

实战
以调试 redis 源码为例介绍常用的命令讲解。
准备
- 下载源码并解压
wget http://download.redis.io/releases/redis-6.0.3.tar.gz
tar zxvf redis-6.0.3.tar.gz
- 进入 redis 源码目录并编译,注意编译时要生成调试符号并且关闭编译器优化选项。
cd redis-6.0.3
make CFLAGS="-g -O0" -j 2 (如果已经编译过先 make clean)
- 由于 redis 是纯 C 项目,使用的编译器是 gcc,因而这里设置编译器的选项时使用的是 CFLAGS 选项;如果项目使用的语言是 C++,那么使用的编译器一般是 g++,相对应的编译器选项是 CXXFLAGS。这点请读者注意区别。
- 另外,这里 makefile 使用了 -j 选项,其值是 2,表示开启 2 个进程同时编译,加快编译速度
- 编译成功后,会在 src 目录下生成多个可执行程序,其中 redis-server 和 redis-cli 是需要调试的程序。 进入 src 目录,使用 GDB 启动 redis-server 这个程序:
cd src
gdb ./redis-serve
run命令
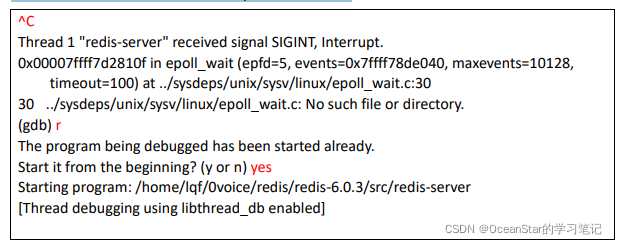
默认情况下, gdb filename 命令只是附加的一个调试文件,并没有启动这个程序,需要输入 run 命令(简写为 r)启动这个程序:

这就是 redis-server 启动界面,假设程序已经启动,再次输入 run 命令则是重启程序。我们在 GDB 界面按 Ctrl + C 快捷键让 GDB 中断下来,再次输入 run 命令,GDB 会询问我们是否重启程序,输入 yes 确认重启。
continue 命令
当 GDB 触发断点或者使用 Ctrl + C 命令中断下来后,想让程序继续运行,只要输入 continue 命令即可(简写为 c)。当然,如果 continue 命令继续触发断点,GDB 就会再次中断下来。


break
break 命令(简写为 b)即我们添加断点的命令,可以使用以下方式添加断点:
- break functionname,在函数名为 functionname 的入口处添加一个断点;
- break LineNo,在当前文件行号为 LineNo 处添加一个断点;
- break filename:LineNo,在 filename 文件行号为 LineNo 处添加一个断点。
这三种方式都是我们常用的添加断点的方式。
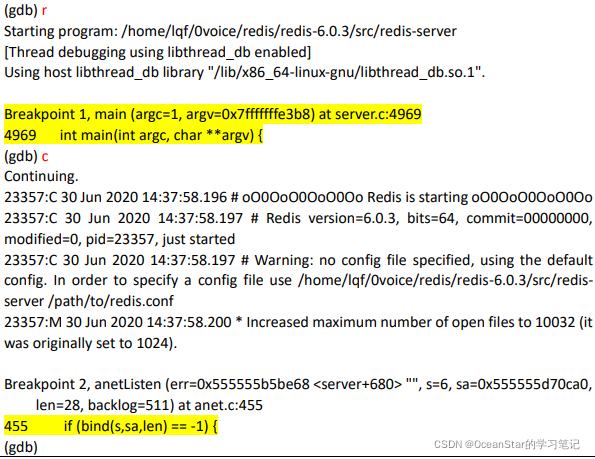
在 redis main() 函数处添加一个断点:

设置断点后重启程序

redis-server 默认端口号是 6379,绑定端口是需要调用 bind 函数,通过文件搜索可以找到相应位置文件,在 anet.c 455 行。
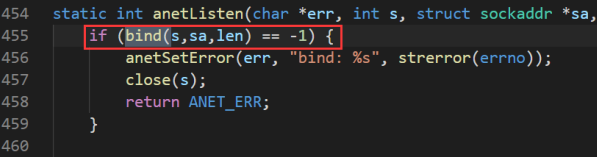
使用 break 命令在这个地方加一个断点:

由于程序绑定端口号是 redis-server 启动时初始化的,为了能触发这个断点,再次使用 run 命令重启下这个程序,GDB 第一次会触发 main() 函数处的断点,输入continue 命令继续运行,接着触发 anet.c:455 处的断点:
anet.c:455 对应的代码:
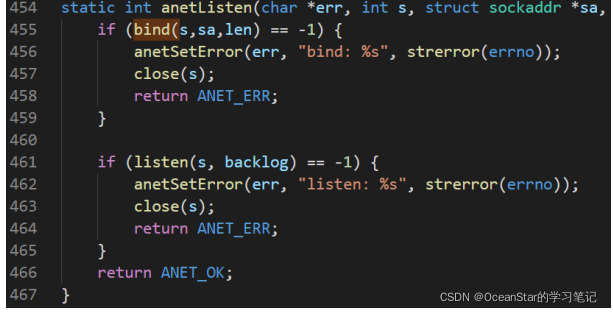
现在断点停在第 455 行,所以当前文件就是 anet.c,可以直接使用“break 行号”添加断点。例如,可以在第 458 行、464 行、466 行分别加一个断点,看看这个函数执行完毕后走哪个 return 语句退出,则可以执行:

