本文属于【Azure Data Platform】系列。
接上文:【Azure Data Platform】ETL工具(18)――ADF 迭代和条件活动(2)
这次来聊聊Azure Databricks
前言
之所以突然停下ADF的介绍转而向Azure Databricks, 是因为最近公司的项目已经呈现出ADF与Databricks的组合趋势。为了更好地运维公司的项目,有必要了解一下Databricks。并且大概介绍一下Azure Data Factory和Azure Databricks的关系。
什么是Databricks
今时今日,大数据已经不是新鲜事,也已经被大范围地使用。大数据中有一个开源引擎Spark用来支持大规模数据分析。主要通过集群,并行地进行数据处理,从而提高数据处理性能。
Databricks简单来说,就是Azure上的Spark。 它可以很容易地与Blob storage, ADLS, SQL DB, PowerBI 等工具集成
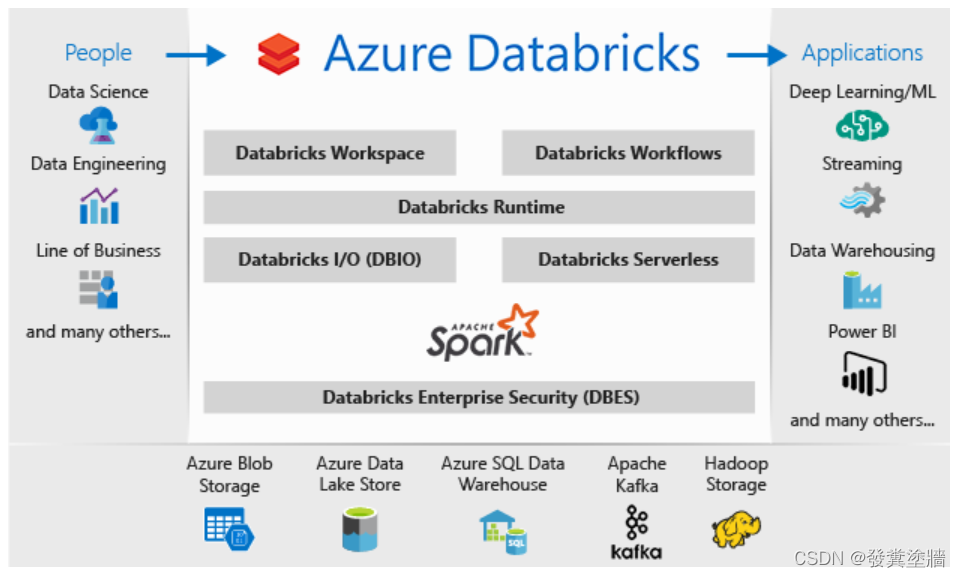
- Databricks Workspace:一个交互式的工作区,用户(主要是数据的消费者)可以通过这个工作区进行合作。
- Databricks Runtime : 用于支持运行,提高性能。
- Databricks File System (DBFS):类似于DataBricks的存储,但是对用户来说是一个抽象层。
它与ADF的区别
ADF主要用于从多个大规模的数据源中进行数据集成,Databricks则通过在单一平台中统一数据、分析和 AI 工作负载从而简化数据架构。
- ADF是一个PaaS,而Databricks偏向于SaaS。
- ADF 偏向于数据集成,Databricks则偏向于数据处理,机器学习等。
- ADF是一个低代码平台,可以通过拖拽的方式来实现绝大部分功能,而Databricks则提供丰富的编程支持
什么时候使用ADF和Databricks
目的上:
ADF:数据集成和数据移动。
Databricks:主要针对机器学习建模。
功能需求上:
ADF:低代码带来的功能并不如Databricks强大。
Databricks:通过编程方式扩展所需功能。
数据处理时效性:
ADF:不适合实时数据流。适合定期抽取数据。
Databricks:通过Spark API,可以实现实时流处理。
综上所述:如果并不需要实时的,过多定制需求的数集成,且希望学习成本不要太高,那么ADF是值得考虑的。否则,那么在ADF和Databricks之间选择的话,Databricks更好。
接下来用一点点篇幅介绍如何创建和使用Azure Databricks。