
Lakehouse由lake和house两个词组合而成,其中lake代表Delta Lake(数据湖),house代表data warehouse(数据仓库)。因此,Lakehouse架构就是数据湖和数据仓库的结合。数据仓库和数据湖各自都存在着很多不足,而Lakehouse的出现综合了两者的优势,弥补了它们的不足。
数据仓库从上世纪 80 年代开始发展和兴起,它的初衷是为了支持BI系统和报表系统,而它的优势也就在于此。结构化的数据可以通过ETL来导入数据仓库,用户可以方便地接入报表系统以及BI系统。同时,它的数据管控能力也比较强。

数据仓库对于数据 schema 的要求非常严格,很多数据仓库甚至也实现了 acid 事务等能力。但是数据仓库对于半结构化数据比如时序数据和日志,以及非结构化数据比如图片、文档等的支持是非常有限的,因此它不适用于类似于机器学习的应用场景。而且一般情况下,数据仓库都是专有系统,使用成本比较高,数据迁移和同步的灵活性比较低。
因此,为了解决上述问题,数据湖的架构应运而生。

数据湖架构的基础是将原始数据以文件的形式存储在像阿里云OSS、AWS S3 和 Azure blob storage 等对象存储系统上。相比于数据仓库使用的专有系统,使用这些对象存储的成本比较低。数据湖的另一个优势是能够对半结构化和非结构化的数据提供非常好的支持。因为数据可以以文件的形式直接存储在数据湖之中,所以数据湖在机器学习等场景中的应用就比较广泛。但是它对于 BI 和报表系统的支持比较差,通常情况下需要通过ETL将数据转存到实时数据库或数据仓库中,才能支持 BI 和报表系统,而这对于数据的实时性和可靠性都会产生负面的影响。
综上,不论是数据仓库还是数据湖,都无法完全满足用户的需求。

因此,在很多实际使用场景中,用户会将两者组合起来使用,但是这导致需要构建很多不同的技术栈来支持所有场景。
比如对于数据分析,需要将结构化的数据输入到数据仓库,然后建立数据市场,对数据分析和 BI 提供支持;对于数据科学和机器学习的场景,需要把不同的数据比如结构化、半结构化以及非结构化的数据存储到数据湖中,经过数据清理,用来支持机器学习和数据科学等场景;而对于流式数据源,需要通过流式数据引擎存储到实时数据库中,同时还需要对数据湖里的数据进行 ETL 提取、转换和加载,来保证数据的质量。
这导致需要很多不同的系统、不同的工具来支持各种架构,同时为了数据的互通(上图红线),还需要处理不同的专有数据格式之间的差异,以上流程都会大大影响整个系统的效率。
而且,由于所有技术栈都是互相独立的,导致了维护和使用这些系统的团队也是分散的。比如,数据分析师主要使用数据仓库系统,而数据科学家主要使用数据湖系统,同时数据工程师也需要维护整个系统的不同团队,沟通成本比较高。此外,系统中维护了很多不同格式的数据副本,没有统一的管理数据模型,不同团队的数据很有可能会产生差异。
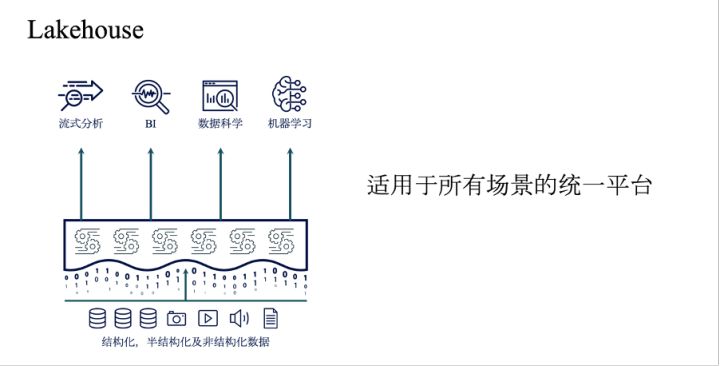
因此,这种复杂的组合型数据系统不是一个好的解决方案。基于此,databricks提出了Lakehouse。Lakehouse的设计基于一个原则:实现一个适用于所有场景的统一平台。
解决的办法是综合数据湖与数据仓库的能力――基于数据湖使用的对象存储,构建数据仓库拥有的数据管控能力。而这一切的关键就是其中的结构化事务层。
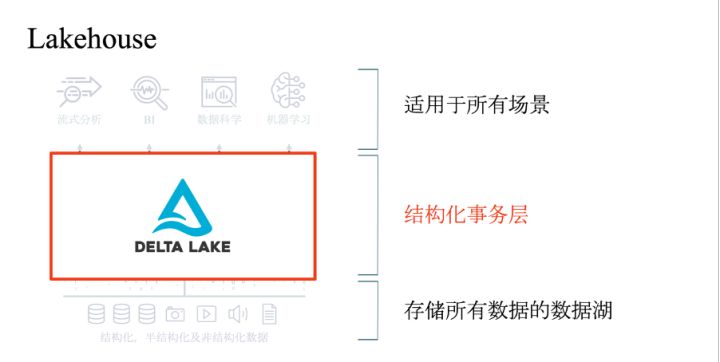
此前,数据湖主要存在以下几个痛点:
- 读写并行,就算是追加写的模式也会产生很多问题。用户的期望是所有写操作能够事务性地被同时读到或者同时没有读到,而这是难以实现的,因为在分布式的对象存储上写多个文件,设置一个文件,数据的一致性都是不能完全被保证的。
- 数据的修改。由于安全合规等原因,用户会有强制性地修改已有数据的需求,特别是有时候需要根据过滤结果细粒度地修改某些数据。由于数据湖在数据管控能力上的不足,在数据湖上实现此需求往往需要使用全部扫描再重写的方式,成本比较高,速度也比较慢。
- 如果一个作业中途失败,而它产生的部分数据已经存入到数据库中,这也会导致数据的损坏。
- 批流混合输入。由于数据在批和流系统中都存在,可能会造成数据在两套系统中不一致,导致读取结果不一致。
- 存数据历史。有些用户需要保证数据查询的可重复性,方案之一是为了这个需求做很多重复的数据快照,但这会导致数据的存储和计算成本都大幅上升。
- 处理海量的元数据。大型数据湖元数据的数据量非常大,经常能够达到大数据的级别。很多数据湖采用的数据目录系统无法支持如此大量的元数据,这也限制了数据湖的扩展性。
- 大量小文件的问题。在数据不断输入的过程中,数据湖内会产生大量小文件,随着时间的推移,小文件的数量可能会越来越多,这会严重影响数据湖的读取性能。
- 性能问题。在数据湖上达到高性能不是一件容易的事。有的时候为了达到一定的性能要求,用户需要手动做一些性能的优化,比如数据分区等,而这些手动的操作又比较容易出错。
- 数据的查询管控。由于数据湖的开放性,确保查询权限合规也是需要解决的问题。
- 质量问题。前面很多点都会导致数据质量的问题。在大数据场景下,如何确保数据的正确性也是一个普遍的问题。
而Delta Lake能够为Lakehouse带来数据质量、可靠性以及查询性能的提升。

