��֪ʶ����Դ�ڸò����������
֪ʶ����Դ������,֪���Ŀ�����������������Դ�
��ɢ֪ʶ���ܽ�2
- MySQL
- sql�������:
- MySQL �����ļ�����?
- MySQL ������Щ��ͬ�ı���?
- ������ MySQL ���ݿ��� MyISAM �� InnoDB ������
- char �� varchar ������?
- �����ͺ�ѡ����ʲô����?
- ���һ������һ�ж���Ϊ TIMESTAMP,������ʲô?
- ��ô����Ϊ���������������?
- �жԱ��������ʲô?
- BLOB �� TEXT ��ʲô����?
- MySQL ����Ż� DISTINCT?
- �����ʾǰ 50 ��?
- ����ʹ�ö����д�������?
- NOW()�� CURRENT_DATE()��ʲô����?
- ʲô�ǷDZ��ַ�������?
- ʲô��ͨ�� SQL ����?
- MySQL ֧��������?
- MySQL ���¼������ʲô�ֶ����ͺ�?
- sqlyog�ǹ��������ݿ�?
- MySQL��Oracle ����?
- Double��decimal��float������?
- ���������������Լ�ȫ���ӵ�����?
- MySQL �й�Ȩ�ı������ļ���?
- �е��ַ������Ϳ�����ʲô?
- MySQL ���ݿ�������ϵͳ�Ĵ洢,һ�����������ϵ�����,Ԥ����ά����,��ô�Ż�?
- �����Ż�����
- �����ĵײ�ʵ��ԭ�����Ż�
- ʲô�������������������ʹ��
- �Ż����ݿ�ķ���
- ������ MySQL ��,����,����,Ψһ����,��������������,�����ݿ��������ʲôӰ��(�Ӷ�д������)
- ���ݿ��е�������ʲô?
- SQL ע��©��������ԭ��?��η�ֹ?
- Ϊ���е��ֶ�ѡ����ʵ���������
- �洢ʱ��
- ���ڹ�ϵ�����ݿ����,�������൱��Ҫ�ĸ���,��ش��й������ļ�������:
- Myql �е�����ع����Ƹ���
- SQL �������ļ�����?ÿ���ֶ�����Щ�����ؼ���?
- ������Լ��������Щ?
- ʲô����?
- ʲô����ͼ?�α���ʲô?
- ʲô�Ǵ洢����?��ʲô������?
- ���ͨ������������ʽ?
- ʲô�ǻ�����?ʲô����ͼ?
- ������ͼ���ŵ�?
- NULL ��ʲô��˼
- ���������������������?
- �������ʲô��ȷ����������ֶ�ֻ�����ض���Χ���ֵ?
- ˵˵�� SQL ����Ż�����Щ����?(ѡ����)
- Java�������(һ)
- �� java ���ػ��̺߳ͱ����߳�����?
- �߳�����̵�����?
- ʲô�Ƕ��߳��е��������л�?
- ���������������,�����뼢��������?
- Java ���õ����̵߳����㷨��ʲô?
- ʲô���߳���,Ϊʲô�� Java �в��Ƽ�ʹ��?
- Ϊʲôʹ�� Executor ���?
- �� Java �� Executor �� Executors ������?
- ����� Windows �� Linux �ϲ����ĸ��߳�ʹ�õ� CPU ʱ���?
- ʲô��ԭ�Ӳ���?�� Java Concurrency API ������Щԭ����(atomic classes)?
- Java Concurrency API �е� Lock �ӿ�(Lock interface)��ʲô?
- ʲô�� Executors ���?
- ʲô����������?�������е�ʵ��ԭ����ʲô?���ʹ������������ʵ��������-������ģ��?
- ʲô�� Callable �� Future?
- ʲô�� FutureTask?ʹ�� ExecutorService ��������
- ʲô�Dz���������ʵ��?
- ���߳�ͬ���ͻ����м���ʵ�ַ���,����ʲô?
- ʲô�Ǿ�������?���������ֺͽ������?
- �㽫���ʹ�� thread dump?�㽫��η��� Thread dump?
- Ϊʲô���ǵ��� start()����ʱ��ִ�� run()����,Ϊʲô���Dz���ֱ�ӵ��� run()����?
- Java ������������һ���������߳�?
- ʲô�Dz��ɱ����,����д����Ӧ����ʲô����?
- ʲô�Ƕ��߳��е��������л�
- Java ���õ����̵߳����㷨��ʲô?
- ʲô���߳���,Ϊʲô�� Java �в��Ƽ�ʹ��?
- Ϊʲôʹ�� Executor ��ܱ�ʹ��Ӧ�ô��������̺߳�?
- java ���м��ַ�������ʵ��һ���߳�?
- ���ֹͣһ���������е��߳�?
- notify()�� notifyAll()��ʲô����?
- ʲô�� Daemon �߳�?����ʲô����?
- java ���ʵ�ֶ��߳�֮���ͨѶ��Э��?
- ʲô�ǿ�������(ReentrantLock)?
- ��һ���߳̽���ij�������һ�� synchronized ��ʵ��������,�����߳��Ƿ�ɽ���˶������������?
- �ֹ����ͱ����������⼰���ʵ��,����Щʵ�ַ�ʽ?
- SynchronizedMap �� ConcurrentHashMap ��ʲô����?
- CopyOnWriteArrayList ��������ʲôӦ�ó���?
- ʲô���̰߳�ȫ?servlet ���̰߳�ȫ��?
- volatile ��ʲô��?�ܷ���һ�仰˵���� volatile ��Ӧ�ó���?
- Ϊʲô�����������?
- �� java �� wait �� sleep �����IJ�ͬ?
- �� Java ʵ����������
- һ���߳�����ʱ�����쳣������?
- ����������̼߳乲������?
- Ϊʲô wait, notify �� notifyAll ��Щ�������� thread ������?
- ʲô�� ThreadLocal ����?
- Java �� interrupted �� isInterrupted ����������?
- Ϊʲô wait �� notify ����Ҫ��ͬ�����е���?
- Ϊʲô��Ӧ����ѭ���м��ȴ�����?
- Java �е�ͬ�������벢��������ʲô����?
- �������ַ�ʽ��ʵ�ּ��ϵ�����?
- Java ����ô��ӡ����?
- Java �е� LinkedList �ǵ�����������˫������?
- Java �е� TreeMap �Dz���ʲô��ʵ�ֵ�?
- Hashtable �� HashMap ��ʲô��֮ͬ��?
- ʲô���̳߳�? ΪʲôҪʹ����?
- ��ô���һ���߳��Ƿ�ӵ����?
- ������� Java �л�ȡ�̶߳�ջ?
- Thread ���е� yield ������ʲô����?
- Java �� ConcurrentHashMap �IJ�������ʲô?
- Java �� Semaphore ��ʲô?
- Java �̳߳��� submit() �� execute()������ʲô����?
- ʲô������ʽ����?
- Java �е� ReadWriteLock ��ʲô?
- volatile ������ atomic ������ʲô��ͬ?
- ����ֱ�ӵ��� Thread ��� run ()����ô?
- ������������е��߳���ͣһ��ʱ��?
- ����߳����ȼ���������ʲô?
- ʲ ô �� �� �� �� �� �� (Thread Scheduler) �� ʱ �� �� Ƭ (TimeSlicing )?
- �����ȷ�� main()�������ڵ��߳��� Java �������������߳�?
- �߳�֮�������ͨ�ŵ�?
- Ϊʲô�߳�ͨ�ŵķ��� wait(), notify()�� notifyAll()��������Object ����?
- Ϊʲô wait(), notify()�� notifyAll ()������ͬ����������ͬ�����б�����?
- Ϊʲô Thread ��� sleep()�� yield ()�����Ǿ�̬��?
- ���ȷ���̰߳�ȫ?
- ͬ��������ͬ����,�ĸ��Ǹ��õ�ѡ��?
- ��δ����ػ��߳�?
- ʲô�� Java Timer ��?��δ���һ�����ض�ʱ����������?
- Java�������(��)
- ���������Ҫ��?
- ʵ�ֿɼ��Եķ�������Щ?
- ���̵߳ļ�ֵ?
- �����̵߳ķ�ʽ����Щ?
- �����̵߳����ַ�ʽ�Ա�
- �߳�״̬��תͼ
- Java �߳̾������л���״̬
- ʲô���̳߳�?���ļ��ִ�����ʽ?
- �����̳߳صĴ���:
- �̳߳ص��ŵ�?
- ���õIJ�������������Щ?
- synchronized ������?
- volatile �ؼ��ֵ�����
- ʲô�� CAS
- CAS ������
- ʲô�� Future?
- ʲô�� AQS
- AQS ֧������ͬ����ʽ:
- ReadWriteLock ��ʲô
- FutureTask ��ʲô
- synchronized �� ReentrantLock ������
- ʲô���ֹ����ͱ�����
- �߳� B ��ô֪���߳� A ���˱���
- synchronized��volatile��CAS �Ƚ�
- sleep ������ wait ������ʲô����?
- ThreadLocal ��ʲô?��ʲô��?
- Ϊʲô wait()������ notify()/notifyAll()����Ҫ��ͬ�����б�����
- ���߳�ͬ�����ļ��ַ���?
- �̵߳ĵ��Ȳ���
- ConcurrentHashMap �IJ�������ʲô
- Linux ��������β����ĸ��߳�ʹ�� CPU �
- Java �����Լ���α���?
- ������ԭ��
- ��ô����һ���������߳�
- ���ɱ����Զ��߳���ʲô����
- ʲô�Ƕ��̵߳��������л�
- ������ύ����ʱ,�̳߳ض�������,��ʱ�ᷢ��ʲô
- Java ���õ����̵߳����㷨��ʲô
- ʲô���̵߳�����(Thread Scheduler)��ʱ���Ƭ(TimeSlicing)?
- ʲô������
- Java Concurrency API �е� Lock �ӿ�(Lock interface)��ʲô?�Ա�ͬ������ʲô����?
- ����ģʽ���̰߳�ȫ��
- ͬ��������ͬ����,�ĸ��Ǹ��õ�ѡ��?
- Java �߳�����������ʲô�쳣?
- dz̸Java SE��Java EE��Java ME���ߵ�����
- Java
- ��a==b���͡�a.equals(b)����ʲô����?
- ��������������������?
- �������η� public,private,protected,�Լ���д(Ĭ��)ʱ������?
- String �������������������?
- float f=3.4;�Ƿ���ȷ?
- short s1 = 1; s1 = s1 + 1;���?short s1 = 1; s1 += 1;���?
- int �� integer ��ʲô����?
- &��&&������?
- Math.round(11.5) ���ڶ���?Math.round(-11.5)���ڶ���?
- switch �Ƿ��������� byte ��,�Ƿ��������� long ��,�Ƿ��������� String ��?
- ������û�� length()����?String ��û�� length()����?
- �� Java ��,���������ǰ�Ķ���Ƕ��ѭ��?
- ������(constructor)�Ƿ�ɱ���дoverride?
- ����(Overload)����д(override)������?���صķ����ܷ���ݷ������ͽ�������?
- **==Ϊʲô���ܸ��ݷ�����������������?==**
- �Ƿ���Լ̳�string��?
- ������(abstract class)�ͽӿ�(interface)��ʲô��ͬ?
- ��̬Ƕ����(Static Nested Class)���ڲ���(Inner Class)�IJ�ͬ?
- Java �л�����ڴ�й©��,���������
- ������̬������ʵ������������
- �Ƿ���Դ�һ����̬(static)�����ڲ������ԷǾ�̬(non-static)�����ĵ���?
- ���ʵ�ֶ����¡?
- GC ��ʲô?ΪʲôҪ�� GC?
- String s=new String("xxc"),�����˼����ַ�������?
- ���ڽӿڡ�������;�����֮��ļ̳�(extends)��ʵ��(implements)����
- һ����.java��Դ�ļ����Ƿ�����������(�����ڲ���)?��ʲô����?
- Anonymous Inner Class(�����ڲ���)�Ƿ���Լ̳�������?�Ƿ����ʵ�ֽӿ�?
- �ڲ�������������İ�����(�ⲿ��)�ij�Ա��?��û��ʲô����?
- Java �е�final�ؼ�������Щ�÷�?
- ��������֮���ת��
- ���ʵ���ַ����ķ�ת���滻?
- ������ GB2312 ������ַ���ת��Ϊ ISO-8859-1 ������ַ���?
- ���ں�ʱ��:
- �Ƚ�Java��JavaScript
- Error �� Exception ��ʲô����?
- try{}����һ�� return ���,��ô��������� try ���finally{}��Ĵ����ᱻִ��,ʲôʱ��ִ��,�� returnǰ���Ǻ�?
- Java ������ν����쳣����,�ؼ���:throws��throw��try��catch��finally �ֱ����ʹ��?
- �г�һЩ�㳣��������ʱ�쳣?
- ���� final��finally��finalize ������
- List��Set��Map �� Queue ֮�������
- List ��Set ��Map �Ƿ�̳���Collection�ӿ�?�����ӿڴ�ȡԪ��ʱ����ʲô�ص�?
- Collection �� Collections ������?
- ����˵��ͬ�����첽��
- ����һ���߳��õ���run()����start()����?
- Java �����ʵ�����л�,��ʲô����?
- Java ���м������͵���?
- дһ������,����һ���ļ�����һ���ַ���,ͳ������ַ���������ļ��г��ֵĴ���
- ����� Java �����г�һ��Ŀ¼�����е��ļ�?
- ������Ŀ����Щ�ط��õ��� XML?
- ���� JDBC �������ݿ�IJ��衣
- ʹ�� JDBC �������ݿ�ʱ,���������ȡ���ݵ�����?��������������ݵ�����?
- �ڽ������ݿ���ʱ,���ӳ���ʲô����?
- ʲô��DAOģʽ?
- poll() ������ remove() ����������?
- ArrayList �� LinkedList �IJ�����?
- �����������ʽ������;��
- Java �������֧���������ʽ������?
- ���һ��������������Щ��ʽ?
- ����һ���������ġ���ԭ��һ����
- ****����һ�����˽�����ģʽ��
- �� Java дһ��ð������
- ð�������㷨
- �� Java дһ���۰���ҡ�(���ַ�)
- Java ��Ӧ��ʹ��ʲô���������������۸�?
- ��ô�� byte ת��Ϊ String?�� bytes ת��Ϊ long ����?
- �����ܽ� int ǿ��ת��Ϊ byte ���͵ı�����?�����ֵ���� byte ���͵ķ�Χ,�������ʲô����?
- ����������,B �̳� A,C �̳� B,�����ܽ� B ת��ΪC ô?�� C = (C) B;
- Java �� ++ ���������̰߳�ȫ����?
- �����ڲ�����ǿ��ת��������½�һ�� double ֵ��ֵ��long ���͵ı�����?
- 3*0.1 == 0.3 ���᷵��ʲô?true ���� false?
- int �� Integer �ĸ���ռ�ø�����ڴ�?
- Ϊʲô Java �е� String �Dz��ɱ��(Immutable)?
- Java �е� HashSet,�ڲ�����ι�����?
- дһ�δ����ڱ��� ArrayList ʱ�Ƴ�һ��Ԫ��?
- �������Լ�дһ��������,Ȼ��ʹ�� for-each ѭ����?
- ��û�п�����������ȵĶ���������ͬ�� hashcode?
- ���ǿ�����hashcode()��ʹ����������� ?
- Java ��,Comparator �� Comparable ��ʲô��ͬ?
- Ϊʲô����д equals ������ʱ����Ҫ��д hashCode ����?
- Java IO �� NIO
- ʲô�� Java IO ?ԭ����ʲô?
- �����������
- ͬ�����첽
- NIOģ��
- Java ������ ByteBuffer?
- TCP/IPЭ����UDPЭ����ʲô����?
- Java ��,ByteBuffer �� StringBuffer ��ʲô����?
- Java ��,��д���̳߳����ʱ�������ѭ��Щ���ʵ��?
- ˵������ Java ��ʹ�� Collections �����ʵ��
- ˵�� 5 �� IO �����ʵ��(��)
- �г� 5 ��Ӧ����ѭ�� JDBC ���ʵ��
- ˵������ Java �з������ص����ʵ��?
- JVM��GC
- 64 λ JVM ��,int �ij����Ƕ���?
- Serial �� Parallel GC ֮��IJ�֮ͬ��?
- 32 λ�� 64 λ�� JVM,int ���ͱ����ij����Ƕ���?
- Java �� WeakReference �� SoftReference ������?
- ����ͨ�� Java �������ж� JVM �� 32 λ ���� 64λ?
- 32 λ JVM �� 64 λ JVM �������ڴ�ֱ��Ƕ���?
- JRE��JDK��JVM �� JIT ֮����ʲô��ͬ?
- ���ܱ�֤ GC ִ����?
- ��ô��ȡ Java ����ʹ�õ��ڴ�?��ʹ�õİٷֱ�?
- Java �жѺ�ջ��ʲô����?
- Date��Time �� Calendar
- JUnit��Ԫ����
- ��β��Ծ�̬����?
- ��ô���� JUnit ������һ���������쳣?
- ��ʹ�ù��ĸ���Ԫ���Կ���������� Java ����?
- @Before �� @BeforeClass ��ʲô����?
- ��ô���һ���ַ���ֻ��������?
- Java ��������÷���дһ�� LRU ����?
- дһ�� Java ���� byte ת��Ϊ long?
- Java����ν��ַ���ת��Ϊ����?
- ��û��ʹ����ʱ�����������ν�����������������ֵ?
- �ӿ���ʲô?ΪʲôҪʹ�ýӿڶ�����ֱ��ʹ�þ�����?
- Java ��,��������ӿ�֮����ʲô��ͬ?
- ���ܽ���һ�������滻ԭ����?
- ʲô����»�Υ�������ط���?Ϊʲô�����������?
- ������ģʽ��ʲô?ʲôʱ��ʹ��?
- ʲô�ǡ�����ע��(IOC)���͡����Ʒ�ת(DI)��?Ϊʲô����ʹ��?
- ��������ʲô?����ӿ���ʲô����?��ΪʲôҪʹ�ù�������?
- ������ע��� setter ����ע��,���ַ�ʽ����?
- ����ע�����ģʽ֮����ʲô��ͬ?
- ������ģʽ��װ����ģʽ��ʲô����?
- ������ģʽ�ʹ���ģʽ֮ǰ��ʲô��ͬ?
- ʲô��ģ�巽��ģʽ?
- ʲôʱ��ʹ�÷�����ģʽ?
- ʲôʱ��ʹ�����ģʽ?
- �̳к����֮����ʲô��ͬ?
- ���� Java �е����غ���д?
- Java ��,Ƕ������̬���붥������ʲô��ͬ?
- OOP �е� ��ϡ��ۺϺ�����ʲô����?
- ����һ�����Ͽ���ԭ������ģʽ������?
- ����ģʽ��ԭ��ģʽ֮�������?
- ʲôʱ��ʹ����Ԫģʽ?
- Ƕ��̬���붥������ʲô����?
- ����д��һ���������ʽ���ж�һ���ַ����Ƿ���һ��������?
- Java ��,�ܼ���쳣 �� ���ܼ���쳣������?
- Java ��,throw �� throws ��ʲô����
- Java ��,Serializable �� Externalizable ������?
- Java ��,DOM �� SAX ��������ʲô��ͬ?
- ˵�� JDK 1.7 �е�����������?
- ˵�� 5 �� JDK 1.8 �����������?
- Java ��,Maven �� ANT ��ʲô����?
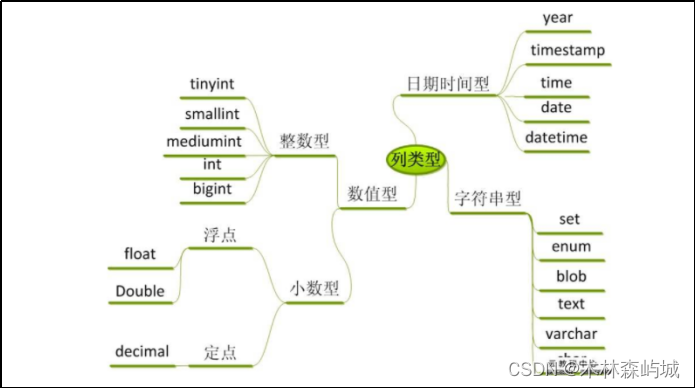
MySQL
sql�������:
4.sql�������:
4.1.������:Create table ����{
�ֶ� ���� ����(����/�Ƿ�����/�Ƿ�����Ϊ��)
//����:PRIMARY KEY ; ����:AUTO_INCREMENT ;��������:NOT NULL
}
4.2.ɾ����:delete from �� (ɾ�����ݿ��Իع�rollback)
Truncate table �� (ɾ�����ݲ����Իع�)
Drop table �� (ɾ�����ݺͱ��ṹ)
4.3.��������:insert into�� (��1,��2��)values (ֵ1,ֵ2��)
4.4.������:update �� set��1=����ֵ1,��2=����ֵ2����where ��������
4.5.ɾ������:delete from ��where ��������
4.6.��ѯ:select ��/* from ��/����ʽ where ��������/group by ��������/having ��������/order by �ֶ� ����ʽ(asc/desc)
��Having ��where ������:having���ڷ��������ݽ��й���
where���ڷ���ǰ�����ݽ��й���
having�������ʹ�þۺϺ���
where���治����ʹ�þۺ�
�ڲ�ѯ������ִ��˳��:from>where>group(���ۺ�)>having>order>select��
�ھۺ����:sum��min��max��avg��count
having�����ú�where����������,����where���ܺ;ۺϺ���(max,min,sum,avg��)һ��ʹ��,�����Ҫhaving��
Eg:select * from table having max(column_name);
4.7.ģ����ѯ:select �ֶ� from �� where���� like ��ģ����ѯ���ݡ�
��ѯ��������:���յ� like ����%��;�����ҳ���Ϊ3 �� like ����__�� ��_����ռ��һ����λ��
MySQL �����ļ�����?
1��������:����С,������;�����������;�������ȴ�,��������ͻ�ĸ������,��������͡�
2���м���:������,������;���������;����������С,��������ͻ�ĸ������,������Ҳ��ߡ�
3��ҳ����:�����ͼ���ʱ����ڱ���������֮��;���������;�������Ƚ��ڱ���������֮��,������һ�㡣
MySQL ������Щ��ͬ�ı���?
���� 5 �����͵ı���:
1��MyISAM
2��Heap
3��Merge
4��INNODB
5��ISAM
������ MySQL ���ݿ��� MyISAM �� InnoDB ������
| MyISAM | InnoDB |
|---|---|
| ��֧������,����ÿ�β�ѯ����ԭ�ӵ�; | ֧�� ACID ������,֧����������ָ��뼶��; |
| ֧�ֱ�����,��ÿ�β����Ƕ�����������; | ֧���м��������Լ��:��˿���֧��д����; |
| �洢����������; | ���洢������: |
| һ�� MYISAM ���������ļ�:�����ļ������ṹ�ļ��������ļ�; | һ�� InnoDb ����洢��һ���ļ��ռ�(�������ռ�,����С���ܲ���ϵͳ����,һ�������ֲܷ��ڶ���ļ���),Ҳ�п���Ϊ���(����Ϊ��������,����С�ܲ���ϵͳ�ļ���С����,һ��Ϊ 2G),�ܲ���ϵͳ�ļ���С������; |
| ���÷ƾۼ�����,�����ļ���������洢ָ�������ļ���ָ�롣������������������һ��,���Ǹ��������ñ�֤Ψһ�ԡ� | �����������þۼ�����(������������洢�����ļ�����),��������������洢������ֵ;��˴Ӹ�������������,��Ҫ��ͨ���������ҵ�����ֵ,�ٷ��ʸ�����;���ʹ����������,��ֹ��������ʱ,Ϊά�� B+���ṹ,�ļ��Ĵ������ |
MySQL �� InnoDB ֧�ֵ�����������뼶������,�Լ���֮�������?
SQL ��������ĸ����뼶��Ϊ:
1��read uncommited :����δ�ύ����
2��read committed:���,�����ظ���
3��repeatable read:���ض�
4��serializable :��������
char �� varchar ������?
- �ڴ洢�ͼ������治ͬ
- CHAR �г��ȹ̶�Ϊ������ʱ�����ij���,����ֵ��Χ�� 1 �� 255 �� CHARֵ���洢ʱ,���DZ��ÿո���䵽�ض�����,���� CHAR ֵʱ��ɾ��β��ո�
�����ͺ�ѡ����ʲô����?
�����ÿһ�ж�������Ψһ��ʶ,һ����ֻ��һ��������
����Ҳ�Ǻ�ѡ�������չ���,��ѡ�����Ա�ָ��Ϊ����,���ҿ��������κ��������
���һ������һ�ж���Ϊ TIMESTAMP,������ʲô?
ÿ���б�����ʱ,ʱ����ֶν���ȡ��ǰʱ�����
������Ϊ AUTO INCREMENT ʱ,����ڱ��дﵽ���ֵ,�ᷢ��ʲô���?
����ֹͣ����,�κν�һ���IJ��붼����������,��Ϊ��Կ�ѱ�ʹ�á�
���������ҳ����һ�β���ʱ�������ĸ��Զ�����?
LAST_INSERT_ID �������� Auto_increment ��������һ��ֵ,���Ҳ���Ҫָ��������
��ô����Ϊ���������������?
������ͨ�����·�ʽΪ�������:
SHOW INDEX FROM <tablename>;
LIKE �����е�%��_��ʲô��˼?
%��Ӧ�� 0 ��������ַ�,_ֻ�� LIKE ����е�һ���ַ���
����� Unix �� MySQL ʱ���֮�����ת��?
UNIX_TIMESTAMP �Ǵ� MySQL ʱ���ת��Ϊ Unix ʱ���������
FROM_UNIXTIME �Ǵ� Unix ʱ���ת��Ϊ MySQL ʱ���������
�жԱ��������ʲô?
�� SELECT �����бȽ���ʹ��
=,<>,<=,<,> =,>,<<,>>,<=>,AND,OR �� LIKE �������
BLOB �� TEXT ��ʲô����?
BLOB ��һ�������ƶ���,�������ɿɱ����������ݡ�TEXT ��һ�������ִ�Сд�� BLOB��
BLOB �� TEXT ����֮���Ψһ�������ڶ� BLOB ֵ��������ͱȽ�ʱ���ִ�Сд,�� TEXT ֵ�����ִ�Сд��
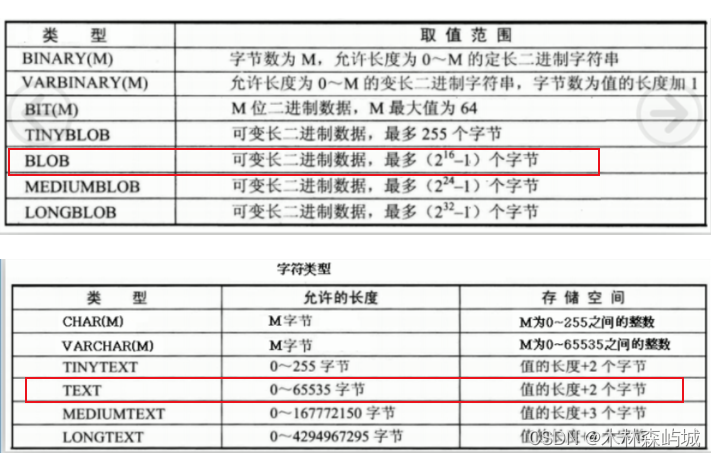

MySQL ����Ż� DISTINCT?
DISTINCT ����������ת��Ϊ GROUP BY,���� ORDER BY �Ӿ���ʹ�á�
SELECT DISTINCT t1.a FROM t1,t2 where t1.a=t2.a;
�����ʾǰ 50 ��?
�� MySQL ��,ʹ�����´����ѯ��ʾǰ 50 ��:
select * from ���� where limit 0,50
����ʹ�ö����д�������?
�κα��������Դ��� 16 �������С�
NOW()�� CURRENT_DATE()��ʲô����?
NOW()����������ʾ��ǰ���,�·�,����,Сʱ,���Ӻ��롣
CURRENT_DATE()����ʾ��ǰ���,�·ݺ����ڡ�
ʲô�ǷDZ��ַ�������?
1��TINYTEXT (tinytext:�dz�С���ı���)
2��TEXT (�ı�)
3��MEDIUMTEXT(mediumtext:�е��ı���)
4��LONGTEXT(����/���ı�����)
ʲô��ͨ�� SQL ����?
1��CONCAT(A, B) �C ���������ַ���ֵ�Դ��������ַ��������ͨ�����ڽ����������ֶκϲ�Ϊһ���ֶΡ�
2��FORMAT(X, D)- ��ʽ������ X �� D ��Ч���֡�
3��CURRDATE(), CURRTIME()- ���ص�ǰ���ڻ�ʱ�䡣
4��NOW() �C ����ǰ���ں�ʱ����Ϊһ��ֵ���ء�
5��MONTH(),DAY(),YEAR(),WEEK(),WEEKDAY() �C ������ֵ����ȡ�������ݡ�
6��HOUR(),MINUTE(),SECOND() �C ��ʱ��ֵ����ȡ�������ݡ�
7��DATEDIFF(A,B) �C ȷ����������֮��IJ���,ͨ�����ڼ�������
8��SUBTIMES(A,B) �C ȷ������֮��IJ��졣
9��FROMDAYS(INT) �C ����������ת��Ϊ����ֵ��
MySQL ֧��������?
��ȱʡģʽ��,MySQL �� autocommit ģʽ��,���е����ݿ���²������ἴʱ�ύ,������ȱʡ�����,MySQL �Dz�֧������ġ�
���������� MySQL ��������ʹ�� InnoDB Tables �� BDB tables �Ļ�,���MySQL �Ϳ���ʹ��������,ʹ�� SETAUTOCOMMIT=0 �Ϳ���ʹ MySQL �����ڷ� autocommit ģʽ,�ڷ�autocommit ģʽ��,�����ʹ�� COMMIT ���ύ��ĸ���,������ ROLLBACK���ع���ĸ��ġ�
MySQL ���¼������ʲô�ֶ����ͺ�?
NUMERIC (��ֵ��)�� DECIMAL(С��,ʮ������) ���ͱ� MySQL ʵ��Ϊͬ��������,���� SQL92 �����������DZ����ڱ���ֵ,��ֵ��ȷ�����Ǽ�����Ҫ��ֵ,�������Ǯ�йص����ݡ�������һ��������Щ����֮һʱ,���Ⱥ�ģ���ܱ�(����ͨ����)ָ����
����:
salary DECIMAL(9,2)
�����������,9(precision)�����������ڴ洢ֵ���ܵ�С��λ��,�� 2(scale)�����������ڴ洢С������λ����
���,�����������,�ܱ��洢�� salary ���е�ֵ�ķ�Χ�Ǵ�-9999999.99 ��
9999999.99��
��MYSQL�����(��Ǯ)��ص����ݴ洢����
int
������Ϸ�ҵȴ���,һ��洢Ϊint�����ǿ��еġ�
��������Խ��,int���ͳ���Ϊ11λ��
�ڴ洢�������صĽ���ʱ��,��ֻ�ܴ洢��9���ȵ������,Ҳ����˵,���ֻ�ܴ洢999999999,����10�ڵ���ֵ,���ҵ�������ܿ�Ļ�,�ͻ���Լ�����������
Decimal
DecimalΪר��Ϊ�������������Ƶ��������͡�
DECIMAL��MySQL 5.1����,�е��������DECIMAL(M,D)����MySQL 5.1��,������ȡֵ��Χ����:
��M�����ֵ������(����)���䷶ΧΪ1~65(�ڽϾɵ�MySQL�汾��,�����ķ�Χ��1~254),M ��Ĭ�� ֵ��10��
��D��С�����Ҳ����ֵ���Ŀ(���)���䷶Χ��0~30,�����ó���M��
˵��:floatռ4���ֽ�,doubleռ8���ֽ�,decimail(M,D)ռM+2���ֽڡ�
��DECIMAL(5,2) �����ֵΪ9 9 9 9 . 9 9,��Ϊ��7 ���ֽڿ��á�
�ܹ�������ݵķ�Χ�;��ȵ����⡣
�ܽ�
�����ַ�ʽ���ǿ��еĽ������,���ǿ��Ը��ݾ������ʹ�ú��ʵķ�����
sqlyog�ǹ��������ݿ�?
MySQL,oracle�����ݿ�,SQLyog������MySQL�Ŀ��ӻ��ͻ�������(���ݿ��������,���ݿ�����)��SQLyog ���Կ���ֱ�۵����û���ɶ����ݿ�IJ���
MySQL��Oracle ����?
����:
Oracle���ݿ��շѵ� MySQL��Դ�����
Oracle�Ǵ������ݿ� Mysql����С�����ݿ�,
���͵�����
mysql:
1��mysqlû��number��varchar2()����;
2��mysql��������������:auto_increment;
3��mysql��double,float����;
oracle:
1��oracleû��double���͡���int���͵���������number������int;
2��oracle����������������:auto_increment,�����Դ�������;
3��oracleС��ֻ��float����;
sql��ѯ��������
oracle sql����mysql sql�����һ��������.
1.oracle������,�����ӿ���ʹ��(+)��ʵ��.
