????����: 1. ����Ϊ�ҵĸ��˸�ϰ�ܽ�, �������ִ��������ʼ�ռ�֪ʶ?������ϸȫ��, �Դǹٷ�������
??????????????2. �����Ǹ����ܽ�, ���������Ļ�����д����
??????????????3. ���д���֮��, ��ָ��
�����˴����������õ�15�������İ�װ, �������4�� �������ж�Ӧ�İ�װ��, ��4���Ժ����в���;
��ͬ�汾�İ�װ�������в�ͬ�İ�װ���÷�ʽ, Ϊ�˲���Ҫ�ı���, ��ʹ�ú���һ���汾�İ�װ�� �Լ� Linuxϵͳ
Ŀ¼:
- Linux
- JDK
- MySQL
- Hadoop
- ZooKeeper
- Hive
- Flume
- Kafka
- HBase-Phoenix
- Scala
- Spark
- Redis
- ClickHouse
- Flink
- ElasticSearch
01. Linux��������
Linux(CentOS-7.6-x64λ)��������, �����ƽ̨VmWare15
CentOS-7.6-x64�������بC> �ٶ�������: https://pan.baidu.com/s/1iWfsCydjEU6soT7HO2OYRA ��ȡ��:1111
VmVare15��װ�����بC> �ٶ�������: https://pan.baidu.com/s/1SfaWn3xpwDBNEGYqipRtaw ��ȡ��:1111
-
������������ú�,ʹ�þ�̬ip, ȷ������(ip��ַ�� 192.168.80.86 ��ǰ3�� 192.168.80 Ϊ���� )ʹ����ȷ, ����������һ��
-
VmWare����������༭����
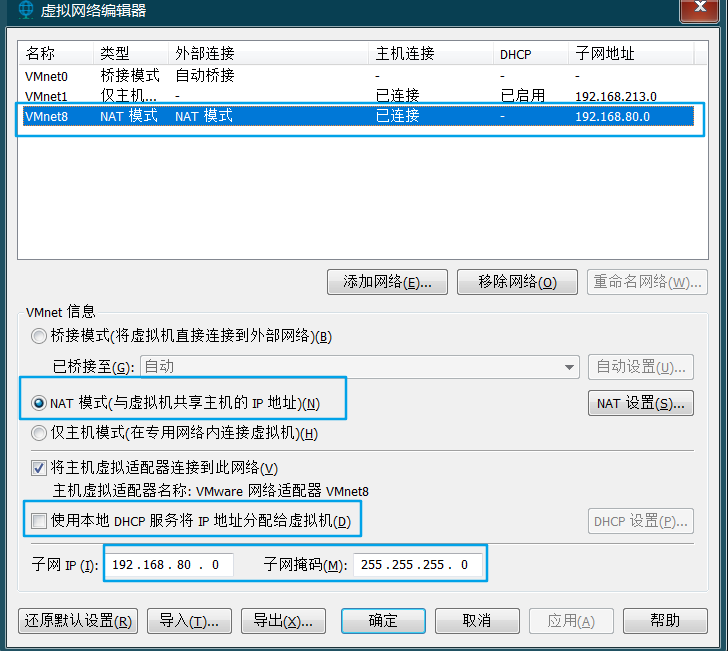
-
�㿪��ͼ��NAT����
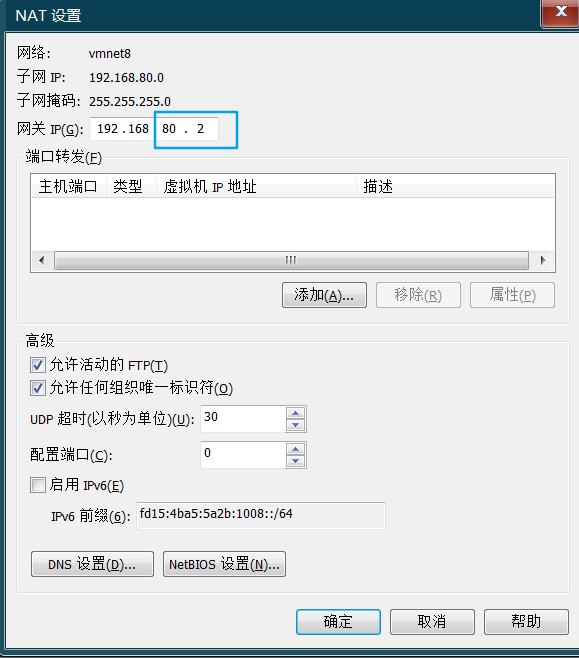
> > > ��ǰһ��ͼͬ����, ����Ϊ.2, ��Ϊ.1��Windows������������ > >-
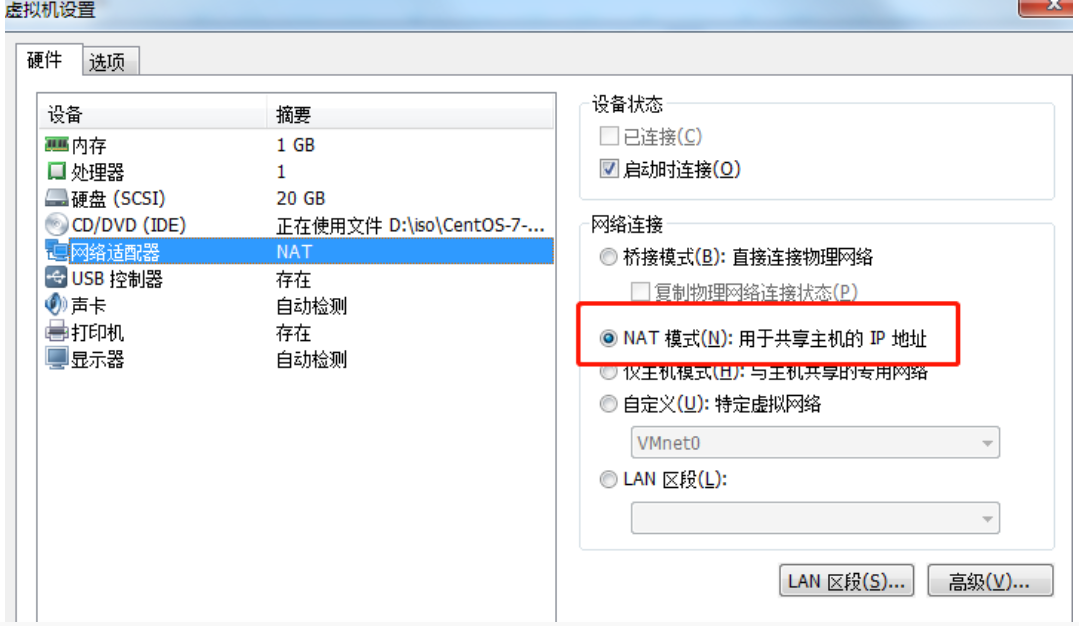
ȷ��Ҫ�����������������������������NATģʽ
-
������������ļ�
vi /etc/sysconfig/network-scripts/ifcfg-ens33DEVICE=��eth0��
BOOTPROTO=��static��
HWADDR=��00:0C:29:83:7F:54��
IPV6INIT=��yes��
NM_CONTROLLED=��yes��
ONBOOT=��yes��TYPE=��Ethernet��
UUID=��aae85c0a-42db-4772-b940-0fc9c875afd2��IPADDR=192.168.80.86 (ͬ����,��ѡ.0, .1, .2)
GATEWAY=192.168.80.2
NETMASK=255.255.255.0
DNS1=192.168.80.2 (������һ������)
DNS2=114.114.114.114
-
�����������
systemctl restart network
-
-
yum���� ��رر���������
yum install -y rsync gcc gcc-c++ vim wget perl ntp ntpdate net-tools lrzsz libaio -
����hosts�ļ�
vim /etc/hosts192.168.80.11 hadoop102 192.168.80.12 hadoop103 192.168.80.13 hadoop104windows��hosts�ļ�Ҳ����һ��,��������˱����ļ�, ���� C:\WINDOWS\System32\drivers\etc Ŀ¼��
-
����SSH���ܵ�¼
-
ִ��ssh-keygen -t rsa (һֱ�س�)���ɹ�Կ˽Կ
-
cd ~/.ssh
-
�� ~/.sshĿ¼�� ssh-copy-id hadoop102 ssh-copy-id hadoop103
ssh-copy-id hadoop104 (hadoop104���ʲ�ͨhadoop102ʱ,��hadoop104��ִ����Щ����)
-
-
�ű���д:
-
�Լ���дxsync.sh�ű�(���ڼ�Ŀ¼��,��Ŀ¼���õ���������/etc/profile��Path��),��rsync����װ,�ڼ�Ⱥ�䷢�Ϳ����ļ�
�ĵ������ļ�����sourceһ�²�����Ч
export PATH=$PATH:~/binxsync.sh�ı�д