上述前五个问题都是关于数据可靠性,它们都可以通过Delta Lake的 acid 事务能力来解决。在Delta Lake上,每一个操作都是事务的,即每一个操作都是一个整体,要么整体成功,要么整体失败。如果 一个操作在中途失败,Delta Lake会负责将其写入的不完整数据清理干净。具体的实现方式是Delta Lake维护了包含所有操作的一个事务日志,能够保证数据与事务日志的一致性。
如上图,某次写操作在某个表中添加了很多数据,这些数据被转换成了parquet格式的两个文件file1和file2。有了事务日志,读操作的时候就能够保证要么读不到这条日志,要么同时读到这两条记录,这样就保证了读取的一致性,解决了读写并行的问题。
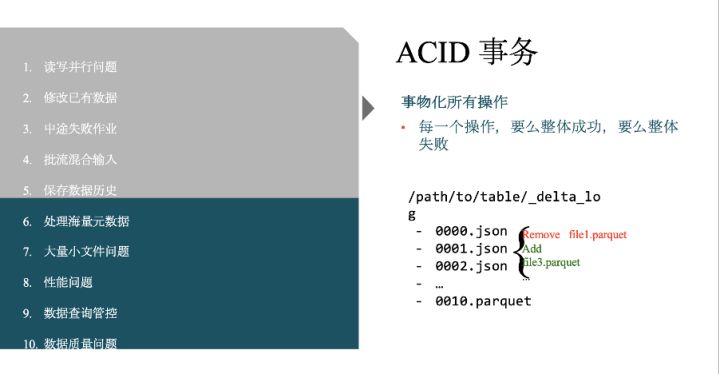
此外,有了事务日志后也可以对已有数据做细粒度的修改。比如下一次写操作对表中的某些数据进行修改,在事务日志中就会出现删除原有文件file1和添加修改后文件file3这样两条记录。同样,在读取的时候,这两条记录也会被同时读到或者忽略,使读取的一致性得到保证。
针对第三点中途失败的作业,Delta Lake写入的事务性能够保证不完整的数据不会被成功写入。
对于批流混合的输入数据,由于Spark天然支持批流一体,在写入时可以将批和流的数据写入到同一张表,避免了数据冗余及不一致性。
由于事务日志保存了所有操作的历史记录,我们可以对之前某个时间点的历史数据进行查询。具体实现方法是:Delta Lake可以查到历史某个时间点对应的事务日志,并且根据历史的事务日志进行数据重放,得到该时间点的数据状态。这个能力被称为“时间旅行”。
那么,Delta Lake是怎样处理海量元数据的呢?答案很简单,使用 Spark 来处理。所有Delta Lake的元数据均以开源parquet的格式存储,数据与元数据总是相伴相生,无需进行同步。使用 Spark 处理元数据,使得Delta Lake的元数据可以在理论上进行无限的扩展。