����ʹ��(+)��һЩע������:
1.(+)������ֻ�ܳ�����WHERE�Ӿ���,���Ҳ�����OUTER JOIN�ͬʱʹ�á�
2. ��ʹ��(+)������ִ��������ʱ,�����WHERE�Ӿ��а����ж������,����������������ж�����(+)��������
3.(+)������ֻ��������,���������ڱ���ʽ�ϡ�
4.(+)������������OR��IN������һ��ʹ�á�
5.(+)������ֻ������ʵ���������Ӻ���������,����������ʵ����ȫ�����ӡ�
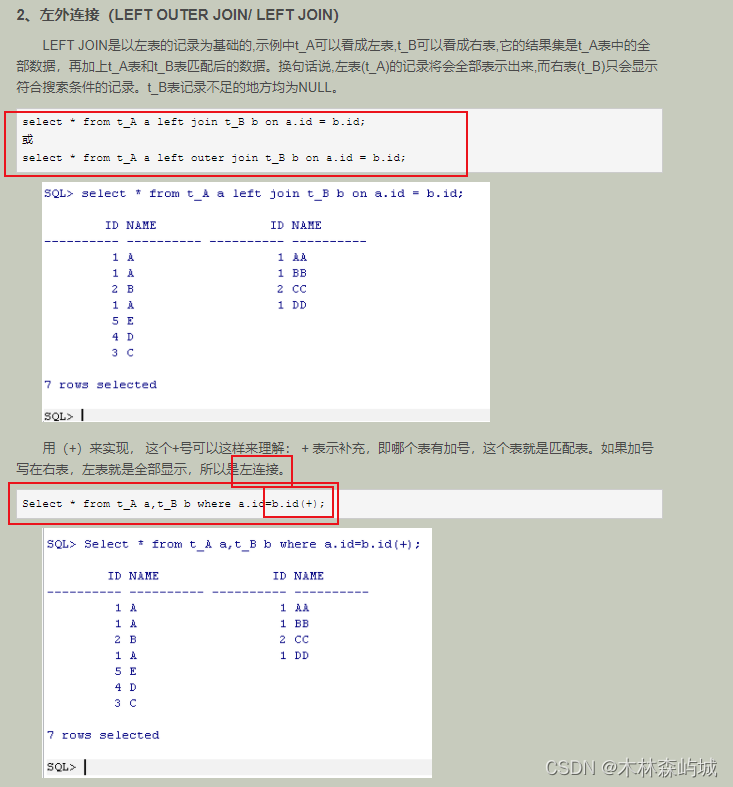
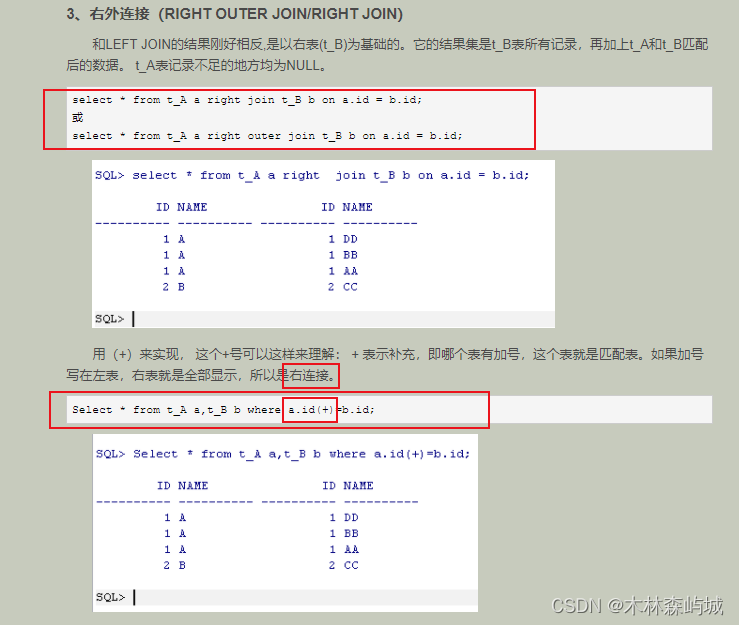
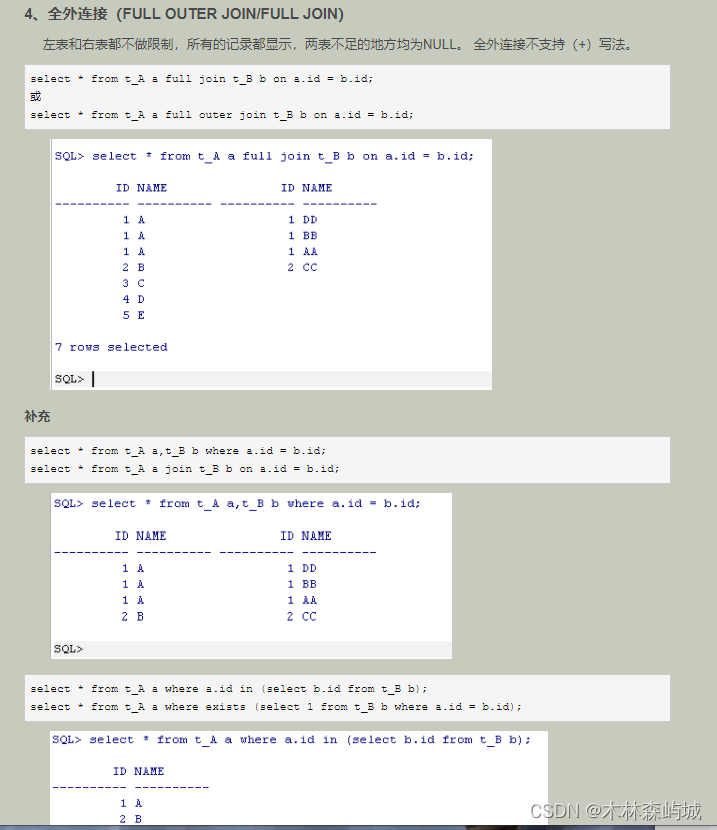
2.Mysqlֻ��ʹ��left join ,right join�ȹؼ���.
���ַ�������
Oracle�п��ַ���''����null(Ҳ����˵,ֻ��null,û�п��ַ�)
,��MySQL������null��''�ġ�
Double��decimal��float������?
Double��decimal��float�����Ա�ʾС��,float�ǵ�����,double��˫����,decimal��������,������ռ���ڴ�ռ䲻һ��,��ʾ��λ��Ҳ��һ����
�ھ�����,double��float��ȷ,������Ȼ����ھ�����ʧ������,�Ҳ��ᱨ�κδ�����쳣;��ռ�ڴ�ʹ����ٶ���,floatҪ��ö�,�������漰��С������Ļ�,���ǻὨ����decimal��
�ܶ���֮,�Լ��������ʹ�ð�
���������������Լ�ȫ���ӵ�����?
������:left join �������,�ұ���ƥ���,������������ұ�������ʱ��ʾ��������ֶ��������ұ�null
������:right join
������:inner join ��ʾ���ұ����е�����
ȫ����:union
ע��:ʹ��union����ƴ�Ӳ�ѯ��ʱ��,�����ֶ�Ҫһ�µ����ſ��Խ��в�ѯ,Ҫ�����׳���
union���Զ�����ȫ�ظ�������ȥ����;union all�ᱣ����Щ�ظ�������
MySQL �й�Ȩ�ı������ļ���?
MySQL ������ͨ��Ȩ�ޱ��������û������ݿ�ķ���,Ȩ�ޱ������ MySQL ���ݿ���,�� MySQL_install_db �ű���ʼ������ЩȨ�ޱ��ֱ� user,db,table_priv,columns_priv �� host��
�е��ַ������Ϳ�����ʲô?
�ַ���������:SET��BLOB��ENUM��CHAR��TEXT
MySQL ���ݿ�������ϵͳ�Ĵ洢,һ�����������ϵ�����,Ԥ����ά����,��ô�Ż�?
1��������õ����ݿ�ṹ,����������������,�������� join ��ѯ,���Ч�ʡ�
2��ѡ����ʵı��ֶ��������ͺʹ洢����,�ʵ�������������
3��MySQL �����Ӷ�д���롣
4���ҹ��ɷֱ�,���ٵ����е���������߲�ѯ�ٶȡ�
5�����ӻ������,���� memcached,apc �ȡ�
6���������Ķ���ҳ��,���ɾ�̬ҳ�档
7����д��Ч�ʵ� SQL������
SELECT * FROM TABEL ��Ϊ SELECT field_1,field_2, field_3 FROM TABLE
�����Ż�����
1�������
2���ֶμ���
3�����������е�ʱ��
4.����߳̾�������ͬ��˳��ȥ��ȡ��Դ
���ܽ��������ȹ���ϸ��,��Ȼ���ܻ�����̵߳ļ������ͷŴ�������,����Ч�ʲ���һ�μ�һ�Ѵ�����
�����ĵײ�ʵ��ԭ�����Ż�
B+��,�����Ż��� B+��
��Ҫ�������е�Ҷ�ӽ����������ָ����һ��Ҷ�ӽڵ��ָ��,��� InnoDB ����Ϊ�ֱ�ʹ��Ĭ��������������Ϊ��������
ʲô�������������������ʹ��
1���ԡ�%����ͷ�� LIKE ���,ģ��ƥ��
2��OR ���ǰ��û��ͬʱʹ������
3���������ͳ�����ʽת��(�� varchar ���ӵ����ŵĻ����ܻ��Զ�ת��Ϊ int ��)
##ʵ��������Ż� MySQL?
����ǰ�������˳���Ż�:
1��SQL ��估�������Ż�
2�����ݿ���ṹ���Ż�
3��ϵͳ���õ��Ż�
4��Ӳ�����Ż�
MySQL ����ѯ�Ż��������Ż����Լ������Ż��ܽ�
�Ż����ݿ�ķ���
1��ѡȡ�����õ��ֶ�����,�����ܼ��ٶ����ֶο���,�������ֶ����� NOTNULL,
���硯ʡ�ݡ������Ա�������� ENUM
2��ʹ������(JOIN)�������Ӳ�ѯ
3����������(UNION)�������ֶ���������ʱ��
4��������
5�����������Ż�������
6���������,�Ż�������
7����������
8���Ż���ѯ���
������ MySQL ��,����,����,Ψһ����,��������������,�����ݿ��������ʲôӰ��(�Ӷ�д������)
������һ��������ļ�(InnoDB ���ݱ��ϵ������DZ��ռ��һ����ɲ���),����
�����Ŷ����ݱ������м�¼������ָ�롣
��ͨ����(�ɹؼ��� KEY �� INDEX ���������)��Ψһ�����Ǽӿ�����ݵķ�����
�ȡ�
��ͨ���������������������а����ظ���ֵ�������ȷ��ij�������н�ֻ������
�˸�����ͬ��ֵ,��Ϊ��������д���������ʱ���Ӧ���ùؼ��� UNIQUE ����
����Ϊһ��Ψһ������Ҳ����˵,Ψһ�������Ա�֤���ݼ�¼��Ψһ�ԡ�
����,��һ�������Ψһ����,��һ�ű���ֻ�ܶ���һ����������,��������Ψ
һ��ʶһ����¼,ʹ�ùؼ��� PRIMARY KEY ��������
�������Ը��Ƕ��������,���� INDEX(columnA, columnB)����,�����������
����
�������Լ����������ݵIJ�ѯ�ٶ�,���ǻή�Ͳ��롢ɾ�������±����ٶ�,
��Ϊ��ִ����Щд����ʱ,��Ҫ���������ļ���
���ݿ��е�������ʲô?
����(transaction)����Ϊһ����Ԫ��һ����������ݿ������������е����в������ɹ�,����Ϊ����ɹ�,��ʹֻ��һ������ʧ��,����Ҳ���ɹ���������в������,�������ύ,���Ľ������������������ݿ���̡����һ������ʧ��,�����ع�,���������в�����Ӱ�춼��ȡ����
��������:
1��ԭ����:�����ɷָ���,����Ҫôȫ����ִ��,Ҫô��ȫ������ִ�С�
2��һ���Ի�ɴ��ԡ������ִ��ʹ�����ݿ��һ����ȷ״̬ת������һ����ȷ״̬
3�������ԡ���������ȷ�ύ֮ǰ,�������Ѹ���������ݵ��κθı��ṩ���κ���������,
4���־��ԡ�������ȷ�ύ��,���������ñ��������ݿ���,��ʹ�������ύ��������������,����Ĵ������Ҳ��õ����档
������������:
������DZ�����һ����Ϊһ����������Ԫ�� SQL ������,����κ�һ��������ʧ����ô���������ͱ�ʧ��,�Ժ�����ͻ�ع�������ǰ״̬,���������и��ڵ㡣Ϊ��ȷ��Ҫôִ��,Ҫô��ִ��,�Ϳ���ʹ������Ҫ�����������Ϊ������,����Ҫͨ�� ACID ����,��ԭ����,һ����,�����Ժͳ־��ԡ�
SQL ע��©��������ԭ��?��η�ֹ?
SQL ע�������ԭ��:���������в�ע��淶��д sql ���Ͷ������ַ����й���,���¿ͻ��˿���ͨ��ȫ�ֱ��� POST �� GET �ύһЩ sql �������ִ�С�
��ֹ SQL ע��ķ�ʽ:
- ���������ļ��е� magic_quotes_gpc �� magic_quotes_runtime
- ����ִ�� sql ���ʱʹ�� addslashes ���� sql ���ת��Sql �����д
- ������Ҫʡ��˫���ź͵����š�
- ���˵� sql ����е�һЩ�ؼ���:update��insert��delete��select�� * ��
- ������ݿ�����ֶε���������,��һЩ��Ҫ���ֶθ��ݳ�����ص�����,ȡ���ױ��µ��ġ�
Ϊ���е��ֶ�ѡ����ʵ���������
�ֶ��������ȼ�:
����int>date,
time>enum,
char>varchar>blob,
text ���ȿ�����������,��������ڻ��߶���������,������ַ�������,ͬ�������������,Ӧ������ѡ��ռ�ÿռ�С����������
�洢ʱ��
datatime:�� yyyy-MM-dd HH:mm:ss ��ʽ�洢ʱ��ʱ��,��ȷ����,
ռ�� 8 ���ֽڵô洢�ռ�,datatime ������ʱ����
������yyyy-MM-dd HH:mm:ss (��-��-�� ʱ:��:��) �Ĵ�Сд˵��:
MM��mm ��д��Ϊ�����֡� �� ���롰 �� ��
HH ��Ϊ������ 12Сʱ�� �� 24Сʱ�� ��Сд��h��12Сʱ��,��д��H��24Сʱ�ơ�
��
Timestamp:��ʱ�����ʽ�洢,ռ�� 4 ���ֽ�,��ΧС 1970-1-1 �� 2038-1-19,��ʾ��������ָ����ʱ��,Ĭ���ڵ�һ�����е�������ʱ�����Զ�����timestamp �е�ֵ
Date:(����)ռ�õ��ֽ�����ʹ���ַ���.datatime.int ����Ҫ��,ʹ�� date ֻ��Ҫ 3 ���ֽ�,�洢�����·�,��������������ʱ�亯���������ڼ�ü���
Time:�洢ʱ�䲿�ֵ�����
ע��:��Ҫʹ���ַ����������洢����ʱ������(ͨ�����ַ���ռ�õô���ռ�С,�ڽ��в��ҹ��˿����������ڵú���)ʹ�� int �洢����ʱ�䲻��ʹ�� timestamp ����
���ڹ�ϵ�����ݿ����,�������൱��Ҫ�ĸ���,��ش��й������ļ�������:
1��������Ŀ����ʲô?
- ���ٷ������ݱ��е��ض���Ϣ,������ٶ�
- ����Ψһ������,��֤���ݿ����ÿһ�����ݵ�Ψһ�ԡ�
- ���ٱ��ͱ�֮�������
- ʹ�÷���������Ӿ�������ݼ���ʱ,�����������ٲ�ѯ�з���������ʱ��
2�����������ݿ�ϵͳ�ĸ���Ӱ����ʲô?
����Ӱ��:����������ά��������Ҫ�ķ�ʱ��,���ʱ�����������������Ӷ�����;������Ҫռ�������ռ�,�����DZ���Ҫռ�����ݿռ�,ÿ������Ҳ��Ҫռ�������ռ�;���Ա���������ɾ���ġ���ʱ������ҲҪ��̬ά��,�����ͽ��������ݵ�ά���ٶȡ�
3��Ϊ���ݱ�����������ԭ������Щ?
����Ƶ��ʹ�õġ�������С��ѯ��Χ���ֶ��Ͻ���������
��Ƶ��ʹ�õġ���Ҫ������ֶ��Ͻ�������
4��ʲô����²��˽�������?
���ڲ�ѯ�к����漰���л����ظ�ֵ�Ƚ϶����,���˽���������
����һЩ�������������,���˽�������,�����ı��ֶ�(text)��
Myql �е�����ع����Ƹ���
����:�����ݿ��������С������Ԫ,����Ϊ������������Ԫִ�е�һϵ�в���;��Щ������Ϊһ������һ����ϵͳ�ύ,Ҫô��ִ�С�Ҫô����ִ��;������һ�鲻���ٷָ�IJ�������(��������Ԫ)
�����Ĵ�����:ԭ���ԡ�һ���ԡ������ԡ�������
����ع�:��ͬһ��������,������һ���쳣��,�����еIJ������ع���δ�ĵ�״̬(�������������Ѿ���ɵIJ��ֶ��ص�δ��״̬)
SQL �������ļ�����?ÿ���ֶ�����Щ�����ؼ���?
SQL ���������ݶ���(DDL)�����ݲ���(DML),���ݿ���(DCL)�����ݲ�ѯ(DQL)
�ĸ����֡�
���ݶ���:Create Table,Alter Table,Drop Table, Craete/Drop Index ��
���ݲ���:Select ,insert,update,delete,
���ݿ���:grant,revoke
���ݲ�ѯ:select
������Լ��������Щ?
����������(Data Integrity)��ָ���ݵľ�ȷ(Accuracy)�Ϳɿ���(Reliability)��
����������:
1��ʵ��������:�涨����ÿһ���ڱ�����Ωһ��ʵ�塣
2����������:��ָ���е��б�������ij���ض�����������Լ��,����Լ���ְ���ȡֵ��Χ�����ȵȹ涨��
3������������:��ָ�����������ؼ��ֺ���ؼ��ֵ�����Ӧһ��,��֤�˱�֮������ݵ�һ����,��ֹ�����ݶ�ʧ������������������ݿ�����ɢ��
4���û������������:��ͬ�Ĺ�ϵ���ݿ�ϵͳ������Ӧ�û����IJ�ͬ,��������ҪһЩ�����Լ���������û�����������Լ������ij���ض���ϵ���ݿ��Լ������,����ӳijһ����Ӧ�ñ������������Ҫ��
����йص�Լ��:������Լ��(NOT NULL(�ǿ�Լ��))�ͱ�Լ��(PRIMARY KEY��foreign key��check��UNIQUE) ��
ʲô����?
���ݿ���һ�����û�ʹ�õĹ�����Դ��������û������ش�ȡ����ʱ,����
�ݿ��оͻ�����������ͬʱ��ȡͬһ���ݵ���������Բ����������ӿ��ƾͿ��ܻ��ȡ�ʹ洢����ȷ������,�ƻ����ݿ��һ���ԡ�
������ʵ�����ݿⲢ�����Ƶ�һ���dz���Ҫ�ļ������������ڶ�ij�����ݶ�����в���ǰ,����ϵͳ��������,�������������������ͶԸ����ݶ�������һ���Ŀ���,�ڸ������ͷ���֮ǰ,�����������ܶԴ����ݶ�����и��²�����
����������:�������м����ͱ�����
ʲô����ͼ?�α���ʲô?
��ͼ��һ������ı�,���к���������ͬ�Ĺ��ܡ����Զ���ͼ������,��,
��,����,��ͼͨ������һ�������߶�������л��е��Ӽ�������ͼ���IJ�Ӱ�����������ʹ�����ǻ�ȡ���ݸ�����,��ȶ����ѯ��
�α�:�ǶԲ�ѯ�����Ľ������Ϊһ����Ԫ����Ч�Ĵ������α���Զ��ڸõ�Ԫ�е��ض���,�ӽ�����ĵ�ǰ�м���һ�л���С����ԶԽ������ǰ�����ġ�һ�㲻ʹ���α�,������Ҫ�����������ݵ�ʱ��,�α��Ե�ʮ����Ҫ��
ʲô�Ǵ洢����?��ʲô������?
�洢������һ��Ԥ����� SQL ���,�ŵ�������ģ�黯�����,����˵ֻ��
����һ��,�Ժ��ڸó����оͿ��Ե��ö�Ρ����ij�β�����Ҫִ�ж�� SQL,ʹ�ô洢���̱ȵ��� SQL ���ִ��Ҫ�졣������һ��������������ô洢���̡�
���ͨ������������ʽ?
��һ��ʽ:1NF �Ƕ����Ե�ԭ����Լ��,Ҫ�����Ծ���ԭ����,�����ٷֽ�;
�ڶ���ʽ:2NF �ǶԼ�¼��Ωһ��Լ��,Ҫ���¼��Ωһ��ʶ,��ʵ���Ωһ��;
������ʽ:3NF �Ƕ��ֶ������Ե�Լ��,���κ��ֶβ����������ֶ���������,��Ҫ���ֶ�û�����ࡣ��
��ʽ�������ȱ��:
�ŵ�:
���Ծ����ü�����������,ʹ�ø��¿�,���С
ȱ��:
���ڲ�ѯ��Ҫ��������й���,����д��Ч�����Ӷ���Ч��,���ѽ�������
�Ż�
����ʽ��:
�ŵ�:���Լ��ٱ��ù���,���Ը��õý��������Ż�
ȱ��:���������Լ������쳣,���ݵ�����Ҫ����ijɱ�
ʲô�ǻ�����?ʲô����ͼ?
�������DZ����������ڵı�,�� SQL ��һ����ϵ�Ͷ�Ӧһ������ ��ͼ�Ǵ�
һ���������������ı�����ͼ�����������洢�����ݿ���,��һ�����
������ͼ���ŵ�?
(1) ��ͼ�ܹ����û��IJ���
(2) ��ͼʹ�û����Զ��ֽǶȿ���ͬһ����;
(3) ��ͼΪ���ݿ��ṩ��һ���̶ȵ���������;
(4) ��ͼ�ܹ��Ի��������ṩ��ȫ����
NULL ��ʲô��˼
NULL ���ֵ��ʾ UNKNOWN(δ֪):������ʾ����(���ַ���)���� NULL ��
��ֵ���καȽ϶�������һ�� NULL ֵ�������ܰ��κ�ֵ��һ�� NULL ֵ���бȽ�,��������ϣ�����һ���𰸡�ʹ�� IS NULL ������ NULL �ж�
���������������������?
| ���� | ��� | ���� | |
|---|---|---|---|
| ���� | Ψһ��ʶһ����¼,�������ظ���,������Ϊ�� | �����������һ��������, ����������ظ���, �����ǿ�ֵ | ���ֶ�û���ظ�ֵ,��������һ����ֵ |
| ���� | ������֤���������� | ������������������ϵ�õ� | ����߲�ѯ������ٶ� |
| ���� | ����ֻ����һ�� | һ���������ж����� | һ���������ж��Ψһ���� |
�������ʲô��ȷ����������ֶ�ֻ�����ض���Χ���ֵ?
Check ����,�������ݿ�����ﱻ����,��������������е�ֵ��
������Ҳ���Ա������������ݿ��������ֶ��ܹ����ܵ�ֵ,�������ְ취Ҫ�����ڱ����ﱻ����,����ܻ���ijЩ�����Ӱ�쵽���ܡ�
˵˵�� SQL ����Ż�����Щ����?(ѡ����)
1��Where �Ӿ���:where ��֮������ӱ���д������ Where ����֮ǰ,��Щ���Թ��˵����������¼����������д�� Where �Ӿ��ĩβ.HAVING (having)���
2���� EXISTS (exists)��� IN���� NOT EXISTS ��� NOT IN��
3�� ��������������ʹ�ü���
4����������������ʹ�� IS NULL �� IS NOT NULL
5���Բ�ѯ�����Ż�,Ӧ��������ȫ��ɨ��,����Ӧ������ where �� order by �漰�����Ͻ���������
select * from �� ��Ϊ select �ֶ�1,�ֶ�2 from ��
6��Ӧ���������� where �Ӿ��ж��ֶν��� null ֵ�ж�,�������������ʹ������������ȫ��ɨ��
7��Ӧ���������� where �Ӿ��ж��ֶν��б���ʽ����,�⽫�����������ʹ������������ȫ��ɨ��
Java�������(һ)
�� java ���ػ��̺߳ͱ����߳�����?
java �е��̷߳�Ϊ����:�ػ��߳�(Daemon)���û��߳�(User)��
�κ��̶߳���������Ϊ�ػ��̺߳��û��߳�,ͨ������ Thread.setDaemon(boolon);true ��Ѹ��߳�����Ϊ�ػ��߳�,��֮��Ϊ�û��̡߳�Thread.setDaemon() ������ Thread.start()֮ǰ����,��������ʱ���׳��쳣��
���ߵ�����:
Ψһ���������ж������(JVM)��ʱ�뿪,Daemon ��Ϊ�����߳��ṩ����,���ȫ���� User Thread �Ѿ�����,Daemon û�пɷ�����߳�,JVM ���롣Ҳ��������Ϊ�ػ��߳��� JVM �Զ��������߳�(����һ��),�û��߳��dz������߳�;���� JVM �����������߳���һ���ػ��߳�,�������߳��Ѿ�����,���ٲ�������,�ػ��߳���Ȼ��û�¿ɸ���,�����������߳��� Java ������Ͻ�ʣ���߳�ʱ,Java ��������Զ��뿪��
(�ػ��߳�Ϊ�����̷߳���,�����еı����̳߳����,JVM�뿪,��ʱʣ�µ��߳̾����ػ��߳�)
��չ:Thread Dump ��ӡ�������߳���Ϣ,���� daemon �������̼߳�Ϊ�ػ�����,���ܻ���:�����ػ����̡������ػ����̡�windows �µļ��� Ctrl+break���ػ����̡�Finalizer �ػ����̡����ô����ػ����̡�GC �ػ����̡�
�߳�����̵�����?
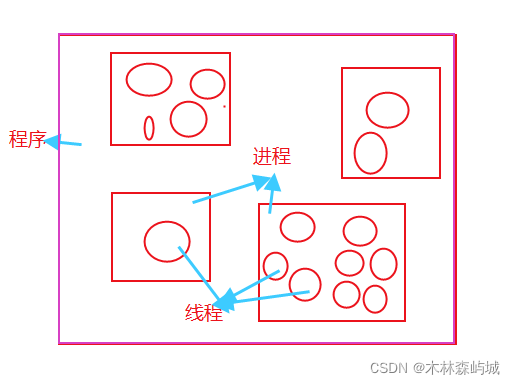
�����Dz���ϵͳ������Դ����С��Ԫ,�߳��Dz���ϵͳ���ȵ���С��Ԫ��
һ������������һ������,һ������������һ���̡߳�
ʲô�Ƕ��߳��е��������л�?
���̻߳Ṳͬʹ��һ�������ϵ� CPU,���߳������ڸ��������� CPU ����ʱ,Ϊ���ø����̶߳���ִ�еĻ���,����Ҫ��תʹ�� CPU����ͬ���߳��л�ʹ�� CPU�������л����ݵȾ����������л���
���������������,�����뼢��������?
����:��ָ�������������ϵĽ���(���߳�)��ִ�й�����,��������Դ����ɵ�һ�ֻ���ȴ�������,������������,���Ƕ������ƽ���ȥ��
���������ı�Ҫ����:
1����������:��ν������ǽ�����ijһʱ���ڶ�ռ��Դ��
2�������뱣������:һ��������������Դ������ʱ,���ѻ�õ���Դ���ֲ��š�
3������������:�����ѻ����Դ,��ĩʹ����֮ǰ,����ǿ�а��ᡣ
4��ѭ���ȴ�����:���ɽ���֮���γ�һ��ͷβ��ӵ�ѭ���ȴ���Դ��ϵ��
����:�������ִ����û�б�����,����ijЩ����û������,����һֱ�ظ�����,ʧ��,����,ʧ�ܡ�
��������������������,���ڻ�����ʵ�����ڲ��ϵĸı�״̬,��ν�ġ��, ������������ʵ�����Ϊ�ȴ�;�����п������н,�������ܡ�
����:һ�����߶���߳���Ϊ����ԭ�����������Ҫ����Դ,����һֱ��ִ�е�״̬��
Java �е��¼�����ԭ��:
1�������ȼ��߳��������еĵ����ȼ��̵߳� CPU ʱ�䡣
2���̱߳����ö�����һ���ȴ�����ͬ�����״̬,��Ϊ�����߳�����������֮ǰ�����ضԸ�ͬ������з��ʡ�
3���߳��ڵȴ�һ������Ҳ�������õȴ���ɵĶ���(��������������� wait ����),��Ϊ�����߳����DZ������ػ�û��ѡ�
Java ���õ����̵߳����㷨��ʲô?
����ʱ��Ƭ��ת�ķ�ʽ�����������̵߳����ȼ�,��ӳ�䵽�²��ϵͳ��������ȼ���,����ر���Ҫ,������Ҫ��,��ֹ�̼߳�����
ʲô���߳���,Ϊʲô�� Java �в��Ƽ�ʹ��?
ThreadGroup ��,�����̹߳�����ijһ���߳�����,�߳����п������̶߳���,Ҳ�������߳���,���л��������߳�,��������֯�ṹ�е�������������ʽ��Ϊʲô���Ƽ�ʹ��?��Ϊʹ���кܶ�İ�ȫ������,û�о�����,�����Ҫʹ��,�Ƽ�ʹ���̳߳ء�
���̳߳ؾ����̵߳ļ���,�̳߳ؼ��й����߳�,��ʵ���̵߳�����,������Դ����,�����Ӧ�ٶȵȡ�
Ϊʲôʹ�� Executor ���?
�Ƽ�:Executor������
Ϊʲôʹ�� Executor ���
- ÿ��ִ�������߳� new Thread()�Ƚ���������,����һ���߳��DZȽϺ�ʱ������Դ�ġ�
- ���� new Thread()�������߳�ȱ������,����ΪҰ�߳�,���ҿ��������ƵĴ���,�߳�֮���������ᵼ�¹���ռ��ϵͳ��Դ������ϵͳ̱��,�����߳�֮���Ƶ������Ҳ�����ĺܶ�ϵͳ��Դ��
ʹ�� new Thread() �������̲߳�������չ,���綨ʱִ�С�����ִ�С���ʱ
����ִ�С��߳��жϵȶ�����ʵ�֡�
�� Java �� Executor �� Executors ������?
Executors ������IJ�ͬ�����������ǵ������˲�ͬ���̳߳�,������ҵ�������
Executor �ӿڶ�����ִ�����ǵ��߳�����
ExecutorService �ӿڼ̳��� Executor �ӿڲ���������չ,�ṩ�˸���ķ��������ܻ������ִ�е�״̬���ҿ��Ի�ȡ����ķ���ֵ��
ʹ�� ThreadPoolExecutor ���Դ����Զ����̳߳ء�
Future ��ʾ�첽����Ľ��,���ṩ�˼������Ƿ���ɵķ���,�Եȴ���������,������ʹ�� get()������ȡ����Ľ����
����� Windows �� Linux �ϲ����ĸ��߳�ʹ�õ� CPU ʱ���?
ʹ�� jstack �ҳ����� CPU �����̴߳���
windows�����������������,linux�¿�����top ������߿��� ��Ȼ�����Ҫ���Ҿ���Ľ���,������ps���� ,����
����java:(1) ps -ef |grep java (��ȡ��Ŀ��pid)
(2)top -H -p pid,˳���ܸı�
��ӡ����ǰ����Ŀ,ÿ���߳�ռ��CPUʱ��İٷֱȡ�ע������������LWP(ʮ����),Ҳ���Dz���ϵͳԭ���̵߳��̺߳�
ʹ�á�top -H -p pid��+��jps pid�����Ժ������ҵ�ij��ռ��CPU�ߵ��̵߳��̶߳�ջ,�Ӷ���λռ��CPU�ߵ�ԭ��,һ������Ϊ�����Ĵ��������������ѭ����
ע��;��top -H -p pid���������LWP��ʮ���Ƶ�,��jps pid��������ı����̺߳���ʮ�����Ƶ�,ת��һ��,���ܶ�λ��ռ��CPU�ߵ��̵߳ĵ�ǰ�̶߳�ջ�ˡ�
Linux�ϲ����߳�ʹ�õ�CPUʱ���
ʲô��ԭ�Ӳ���?�� Java Concurrency API ������Щԭ����(atomic classes)?
ԭ�Ӳ���(atomic operation)��Ϊ�����ɱ��жϵ�һ����һϵ�в����� ��
������ʹ�û��ڶԻ���������������ķ�ʽ��ʵ�ֶദ����֮���ԭ�Ӳ������� Java �п���ͨ������ѭ�� CAS �ķ�ʽ��ʵ��ԭ�Ӳ����� CAS ��������Compare & Set,���� Compare & Swap,���ڼ������е� CPU ָ�֧�� CAS��ԭ�Ӳ�����
ԭ�Ӳ�����ָһ��������������Ӱ��IJ�������Ԫ��ԭ�Ӳ������ڶ��̻߳����±������ݲ�һ�±�����ֶΡ�
int++������һ��ԭ�Ӳ���,���Ե�һ���̶߳�ȡ����ֵ���� 1 ʱ,����һ���߳��п��ܻ����֮ǰ��ֵ,��ͻ���������
Ϊ�˽���������,���뱣֤���Ӳ�����ԭ�ӵ�,�� JDK1.5 ֮ǰ���ǿ���ʹ��ͬ��������������һ�㡣�� JDK1.5,java.util.concurrent.atomic ���ṩ�� int ��long ���͵�ԭ�Ӱ�װ��,���ǿ����Զ��ı�֤�������ǵIJ�����ԭ�ӵIJ��Ҳ���Ҫʹ��ͬ����
java.util.concurrent ����������ṩ��һ��ԭ���ࡣ����������Ծ����ڶ��̻߳�����,���ж���߳�ͬʱִ����Щ���ʵ�������ķ���ʱ,����������,����ij���߳̽��뷽��,ִ�����е�ָ��ʱ,���ᱻ�����̴߳��,������߳̾���������һ��,һֱ�ȵ��÷���ִ�����,���� JVM �ӵȴ�������ѡ��һ����һ���߳̽���,��ֻ��һ�����ϵ����⡣
ԭ����:AtomicBoolean,AtomicInteger,AtomicLong,AtomicReference
ԭ������:AtomicIntegerArray,AtomicLongArray,AtomicReferenceArray
ԭ�����Ը�����:AtomicLongFieldUpdater,AtomicIntegerFieldUpdater,
AtomicReferenceFieldUpdater
��� ABA �����ԭ����:AtomicMarkableReference(ͨ������һ�� boolean
����ӳ�м���û�б��),AtomicStampedReference(ͨ������һ�� int ���ۼ�����ӳ�м���û�б��)
Java Concurrency API �е� Lock �ӿ�(Lock interface)��ʲô?