添加好这三个断点以后,我们使用 continue 命令继续运行程序,发现程序运行到第 466 行中断下来(即触发 Breakpoint 5):
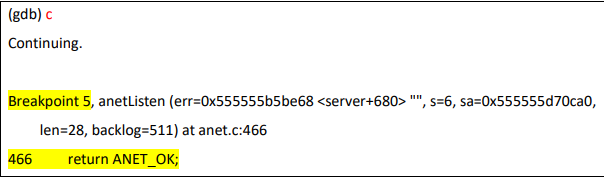
说明 redis-server 绑定端口号并设置侦听(listen)成功,我们可以再打开一个 SSH 窗口,验证一下,发现 6379 端口确实已经处于侦听状态了。

backtrace 与 frame 命令
backtrace 命令(简写为 bt)用来查看当前调用堆栈。接上,redis-server 现在中断在 anet.c:466 行,可以通过 backtrace 命令来查看当前的调用堆栈:
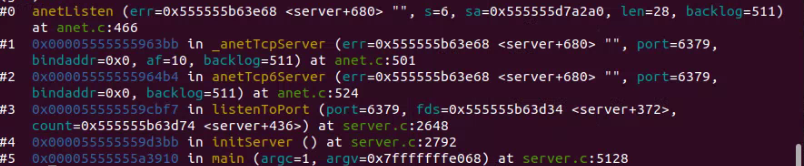
这里一共有 6 层堆栈,最顶层是 main() 函数,最底层是断点所在的 anetListen() 函数,堆栈编号分别是 #0 ~ #5 ,如果想切换到其他堆栈处,可以使用 frame 命令(简写为 f),该命令的使用方法是“frame 堆栈编号(编号不加 #)”。在这里依次切换至堆栈顶部,然后再切换回 #0 练习一下:
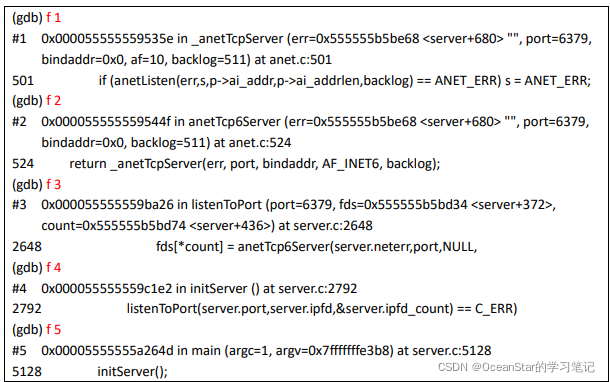
info break、enable、disable 和 delete 命令
在程序中加了很多断点,而我们想查看加了哪些断点时,可以使用 info break 命令(简写为 info b)
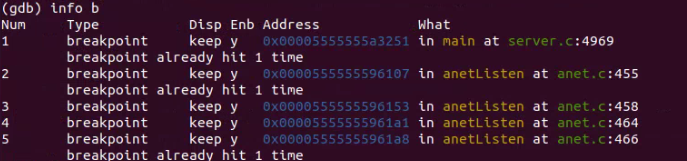
通过上面的内容片段可以知道,目前一共增加了 5 个断点,相应的断点信息比如每个断点的位置(所在的文件和行号)、内存地址、断点启用和禁用状态信息也一目了然。如果我们想禁用某个断点,使用“ disable 断点编号”就可以禁用这个断点了,被禁用的断点不会再被触发;同理,被禁用的断点也可以使用“ enable 断点编号”重新启用。
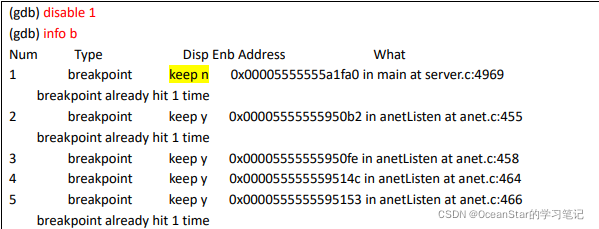
使用 disable 1 以后,第一个断点的 Enb 一栏的值由 y 变成 n,重启程序也不会再次触发
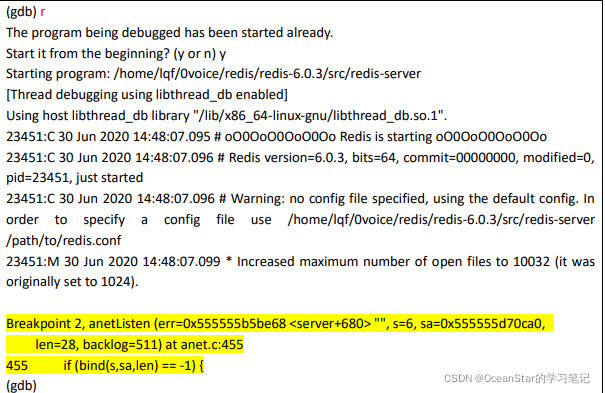
如果 disable 命令和 enable 命令不加断点编号,则分别表示禁用和启用所有断点:
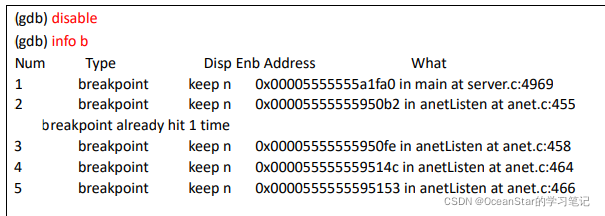
使用“delete 编号”可以删除某个断点,如 delete 2 3 则表示要删除的断点 2 和断点 3:
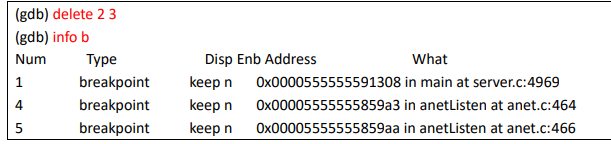
同样的道理,如果输入 delete 不加命令号,则表示删除所有断点。
list 命令
(gdb) list
- 如果不带任何参数的话,该命令会接着打印上次 list 命令打印出代码后面的代码。
- 如果是第一次执行 list 命令则会显示当前正在执行代码位置附近的代码。
(gdb) list -
- 如果参数是一个减号的话,则和前面刚好相反,会打印上次 list 命令打印出代码前面的代码。
(gdb) list LOATION
- list 命令还可以带一个代码位置作为参数,顾名思义,这样的话就会打印出该代码位置附近的代码。
- 这个代码位置的定义和在 break 命令中定义的相同,可以是一个行号:
(gdb) list 100
- 列出当前代码文件中第 100 行附近代码
