基础
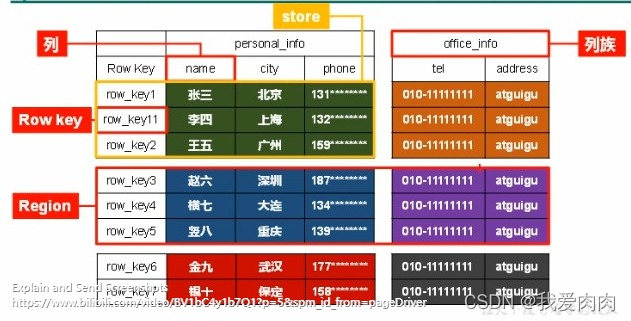
用户自定义的表默认情况下命名空间为default,而系统自带的元数据表的命名空间为hbase
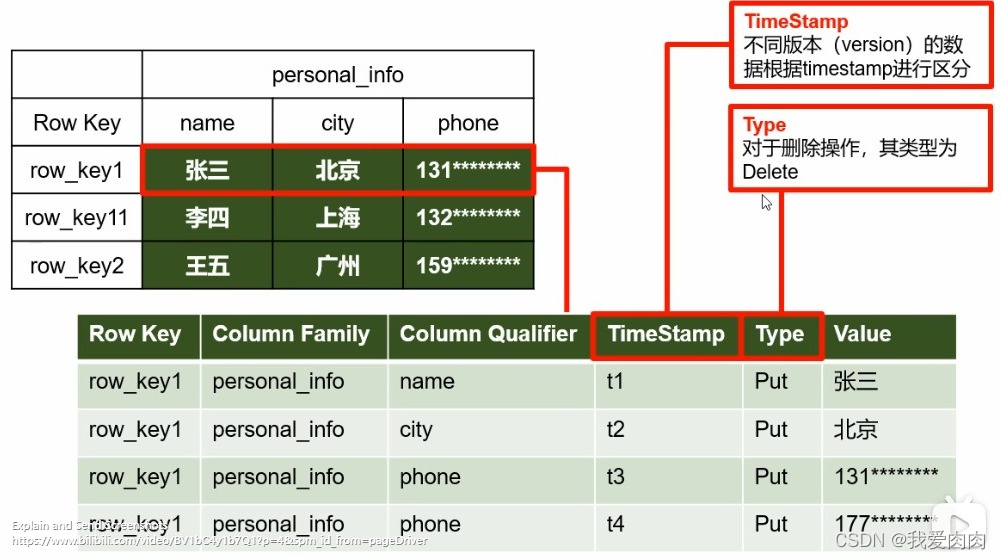
当TimeStamp最大值的Type为Delete,且代表数据已删除,不会返回值
数据按照rowkey字典顺序存储
列族+rowkey+时间戳 来唯一确定数据 = cell 单元格
put 'stu', '1001', 'info:name', 'zhangsan' 插入操作,这里stu为表名,1001为rowkey,info 列:name列名,zhangsan 值
外部文章
Hbase优缺点
Hadoop+HBase+ZooKeeper三者关系与安装配置
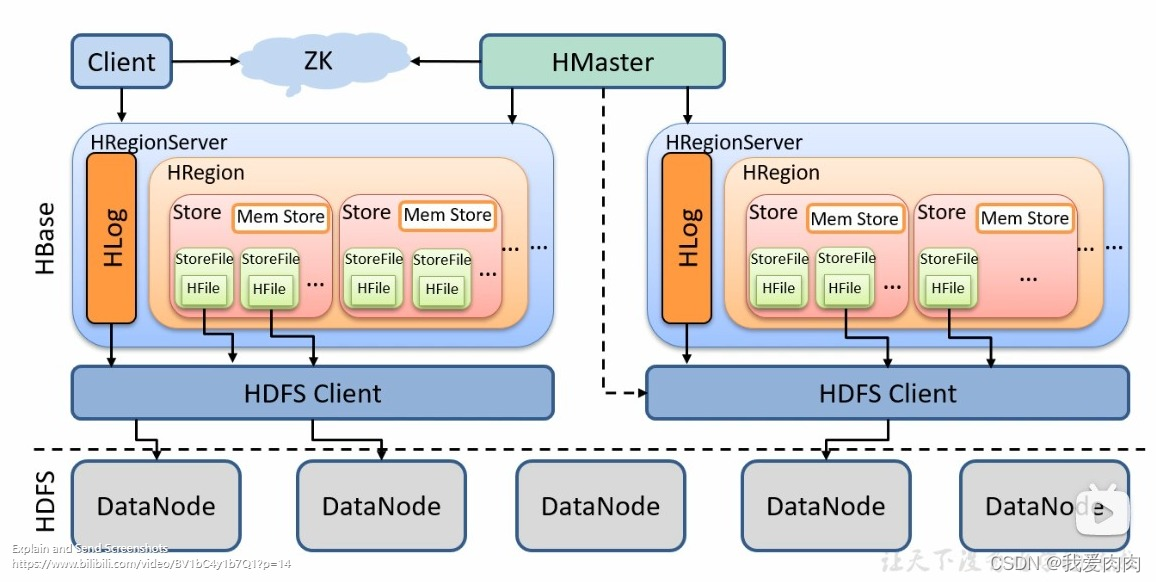
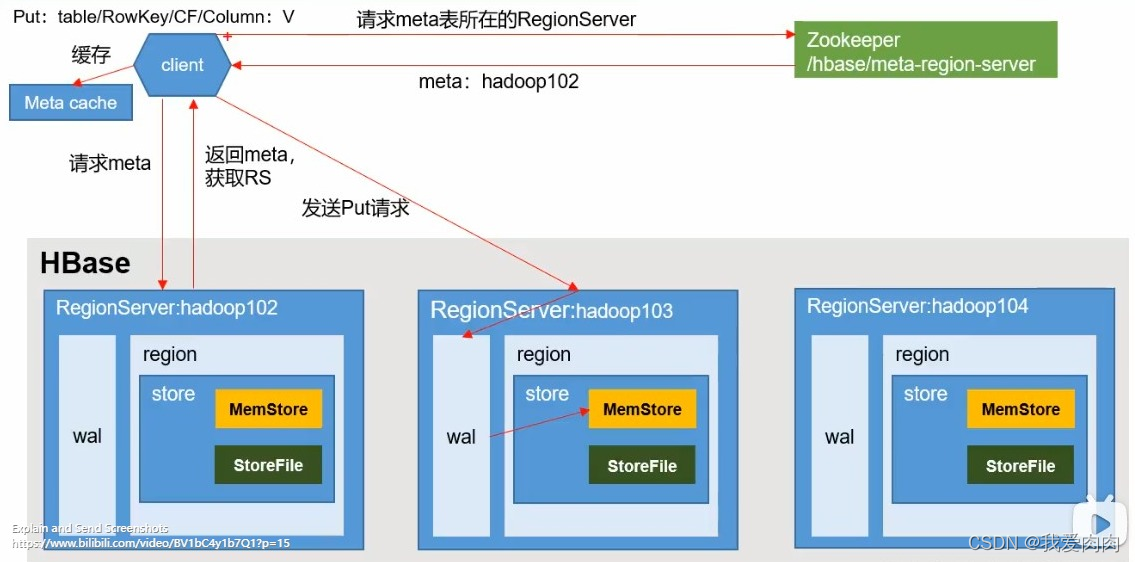
HBase数据检索流程与数据存储
写流程
读流程比写流程慢
写流程