Lock �ӿڱ�ͬ��������ͬ�����ṩ�˸�����չ�Ե���������
�������������Ľṹ,���Ծ�����ȫ��ͬ������,���ҿ���֧�ֶ����������������
����������:
- ����ʹ������ƽ
- ����ʹ�߳��ڵȴ�����ʱ����Ӧ�ж�
- �������̳߳��Ի�ȡ��,��������ȡ����ʱ���������ػ��ߵȴ�һ��ʱ��
- �����ڲ�ͬ�ķ�Χ,�Բ�ͬ��˳���ȡ���ͷ���
��������˵ Lock �� synchronized (ͬ����)����չ��,Lock �ṩ���������ġ�����ѯ��(tryLock ����)����ʱ��(tryLock ���η���)�����жϵ�(lockInterruptibly)���ɶ��������е�(newCondition ����)������������ Lock ��ʵ���������֧�ַǹ�ƽ��(Ĭ��)��ƽ��,synchronized ֻ֧�ַǹ�ƽ��,��Ȼ,�ڴ������,�ǹ�ƽ���Ǹ�Ч��ѡ��
ʲô�� Executors ���?
Executor �����һ������һ��ִ�в��Ե���,����,ִ�кͿ��Ƶ��첽����Ŀ�ܡ�
�����ƵĴ����̻߳�����Ӧ�ó����ڴ���������Դ���һ���̳߳��Ǹ����õĵĽ������,��Ϊ���������̵߳��������ҿ��Ի�����������Щ�̡߳�����Executors ��ܿ��Էdz�����Ĵ���һ���̳߳ء�
ʲô����������?�������е�ʵ��ԭ����ʲô?���ʹ������������ʵ��������-������ģ��?
��������(BlockingQueue)��һ��֧���������Ӳ����Ķ��С�
���������ӵIJ�����:�ڶ���Ϊ��ʱ,��ȡԪ�ص��̻߳�ȴ����б�Ϊ�ǿա���������ʱ,�洢Ԫ�ص��̻߳�ȴ����п��á�
�������г����������ߺ������ߵij���,��������������������Ԫ�ص��߳�,�������ǴӶ�������Ԫ�ص��̡߳��������о��������ߴ��Ԫ�ص�����,��������Ҳֻ����������Ԫ�ء�
JDK7 �ṩ�� 7 ���������С��ֱ���:
ArrayBlockingQueue :һ��������ṹ��ɵ��н��������С�
LinkedBlockingQueue :һ���������ṹ��ɵ��н��������С�
PriorityBlockingQueue :һ��֧�����ȼ���������������С�
DelayQueue:һ��ʹ�����ȼ�����ʵ�ֵ����������С�
SynchronousQueue:һ�����洢Ԫ�ص��������С�
LinkedTransferQueue:һ���������ṹ��ɵ����������С�
LinkedBlockingDeque:һ���������ṹ��ɵ�˫���������С�
Java 5 ֮ǰʵ��ͬ����ȡʱ,����ʹ����ͨ��һ������,Ȼ����ʹ���̵߳�Э�����߳�ͬ������ʵ��������,������ģʽ,��Ҫ�ļ��������ú�,
wait ,notify,notifyAll,sychronized ��Щ�ؼ��֡����� java 5 ֮��,����ʹ����
��������ʵ��,�˷�ʽ�������˴�����,ʹ�ö��̱߳�̸�������,��ȫ����Ҳ�б��ϡ�
BlockingQueue �ӿ��� Queue ���ӽӿ�,������Ҫ��;��������Ϊ����,������Ϊ�߳�ͬ���ĵĹ���,���������һ�������Ե�����,���������߳���ͼ��BlockingQueue ����Ԫ��ʱ,�����������,���̱߳�����,���������߳���ͼ����ȡ��һ��Ԫ��ʱ,�������Ϊ��,����̻߳ᱻ����,������Ϊ���������������,�����ڳ����ж���߳̽����� BlockingQueue �з���Ԫ��,ȡ��Ԫ��,�����ԺܺõĿ����߳�֮���ͨ�š�
��������ʹ�����ij������� socket �ͻ������ݵĶ�ȡ�ͽ���,��ȡ���ݵ��̲߳��Ͻ����ݷ������,Ȼ������̲߳��ϴӶ���ȡ���ݽ�����
ʲô�� Callable �� Future?
Callable �ӿ������� Runnable,�����־Ϳ��Կ�������,���� Runnable ���᷵�ؽ��,�������׳����ؽ�����쳣,�� Callable ���ܸ�ǿ��һЩ,���߳�ִ�к�,���Է���ֵ,�������ֵ���Ա� Future �õ�,Ҳ����˵,Future �����õ��첽ִ������ķ���ֵ��������Ϊ�Ǵ��лص��� Runnable��
Future �ӿڱ�ʾ�첽����,�ǻ�û����ɵ����������δ�����������˵ Callable���ڲ������,Future ���ڻ�ȡ�����
ʲô�� FutureTask?ʹ�� ExecutorService ��������
�� Java ���������� FutureTask ��ʾһ������ȡ�����첽���㡣����������ȡ�����㡢��ѯ�����Ƿ���ɺ�ȡ���������ȷ�����ֻ�е�������ɵ�ʱ��������ȡ��,���������δ��� get ��������������һ�� FutureTask ������ԶԵ����� Callable �� Runnable �Ķ�����а�װ,���� FutureTask Ҳ�ǵ����� Runnable�ӿ������������ύ�� Executor ��ִ�С�
ʲô�Dz���������ʵ��?
��Ϊͬ������:���Լ�����Ϊͨ�� synchronized ��ʵ��ͬ��������,����ж���̵߳���ͬ�������ķ���,���ǽ��ᴮ��ִ�С����� Vector,Hashtable,�Լ� Collections.synchronizedSet,synchronizedList �ȷ������ص�������
����ͨ���鿴 Vector,Hashtable ����Щͬ��������ʵ�ִ���,���Կ�����Щ����ʵ���̰߳�ȫ�ķ�ʽ���ǽ����ǵ�״̬��װ����,������Ҫͬ���ķ����ϼ��Ϲؼ��� synchronized��
��������ʹ������ͬ��������ȫ��ͬ�ļ����������ṩ���ߵIJ����Ժ�������,������ ConcurrentHashMap �в�����һ�����ȸ�ϸ�ļ�������,���Գ�Ϊ�ֶ���,��������������,�������������Ķ��̲߳����ط��� map,����ִ�ж��������̺߳�д�������߳�Ҳ���Բ����ķ��� map,ͬʱ����һ��������д�����̲߳������� map,�����������ڲ���������ʵ�ָ��ߵ���������
���߳�ͬ���ͻ����м���ʵ�ַ���,����ʲô?
�߳�ͬ����ָ�߳�֮�������е�һ����Լ��ϵ,һ���̵߳�ִ��������һ���̵߳���Ϣ,����û�еõ���һ���̵߳���ϢʱӦ�ȴ�,ֱ����Ϣ����ʱ�ű����ѡ�
�̻߳�����ָ���ڹ����Ľ���ϵͳ��Դ,�ڸ������̷߳���ʱ�������ԡ��������ɸ��̶߳�Ҫʹ��ijһ������Դʱ,�κ�ʱ�����ֻ����һ���߳�ȥʹ��,����Ҫʹ�ø���Դ���̱߳���ȴ�,ֱ��ռ����Դ���ͷŸ���Դ���̻߳�����Կ�����һ��������߳�ͬ����
�̼߳��ͬ����������ɷ�Ϊ����:�û�ģʽ���ں�ģʽ������˼��,�ں�ģʽ����ָ����ϵͳ�ں˶���ĵ�һ��������ͬ��,ʹ��ʱ��Ҫ�л��ں�̬���û�̬,���û�ģʽ���Dz���Ҫ�л����ں�̬,ֻ���û�̬��ɲ�����
�û�ģʽ�µķ�����:ԭ�Ӳ���(����һ����һ��ȫ�ֱ���),�ٽ������ں�ģʽ�µķ�����:�¼�,�ź���,��������
ʲô�Ǿ�������?���������ֺͽ������?
��������̶���ͼ�Թ������ݽ���ij�ִ���,�����Ľ����ȡ���ڽ������е�˳��ʱ,��������Ϊ�ⷢ���˾�������(race condition)��
�㽫���ʹ�� thread dump?�㽫��η��� Thread dump?
�½�״̬(New)
�� new ��䴴�����̴߳����½�״̬,��ʱ�������� Java ����һ��,�����ڶ����б��������ڴ档
����״̬(Runnable)
��һ���̶߳�����,�����̵߳������� start()����,���߳̾ͽ������״̬,Java �������Ϊ��������������ջ�ͳ�����������������״̬���߳�λ�ڿ����г���,�ȴ���� CPU ��ʹ��Ȩ��
����״̬(Running)
�������״̬���߳�ռ�� CPU,ִ�г�����롣ֻ�д��ھ���״̬���̲߳��л���ת������״̬��
����״̬(Blocked)
����״̬��ָ�߳���ΪijЩԭ����� CPU,��ʱֹͣ���С����̴߳�������״̬ʱ,Java �����������̷߳��� CPU��ֱ���߳����½������״̬,�����л���ת������״̬��
����״̬�ɷ�Ϊ���� 3 ��:
- λ�ڶ���ȴ����е�����״̬(Blocked in object��s wait pool):
���̴߳�������״̬ʱ,���ִ����ij������� wait()����,Java ������ͻ���̷߳ŵ��������ĵȴ�����,���漰�����߳�ͨ�š������ݡ�
- λ�ڶ��������е�����״̬(Blocked in object��s lock pool):
���̴߳�������״̬ʱ,��ͼ���ij�������ͬ����ʱ,����ö����ͬ�����Ѿ��������߳�ռ��,Java ������ͻ������̷߳ŵ���������������,���漰�����߳�ͬ���������ݡ�
- ��������״̬(Otherwise Blocked):
��ǰ�߳�ִ���� sleep()����,���ߵ����������̵߳� join()����,���߷����� I/O����ʱ,�ͻ�������״̬
����״̬(Dead)
���߳��˳� run()����ʱ,�ͽ�������״̬,���߳̽����������ڡ�
��������֮ǰ���Ǹ��������� SimpleDeadLock.java,Ȼ���������Ϣ(
/* ʱ��,jvm ��Ϣ */
2017-11-01 17:36:28
Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.144-b01 mixed
mode):
/* �߳�����:DestroyJavaVM
���:#13
���ȼ�:5
ϵͳ���ȼ�:0
jvm �ڲ��߳� id:0x0000000001c88800
��Ӧϵͳ�߳� id(NativeThread ID):0x1c18
�߳�״̬: waiting on condition [0x0000000000000000] (�ȴ�ij������)
�߳���ϸ״̬:java.lang.Thread.State: RUNNABLE ��֮������*/
"DestroyJavaVM" #13 prio=5 os_prio=0 tid=0x0000000001c88800
nid=0x1c18 waiting on condition [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Thread-1" #12 prio=5 os_prio=0 tid=0x0000000018d49000
nid=0x17b8 waiting for monitor entry [0x0000000019d7f000]
/* �߳�״̬:����(�ڶ���ͬ����)
�����:at
com.leo.interview.SimpleDeadLock$B.run(SimpleDeadLock.java:56)
�ȴ���:0x00000000d629b4d8
�Ѿ������:0x00000000d629b4e8*/
java.lang.Thread.State: BLOCKED (on object monitor)
at
com.leo.interview.SimpleDeadLock$B.run(SimpleDeadLock.java:56)
- waiting to lock <0x00000000d629b4d8> (a java.lang.Object)
- locked <0x00000000d629b4e8> (a java.lang.Object)
"Thread-0" #11 prio=5 os_prio=0 tid=0x0000000018d44000 nid=0x1ebc
waiting for monitor entry [0x000000001907f000]
java.lang.Thread.State: BLOCKED (on object monitor)
at
com.leo.interview.SimpleDeadLock$A.run(SimpleDeadLock.java:34)
- waiting to lock <0x00000000d629b4e8> (a java.lang.Object)
- locked <0x00000000d629b4d8> (a java.lang.Object)
"Service Thread" #10 daemon prio=9 os_prio=0
tid=0x0000000018ca5000 nid=0x1264 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C1 CompilerThread2" #9 daemon prio=9 os_prio=2
tid=0x0000000018c46000 nid=0xb8c waiting on condition
[0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread1" #8 daemon prio=9 os_prio=2
tid=0x0000000018be4800 nid=0x1db4 waiting on condition
[0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"C2 CompilerThread0" #7 daemon prio=9 os_prio=2
tid=0x0000000018be3800 nid=0x810 waiting on condition
[0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Monitor Ctrl-Break" #6 daemon prio=5 os_prio=0
tid=0x0000000018bcc800 nid=0x1c24 runnable [0x00000000193ce000]
java.lang.Thread.State: RUNNABLE
at java.net.SocketInputStream.socketRead0(Native Method)
at
java.net.SocketInputStream.socketRead(SocketInputStream.java:116)
at java.net.SocketInputStream.read(SocketInputStream.java:171)
at java.net.SocketInputStream.read(SocketInputStream.java:141)
at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284)
at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326)
at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178)
- locked <0x00000000d632b928> (a java.io.InputStreamReader)
at java.io.InputStreamReader.read(InputStreamReader.java:184)
at java.io.BufferedReader.fill(BufferedReader.java:161)
at java.io.BufferedReader.readLine(BufferedReader.java:324)
- locked <0x00000000d632b928> (a java.io.InputStreamReader)
at java.io.BufferedReader.readLine(BufferedReader.java:389)
at
com.intellij.rt.execution.application.AppMainV2$1.run(AppMainV2.java:6
4)
"Attach Listener" #5 daemon prio=5 os_prio=2
tid=0x0000000017781800 nid=0x524 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Signal Dispatcher" #4 daemon prio=9 os_prio=2
tid=0x000000001778f800 nid=0x1b08 waiting on condition
[0x0000000000000000]
java.lang.Thread.State: RUNNABLE
"Finalizer" #3 daemon prio=8 os_prio=1 tid=0x000000001776a800
nid=0xdac in Object.wait() [0x0000000018b6f000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x00000000d6108ec8> (a
java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143)
- locked <0x00000000d6108ec8> (a
java.lang.ref.ReferenceQueue$Lock)
at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209)
"Reference Handler" #2 daemon prio=10 os_prio=2
tid=0x0000000017723800 nid=0x1670 in Object.wait()
[0x00000000189ef000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x00000000d6106b68> (a
java.lang.ref.Reference$Lock)
at java.lang.Object.wait(Object.java:502)
at java.lang.ref.Reference.tryHandlePending(Reference.java:191)
- locked <0x00000000d6106b68> (a java.lang.ref.Reference$Lock)
at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
"VM Thread" os_prio=2 tid=0x000000001771b800 nid=0x604 runnable
"GC task thread#0 (ParallelGC)" os_prio=0 tid=0x0000000001c9d800
nid=0x9f0 runnable
"GC task thread#1 (ParallelGC)" os_prio=0 tid=0x0000000001c9f000
nid=0x154c runnable
"GC task thread#2 (ParallelGC)" os_prio=0 tid=0x0000000001ca0800
nid=0xcd0 runnable
"GC task thread#3 (ParallelGC)" os_prio=0 tid=0x0000000001ca2000
nid=0x1e58 runnable
"VM Periodic Task Thread" os_prio=2 tid=0x0000000018c5a000
nid=0x1b58 waiting on condition
JNI global references: 33
/* �˴����Կ��������������Ϣ! */
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x0000000017729fc8 (object
0x00000000d629b4d8, a java.lang.Object),
which is held by "Thread-0"
"Thread-0":
waiting to lock monitor 0x0000000017727738 (object
0x00000000d629b4e8, a java.lang.Object),
which is held by "Thread-1"
Java stack information for the threads listed above:
==============================================
=====
"Thread-1":
at
com.leo.interview.SimpleDeadLock$B.run(SimpleDeadLock.java:56)
- waiting to lock <0x00000000d629b4d8> (a java.lang.Object)
- locked <0x00000000d629b4e8> (a java.lang.Object)
"Thread-0":
at
com.leo.interview.SimpleDeadLock$A.run(SimpleDeadLock.java:34)
- waiting to lock <0x00000000d629b4e8> (a java.lang.Object)
- locked <0x00000000d629b4d8> (a java.lang.Object)
Found 1 deadlock.
/* �ڴ�ʹ��״��,����ÿ� JVM ������� */
Heap
PSYoungGen total 37888K, used 4590K [0x00000000d6100000,
0x00000000d8b00000, 0x0000000100000000)
eden space 32768K, 14% used
[0x00000000d6100000,0x00000000d657b968,0x00000000d8100000)
from space 5120K, 0% used
[0x00000000d8600000,0x00000000d8600000,0x00000000d8b00000)
to space 5120K, 0% used
[0x00000000d8100000,0x00000000d8100000,0x00000000d8600000)
ParOldGen total 86016K, used 0K [0x0000000082200000,
0x0000000087600000, 0x00000000d6100000)
object space 86016K, 0% used
[0x0000000082200000,0x0000000082200000,0x0000000087600000)
Metaspace used 3474K, capacity 4500K, committed 4864K,
reserved 1056768K
class space used 382K, capacity 388K, committed 512K, reserved
1048576K
Ϊʲô���ǵ��� start()����ʱ��ִ�� run()����,Ϊʲô���Dz���ֱ�ӵ��� run()����?
������� start()����ʱ�㽫�����µ��߳�,����ִ���� run()������Ĵ��롣
���������ֱ�ӵ��� run()����,�����ᴴ���µ��߳�Ҳ����ִ�е����̵߳Ĵ���,ֻ��� run ����������ͨ����ȥִ�С�
Java ������������һ���������߳�?
�� Java ��չʷ������ʹ�� suspend()��resume()���������߳̽�����������,����֮���ֺܶ�����,�Ƚϵ��͵Ļ����������⡣
�����������ʹ���Զ���ΪĿ�������,������ Object ��� wait()�� notify()����ʵ���߳�������
����,wait��notify ��������Զ����,������������ wait()�������������߳�����,������ͬʱҲ���ͷŸö������,��Ӧ��,������������ notify()�������������ö����������߳�,������Ҫ���»�ȡ�Ķ������,ֱ����ȡ�ɹ���������ִ��;���,wait��notify ���������� synchronized ����б�����,����Ҫ��֤ͬ������������������ wait��notify �����Ķ�����ͬһ��,���һ���ڵ��� wait ֮ǰ��ǰ�߳̾��Ѿ��ɹ���ȡij�������,ִ�� wait ������ǰ�߳̾ͽ�֮ǰ��ȡ�Ķ������ͷš�
ʲô�Dz��ɱ����,����д����Ӧ����ʲô����?
���ɱ����(Immutable Objects)������һ������������״̬(���������,Ҳ����������ֵ)�Ͳ��ܸı�,��֮��Ϊ�ɱ����(Mutable Objects)��
���ɱ������༴Ϊ���ɱ���(Immutable Class)��Java ƽ̨����а�������ɱ���,�� String���������͵İ�װ�ࡢBigInteger �� BigDecimal �ȡ�
���ɱ�����������̰߳�ȫ�ġ����ǵij���(��)���ڹ��캯���д����ġ���Ȼ���ǵ�״̬����,��Щ������Զ����䡣
���ɱ������Զ���̰߳�ȫ�ġ�
ֻ����������״̬,һ��������Dz��ɱ��;
����״̬�����ڴ������ٱ���;
�������� final ����;����,
������ȷ����(�����ڼ�û�з��� this ���õ��ݳ�)��
ʲô�Ƕ��߳��е��������л�
���������л�������,CPU ��ֹͣ������ǰ���еij���,�����浱ǰ�������еľ���λ���Ա�֮��������С�������Ƕ�����,�������л��е�������ͬʱ�Ķ�������,�������л��鱾��ͬʱ������Ҫ��סÿ���鵱ǰ������ҳ�롣�ڳ�����,�������л������еġ�ҳ�롱��Ϣ�DZ����ڽ��̿��ƿ�(PCB)�еġ�PCB ���������������л��塱(switchframe)����ҳ�롱��Ϣ��һֱ���浽 CPU ���ڴ���,ֱ�����DZ��ٴ�ʹ�á�
�������л��Ǵ洢�ͻָ� CPU ״̬�Ĺ���,��ʹ���߳�ִ���ܹ����жϵ�ָ�ִ�С��������л��Ƕ��������ϵͳ�Ͷ��̻߳����Ļ���������
Java ���õ����̵߳����㷨��ʲô?
�����ͨ��ֻ��һ�� CPU,������ʱ��ֻ��ִ��һ������ָ��,ÿ���߳�ֻ�л��CPU ��ʹ��Ȩ����ִ��ָ��.��ν���̵߳IJ�������,��ʵ��ָ�Ӻ���Ͽ�,�����߳�������� CPU ��ʹ��Ȩ,�ֱ�ִ�и��Ե�����.�����г���,���ж�����ھ���״̬���߳��ڵȴ� CPU,JAVA �������һ��������Ǹ����̵߳ĵ���,�̵߳�����ָ�����ض�����Ϊ����̷߳��� CPU ��ʹ��Ȩ.
�����ֵ���ģ��:��ʱ����ģ�ͺ���ռʽ����ģ�͡�
��ʱ����ģ����ָ�����е��߳�������� cpu ��ʹ��Ȩ,����ƽ������ÿ���߳�ռ�õ� CPU ��ʱ��Ƭ���Ҳ�ȽϺ����⡣
java �����������ռʽ����ģ��,��ָ�����ÿ����г������ȼ��ߵ��߳�ռ��CPU,��������г��е��߳����ȼ���ͬ,��ô�����ѡ��һ���߳�,ʹ��ռ��CPU����������״̬���̻߳�һֱ����,ֱ�������ò����� CPU��
ʲô���߳���,Ϊʲô�� Java �в��Ƽ�ʹ��?
�߳���:Ϊ�˷����̵߳Ĺ���
�̳߳�:Ϊ�˹����̵߳���������,�����߳�,���ٴ��������̵߳Ŀ�����
Ϊʲôʹ�� Executor ��ܱ�ʹ��Ӧ�ô��������̺߳�?
1��ÿ��ִ�������߳� new Thread()�Ƚ���������,����һ���߳��DZȽϺ�ʱ������Դ�ġ�
2������ new Thread()�������߳�ȱ������,����ΪҰ�߳�,���ҿ��������ƵĴ���,�߳�֮���������ᵼ�¹���ռ��ϵͳ��Դ������ϵͳ̱��,�����߳�֮���Ƶ������Ҳ�����ĺܶ�ϵͳ��Դ��
3��ֱ��ʹ�� new Thread() �������̲߳�������չ,���綨ʱִ�С�����ִ�С���ʱ����ִ�С��߳��жϵȶ�����ʵ�֡�
ʹ�� Executor �̳߳ؿ�ܵ��ŵ�
1���ܸ����Ѵ��ڲ����е��̴߳Ӷ������̶߳���Ĵ����Ӷ������������̵߳Ŀ�����
2������Ч��������߳���,���ϵͳ��Դʹ����,ͬʱ���������Դ������
3��������Ѿ��ж�ʱ�����ڡ����̡߳����������Ƶȹ��ܡ�
��������ʹ���̳߳ؿ�� Executor �ܸ��õĹ����̡߳��ṩϵͳ��Դʹ���ʡ�
java ���м��ַ�������ʵ��һ���߳�?
�̳� Thread ��
ʵ�� Runnable �ӿ�
ʵ�� Callable �ӿ�,��Ҫʵ�ֵ��� call() ����
���ֹͣһ���������е��߳�?
ʹ�ù��������ķ�ʽ
�����ַ�ʽ��,֮�������빲������,����Ϊ�ñ������Ա����ִ����ͬ������߳�������Ϊ�Ƿ��жϵ��ź�,֪ͨ�ж��̵߳�ִ�С�
ʹ�� interrupt ������ֹ�߳�
���һ���߳����ڵȴ�ijЩ�¼��ķ�����������,�ָ�����ֹͣ���߳���?������������ᷢ��,���統һ���߳�������Ҫ�Ⱥ���������������,���ߵ���Thread.join()����,���� Thread.sleep()����,�������е���
ServerSocket.accept()����,���ߵ����� DatagramSocket.receive()����ʱ,���п��ܵ����߳�����,ʹ�̴߳��ڴ��ڲ�������״̬ʱ,��ʹ�������н����̵߳Ĺ�����������Ϊ true,�����̴߳�ʱ���������ѭ����־,��ȻҲ���������жϡ��������Ǹ����Ľ�����,��Ҫʹ�� stop()����,����ʹ�� Thread �ṩ��interrupt()����,��Ϊ�÷�����Ȼ�����ж�һ���������е��߳�,����������ʹһ�����������߳��׳�һ���ж��쳣,�Ӷ�ʹ�߳���ǰ��������״̬,�˳��������롣
notify()�� notifyAll()��ʲô����?
notifyAll:�������д��� wait ״̬���߳�,����������������ȷ����������һ���߳��ܼ������С�
notify:���ܻ���ij��������߳�,ֻ�ܻ���һ������ wait ״̬���߳�
����һ���߳̽��� wait ֮��,�ͱ���������̡߳�
ʲô�� Daemon �߳�?����ʲô����?
��ν��̨(daemon)�߳�,��ָ�ڳ������е�ʱ���ں�̨�ṩһ��ͨ�÷�����߳�,��������̲߳������ڳ����в��ɻ�ȱ�IJ��֡����,�����еķǺ�̨�߳̽���ʱ,����Ҳ����ֹ��,ͬʱ��ɱ�������е����к�̨�̡߳�������˵,ֻҪ���κηǺ�̨�̻߳�������,����Ͳ�����ֹ���������߳�����֮ǰ����setDaemon()����,���ܰ�������Ϊ��̨�̡߳�ע��:��̨�����ڲ�ִ�� finally�Ӿ������¾ͻ���ֹ�� run()������
����:JVM �����������߳̾��� Daemon �߳�,Finalizer Ҳ���ػ��̡߳�
java ���ʵ�ֶ��߳�֮���ͨѶ��Э��?
�жϺ�������
ʲô�ǿ�������(ReentrantLock)?
������˵�����Ŀ�������
public class UnReentrant{
Lock lock = new Lock();
public void outer(){
lock.lock();
inner();
lock.unlock();
}
public void inner(){
lock.lock();
//do something
lock.unlock();
} }
outer �е����� inner,outer ����ס�� lock,���� inner �Ͳ����ٻ�ȡ lock����ʵ���� outer ���߳��Ѿ���ȡ�� lock ��,���Dz����� inner ���ظ������Ѿ���ȡ������Դ,����������֮Ϊ ����������������ζ��:�߳̿��Խ����κ�һ�����Ѿ�ӵ�е�����ͬ���ŵĴ���顣
synchronized��ReentrantLock ���ǿ��������,�������������˵���˲�����̵Ŀ���
��һ���߳̽���ij�������һ�� synchronized ��ʵ��������,�����߳��Ƿ�ɽ���˶������������?
�����������û�� synchronized �Ļ�,�����߳��ǿ��Խ���ġ�
����Ҫ����һ���̰߳�ȫ�Ķ���ʱ,�ñ�֤ÿ�����������̰߳�ȫ�ġ�
�ֹ����ͱ����������⼰���ʵ��,����Щʵ�ַ�ʽ?
������:���Ǽ���������,ÿ��ȥ�����ݵ�ʱ����Ϊ���˻���,����ÿ���������ݵ�ʱ������,������������������ݾͻ�����ֱ�����õ�������ͳ�Ĺ�ϵ�����ݿ���߾��õ��˺ܶ�����������,��������,������,����,д����,������������֮ǰ���������ٱ��� Java �����ͬ��ԭ�� synchronized �ؼ��ֵ�ʵ��Ҳ�DZ�������
�ֹ���:����˼��,���Ǻ��ֹ�,ÿ��ȥ�����ݵ�ʱ����Ϊ���˲�����,���Բ�������,�����ڸ��µ�ʱ����ж�һ���ڴ��ڼ������û��ȥ�����������,����ʹ�ð汾�ŵȻ��ơ��ֹ��������ڶ����Ӧ������,�����������������,�����ݿ��ṩ�������� write_condition ����,��ʵ�����ṩ���ֹ������� Java �� java.util.concurrent.atomic �������ԭ�ӱ��������ʹ�����ֹ�����һ��ʵ�ַ�ʽ CAS ʵ�ֵġ�
�ֹ�����ʵ�ַ�ʽ:
1��ʹ�ð汾��ʶ��ȷ���������������ύʱ�������Ƿ�һ�¡��ύ���İ汾��
ʶ,��һ��ʱ���Բ�ȡ�������ٴγ��ԵIJ��ԡ�
2��java �е� Compare and Swap �� CAS ,������̳߳���ʹ�� CAS ͬʱ����
ͬһ������ʱ,ֻ������һ���߳��ܸ��±�����ֵ,�������̶߳�ʧ��,ʧ�ܵ�
�̲߳����ᱻ����,���DZ���֪��ξ�����ʧ��,�������ٴγ��ԡ� CAS ����
�а������������� ���� ��Ҫ��д���ڴ�λ��(V)�����бȽϵ�Ԥ��ԭֵ(A)
����д�����ֵ(B)������ڴ�λ�� V ��ֵ��Ԥ��ԭֵ A ��ƥ��,��ô����������
������λ��ֵ����Ϊ��ֵ B���������������κβ���
CAS ȱ��:
1��ABA ����:(������:��è��̫��)
����˵һ���߳� one ���ڴ�λ�� V ��ȡ�� A,��ʱ����һ���߳� two Ҳ���ڴ���ȡ�� A,���� two ������һЩ��������� B,Ȼ�� two �ֽ� V λ�õ����ݱ�� A,��ʱ���߳� one ���� CAS ���������ڴ�����Ȼ�� A,Ȼ�� one �����ɹ��������߳� one �� CAS �����ɹ�,�����ܴ���DZ�ص����⡣�� Java1.5 ��ʼ JDK �� atomic�����ṩ��һ���� AtomicStampedReference ����� ABA ���⡣
2��ѭ��ʱ�䳤������:
������Դ��������(�̳߳�ͻ����)�����,CAS �����ĸ��ʻ�Ƚϴ�,�Ӷ��˷Ѹ���� CPU ��Դ,Ч�ʵ��� synchronized��
3��ֻ�ܱ�֤һ������������ԭ�Ӳ���:����һ����������ִ�в���ʱ,���ǿ���ʹ��ѭ�� CAS �ķ�ʽ����֤ԭ�Ӳ���,���ǶԶ��������������ʱ,ѭ�� CAS ������֤������ԭ����,���ʱ��Ϳ���������
SynchronizedMap �� ConcurrentHashMap ��ʲô����?
SynchronizedMap һ����ס���ű�����֤�̰߳�ȫ,����ÿ��ֻ����һ���߳���
��Ϊ map��
ConcurrentHashMap ʹ�÷ֶ�������֤�ڶ��߳��µ����ܡ�
ConcurrentHashMap ������һ����סһ��Ͱ��ConcurrentHashMap Ĭ�Ͻ�
hash ����Ϊ 16 ��Ͱ,���� get,put,remove �ȳ��ò���ֻ����ǰ��Ҫ�õ���Ͱ��
����,ԭ��ֻ��һ���߳̽���,����ȴ��ͬʱ�� 16 ��д�߳�ִ��,�������ܵ���
�����Զ����ġ�
���� ConcurrentHashMap ʹ����һ�ֲ�ͬ�ĵ�����ʽ�������ֵ�����ʽ��,��
iterator ���������ٷ����ı�Ͳ������׳�
ConcurrentModificationException,ȡ����֮�����ڸı�ʱ new �µ����ݴӶ�
��Ӱ��ԭ�е����� ,iterator ��ɺ��ٽ�ͷָ���滻Ϊ�µ����� ,���� iterator
�߳̿���ʹ��ԭ���ϵ�����,��д�߳�Ҳ���Բ�������ɸı䡣
CopyOnWriteArrayList ��������ʲôӦ�ó���?
CopyOnWriteArrayList(��������)�ĺô�֮һ�ǵ����������ͬʱ������������б�ʱ,�����׳� ConcurrentModificationException����
CopyOnWriteArrayList ��,д�뽫���´��������ײ�����ĸ���,��Դ���齫������ԭ��,ʹ�ø��Ƶ������ڱ���ʱ,��ȡ��������ȫ��ִ�С�
1������д������ʱ��,��Ҫ��������,�������ڴ�,���ԭ��������ݱȽ϶�������,���ܵ��� young gc ���� full gc;
2����������ʵʱ���ij���,�����顢����Ԫ�ض���Ҫʱ��,���Ե���һ�� set������,��ȡ�����ݿ��ܻ��Ǿɵ�,��Ȼ CopyOnWriteArrayList ����������һ����,���ǻ���û������ʵʱ��Ҫ��;
CopyOnWriteArrayList ¶��˼��
1����д����,����д�ֿ�
2������һ����
3��ʹ������ٿռ��˼·,�����������ͻ
ʲô���̰߳�ȫ?servlet ���̰߳�ȫ��?
�̰߳�ȫ�DZ���е�����,ָij���������������ڶ��̻߳����б�����ʱ,�ܹ���ȷ�ش�������߳�֮��Ĺ�������,ʹ��������ȷ��ɡ�
Servlet �����̰߳�ȫ��,servlet �ǵ�ʵ�����̵߳�,������߳�ͬʱ����ͬһ������,�Dz��ܱ�֤�����������̰߳�ȫ�Եġ�
Struts2 �� action �Ƕ�ʵ�����̵߳�,���̰߳�ȫ��,ÿ������������� new һ���µ� action ������������,������ɺ����١�
SpringMVC �� Controller ���̰߳�ȫ����?
���ǵ�,�� Servlet ���ƵĴ������̡�
Struts2 �ô��Dz��ÿ����̰߳�ȫ����;
Servlet �� SpringMVC ��Ҫ�����̰߳�ȫ����,�������ܿ����������ô���̫��� gc,����ʹ�� ThreadLocal ���������̵߳�����
volatile ��ʲô��?�ܷ���һ�仰˵���� volatile ��Ӧ�ó���?
volatile ��֤�ڴ�ɼ��Ժͽ�ָֹ�����š�
volatile ���ڶ��̻߳����µĵ��β���(���ζ����ߵ���д)��
Ϊʲô�����������?