(gdb) list tcpdump.c:450
- 列出 tcpdump.c 文件中第 450 行附近代码
(gdb) list main
- 列出当前代码文件中 main 函数附近代码
(gdb) list inet.c:pcap_lookupdev
- 列出 inet.c 代码文件中指定函数附近代码
(gdb) list FIRST,LAST
- 这里 FIRST 和 LAST 都是具体的代码位置,此时该命令将显示 FIRST 到 LAST 之间的代码。
- 可以不指定 FIRST 或者 LAST 参数,这样的话就将显示 LAST 之前或者 FIRST 之后的代码。
- 注意,即使只指定一个参数也要带逗号,否则就编程前面的命令,显示代码位置附近的代码了。
(gdb) set listsize COUNT
- list 命令默认只会打印出 10 行源代码,如果觉得不够,可以使用这个命令修改:
(gdb) show listsize
- 如果想查看listsize参数当前被设置成多少
(gdb) info functions
- 如果你想看程序中一共定义了哪些函数,可以使用 info functions
- 这个命令会显示程序中所有函数的名词,参数格式,返回值类型以及函数处于哪个代码文件中。
常用方法:
- list 命令(简写为 l)可以查看当前断点处的代码
- 再次输入 list 命令试一下,则往后查阅代码
- 继续输入 list 指令会以递增行号的形式继续显示剩下的代码行,一直到文件结束为止。当然 list 指令还可以往前和往后显示代码,命令分别是“list + (加号)”和“list -(减号)”, 比如 list +20 和 list -20
通过 print 命令(简写为 p)我们可以在调试过程中方便地查看变量的值,也可以修改当前内存中的变量值。切换当前断点到堆栈 #4 ,然后打印以下三个变量。
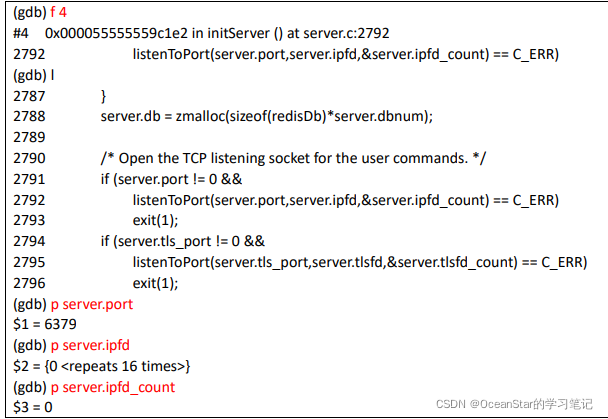
这里使用 print 命令分别打印出 server.port 、server.ipfd 、server.ipfd_count 的值,其中 server.ipfd 显示 “{0 <repeats 16 times>}”,这是 GDB 显示字符串或字符数据特有的方式,当一个字符串变量或者字符数组或者连续的内存值重复若干次,GDB 就会以这种模式来显示以节约空间。
print 命令不仅可以显示变量值,也可以显示进行一定运算的表达式计算结果值,甚至可以显示一些函数的执行结果值。举个例子:
- 我们可以输入
p &server.port来输出 server.port 的地址值 - 如果在 C++ 对象中,可以通过
p this来显示当前对象的地址,也可以通过p *this来列出当前对象的各个成员变量值 - 如果有三个变量可以相加( 假设变量名分别叫 a、b、c ),可以使用 p a + b + c 来打印这三个变量的结果值
假设 func() 是一个可以执行的函数,p func() 命令可以输出该变量的执行结果。举一个最常用的例子,某个时刻,某个系统函数执行失败了,通过系统变量 errno 得到一个错误码,则可以使用p strerror(errno)将这个错误码对应的文字信息打印出来,这样就不用费劲地去 man 手册上查找这个错误码对应的错误含义了。
print 命令不仅可以输出表达式结果,同时也可以修改变量的值,我们尝试将上文中的端口号从 6379 改成 6400 试试:

总结起来,利用 print 命令,我们不仅可以查看程序运行过程中的各个变量的状态值,也可以通过临时修改变量的值来控制程序的行为。
ptype
ptype ,顾名思义,其含义是“print type”,就是输出一个变量的类型。例如,我们试着输出 Redis 堆栈 #4 的变量 server 和变量 server.port 的类型:

可以看到,对于一个复合数据类型的变量,ptype 不仅列出了这个变量的类型( 这里是一个名叫 redisServer 的结构体),而且详细地列出了每个成员变量的字段名,方便我们去查看每个变量的类型定义。
info 和 thread 命令
info 命令是一个复合指令,可以用来查看当前进程的所有线程运行情况。
我们先使用 delete 命令删掉所有断点,然后使用 run 命令重启一下 redis-server,等程序正常启动后,我们按快捷键 Ctrl+C 中断程序,然后使用 info thread 命令来查看当前进程有哪些线程,分别中断在何处:
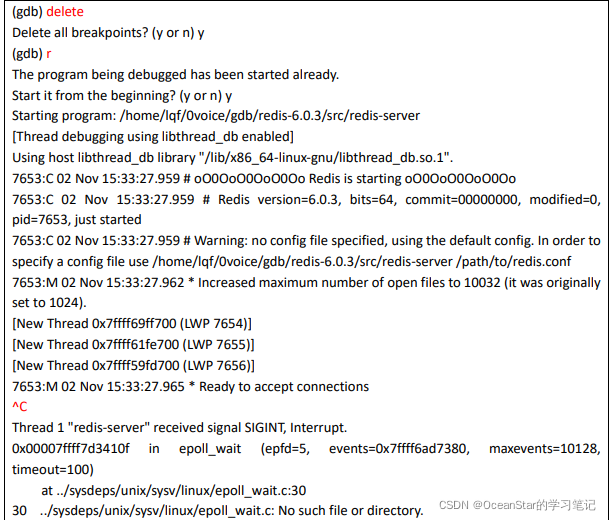
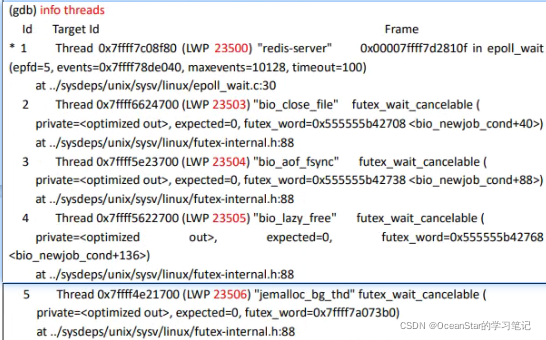
-
通过 info thread 的输出可以知道 redis-server 正常启动后,一共产生了 5 个线程,包括一个主线程和四个工作线程,线程编号(Id 那一列)分别是 5、4、3、2、1。
-
注意 虽然第一栏的名称叫 Id,但第一栏的数值不是线程的 Id,第三栏括号里的内容(如 LWP 23500)中,23500 这样的数值才是当前线程真正的 Id。Light Weight Process(轻量级进程),即是我们所说的线程。
怎么知道线程哪个线程是主线程?
- 现在有 5 个线程,也就有 5 个调用堆栈,如果此时输入 backtrace 命令查看调用堆栈,由于当前 GDB 作用在线程 1,因此 backtrace 命令显示的一定是线程 1 的调用堆栈:

如何切换到其他线程呢?
- 可以通过“thread 线程编号”切换到具体的线程上去。例如,想切换到线程 2 上去,只要输入 thread 2 即可,然后输入 bt 就能查看这个线程的调用堆栈了:

- 当前作用的线程切换到线程 2 上之后,线程 2 前面就被加上了星号

info 命令还可以用来查看当前函数的参数值,组合命令是 info args,我们找个函数值多一点的堆栈函数来试一下:

上述代码片段切回至主线程 1,然后切换到堆栈 #2,堆栈 #2 调用处的函数是aeProcessEvents() ,一共有两个参数,使用 info args 命令可以输出当前两个函数参数的值,参数 eventLoop 是一个指针类型的参数,对于指针类型的参数,GDB 默认会输出该变量的指针地址值,如果想输出该指针指向对象的值,在变量名前面加上 * 解引用即可,这里使用 p *eventLoop 命令:

如果还要查看其成员值,继续使用 变量名 ->字段名 即可
next、step、until、finish、return 和 jump 命令
这几个命令是 GDB 调试程序时最常用的几个控制流命令,因此放在一起介绍
next
next 命令(简写为 n)是让 GDB 调到下一条命令去执行,这里的下一条命令不一定是代码的下一行,而是根据程序逻辑跳转到相应的位置。
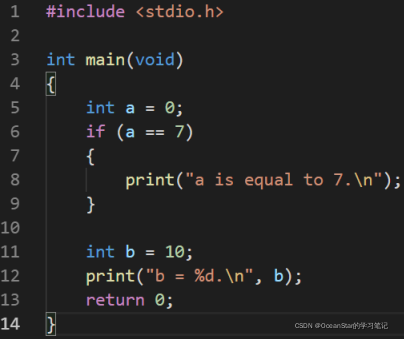
如果当前 GDB 中断在上述代码第 6 行,此时输入 next 命令 GDB 将调到第 11 行,因为这里的 if 条件并不满足。这里有一个小技巧,在 GDB 命令行界面如果直接按下回车键,默认是将最近一条
命令重新执行一遍,因此,当使用 next 命令单步调试时,不必反复输入 n 命令,直接回车就可以了。
step
next 命令用调试的术语叫“单步步过”(step over),即遇到函数调用直接跳过,不进入函数体内部。而下面的 step 命令(简写为 s)就是“单步步入”(step into),顾名思义,就是遇到函数调用,进入函数内部。
以redis为例,使用 b main 命令在 main() 处加一个断点,然后使用 r 命令重新跑一下程序,会触发刚才加在 main() 函数处的断点,然后使用 n 命令让程序走到 spt_init(argc, argv) 函数调用处,再输入 s 命令就可以进入该函数了:
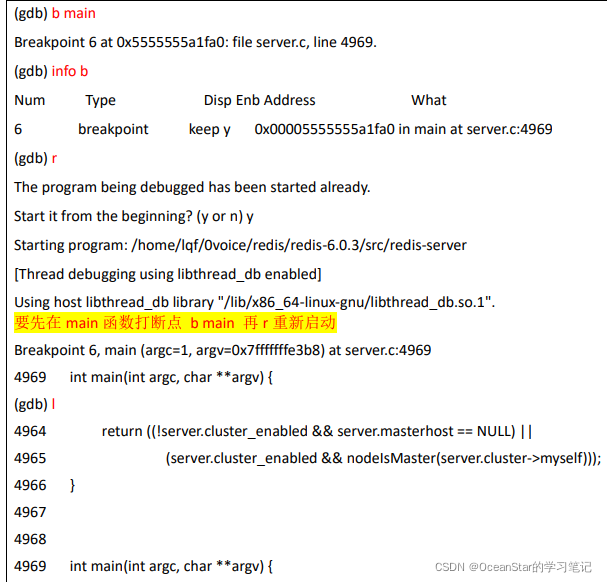
return 和 finish 命令
- 实际调试时,我们在某个函数中调试一段时间后,不需要再一步步执行到函数返回处,希望直接执行完当前函数并回到上一层调用处,就可以使用 finish 命令。与 finish 命令类似的还有 return 命令,return 命令的作用是结束执行当前函数,还可以指定该函数的返回值。
- 这里需要注意一下二者的区别:finish 命令会执行函数到正常退出该函数;而 return 命令是立即结束执行当前函数并返回,也就是说,如果当前函数还有剩余的代码未执行完毕,也不会执行了。
until 命令
实际调试时,还有一个 until 命令(简写为 u)可以指定程序运行到某一行停下来,还是以 redis-server 的代码为例
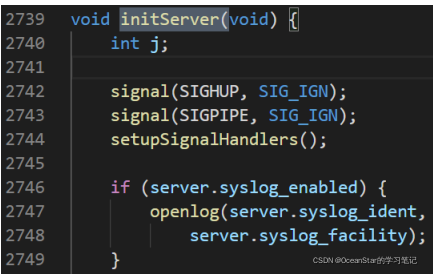
这是 redis-server 代码中 initServer() 函数的一个代码片段,位于文件 server.c 中,当停在第 2742 行,想直接跳到第 2746 行,可以直接输入 u 2746,这样就能快速执行完中间的代码。当然,也可以先在第 2746 行加一个断点,然后使用 continue 命令运行到这一行,但是使用 until 命令会更简便。
Jump 命令
jump 命令基本用法是:jump <location>,该命令会带一个参数,即要跳转到的代码位置,可以是源代码的行号:
- (gdb)
jump 555#跳转到源代码的第 555 行的位置
可以是相对当前代码位置的偏移量:
- (gdb)
jump +10#跳转到距当前代码下 10 行的位置
也可以是代码所处的内存地址:
(gdb) jump *0x12345678#跳转到位于该地址的代码
注意,在内存地址前面要加“*”。还有,jump 命令不会改变当前程序调用栈的内容,所以当你从一个函数跳到另一个函数时,当函数运行完返回进行退栈操作时就会发生错误,因此最好还是在同一个函数中进行跳转。
location 可以是程序的行号或者函数的地址,jump 会让程序执行流跳转到指定位置执行,当然其行为也是不可控制的,例如您跳过了某个对象的初始化代码,直接执行操作该对象的代码,那么可能会导致程序崩溃或其他意外行为。jump 命令可以简写成j,但是不可以简写成 jmp,其使用有一个注意事项,即如果 jump 跳转到的位置后续没有断点,那么 GDB 会执行完跳转处的代码会继续执行。举个例子:

假设我们的断点初始位置在行号 3 处(代码 A),这个时候我们使用 jump 6,那么程序会跳过代码 B 和 C 的执行,执行完代码 D( 跳转点),程序并不会停在代码 6 处,而是继续执行后续代码,因此如果我们想查看执行跳转处的代码后的结果,需要在行号6、7 或 8 处设置断点。
有时候也可以用来测试一些我们想要执行的代码(正常逻辑不太可能跑到),比如
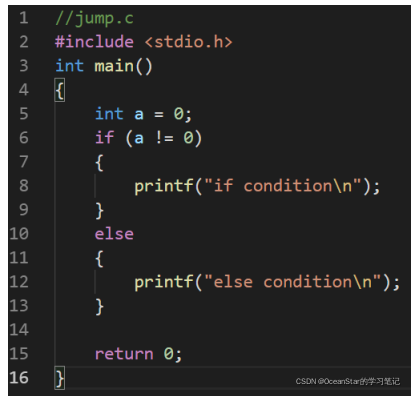
我们想执行 12 行的代码。
则
b main
jump 12
就会将 else 分支执行。
disassemble 命令
当进行一些高级调试时,我们可能需要查看某段代码的汇编指令去排查问题,或者是在调试一些没有调试信息的发布版程序时,也只能通过反汇编代码去定位问题,那么disassemble 命令就派上用场了。

set args 和 show args 命令
很多程序需要我们传递命令行参数。在 GDB 调试中,很多人会觉得可以使用 gdb filename args 这种形式来给 GDB 调试的程序传递命令行参数,这样是不行的。正确的做法是在用 GDB 附加程序后,在使用 run 命令之前,使用“set args 参数内容”来设置命令行参数。
还是以 redis-server 为例,Redis 启动时可以指定一个命令行参数,它的默认配置文件位于 redis-server 这个文件的上一层目录,因此我们可以在 GDB 中这样传递这个参数:set args …/redis.conf(即文件 redis.conf 位于当前程序 redis-server 的上一层目录),可以通过 show args 查看命令行参数是否设置成功。

如果单个命令行参数之间含有空格,可以使用引号将参数包裹起来。

如果想清除掉已经设置好的命令行参数,使用 set args 不加任何参数即可。


tbreak 命令
tbreak 命令也是添加一个断点,第一个字母“t”的意思是 temporarily(临时的),也就是说这个命令加的断点是临时的,所谓临时断点,就是一旦该断点触发一次后就会自动删除。添加断点的方法与上面介绍的 break 命令一模一样,这里不再赘述。这里文档就不再描述,大家自行测试即可。
watch 命令
watch 命令是一个强大的命令,它可以用来监视一个变量或者一段内存,当这个变量或者该内存处的值发生变化时,GDB 就会中断下来。被监视的某个变量或者某个内存地址会产生一个 watch point(观察点)。
watch 命令的使用方式是“watch 变量名或内存地址”,一般有以下几种形式:
(1) 形式一:整型变量
int i;
watch i
(2) 形式二:指针类型
char *p;
watch p 与 watch *p
注意:
- watch p 与
watch *p是有区别的,前者是查看*(&p),是 p 变量本身;后者是 p 所指内存的内容 - 我们需要查看地址,因为目的是要看某内存地址上的数据是怎样变化的。
(3)形式三:watch 一个数组或内存区间
char buf[128];
watch buf
- 这里是对 buf 的 128 个数据进行了监视,此时不是采用硬件断点,而是用软中断实现的。
- 用软中断方式去检查内存变量是比较耗费 CPU 资源的,精确地指明地址是硬件中断
注意:当设置的观察点是一个局部变量时,局部变量无效后,观察点也会失效。在观察点失效时 GDB 可能会提示如下信息:
Watchpoint 2 deleted because the program has left the block in which its expression isvalid
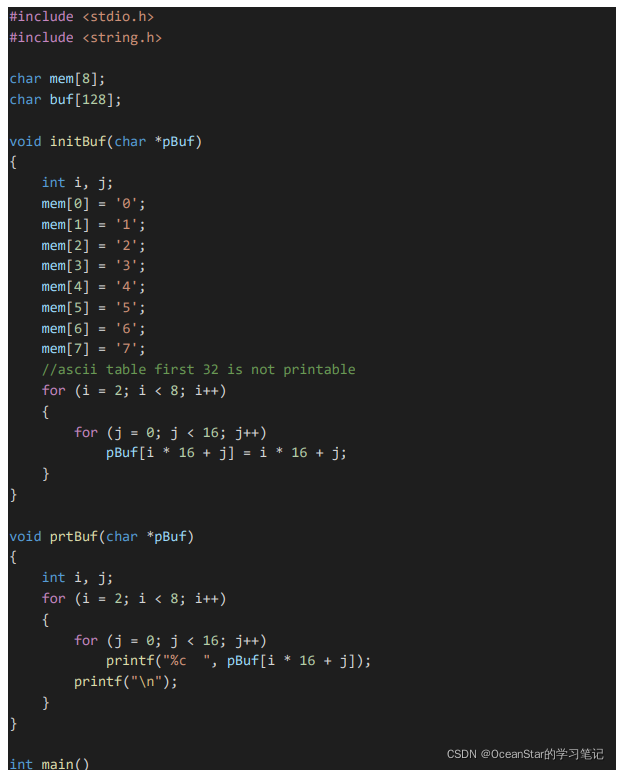