#!/bin/bash #1. �жϲ������� if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. ������Ⱥ���л��� for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. ��������Ŀ¼,�������� for file in $@ do #4 �ж��ļ��Ƿ���� if [ -e $file ] then #5. ��ȡ��Ŀ¼ pdir=$(cd -P $(dirname $file); pwd) #6. ��ȡ��ǰ�ļ������� fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done donecd ������, pwdһ����ʾ��������ָ���ʵ���ļ�����Ŀ¼; �� cd -P ������, pwdһ����ʾ��������������Ŀ¼
chmod +x xsync.sh
-
ת������ű�all
#!/bin/bash for i in hadoop102 hadoop103 hadoop104 do echo --------- $i ---------- ssh $i "$*" donechmod +x all
-
-
�رղ����÷���ǽ����
systemctl stop firewalld && systemctl disable firewalld -
����ʱ��Ϊ����ʱ��, ʱ��ͬ��
ntpdate ntp.aliyun.comhwclock --systohc
������ڴ����¿���,�������������,�Ժ���Զ�β�����ϰ
02. JDK��װ����
Linux�� OpenJDK1.8 �İ�װ�뻷����������
��װ�����بC> �ٶ�������: https://pan.baidu.com/s/1aN9VVMYc9_Fw_xq0Q-lOxA ��ȡ��:1111
-
��ѹ��ָ��Ŀ¼��������Ϊ /opt/module/jdk-1.8
-
���û�������
vim /etc/profile.d/jdk.sh -
����Ƿ�װ�ɹ�
java -version -
���û�������
vim /etc/profile.d/jdk.sh# JAVA export JAVA_HOME=/opt/module/jdk-1.8 export PATH=$PATH:$JAVA_HOME/binsource /etc/profile.d/jdk.sh chmod 755 /tmp/hsperfdata_* -
xsyn.shͬ���ַ�
��Ⱥͬ���ַ��ļ�
��Ⱥͬ���ַ������ļ�/etc/profile.d/jdk.sh�Ļ�,��Ҫsourceһ��
03. MySQL��װ����
MySQL 5.7.16 ��װ����, Ĭ�����Ӷ˿�3306
��װ�����بC> �ٶ�������: https://pan.baidu.com/s/19PlQdOiInNxXzFpGDqjhHA ��ȡ��:1111
-
����Ƿ�������װ��mysql
rpm -qa|grep mariadb # ����,��� rpm -e --nodeps mariadb-libs -
���mysql������������ libaio�� net-tools �� perl
rpm -qa|grep libaio rpm -qa|grep net-tools rpm -qa|grep perl # ��û��,���Ե��Դ���media�������Ұ�װ�����а�װ -
�����ļ��ж�д��ִ��Ȩ��
# ����mysql��װ������,��ͨ��mysql�û���/tmpĿ¼���½�tmp_db�ļ�,�������/tmp�ϴ��Ȩ�� chmod -R 777 /tmp -
��װ, ��rpm��װ, �����ü���tar.gz��װ
# ��mysql�İ�װ�ļ�Ŀ¼��ִ��:(���밴��˳��ִ��) rpm -ivh mysql-community-common-5.7.16-1.el7.x86_64.rpm rpm -ivh mysql-community-libs-5.7.16-1.el7.x86_64.rpm rpm -ivh mysql-community-client-5.7.16-1.el7.x86_64.rpm rpm -ivh mysql-community-server-5.7.16-1.el7.x86_64.rpm -
����Ƿ�װ�ɹ�
mysqladmin --version -
mysql����ij�ʼ��
mysqld --initialize --user=mysql # �鿴����: cat /var/log/mysqld.log | grep root@localhost # root@localhost: ������dz�ʼ��������, :+�ո�+���� -
