�����ѧϰ���ʹ��hdfs���洢�ļ�,������ѧϰ��һ��,��ȷ��HDFS(Hadoop Distribute File System �ֲ�ʽ�洢)��mapReduce(�ֲ�ʽ����)��YARN(Yet Another Resource Negotiator��Դ����)��hadoop��������ɲ���,Ҫ��ʹ��hdfs,����hadoop��Ⱥ,Ϊ��չ���˽�һ�����ڵ�������
���ϵĽ̳��кܶ�,���ܶд�IJ�ȫ,�Լ�Ҳ��һֱ�ȿ�,����֮��ֻ�ö��Źٷ��ĵ�һ������,�����Ⲣ��ȷ�˲���,�ھ�����������ȷ������֮��,�����ڴ˼�¼һ��,�Ա����ҽ���������
1����Ⱥ�滮
1.1 hadoop�汾
hadoop�汾��ͬ,���õ�����Ҳ��ͬ,����ʹ�õ���hadopp-3.3.2,ͬ������3�������汾,��װ�����Ӽ�2.1��
1.2 �ڵ�����
ֻΪ����ѧϰ,�ڵ㲻��̫��,�ƻ�ʹ��3���ڵ�,������3��docker����,1��namenode�ڵ�,2��datanode�ڵ�,����1��datanode��Ϊsecond namenode
1.3 hostname��ip
hadoop��ȺҪ��ڵ���й̶���hostname��ip,�ڴ������¹滮:
namenode��hostnameΪmaster,ipΪ192.168.0.10
��1��datanode��hostnameΪslave1,ipΪ192.168.0.11
��2��datanode��hostnameΪslave2,ipΪ192.168.0.12
1.4 �˿�
hadoop��Ⱥ�ṩ����ҳ��������,��Ҫ����hdfs(�ļ�ϵͳ)��cluster(��Ⱥ)��jobhistory(��ʷ����)����,ÿ�����ֶ��з��ʵĶ˿ں�
ͨ�����Ĺٷ��ĵ�ȷ����Ĭ�ϵĶ˿ںŷֱ�Ϊ9870��8088��19888,����ֱ��ʹ����ЩĬ�ϵĶ˿ں�

2��hadoop����
2.1 ��װ��
hadoop-3.3.2.tar.gz
jdk-8u321-linux-x64.tar.gz hadoop��Ҫjava�Ļ���,�˰�������Ҫoracle�˺�,û���˺ŵĿ������ע��,�����ʹ��m1 macϵͳ��������jdk17 Arm64�汾��
2.2 Dockerfile
������������ʹ��Dockerfile,ע������ļ������ݴ�ҿ��Ը����Լ��������,��
����Դ:ʹ��centos7,��ҿ��Ի�
LABEL:Ԫ���������������ߺ�����,��ҿ��Ըij��Լ�����Ϣ
ssh:���ڽڵ�ֱ���������
which:hadoop����ִ����Ҫwhich,��Ȼ�ᱨ��
jdk:����8u321�汾��,�����������������еİ汾��Ϣ
ADD jdk-8u321-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_321 /usr/local/jdk1.8
hadoop:����3.3.2�汾��,�����������������еİ汾��Ϣ
ADD hadoop-3.3.2.tar.gz /usr/local
RUN mv /usr/local/hadoop-3.3.2 /usr/local/hadoop
�������������ļ�����
# ����Դ
FROM centos:7
# ����Ԫ����
LABEL author="hjq" date="2022/03/05"
# ��װopenssh-server��sudo������,���ҽ�sshd��UsePAM�������ó�no
RUN yum install -y openssh-server sudo
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
# ��װopenssh-clients
RUN yum install -y openssh-clients
# ��װwhich
RUN yum install -y which
# ���Ӳ����û�root,����root,���ҽ����û����ӵ�sudoers��
RUN echo "root:root" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# ����sshd�����ұ�¶22�˿�
RUN mkdir /var/run/sshd
EXPOSE 22
# ��������ѹjdk,�����Լ��İ汾��
ADD jdk-8u321-linux-x64.tar.gz /usr/local/
RUN mv /usr/local/jdk1.8.0_321 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATH
# ��������ѹhadoop,�����Լ��İ汾��
ADD hadoop-3.3.2.tar.gz /usr/local
RUN mv /usr/local/hadoop-3.3.2 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATH
# ����������������
CMD ["/usr/sbin/sshd", "-D"]
2.3 ����
�ڱ����½�һ���Զ������Ƶ��ļ���,��������Dockerfile��hadoop-3.3.2.tar.gz��jdk-8u321-linux-x64.tar.gz���������ļ�����,Ȼ��ʹ���ն˽����Ŀ¼,������docker build -t hadoop-test .�����˺����.
�ȴ����н���,����ssh��jdk��hadoop�ľ�����������
3��hadoop��������
�����������������õľ�������һ����������,�ڴ����������úò�����,����Ϊ�µľ���,�����Ժ�node�����Ͳ�������������
- ��������
docker run -d --name hadoop-test hadoop-test - ��������
docker exec -it hadoop-test bash - ����hadoop����Ŀ¼
cd /usr/local/hadoop/etc/hadoop/ - ����hadoop��������
vi hadoop-env.sh
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export JAVA_HOME=/usr/local/jdk1.8
- ���ú��IJ���
vi core-site.xml
io.file.buffer.size:�ļ���������С,Ĭ��Ϊ4096(4MB),��������
fs.trash.interval:��������վ�ļ��,��λΪ����,Ĭ��Ϊ0,��ʾhdfs��ɾ�����ļ�����������վ,����ֱ��ɾ��,��������
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
- ����hdfs
vi hdfs-site.xml
dfs.namenode.name.dir:namenode�洢����Ϣ��·��
dfs.datanode.data.dir:datanode�洢ʵ���ļ����ݿ��·��
dfs.replication:�ļ���������,������datanode�ĸ���
dfs.namenode.secondary.http-address:secondary namenode������ַ,�˿ں�Ĭ��Ϊ9868,�ɰ�����
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
</configuration>
- ������Դ����
vi yarn-site.xml
yarn.resourcemanager.hostname:yarn������������
yarn.nodemanager.aux-services:Ĭ��
yarn.log-aggregation-enable:�Ƿ�ۺϸ��ӽڵ����־��Ϣ�����ڵ�,����Ϊ��,��Ȼ��web�Ͽ�������־
yarn.log-aggregation.retain-seconds:��־����ʱ��,��λ��,Ĭ��Ϊ-1,��ɾ��,�ɰ�������
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
</configuration>
- ���÷ֲ�ʽ����
vi mapred-site.xml
mapreduce.framework.name:����ִ��MapReduce��ҵ������ʱ���,��ѡ����local��classic��yarn,Ĭ��Ϊlocal,����ѡyarn
mapreduce.jobhistory.address:��־��ʷ��������ַ,Ĭ��Ϊ0.0.0.0:10020,�ɰ�����
mapreduce.jobhistory.webapp.address:��־��ʷ��ҳ��ַ,Ĭ��Ϊ0.0.0.0:19888,�ɰ�����
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
- �����ӽڵ�
vi workershadoop2���õ�slaves,����2��3��һ����
�����е�localhost�����ǵ�datanode��hostname�滻
slave1
slave2
- ����hadoop�����û����㶨,�˳����ر�����
������������Ϊ�µľ���docker commit hadoop-test hadoop:base
4����Ⱥ�
�����������úõ�hadoop����,���ǿ��Կ��ٹ��� node ����
4.1 ����docker����
֮ǰ˵��,hadoopҪ��ڵ���й̶�ip,docker����ͨ��networkΪ�������ù̶�ip
docker network create --subnet=192.168.0.0/24 hadoop
����24��ʾip��ǰ24λΪ�̶�,��8Ϊ����,��192.168.0.1-192.168.0.254����,hadoopΪnetwork������,�˲��ֿɰ�����
4.2 ����node����
�ֱ��������������master��slave1��slave2��������,���ШChostname��������node����������,�Cip�������ù̶�ip
����Ϊmaster��8088��9870��19888�˿ں�,�����ڱ��ط���
��Ҫע�����,�����ڹ�������ʱΪ������������������CMD ["/usr/sbin/sshd", "-D"](Dockerfile���һ��,ʹ��������ʱ�Զ�����ssh����),���Բ�Ҫʹ��docker run -itd����������,����ᱻ�����Զ��������(��bash)�滻,����sshδ����,�Ӷ�����22�˿������ʵ�����
docker run -d --name master --hostname master --network hadoop --ip 192.168.0.10 -P -p 8088:8088 -p 9870:9870 -p 19888:19888 hadoop:base
docker run -d --name slave1 --hostname slave1 --network hadoop --ip 192.168.0.11 -P hadoop:base
docker run -d --name slave2 --hostname slave2 --network hadoop --ip 192.168.0.12 -P hadoop:base
4.3 ����node���ܵ�¼
����master���� docker exec -it master bash
������Կ ssh-keygen һֱ�س�����
����Կ�ַ�������node,�˹�����Ҫ���� yes �� ����(Dockerfile�����õ���root)
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
��������datanode�ڵ�������ͬ���IJ���
4.4 ��������
ok,����ȫ�����ú���,�ص�master����ȥ��������
- ��ʽ��hdfs
hdfs namenode -formatע��,��һ�θ�ʽ������,�Ժ�����,��ʽ���ᵼ��namenode��clusterID��datanode��clusterID��һ��,����datanode������ - ��������
$HADOOP_HOME/sbin/start-all.sh - ������ʷ��־����
$HADOOP_HOME/bin/mapred --daemon start historyserver - �鿴�����ķ���
jps,master�ڵ������·����ʾ����

- ����
slave1��slave2����,����jps,slave�ڵ������·����ʾ����
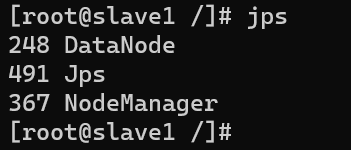
4.5 �رշ���
�����Ҫ�رշ���,��ִ����������
- �ر���ʷ�������
$HADOOP_HOME/bin/mapred --daemon stop historyserver - �رշ���
$HADOOP_HOME/sbin/stop-all.sh
5��hadoop����
5.1 hdfs�������
- ��master�������½�һ���ļ�
vi test.txt,�������һЩ�ַ�,�������˳� - ���ļ����浽hdfs�ĸ�Ŀ¼
hdfs dfs -put test.txt / - �鿴hdfs�ĸ�Ŀ¼����
hadoop fs -ls /,���Կ����ļ��ѱ��浽hdfs

- ����Ҳ����ͨ�����������hdfs��������,�������������
localhost:9870,����Utilities�е��Browse the file system,���ɿ����ļ��洢���,��ַ�˿ںŸ����Լ���������

5.2 mapReduce�������
- ����hadoop��������Ŀ¼
cd $HADOOP_HOME/share/hadoop/mapreduce - ���������
hadoop jar hadoop-mapreduce-examples-3.3.2.jar pi 3 100����jar������pi��ֵ,����100��(�����Լ���hadoop�汾������) - ͨ��������鿴,�������������
localhost:8088,���Բ鿴��������Լ���־��,��ַ�˿ںŸ����Լ���������

- ������������һ��ʱ������,��ʱ����ȥ��ʷ����ҳ��鿴,��ַΪ
localhost:19888,��ַ�˿ںŸ����Լ���������

����
д��һ��������д����,���һ��û���æ��,���滹�ü�������ѧϰ,����~