测试:
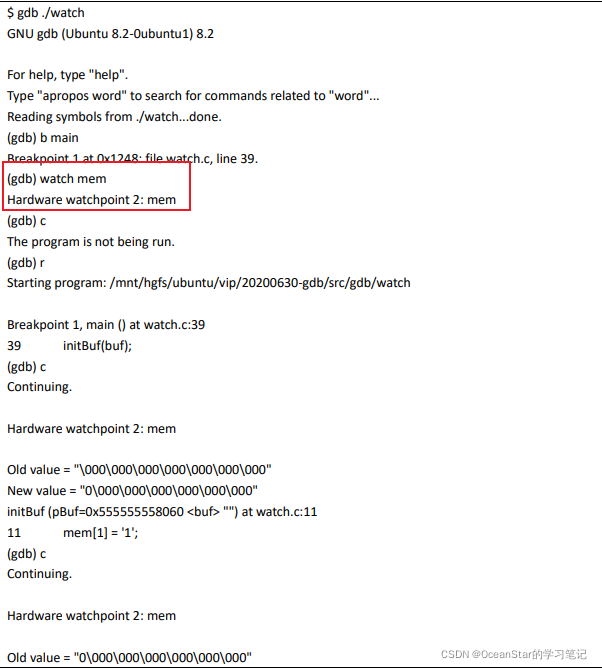
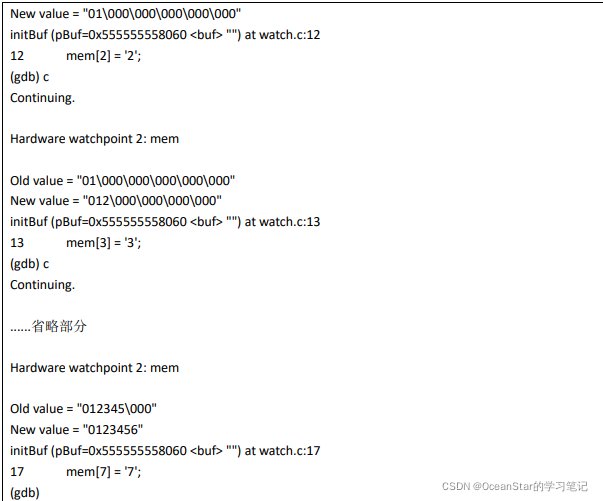
watch i 的问题:是可以同时去 watch,只是局部变量需要进入到相应的起作用范围才能 watch。比如 initBuf 函数的 i。
问题来了,如果要取消 watch 怎么办?
先用 info watch 查看 watch 的变量,然后根据编号使用 delete 删除相应的 watch 变量。

display
display 命令监视的变量或者内存地址,每次程序中断下来都会自动输出这些变量或内存的值。例如,假设程序有一些全局变量,每次断点停下来我都希望 GDB 可以自动输出这些变量的最新值,那么使用“display 变量名”设置即可。

上述代码中,使用 display 命令分别添加了寄存器 ebp 和寄存器 eax,ebp 寄存器分别使用十进制和十六进制两种形式输出其值,这样每次程序中断下来都会自动把这些值打印出来,可以使用 info display 查看当前已经自动添加了哪些值,使用 delete display 清除全部需要自动输出的变量,使用 delete diaplay 编号 删除某个自动输出的变量。

调试技巧
将 print 打印结果显示完整
当使用 print 命令打印一个字符串或者字符数组时,如果该字符串太长,print 命令默认显示不全的,我们可以通过在 GDB 中输入 set print element 0 命令设置一下,这样再次使用 print 命令就能完整地显示该变量的所有字符串了。
多线程下禁止线程切换
假设现在有 5 个线程,除了主线程,工作线程都是下面这样的一个函数:

为了能说清楚这个问题,我们把四个工作线程分别叫做 A、B、C、D。
假设 GDB 当前正在处于线程 A 的代码行 3 处,此时输入 next 命令,我们期望的是调试器跳到代码行 4 处;或者使用“u 代码行 10”,那么我们期望输入 u 命令后调试器可以跳转到代码行 10 处。
但是在实际情况下,GDB 可能会跳转到代码行 1 或者代码行 2 处,甚至代码行13、代码行 14 这样的地方也是有可能的,这不是调试器 bug,这是多线程程序的特点,当我们从代码行 4 处让程序 continue 时,线程 A 虽然会继续往下执行,但是如果此时系统的线程调度将 CPU 时间片切换到线程 B、C 或者 D 呢?那么程序最终停下来的时候,处于代码行 1 或者代码行 2 或者其他地方就不奇怪了,而此时打印相关的变量值,可能就不是我们需要的线程 A 的相关值。
为了解决调试多线程程序时出现的这种问题,GDB 提供了一个在调试时将程序执行流锁定在当前调试线程的命令:set scheduler-locking on。当然也可以关闭这一选项,使用 set scheduler-locking off。除了 on/off 这两个值选项,还有一个不太常用的值叫 step,这里就不介绍了。
条件断点
在实际调试中,我们一般会用到三种断点:普通断点、条件断点和硬件断点。
硬件断点又叫数据断点,这样的断点其实就是前面课程中介绍的用watch命令添加的部分断点(为什么是部分而不是全部,前面介绍原因了,watch 添加的断点有部分是通过软中断实现的,不属于硬件断点)。硬件断点的触发时机是监视的内存地址或者变量值发生变化。
普通断点就是除去条件断点和硬件断点以外的断点。
下面重点来介绍一下条件断点,所谓条件断点,就是满足某个条件才会触发的断点,这里先举一个直观的例子:
void do_something_func(int i)
{
i ++;
i = 100 * i;
}
int main()
{
for(int i = 0; i < 10000; ++i)
{
do_something_func(i);
}
return 0;
}
在上述代码中,假如我们希望当变量 i=5000 时,进入 do_something_func() 函数追踪一下这个函数的执行细节。此时可以修改代码增加一个 i=5000 的 if 条件,然后重新编译链接调试,这样显然比较麻烦,尤其是对于一些大型项目,每次重新编译链接都需要花一定的时间,而且调试完了还得把程序修改回来。
有了条件断点就不需要这么麻烦了,添加条件断点的命令是 break [lineNo] if [condition],其中 lineNo 是程序触发断点后需要停下的位置,condition 是断点触发的条件。这里可以写成 break 11 if i==5000,其中,11 就是调用 do_something_fun() 函数所在的行号。当然这里的行号必须是合理行号,如果行号非法或者行号位置不合理也不会触发这个断点。
(gdb) break 11 if i==5000
Breakpoint 2 at 0x400514: file test1.c, line 10.
(gdb) r
The program being debugged has been started already.
Start it from the beginning? (y or n) y
Starting program: /root/testgdb/test1
Breakpoint 1, main () at test1.c:9
9 for(int i = 0; i < 10000; ++i)
(gdb) c
Continuing.
Breakpoint 2, main () at test1.c:11
11 do_something_func(i);
(gdb) p i
$1 = 5000
把 i 打印出来,GDB 确实是在 i=5000 时停下来了。
添加条件断点还有一个方法就是先添加一个普通断点,然后使用“condition 断点编号断点触发条件”这样的方式来添加。添加一下上述断点:
(gdb) b 11
Breakpoint 1 at 0x400514: file test1.c, line 11.
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000400514 in main at test1.c:11
(gdb) condition 1 i==5000
(gdb) r
Starting program: /root/testgdb/test1
y
Breakpoint 1, main () at test1.c:11
11 do_something_func(i);
Missing separate debuginfos, use: debuginfo-install glibc-2.17-196.el7_4.2.x86_64
(gdb) p i
$1 = 5000
(gdb)
使用 GDB 调试多进程程序
这里说的多进程程序指的是一个进程使用 Linux 系统调用 fork() 函数产生的子进程,没有相互关联的进程就是普通的 GDB 调试,不必刻意讨论。
在实际的应用中,如有这样一类程序,如 Nginx,对于客户端的连接是采用多进程模型,当 Nginx 接受客户端连接后,创建一个新的进程来处理这一路连接上的信息来往,新产生的进程与原进程互为父子关系,那么如何用 GDB 调试这样的父子进程呢?一般有两种方法:
(1)用 GDB 先调试父进程,等子进程 fork 出来后,使用 gdb attach 到子进程上去,当然这需要重新开启一个 session 窗口用于调试,gdb attach 的用法在前面已经介绍过了
(2)GDB 调试器提供了一个选项叫 follow-fork,可以使用 show follow-fork mode 查看当前值,也可以通过 set follow-fork mode 来设置是当一个进程 fork 出新的子进程时,GDB 是继续调试父进程还是子进程(取值是 child),默认是父进程( 取值是 parent)。
(gdb) show follow-fork mode
Debugger response to a program call of fork or vfork is "parent".
(gdb) set follow-fork child
(gdb) show follow-fork mode
Debugger response to a program call of fork or vfork is "child".
(gdb)
问题
解决gdb调试过程中打印时出现optimized out问题
用gdb调试时想打印变量值,结果出现了optimized out,打印不出变量内容,后来找到解决方案,将makefile中的编译命令中-O3优化改为-O0取消优化即可