����ͣ
����: systemctl start mysqld �ر�: systemctl stop mysqld ������: systemctl enable mysqld (mysqld.service) -
�״ε�¼
# ��½��������,��Ȼ�ó�ʼ������������ ALTER USER 'root'@'localhost' IDENTIFIED BY 'root12345'; # Ȼ���˳�,�����������µ�¼ -
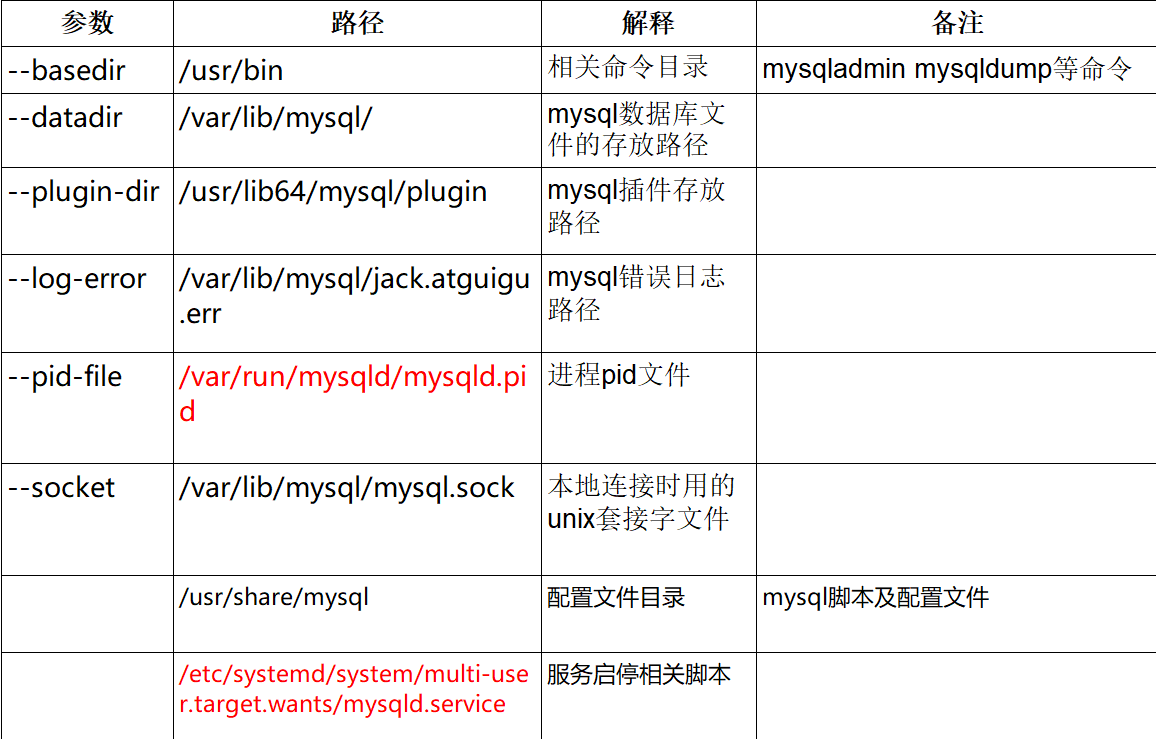
mysql�İ�װĿ¼
-
��������Զ�̷���
grant all privileges on *.* to root@'%' identified by 'root12345';flush privileges; -
sqlmode
show variables like ��sql_mode��;
set sql_mode=��ONLY_FULL_GROUP_BY��;sql_mode����ֵ����:
-
ONLY_FULL_GROUP_BY:
����GROUP BY�ۺϲ���,�����SELECT�е���,û����GROUP BY�г���,��ô���SQL�Dz��Ϸ���,��Ϊ�в���GROUP BY�Ӿ��� -
NO_AUTO_VALUE_ON_ZERO:
��ֵӰ���������еIJ��롣Ĭ��������,����0��NULL����������һ��������ֵ������û� ϣ�������ֵΪ0,������������������,��ô���ѡ��������ˡ� -
STRICT_TRANS_TABLES:
�ڸ�ģʽ��,���һ��ֵ���ܲ��뵽һ���������,���жϵ�ǰ�IJ���,�Է��������������
NO_ZERO_IN_DATE:
���ϸ�ģʽ��,���������ں��·�Ϊ�� -
NO_ZERO_DATE:
���ø�ֵ,mysql���ݿⲻ��������������,���������ڻ��׳���������Ǿ��档 -
ERROR_FOR_DIVISION_BY_ZERO:
��INSERT��UPDATE������,������ݱ����,�����������Ǿ��档�� ��δ������ģʽ,��ô���ݱ����ʱMySQL����NULL -
NO_AUTO_CREATE_USER:
��ֹGRANT��������Ϊ�յ��û� -
NO_ENGINE_SUBSTITUTION:
�����Ҫ�Ĵ洢���汻���û�δ����,��ô�׳��������ô�ֵʱ,��Ĭ�ϵĴ洢�������,���׳�һ���쳣 -
PIPES_AS_CONCAT:
��"||"��Ϊ�ַ��������Ӳ��������ǻ������,���Oracle���ݿ���һ����,Ҳ���ַ�����ƴ�Ӻ���Concat������ -
ANSI_QUOTES:
����ANSI_QUOTES��,������˫�����������ַ���,��Ϊ��������Ϊʶ��� -
ORACLE: ���õ�ͬPIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,
? NO_KEY_OPTIONS, NO_TABLE_OPTIONS, NO_FIELD_OPTIONS, NO_AUTO_CREATE_USER
-
-
���ַ���
vim /etc/my.cnf
�������������ַ������� character_set_server=utf8mb4, ����mysql
���Ѿ����ڵĿ���: alter database mydb character set ��utf8mb4��;
���Ѿ����ڵı���: alter table mytbl convert to character set ��utf8mb4��;
���Ѿ����ڵ�����,��Ҫ��ֻ��ɾ��������������������
Ȼ������mysqld���� systemctl restart mysqld.service
-
mysql����
-
Can��t connect to local MySQL server through socket ��/var/run/mysqld/mysqld.sock��
����취: �����ļ���mysqld��ָ��socketʵ��·��,�������socket = /var/lib/mysql/mysql.sock
-
[ERROR] Plugin ��InnoDB�� init function returned error.
? [ERROR] Plugin ��InnoDB�� registration as a STORAGE ENGINE failed.
