Hadoop的分支hdfs的搭建
首先是三台服务器之间的免密
我写的免密操作
链接
追加自己的免密
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
安装JDK
上传jdk压缩包
然后在linux中将jdk压缩包解压到/root/apps 下
配置环境变量:JAVA_HOME PATH
vim /etc/profile
export JAVA_HOME=/root/apps/jdk1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin
安装hdfs集群
下载安装包
原理图
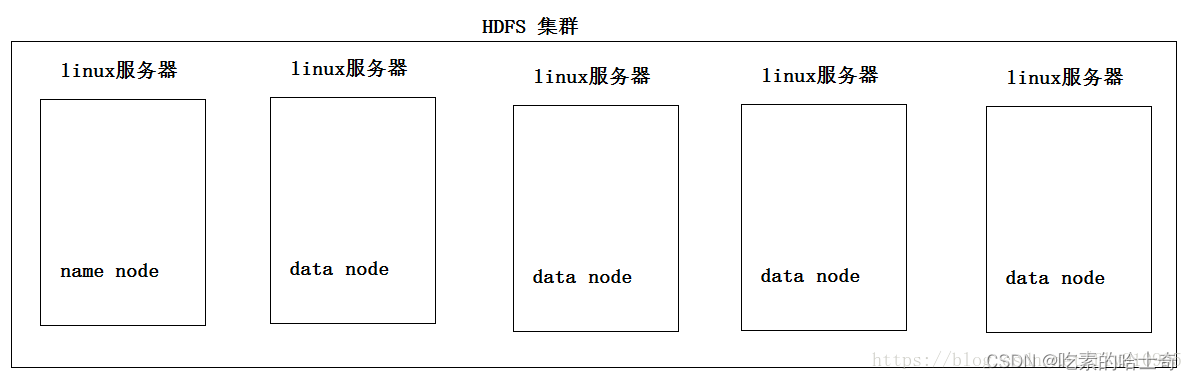
一台主机,其他都是数据机器
修改配置文件
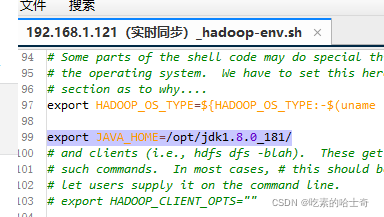
hadoop-env.sh
设置定点的jdk,然后你也可以不设置,直接用环境变量的jdk,但是如果jdk有多个的时候你就想用某个jdk就可以在这里定义
cd /usr/local/hadoop-3.3.2/etc/hadoop
vim hadoop-env.sh
加上
export JAVA_HOME=/opt/jdk1.8.0_181/
需要修改两个文件core-site.xml,hdfs-site.xml
文件所在文件夹
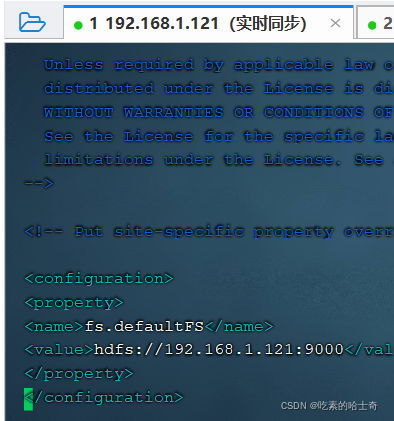
core-site.xml的修改
cd /usr/local/hadoop-3.3.2/etc/hadoop
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.121:9000</value>
</property>
</configuration>
另外,如果需要去再安装hive的话记得加上下面这段:不然无法访问
<!-- 表示设置 hadoop 的代理用户-->
<property>
<!--表示代理用户的组所属-->
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<!--表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群-->
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
然后分发出去:另外两台关联机器
scp /usr/local/hadoop-3.3.2/etc/hadoop/core-site.xml 192.168.1.88:/usr/local/hadoop-3.3.2/etc/hadoop/
scp /usr/local/hadoop-3.3.2/etc/hadoop/core-site.xml 192.168.1.92:/usr/local/hadoop-3.3.2/etc/hadoop/
hdfs-site.xml的修改
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hdpdata/name/</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hdpdata/data</value>
</property>
<!-- 复本,三份复本,这也其中一台机器丢了数据其他机器就会找补回来 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
然后分发出去:另外两台关联机器
scp /usr/local/hadoop-3.3.2/etc/hadoop/hdfs-site.xml 192.168.1.88:/usr/local/hadoop-3.3.2/etc/hadoop/
scp /usr/local/hadoop-3.3.2/etc/hadoop/hdfs-site.xml 192.168.1.92:/usr/local/hadoop-3.3.2/etc/hadoop/
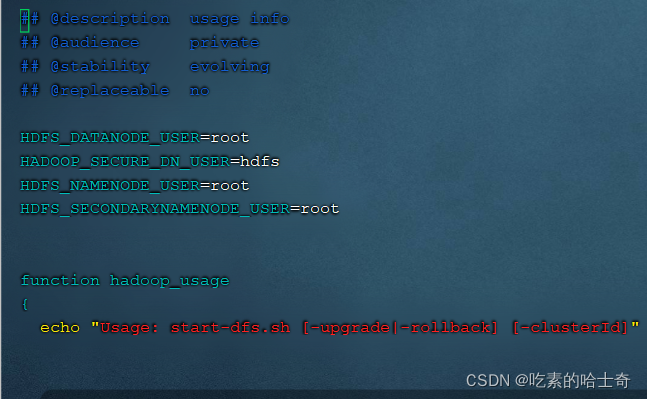
修改start-dfs.sh,stop-dfs.sh
为什么要修改呢:因为默认值的这些参数和你本机不对,所以需要加这个,
按理说应该在/usr/local/hadoop-3.3.2/etc/hadoop里面的某个XXX-env.sh里面去定义的,但是实在太多我也不知道写在哪个里面了。
[root@node121 sbin]# vim start-dfs.sh
[root@node121 sbin]# vim stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root