Delta Lake还采用索引的机制来优化性能,它采用分区和不同过滤器等的机制,可以跳过数据的扫描。还采用了Z-ordering的机制,可以在对某个列进行优化的同时,使其他列性能牺牲最小化。
为了解决大量小文件的问题,Delta Lake还可以在后台定期对数据布局进行自动优化。如果存储的小文件过多,会自动的将他们合并成大文件,这解决了数据湖中小文件越来越多的问题。

对于数据查询的管控,Delta Lake实现了表级别的权限控制,也提供了权限设置 API,可以根据用户的权限动态对视图进行脱敏。

最后,Delta Lake实现了schema的验证功能来保证数据质量。存在Delta Lake表中的所有数据都必须严格符合其对应的schema,它还支持在数据写入时做schema 的合并演化。当输入数据的 schema 发生变化的时候,Delta Lake可以自动对表的schema进行相应的演化。

总的来说,Delta Lake是在数据湖存储之上,实现了数据仓库拥有的ACID事务特性、高性能数据治理能力以及数据质量保证。同时它是基于开放的存储格式,其本身也是开源的。此外,Delta Lake在架构设计上采用了多层的数据模型来简化设计,一层层逐步提高数据质量。
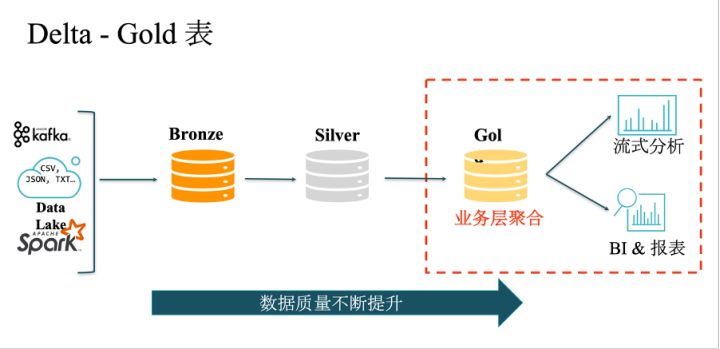
刚刚进入Delta Lake的数据表,完全对应着数据的原始输入,数据质量比较低的,被称为Bronze表。Bronze表的数据保留也可以设置得长一些,以便从这些表中回溯历史数据。Bronze表中的数据经过过滤清理,就可以得到下一层的Silver表,可以使其与其他表或者维度表进行创意操作,进行数据的扩展。再往下一层,可以根据业务的需求对已经清理过滤好的数据进行聚合,得到Gold表,可以直接支持业务分析、报表等应用。
可以看到,在Delta Lake架构中,数据质量是在不断提升的。相比于lambda 架构,它的设计优势在于在每一层都可以使用PDO统一的数据管道,以事务性的操作对表进行更新,还可以减少数据冗余,从而优化存储和计算的开销。
总体而言,Lakehouse的架构优势有以下几个方面:
- Delta Lake的计算和存储天然分离,用户可以进行更灵活的资源调度。
- Lakehouse依赖于可以无限扩容的对象存储服务,其元数据的处理也依赖于高扩展性的 Spark 作业,用户无须关心存储容量的问题。
- 开放的数据格式可以让数据在不同系统之间的迁移更加顺畅。
- 与数据湖相同,Lakehouse同时支持结构化、半结构化与非结构化的数据。
- 批流一体。与 lambda 架构不同,Lakehouse能够做到真正的批流一体,从而简化数据的架构。

Databricks公司与阿里云联手打造了全新的产品 databricks 数据洞察,简称DDI。

Databricks 独家优化了databricks runtime引擎,也可以理解为Apache Spark的加强版,它与Delta Lake 融合进阿里云的整套生态系统中,与ECS、OSS、JindoFS进行了很好的结合,提供了全托管高性能的企业级 Spark平台,能够同时支持企业的商业洞察分析以及机器学习训练等。
作者:张泊 Databricks 软件工程师
本文为阿里云原创内容,未经允许不得转载。