? ����취: ��/var/lib/mysql��ib_logfile��ͷ���ļ�ɾ����
- mysql����ʧ��ʱ,����var/run/mysqldĿ¼ɾ���ؽ�
-
-
maxwellʱ����
server-id=1
log-bin=master
binlog_format=row
����mysqld������: /usr/sbin/mysqld --user=root
04. Hadoop��Ⱥ�
Hadoop[3.1.3] ��ȫ�ֲ�ʽģʽ�����
��װ������ --> �ٶ�������: https://pan.baidu.com/s/1HDEF-JoWfD-Nj_9rEkyyBg ��ȡ��:1111
-
��ѹ��ָ��Ŀ¼��������Ϊ /opt/module/hadoop-3.1.3
-
���û������� vim /etc/profile.d/hdp.sh
#HADOOP export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
Hadoop��ҪĿ¼
(1)binĿ¼:��Ŷ�Hadoop��ط���(HDFS,YARN)���в����Ľű�
(2)etcĿ¼:Hadoop�������ļ�Ŀ¼
(3)libĿ¼: ���Hadoop�ı��ؿ�(�����ݽ���ѹ����ѹ������)
(4)sbinĿ¼:���������ֹͣHadoop��ط���Ľű�
(5)shareĿ¼:���Hadoop������jar�����ĵ����ٷ�����
Hadoop������ģʽ:
- ����ģʽ: �Ƿֲ�ʽ, �����κ�����, ֱ�Ӽ�Java��������, �������� HDFS&Yarn
- α�ֲ�ʽģʽ: HDFS&Yarn����ͬһ̨������ͬһ��Hadoop��
- ��ȫ�ֲ�ʽģʽ: HDFS&Yarn�ڲ�ͬ�����IJ�ͬHadoop��
��Ⱥ�滮����:
-
NameNode��SecondaryNameNode��Ҫ��װ��ͬһ̨������
-
ResourceManagerҲ�������ڴ�,��Ҫ��NameNode��SecondaryNameNode������ͬһ̨������
-
hadoop103���ٸ�cpu (1*2)��,8g�ڴ�, ��ΪYarn̫����Դ
hadoop102 hadoop103 hadoop104 HDFS NameNode DataNode DataNode SecondaryNameNode DataNode YARN NodeManager ResourceManager NodeManager NodeManager
�����ļ�:
��$HADOOP_HOME/etc/hadoop/hadoop-env.sh������
export JAVA_HOME=/opt/module/jdk-1.8
��$HADOOP_HOME/etc/hadoop/workers��д��: (���ж���ո����)
hadoop102
hadoop103
hadoop104
���������ļ�: core, hdfs, mapred, yarn, ����site�ļ���,�ֶ��������ĸ�-site.xml��һ��,��������Ҫ���û��Ƿŵ�core-site.xml��
core-site.xml:
<configuration>
<!--�洢Ŀ¼-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!--����������,�û�,����-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- ����hadoop fs -ls ������ʾ����Ŀ¼������-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<!--����,0������������ȫģʽ,���ڵ���1����������ȫģʽ -->
<property>
<name>dfs.safemode.threshold.pct</name>
<value>0</value>
</property>
<!--secondnode�ĵ�ַ-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
<!-- nn web �˷��ʵ�ַ-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- ָ��HDFS����������,Ĭ��Ϊ3 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred.xml:
<configuration>
<!-- ָ��MR���������� -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- ��ʷ�������˵�ַ -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- ��ʷ������web�˵�ַ -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
<!-- ���Ҳ���classpath -->
<property>
<name>mapreduce.application.classpath</name>
<value>
${HADOOP_HOME}/etc/hadoop,
${HADOOP_HOME}/share/hadoop/common/*,
${HADOOP_HOME}/share/hadoop/common/lib/*,
${HADOOP_HOME}/share/hadoop/hdfs/*,
${HADOOP_HOME}/share/hadoop/hdfs/lib/*,
${HADOOP_HOME}/share/hadoop/mapreduce/*,
${HADOOP_HOME}/share/hadoop/mapreduce/lib/*,
${HADOOP_HOME}/share/hadoop/yarn/*,
${HADOOP_HOME}/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
yarn-site.xml:
<configuration>
<!--����Task��������С����ڴ�-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!--NodeManager���ڴ�-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!--�����ڴ���ص�, jdk8����ڴ���centos7����ڴ��ͻ-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- ��־������ -->
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.timeline-service.hostname</name>
<value>${yarn.resourcemanager.hostname}</value>
</property>
<property>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<!-- ������־�ۼ����� -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- ������־�ۼ���������ַ(��ÿ����������־�ŵ�һ��) -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- ������־����ʱ��Ϊ 7 �� -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- yarn��ip:port -->
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop103:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop103:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop103:8031</value>
</property>
<!-- ���Ҳ�����·�� -->
<property>
<name>yarn.application.classpath</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/common/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/hdfs/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/mapreduce/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn:/opt/module/hadoop-3.1.3/share/hadoop/yarn/lib/*:/opt/module/hadoop-3.1.3/share/hadoop/yarn/*</value>
</property>
<!-- ָ�� ResourceManager �ĵ�ַ-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- ָ�� MR �� shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ���������ļ̳� -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
</configuration>
��ȫ�û�:
1������start-dfs.sh��stop-dfs.sh�ļ�,�������в���:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
2������start-yarn.sh��stop-yarn.sh�ļ�,�������в���:
YARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root
������Ⱥ
1. ��ʽ��:
? ��һ������ʱ��hadoop102��ʽ��NameNode, �����ʽ��ʧ��,��Ҫɱ�����е�hadoop����,Ȼ��ɾ��ָ���ı���dataĿ¼ (��ֹ���¸�ʽ�����ɵ�clusterId��dataĿ¼���ϵ�clusterId��һ��)
hdfs namenode -format
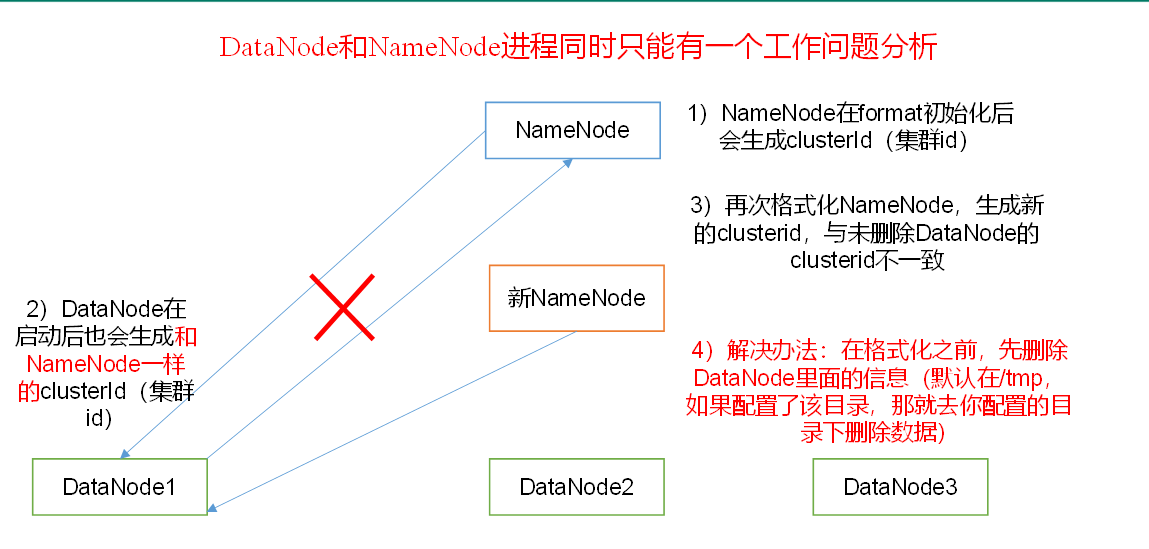
2. xsync.sh��Ⱥ�ַ�
��Ⱥͬ���ַ��ļ�
��Ⱥͬ���ַ������ļ�/etc/profile.d/hdp.sh�Ļ�,��Ҫsourceһ��
3. ����ֹͣ����:
sbin/start-all.sh
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
hdfs --daemon start namenode/datanode/secondarynamenode
yarn --daemon start resourcemanager/nodemanager
4.���Թٷ�����wordcount
��дwc.txt �ϴ���HDFS��, �������ŵ�HDFS��/out��, ���ܼ���ɹ�, ��˵����װ����OK��
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wc.txt /out
5. Web�˷���:
- �鿴NN http://hadoop102:9870/
- �鿴2NN http://hadoop104:9868/status.html
- �鿴MR����־ http://hadoop102:19888/jobhistory
- �鿴Yarn�ļ����־(��ȫ,��ֻ��MR) http://hadoop103:8088/
05. ZooKeeper��Ⱥ�
ZooKeeper [3.5.7] �����е��������ͼ�Ⱥ�����, Ĭ�����Ӷ˿ں�2181
��װ�����بC> �ٶ�������: https://pan.baidu.com/s/1PsiwnwILw8pk_gDh726tIw ��ȡ��:1111
-
������
-
��ѹ��ָ��Ŀ¼��������Ϊ /opt/module/zookeeper-3.5.7
-
���û�������
vim /etc/profile.d/zk.sh# ZOOKEEPER export ZOOKEEPER_HOME=/opt/module/zookeeper-3.5.7 export PATH=$PATH:$ZOOKEEPER_HOME/binsource /etc/profile.d/zk.sh -
����ZooKeeper����Ҫ�Ĺ���Ŀ¼
mkdir /opt/module/zookeeper-3.5.7/zkData -
����ģ�����������ļ�
cp /opt/module/zookeeper-3.5.7/conf/zoo_sample.cfg /opt/module/zookeeper-3.5.7/conf/zoo.cfg -
�༭�����ļ�
vim /opt/module/zookeeper-3.5.7/conf/zoo.cfg#����������: dataDir=/opt/module/zookeeper-3.5.7/zkData -
ZooKeeper��������ֹͣ
���������: /opt/module/zookeeper-3.5.7/bin/zkServer.sh start
�����״̬�鿴: /opt/module/zookeeper-3.5.7/bin/zkServer.sh status
����˹ر�: /opt/module/zookeeper-3.5.7/bin/zkServer.sh stop
jpsһ�³���:
4020 Jps 4001 QuorumPeerMain #��ΪZooKeeper����
�ͻ�������: /opt/module/zookeeper-3.5.7/bin/zkCli.sh
�ͻ����˳�: quit
-
-
��Ⱥ��
�������굥����Ļ�����, ��ÿ�������� /opt/module/zookeeper-3.5.7/zkData���½�һ��myid���ļ�,����д���Լ���id(����, ���ظ�����)
Ȼ���������ļ�/opt/module/zookeeper-3.5.7/conf/zoo.cfg������
#######################cluster##########################server.2=hadoop102:2888:3888server.3=hadoop103:2888:3888server.4=hadoop104:2888:3888#��server.2=hadoop102:2888:3888Ϊ��, 2ָ����myid��id��,#2888�˿������������Follower�뼯Ⱥ�е�Leader������������Ϣ�Ķ˿�,#3888�˿���ѡ��ʱͨѶҪ�õĶ˿���Ⱥͬ���ַ��ļ����������myid�ļ�,ʹÿ��������id����һ��,
��Ⱥͬ���ַ������ļ�/etc/profile.d/zk.sh�Ļ�,��Ҫsourceһ��
�ͻ��˻�������:
�������� �������� help ��ʾ���в������� ls path ʹ�� ls �������鿴��ǰznode���ӽڵ� -w �����ӽڵ�仯 -s ���Ӵμ���Ϣ create ��ͨ���� -s �������� -e ��ʱ(�������߳�ʱ��ʧ) get path ��ýڵ��ֵ -w �����ڵ����ݱ仯 -s ���Ӵμ���Ϣ set ���ýڵ�ľ���ֵ stat �鿴�ڵ�״̬ delete ɾ���ڵ� deleteall �ݹ�ɾ���ڵ�
�����ļ����:
1)tickTime =2000:ͨ��������,ZooKeeper��������ͻ�������ʱ��,��λ����
ZooKeeperʹ�õĻ���ʱ��,������֮���ͻ����������֮��ά��������ʱ����,Ҳ����ÿ��tickTimeʱ��ͻᷢ��һ������,ʱ�䵥λΪ���롣
��������������,����������С��session��ʱʱ��Ϊ��������ʱ�䡣(session����С��ʱʱ����2*tickTime)
2)initLimit =10:LF��ʼͨ��ʱ��
Follwer��Leader���� initLimit * tickTime��û��ʼ����ʱ�����Ͻ���ͨ��,���߳�Follwer
3)syncLimit =5:LFͬ��ͨ��ʱ��
Follwer��Leader���� syncLimit * tickTime��û�ɹ�����ͬ��,���߳�Follwer
4)dataDir:�����ļ�Ŀ¼**+**���ݳ־û�·��
��Ҫ���ڱ���ZooKeeper�е����ݡ�
5)clientPort =2181:����˶˿�
06. Hive��װ����
Hive [3.1.2] �����пͻ��˽��� ֱ�ӱ�������, ��metastore����ʽ��������,
��hiveserver2-JDBCԶ������(�˿ں�10000)3��
Hive��װ�����بC> �ٶ�������: https://pan.baidu.com/s/1NrCB-Qi-hO0n8EfHnu3HLw ��ȡ��:1111
MySQL��JDBC�������������بC> �ٶ�������: https://pan.baidu.com/s/1u_vThTJI0z-oP2pPOODJ9g ��ȡ��:1111
������Hadoop��HDFS��MapReduce, ������������Hadoop��HDFS��Yarn
-
ֱ�ӱ�������
-
��ѹ��ָ��Ŀ¼��������Ϊ /opt/module/hive-3.1.2
-
���û�������
vim /etc/profile.d/hive.sh# HIVE export HIVE_HOME=/opt/module/hive-3.1.2 export PATH=$PATH:$HIVE_HOME/binsource /etc/profile.d/h.sh -
�����־jar����ͻ, ��Hive��lib��
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak -
����Ĭ�ϵ�derby��ΪԪ���ݿ�,��mysql��ΪԪ���ݿ�,������lib������mysql��jdbc������(������õ����Ҹ���İ�װ��,�Ͳ���ִ����һ����,��Ϊ�Ҹ���������ĺ����´����,�Ѿ�������һ����)
-
mysql���½�һ����,����������Ϊmetastore,��Ҳ��������������
-
��conf Ŀ¼���½� hive-site.xml �ļ�,ע���������jdbc(�û���,����,url,����)����
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- jdbc ���ӵ� URL, �����õĿ�,�����洴���� ��Ԫ���ݵĿ�metastore--> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value> </property> <!-- jdbc ���ӵ� Driver--> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <!-- jdbc ���ӵ� username--> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- jdbc ���ӵ� password --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root12345</value> </property> <!-- Hive Ԫ���ݴ洢�汾����֤ --> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <!--Ԫ���ݴ洢��Ȩ--> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!--��ʾ ��ǰ��--> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <!--��ʾ ��ǰ��ͷ--> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <!-- Hive Ĭ���� HDFS �Ĺ���Ŀ¼ --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <!-- <property> <name>hive.exec.mode.local.auto</name> <value>true</value> </property> --> </configuration> -
