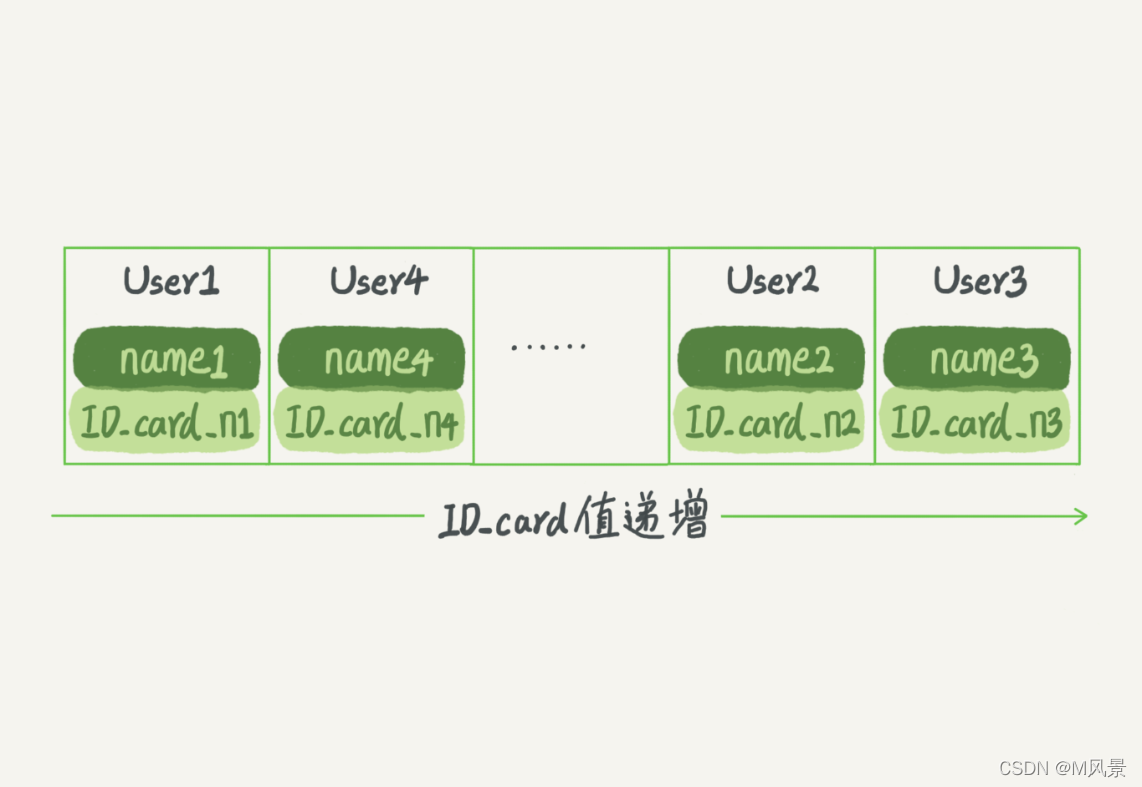
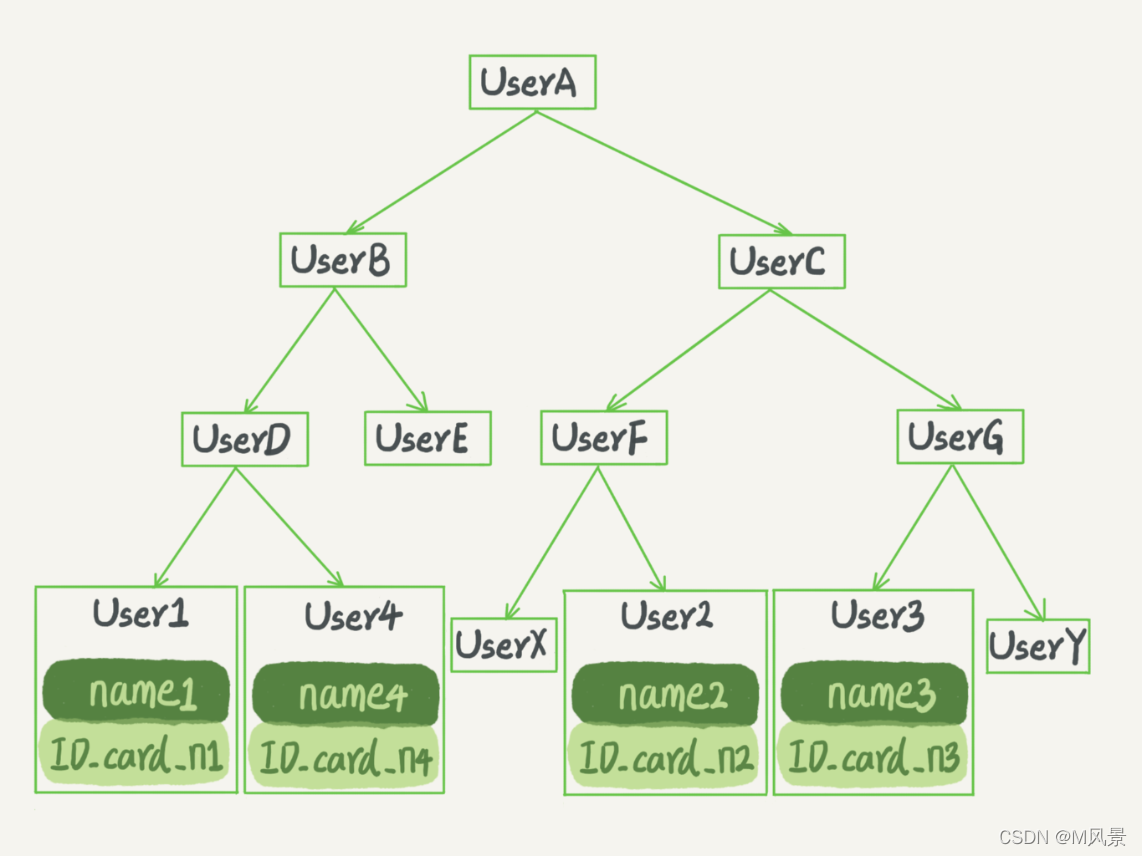
分库分表
INNODB