��ִ�г���ʱ,Ϊ���ṩ����,�������ͱ������������ָ�����������,���Dz�������������,����������ô�������ô����,����Ҫ����������������:
�ڵ��̻߳����²��ܸı�������еĽ��;
��������������ϵ�IJ�������������Ҫע�����:������Ӱ�쵥�̻߳�����ִ�н��,���ǻ��ƻ����̵߳�ִ�����塣
�� java �� wait �� sleep �����IJ�ͬ?
���IJ�ͬ���ڵȴ�ʱ wait ���ͷ���,�� sleep һֱ��������Wait ͨ���������̼߳佻��,sleep ͨ����������ִͣ�С�
ֱ���˽������һ���:
�� Java ���̵߳�״̬һ�����ֳ� 6 ��:
��ʼ̬:NEW
����һ�� Thread ����,����δ���� start()�����߳�ʱ,�̴߳��ڳ�ʼ̬��
����̬:RUNNABLE
�� Java ��,����̬��������̬ �� ����̬��
����̬ :��״̬�µ��߳��Ѿ����ִ�������������Դ,ֻҪ CPU ����ִ��Ȩ�������С����о���̬���̴߳���ھ��������С�
����̬ :��� CPU ִ��Ȩ,����ִ�е��̡߳�����һ�� CPU ͬһʱ��ֻ��ִ��һ���߳�,���ÿ�� CPU ÿ��ʱ��ֻ��һ������̬���̡߳�
����̬
��һ������ִ�е��߳�����ijһ��Դʧ��ʱ,�ͻ��������̬������ Java ��,����̬רָ������ʧ��ʱ�����״̬����һ���������д����������̬���̡߳���������̬���̻߳��������Դ,һ������ɹ�,�ͻ�����������,�ȴ�ִ�С�
PS:����IO��Socket �ȶ���Դ��
�ȴ�̬
��ǰ�߳��е��� wait��join��park ����ʱ,��ǰ�߳̾ͻ����ȴ�̬��Ҳ��һ���ȴ����д�����еȴ�̬���̡߳��̴߳��ڵȴ�̬��ʾ����Ҫ�ȴ������̵߳�ָʾ���ܼ������С�����ȴ�̬���̻߳��ͷ� CPU ִ��Ȩ,���ͷ���Դ(��:��)
��ʱ�ȴ�̬
�������е��̵߳��� sleep(time)��wait��join��parkNanos��parkUntil ʱ,��
������״̬;���͵ȴ�̬һ��,��������Ϊ������Դ,������������,���ҽ������Ҫ�����̻߳���;�����״̬���ͷ� CPU ִ��Ȩ �� ռ�е���Դ����ȴ�̬������:���˳�ʱʱ����Զ�������������,��ʼ��������
��ֹ̬
�߳�ִ�н������״̬��
ע��:
- wait()�������ͷ� CPU ִ��Ȩ �� ռ�е�����
- sleep(long)�������ͷ� CPU ʹ��Ȩ,����Ȼռ��;�̱߳����볬ʱ�ȴ�����,��yield ���,����ʹ�߳̽ϳ�ʱ��ò������С�
- yield()�������ͷ� CPU ִ��Ȩ,����Ȼռ��,�̻߳ᱻ�����������,���ڶ�ʱ�����ٴ�ִ�С�
- wait �� notify ��������ʹ��,������ʹ��ͬһ��������;
- wait �� notify �������һ��ͬ�����е��� wait �� notify �Ķ����������������ͬ�����������
�� Java ʵ����������
һ���߳�����ʱ�����쳣������?
����쳣û�б�������߳̽���ִֹͣ�С�Thread.UncaughtExceptionHandler
�����ڴ���δ�����쳣����߳�ͻȻ�ж������һ����Ƕ�ӿڡ���һ��δ�����쳣������߳��жϵ�ʱ�� JVM ��ʹ�� Thread.getUncaughtExceptionHandler()
����ѯ�̵߳� UncaughtExceptionHandler �����̺߳��쳣��Ϊ�������ݸ�
handler �� uncaughtException()�����������
����������̼߳乲������?
�������̼߳乲����������ʵ�ֹ�����
һ����˵,��������Ҫ������������̰߳�ȫ��,Ȼ�����߳���ʹ�õ�ʱ��,����жԹ��������ĸ��ϲ���,��ôҲ�ñ�֤���ϲ������̰߳�ȫ��
Ϊʲô wait, notify �� notifyAll ��Щ�������� thread ������?
һ�������Ե�ԭ���� JAVA �ṩ�����Ƕ��Ķ������̼߳���,ÿ����������,ͨ���̻߳�á����� wait,notify �� notifyAll ����������IJ���,�������Ƕ����� Object ������Ϊ�����ڶ���
ʲô�� ThreadLocal ����?
ThreadLocal �� Java ��һ������ı�����ÿ���̶߳���һ�� ThreadLocal ����ÿ���̶߳�ӵ�����Լ�������һ������,�������������������ˡ�����Ϊ�������۸߰��Ķ����ȡ�̰߳�ȫ�ĺ÷���,����������� ThreadLocal ��
SimpleDateFormat ����̰߳�ȫ��,��Ϊ�Ǹ��ഴ�����۸߰���ÿ�ε��ö���Ҫ������ͬ��ʵ�����Բ�ֵ���ھֲ���Χʹ����,���Ϊÿ���߳��ṩһ���Լ����еı�������,��������Ч�ʡ�����,ͨ�����ü����˴��۸߰��Ķ���Ĵ������������,����û��ʹ�øߴ��۵�ͬ�����߲����Ե�����»�����̰߳�ȫ��
Java �� interrupted �� isInterrupted ����������?
interrupt
interrupt ���������ж��̡߳����ø÷������̵߳�״̬Ϊ������Ϊ���жϡ�״̬��
ע��:�߳��жϽ��������̵߳��ж�״̬λ,����ֹͣ�̡߳���Ҫ�û��Լ�ȥ�����̵߳�״̬Ϊ����������֧���߳��жϵķ���(Ҳ�����߳��жϺ���׳�
interruptedException �ķ���)�����ڼ����̵߳��ж�״̬,һ���̵߳��ж�״̬����Ϊ���ж�״̬��,�ͻ��׳��ж��쳣��
interrupted
��ѯ��ǰ�̵߳��ж�״̬,�������ԭ״̬�����һ���̱߳��ж���,��һ�ε��� interrupted �� true,�ڶ��κͺ���ľͷ��� false �ˡ�
isInterrupted
�����Dz�ѯ��ǰ�̵߳��ж�״̬
Ϊʲô wait �� notify ����Ҫ��ͬ�����е���?
Java API ǿ��Ҫ��������,����㲻��ô��,��Ĵ�����׳�
IllegalMonitorStateException �쳣������һ��ԭ����Ϊ�˱��� wait �� notify
֮�������̬����
Ϊʲô��Ӧ����ѭ���м��ȴ�����?
���ڵȴ�״̬���߳̿��ܻ��յ�������α����,�������ѭ���м��ȴ���
��,����ͻ���û���������������������˳���
Java �е�ͬ�������벢��������ʲô����?
ͬ�������벢�����϶�Ϊ���̺߳Ͳ����ṩ�˺��ʵ��̰߳�ȫ�ļ���,�����������ϵĿ���չ�Ը��ߡ��� Java1.5 ֮ǰ����Ա��ֻ��ͬ�������������ڶ��̲߳�����ʱ��ᵼ������,�谭��ϵͳ����չ�ԡ�Java5 �����˲���������
ConcurrentHashMap,�����ṩ�̰߳�ȫ������������ڲ��������ִ���������˿���չ�ԡ�
�������ַ�ʽ��ʵ�ּ��ϵ�����?
�����ʹ������,�� TreeSet �� TreeMap,��Ҳ����ʹ����˳��ĵļ���, �� list,Ȼ��ͨ�� Collections.sort() ������
Java ����ô��ӡ����?
�����ʹ�� Arrays.toString() �� Arrays.deepToString() ��������ӡ���顣��
������û��ʵ�� toString() ����,������������鴫�ݸ� System.out.println()
����,������ӡ�����������,���� Arrays.toString() ���Դ�ӡÿ��Ԫ�ء�
Java �е� LinkedList �ǵ�����������˫������?
��˫������,����Լ�� JDK ��Դ�롣�� Eclipse,�����ʹ�ÿ�ݼ� Ctrl + T,ֱ���ڱ༭���д��ࡣ
Java �е� TreeMap �Dz���ʲô��ʵ�ֵ�?
Java �е� TreeMap ��ʹ�ú����ʵ�ֵ�
Hashtable �� HashMap ��ʲô��֮ͬ��?
�������������ͬ�ĵط�,�����г���һ����:
a) Hashtable �� JDK 1 ������������,�� HashMap �Ǻ������ӵġ�
b)Hashtable ��ͬ����,�Ƚ���,�� HashMap û��ͬ������,���Ի���졣
c)Hashtable �������и��յ� key,���� HashMap ��������һ�� null key��
ʲô���̳߳�? ΪʲôҪʹ����?
�����߳�Ҫ���Ѱ������Դ��ʱ��,����������˲Ŵ����߳���ô��Ӧʱ����
��,����һ�������ܴ������߳������ޡ�Ϊ�˱�����Щ����,�ڳ���������ʱ��
�ʹ��������߳�����Ӧ����,���DZ���Ϊ�̳߳�,������߳̽й����̡߳���
JDK1.5 ��ʼ,Java API �ṩ�� Executor ���������Դ�����ͬ���̳߳ء�
��ô���һ���߳��Ƿ�ӵ����?
�� java.lang.Thread ����һ�������� holdsLock(),������ true ������ҽ�����ǰ�߳�ӵ��ij��������������
������� Java �л�ȡ�̶߳�ջ?
kill -3 [java pid]
�����ڵ�ǰ�ն����,�������������ִ�еĻ�ָ���ĵط�ȥ������,kill -3
tomcat pid, �����ջ�� log Ŀ¼�¡�
Jstack [java pid]
����Ƚϼ�,�ڵ�ǰ�ն���ʾ,Ҳ�����ض���ָ���ļ��С�
-JvisualVM:Thread Dump
����˵��,�� JvisualVM ��,���ǽ������,���̻��Ǻܼġ�
JVM ���ĸ����������������̵߳�ջ��ջС��?
-Xss ÿ���̵߳�ջ��С
Thread ���е� yield ������ʲô����?
ʹ��ǰ�̴߳�ִ��״̬(����״̬)��Ϊ��ִ��̬(����״̬)��
��ǰ�̵߳��˾���״̬,��ô�������ĸ��̻߳�Ӿ���״̬���ִ��״̬��?�����ǵ�ǰ�߳�,Ҳ�����������߳�,��ϵͳ�ķ����ˡ�
Java �� ConcurrentHashMap �IJ�������ʲô?
ConcurrentHashMap ��ʵ�� map ���ֳ����ɲ�����ʵ�����Ŀ���չ�Ժ��̰߳�ȫ�����ֻ�����ʹ�ò����Ȼ�õ�,���� ConcurrentHashMap ��캯����һ����ѡ����,Ĭ��ֵΪ 16,�����ڶ��߳�����¾��ܱ������á�
�� JDK8 ��,�������� Segment(����)�ĸ���,����������һ��ȫ�µķ�ʽʵ��,���� CAS �㷨��ͬʱ�����˸���ĸ�����������߲�����,�������ݻ��Dz鿴Դ��ɡ�
Java �� Semaphore ��ʲô?
Java �е� Semaphore ��һ���µ�ͬ����,����һ�������źš��Ӹ����Ͻ�,�Ӹ����Ͻ�,�ź���ά����һ�����ɼ��ϡ����б�Ҫ,�����ɿ���ǰ������ÿһ��acquire(),Ȼ���ٻ�ȡ�����ɡ�ÿ�� release()����һ������,�Ӷ������ͷ�һ�����������Ļ�ȡ�ߡ�����,��ʹ��ʵ�ʵ����ɶ���,Semaphore ֻ�Կ������ɵĺ�����м���,����ȡ��Ӧ���ж����ź����������ڶ��̵߳Ĵ�����,�������ݿ����ӳ�
Java �̳߳��� submit() �� execute()������ʲô����?
�����������������̳߳��ύ����,
execute()�����ķ��������� void,��������Executor �ӿ��С�
�� submit()�������Է��س��м������� Future ����,��������
ExecutorService �ӿ���,����չ�� Executor �ӿ�,�����̳߳�����
ThreadPoolExecutor �� ScheduledThreadPoolExecutor ������������
ʲô������ʽ����?
����ʽ������ָ�����һֱ�ȴ��÷�������ڼ䲻����������,ServerSocket ��accept()��������һֱ�ȴ��ͻ������ӡ������������ָ���ý������֮ǰ,��ǰ�̻߳ᱻ����,ֱ���õ����֮��Ż᷵�ء�����,�����첽�ͷ�����ʽ�������������ǰ�ͷ��ء�
Java �е� ReadWriteLock ��ʲô?
��д�����������������������ܵ������뼼���ijɹ���
volatile ������ atomic ������ʲô��ͬ?
Volatile ��������ȷ�����й�ϵ,��д�����ᷢ���ں����Ķ�����֮ǰ, ���������ܱ�֤ԭ���ԡ������� volatile ���� count ������ô count++ �����Ͳ���ԭ���Եġ�
�� AtomicInteger ���ṩ�� atomic �������������ֲ�������ԭ������
getAndIncrement()������ԭ���ԵĽ������������ѵ�ǰֵ��һ,�����������ͺ����ñ���Ҳ���Խ������Ʋ�����
����ֱ�ӵ��� Thread ��� run ()����ô?
��Ȼ���ԡ�����������ǵ����� Thread �� run()����,������Ϊ�ͻ����ͨ�ķ���һ��,���ڵ�ǰ�߳���ִ�С�Ϊ�����µ��߳���ִ�����ǵĴ���,����ʹ��Thread.start()����
������������е��߳���ͣһ��ʱ��?
���ǿ���ʹ�� Thread ��� Sleep()�������߳���ͣһ��ʱ�䡣��Ҫע�����,�Ⲣ�������߳���ֹ,һ���������л����߳�,�̵߳�״̬���ᱻ�ı�Ϊ Runnable,���Ҹ����̵߳���,�����õ�ִ�С�
����߳����ȼ���������ʲô?
ÿһ���̶߳��������ȼ���,һ����˵,�����ȼ����߳�������ʱ���������Ȩ,�����������̵߳��ȵ�ʵ��,���ʵ���ǺͲ���ϵͳ��ص�(OS dependent)�����ǿ��Զ����̵߳����ȼ�,�����Ⲣ���ܱ�֤�����ȼ����̻߳��ڵ����ȼ����߳�ǰִ�С��߳����ȼ���һ�� int ����(�� 1-10),1 ����������ȼ�,10 ����������ȼ���
java ���߳����ȼ����Ȼ�ί�и�����ϵͳȥ����,���������IJ���ϵͳ���ȼ��й�,����ر���Ҫ,һ�����������߳����ȼ���
ʲ ô �� �� �� �� �� �� (Thread Scheduler) �� ʱ �� �� Ƭ (TimeSlicing )?
�̵߳�������һ������ϵͳ����,������Ϊ Runnable ״̬���̷߳��� CPU ʱ�䡣һ�����Ǵ���һ���̲߳�������,����ִ�б��������̵߳�������ʵ�֡�ͬ��һ������,�̵߳��Ȳ����ܵ� Java ���������,������Ӧ�ó������������Ǹ��õ�ѡ��(Ҳ����˵��Ҫ����ij����������̵߳����ȼ�)��
ʱ���Ƭ��ָ�����õ� CPU ʱ���������õ� Runnable �̵߳Ĺ��̡����� CPUʱ����Ի����߳����ȼ������̵߳ȴ���ʱ�䡣
�����ȷ�� main()�������ڵ��߳��� Java �������������߳�?
���ǿ���ʹ�� Thread ��� join()������ȷ�����г������߳��� main()�����˳�ǰ������
�߳�֮�������ͨ�ŵ�?
���̼߳��ǿ��Թ�����Դʱ,�̼߳�ͨ����Э�����ǵ���Ҫ���ֶΡ�Object ���� wait()\notify()\notifyAll()�������������̼߳�ͨ�Ź�����Դ������״̬
Ϊʲô�߳�ͨ�ŵķ��� wait(), notify()�� notifyAll()��������Object ����?
Java ��ÿ�������ж���һ����(monitor,Ҳ���Գ�Ϊ������) ���� wait(),notify()�ȷ������ڵȴ������������֪ͨ�����̶߳���ļ��������á��� Java ���߳��в�û�пɹ��κζ���ʹ�õ�����ͬ�����������Ϊʲô��Щ������ Object ���һ����,���� Java ��ÿһ����������̼߳�ͨ�ŵĻ���������
Ϊʲô wait(), notify()�� notifyAll ()������ͬ����������ͬ�����б�����?
��һ���߳���Ҫ���ö���� wait()������ʱ��,����̱߳���ӵ�иö������,�������ͻ��ͷ����������������ȴ�״ֱ̬�������̵߳�����������ϵ� notify()������ͬ����,��һ���߳���Ҫ���ö���� notify()����ʱ,�����ͷ�����������,�Ա������ڵȴ����߳̾Ϳ��Եõ�������������������е���Щ��������Ҫ�̳߳��ж������,������ֻ��ͨ��ͬ����ʵ��,��������ֻ����ͬ����������ͬ�����б����á�
Ϊʲô Thread ��� sleep()�� yield ()�����Ǿ�̬��?
Thread ��� sleep()�� yield()�������ڵ�ǰ����ִ�е��߳������С��������������ڵȴ�״̬���߳��ϵ�����Щ������û������ġ������Ϊʲô��Щ�����Ǿ�̬�ġ����ǿ����ڵ�ǰ����ִ�е��߳��й���,���������Ա�������Ϊ�����������������̵߳�����Щ������
���ȷ���̰߳�ȫ?
�� Java �п����кܶ������֤�̰߳�ȫ����ͬ��,ʹ��ԭ����(atomic
concurrent classes),ʵ�ֲ�����,ʹ�� volatile �ؼ���,ʹ�ò�������̰߳�ȫ�ࡣ
ͬ��������ͬ����,�ĸ��Ǹ��õ�ѡ��?
ͬ�����Ǹ��õ�ѡ��,��Ϊ��������ס��������(��Ȼ��Ҳ����������ס��������)��ͬ����������ס��������,������������ж�����������ͬ����,��ͨ���ᵼ������ִֹͣ�в���Ҫ�ȴ������������ϵ�����
ͬ�����Ҫ���Ͽ��ŵ��õ�ԭ��,ֻ����Ҫ��ס�Ĵ������ס��Ӧ�Ķ���,�����Ӳ�����˵Ҳ���Ա���������
��δ����ػ��߳�?
ʹ�� Thread ��� setDaemon(true)�������Խ��߳�����Ϊ�ػ��߳�,��Ҫע�����,��Ҫ�ڵ��� start()����ǰ�����������,������׳�
IllegalThreadStateException �쳣��
ʲô�� Java Timer ��?��δ���һ�����ض�ʱ����������?
java.util.Timer ��һ��������,�������ڰ���һ���߳���δ����ij���ض�ʱ��ִ�С�Timer ������ð���һ�������������������
java.util.TimerTask ��һ��ʵ���� Runnable �ӿڵij�����,������Ҫȥ�̳�����������������Լ��Ķ�ʱ����ʹ�� Timer ȥ��������ִ��
Java�������(��)
���������Ҫ��?
1��ԭ����
ԭ����ָ����һ�����߶������,Ҫôȫ��ִ�в�����ִ�еĹ����в���������
�����,Ҫô��ȫ������ִ�С�
2���ɼ���
�ɼ���ָ����̲߳���һ����������ʱ,����һ���̶߳Ա��������ĺ�,����
�߳̿������������ĵĽ����
3��������
������,�������ִ��˳���մ�����Ⱥ�˳����ִ�С�
ʵ�ֿɼ��Եķ�������Щ?
synchronized ���� Lock:��֤ͬһ��ʱ��ֻ��һ���̻߳�ȡ��ִ�д���,���ͷ�֮ǰ�����µ�ֵˢ�µ����ڴ�,ʵ�ֿɼ��ԡ�
���̵߳ļ�ֵ?
1�����Ӷ�� CPU ������
���߳�,�����������ӳ���� CPU ��������,�ﵽ������� CPU ��Ŀ��,���ö��̵߳ķ�ʽȥͬʱ��ɼ����������������š�
2����ֹ����
�ӳ�������Ч�ʵĽǶ�����,���� CPU �������ᷢ�ӳ����̵߳�����,��������Ϊ�ڵ��� CPU �����ж��̵߳����߳������ĵ��л�,�����ͳ��������Ч�ʡ����ǵ��� CPU ���ǻ���ҪӦ�ö��߳�,����Ϊ�˷�ֹ����������,������� CPU ʹ�õ��߳�,��ôֻҪ����߳�������,�ȷ�˵Զ�̶�ȡij�����ݰ�,�Զ˳ٳ�δ������û�����ó�ʱʱ��,��ô����������������ݷ��ػ���֮ǰ��ֹͣ�����ˡ����߳̿��Է�ֹ�������,�����߳�ͬʱ����,����һ���̵߳Ĵ���ִ�ж�ȡ��������,Ҳ����Ӱ�����������ִ�С�
3�����ڽ�ģ
��������һ��û����ô���Ե��ŵ��ˡ�������һ��������� A,���̱߳��,��ô��Ҫ���Ǻܶ�,������������ģ�ͱȽ��鷳��������������������� A �ֽ�ɼ���С����,���� B������ C������ D,�ֱ�������ģ��,��ͨ�����̷ֱ߳������⼸������,�Ǿͼܶ��ˡ�
�����̵߳ķ�ʽ����Щ?
- �̳�Thread �ഴ���߳���;
- ͨ��Runnable �ӿڴ����߳���;
- ͨ��Callable �� Future �����߳�;
- ͨ���̳߳ش���
�����̵߳����ַ�ʽ�Ա�
1������ʵ�� Runnable��Callable �ӿڵķ�ʽ�������̡߳�
������:
�߳���ֻ��ʵ���� Runnable �ӿڻ� Callable �ӿ�,�����Լ̳������ࡣ�����ַ�ʽ��,����߳̿��Թ���ͬһ�� target ����,���Էdz��ʺ϶����ͬ��
��������ͬһ����Դ�����,�Ӷ����Խ� CPU����������ݷֿ�,�γ�������ģ��,�Ϻõ���������������˼�롣
������:
���������,���Ҫ���ʵ�ǰ�߳�,�����ʹ�� Thread.currentThread()������
2��ʹ�ü̳� Thread ��ķ�ʽ�������߳�
������:
��д��,�����Ҫ���ʵ�ǰ�߳�,������ʹ�� Thread.currentThread()����,ֱ��ʹ�� this ���ɻ�õ�ǰ�̡߳�
������:
�߳����Ѿ��̳��� Thread ��,���Բ����ټ̳��������ࡣ
3��Runnable �� Callable ������
1��Callable �涨(��д)�ķ����� call(),Runnable �涨(��д)�ķ����� run()��
2��Callable ������ִ�к�ɷ���ֵ,�� Runnable �������Dz��ܷ���ֵ�ġ�
3��Call ���������׳��쳣,run ���������ԡ�
4������ Callable ��������õ�һ�� Future ����,��ʾ�첽����Ľ�������ṩ�˼������Ƿ���ɵķ���,�Եȴ���������,����������Ľ����ͨ�� Future��������˽�����ִ�����,��ȡ�������ִ��,���ɻ�ȡִ�н����
�߳�״̬��תͼ
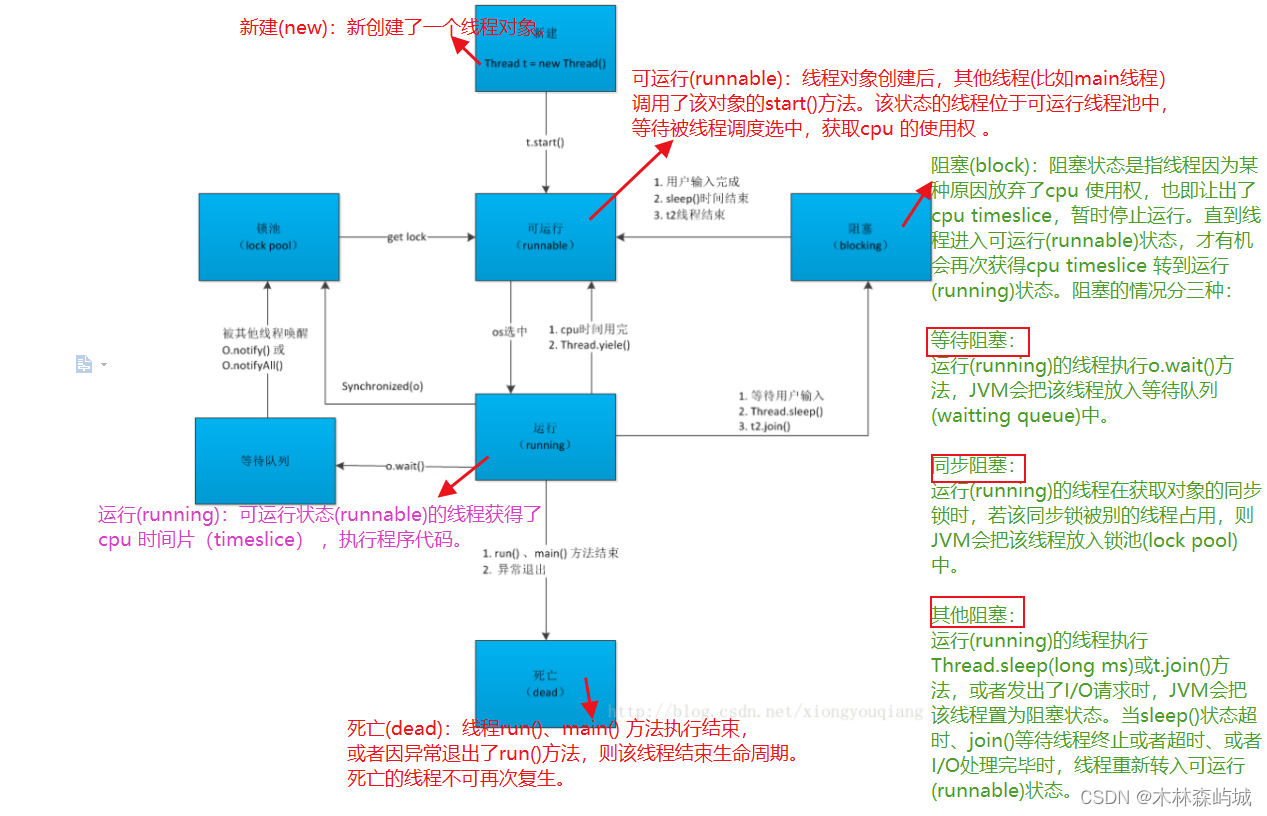
Java �߳̾������л���״̬
1���½�״̬(New):���̶߳���Դ�����,���������½�״̬,��:
Thread t = new MyThread();
2������״̬(Runnable):�������̶߳���� start()����(t.start();),�̼߳��������״̬�����ھ���״̬���߳�,ֻ��˵�����߳��Ѿ���������,��ʱ�ȴ� CPU ����ִ��,������˵ִ���� t.start()���߳������ͻ�ִ��;
3������״̬(Running):�� CPU ��ʼ���ȴ��ھ���״̬���߳�ʱ,��ʱ�̲߳ŵ�������ִ��,�����뵽����״̬��ע:�� ��״̬�ǽ��뵽����״̬��Ψһ���,Ҳ����˵,�߳�Ҫ���������״ִ̬��,���ȱ��봦�ھ���״̬��;
4������״̬(Blocked):��������״̬�е��߳�����ij��ԭ��,��ʱ������ CPU��ʹ��Ȩ,ִֹͣ��,��ʱ��������״̬,ֱ������뵽����״̬,�� �л����ٴα� CPU �����Խ��뵽����״̬����������������ԭ��ͬ,����״̬�ֿ��Է�Ϊ����:
1���ȴ�����:����״̬�е��߳�ִ�� wait()����,ʹ���߳̽��뵽�ȴ�����״̬;
2��ͬ������:�߳��ڻ�ȡ synchronized ͬ����ʧ��(��Ϊ���������߳���ռ��),
�������ͬ������״̬;
3����������:ͨ�������̵߳� sleep()�� join()���� I/O ����ʱ,�̻߳���뵽����״̬���� sleep()״̬��ʱ��join()�ȴ��߳���ֹ���߳�ʱ������ I/O �������ʱ,�߳�����ת�����״̬��
5������״̬(Dead):�߳�ִ�����˻������쳣�˳��� run()����,���߳̽�����������
ʲô���̳߳�?���ļ��ִ�����ʽ?
�̳߳ؾ�����ǰ�������ɸ��߳�,�����������Ҫ����,�̳߳�����߳̾ͻᴦ������,������֮���̲߳����ᱻ����,���ǵȴ���һ���������ڴ����������̶߳�������ϵͳ��Դ��,���Ե�����ҪƵ���Ĵ����������̵߳�ʱ��Ϳ��Կ���ʹ���̳߳�������ϵͳ�����ܡ�
java �ṩ��һ�� java.util.concurrent.Executor �ӿڵ�ʵ�����ڴ����̳߳ء�
�����̳߳صĴ���:
1��newCachedThreadPool ����һ���ɻ����̳߳�
2��newFixedThreadPool ����һ�������̳߳�,�ɿ����߳��������
3��newScheduledThreadPool ����һ�������̳߳�,֧�ֶ�ʱ������������ִ�С�
4��newSingleThreadExecutor ����һ�����̻߳����̳߳�,��ֻ����Ψһ�Ĺ����߳���ִ������
�̳߳ص��ŵ�?
1�����ô��ڵ��߳�,���ٶ������ٵĿ�����
2������Ч�Ŀ�������߳���,���ϵͳ��Դ��ʹ����,ͬʱ���������Դ����,���������
3���ṩ��ʱִ�С�����ִ�С����̡߳����������Ƶȹ��ܡ�
���õIJ�������������Щ?
1��CountDownLatch
2��CyclicBarrier
3��Semaphore
4��Exchanger
synchronized ������?
�� Java ��,synchronized �ؼ��������������߳�ͬ����,�����ڶ��̵߳Ļ�����,���� synchronized ����β�������߳�ͬʱִ�С�
synchronized �ȿ��Լ���һ�δ�����,Ҳ���Լ��ڷ����ϡ�
volatile �ؼ��ֵ�����
���ڿɼ���,Java �ṩ�� volatile �ؼ�������֤�ɼ��ԡ�
��һ������������ volatile ����ʱ,���ᱣ֤�ĵ�ֵ�����������µ�����,���������߳���Ҫ��ȡʱ,����ȥ�ڴ��ж�ȡ��ֵ��
��ʵ���Ƕȶ���,volatile ��һ����Ҫ���þ��Ǻ� CAS ���,��֤��ԭ����,��ϸ�Ŀ��Բμ� java.util.concurrent.atomic ���µ���,
���� AtomicInteger��
ʲô�� CAS
CAS �� compare and swap ����д,��������˵�ıȽϽ�����
cas ��һ�ֻ������IJ���,�������ֹ������� java ������Ϊ�ֹ����ͱ�������
�������ǽ���Դ��ס,��һ��֮ǰ��������߳��ͷ���֮��,��һ���̲߳ſ��Է��ʡ�
���ֹ�����ȡ��һ�ֿ�����̬��,ͨ��ij�ַ�ʽ��������������Դ,����ͨ
������¼�� version ����ȡ����,���ܽϱ������кܴ����ߡ�
CAS ������������������ ���� �ڴ�λ��(V)��Ԥ��ԭֵ(A)����ֵ(B)������ڴ��ַ�����ֵ�� A ��ֵ��һ����,��ô�ͽ��ڴ������ֵ���³� B��CAS��ͨ������ѭ������ȡ���ݵ�,�����ڵ�һ��ѭ����,a �̻߳�ȡ��ַ�����ֵ�� b �߳�����,��ô a �߳���Ҫ����,���´�ѭ�����п��ܻ���ִ�С�java.util.concurrent.atomic ���µ�������ʹ�� CAS ������ʵ�ֵ�
( AtomicInteger,AtomicBoolean,AtomicLong)��
CAS ������
1��CAS ������� ABA ����
2�����ܱ�֤������ԭ����(CAS ��������֤��֪ʶһ��������ԭ���Բ���,�����ܱ�֤����������ԭ���ԡ�������Ҫ��֤ 3 ��������ͬ����ԭ���Եĸ���,�Ͳ��ò�ʹ�� synchronized �ˡ�)
3��CAS ��� CPU ����������(֮ǰ˵���� CAS ������һ��ѭ���жϵĹ���,����߳�һֱû�л�ȡ��״̬,cpu
��Դ��һֱ��ռ�á�)
ʲô�� Future?