��ʼ�� Hive Ԫ���ݿ�
schematool -initSchema -dbType mysql - verbose -
����Hive
bin/hive #���ɽ��뵽������mysql��������, ����дsql ����: show databases; use default; create table test (id int); insert into test values(1); select * from test;
-
-
��metastore����ʽ��������
���������汾�����ӵĻ�����
-
�� hive-site.xml �ļ�����������������Ϣ
<!-- ָ���洢Ԫ���ݷ������ڵĵ�ַ --> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop102:9083</value> </property> -
����metastore
hive --service metastore
-
-
��hiveserver2��JDBC����ʽԶ������
���������汾�����ӵĻ�����,��Ϊhiveserver2������metastore
-
�� hive-site.xml �ļ�����������������Ϣ
<!-- ָ�� hiveserver2 ���ӵ� host --><property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value></property><!-- ָ�� hiveserver2 ���ӵĶ˿ں� --><property><name>hive.server2.thrift.port</name><value>10000</value></property> -
��hiveserver2���ڴ�����,
��bin/hive-config.sh����:
export HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-256}
��Ϊexport HADOOP_HEAPSIZE=${HADOOP_HEAPSIZE:-1500}
-
������metastore����, hive --service metastore
������hiveserver2���� hive --service hiveserver2 (�ȴ���Ϊ����)
�����������Ϻ�,���ɿ�ʼ���пͻ���Զ�̷���
�ͻ���ִ�� bin/beeline -u jdbc:hive2://hadoop102:10000 -n root ����ΪHDFS�����õ��û�����
-
07. Flume��װ����
Flume [1.9.0] ��װ����
��װ�����بC> �ٶ�������: https://pan.baidu.com/s/1BtYeNNRwa0yxv2dEfMWhww ��ȡ��:1111
-
��ѹ��ָ��Ŀ¼��������Ϊ /opt/module/flume-1.9.0
-
��lib�ļ����µ�guava-11.0.2.jarɾ���Լ���Hadoop 3.1.3
rm -f /opt/module/flume-1.9.0/lib/guava-11.0.2.jar -
����
-
��װnc
yum install -y nc -
��flumeĿ¼�´���job������
-
�½��༭ flume-netcat-logger.conf�����ļ�
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 # Describe the sink a1.sinks.k1.type = logger # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 -
��flumeĿ¼������flume
bin/flume-ng agent -c conf/ -n a1 -f job/flume-netcat-logger.conf -Dflume.root.logger=INFO,console -
�½�һ���ն� ��44444�˿ڷ�������, �۲�flume����̨�ɼ����ݴ�ӡ���
nc -lk 44444
-
08. Kafka��Ⱥ�
Kafka [2.11-0.11.0.0] ��Ⱥ�
��װ�����بC> �ٶ�������: https://pan.baidu.com/s/1sLSqZEisEfcNiACTEF-0Mw ��ȡ��:1111
������ZooKeeper,������ZooKeeper
��Ⱥ�
��ѹ��ָ��Ŀ¼��������Ϊ /opt/module/kafka_2.11-0.11.0.0
���û�������
vim /etc/profile.d/kfk.sh# KAFKA export KAFKA_HOME=/opt/module/kafka_2.11-0.11.0.0 export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile.d/kfk.sh��/opt/module/kafka_2.11-0.11.0.0 Ŀ¼�´���logs�ļ���
�������ļ� config/server.properties
#��: #broker��ȫ��Ψһ���,�����ظ� broker.id=2 log.dirs=/opt/module/kafka_2.11-0.11.0.0/logs #��������Zookeeper��Ⱥ��ַ zookeeper.connect=hadoop102:2181/kafka #zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka #����: #ɾ��topic����ʹ�� delete.topic.enable=true #��������Զ�̷��� listeners=PLAINTEXT://:9092 advertised.listeners=PLAINTEXT://hadoop101:9092 #����˵�� #num.partitions=1 topic�ڵ�ǰbroker�ϵķ������� #log.retention.hours=168 segment�ļ��������ʱ��, ��ʱ����ɾ���ַ������ļ�/etc/profile.d/kfk.sh��source, �ַ�kafka, ����broker.idʹÿ��������broker.id����һ��
������ZooKeeper,
������Kafka kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
ֹͣKafka kafka-server-stop.sh
����
����һ��topic
kafka-topics.sh --zookeeper hadoop102:2181/kafka --create --replication-factor 3 --partitions 1 --topic demo? �����߷�����Ϣ
kafka-console-producer.sh --broker-list hadoop102:9092 --topic demo? ������������Ϣ
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic demo
09. HBase-Phoenix��Ⱥ�
HBase [2.2.7] ��Ⱥ�, Phoenix�汾5.0.0
��װ�����بC> �ٶ�������: https://pan.baidu.com/s/1W8Szu4MAWTSZW3ursz8RGQ ��ȡ��:1111
������ZooKeeper,HDFS, ������ZooKeeper��HDFS
HBase��Ⱥ�
��ѹ��ָ��Ŀ¼��������Ϊ /opt/module/hbase-2.2.7-bin-phoenix5.0.0
���û�������
vim /etc/profile.d/hbase.sh# HBASE export HBASE_HOME=/opt/module/hbase-2.2.7 export PATH=$PATH:$HBASE_HOME/binsource /etc/profile.d/hbase.sh�༭conf�µ� hbase-env.sh, ����
export HBASE_MANAGES_ZK=false export JAVA_HOME=/opt/module/jdk-1.8�༭conf�µ�hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://hadoop102:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop102,hadoop103,hadoop104</value> </property> <property> <name>hbase.tmp.dir</name> <value>./tmp</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property> <property> <name>hbase.wal.provider</name> <value>filesystem</value> </property> </configuration>�༭conf�µ�reginservers
hadoop102 hadoop103 hadoop104������Hadoop�����ļ���HBase:
ln -s /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml /opt/module/hbase-2.2.7/conf/core-site.xml ln -s /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /opt/module/hbase-2.2.7/conf/hdfs-site.xml�ַ������ļ�/etc/profile.d/hbase.sh��source, �ַ�HBase