确定 RegionServer 后
1 JUC加锁,为了读写分离
2 写wal日志,如果wal写入失败则删除内存数据回滚
3 数据存入 MemStore
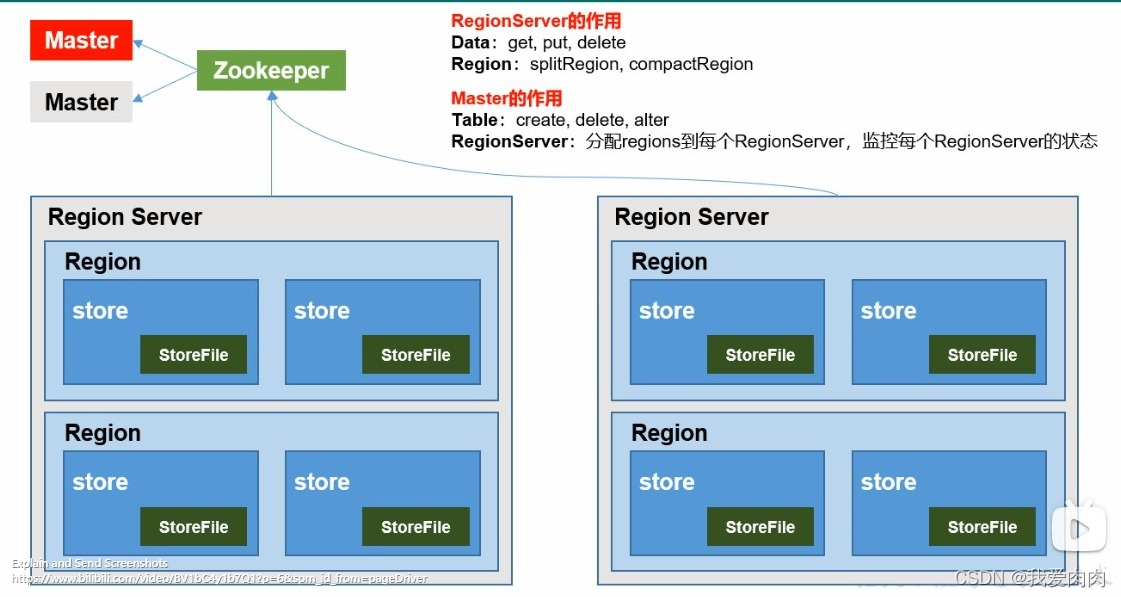
4 RegionServer 内所有 MemStore 达到阈值(百分之45)/ 达到设定时间(默认1h) / 达到HRegion内存阈值(默认128mb)/wal文件数量达到阈值 ,则 Flush 成一个 StoreFile
5 StoreFile增长到一定阈值 ,则触发Compact合并操作,多个StoreFile合并成一个StoreFile
读流程・
因为无法确定内存数据和磁盘数据哪个时间戳更大,所以得同时读取内存和磁盘的数据,
再合并以KeyValueHeap:PriorityQueue形式得出最终结果
数据删除时间点
flush阶段和Compact大合并会删除数据
1 flush:删除当前memStore中重复的数据(timestamp较小的删除)。
如果数据唯一则type标记为删除,但不实际删除数据。
因为flush操作的是memstore的数据,即最新的数据。如果flush时,被memstore标记的数据删除了,StoreFile中有相同rowkey的数据,但是却无法知道该数据已删除,查询数据时会从磁盘中查到理论已删除的数据,则产生冲突
2 Compact:每次flush都会判断一次是否需要合并,有两种合并方式
小合并:就会在该记录上打上标记,被打上标记的记录就成了墓碑记录,该记录使用get和scan查询不到。但不做任何删除数据
大合并:小时间戳数据会被大时间戳数据覆盖,会重新新文件,删除淘汰数据。默认7天,非常消耗时间
3 split:
当每次执行完flush 或者compact操作,都会判断是否需要split。当发生split的时候,会生成两个region A 和 region B但是parent region数据file并不会发生复制等操作,而是region A 和region B 会有这些file的引用。这些引用文件会在下次发生compact操作的时候清理掉,并且当region中有引用文件的时候是不会再进行split操作的