�ڲ��������,���Ǿ����õ���������ģ��,��֮ǰ�Ķ��̵߳�����ʵ����,�����Ǽ̳� thread ���ʵ�� runnable �ӿ�,������֤��ȡ��֮ǰ��ִ�н����
ͨ��ʵ�� Callback �ӿ�,���� Future ���������ն��̵߳�ִ�н����
Future ��ʾһ�����ܻ�û����ɵ��첽����Ľ��,�����������������
Callback �Ա�������ִ�гɹ���ʧ�ܺ�������Ӧ�IJ�����
ʲô�� AQS
AQS �� AbustactQueuedSynchronizer �ļ��,����һ�� Java ��ߵĵײ�ͬ��������,��һ�� int ���͵ı�����ʾͬ��״̬,���ṩ��һϵ�е� CAS �������������ͬ��״̬��
AQS ��һ��������������ͬ�����Ŀ��,ʹ�� AQS �ܼ��Ҹ�Ч�ع����Ӧ�ù㷺�Ĵ�����ͬ����,���������ᵽ�� ReentrantLock,Semaphore,����������ReentrantReadWriteLock,SynchronousQueue,FutureTask �ȵȽ��ǻ���AQS �ġ�
AQS ֧������ͬ����ʽ:
1����ռʽ
2������ʽ
��������ʹ����ʵ�ֲ�ͬ���͵�ͬ�����,��ռʽ�� ReentrantLock,����ʽ��Semaphore,CountDownLatch,���ʽ���� ReentrantReadWriteLock����֮,
AQS Ϊʹ���ṩ�˵ײ�֧��,�����װʵ��,ʹ���߿������ɷ��ӡ�
ReadWriteLock ��ʲô
������ȷһ��,����˵ ReentrantLock ����,ֻ�� ReentrantLock ijЩʱ���о��ޡ����ʹ�� ReentrantLock,���ܱ�����Ϊ�˷�ֹ�߳� A ��д���ݡ��߳� B �ڶ�������ɵ����ݲ�һ��,������,����߳� C �ڶ����ݡ��߳� D Ҳ�ڶ�����,�������Dz���ı����ݵ�,û�б�Ҫ����,���ǻ��Ǽ�����,�����˳�������ܡ���Ϊ���,�ŵ����˶�д�� ReadWriteLock��ReadWriteLock ��һ����д���ӿ�,ReentrantReadWriteLock �� ReadWriteLock �ӿڵ�һ������ʵ��,ʵ���˶�д�ķ���,�����ǹ�����,д���Ƕ�ռ��,���Ͷ�֮�䲻�ụ��,����д��д�Ͷ���д��д֮��Żụ��,�����˶�д�����ܡ�
FutureTask ��ʲô
�����ʵǰ�����ᵽ��,FutureTask ��ʾһ���첽���������FutureTask ������Դ���һ�� Callable �ľ���ʵ����,���Զ�����첽���������Ľ�����еȴ���ȡ���ж��Ƿ��Ѿ���ɡ�ȡ������Ȳ�������Ȼ,���� FutureTask Ҳ��Runnable �ӿڵ�ʵ����,���� FutureTask Ҳ���Է����̳߳��С�
synchronized �� ReentrantLock ������
synchronized �Ǻ� if��else��for��while һ���Ĺؼ���,ReentrantLock ����,���Ƕ��ߵı������𡣼�Ȼ ReentrantLock ����,��ô�����ṩ�˱�
synchronized �������������,���Ա��̳С������з����������и��ָ����������,ReentrantLock �� synchronized ����չ�������ڼ�����:
1��ReentrantLock ���ԶԻ�ȡ���ĵȴ�ʱ���������,�����ͱ���������
2��ReentrantLock ���Ի�ȡ����������Ϣ
3��ReentrantLock ��������ʵ�ֶ�·֪ͨ
����,���ߵ���������ʵҲ�Dz�һ���ġ�ReentrantLock �ײ���õ��� Unsafe ��
park ��������,synchronized ������Ӧ���Ƕ���ͷ�� mark word,����Ҳ���
ȷ����
ʲô���ֹ����ͱ�����
1���ֹ���:������������һ��,���ڲ���������������̰߳�ȫ������ֹ�״̬,�ֹ�����Ϊ���������ǻᷢ��,���������Ҫ������,���Ƚ�-�滻������������Ϊһ��ԭ�Ӳ�������ȥ���ڴ��еı���,���ʧ�����ʾ������ͻ,��ô��Ӧ������Ӧ����������
2��������:��������������һ��,���ڲ���������������̰߳�ȫ����ֱ���״̬,��������Ϊ�������ǻᷢ��,���ÿ�ζ�ij��Դ���в���ʱ,�������һ����ռ����,���� synchronized,�������߶�ʮһ,ֱ���������Ͳ�����Դ�ˡ�
�߳� B ��ô֪���߳� A ���˱���
1��volatile �����
2��synchronized �����ı����ķ���
3��wait/notify
4��while ��ѯ
synchronized��volatile��CAS �Ƚ�
1��synchronized �DZ�����,������ռʽ,�����������߳�������
2��volatile �ṩ���̹߳��������ɼ��Ժͽ�ָֹ���������Ż���
3��CAS �ǻ��ڳ�ͻ�����ֹ���(������)
sleep ������ wait ������ʲô����?
������ⳣ��,sleep ������ wait ������������������ CPU һ����ʱ��,��ͬ����������̳߳���ij������ļ�����,sleep ������������������ļ�����,wait ����������������ļ�����
ThreadLocal ��ʲô?��ʲô��?
ThreadLocal ��һ�������̸߳������������ࡣ��Ҫ���ڽ�˽���̺߳��̴߳�ŵĸ���������һ��ӳ��,�����߳�֮��ı�����������,�ڸ߲���������,����ʵ����״̬�ĵ���,�ر������ڸ����߳�������ͨ�ı���ֵ��ɲ����ij�����
��˵ ThreadLocal ����һ���Կռ任ʱ�������,��ÿ�� Thread ����ά����һ���Կ���ַ��ʵ�ֵ� ThreadLocal.ThreadLocalMap,�����ݽ��и���,���ݲ�����,��Ȼ��û���̰߳�ȫ����������ˡ�
Ϊʲô wait()������ notify()/notifyAll()����Ҫ��ͬ�����б�����
���� JDK ǿ�Ƶ�,wait()������ notify()/notifyAll()�����ڵ���ǰ�������Ȼ�ö������
���߳�ͬ�����ļ��ַ���?
Synchronized �ؼ���,Lock ��ʵ��,�ֲ�ʽ���ȡ�
�̵߳ĵ��Ȳ���
�̵߳�����ѡ�����ȼ���ߵ��߳�����,����,��������������,�ͻ���ֹ�̵߳�����:
1���߳����е����� yield �����ó��˶� cpu ��ռ��Ȩ��
2���߳����е����� sleep ����ʹ�߳̽���˯��״̬
3���߳����� IO �����ܵ�����
4������һ���������ȼ��̳߳���
5����֧��ʱ��Ƭ��ϵͳ��,���̵߳�ʱ��Ƭ����
ConcurrentHashMap �IJ�������ʲô
ConcurrentHashMap �IJ����Ⱦ��� segment �Ĵ�С,Ĭ��Ϊ 16,����ζ�����ͬʱ������ 16 ���̲߳��� ConcurrentHashMap,��Ҳ��
ConcurrentHashMap �� Hashtable ���������,�κ������,Hashtable ��ͬʱ�������̻߳�ȡ Hashtable �е�������?
Linux ��������β����ĸ��߳�ʹ�� CPU �
1����ȡ��Ŀ�� pid,jps ���� ps -ef | grep java,���ǰ���н���
2��top -H -p pid,˳���ܸı�
Java �����Լ���α���?
Java �е�������һ�ֱ�����,�������������̱߳���������,Java ��������������������̺߳������������Դ��
Java ���������ĸ���ԭ����:��������ʱ�����˽���ջ����롣
������ԭ��
1���Ƕ���߳��漰�������,��Щ�������Ž���,���Կ��ܻᵼ����һ���������ıջ���
����:�߳��ڻ������ A ����û���ͷŵ������ȥ������ B,��ʱ,��һ���߳��Ѿ�������� B,���ͷ��� B ֮ǰ��Ҫ�Ȼ���� A,��˱ջ�����,��������ѭ����
2��Ĭ�ϵ�����������������ġ�
����Ҫ��������,��Ҫ��һ���������������������,��Ҫ��ϸ����⼸����������е����з���,�Ƿ�����ŵ����������Ļ�·�Ŀ����ԡ���֮�Ǿ���������һ��ͬ�������е��������������ʱ������ͬ��������
��ô����һ���������߳�
����߳�����Ϊ������ wait()��sleep()���� join()���������µ�����,�����ж��߳�,����ͨ���׳� InterruptedException ��������;����߳������� IO ����,����Ϊ��,��Ϊ IO �Dz���ϵͳʵ�ֵ�,Java ���벢û�а취ֱ�ӽӴ�������ϵͳ��
���ɱ����Զ��߳���ʲô����
ǰ�����ᵽ����һ������,���ɱ����֤�˶�����ڴ�ɼ���,�Բ��ɱ����Ķ�ȡ����Ҫ���ж����ͬ���ֶ�,�����˴���ִ��Ч�ʡ�
ʲô�Ƕ��̵߳��������л�
���̵߳��������л���ָ CPU ����Ȩ��һ���Ѿ��������е��߳��л�������һ���������ȴ���ȡ CPU ִ��Ȩ���̵߳Ĺ��̡�
������ύ����ʱ,�̳߳ض�������,��ʱ�ᷢ��ʲô
��������һ��:
1�����ʹ�õ�������� LinkedBlockingQueue,Ҳ��������еĻ�,û��ϵ,���������������������еȴ�ִ��,��Ϊ LinkedBlockingQueue ���Խ�����Ϊ��һ�������Ķ���,�������������
2�����ʹ�õ����н���б��� ArrayBlockingQueue,�������Ȼᱻ���ӵ�
ArrayBlockingQueue ��,ArrayBlockingQueue ����,�����
maximumPoolSize ��ֵ�����߳�����,����������߳��������Ǵ���������,ArrayBlockingQueue ������,��ô���ʹ�þܾ�����
RejectedExecutionHandler �������˵�����,Ĭ���� AbortPolicy
Java ���õ����̵߳����㷨��ʲô
��ռʽ��һ���߳����� CPU ֮��,����ϵͳ������߳����ȼ����̼߳���������������һ���ܵ����ȼ���������һ��ʱ��Ƭ��ij���߳�ִ�С�
ʲô���̵߳�����(Thread Scheduler)��ʱ���Ƭ(TimeSlicing)?
�̵߳�������һ������ϵͳ����,������Ϊ Runnable ״̬���̷߳��� CPU ʱ�䡣һ�����Ǵ���һ���̲߳�������,����ִ�б��������̵߳�������ʵ�֡�ʱ���Ƭ��ָ�����õ� CPU ʱ���������õ� Runnable �̵߳Ĺ��̡����� CPU ʱ����Ի����߳����ȼ������̵߳ȴ���ʱ�䡣�̵߳��Ȳ����ܵ� Java ���������,������Ӧ�ó������������Ǹ��õ�ѡ��(Ҳ����˵��Ҫ����ij����������̵߳���
�ȼ�)��
ʲô������
�ܶ� synchronized ����Ĵ���ֻ��һЩ�ܼĴ���,ִ��ʱ��dz���,��ʱ�ȴ����̶߳�����������һ�ֲ�ֵ̫�õIJ���,��Ϊ�߳������漰���û�̬���ں�̬�л������⡣��Ȼ synchronized ����Ĵ���ִ�е÷dz���,�����õȴ������̲߳�Ҫ������,������ synchronized �ı߽���æѭ��,�����������������˶��æѭ�����ֻ�û�л����,������,����������һ�ָ��õIJ��ԡ�
Java Concurrency API �е� Lock �ӿ�(Lock interface)��ʲô?�Ա�ͬ������ʲô����?
Lock �ӿڱ�ͬ��������ͬ�����ṩ�˸�����չ�Ե����������������������Ľṹ,���Ծ�����ȫ��ͬ������,���ҿ���֧�ֶ����������������
����������:
1������ʹ������ƽ
2������ʹ�߳��ڵȴ�����ʱ����Ӧ�ж�
3���������̳߳��Ի�ȡ��,��������ȡ����ʱ���������ػ��ߵȴ�һ��ʱ��
4�������ڲ�ͬ�ķ�Χ,�Բ�ͬ��˳���ȡ���ͷ���
����ģʽ���̰߳�ȫ��
������̸��������,����Ҫ˵���ǵ���ģʽ���̰߳�ȫ��ζ��:ij�����ʵ���ڶ��̻߳�����ֻ�ᱻ����һ�γ���������ģʽ�кܶ��ֵ�д��,�ܽ�һ��:
1������ʽ����ģʽ��д��:�̰߳�ȫ
2������ʽ����ģʽ��д��:���̰߳�ȫ
3��˫��������ģʽ��д��:�̰߳�ȫ
ͬ��������ͬ����,�ĸ��Ǹ��õ�ѡ��?
ͬ����,����ζ��ͬ����֮��Ĵ������첽ִ�е�,���ͬ���������������������Ч�ʡ���֪��һ��ԭ��:ͬ���ķ�ΧԽСԽ�á�
Java �߳�����������ʲô�쳣?
1���̵߳��������ڿ����dz���
2�����Ĺ���� CPU ��Դ
��������е��߳��������ڿ��ô�����������,��ô���߳̽��ᱻ���á��������е��̻߳�ռ�������ڴ�,����������������ѹ��,���Ҵ������߳��ھ��� CPU��Դʱ���������������ܵĿ�����
3�������ȶ���
JVM �ڿɴ����̵߳������ϴ���һ������,�������ֵ������ƽ̨�IJ�ͬ����ͬ,���ҳ����Ŷ��������Լ,���� JVM ������������Thread ���캯��������ջ�Ĵ�С,�Լ��ײ����ϵͳ���̵߳����Ƶȡ�����ƻ�����Щ����,��ô�����׳�OutOfMemoryError �쳣��
dz̸Java SE��Java EE��Java ME���ߵ�����
- Java SE(Java Platform,Standard Edition)��Java SE ��ǰ��Ϊ J2SE�������������Ͳ��������桢��������Ƕ��ʽ������ʵʱ������ʹ�õ� Java Ӧ�ó���Java SE ������֧�� Java Web ��������,��Ϊ Java Platform,Enterprise Edition(Java EE)�ṩ������
- Java EE(Java Platform,Enterprise Edition)������汾��ǰ��Ϊ J2EE����ҵ�汾���������Ͳ������ֲ����׳���������Ұ�ȫ�ķ������� Java Ӧ�ó���Java EE ���� Java SE �Ļ����Ϲ�����,���ṩ Web �������ģ�͡�������ͨ�� API,��������ʵ����ҵ�������������ϵ�ṹ(service-oriented architecture,SOA)�� Web 2.0 Ӧ�ó���
- Java ME(Java Platform,Micro Edition)������汾��ǰ��Ϊ J2ME��Java ME Ϊ���ƶ��豸��Ƕ��ʽ�豸(�����ֻ���PDA�����ӻ����кʹ�ӡ��)�����е�Ӧ�ó����ṩһ����׳�����Ļ�����Java ME ���������û����桢��׳�İ�ȫģ�͡��������õ�����Э���Լ��Կ��Զ�̬���ص�����������Ӧ�ó���ķḻ֧�֡����� Java ME �淶��Ӧ�ó���ֻ���дһ��,�Ϳ������������豸,���ҿ�������ÿ���豸�ı������ܡ�
˵�ø���
Java SE �������������������
Java EE ����������վ��-(���dz�����JSP����)
Java ME �����ֻ������ġ�
Java
��a==b���͡�a.equals(b)����ʲô����?
��� a �� b ���Ƕ���,�� a==b �DZȽ��������������,ֻ�е� a �� b ָ
����Ƕ��е�ͬһ������Ż᷵�� true,�� a.equals(b) �ǽ������Ƚ�,����ͨ����Ҫ��д�÷������ṩ��һ���ԵıȽϡ�����,String ����д equals() ����,���Կ�������������ͬ����,���ǰ�������ĸ��ͬ�ıȽϡ�
��������������������?
��������������Ҫ�����¼�������:
-
����:�����ǽ�һ�����Ĺ�ͬ�����ܽ����������Ĺ���,�������ݳ�
�����Ϊ���������档����ֻ��ע��������Щ���Ժ���Ϊ,������ע��Щ��Ϊ��ϸ����ʲô�� -
�̳�:�̳��Ǵ�������õ��̳���Ϣ��������Ĺ��̡��ṩ�̳���Ϣ����
����Ϊ����(���ࡢ����);�õ��̳���Ϣ���౻��Ϊ����(������)���̳��ñ仯�е�����ϵͳ����һ����������,ͬʱ�̳�Ҳ�Ƿ�װ�����пɱ����ص���Ҫ�ֶ�(��������������Ķ��ֺ격ʿ�ġ�Java ��ģʽ�������ģʽ���⡷�й�������ģʽ�IJ���)�� -
��װ:ͨ����Ϊ��װ�ǰ����ݺͲ������ݵķ���������,�����ݵķ���
ֻ��ͨ���Ѷ���Ľӿڡ��������ı��ʾ��ǽ���ʵ��������һϵ����ȫ��
�Ρ���յĶ������������б�д�ķ������Ƕ�ʵ��ϸ�ڵ�һ�ַ�װ;���DZ�дһ������Ƕ����ݺ����ݲ����ķ�װ������˵,��װ��������һ�п����صĶ���,ֻ������ṩ��ı�̽ӿ�(����������ͨϴ�»���ȫ�Զ�ϴ�»��IJ��,����ȫ�Զ�ϴ�»���װ������˲�����������;��������ʹ�õ������ֻ�Ҳ�Ƿ�װ���㹻�õ�,��Ϊ���������㶨�����е�����)�� -
��̬��:��̬����ָ������ͬ�����͵Ķ����ͬһ��Ϣ������ͬ����Ӧ��
��˵������ͬ���Ķ������õ���ͬ���ķ����������˲�ͬ�����顣��̬�Է�Ϊ����ʱ�Ķ�̬�Ժ�����ʱ�Ķ�̬�ԡ����������ķ�����Ϊ����������ṩ�ķ���,��ô����ʱ�Ķ�̬�Կ��Խ���Ϊ:�� A ϵͳ���� B ϵͳ�ṩ�ķ���ʱ,Bϵͳ�ж����ṩ����ķ�ʽ,��һ�ж� A ϵͳ��˵��������(����綯���뵶�� A ϵͳ,���Ĺ���ϵͳ�� B ϵͳ,B ϵͳ����ʹ�õ�ع�������ý�����,�������п�����̫����,A ϵͳֻ��ͨ�� B �������ù���ķ���,������֪������ϵͳ�ĵײ�ʵ����ʲô,����ͨ�����ַ�ʽ����˶���)����������(overload)ʵ�ֵ��DZ���ʱ�Ķ�̬��(Ҳ��Ϊǰ��),��������д(override)ʵ�ֵ�������ʱ�Ķ�̬��(Ҳ��Ϊ���)������ʱ�Ķ�̬������������Ķ���,
Ҫʵ�ֶ�̬��Ҫ��������:
1). ������д(����̳и��ಢ��д���������еĻ����ķ���);
2). ��������(�ø������������������Ͷ���,����ͬ�������õ���ͬ���ķ����ͻ�����������IJ�ͬ�����ֳ���ͬ����Ϊ)��
�������η� public,private,protected,�Լ���д(Ĭ��)ʱ������?
| ���η� | ��ǰ�� | ͬ�� | ���� | ������ |
|---|---|---|---|---|
| public(������) | �� | �� | �� | �� |
| protected(�ܱ�����) | �� | �� | �� | �� |
| default(Ĭ�ϵ�) | �� | �� | �� | �� |
| private(˽�е�) | �� | �� | �� | �� |
��ij�Ա��д��������ʱĬ��Ϊ default��Ĭ�϶���ͬһ�����е��������൱�ڹ���(public),���ڲ���ͬһ�����е��������൱��˽��(private)���ܱ���(protected)�������൱�ڹ���,�Բ���ͬһ���е�û�и��ӹ�ϵ�����൱��˽�С�Java ��,�ⲿ������η�ֻ���� public ��Ĭ��,��ij�Ա(�����ڲ���)�����η��������������֡�
String �������������������?
���ǡ�Java �еĻ�����������ֻ�� 8 ��:byte��short��int��long��float��double��char��boolean;
���˻�������(primitive type),ʣ�µĶ�����������(reference
type),Java 5 �Ժ������ö������Ҳ����һ�ֱȽ�������������͡�
float f=3.4;�Ƿ���ȷ?
����ȷ��3.4 ��˫������,��˫������(double)��ֵ��������(float)����
��ת��(down-casting,Ҳ��Ϊխ��)����ɾ�����ʧ,�����Ҫǿ������ת��
float f =(float)3.4;
�����
float f =3.4F;��
short s1 = 1; s1 = s1 + 1;���?short s1 = 1; s1 += 1;���?
����
short s1 = 1;
s1 = s1 + 1;//���� 1 �� int ����,��� s1+1 ������Ҳ�� int��,��Ҫǿ��ת�����Ͳ��ܸ�ֵ�� short ��
//���Բ�������ȷ����
short s1 = 1;
s1 += 1;
//������ȷ����,��Ϊ s1+= 1;�൱�� s1 = (short)(s1 + 1);������������ǿ������ת��
int �� integer ��ʲô����?
Java ��һ������������������������,����Ϊ�˱�̵ķ��㻹�������˻�����������,����Ϊ���ܹ�����Щ�����������͵��ɶ������,Java Ϊÿһ�������������Ͷ������˶�Ӧ�İ�װ����(wrapper class),int �İ�װ����� Integer, �� Java 5 ��ʼ�������Զ�װ��/�������,ʹ�ö��߿����ת����
Java Ϊÿ��ԭʼ�����ṩ�˰�װ����:
- ԭʼ����: boolean,char,byte,short,int,long,float,double
- ��װ����:Boolean,Character,Byte,Short,Integer,Long,Float,
Double
class AutoUnboxingTest {
public static void main(String[] args) {
Integer a = new Integer(3);
Integer b = 3; // �� 3 �Զ�װ��� Integer ����
int c = 3;
System.out.println(a == b); // false ��������û������ͬһ��
��
System.out.println(a == c); // true a �Զ������ int �����ٺ� c
�Ƚ�
} }
�����Զ�װ��Ͳ���(������)
public class Test03 {
public static void main(String[] args) {
Integer f1 = 100, f2 = 100, f3 = 150, f4 = 150;//ע��:������ĸ��������� integer ��������
System.out.println(f1 == f2);//�Ƚ�����
System.out.println(f3 == f4);
} }
������������������Ϊ�������Ҫô���� true Ҫô���� false��������Ҫע����� f1��f2��f3��f4 �ĸ��������� Integer ��������,���������==����ȽϵIJ���ֵ�������á�װ��ı�����ʲô��?�����Ǹ�һ�� Integer ����һ�� int ֵ��ʱ��,����� Integer ��ľ�̬���� valueOf,������� valueOf ��Դ�����֪��������ʲô��
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
IntegerCache �� Integer ���ڲ���,�����������ʾ:
/**
* Cache to support the object identity semantics of autoboxing for
values between
* -128 and 127 (inclusive) as required by JLS.
** The cache is initialized on first usage. The size of the cache
* may be controlled by the {@code -XX:AutoBoxCacheMax=<size>}
option.
* During VM initialization, java.lang.Integer.IntegerCache.high
property
* may be set and saved in the private system properties in the
* sun.misc.VM class.
*/
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int,
ignore it.
} }
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
��˵,���������������ֵ��-128 �� 127 ֮��,��ô���� new �µ� Integer����,����ֱ�����ó������е� Integer ����,����������������� f1f4 �Ľ���� false��
����:Խ��ò�Ƽ����������е�������Խ��,��Ҫ���������൱���Ĺ�����
���������ͷ�����Դ�����硿
&��&&������?
&������������÷�:
(1)���;
(2)���롣
&&������Ƕ�·�����㡣���� ����·��IJ���Ƿdz����,��Ȼ���߶�Ҫ��������������˵IJ���ֵ����true ��������ʽ��ֵ���� true��&&֮���Գ�Ϊ��·��������Ϊ,���&&��ߵı���ʽ��ֵ�� false,�ұߵı���ʽ�ᱻֱ�Ӷ�·��,����������㡣�ܶ�ʱ�����ǿ��ܶ���Ҫ��&&������&,
��������֤�û���¼ʱ�ж��û������� null ���Ҳ��ǿ��ַ���,Ӧ��дΪ:
username != null &&!username.equals(����),
���ߵ�˳���ܽ���,��������&�����,��Ϊ��һ���������������,�������ܽ����ַ����� equals �Ƚ�,�������� NullPointerException �쳣��
ע��:���������(|)�Ͷ�·�������(||)�IJ��Ҳ����ˡ�
����:�������Ϥ JavaScript,������ܸ��ܸ��ܵ���·�����ǿ��,���Ϊ
JavaScript �ĸ��־��ȴ���ת��·���㿪ʼ�ɡ�
Math.round(11.5) ���ڶ���?Math.round(-11.5)���ڶ���?
Math.round(11.5)�ķ���ֵ�� 12,
Math.round(-11.5)�ķ���ֵ��-11��
���������ԭ��(����ȡ)���ڲ����ϼ� 0.5 Ȼ�������ȡ����
switch �Ƿ��������� byte ��,�Ƿ��������� long ��,�Ƿ��������� String ��?
�� Java 5 ��ǰ,switch(expr)��,expr ֻ���� byte��short��char��int���� Java5 ��ʼ,Java ��������ö������,expr Ҳ������ enum ����,�� Java 7 ��ʼ,expr ���������ַ���(String),���dz�����(long)��Ŀǰ���еİ汾�ж��Dz����Եġ�
������û�� length()����?String ��û�� length()����?
����û�� length()����,�� length �����ԡ�
String �� length()����
JavaScript��,����ַ����ij�����ͨ�� length ���Եõ���,��һ������ Java ������
�� Java ��,���������ǰ�Ķ���Ƕ��ѭ��?
�������ѭ��ǰ��һ������� A,Ȼ���� break A;������������ѭ����(Java ��֧�ִ���ǩ�� break �� continue ���,�����е������� C �� C++�е� goto �� ��,���Ǿ���Ҫ����ʹ�� goto һ��,Ӧ�ñ���ʹ�ô���ǩ�� break �� continue,��Ϊ����������ij����ø�����,�ܶ�ʱ���������෴������,�����������ʵ��֪������)
������(constructor)�Ƿ�ɱ���дoverride?
���������ܱ��̳�,��˲��ܱ���д,�����Ա����ء�
����(Overload)����д(override)������?���صķ����ܷ���ݷ������ͽ�������?
���������غ���д����ʵ�ֶ�̬�ķ�ʽ,����
����(Overload):ʵ�ֵ�������ʱ�Ķ�̬��,���ط�����һ������,ͬ���ķ�������в�ͬ�IJ����б�(�������Ͳ�ͬ������������ͬ���߶��߶���ͬ)����Ϊ����,���ضԷ�������û�������Ҫ��
��д(override):ʵ�ֵ�������ʱ�Ķ�̬��,��д�����������븸��֮��,��дҪ�����౻��д�����븸�౻��д��������ͬ�ķ�������,�ȸ��౻��д�������÷���,���ܱȸ��౻��д��������������쳣(���ϴ���ԭ��)��
Ϊʲô���ܸ��ݷ�����������������?
���� �C Ϊʲô���ܸ��ݷ�����������������?
�Ƿ���Լ̳�string��?
��,��Ϊstring����final��,�����Ա��̳�
����:�̳� String ��������һ���������Ϊ,�� String ������õ����÷�ʽ�ǹ�����ϵ(Has-A)��������ϵ(Use-A)�����Ǽ̳й�ϵ(Is-A)��
������(abstract class)�ͽӿ�(interface)��ʲô��ͬ?
������ͽӿڶ����ܹ�ʵ����,�����Զ��������ͽӿ����͵����á�һ��������̳���ij�����������ʵ����ij���ӿڶ���Ҫ�����еij���ȫ������ʵ��,���������Ȼ��Ҫ������Ϊ�����ࡣ�ӿڱȳ�������ӳ���,��Ϊ�������п��Զ��幹����,�����г����;��巽��,���ӿ��в��ܶ��幹�����������еķ���ȫ�����dz������������еij�Ա������ private��Ĭ�ϡ�protected��public ��,���ӿ��еij�Աȫ���� public �ġ��������п��Զ����Ա����,���ӿ��ж���ij�Ա����ʵ���϶��dz������г���������뱻����Ϊ������,��������δ��Ҫ�г�����
��̬Ƕ����(Static Nested Class)���ڲ���(Inner Class)�IJ�ͬ?
Static Nested Class �DZ�����Ϊ��̬(static)���ڲ���,�����Բ��������ⲿ��ʵ����ʵ��������ͨ�����ڲ�����Ҫ���ⲿ��ʵ���������ʵ����,���������ͦ�����,������ʾ��
/**
* �˿���(һ���˿�)
* @author ���
*/
public class Poker {
private static String[] suites = {"����", "����", "�ݻ�", "����"};
private static int[] faces = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13};
private Card[] cards;
/**
* ������
*
*/
public Poker() {
cards = new Card[52];
for(int i = 0; i < suites.length; i++) {
for(int j = 0; j < faces.length; j++) {
cards[i * 13 + j] = new Card(suites[i], faces[j]);
} } }
/**
* ϴ�� (�������)
*
*/
public void shuffle() {
for(int i = 0, len = cards.length; i < len; i++) {
int index = (int) (Math.random() * len);
Card temp = cards[index];
cards[index] = cards[i];
cards[i] = temp;
}
}
/**
* ����
* @param index ���Ƶ�λ��
*
*/
public Card deal(int index) {
return cards[index];
}
/**
* ��Ƭ��(һ���˿�)
* [�ڲ���] * @author ���
*
*/
public class Card {
private String suite; // ��ɫ
private int face; // ����
public Card(String suite, int face) {
this.suite = suite;
this.face = face;
}
@Override
public String toString() {
String faceStr = "";
switch(face) {
case 1: faceStr = "A"; break;
case 11: faceStr = "J"; break;
case 12: faceStr = "Q"; break;
case 13: faceStr = "K"; break;
default: faceStr = String.valueOf(face);
}
return suite + faceStr;
} } }
���Դ���:
class PokerTest {
public static void main(String[] args) {
Poker poker = new Poker();
poker.shuffle(); // ϴ��
Poker.Card c1 = poker.deal(0); // ����һ����
// ���ڷǾ�̬�ڲ��� Card
// ֻ��ͨ�����ⲿ�� Poker ������ܴ��� Card ����
Poker.Card c2 = poker.new Card("����", 1); // �Լ�����һ����
System.out.println(c1); // ϴ�ƺ�ĵ�һ��
System.out.println(c2); // ��ӡ: ���� A } }
������ - ����Ĵ�����Щ�ط�������������?
class Outer {
class Inner {}
public static void foo() { new Inner(); }
public void bar() { new Inner(); }
public static void main(String[] args) {
new Inner();
} }
ע��:Java �зǾ�̬�ڲ������Ĵ���Ҫ�������ⲿ�����,������������� foo �� main �������Ǿ�̬����,��̬������û�� this,Ҳ����˵û����ν���ⲿ�����,����������ڲ������,���Ҫ�ھ�̬�����д����ڲ������,����������:
new Outer().new Inner();
Java �л�����ڴ�й©��,���������
������ Java ��Ϊ���������ջ���(GC)��������ڴ�й¶����(��Ҳ�� Java ���㷺ʹ���ڷ������˱�̵�һ����Ҫԭ��);Ȼ����ʵ�ʿ�����,���ܻ�������õ��ɴ�Ķ���,��Щ�����ܱ� GC ����,���Ҳ�ᵼ���ڴ�й¶�ķ���������
Hibernate �� Session(һ������)�еĶ������ڳ־�̬,�����������Dz��������Щ�����,Ȼ����Щ�����п��ܴ������õ���������,�������ʱ�ر�(close)�����(flush)һ������Ϳ��ܵ����ڴ�й¶�����������еĴ���Ҳ�ᵼ���ڴ�й¶��
import java.util.Arrays;
import java.util.EmptyStackException;
public class MyStack<T> {
private T[] elements;
private int size = 0;
private static final int INIT_CAPACITY = 16;
public MyStack() {
elements = (T[]) new Object[INIT_CAPACITY];
}
public void push(T elem) {
ensureCapacity();
elements[size++] = elem;
}
public T pop() {
if(size == 0)
throw new EmptyStackException();
return elements[--size];
}
private void ensureCapacity() {
if(elements.length == size) {
elements = Arrays.copyOf(elements, 2 * size + 1);
} } }
����Ĵ���ʵ����һ��ջ(�Ƚ����(FILO))�ṹ,է��֮���ƺ�û��ʲô���Ե�����,����������ͨ�����д�ĸ��ֵ�Ԫ���ԡ�Ȼ�����е� pop ����ȴ�����ڴ�й¶������,�������� pop ��������ջ�еĶ���ʱ,�ö��ᱻ������������,��ʹʹ��ջ�ij�����������Щ����,��Ϊջ�ڲ�ά���Ŷ���Щ����Ĺ�������(obsolete reference)����֧���������յ�������,�ڴ�й¶�Ǻ����ε�,�����ڴ�й¶��ʵ��������ʶ�Ķ��֡����һ���������ñ�����ʶ�ı���������,��ô�������������ᴦ���������,Ҳ���ᴦ���ö������õ���������,��ʹ�����Ķ���ֻ����������,Ҳ���ܻᵼ�ºܶ�Ķ����ų�����������֮��,�Ӷ�����������ش�Ӱ��,��������»����� Disk Paging(�����ڴ���Ӳ�̵������ڴ潻������),������� OutOfMemory
������̬������ʵ������������
��̬�����DZ� static ���η����εı���,Ҳ��Ϊ�����,��������,����������κ�һ������,һ����ܴ������ٸ�����,��̬�������ڴ������ҽ���һ������;ʵ����������������ijһʵ��,��Ҫ�ȴ�������Ȼ��ͨ��������ܷ��ʵ�������̬��������ʵ���ö���������ڴ档
����:�� Java ������,���������������ͨ�����д����ľ�̬��Ա��
�Ƿ���Դ�һ����̬(static)�����ڲ������ԷǾ�̬(non-static)�����ĵ���?
������,��̬����ֻ�ܷ��ʾ�̬��Ա,��Ϊ�Ǿ�̬�����ĵ���Ҫ�ȴ�������,�ڵ��þ�̬����ʱ���ܶ���û�б���ʼ����
���ʵ�ֶ����¡?