3̨�����϶�ִ��ʱ��ͬ��
ntpdate ntp.aliyun.com hwclock --systohc������ZooKeeper,
������HBase start-hbase.sh
ֹͣHBase stop-hbase.sh
�鿴����HBase��Webҳ��: http://hadoop102:16010
����
HBase��Shell����
hbase shelllistcreate 'student','info'put 'student','1001','info:sex','male'scan 'student'
Phoenix��ʹ��
Phoenix��HBase�Ŀ�ԴSQLƤ��������ʹ��sql����HBase�ͻ���API��������,�������ݺͲ�ѯHBase����
�Ҹ��İ�װ�������Ѿ�������Phoenix֮�����´����, ʹ���ҵİ�װ�� �Ͳ��ôӹ�������Phoenix��; ��ʹ�ù�����,���ø�¼����IJ��谲װ����
���û�������
vim /etc/profile.d/hbase.sh#PHOENIXexport PHOENIX_HOME=/opt/module/hbase-2.2.7/phoenixexport PHOENIX_CLASSPATH=$PHOENIX_HOMEexport PATH=$PATH:$PHOENIX_HOME/binsource /etc/profile.d/hbase.sh����Phoenix
/opt/module/hbase-2.2.7/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181����:
��sql��������,
!tablesCREATE TABLE "teacher"("username" VARCHAR(30) PRIMARY KEY);upsert into "teacher" values('zhangsan');select * from "teacher";
��¼(��������Phoenix, ��װ����Ŀ¼�Լ�����ʵ�����,��һ���ĵط���һ��):
��װbsdtar3
sudo yum install -y epel-releasesudo yum install -y bsdtar3�ϴ�����ѹtar��(������ܻᱨ��ʶ����ļ�ͷ,���Լ���,���߿��Ը���bsdtar)
tar -zxvf /opt/software/apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /opt/module
mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix
����server���������������ڵ��hbase-2.2.7/lib
����client���������������ڵ��hbase-2.2.7/lib
���û�������
vim /etc/profile.d/hbase.sh#PHOENIXexport PHOENIX_HOME=/opt/module/phoenixexport PHOENIX_CLASSPATH=$PHOENIX_HOMEexport PATH=$PATH:$PHOENIX_HOME/binsource /etc/profile.d/hbase.sh����Phoenix
/opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
10. Scala��װ����
Linux�� Scala-2.12.11 �İ�װ�뻷����������
��װ�����بC> �ٶ�������: https://pan.baidu.com/s/1_KYhe95mcUqQBiqtQAkVBA ��ȡ��:1111
-
��ѹ��ָ��Ŀ¼��������Ϊ /opt/module/scala-2.12.11
-
���û�������
vim /etc/profile.d/scala.sh# SCALA export SCALA_HOME=/opt/module/scala-2 export PATH=$PATH:$SCALA_HOME/binsource /etc/profile.d/scala.sh -
xsyn.shͬ���ַ�
��Ⱥͬ���ַ��ļ�
��Ⱥͬ���ַ������ļ�/etc/profile.d/scala.sh�Ļ�,��Ҫsourceһ��
-
����Ƿ�װ�ɹ�
scala -version
11. Spark��Ⱥ�
Spark [3.0.0] ��Ⱥ�, ��Local, Standalone,��Yarn����ģʽ
Spark��װ�����بC> �ٶ�������: https://pan.baidu.com/s/1LIMwN_MCevenyzDZsyVkhQ ��ȡ��:1111
-
Local ģʽ:
-
��ѹ��ָ��Ŀ¼��������Ϊ /opt/module/spark-3.0.0-bin-hadoop3.2
-
���û�������
vim /etc/profile.d/spark.sh# SPARK export SPARK_HOME=/opt/module/spark-3.0.0-bin-hadoop3.2 export PATH=$PATH:$SPARK_HOME/binsource /etc/profile.d/spark.sh -
����spark-shell���ɽ��뽻������
-
���Թٷ�����,����Բ���ʵ�ֵ
spark-submit --class org.apache.spark.examples.SparkPi --master local[2] /opt/module/spark-3.0.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.0.jar 10
-
-
Standaloneģʽ
��Localģʽ�����õĻ�����
-
��conf��
mv slaves.template slaves mv spark-env.sh.template spark-env.shvim slaves
hadoop102 hadoop103 hadoop104vim spark-env.sh
export JAVA_HOME=/opt/module/jdk-1.8 SPARK_MASTER_HOST=hadoop102 SPARK_MASTER_PORT=7077 -
xsyn.shͬ���ַ�
��Ⱥͬ���ַ��ļ�
��Ⱥͬ���ַ������ļ�/etc/profile.d/spark.sh�Ļ�,��Ҫsourceһ��
-
���� sbin/start-all.sh
�ر� sbin/stop-all.sh
�鿴 Master ��Դ��� Web UI ����: http://hadoop102:8080
-
���Թٷ�����,����Բ���ʵ�ֵ
spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop102:7077 /opt/module/spark-3.0.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.0.jar 10
-
-
Yarnģʽ
�����Standalone�Ļ�����
-
vim spark-env.sh ����
YARN_CONF_DIR=/opt/module/hadoop-3.1.3/etc/hadoop -
xsyn.shͬ���ַ�
��Ⱥͬ���ַ��ļ�
��Ⱥͬ���ַ������ļ�/etc/profile.d/spark.sh�Ļ�,��Ҫsourceһ��
-
����HDFS��Yarn, Ȼ��ִ��sbin/start-all.sh ����spark
-
���Թٷ�����,����Բ���ʵ�ֵ
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster /opt/module/spark-3.0.0-bin-hadoop3.2/examples/jars/spark-examples_2.12-3.0.0.jar 10
-
12. Redis�
Redis6 �е���, ��Ⱥ����ģʽ
һ: ����ģʽ
��ѹ
��װ����
yum install -y centos-release-scl scl-utils-build gcc gcc-c++ yum install -y devtoolset-8-toolchain���û���
scl enable devtoolset-8 bash����redis��Ŀ¼ make, ���makeʧ��, make distclean �������һ�ε�make
make #make distcleanmv src bin mkdir /opt/module/redis-6.0.6/logs/ touch /opt/module/redis-6.0.6/logs/redis.log��redis.conf�ļ�
vim redis.conf bind 127.0.0.1 ע�͵��� protected-mode yes ��Ϊ no daemonize no ��Ϊ yes logfile "" ��Ϊ logfile /opt/module/redis-6.0.6/logs/redis.log����
bin/redis-server /xxx/redis.conf
- ����ͻ���:
bin/redis-cli bin/redis-cli -h hadoop101 -p 6379 bin/redis-cli -h hadoop101 -p 6379 -a root12345
- �ر�
bin/redis-cli shutdown
13. ClickHouse��װ����
ClickHouse ��װ����, Ĭ�����Ӷ˿�8123
һ: ����ģʽ
��Linux������һЩ����
vim /etc/security/limits.conf #���� * soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072 vim /etc/security/limits.d/20-nproc.conf #���� * soft nofile 65536 * hard nofile 65536 * soft nproc 131072 * hard nproc 131072 vim /etc/selinux/config #�� SELINUX=disabled��װ����
sudo yum install -y libtool yum install -y *unixODBC*
����һ: rpm��װ, ��������user,ֱ�ӻس������ͺ�
rpm -ivh clickhouse-common-static-21.7.3.14-2.x86_64.rpm rpm -ivh clickhouse-common-static-dbg-21.7.3.14-2.x86_64.rpm rpm -ivh clickhouse-client-21.7.3.14-2.noarch.rpm rpm -ivh clickhouse-server-21.7.3.14-2.noarch.rpm
������: ִ���������yum���߰�װ:
sudo yum install yum-utils sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/clickhouse.repo sudo yum install clickhouse-server clickhouse-client������:
vim /etc/clickhouse-server/config.xml #���� <listen_host>0.0.0.0</listen_host>����
/etc/init.d/clickhouse-server start����ͻ���
clickhouse-client #���д���һ�����Ľ��� clickhouse-client -m #�ֺŴ���һ�����Ľ���, ��ճ���������ֻ����һ���ֺ�����������: Connecting to localhost:9000 as user default. Code: 210. DB::NetException: Connection refused (localhost:9000)
����취:
ʹ��systemctl������ֹͣ, ������ֱ����ԭ��/etc/init.d�µ��ļ�
sudo systemctl stop clickhouse-server
sudo systemctl start clickhouse-server
�ر�
/etc/init.d/clickhouse-server stop��Ҫ�ļ�:
- �����ļ�: /var/lib/clickhouse/
- ��־�ļ�: /var/log/clickhouse-server/clickhouse-server.log
14. Flink��Ⱥ�
Flink [1.1.13] ��Ⱥ�, ��Standalone,Yarn �� Kubernetes����ģʽ
һ: Standaloneģʽ
��ѹ
�������ļ�
vim conf/flink-conf.yaml # �� jobmanager.rpc.address: localhost ��Ϊ��Ӧ��ip taskmanager.numberOfTaskSlots: 1 �ij�4 vim conf/slaves #���� hadoop101����
bin/start-cluster.sh����Web-UI http://localhost:8081
�ύ����
bin/flink run examples/batch/WordCount.jar bin/flink run -c com.atguigu.wc.StreamWordCount myJar/flink-1-1.0-SNAPSHOT-jar-with-dependencies.jar�ر�
bin/stop-cluster.sh
��: Yarnģʽ
������Standalone��ɵĻ�����, ע����ʱ��۵���Դ��Yarn��̬�����
������HDFS��YARN
������HADOOP_CLASSPATH��������, ��source
export HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`����:
-n(�Ccontainer): TaskManager ������
-s(�Cslots): ÿ��TaskManager��slot����, Ĭ��ÿ��TaskManager��1��slot, һ��slotһ��core
-jm: JobManager ���ڴ�(��λ MB)
-tm: ÿ�� taskmanager ���ڴ�(��λ MB)��
-nm: ���appName
-d: ��ִ̨��
һ: Session-Cluster ģʽ
����һ�����õ�Flink��Ⱥ, ÿ��һ��job�����������Ⱥ���� (���Ƽ�)
����, ���ᴴ��һ�� /tmp/.yarn-properties-root����ʱ�ļ�
bin/yarn-session.sh -jm 1024 -tm 1024 -d����http://localhost:8088/cluster ��Yarn������ �����б���Tracking UI��һ�м��ɽ��뵽��ؽ���
�ύ����
bin/flink run examples/batch/WordCount.jar bin/flink run -c com.atguigu.wc.StreamWordCount myJar/flink-1-1.0-SNAPSHOT-jar-with-dependencies.jar�ر�
yarn application -kill application_1631431602106_0001��: yarn-per-job ģʽ
����һ����ʱ��Flink��Ⱥ, ÿ��һ��job���¿�һ����Ⱥ���� (�Ƽ�, ����������, ���ڹ���)
���ύ����ʱ������Ⱥ
�ύ����:
bin/flink run -t yarn-per-job -yjm 1024m -ytm 1024m examples/batch/WordCount.jar�������� -t yarn-per-job
jm���yjm
tm���ytm
15. ElasticSearch��Ⱥ�
ElasticSearch �е���, ��Ⱥ����ģʽ
һ: ����ģʽ
��ѹ
����Linux��ͨ�û�, ��ΪElasticsearch������root�û�ֱ������
useradd es #����es�û� passwd es #Ϊes�û��������� chown -R es:es /opt/module/elasticsearch-7.8.0 #�����û�����Ŀ¼Ȩ��������
vim config/elasticsearch.yml # ������������ cluster.name: elasticsearch node.name: node-1 network.host: 0.0.0.0 http.port: 9200 cluster.initial_master_nodes: ["node-1"]vim /etc/security/limits.conf #���� #ÿ�����̿��Դ��ļ��������� es soft nofile 65536 es hard nofile 65536 vim /etc/security/limits.d/20-nproc.conf #���� #ÿ�����̿��Դ��ļ��������� es soft nofile 65536 es hard nofile 65536 #����ϵͳ�����ÿ���û������Ľ�����������, *����Linux�����û����� * hard nproc 4096 vim /etc/sysctl.conf #���� #һ�����̿���ӵ�е�VMA(�����ڴ�����)������,Ĭ��ֵΪ65536 vm.max_map_count=655360ˢ�¼�������
sysctl -p�л�es�û�, ����
su es bin/elasticsearch # -d������̨���� bin/elasticsearch -dWebUI����: http://hadoop102:9200
��: ��Ⱥģʽ
����������ģʽһ��
ÿ̨������Ҫ��Linuxϵͳ����
��elasticsearch�����ļ�:
vim config/elasticsearch.yml #���� #��Ⱥ���� cluster.name: cluster-es #�ڵ�����,ÿ���ڵ�����Ʋ����ظ� node.name: node-1 #ip��ַ,ÿ���ڵ�ĵ�ַ�����ظ� network.host: hadoop102 #es7.x ֮������������,��ʼ��һ���µļ�Ⱥʱ��Ҫ��������ѡ�� master cluster.initial_master_nodes: ["node-1"] # TODO #�Dz������ʸ����ڵ� node.master: true node.data: true http.port: 9200 # head �����Ҫ������������� http.cors.allow-origin: "*" http.cors.enabled: true http.max_content_length: 200mb #es7.x ֮������������,�ڵ㷢�� discovery.seed_hosts: ["hadoop102:9300","hadoop103:9300","hadoop104:9300"] # TODO gateway.recover_after_nodes: 2 network.tcp.keep_alive: true network.tcp.no_delay: true transport.tcp.compress: true #��Ⱥ��ͬʱ�����������������,Ĭ���� 2 �� cluster.routing.allocation.cluster_concurrent_rebalance: 16 #���ӻ�ɾ���ڵ㼰���ؾ���ʱ�����ָ����̸߳���,Ĭ�� 4 �� cluster.routing.allocation.node_concurrent_recoveries: 16 #��ʼ�����ݻָ�ʱ,�����ָ��̵߳ĸ���,Ĭ�� 4 �� cluster.routing.allocation.node_initial_primaries_recoveries: 16