�����ַ�ʽ:
1). ʵ�� Cloneable �ӿڲ���д Object ���е� clone()����;
2). ʵ�� Serializable �ӿ�,ͨ����������л��ͷ����л�ʵ�ֿ�¡,����ʵ����������ȿ�¡,�������¡�
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class MyUtil {
private MyUtil() {
throw new AssertionError();
}
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T obj) throws
Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new
ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// ˵��:���� ByteArrayInputStream �� ByteArrayOutputStream
����� close ����û���κ�����
// �����������ڴ����ֻҪ��������������������ܹ��ͷ���Դ,��
һ�㲻ͬ�ڶ��ⲿ��Դ(���ļ���)���ͷ�
} }
�����Dz��Դ���:
import java.io.Serializable;
/**
* ����
* @author ���
*
*/
class Person implements Serializable {
private static final long serialVersionUID = -9102017020286042305L;
private String name; // ����
private int age; // ����
private Car car; // ����
public Person(String name, int age, Car car) {
this.name = name;
this.age = age;
this.car = car;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Car getCar() {
return car;
}
public void setCar(Car car) {
this.car = car;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", car=" +
car + "]";
} }
/**
* ������
* @author ���
*
*/
class Car implements Serializable {
private static final long serialVersionUID = -5713945027627603702L;
private String brand; // Ʒ��
private int maxSpeed; // ���ʱ��
public Car(String brand, int maxSpeed) {
this.brand = brand;
this.maxSpeed = maxSpeed;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public int getMaxSpeed() {
return maxSpeed;
}
public void setMaxSpeed(int maxSpeed) {
this.maxSpeed = maxSpeed;
}
@Override
public String toString() {
return "Car [brand=" + brand + ", maxSpeed=" + maxSpeed +
"]";
} }
class CloneTest {
public static void main(String[] args) {
try {
Person p1 = new Person("Hao LUO", 33, new Car("Benz",
300));
Person p2 = MyUtil.clone(p1); // ��ȿ�¡
p2.getCar().setBrand("BYD");
// �Ŀ�¡�� Person ���� p2 ���������������Ʒ������
// ԭ���� Person ���� p1 ���������������ܵ��κ�Ӱ��
// ��Ϊ�ڿ�¡ Person ����ʱ���������������Ҳ����¡��
System.out.println(p1);
} catch (Exception e) {
e.printStackTrace();
} } }
ע��:�������л��ͷ����л�ʵ�ֵĿ�¡����������ȿ�¡,����Ҫ����ͨ��������,���Լ���Ҫ��¡�Ķ����Ƿ�֧�����л�,�������DZ�������ɵ�,����������ʱ�׳��쳣,�����Ƿ�����������ʹ�� Object ��� clone ������¡�����������ڱ����ʱ��¶�������Ǻù���������������ʱ��
GC ��ʲô?ΪʲôҪ�� GC?
GC �������ռ�����˼,�ڴ洦���DZ����Ա���׳�������ĵط�,���ǻ��ߴ�����ڴ���ջᵼ�³����ϵͳ�IJ��ȶ���������,Java �ṩ�� GC ���ܿ����Զ��������Ƿ�������Ӷ��ﵽ�Զ������ڴ��Ŀ��,Java ����û���ṩ�ͷ��ѷ����ڴ����ʾ����������Java ����Ա���õ����ڴ����,��Ϊ�����ռ������Զ����й�����Ҫ���������ռ�,���Ե�������ķ���֮һ:System.gc() ��Runtime.getRuntime().gc() ,�� JVM �������ε���ʾ���������յ��á�
�������տ�����Ч�ķ�ֹ�ڴ�й¶,��Ч��ʹ�ÿ���ʹ�õ��ڴ档����������ͨ������Ϊһ�������ĵ����ȼ����߳�����,����Ԥ֪������¶��ڴ�����Ѿ������Ļ��߳�ʱ��û��ʹ�õĶ����������ͻ���,����Ա����ʵʱ�ĵ���������������ij����������ж�������������ա��� Java ��������,���������� Java��������֮һ,��Ϊ�������˵ı����Ҫ��Ч�ķ�ֹ�ڴ�й¶����,Ȼ��ʱ����Ǩ,��� Java ���������ջ����Ѿ���Ϊ��ڸ���Ķ������ƶ������ն��û�ͨ������ iOS ��ϵͳ�� Android ϵͳ�и��õ��û�����,����һ�����ε�ԭ������� Android ϵͳ���������յIJ���Ԥ֪�ԡ�
String s=new String(��xxc��),�����˼����ַ�������?
String s=new String("xxc");//��������������,һ���Ǿ�̬���ġ�xxc��,һ������new �����ڶ��ϵĶ���
���ڽӿڡ�������;�����֮��ļ̳�(extends)��ʵ��(implements)����
�ӿڿ��Լ̳нӿ�(extends)��֧�ֶ�̳С�;
������( abstract class)����ʵ��(implements)�ӿ�;
��������Լ̳о�����Ҳ���Լ̳г�����
�������ܽ�涨
- ������ܱ�ʵ����(��ѧ�ߺ������Ĵ�),�����ʵ����,�ͻᱨ��,������ͨ����ֻ�г�����ķdz���������Դ�������
- �������в�һ����������,�����г�������ض��dz����ࡣ
- �������еij���ֻ������,������������,���Dz����������ľ���ʵ��Ҳ���Ƿ����ľ��幦�ܡ�
- ���췽��,���(�� static ���εķ���)��������Ϊ������
- ������������������������еij����ľ���ʵ��,���Ǹ�����Ҳ�dz����ࡣ
һ����.java��Դ�ļ����Ƿ�����������(�����ڲ���)?��ʲô����?
����,��һ��Դ�ļ������ֻ����һ��������(public class)�����ļ�������������������ȫ����һ�¡�
Anonymous Inner Class(�����ڲ���)�Ƿ���Լ̳�������?�Ƿ����ʵ�ֽӿ�?
���Լ̳��������ʵ�������ӿ�,�� Swing ��̺� Android �����г��ô˷�ʽ��ʵ���¼������ͻص���
�ڲ�������������İ�����(�ⲿ��)�ij�Ա��?��û��ʲô����?
һ���ڲ��������Է��ʴ��������ⲿ�����ij�Ա,����˽�г�Ա��
Java �е�final�ؼ�������Щ�÷�?
- ������:��ʾ����,���ܱ��̳�;
- ���η���:��ʾ����,���ܱ���д;
- ���α���:��ʾ����,���ܱ����¸�ֵ
��������֮���ת��
���ַ���ת��Ϊ������������:
���û����������Ͷ�Ӧ�İ�װ���еķ��� parseXXX(String)��
valueOf(String)���ɷ�����Ӧ��������;
��������������ת��Ϊ�ַ���:
һ�ַ����ǽ�����������������ַ���(����)����(+)���ɻ������
��Ӧ���ַ���;��һ�ַ����ǵ��� String ���е� valueOf()����������Ӧ�ַ�
����
���ʵ���ַ����ķ�ת���滻?
�����ܶ�,�����Լ�дʵ��Ҳ����ʹ�� String �� StringBuffer/StringBuilder ��
�ķ�������һ���ܳ��������������õݹ�ʵ���ַ�����ת,����������ʾ:
public static String reverse(String originStr) {
if(originStr == null || originStr.length() <= 1)
return originStr;
return reverse(originStr.substring(1)) + originStr.charAt(0);
}
������ GB2312 ������ַ���ת��Ϊ ISO-8859-1 ������ַ���?
����������ʾ:
String s1 = "���";
String s2 = new String(s1.getBytes("GB2312"), "ISO-8859-1");
���ں�ʱ��:
- ���ȡ�������ա�Сʱ������?
���� java.util.Calendar ʵ��,������ get()�������벻ͬ�IJ������ɻ�
�ò�������Ӧ��ֵ��Java 8 �п���ʹ�� java.time.LocalDateTimel ����ȡ,����������ʾ��
public class DateTimeTest {
public static void main(String[] args) {
Calendar cal = Calendar.getInstance();
System.out.println(cal.get(Calendar.YEAR));
System.out.println(cal.get(Calendar.MONTH)); // 0 - 11
System.out.println(cal.get(Calendar.DATE));
System.out.println(cal.get(Calendar.HOUR_OF_DAY));
System.out.println(cal.get(Calendar.MINUTE));
System.out.println(cal.get(Calendar.SECOND));
// Java 8
LocalDateTime dt = LocalDateTime.now();
System.out.println(dt.getYear());
System.out.println(dt.getMonthValue()); // 1 - 12
System.out.println(dt.getDayOfMonth());
System.out.println(dt.getHour());
System.out.println(dt.getMinute());
System.out.println(dt.getSecond());
} }
- ���ȡ�ô� 1970 �� 1 �� 1 �� 0 ʱ 0 �� 0 �뵽���ڵĺ�����?
Calendar.getInstance().getTimeInMillis();
System.currentTimeMillis();
Clock.systemDefaultZone().millis(); // Java 8
- ���ȡ��ij�µ����һ��?
Calendar time = Calendar.getInstance();
time.getActualMaximum(Calendar.DAY_OF_MONTH);
- ��θ�ʽ������?
���� java.text.DataFormat ������(�� SimpleDateFormat ��)�е�
format(Date)�����ɽ����ڸ�ʽ����Java 8 �п�����
java.time.format.DateTimeFormatter ����ʽ��ʱ������,����������ʾ
import java.text.SimpleDateFormat;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Date;
class DateFormatTest {
public static void main(String[] args) {
SimpleDateFormat oldFormatter = new
SimpleDateFormat("yyyy/MM/dd");
Date date1 = new Date();
System.out.println(oldFormatter.format(date1));
// Java 8
DateTimeFormatter newFormatter =
DateTimeFormatter.ofPattern("yyyy/MM/dd");
LocalDate date2 = LocalDate.now();
System.out.println(date2.format(newFormatter));
} }
����:Java ��ʱ������ API һֱ�������DZ�ڸ���Ķ���,Ϊ�˽����һ����,Java8 ���������µ�ʱ������ API,���а��� LocalDate��LocalTime��LocalDateTime��Clock��Instant ����,��Щ�������ƶ�ʹ���˲���ģʽ,������̰߳�ȫ����ơ������������Щ����,����
�Ƽ��ο����ġ����� Java ������̵��ܽ��˼����
�Ƚ�Java��JavaScript
Java �� JavaScript ��֮ͬ��:
| Java | JavaScript | |
|---|---|---|
| *�ô� | �㷺Ӧ����PC�ˡ��ֻ��ˡ����������������ĵȵ� | ��Ҫ����Ƕ���ı���HTMLҳ��,��дHTMLԪ��,����cookies�� |
| ���� | ��SUN Microsystems ��˾�Ƴ�����һ���������ij���������� | ��Netscape(����)��˾�Ľű����� |
| Ƕ�뷽ʽ(��HTML�ĵ���) | ʹ�� Applet ����ʶ�� | ʹ��<script></script> ����ʶ |
| *�������� | �Ǿ�̬�������� | ��̬�������� |
| ����ȡ�ı��� | Java ����ǿ���ͱ������,�����б����ڱ���֮ǰ���������� | JavaScript �еı�����������������,��������ʹ��ǰ����������,���ǽ�����������ʱ����ƶ����������� |
| �����ʽ | Java ��һ���� HTML �صĸ�ʽ,����ͨ���� HTML ��������ý����ô����װ��,��������ֽڴ������ʽ�����ڶ������ĵ���,������ļ��ĸ�ʽΪ *.class;Java ���þ�̬����,�� Java �Ķ������ñ����ڱ���ʱ�Ľ���,��ʹ�������ܹ�ʵ��ǿ���ͼ��;Java ����ֱ�Ӷ��ı���ͼ�ν��в��� | Javascript �Ĵ�����һ�ֶ�̬��,����ֱ��Ƕ�� HTML �ĵ�,���ҿɶ�̬װ��,��д HTML �ĵ�����༭�ı��ļ�һ������,������ļ��ĸ�ʽΪ*.js;Javascript ���ö�̬����,�� Javascript �Ķ�������������ʱ���м�� ;Javascript ��ֱ�Ӷ��ı���ͼ�ν��в���,���� Web ҳ������ HTML Ԫ�����һ������,�������Կ��������,�������ֱ�Ӷ��ı���ͼ�ν��д��� |
| ���ڶ����������� | Java ��һ��������������������,��ʹ�ǿ����ij���,������ƶ��� | JavaScript ���ֽű�����,���������������������ص�,���û��������õĸ�������������һ�ֻ��ڶ���(Object-Based)���¼�����(Event-Driven)�ı������,����������ṩ�˷dz��ḻ���ڲ����������Աʹ�� |
| ���ͺͱ��� | Java ��Դ������ִ��֮ǰ,���뾭������ | JavaScript ��һ�ֽ����Ա������,��Դ���벻�辭������,�����������ִ�С�(Ŀǰ�������������ʹ���� JIT(��ʱ����)���������� JavaScript ������Ч�� |
Java �� JavaScript ��֮ͬ��:
- ���ǵ���� C ���Զ�������;
- ���Ƕ�����������(��Ȼʵ�ֵķ�ʽ���в�ͬ);
- JavaScript �����ʱ������ Java ����������;
�ܶ���֮,JavaScript ���˳��ú� Java �Ƚ���֮��,���Է����ȥ��Զ��JavaScript �����ʱ���ο��Ķ����� Java,���������� Self �� Scheme ���������ԡ���ʱ Netscape ֮���Խ� LiveScript ����Ϊ JavaScript,����Ϊ����(������Sun)��˾һ������������г�, Java �ǵ�ʱ�����еı������,���� ��Java�� �����������������������ԵĴ�����
Java��JavaScript������������ר��,Java����̨�ڱ������,��JavaScript�ĵ���֮������Webҳ����,�������������ܡ�
Java��JavaScript��������ϵ
��Javascript�����ǡ�������һ��
��Javascript�̳л��Ƶ����˼�롷������һ��
Error �� Exception ��ʲô����?
Error ��ʾϵͳ���Ĵ���ͳ��ش������쳣,�ǻָ����Dz����ܵ������ѵ�����µ�һ����������;�����ڴ����,������ָ�������ܴ������������;
Exception ��ʾ��Ҫ��������Ҫ������д������쳣,��һ����ƻ�ʵ������;Ҳ����˵,����ʾ���������������,�Ӳ��ᷢ���������
������:2005 ��Ħ�������������������ʹ���ôһ������
��If a process reports a stack overflow run-time error, what��s the most possible cause?��,
(������̱����˶�ջ�������ʱ����,����ܵ�ԭ����ʲô )
�����ĸ�ѡ��
a. lack of memory;(ȱ������)
b. write on an invalid memory space; (д����Ч���ڴ�ռ�)
c.recursive function calling; (�ݹ麯������)
d. array index out of boundary. (�������������߽�)
Java ����������ʱҲ���ܻ����� StackOverflowError(��ջ�������),����һ�����ָ��Ĵ���,ֻ�������Ĵ����ˡ����д�˲���Ѹ�������ĵݹ�,����п�������ջ����Ĵ���,������ʾ:
class StackOverflowErrorTest {
public static void main(String[] args) {
main(null);
} }
��ʾ:�õݹ��д����ʱһ��Ҫ�μ�����:
- �ݹ鹫ʽ;
- ��������(ʲô��Ͳ��ټ����ݹ�)��
try{}����һ�� return ���,��ô��������� try ���finally{}��Ĵ����ᱻִ��,ʲôʱ��ִ��,�� returnǰ���Ǻ�?
�쳣������,try��catch��finally��ִ��˳��,��Ҷ�֪���ǰ�˳��ִ�еġ���,���try��û���쳣,��˳��Ϊtry��finally,���try�����쳣,��˳��Ϊtry��catch��finally�����ǵ�try��catch��finally�м���return֮��,�ͻ��м��ֲ�ͬ���������,����ֱ�ӿ��ܽᡣ
��ִ��,�ڷ������ص�����ǰִ�С�
�ܽ�:
1��finally�еĴ����ܻᱻִ�С�
2����try��catch����returnʱ,Ҳ��ִ��finally��return��ʱ��,Ҫע�ⷵ��ֵ������,�Ƿ��ܵ�finally�д����Ӱ�졣
3��finally����returnʱ,��ֱ����finally���˳�,����try��catch�е�returnʧЧ��
ע��:�� finally �иı䷵��ֵ�������Dz��õ�,��Ϊ������� finally �����,try
�е� return ��䲻���������ص�����,���Ǽ�¼�·���ֵ�� finally �����ִ����
��֮����������߷�����ֵ,Ȼ������� finally �����˷���ֵ,�ͻ᷵����
���ֵ����Ȼ,�� finally �з��ػ����ķ���ֵ��Գ�����ɺܴ������,C#��
ֱ���ñ������ķ�ʽ����ֹ����Ա����������������,Java ��Ҳ����ͨ������
�����������鼶����������������,Eclipse �п�������ͼ��ʾ�ĵط�����
����,ǿ�ҽ��齫��������Ϊ�������
Java ������ν����쳣����,�ؼ���:throws��throw��try��catch��finally �ֱ����ʹ��?
Java ͨ���������ķ��������쳣����,�Ѹ��ֲ�ͬ���쳣���з���,���ṩ�����õĽӿڡ��� Java ��,ÿ���쳣����һ������,���� Throwable ����������ʵ������һ�����������쳣����׳�һ���쳣����,�ö����а������쳣��Ϣ,�����������ķ������Բ�������쳣�����Զ�����д�����Java ���쳣������ͨ�� 5 ���ؼ�����ʵ�ֵ�:try��catch��throw��throws �� finally��һ����������� try ��ִ��һ�γ���,���ϵͳ���׳�(throw)һ���쳣����,����ͨ����������������(catch)��,��ͨ������ִ�д����(finally)������;try ����ָ��һ��Ԥ�������쳣�ij���;catch �Ӿ������ try �����,����ָ������Ҫ������쳣������;throw ���������ȷ���׳�һ���쳣;throws ��������һ�����������׳��ĸ����쳣(��Ȼ�����쳣ʱ����������);finally Ϊȷ��һ�δ��벻�ܷ���ʲô�쳣״����Ҫ��ִ��;try ������Ƕ��,ÿ������һ�� try �� ���쳣�Ľṹ�ͻᱻ�����쳣ջ��,ֱ�����е� try ��䶼��ɡ������һ����try ���û�ж�ij���쳣���д���,�쳣ջ�ͻ�ִ�г�ջ����,ֱ�������д��������쳣�� try ���������ս��쳣�� JVM��
�г�һЩ�㳣��������ʱ�쳣?
- ArithmeticException(�����쳣)
- ClassCastException (��ת���쳣)
- IllegalArgumentException (�Ƿ������쳣)
- IndexOutOfBoundsException (�±�Խ���쳣)
- NullPointerException (��ָ���쳣)
- SecurityException (��ȫ�쳣)
���� final��finally��finalize ������
final:���η�(�ؼ���)�������÷�:
- �౻����Ϊ final,�������������µ�����,�����ܱ��̳�,������� abstract (�����)�Ƿ���ʡ�
- ��������Ϊ final,���Ա�֤������ʹ���в����ı�,������Ϊ final �ı�������������ʱ������ֵ,�����Ժ��������ֻ�ܶ�ȡ�����ġ�
- ����������Ϊ final,Ҳͬ��ֻ��ʹ��,�����������б���д��
finally:ͨ������ try��catch���ĺ��湹������ִ�д����,�����ζ�ų�����������ִ�л��Ƿ����쳣,����Ĵ���ֻҪ JVM ���رն���ִ��,���Խ��ͷ��ⲿ��Դ�Ĵ���д�� finally ���С�
finalize :Object ���ж���ķ���,Java ������ʹ�� finalize()�����������ռ�����������ڴ��������ȥ֮ǰ����Ҫ����������������������������ռ��������ٶ���ʱ���õ�,ͨ����д finalize()������������ϵͳ��Դ����ִ����������������(finalize �������ڶ�����֮ǰ���õķ���,
�������Լ����һ������Ļ���,����ʲôʱ����� finalize û�б�֤)
List��Set��Map �� Queue ֮�������
List ��һ������,����Ԫ���ظ�������ijЩʵ�ֿ����ṩ�����±�ֵ�ij�������ʱ��,�����ⲻ�� List �ӿڱ�֤�ġ�Set ��һ�����ϡ�
List ��Set ��Map �Ƿ�̳���Collection�ӿ�?�����ӿڴ�ȡԪ��ʱ����ʲô�ص�?
- List ��Set ��,Set �洢����ɢ��Ԫ���Ҳ��������ظ�Ԫ��(��ѧ�еļ���Ҳ�����), List�����Խṹ������,�����ڰ���ֵ��������Ԫ�ص����Ρ�
- Map ����,Map �Ǽ�ֵ��ӳ������
��ȡԪ��ʱ���ص�
- List ���ض���������ȡԪ��,�������ظ�Ԫ�ء�
- Set ���ܴ���ظ�Ԫ��(�ö����equals()����������Ԫ���Ƿ��ظ�)��
- Map �����ֵ��(key-value pair)ӳ��,ӳ���ϵ������һ��һ����һ��
Set �� Map �������л��ڹ�ϣ�洢��������������ʵ�ְ汾,���ڹ�ϣ�洢�İ汾���۴�ȡʱ�临�Ӷ�Ϊ O(1),�������������汾��ʵ���ڲ����ɾ��Ԫ��ʱ�ᰴ��Ԫ�ػ�Ԫ�صļ�(key)�����������Ӷ��ﵽ�����ȥ�ص�Ч����
Collection �� Collections ������?
Collection :��һ���ӿ�,�� List ��Set �����ĸ��ӿ�
Collections :��һ��������,�ṩ��һϵ�еľ�̬������������������,��Щ ���������������������������̰߳�ȫ���ȵȡ�
����˵��ͬ�����첽��
���ϵͳ�д����ٽ���Դ(��Դ�������ھ�����Դ���߳���������Դ),��������д�������Ժ���ܱ���һ���̶߳���,�������ڶ������ݿ����Ѿ�����һ���߳�д����,��ô��Щ���ݾͱ������ͬ����ȡ(���ݿ�����е�������������õ�����)��
��Ӧ�ó����ڶ����ϵ�����һ����Ҫ���Ѻܳ�ʱ����ִ�еķ���,���Ҳ�ϣ���ó���ȴ������ķ���ʱ,��Ӧ��ʹ���첽���,�ںܶ�����²����첽;����������Ч�ʡ�
��ʵ��,��ν��ͬ������ָ����ʽ����,���첽���Ƿ�����ʽ����
����һ���߳��õ���run()����start()����?
����һ���߳��ǵ��� start()����,ʹ�߳�������������������ڿ�����״̬,����ζ���������� JVM ���Ȳ�ִ��,�Ⲣ����ζ���߳̾ͻ��������С�run()�������߳�������Ҫ���лص�(callback)�ķ�����
Java �����ʵ�����л�,��ʲô����?
���л�����һ�����������������Ļ���,��ν������Ҳ���ǽ���������ݽ������������Զ�������Ķ�����ж�д����,Ҳ�ɽ�������Ķ�����������֮�䡣
���л���Ϊ�˽����������д����ʱ��������������(������������л����ܻ�����������������)��
Ҫʵ�����л�,��Ҫ��һ����ʵ�� Serializable �ӿ�,�ýӿ���һ����ʶ�Խӿ�,��ע��������ǿɱ����л���,Ȼ��ʹ��һ�������������һ�������������ͨ�� writeObject(Object)�����Ϳ��Խ�ʵ�ֶ���д��(��������״̬);�����Ҫ�����л��������һ����������������������,Ȼ��ͨ�� readObject ���������ж�ȡ����
���л������ܹ�ʵ�ֶ���ij־û�֮��,���ܹ����ڶ������ȿ�¡
Java ���м������͵���?
�ֽ������ַ�����
�ֽ����̳��� InputStream��OutputStream,
�ַ����̳��� Reader��Writer��
�� java.io ���л���������������,��Ҫ��Ϊ��������ܺ�ʹ�÷��㡣
���� Java �� I/O ��Ҫע���������:
һ�����ֶԳ���(���������ĶԳ���,�ֽں��ַ��ĶԳ���);
�����������ģʽ(������ģʽ��װ��ģʽ)��
���� Java �е�����ͬ�� C#������ֻ��һ��ά��һ������
дһ������,����һ���ļ�����һ���ַ���,ͳ������ַ���������ļ��г��ֵĴ���
import java.io.BufferedReader;
import java.io.FileReader;
public final class MyUtil {
// �������еķ������Ǿ�̬��ʽ���ʵ���˽�������˽�в�������������(���Ժ�ϰ��)
private MyUtil() {
throw new AssertionError();
}
/**
* ͳ�Ƹ����ļ��и����ַ����ij��ִ���
** @param filename �ļ���
* @param word �ַ���
* @return �ַ������ļ��г��ֵĴ���
*/
public static int countWordInFile(String filename, String word) {
int counter = 0;
try (FileReader fr = new FileReader(filename)) {
try (BufferedReader br = new BufferedReader(fr)) {
String line = null;
while ((line = br.readLine()) != null) {
int index = -1;
while (line.length() >= word.length() && (index =
line.indexOf(word)) >= 0) {
counter++;
line = line.substring(index + word.length());
} } } } catch (Exception ex) {
ex.printStackTrace();
}
return counter;
}
}
����� Java �����г�һ��Ŀ¼�����е��ļ�?
���г���ǰ�ļ����µ��ļ�
import java.io.File;
class Test12 {
public static void main(String[] args) {
File f = new File("/Users/Hao/Downloads");
for(File temp : f.listFiles()) {
if(temp.isFile()) {
System.out.println(temp.getName());
}
}
}
}
���ļ��м���չ��
import java.io.File;
class Test12 {
public static void main(String[] args) {
showDirectory(new File("/Users/Hao/Downloads"));
}
public static void showDirectory(File f) {
_walkDirectory(f, 0);
}
private static void _walkDirectory(File f, int level) {
if(f.isDirectory()) {
for(File temp : f.listFiles()) {
_walkDirectory(temp, level + 1);
}
}
else {
for(int i = 0; i < level - 1; i++) {
System.out.print("\t");
}
System.out.println(f.getName());
}
}
}
�� Java 7 �п���ʹ�� NIO.2 �� API ����ͬ��������,����������ʾ:
class ShowFileTest {
public static void main(String[] args) throws IOException {
Path initPath = Paths.get("/Users/Hao/Downloads");
Files.walkFileTree(initPath, new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file,BasicFileAttributes attrs) throws IOException {
System.out.println(file.getFileName().toString());
return FileVisitResult.CONTINUE;
}
});
}
}
������Ŀ����Щ�ط��õ��� XML?
XML ����Ҫ��������������:���ݽ�������Ϣ���á�
�������ݽ���ʱ,XML �������ñ�ǩ��װ������,Ȼ��ѹ��������ܺ�ͨ�����紫��������,���ս������ѹ�����ٴ� XML �ļ��л�ԭ�����Ϣ���д���,XML �������칹ϵͳ�佻�����ݵ���ʵ��,������ܼ����Ѿ��� JSON(JavaScript Object Notation)ȡ����֮����Ȼ,Ŀǰ�ܶ�������Ȼʹ�� XML ���洢������Ϣ,�����ںܶ���Ŀ��ͨ��Ҳ�Ὣ��Ϊ������Ϣ��Ӳ����д�� XML �ļ���,Java �ĺܶ���Ҳ����ô����,������Щ��ܶ�ѡ���� dom4j ��Ϊ���� XML �Ĺ���,��Ϊ Sun ��˾�Ĺٷ�API ʵ�ڲ���ô���á�
����:�����кܶ�ʱ�ֵ�����(�� Sublime)�Ѿ���ʼ�������ļ���д�� JSON��ʽ,�����Ѿ�ǿ�ҵĸ��ܵ� XML ����һ���Ҳ����ҵ��������
���� JDBC �������ݿ�IJ��衣
����Ĵ��������ӱ����� Oracle ���ݿ�Ϊ��,��ʾ JDBC �������ݿ�IJ��衣
- ����������
Class.forName("oracle.jdbc.driver.OracleDriver");
- �������ӡ�
Connection con =
DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:orcl","scott", "tiger");
- ������䡣
PreparedStatement ps = con.prepareStatement("select * from emp where sal between ? and ?");
ps.setInt(1, 1000);
ps.setInt(2, 3000);
- ִ����䡣
ResultSet rs = ps.executeQuery();
- ���������
while(rs.next()) {
System.out.println(rs.getInt("empno") + " - " +
rs.getString("ename"));
}
- �ر���Դ��
finally {
if(con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
��ʾ:�ر��ⲿ��Դ��˳��Ӧ�úʹ�˳���෴,Ҳ����˵�ȹر� ResultSet���ٹر� Statement���ڹر� Connection������Ĵ���ֻ�ر��� Connection(�� ��),��Ȼͨ��������ڹر�����ʱ,�����ϴ��������ʹ��α�Ҳ��ر�,
�����ܱ�֤�������,���Ӧ�ð��ող�˵��˳��ֱ�رա�����,��һ������������ JDBC 4.0 ���ǿ���ʡ�Ե�(�Զ�����·���м�������),�������ǽ��鱣����
ʹ�� JDBC �������ݿ�ʱ,���������ȡ���ݵ�����?��������������ݵ�����?
Ҫ������ȡ���ݵ�����,����ָ��ͨ�������(ResultSet)�����setFetchSize()����ָ��ÿ��ץȡ�ļ�¼��(���͵Ŀռ任ʱ�����);Ҫ�����������ݵ����ܿ���ʹ�� PreparedStatement ��乹��������,������ SQL �������һ����������ִ�С�
�ڽ������ݿ���ʱ,���ӳ���ʲô����?
���ڴ������Ӻ��ͷ����Ӷ��кܴ�Ŀ���(���������ݿ���������ڱ���ʱ,ÿ��
�������Ӷ���Ҫ���� TCP ����������,
�ͷ�������Ҫ���� TCP �Ĵ�����,
��ɵĿ����Dz��ɺ��ӵ�),Ϊ������ϵͳ�������ݿ������,�������ȴ������������������ӳ���,��Ҫʱֱ�Ӵ����ӳػ�ȡ,ʹ�ý���ʱ�黹���ӳض����عر�����,�Ӷ�����Ƶ���������ͷ���������ɵĿ���,���ǵ��͵��ÿռ任ȡʱ��IJ���(�˷��˿ռ�洢����,����ʡ�˴������ͷ����ӵ�ʱ��)��
�ػ�������Java �������Ǻܳ�����,��ʹ���߳�ʱ�����̳߳صĵ��������ͬ������ Java �Ŀ�Դ���ݿ����ӳ���Ҫ��:C3P0��Proxool��DBCP��BoneCP��Druid �ȡ�
����:�ڼ����ϵͳ��ʱ��Ϳռ��Dz��ɵ��͵�ì��,������һ��������������Ҫ����㷨��������Ҫ�ġ�������վ�����Ż���һ���ؼ�����ʹ�û���,����������潲�����ӳص����dz�����,Ҳ��ʹ�ÿռ任ʱ��IJ��ԡ����Խ��ȵ��������ڻ�����,���û���ѯ��Щ����ʱ����ֱ�Ӵӻ����еõ�,���������Ҳ���ȥ���ݿ��в�ѯ����Ȼ,������û����Ե�Ҳ���ϵͳ���ܲ�����ҪӰ��,�����������������Ѿ�����������Ҫ�����ķ�Χ��
ʲô��DAOģʽ?
ʲô��DAOģʽ
DAO(Data Access Object)����˼����һ��Ϊ���ݿ�������־û������ṩ�˳���ӿڵĶ���,�ڲ���¶�ײ�־û�����ʵ��ϸ�ڵ�ǰ�����ṩ�˸������ݷ��ʲ�������ʵ�ʵĿ�����,Ӧ�ý����ж�����Դ�ķ��ʲ������г����װ��һ������API�С��ó������������˵,���ǽ���һ���ӿ�,�ӿ��ж����˴�Ӧ�ó����н����õ������������������Ӧ�ó�����,����Ҫ������Դ���н�����ʱ����ʹ������ӿ�,���ұ�дһ������������ʵ������ӿ�,�����ϸ����Ӧһ���ض������ݴ洢��DAOģʽʵ���ϰ���������ģʽ,һ��Data Accessor(���ݷ�����),����Data Object(���ݶ���),ǰ��Ҫ�����η������ݵ�����,������Ҫ�����������ö����װ���ݡ�
poll() ������ remove() ����������?
poll() �� remove() ���ǴӶ�����ȡ��һ��Ԫ��,���� poll() �ڻ�ȡԪ��ʧ��
��ʱ��᷵�ؿ�,���� remove() ʧ�ܵ�ʱ����׳��쳣��
ArrayList �� LinkedList �IJ�����?
�����Ե������� ArrrayList �ײ�����ݽṹ������,֧���������,��
LinkedList �ĵײ����ݽṹ������,��֧��������ʡ�ʹ���±����һ��Ԫ��,ArrayList ��ʱ�临�Ӷ��� O(1),�� LinkedList �� O(n)��
�����������ʽ������;��
�ڱ�д�����ַ����ij���ʱ,�������в��ҷ���ijЩ���ӹ�����ַ�������Ҫ���������ʽ��������������Щ����Ĺ��ߡ����仰˵,�������ʽ���Ǽ�¼�ı�����Ĵ��롣
˵��:������������ڴ�������Ϣ����������ֵ,����ʱ����Ǩ,��������ʹ�ü������������Ϣ�����ʱ������ֵ�����ַ���,�������ʽ�����ڽ����ַ���ƥ��ʹ�����ʱ����Ϊǿ��Ĺ���,����������Զ��ṩ�˶��������ʽ��֧�֡�
Java �������֧���������ʽ������?
Java �е� String ���ṩ��֧���������ʽ�����ķ���,����:matches()��
replaceAll()��replaceFirst()��split()������,Java �п����� Pattern ���ʾ�������ʽ����,���ṩ�˷ḻ�� API ���и����������ʽ����,��ο�����������Ĵ��롣
������: - ���Ҫ���ַ����н�ȡ��һ��Ӣ��������֮ǰ���ַ���,����:������(������)(������)(������),��ȡ���Ϊ:������,��ô�������ʽ��ôд?
import java.util.regex.Matcher;
import java.util.regex.Pattern;
class RegExpTest {
public static void main(String[] args) {
String str = "������(������)(������)(������)";
Pattern p = Pattern.compile(".*?(?=\\()");
Matcher m = p.matcher(str);
if(m.find()) {
System.out.println(m.group());
}
}
}
���һ��������������Щ��ʽ?
- ���� 1:����.class,����:String.class
- ���� 2:����.getClass(),����:��hello��.getClass()
- ���� 3:Class.forName(),����:Class.forName(��java.lang.String��)
����һ���������ġ���ԭ��һ����
-
��һְ��ԭ��:һ����ֻ�������������顣(��һְ��ԭ�������ľ��ǡ����ھۡ�,д�������ռ���ԭ��ֻ�������֡����ھۡ�����ϡ�,����ͬ����������а��������˼��Ͱ˸��֡������˹������Թ���,��ν�ĸ��ھ۾���һ������ģ��ֻ���һ���,�����������,���ֻ��һ�����������������,�����漰�����ص�������Ǽ����˸��ھ۵�ԭ��,������ֻ�е�һְ�����Ƕ�֪��һ�仰�С���Ϊרע,����רҵ��,һ����������е�̫���ְ��,��ôע����ʲô�������á�����������κκõĶ���������������,һ���ǹ��ܵ�һ,�õ�������Բ��ǵ��ӹ���������������һ��������һ�ٶ��ֹ��ܵ�,��������ֻ������;��һ����ģ�黯,�õ����г�����װ��,�Ӽ���桢ɲ����������,���еIJ������ǿ��Բ�ж��������װ��,�õ�ƹ������Ҳ���dz�Ʒ��,һ���ǵװ�ͽ�Ƥ���Բ�ֺ�������װ��,һ���õ�����ϵͳ,�������ÿ������ģ��ҲӦ���ǿ��������õ�����ϵͳ��ʹ�õ�,��������ʵ���������õ�Ŀ�ꡣ)
-
����ԭ��:����ʵ��Ӧ������չ����,���Ĺرա�(�������״̬��,��������ҪΪһ������ϵͳ�����¹���ʱ,ֻ��Ҫ��ԭ����ϵͳ������һЩ����Ϳ���,����Ҫ��ԭ�����κ�һ�д��롣Ҫ��������������Ҫ��:
�ٳ����ǹؼ�,һ��ϵͳ�����û�г������ӿ�ϵͳ��û����չ��;
�ڷ�װ�ɱ���,��ϵͳ�еĸ��ֿɱ����ط�װ��һ���̳нṹ��,�������ɱ����ػ�����һ��,ϵͳ����ø��Ӷ�����,����������η�װ�ɱ���,���Բο������ģʽ���⡷һ���ж�����ģʽ�Ľ�����½ڡ�) -
������תԭ��:����ӿڱ�̡�(��ԭ��˵��ֱ�;���һЩ�������������IJ������͡������ķ������͡���������������ʱ,������ʹ�ó������Ͷ����þ�������,��Ϊ�������Ϳ��Ա������κ�һ�������������,��ο�����������滻ԭ��)
-
�����滻ԭ��:�κ�ʱ�������������滻�������͡�(���������滻ԭ�������,Barbara Liskov Ůʿ�����������Ҫ���ӵö�,����˵�������ø����͵ĵط���һ����ʹ�������͡������滻ԭ����Լ��̳й�ϵ�Ƿ����,���һ���̳й�ϵΥ���������滻ԭ��,��ô����̳й�ϵһ���Ǵ����,��Ҫ�Դ�������ع���������è�̳й�,���߹��̳�è,�ֻ����������μ̳г����ζ��Ǵ���ļ̳й�ϵ,��Ϊ��������ҵ�Υ�������滻ԭ��ij�������Ҫע�����:����һ�������Ӹ�������������Ǽ��ٸ��������,��Ϊ����ȸ������������,��������Ķ��������ٵĶ������õ�Ȼû���κ����⡣)
-
�ӿڸ���ԭ��:�ӿ�ҪС��ר,�����ܴ��ȫ��(ӷ�Ľӿ��ǶԽӿڵ���Ⱦ,��Ȼ�ӿڱ�ʾ����,��ôһ���ӿ�ֻӦ������һ������,�ӿ�ҲӦ���Ǹ߶��ھ۵ġ�����,�����黭��Ӧ�÷ֱ����Ϊ�ĸ��ӿ�,����Ӧ��Ƴ�һ���ӿ��е��ĸ�����,��Ϊ�����Ƴ�һ���ӿ��е��ĸ�����,��ô����ӿں�����,�Ͼ������黭��������ͨ���˻�������,�������Ƴ��ĸ��ӿ�,�Ἰ���ʵ�ּ����ӿ�,�����Ļ�ÿ���ӿڱ����õĿ������Ǻܸߵġ�Java �еĽӿڴ�������������Լ����������ɫ,�ܷ���ȷ��ʹ�ýӿ�һ���DZ��ˮƽ�ߵ͵���Ҫ��ʶ��)
-
�ϳɾۺϸ���ԭ��:����ʹ�þۺϻ�ϳɹ�ϵ���ô��롣(ͨ���̳������ô�������������������б����õ����Ķ���,��Ϊ���еĽ̿��鶼��һ����ĶԼ̳н����˹Ĵ��Ӷ����˳�ѧ��,������֮���˵�����ֹ�ϵ,Is-A ��ϵ��Has-A ��ϵ��Use-A ��ϵ,�ֱ�����̳С�����������������,������ϵ�����������ǿ���ֿ��Խ�һ������Ϊ�������ۺϺͺϳ�,��˵���˶���Has-A ��ϵ,�ϳɾۺϸ���ԭ�������������ȿ��� Has-A ��ϵ������ Is-A ��ϵ���ô���,ԭ��������Լ��Ӱٶ����ҵ�һ�������,��Ҫ˵������,��ʹ��
Java �� API ��Ҳ�в������ü̳е�����,���� Properties ��̳��� Hashtable��,Stack ��̳��� Vector ��,��Щ�̳����Ծ��Ǵ����,���õ���������Properties ���з���һ�� Hashtable ���͵ij�Ա���ҽ������ֵ������Ϊ�ַ������洢����,�� Stack ������ҲӦ������ Stack ���з�һ�� Vector �������洢���ݡ���ס:�κ�ʱ��Ҫ�̳й�����,�����ǿ���ӵ�в�����ʹ�õ�,�����������̳еġ�) -
�����ط���:�����ط����ֽ�����֪ʶԭ��,һ������Ӧ�������������о������ٵ��˽⡣(�����ط����˵�����������������ϡ�,����ģʽ�͵�ͣ��ģʽ���ǶԵ����ط���ļ��С���������ģʽ���Ծ�һ��������,��ȥһ�ҹ�˾Ǣ̸ҵ��,�㲻��Ҫ�˽������˾�ڲ������������,���������Զ������˾һ����֪,ȥ��ʱ��ֻ��Ҫ�ҵ���˾��ڴ���ǰ̨��Ů,����������Ҫ��ʲô,���ǻ��ҵ����ʵ��˸����Ǣ,ǰ̨����Ů���ǹ�˾���ϵͳ�����档�ٸ��ӵ�ϵͳ������Ϊ�û��ṩһ��������,Java Web ��������Ϊǰ�˿������� Servlet �� Filter ������һ��������,������Է�������������ʽһ����֪,����ͨ��ǰ�˿��������ܹ������������õ���Ӧ�ķ���ͣ��ģʽҲ���Ծ�һ����������˵��,����һ̨�����,CPU���ڴ桢Ӳ�̡��Կ������������豸��Ҫ���ϲ��ܺܺõĹ���,���������Щ������ֱ�����ӵ�һ��,������IJ��߽��쳣����,�����������,������Ϊһ����ͣ�ߵ����ݳ���,���������豸������һ�������Ҫÿ���豸֮��ֱ�ӽ�������,�����ͼ�С��ϵͳ����϶Ⱥ��Ӷ�,����ͼ��ʾ�������ط�����ͨ�Ļ��������Dz�Ҫ��İ���˴�,��������Ҫ,��һ���Լ�������,���������İ���˴���)
****����һ�����˽�����ģʽ��
��ν���ģʽ,����һ�ױ�����ʹ�õĴ�����ƾ�����ܽ�(�龳��һ�����⾭��֤ʵ��һ���������)��ʹ�����ģʽ��Ϊ�˿����ô��롢�ô�������ױ��������⡢��֤����ɿ��ԡ����ģʽʹ���ǿ��Ը��Ӽ���ĸ��óɹ�����ƺ���ϵ�ṹ������֤ʵ�ļ������������ģʽҲ��ʹ��ϵͳ�����߸����������������˼·��
�� 23 �����ģʽ,����:
***Abstract Factory(����ģʽ),
Builder(������ģʽ),
Factory Method(��������ģʽ),
Prototype(ԭʼģ��ģʽ),
*Singleton(����ģʽ:����ʽ����;����ʽ����);
Facade(����ģʽ),
***Adapter(������ģʽ),
Bridge(����ģʽ),
Composite(�ϳ�ģʽ),
Decorator(װ��ģʽ),
Flyweight(��Ԫģʽ),
***Proxy(����ģʽ);
Command(����ģʽ)
Interpreter(������ģʽ),
Visitor(������ģʽ),
Iterator(������ģʽ),
Mediator(��ͣ��ģʽ),
Memento(����¼ģʽ),
Observer(�۲���ģʽ),
State(״̬ģʽ),
Strategy(����ģʽ),
***Template Method(ģ�巽��ģʽ),
Chain Of Responsibility(������ģʽ)��
-
����ģʽ:��������Ը����������ɲ�ͬ������ʵ��,��Щ������һ�������ij����ಢ��ʵ������ͬ�ķ���,������Щ������Բ�ͬ�����ݽ����˲�ͬ�IJ���(��̬����)�����õ������ʵ����,������Ա���Ե��û����еķ��������ؿ��ǵ����ص�����һ�������ʵ����
-
����ģʽ:��һ�������ṩһ����������,���ɴ����������ԭ��������á�ʵ�ʿ�����,����ʹ��Ŀ�ĵIJ�ͬ,�������Է�Ϊ:Զ�̴������������������������Cache ����������ǽ������ͬ�����������������ô�����
-
������ģʽ:��һ����Ľӿڱ任�ɿͻ������ڴ�����һ�ֽӿ�,�Ӷ�ʹ
ԭ����ӿڲ�ƥ�������һ��ʹ�õ����ܹ�һ������ -
ģ�巽��ģʽ:�ṩһ��������,���������Ծ��巽������������ʽ
ʵ��,Ȼ������һЩ��������ʹ����ʵ��ʣ���������ͬ����������Բ�ͬ�ķ�ʽʵ����Щ����(��̬ʵ��),�Ӷ�ʵ�ֲ�ͬ��ҵ������
Singleton(����ģʽ:����ʽ����;����ʽ����);
����ʽ����
public class Singleton {
private Singleton(){}
private static Singleton instance = new Singleton();
public static Singleton getInstance(){
return instance;
}
}
����ʽ����
public class Singleton {
private static Singleton instance = null;
private Singleton() {}
public static synchronized Singleton getInstance(){
if (instance == null) instance = new Singleton();
return instance;
}
}
ע��:ʵ��һ������������ע������,
�ٽ�������˽��,���������ͨ����������������;
��ͨ�������ľ�̬��������緵�����Ψһʵ����������һ�������
��˼��:Spring �� IoC ��������Ϊ��ͨ���ഴ������,������ô��������?���
�� Java дһ��ð������
ð�����������Գ��ʵ�����,�����вο�����
import java.util.Comparator;
/**
* �������ӿ�(����ģʽ: ���㷨��װ�����й�ͬ�ӿڵĶ���������ʹ�����ǿ�
����滻) * @author ���
*/
public interface Sorter {
/**
* ����
* @param list �����������
*/
public <T extends Comparable<T>> void sort(T[] list);
/**
* ����
* @param list �����������
* @param comp �Ƚ���������ıȽ���
*/
public <T> void sort(T[] list, Comparator<T> comp);
}
import java.util.Comparator;
/**
* ����
** @author ���
*
*/
public class BubbleSorter implements Sorter {
@Override
public <T extends Comparable<T>> void sort(T[] list) {
boolean swapped = true;
for (int i = 1, len = list.length; i < len && swapped; ++i) {
swapped = false;
for (int j = 0; j < len - i; ++j) {
if (list[j].compareTo(list[j + 1]) > 0) {
T temp = list[j];
list[j] = list[j + 1];
list[j + 1] = temp;
swapped = true;
}
}
}
}
@Override
public <T> void sort(T[] list, Comparator<T> comp) {
boolean swapped = true;
for (int i = 1, len = list.length; i < len && swapped; ++i) {
swapped = false;
for (int j = 0; j < len - i; ++j) {
if (comp.compare(list[j], list[j + 1]) > 0) { T temp = list[j];
list[j] = list[j + 1];
list[j + 1] = temp;
swapped = true;
}
}
}
}
}
ʲô���¼���ð��?�¼�����?�¼���?
�¼���:��һ��HTMLԪ�ز���һ���¼�ʱ,���¼�����Ԫ�ؽڵ�����ڵ�֮���·������,·���������Ľڵ㶼���յ����¼�,��������Ĺ��̽���DOM�¼���Ԫ�ش����¼�ʱ,�¼��Ĵ������̳�Ϊ�¼���,���̷�Ϊ�����ð������
�¼�ð��:������� �¼�����Ԫ�ش��ݵ���Ԫ�صĹ���,����ð��
�¼�����:��������� �¼��ɸ�Ԫ�ص���Ԫ�ش��ݵĹ���,�����¼�����
ð�������㷨
ð�������㷨��ԭ������:
- �Ƚ����ڵ�Ԫ�ء������һ���ȵڶ�����,�ͽ�������������
- ��ÿһ������Ԫ����ͬ���Ĺ���,�ӿ�ʼ��һ�Ե���β�����һ�ԡ�����һ��,����Ԫ��Ӧ�û�����������
- ������е�Ԫ���ظ����ϵIJ���,�������һ����
- ����ÿ�ζ�Խ��Խ�ٵ�Ԫ���ظ�����IJ���,ֱ��û���κ�һ��������Ҫ�Ƚϡ�
�Ƽ�:ð�������㷨(������ϸ)
�� Java дһ���۰���ҡ�(���ַ�)
�۰����,Ҳ�ƶ��ֲ��ҡ���������,��һ�������������в���ijһ�ض�Ԫ�ص������㷨�����ع��̴�������м�Ԫ�ؿ�ʼ,����м�Ԫ��������Ҫ���ҵ�Ԫ��,�����ع��̽���;���ijһ�ض�Ԫ�ش��ڻ���С���м�Ԫ��,����������ڻ�С���м�Ԫ�ص���һ���в���,���Ҹ���ʼһ�����м�Ԫ�ؿ�ʼ�Ƚϡ������ijһ���������Ѿ�Ϊ��,���ʾ�Ҳ���ָ����Ԫ�ء����������㷨ÿһ�αȽ϶�ʹ������Χ��Сһ��,��ʱ�临�Ӷ��� O(logN)��
import java.util.Comparator;
public class MyUtil {
public static <T extends Comparable<T>> int binarySearch(T[] x, T key) {
return binarySearch(x, 0, x.length- 1, key);
}
// ʹ��ѭ��ʵ�ֵĶ��ֲ���
public static <T> int binarySearch(T[] x, T key, Comparator<T> comp){
int low = 0;
int high = x.length - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
int cmp = comp.compare(x[mid], key);
if (cmp < 0) {
low= mid + 1;
}
else if (cmp > 0) {
high= mid - 1;
}
else {
return mid;
}
}
return -1;
}
// ʹ�õݹ�ʵ�ֵĶ��ֲ���
private static<T extends Comparable<T>> int binarySearch(T[] x, int low, int high, T key) {
if(low <= high) {
int mid = low + ((high -low) >> 1);
if(key.compareTo(x[mid])== 0) {
return mid;
}
else if(key.compareTo(x[mid])< 0) {
return binarySearch(x,low, mid - 1, key);
}
else {
return binarySearch(x,mid + 1, high, key);
}
}
return -1;
}
}
˵��:����Ĵ����и������۰���ҵ������汾,һ���õݹ�ʵ��,һ����ѭ��ʵ�֡���Ҫע����Ǽ����м�λ��ʱ��Ӧ��ʹ��(high+ low) / 2 �ķ�ʽ,��Ϊ�ӷ�������ܵ�������Խ��,����Ӧ��ʹ���������ַ�ʽ֮һ:
low + (high - low)/ 2 �� low + (high �C low) >> 1 ��(low + high) >>> 1
(>>>��������,�Dz������������)
Java ��Ӧ��ʹ��ʲô���������������۸�?
��������ر�����ڴ�����ܵĻ�,ʹ��BigDecimal
���ʹ��Ԥ���徫�ȵĻ�,ʹ��double(˫���ȸ�����)
��ô�� byte ת��Ϊ String?�� bytes ת��Ϊ long ����?
- byte ת��Ϊ String
����ʹ�� String ���� byte[] �����Ĺ�����������ת��,��Ҫע��ĵ���Ҫ�õ���ȷ�ı���,�����ʹ��ƽ̨Ĭ�ϱ���,���������ܸ�ԭ���ı�����ͬ,Ҳ���ܲ�ͬ�� - �� bytes ת��Ϊ long ����
������:
(1)Java����ʵ��,�����������κ��Ѿ��е���,ֱ�ӽ���ת��
(2)����java.nio.ByteBufferʵ��,ֻҪ��byte[]ת��ΪByteBuffer�Ϳ���ʵ������primitive���͵����ݶ�ȡ��
(3)����java.io.DataInputStreamʵ��,ֻҪ��byte[]ת��ΪDataInputStream�Ϳ���ʵ������primitive���͵����ݶ�ȡ��
��������:java:bytes[]תlong�����ַ�ʽ
package net.gdface.facelog;
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import org.junit.Test;
public class TestSerialVersionUID {
/**
* ����MD5����
*
* @param source
* @return
*/
static public byte[] getMD5(byte[] source) {
if (null==source)
return null;
try {
MessageDigest md = MessageDigest.getInstance("MD5");
return md.digest(source);
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
return null;
}
/**
* ��16λbyte[] ת��Ϊ32λ��HEX��ʽ���ַ���String
*
* @param buffer
* @return
*/
static public String toHex(byte buffer[]) {
if (null==buffer)
return null;
StringBuffer sb = new StringBuffer(buffer.length * 2);
for (int i = 0; i < buffer.length; i++) {
sb.append(Character.forDigit((buffer[i] & 240) >> 4, 16));
sb.append(Character.forDigit(buffer[i] & 15, 16));
}
return sb.toString();
}
/**
* ���ֽ�����תΪlong<br>
* ���inputΪnull,��offsetָ����ʣ�����鳤�Ȳ���8�ֽ����׳��쳣
* @param input
* @param offset ��ʼƫ����
* @param littleEndian ���������Ƿ�С��ģʽ
* @return
*/
public static long longFrom8Bytes(byte[] input, int offset, boolean littleEndian){
if(offset <0 || offset+8>input.length)
throw new IllegalArgumentException(String.format("less than 8 bytes from index %d is insufficient for long",offset));
long value=0;
for(int count=0;count<8;++count){
int shift=(littleEndian?count:(7-count))<<3;
value |=((long)0xff<< shift) & ((long)input[offset+count] << shift);
}
return value;
}
/**
* ���� {@link java.nio.ByteBuffer}ʵ��byte[]תlong
* @param input
* @param offset
* @param littleEndian ���������Ƿ�С��ģʽ
* @return
*/
public static long bytesToLong(byte[] input, int offset, boolean littleEndian) {
if(offset <0 || offset+8>input.length)
throw new IllegalArgumentException(String.format("less than 8 bytes from index %d is insufficient for long",offset));
ByteBuffer buffer = ByteBuffer.wrap(input,offset,8);
if(littleEndian){
// ByteBuffer.order(ByteOrder) ����ָ���ֽ���,����С��ģʽ(BIG_ENDIAN/LITTLE_ENDIAN)
// ByteBuffer Ĭ��Ϊ���(BIG_ENDIAN)ģʽ
buffer.order(ByteOrder.LITTLE_ENDIAN);
}
return buffer.getLong();
}
@Test
public void test() throws IOException {
String input="net.gdface.facelog.dborm.person.FlPersonBeanBase";
byte[] md5 = getMD5(input.getBytes());
System.out.printf("md5 [%s]\n",toHex(md5));
// ���ַ�ʽ�������Ա���֤
DataInputStream dataInput = new DataInputStream(new ByteArrayInputStream(md5));
long l1 = dataInput.readLong();
long l2 = dataInput.readLong();
System.out.printf("l1=0x%x l2=0x%x,DataInputStream\n", l1,l2);
long ln1 = bytesToLong(md5,0, false);
long ln2 = bytesToLong(md5,8, false);
System.out.printf("ln1=0x%x ln2=0x%x,ByteBuffer\n", ln1,ln2);
long ll1 = longFrom8Bytes(md5,0, false);
long ll2 = longFrom8Bytes(md5,8, false);
System.out.printf("ll1=0x%x ll2=0x%x\n", ll1,ll2);
}
}
������:
md5 [39627933ceeebf2740e1f822921f5837]
l1=0x39627933ceeebf27 l2=0x40e1f822921f5837,DataInputStream
ln1=0x39627933ceeebf27 ln2=0x40e1f822921f5837,,ByteBuffer
ll1=0x39627933ceeebf27 ll2=0x40e1f822921f5837
�Ƽ�:��Java �� byte��byte ����� int��long ֮���ת����
�����ܽ� int ǿ��ת��Ϊ byte ���͵ı�����?�����ֵ���� byte ���͵ķ�Χ,�������ʲô����?
���Ե�,ֻ��int��32λ��,��byte��8λ,��ʱ�����Ҫת���Ļ��ͱ������ǿ��ת����(��תС),��Ȼ����ת��ʱ�������ֻᱻ�ص���
����������,B �̳� A,C �̳� B,�����ܽ� B ת��ΪC ô?�� C = ? B;
���Ե�,���ݼ̳й�ϵ����ת��ʱ�dz�����
��ͼ�����ȷ�
�������:(��Դ֪����)
class B {
@Override
public String toString() {
return "This is cat";
}
}
class C extends B {
@Override
public String toString() {
return "This is black cat";
}
}
//����ת��
public class Test {
public static void main(String[] args) {
B b = new B();
C c = (C) b;
System.out.println(c.toString());
}
}
//���Խ��:Exception in thread "main" java.lang.ClassCastException: B cannot be cast to C at Test.main(Test.java:4)
//����ת��
public class Test {
public static void main(String[] args) {
B b = new C();
C c = (C) b;
System.out.println(c.toString());
}
}
//���Խ�����:This is black cat
Java �� ++ ���������̰߳�ȫ����?
�����̰߳�ȫ�IJ��������漰�����ָ��,���ȡ����ֵ,
����,Ȼ��洢���ڴ�,������̿��ܻ���ֶ���߳̽���
�����ڲ�����ǿ��ת��������½�һ�� double ֵ��ֵ��long ���͵ı�����?
����,��Ϊdouble���͵ķ�Χ��long���͵ķ�Χ��
3*0.1 == 0.3 ���᷵��ʲô?true ���� false?
false,��Ϊ��Щ������������ȫ��ȷ�ı�ʾ������
int �� Integer �ĸ���ռ�ø�����ڴ�?
Integer �����ռ�ø�����ڴ档Integer ��һ������,��Ҫ�洢�����Ԫ���ݡ����� int ��һ��ԭʼ���͵�����,����ռ�õĿռ���١�
Ϊʲô Java �е� String �Dz��ɱ��(Immutable)?
Java �е� String ���ɱ�����Ϊ Java ���������Ϊ�ַ���ʹ�÷dz�Ƶ��,���ַ�������Ϊ���ɱ������������ͻ���֮�乲����ͬ���ַ�����
Java �е� HashSet,�ڲ�����ι�����?
HashSet ���ڲ����� HashMap ��ʵ�֡����� Map ��Ҫ key �� value,����
���� key �Ķ���һ��Ĭ�� value�������� HashMap,HashSet �������ظ���
key,ֻ������һ�� null key,��˼���� HashSet ��ֻ�����洢һ�� null ����
дһ�δ����ڱ��� ArrayList ʱ�Ƴ�һ��Ԫ��?
������Ĺؼ�����������ʹ�õ��� ArrayList �� remove() ���� Iterator ��
remove()����������һ��ʾ������,��ʹ����ȷ�ķ�ʽ��ʵ���ڱ����Ĺ������Ƴ�Ԫ��,��������� ConcurrentModificationException �쳣��ʾ�����롣
�������Լ�дһ��������,Ȼ��ʹ�� for-each ѭ����?
����,�����дһ���Լ��������ࡣ�������ʹ�� Java ����ǿ��ѭ��������,��ֻ��Ҫʵ�� Iterable �ӿڡ������ʵ�� Collection �ӿ�,Ĭ�Ͼ;��и����ԡ�
��û�п�����������ȵĶ���������ͬ�� hashcode?
�п���,��������ȵĶ�����ܻ�����ͬ�� hashcode ֵ,�����Ϊʲô��
hashmap �л��г�ͻ����� hashcode ֵ�Ĺ涨ֻ��˵��������������,��������ͬ�� hashcode ֵ,����û�й��ڲ���ȶ�����κι涨��
���ǿ�����hashcode()��ʹ����������� ?
����,��Ϊ�����hashcode ֵ��������ͬ�ġ�
�Ƽ�:Java��hashcode������
Java ��,Comparator �� Comparable ��ʲô��ͬ?
| Comparator | Comparable |
|---|---|
| comparator ͨ�����ڶ����û����Ƶ�˳�� | Comparable �ӿ����ڶ���������Ȼ˳�� |
| �����ж�� comparator ����������˳�� | Comparable ����ֻ��һ�� |
Ϊʲô����д equals ������ʱ����Ҫ��д hashCode ����?
��Ϊ��ǿ�ƵĹ淶ָ�� ��Ҫͬʱ��д hashcode �� equal ����,����������, �� HashMap��HashSet �������� hashcode �� equals �Ĺ涨
Java IO �� NIO
ʲô�� Java IO ?ԭ����ʲô?
Java IO:Java���������
Java Ioԭ��:
IO�����������豸֮������ݴ���,Java������,�������ݵ�����/������� �����ԡ������ķ�ʽ���еġ�java.io�����ṩ�˸��֡�������Ľӿ�,���Ի�ȡ��ͬ���������,��ͨ�����ķ��������������ݡ�
���ڼ������˵,���ݶ����Զ�������ʽ������д��ġ����ǿ����ļ�����Ϊһ��Ͱ,���ǿ���ͨ���ܵ���Ͱ���ˮ�����������Ĺܵ�Ҳ���൱��Java�е��������ı�����һ����������ݼ���,������Դ��Ŀ�ĵء�
������Java.io��������Ҫ�ľ���5�����һ���ӿڡ�5����ָ����File��OutputStream��InputStream��Writer��Reader;һ���ӿ�ָ����Serializable.��������ЩIO�ĺ��IJ�����ô����Java�е�IO��ϵҲ������һ����������ʶ��
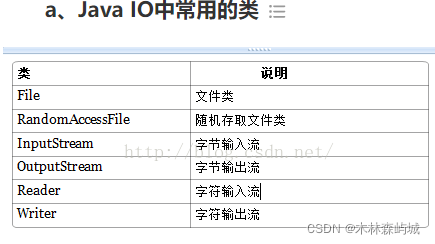
���ķ���
�������ķ���(������붼��վ�ڳ��������ڴ�ĽǶȻ��ֵ�)
������:ֻ�ܴ��ж�����
�����:ֻ�����ļ���д����
�������IJ�����Ԫ
�ֽ���: InputStream OutputStream
�������ݽ���Ϊԭʼ�Ķ��������� ; ��д��Ϊ�ֽ�����;���������ݲ���Ҫ����ͽ���,���ı�IoЧ�ʸ���;����ֲ(��������뷽ʽ��)��
�ַ���:Reader Writer
�ڵ���: �Ӿ�����ʶ�д���ݵ���
������:�Խڵ������а�װ�����ض��Ĵ���
�ֽ����ַ�������
A,��д��λ��ͬ,�ֽ������ֽ�Ϊ��λ(һ���ֽ�Ϊ8bitλ),�ַ������ַ�Ϊ��λ
B,��������ͬ,�ֽ������Դ����κ����� �ַ���ֻ�ܴ����ַ������������
�ֽ�ת��Ϊ�ַ�����:�����(�����ַ����ֽڵ�ӳ���ϵ) ASCII(����һ���� �ڴ洢����,һ���ֽڵ�7��bitλ)
GBK:��Ҫ��������,���������ֽڴ洢����) utf-8(��Unicode�����ʽ���� ��,һ���ֽڴ洢
Unicode:2���ֽ�,�����Ǵ������ĵ�
���롢������
charSet
URLEncode,URLDecode ��ҳ������ر��������
���ս�ɫ����
�ڵ���: ����ֱ�����ӵ�ʵ�ʵ�����Դ InputStream
������: ��һ���Ѵ��ڵ������з�װ BufferInputStream
| �ֽ��� | �ַ��� | |
|---|---|---|
| ������ | InputStream | Reader |
| ����� | OutputStream | Writer |
����:��ȡ�ⲿ����(���̡����̵ȴ洢�豸������)������(�ڴ�)�С�
���:������(�ڴ�)������������̡����̵ȴ洢�豸��
Java�������ṹͼ;
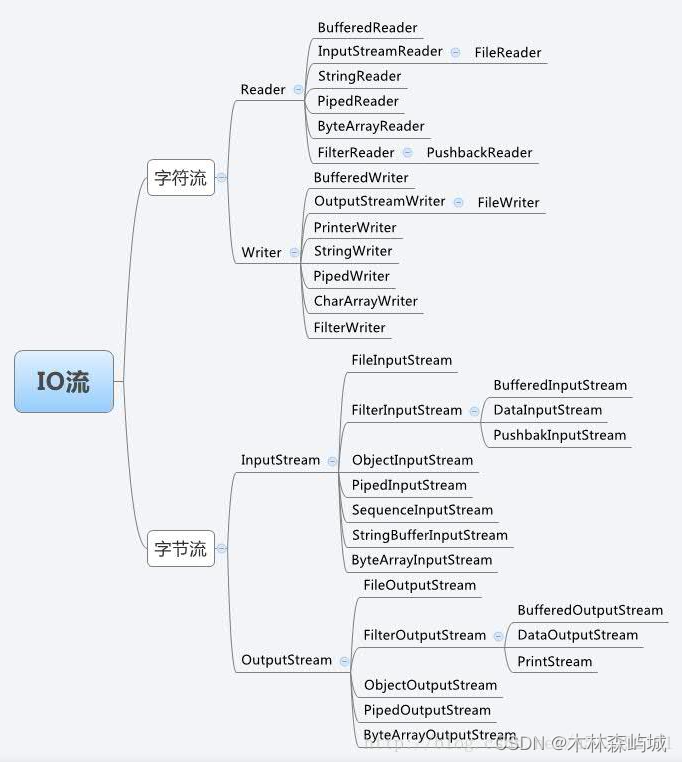
����java io �Ƚϻ�����һЩ������,����֮�����ǻ����ᵽһЩ�Ƚ�����Ļ���io�Ĵ�����,����console��,SteamTokenzier,Externalizable�ӿ�,Serializable�ӿڵȵ�һЩ���÷�����ԭ
��Դ:https://www.cnblogs.com/ylspace/p/8128112.html
��Ҫ��������:
1. File(�ļ����������):�����ļ�����Ŀ¼��������Ϣ,����������Ŀ¼,���ļ���,ɾ���ļ�,�ж��ļ�����·���ȡ�
2. InputStream(�����Ƹ�ʽ����):������,�����ֽڵ��������,�������������ĸ��ࡣ���������������������еĹ�ͬ������
3. OutputStream(�����Ƹ�ʽ����):�����ࡣ�����ֽڵ����������������������ĸ��ࡣ��������������������еĹ�ͬ������
4.Reader(�ļ���ʽ����):������,�����ַ������������
5. Writer(�ļ���ʽ����):������,�����ַ������������
6. RandomAccessFile(����ļ�����):һ����������,ֱ�Ӽ̳���Object.���Ĺ��ܷḻ,���Դ��ļ�������λ�ý��д�ȡ(�������)������
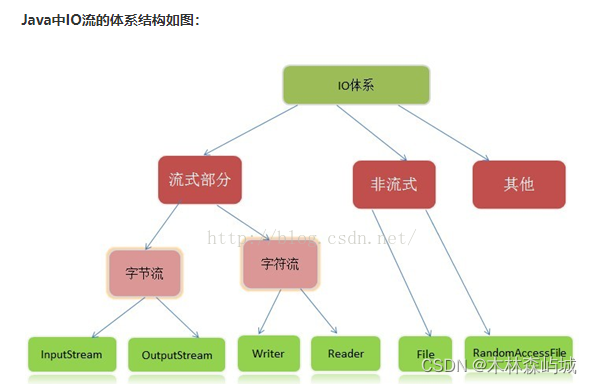
Java I/O��Ҫ�������¼������,������������:
1.��ʽ���֨D�DIO�����岿��;
2.����ʽ���֨D�D��Ҫ����һЩ������ʽ���ֵ���,��:File�ࡢRandomAccessFile���FileDescriptor����;
3.������C�ļ���ȡ���ֵ��밲ȫ��ص���,��:SerializablePermission��,�Լ��뱾�ز���ϵͳ��ص��ļ�ϵͳ����,��:FileSystem���Win32FileSystem���WinNTFileSystem�ࡣ
�����������
����������������������ڷ���ij����Դʱ,�����Ƿ��������ĵ�һ�ִ�����ʽ��������û��������ʱ:
����:�̳߳����ȴ���Դ�����������,ֱ��������Ӧ�����
������:�߳�ֱ�ӷ��ؽ��,��������ȴ���Դ�����ݽ��������Ӧ�����
ͬ�����첽
ͬ�����첽��ָ�������ݵĻ���,ͬ��һ��ָ�������ȴ�IO������ɵķ�ʽ��
�첽��ָ�����������ݺ����Լ���������������,���ȴ�IO������ϵ�֪ͨ��
�������˽�:ͬ��������ͬ�����������첽�������첽������
�����տ�ˮ:
1����ͨˮ����ˮ,վ���Ա�,�����Ŀ�ˮ����û��?ͬ��������
2����ͨˮ����ˮ,ȥ�ɵ�����,ÿ��һ��ʱ��ȥ����ˮ����û��,ˮû�������ˡ� ͬ��������
3����ˮ����ˮ,վ���Ա�,����ÿ��һ��ʱ��������ˮ����û�С����ˮ����,ˮ���Զ�֪ͨ���� �첽����
4����ˮ����ˮ,ȥ�ɵ�����,���ˮ����,ˮ���Զ�֪ͨ�����첽������
NIOģ��
NIO(JDK1.4)ģ����һ��ͬ��������IO,
��Ҫ��������IJ���:
Channel(ͨ��),
Buffer(������),
Selector(��·������)��
��ͳIO�����ֽ������ַ������в���,��NIO����Channel��Buffer(������)���в���,�������Ǵ�ͨ����ȡ����������,���ߴӻ�����д�뵽ͨ���С�
Selector(��·������)���ڼ������ͨ�����¼�(����:���Ӵ�,���ݵ���)�����,�����߳̿��Լ����������ͨ����
NIO�ʹ�ͳIO(���¼��IO)֮���һ������������,IO����������,NIO���������ġ�
Java IO��������ζ��ÿ�δ����ж�һ�������ֽ�,ֱ����ȡ�����ֽ�,����û�б��������κεط�������,������ǰ���ƶ����е����ݡ������Ҫǰ���ƶ������ж�ȡ������,��Ҫ�Ƚ������浽һ����������NIO�Ļ��嵼�����в�ͬ�����ݶ�ȡ��һ�����Ժ����Ļ�����,��Ҫʱ���ڻ�������ǰ���ƶ�����������˴��������е�����ԡ�����,����Ҫ����Ƿ�û������а�����������Ҫ���������ݡ�����,��ȷ������������ݶ��뻺����ʱ,��Ҫ���ǻ���������δ���������ݡ�
IO�ĸ������������ġ�����ζ��,��һ���̵߳���read() �� write()ʱ,���̱߳�����,ֱ����һЩ���ݱ���ȡ,��������ȫд�롣���߳��ڴ��ڼ䲻���ٸ��κ������ˡ�
NIO�ķ�����ģʽ,ʹһ���̴߳�ijͨ�����������ȡ����,���������ܵõ�Ŀǰ���õ�����,���Ŀǰû�����ݿ���ʱ,��ʲô�������ȡ�������DZ����߳�����,����ֱ�����ݱ�Ŀ��Զ�ȡ֮ǰ,���߳̿��Լ��������������顣 ������дҲ����ˡ�һ���߳�����д��һЩ���ݵ�ijͨ��,������Ҫ�ȴ�����ȫд��,����߳�ͬʱ����ȥ��������顣 �߳�ͨ����������IO�Ŀ���ʱ������������ͨ����ִ��IO����,����һ���������߳����ڿ��Թ��������������ͨ��(channel)��
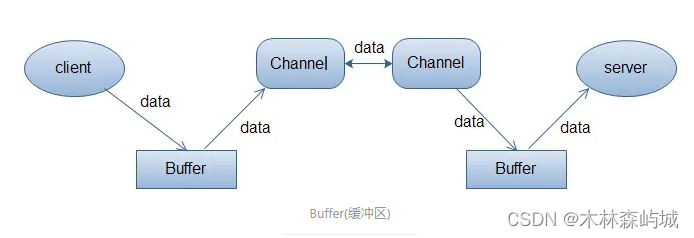
NIO�ŵ�:
ͨ��Channelע�ᵽSelector�ϵ�״̬��ʵ��һ�ֿͻ��������˵�ͨ�š�
Channel�����ݵĶ�ȡ��ͨ��Buffer , һ�ַ������Ķ�ȡ��ʽ��
Selector ��·������ ���߳�ģ��, �̵߳���Դ������ԱȽ�С��
Java ������ ByteBuffer?
byte[] bytes = new byte[10];
ByteBuffer buf = ByteBuffer.wrap(bytes);
TCP/IPЭ����UDPЭ����ʲô����?
Java ��,ByteBuffer �� StringBuffer ��ʲô����?
����ûʲô��ϵ��
ByteBuffer��Java NIO�е�buffer��
��StringBuffer���ַ��������õ�buffer�ࡣ
Java ��,��д���̳߳����ʱ�������ѭ��Щ���ʵ��?
a)���߳�����,�������������ԡ�
b)��С��ͬ���ķ�Χ,�����ǽ���������ͬ��,ֻ�Թؼ�������ͬ����
c)�������,��ƫ����ʹ�� volatile ������ synchronized�� d)ʹ�ø��߲�εIJ�������,������ʹ�� wait() �� notify() ��ʵ���̼߳�ͨ
��,�� BlockingQueue,CountDownLatch �� Semeaphore�� e)����ʹ�ò�������,�����ǶԼ��Ͻ���ͬ�������������ṩ���õĿ���չ�ԡ�
˵������ Java ��ʹ�� Collections �����ʵ��
a)ʹ����ȷ�ļ�����,����,�������Ҫͬ���б�,ʹ�� ArrayList ������
Vector��
b)����ʹ�ò�������,�����ǶԼ��Ͻ���ͬ�������������ṩ���õĿ���չ�ԡ�
c)ʹ�ýӿڴ����ͷ��ʼ���,��ʹ�� List �洢 ArrayList,ʹ�� Map �洢
HashMap �ȵȡ�
d)ʹ�õ�������ѭ�����ϡ�
e)ʹ�ü��ϵ�ʱ��ʹ�÷��͡�
˵�� 5 �� IO �����ʵ��(��)
IO �� Java Ӧ�õ����ܷdz���Ҫ�����������,�㲻Ӧ������Ӧ�õĹؼ�·���ϱ��� IO ������������һЩ��Ӧ����ѭ�� Java IO ���ʵ��:
a)ʹ���л������� IO ��,����Ҫ������ȡ�ֽڻ��ַ���
b)ʹ�� NIO �� NIO2
c)�� finally ���йر���,����ʹ�� try-with-resource ��䡣
d)ʹ���ڴ�ӳ���ļ���ȡ����� IO��
�г� 5 ��Ӧ����ѭ�� JDBC ���ʵ��
�кܶ�����ʵ��,����Ը������ϲ�������١�������һЩ��ͨ�õ�ԭ��:
a)ʹ�������IJ����������������
b)ʹ�� PreparedStatement(Ԥ������) ������ SQL �쳣,��������ܡ�
c)ʹ�����ݿ����ӳ�
d)ͨ����������ȡ�����,��Ҫʹ���е��±�����ȡ��
˵������ Java �з������ص����ʵ��?
�����м���������ѭ�ķ������ص����ʵ������������Զ�װ��Ļ��ҡ�
a)��Ҫ���������ķ���:һ���������� int ����,�������������� Integer ��
����
b)��Ҫ���ز�������һ��,��ֻ�Dz���˳��ͬ�ķ�����
c)������صķ��������������� 5 ��,���ÿɱ������
JVM��GC
JVM( Java Virtual Machine):Java����� JVM
GC(Garbage Collection):����������������� GC
64 λ JVM ��,int �ij����Ƕ���?
Java ��,int ���ͱ����ij�����һ���̶�ֵ,��ƽ̨��,���� 32 λ����˼����˵,�� 32 λ �� 64 λ �� Java �������,int ���͵ij�������ͬ�ġ�
Serial �� Parallel GC ֮��IJ�֮ͬ��?
Serial �� Parallel �� GC ִ�е�ʱ������ stop-the-world������֮����Ҫ
��ͬ serial �ռ�����Ĭ�ϵĸ����ռ���,ִ�� GC ��ʱ��ֻ��һ���߳�,��
parallel �ռ���ʹ�ö�� GC �߳���ִ�С�
32 λ�� 64 λ�� JVM,int ���ͱ����ij����Ƕ���?
32 λ�� 64 λ�� JVM ��,int ���ͱ����ij�������ͬ��,���� 32 λ���� 4
���ֽڡ�
Java �� WeakReference �� SoftReference ������?
��Ȼ WeakReference (������)�� SoftReference(������) ����������� GC �� �ڴ��Ч��,���� WeakReference ,һ��ʧȥ���һ��ǿ����,�ͻᱻ GC ����,����������Ȼ������ֹ������,���ǿ����ӳٵ� JVM �ڴ治���ʱ��
����ͨ�� Java �������ж� JVM �� 32 λ ���� 64λ?
����Լ��ijЩϵͳ������ sun.arch.data.model �� os.arch ����ȡ����Ϣ
32 λ JVM �� 64 λ JVM �������ڴ�ֱ��Ƕ���?
������˵�� 32 λ�� JVM ���ڴ���Ե��� 2^32,�� 4GB,��ʵ���ϻ�����
С�ܶࡣ��ͬ����ϵͳ֮�䲻ͬ,�� Windows ϵͳ��Լ 1.5 GB,Solaris ��Լ3GB��64 λ JVM ����ָ�����Ķ��ڴ�,�����Ͽ��Դﵽ 2^64,����һ���dz��������,ʵ���������ָ�����ڴ��С�� 100GB�������е� JVM,�� Azul,���ڴ浽 1000G ���ǿ��ܵġ�
JRE��JDK��JVM �� JIT ֮����ʲô��ͬ?
JRE ���� Java ����ʱ(Java run-time),������ Java ����������ġ�
JDK �� �� Java ��������(Java development kit),�� Java ����Ŀ�������,�� Java������,��Ҳ���� JRE��
JVM ���� Java �����(Java virtual machine),�������������� Java Ӧ�á�
JIT ������ʱ����(Just In Time compilation),������ִ�еĴ�������һ������ֵʱ,�Ὣ Java �ֽ���ת��Ϊ���ش���
��,��Ҫ���ȵ����ᱻ��Ϊ���ش���,���������������� Java Ӧ�õ����ܡ�
���ܱ�֤ GC ִ����?
����,��Ȼ����Ե��� System.gc() ���� Runtime.gc(),����û�а취��֤ GC��ִ��
��ô��ȡ Java ����ʹ�õ��ڴ�?��ʹ�õİٷֱ�?
����ͨ�� java.lang.Runtime �������ڴ���ط�������ȡʣ����ڴ�,���ڴ漰�����ڴ档ͨ����Щ������Ҳ���Ի�ȡ����ʹ�õİٷֱȼ����ڴ��ʣ��ռ䡣
Runtime.freeMemory() ��������ʣ��ռ���ֽ���,
Runtime.totalMemory()�������ڴ���ֽ���,
Runtime.maxMemory() ��������ڴ���ֽ�����
Java �жѺ�ջ��ʲô����?
JVM �жѺ�ջ���ڲ�ͬ���ڴ�����,ʹ��Ŀ��Ҳ��ͬ��
ջ�����ڱ��淽��֡�;ֲ�����,�����������ڶ��Ϸ��䡣
ջͨ�����ȶ�С,Ҳ�����ڶ���߳�֮�乲��,���ѱ����� JVM �������̹߳�����
Date��Time �� Calendar
�ڶ��̻߳�����,SimpleDateFormat ���̰߳�ȫ����?
����,�dz�����,DateFormat ������ʵ��,���� SimpleDateFormat ������
�̰߳�ȫ��,����㲻Ӧ���ڶ��߳�����ʹ��,�������ڶ����̰߳�ȫ�Ļ�����ʹ��,�� �� SimpleDateFormat ������ ThreadLocal �С�����㲻��ô��,�ڽ������߸�ʽ�����ڵ�ʱ��,���ܻ��ȡ��һ������ȷ�Ľ�������,�����ڡ�ʱ�䴦��������ʵ����˵,��ǿ���Ƽ� joda-time �⡣
��Java����θ�ʽ��һ������?(��ʽ:ddMMyyyy)
Java ��,����ʹ�� SimpleDateFormat ����� joda-time ������ʽ���ڡ�
DateFormat ��������ʹ�ö������еĸ�ʽ����ʽ�����ڡ��μ����е�ʾ������,��������ʾ�˽����ڸ�ʽ���ɲ�ͬ�ĸ�ʽ,�� dd-MM-yyyy �� ddMMyyyy��
������:
Date datenow = new Date();
SimpleDateFormat ft = new SimpleDateFormat("yyyy.MM.dd hh:mm:ss"); System.out.println(ft.format(datenow));
/*ע��:
1�� ���� SimpleDateFormat ����� parse() ����ʱ���ܻ����ת���쳣,�� ParseException ,�����Ҫ�����쳣����
2�� ʹ�� Date ��ʱ��Ҫ���� java.util ��,ʹ�� SimpleDateFormat ʱ��Ҫ���� java.text
*/
public static void main(String[] args){
// ʹ��format()����������ת��Ϊָ����ʽ���ı�
SimpleDateFormat sdf1 = new SimpleDateFormat("yyyy��MM��dd�� HHʱmm��ss��");
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy/MM/dd HH:mm");
SimpleDateFormat sdf3 = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// ����Date����,��ʾ��ǰʱ��
Date now = new Date();
// ����format()����,������ת��Ϊ�ַ��������
System.out.println(sdf1.format(now));//2019��02��11�� 21ʱ50��48��
System.out.println(sdf2.format(now));//2019/02/11 21:50
System.out.println(sdf3.format(now));//2019-02-11 21:50:48
// ʹ��parse()�������ı�ת��Ϊ����
String d = "2019-2-11 21:50:36";
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// ����parse()����,���ַ���ת��Ϊ����
try {
//ע��һ��Ҫ��ָ���ĸ�ʽƥ��
Date date =sdf.parse(d);
System.out.println(date);//Mon Feb 11 21:50:36 CST 2019
}catch(ParseException e){
e.printStackTrace();
}
}
Java ��,��ô�ڸ�ʽ������������ʾʱ��?
��ʵ�ڸ�ʽ���ļ���Z,��ʾ�ľ���ʱ��
String timestamp = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS Z",
Locale.ENGLISH).format(new Date());//2022-3-9 12:40:40.203 +0800
Java �� java.util.Date �� java.sql.Date ��ʲô����?
- java.util.Date�������ں�ʱ��,(�ڳ���SQL�����������ʹ��,��ʾʱ�����,����ͨ����ʽ�����ߵõ���ǰʱ�䶼������)
- java.sql.Dateֻ����������Ϣ,��û�о����ʱ����Ϣ����������ʱ����Ϣ�洢�����ݿ� ��,���Կ���ʹ��Timestamp����DateTime�ֶΡ�(�����SQL���ʹ�õ�,�ڶ�д���ݿ��ʱ������,��ΪPreparedStament��setDate()�ĵ�2������ResultSet��getDate()�����ĵ�2����������java.sql.Date
ת����
java.sql.Date date=new Java.sql.Date();
java.util.Date d=new java.util.Date (date.getTime());
��������һ����
java.sql.Date ��getTime�������غ�����,��Ȼ�Ϳ���ֱ�ӹ���
java.util.Date d = new java.util.Date(sqlDate.getTime());
�̳й�ϵ:java.lang.Object --�� java.util.Date --�� java.sql.Date
�����ת����ϵ����
java.util.Date d=new java.util.Date (new Java.sql.Date());
SimpleDateFormat f=new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
java.util.Date utilDate=new Date();
java.sql.Date sqlDate=new java.sql.Date(utilDate.getTime());
java.sql.Time sTime=new java.sql.Time(utilDate.getTime());
java.sql.Timestamp stp=new java.sql.Timestamp(utilDate.getTime());
System.out.println(utilDate.getYear());
//��������ʱ�����ڶ����Ա�SimpleDateFormat��ʽ��format()
f.format(stp);f.format(sTime);f.format(sqlDate);f.format(utilDate)
java.sql.Date sqlDate=java.sql.Date.valueOf("2005-12-12");
utilDate=new java.util.Date(sqlDate.getTime());
//===����ȡ�������յķ���:===
import java.text.SimpleDateFormat;
import java.util.*;
java.util.Date date = new java.util.Date();
//���ϣ���õ�YYYYMMDD�ĸ�ʽ
SimpleDateFormat sy1=new SimpleDateFormat("yyyyMMDD");
String dateFormat=sy1.format(date);
//���ϣ���ֿ��õ���,��,��
SimpleDateFormat sy=new SimpleDateFormat("yyyy");
SimpleDateFormat sm=new SimpleDateFormat("MM");
SimpleDateFormat sd=new SimpleDateFormat("dd");
String syear=sy.format(date);
String smon=sm.format(date);
String sday=sd.format(date);
ת���ڲ���:https://www.cnblogs.com/IamThat/p/3264234.html
Java ��,��μ�����������֮��IJ��
�𰸲ο�:https://www.cnblogs.com/rinack/p/6798433.html
Java ��,��ν��ַ��� YYYYMMDD ת��Ϊ����?
������:20220309ת��Ϊ2022��03��09��
import java.util.*;
import java.text.*;
import java.io.*;
class StrToDate{
public static void main(String[] args){
String dateString = "20220309";
try {
Date date=new SimpleDateFormat("yyyyMMdd").parse(dateString);
/*
DateFormat.getInstance(); // �õ�����ʱ�䶼ʹ��SHORT��������ʱ���ʽ����
DateFormat.getDateInstance(); // �õ����ڸ�ʽ����,ʹ��Ĭ�����Ի�����Ĭ�Ϸ��
DateFormat.getDateTimeInstance(); // �õ�����ʱ���ʽ����,ʹ��Ĭ�����Ի�����Ĭ�Ϸ��
*/
System.out.println(DateFormat.getDateInstance().format(date));//����Ľ��Ϊ2022-03-09
System.out.println(new SimpleDateFormat("yyyy/MM/dd").format(date));//����Ľ��Ϊ2022/03/09
//SimpleDateFormat sdf2 = new SimpleDateFormat("yyyy��MM��dd��");
System.out.println(new SimpleDateFormat("yyyy��MM��dd��").format(date));//����Ľ��Ϊ2022��03��09��
} catch (Exception ex) {
System.out.println(ex.getMessage());
}
}
}
JUnit��Ԫ����
��β��Ծ�̬����?
����ʹ�� PowerMock �������Ծ�̬������ PowerMockʹ�����
��ô���� JUnit ������һ���������쳣?
��ʹ�ù��ĸ���Ԫ���Կ���������� Java ����?
JUnit
�Ƽ�����:10�Ԫ���Թ���
@Before �� @BeforeClass ��ʲô����?
@before:��ÿ�����Է���֮ǰ��ִ��һ��, ������Ҫ����Ϊpublic
@beforeclass:ֻ������ִ��һ��, ��������Ϊpublic static
@After:�ͷ���Դ ����ÿһ�����Է�����Ҫִ��һ��
@Afterclass:���в�������ִ�����ִ��һ��
һ��JUnit4�ĵ�Ԫ��������ִ��˳��Ϊ:
@BeforeClass -> @Before -> @Test -> @After -> @AfterClass;
ÿһ�����Է����ĵ���˳��Ϊ: @Before -> @Test -> @After;
��ô���һ���ַ���ֻ��������?
һ����JAVA�Դ��ĺ���
public static boolean isNumeric(String str){
for (int i = str.length();--i>=0;){
if (!Character.isDigit(str.charAt(i))){
return false;
}
}
return true;
}
�������������ʽ
public static boolean isNumeric(String str){
for (int i = str.length();--i>=0;){
if (!Character.isDigit(str.charAt(i))){
return false;
}
}
return true;
}
������ascii���ж�
public static boolean isNumeric(String str){
/*
�����ַ����ĵ�һ���ַ���ʼ�����һ���ַ�����,�ж��ַ��Ƿ�����(ASCIIֵ�Ƿ������ַ�Χ��:48����57)������������˳�����,���ַ�����ֻ�������֡�������������ַ���ֻ�������֡���
*/
for(int i=str.length();--i>=0;){
int chr=str.charAt(i);
if(chr<48 || chr>57)
return false;
}
return true;
}
Java ��������÷���дһ�� LRU ����?
дһ�� Java ���� byte ת��Ϊ long?
Java����ν��ַ���ת��Ϊ����?
String str ="123";
int i;
//��һ��:
i=Integer.parseInt(str);
//�ڶ���:
i=Integer.valueOf(str).intValue();
��û��ʹ����ʱ�����������ν�����������������ֵ?
int a=3,b=2;
a=a+b;// a=3+2=5
b=a-b;// b=5-2=3
a=a-b;// a=5-3=2
�ӿ���ʲô?ΪʲôҪʹ�ýӿڶ�����ֱ��ʹ�þ�����?
�ӿ����ڶ��� API������������������ѭ�Ĺ���ͬʱ,���ṩ��һ�ֳ���,��Ϊ�ͻ���ֻʹ�ýӿ�,���������ж���ʵ��,�� List �ӿ�,�����ʹ�ÿ�������ʵ� ArrayList,Ҳ����ʹ�÷�������ɾ���� LinkedList���ӿ��в�����д����,�Դ�����֤����,���� Java 8 ��������ڽӿ�������̬��Ĭ�Ϸ���,���ַ����Ǿ���ġ�
Java ��,��������ӿ�֮����ʲô��ͬ?
Java ��,������ͽӿ��к֮ܶͬ��,��������Ҫ��һ���� Java ������һ����ֻ�ܼ̳�һ����,���ǿ���ʵ�ֶ���ӿڡ���������ԺܺõĶ���һ���������Ĭ����Ϊ,���ӿ��ܸ��õĶ�������,�����ں���ʵ�ֶ�̬���ơ�
���ܽ���һ�������滻ԭ����?
ʲô����»�Υ�������ط���?Ϊʲô�����������?
�����ط����顰ֻ������˵��,��Ҫİ����˵����;��talk only to your immediate friends��,�Դ���������֮������
����OOD��˵,�ֱ�����Ϊ���漸�ַ�ʽ:һ������ʵ��Ӧ���������ٵ�������ʵ�巢������á�ÿһ��������λ�������ĵ�λ��ֻ�����ٵ�֪ʶ,���Ҿ�������Щ�뱾��λ������ص�������λ��
�����ط���ij������ڽ�����֮�����ϡ�����ÿ���ྡ�����ٶ������������,���,������ʹ��ϵͳ�Ĺ���ģ�鹦�ܶ���,�֮�䲻����(�������)������ϵ��
�����ط���ϣ����֮�佨��ֱ�ӵ���ϵ������������Ҫ������ϵ,Ҳϣ����ͨ��������Ԫ����ת����,Ӧ�õ����ط����п�����ɵ�һ���������:ϵͳ�д��ڴ������н���,��Щ��֮���Դ�����ȫ��Ϊ�˴�����֮�������ù�ϵ��������һ���̶���������ϵͳ�ĸ��Ӷȡ�
����Ȥ�����о�һ�����ģʽ������ģʽ(Facade)���н�ģʽ(Mediator),���ǵ����ط���Ӧ�õ����ӡ�
ֵ��һ�����,��ȻIan Holland�Լ������ѧ�Ĺ���Ҳ��������һ������,��������Ľ�������,����,��һ����ȴ�����������ڼ��������,����������Ҳͬ�����á�����,�����˾��ں���ϵͳ������в�����һ����
������ģʽ��ʲô?ʲôʱ��ʹ��?
������ģʽ�ṩ�Խӿڵ�ת���������Ŀͻ���ʹ��ijЩ�ӿ�,������������һЩ�ӿ�,��Ϳ���дһ������ȥ��������Щ�ӿڡ�
ʲô�ǡ�����ע��(IOC)���͡����Ʒ�ת(DI)��?Ϊʲô����ʹ��?
-
���Ʒ�ת(IOC)�� Spring ��ܵĺ���˼��,����ʲô����,
��Java������,Ioc��ζ�Ž�����ƺõĶ�����������,�����Ǵ�ͳ������Ķ����ڲ�ֱ�ӿ���(���仰˵,������Ҫʵ��ʲô����,�����ȥ��������ɾͿ�����) -
����ע��(DI) :IOC��һ���ص�����ϵͳ������,��̬����ij�������ṩ������Ҫ������������һ����ͨ��DI(Dependency Injection,����ע��)��ʵ�ֵġ�����ͨ���ӿڵ����ú��췽���ı���,��һЩ���������˷�����������Ҫ�õ��ĵط�
�Ƽ�:����ע��Ϳ��Ʒ�ת������,ͨ����,��ľ����
��������ʲô?����ӿ���ʲô����?��ΪʲôҪʹ�ù�������?
�ӿ����ڹ淶,���������ڹ���.
���������Ĵ��ڶ���ȥʵ�������౻����������
�ӿ�(interface)�dz�����ı��塣�ڽӿ���,���з������dz���ġ�
������ע��� setter ����ע��,���ַ�ʽ����?
ÿ�ַ�ʽ��������ȱ����ŵ㡣������ע�뱣֤���е�ע�붼����ʼ��,����setter ע���ṩ���õ�����������ÿ�ѡ���������ʹ�� XML ����������,Setter ע��Ŀɶ�д���ǿ�����鷨����ǿ������ʹ�ù�����ע��,��ѡ����ʹ�� setter ע�롣
����ע�����ģʽ֮����ʲô��ͬ?
��Ȼ����ģʽ���ǽ�����Ĵ�����Ӧ�õ����з���,��������ע��ȹ���ģʽ��������ͨ������ע��,�������� POJO,��ֻ֪��������������������ô��ȡ��
ʹ�ù���ģʽ,�������Ҫͨ����������ȡ���������,ʹ�� DI ���ʹ�ù���ģʽ�����ײ��ԡ�
������ģʽ��װ����ģʽ��ʲô����?
��Ȼ������ģʽ��װ����ģʽ�Ľṹ����,����ÿ��ģʽ�ij�����ͼ��ͬ��������ģʽ�������Ž������ӿ�,��װ��ģʽ��Ŀ�����ڲ����������¸��������µĹ��ܡ�
������ģʽ�ʹ���ģʽ֮ǰ��ʲô��ͬ?
���������ǰ�������,������ģʽ�ʹ���ģʽ�������������ǵ���ͼ��ͬ������������ģʽ�ʹ���ģʽ���Ƿ�װ����ִ�ж�������,��˽ṹ��һ�µ�,����������ģʽ���ڽӿ�֮���ת��,������ģʽ��������һ��������м��,�Ա�֧�ַ��䡢���ƻ����ܷ��ʡ�
ʲô��ģ�巽��ģʽ?
ģ�巽���ṩ�㷨�Ŀ��,������Լ�ȥ���û��岽�衣
����,����Խ������㷨������һ��ģ�塣������������IJ���,���Ǿ���ıȽ�,����ʹ��Comparable ���������������ƶ���,�����������ȥ���á��г��㷨��Ҫ�ķ�������������֪��ģ�巽����
ʲôʱ��ʹ�÷�����ģʽ?
������ģʽ���ڽ������ļ̳в�������Ӳ���,���Dz�ֱ����֮����������ģʽ����˫�ɷ�����ʽ�������м�㡣
ʲôʱ��ʹ�����ģʽ?
���ģʽʹ�����ṹ��չʾ����������̳й�ϵ���������ͻ��˲���ͳһ����ʽ���Դ���������Ͷ���������������Ҫչʾ�������ֲ���������ļ̳й�ϵʱ�������ģʽ��
�̳к����֮����ʲô��ͬ?
��Ȼ���ֶ�����ʵ�ִ��븴��,������ϱȼ̳й����,��Ϊ���������������ʱѡ��ͬ��ʵ�֡������ʵ�ֵĴ���Ҳ�ȼ̳в����������Ӽ�
���� Java �е����غ���д?
���غ���д������������ͬ��������ʵ�ֲ�ͬ�Ĺ���,���������DZ���ʱ�,����д������ʱ����������ͬһ���������ط���,����ֻ������������д��������д����Ҫ�м̳С�
Java ��,Ƕ������̬���붥������ʲô��ͬ?
����ڲ������ж��Ƕ������̬��,����һ�� Java Դ�ļ�ֻ����һ������������,���Ҷ����������������Դ�ļ����Ʊ���һ�¡�
OOP �е� ��ϡ��ۺϺ�����ʲô����?
�����������˴��й�ϵ,��˵�����DZ˴�������ġ���Ϻ;ۺ�����������е�������ʽ�Ĺ����������һ�ֱȾۺϸ�ǿ���Ĺ����������,һ����������һ����ӵ����,���ۺ�����ָһ������ʹ����һ������������� A ���ɶ��� B ��ϵ�,�� A �����ڵĻ�,B һ��������,������� A ����ۺ���һ������ B,��ʹ A ��������,B Ҳ���Ե������ڡ�
����һ�����Ͽ���ԭ������ģʽ������?
����ԭ��Ҫ����Ĵ������չ����,���Ĺرա������˼����˵,�����������һ���µĹ���,����Ժ������ڲ��ı��Ѳ��Թ��Ĵ����ǰ���������µĴ��롣�кü������ģʽ�ǻ��ڿ���ԭ���,�����ģʽ,�������Ҫһ���µIJ���,ֻ��Ҫʵ�ֽӿ�,��������,����Ҫ�ı��������һ�����ڹ�����������Collections.sort() ����,����ǻ��ڲ���ģʽ,��ѭ����ԭ���,�㲻��Ϊ�µĶ����� sort() ����,����Ҫ���Ľ�����ʵ�����Լ��� Comparator �ӿڡ�
����ģʽ��ԭ��ģʽ֮�������?
����ģʽ:ͨ���ɹ�������ģʽ��ʵ�֡���һ���������������ж��������������һϵ�еIJ�Ʒ�����ģʽǿ�����ǿͻ�����һ�α�ֻ֤ʹ��һ��ϵ�еIJ�Ʒ����Ҫ�л�Ϊ��һ��ϵ�еIJ�Ʒ,��һ�������༴�ɡ�
ԭ��ģʽ:�������������ȱ�����,��Ӧһ���̳���ϵ�IJ�Ʒ��,Ҫ��һ��ͬ�����ӵĹ�����ļ̳���ϵ�����ǿ��ѹ������еĹ��������ŵ���Ʒ������֮����?��������Ļ�,�Ϳ��Խ������̳���ϵΪһ������Ҳ����ԭ��ģʽ��˼��,ԭ��ģʽ�еĹ�������Ϊ clone,���᷵��һ������(������dz����,Ҳ���������,������߾���)��Ϊ�˱�֤�û������е�ʱ����ͨ��ָ����� clone ����̬����������ľ�����ࡣ��Щԭ�Ͷ���������ȹ���á�ԭ��ģʽ��Թ�������ģʽ����һ���ô���,������Ч��һ��Թ����Ч��Ҫ�ߡ�
ʲôʱ��ʹ����Ԫģʽ?
��Ԫģʽͨ���������������ⴴ��̫��Ķ���Ϊ��ʹ����Ԫģʽ,����Ҫȷ����Ķ����Dz��ɱ��,��������ܰ�ȫ�Ĺ�����JDK �� String �ء�Integer ���Լ� Long �ض��Ǻܺõ�ʹ������Ԫģʽ�����ӡ�
Java ������������ʽ����������
�ⲿ�ְ��� Java �й��� XML ��������,�������ʽ������,Java ������쳣�����л�������
Ƕ��̬���붥������ʲô����?
һ�������Ķ������Դ�ļ�������������ͬ,��Ƕ��̬��û�����Ҫ��һ��Ƕ����λ�ڶ������ڲ�,��Ҫʹ�ö����������������Ƕ��̬��,��
HashMap.Entry ��һ��Ƕ��̬��,HashMap ��һ��������,Entry ��һ��Ƕ��̬�ࡣ
����д��һ���������ʽ���ж�һ���ַ����Ƿ���һ��������?
һ�������ַ���,ֻ�ܰ�������,�� 0 �� 9 �Լ� +��- ��ͷ,ͨ�������Ϣ,�������һ�����µ��������ʽ���жϸ������ַ����Dz������֡�
����Ҫ
import java.util.regex.Pattern �� java.util.regex.Matcher
public boolean isNumeric(String str){
Pattern pattern = Pattern.compile("[0-9]*");
Matcher isNum = pattern.matcher(str);
if( !isNum.matches() ){
return false;
}
return true;
}
Java ��,�ܼ���쳣 �� ���ܼ���쳣������?
�ܼ���쳣�������ڱ����ڼ��顣���������쳣,����ǿ�ƴ�������ͨ��
throws �Ӿ�����������һ������� Exception �����൫����
RuntimeException �����ࡣ���ܼ���� RuntimeException ������,�ڱ���β��ܱ������ļ�顣
Java ��,throw �� throws ��ʲô����
throw �����׳� java.lang.Throwable ���һ��ʵ��������,��˼��˵�����ͨ���ؼ��� throw �׳�һ�� Error ���� һ�� Exception,��:
throw new IllegalArgumentException(��size must be multiple of 2�� ) �� throws ����������Ϊ����������ǩ����һ����,�������׳���Ӧ���쳣�Ա�
�������ܴ�����Java ��,�κ�δ�������ܼ���쳣ǿ���� throws �Ӿ���������
Java ��,Serializable �� Externalizable ������?
Serializable �ӿ���һ�����л� Java ��Ľӿ�,�Ա������ǿ����������ϴ�����߿��Խ����ǵ�״̬�����ڴ�����,�� JVM ��Ƕ��Ĭ�����л���ʽ,�ɱ��ߡ��������Ҳ���ȫ��Externalizable ����������������л�����,ָ���ض��Ķ����Ƹ�ʽ,���Ӱ�ȫ���ơ�
Java ��,DOM �� SAX ��������ʲô��ͬ?
DOM ������������ XML �ĵ����ص��ڴ�������һ�� DOM ģ����,�������Ը���IJ��ҽڵ���� XML �ṹ,�� SAX ��������һ�������¼��Ľ�����,���Ὣ���� XML �ĵ����ص��ڴ档�������ԭ��,DOM �� SAX ����,ҲҪ�������ڴ�,���ʺ��ڽ����� XML �ļ���
˵�� JDK 1.7 �е�����������?
��Ȼ JDK 1.7 ���� JDK 5 �� 8 һ���Ĵ�汾,����,�����кܶ��µ�����,
��
try-with-resource ���,��������ʹ����������Դ��ʱ��,�Ͳ���Ҫ�ֶ��ر�,Java ���Զ��رա�
Fork-Join ��ij�̶ֳ���ʵ�� Java ��� Map-reduce������ Switch ���� String �������ı������β�����(<>)���������ƶ�,������Ҫ�ڱ����������ұ���������,��˿���д���ɶ�д��ǿ�������Ĵ��롣��һ��ֵ��һ��������Ǹ����쳣����,��������ͬһ�� catch ���в������쳣��
˵�� 5 �� JDK 1.8 �����������?
Java 8 �� Java ��ʷ����һ�������µİ汾,���� JDK 8 �� 5 ����Ҫ������:
- Lambda ����ʽ,���������һ��������������
- Stream API,��������ִ���� CPU,����д���ܼ��Ĵ���
- Date �� Time API,����,��һ���ȶ��������ں�ʱ���ɹ���ʹ��
- ��չ����,����,�ӿ��п����о�̬��Ĭ�Ϸ�����
- �ظ�ע��,��������Խ���ͬ��ע����ͬһ������ʹ�ö�Ρ�
Java ��,Maven �� ANT ��ʲô����?
��Ȼ���߶��ǹ�������,�����ڴ��� Java Ӧ��,���� Maven �����������,�ڻ��ڡ�Լ���������á�(Լ����������)�ĸ�����,�ṩ���� Java ��Ŀ�ṹ,ͬʱ��ΪӦ���Զ���������(Ӧ������������ JAR �ļ�),Maven �� ANT ���߸���IJ�֮ͬ����μ���Maven �� Ant ������?��