GreatDB ���ݿ����
GreatDB ���ݿ�ؼ���������
- ˮƽ���:֧������sharding�ͷֲ�ʽ����
- ��̬��չ:֧�ֶ�̬����,���������طֲ�
- ���ϻָ�:�����Զ��л���֤ϵͳ�߿�����
- �ֲ�ʽ����:�ṩACID�ֲ�ʽ����֧��
- ���ݰ�ȫ:�ṩ��ҵ�����ݰ�ȫ����,���簲ȫ���,���ʿ���
- MySQLЭ��:��������mysql,�̳�mysql��̬
- SQL�����:֧����ͼ�����������洢���̡��Զ��庯���ȶ���
- ���м���:���ڷֲ�ʽ����,ͨ���ֲ�ʽ����ʵ�ָ�����
- HTAP�ں�:ʵ�ֻ����ڴ�����TP��AP��ϸ���֧��
- �ƻ�֧��:֧��OpenStack���������������ȶ��ֲ���ģʽ
- ����Ӳ��֧��:֧�ֹ�����Ӳ����о�����ڡ�����������,�б�����оƬ���������롢��֮�ȡ�ͳһ����ϵͳ��
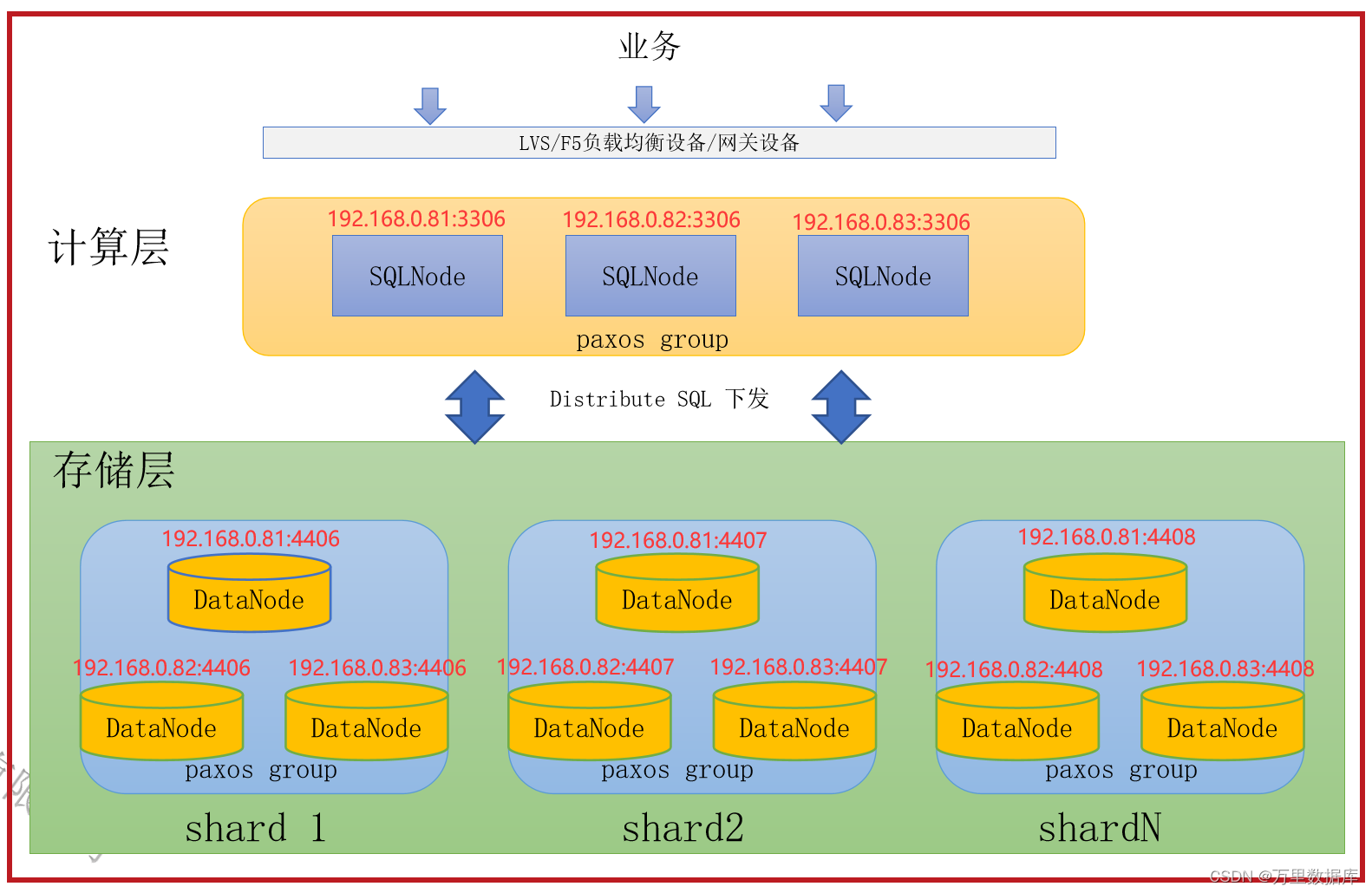
��Ʒ�ܹ�
GreatDB Cluster ��?��?����(share-nothing)�Ҽ���ʹ洢����ļܹ����,�������SQL�ڵ� GreatSQL ���,�洢�������ݽڵ� GreatDB ��ɡ�
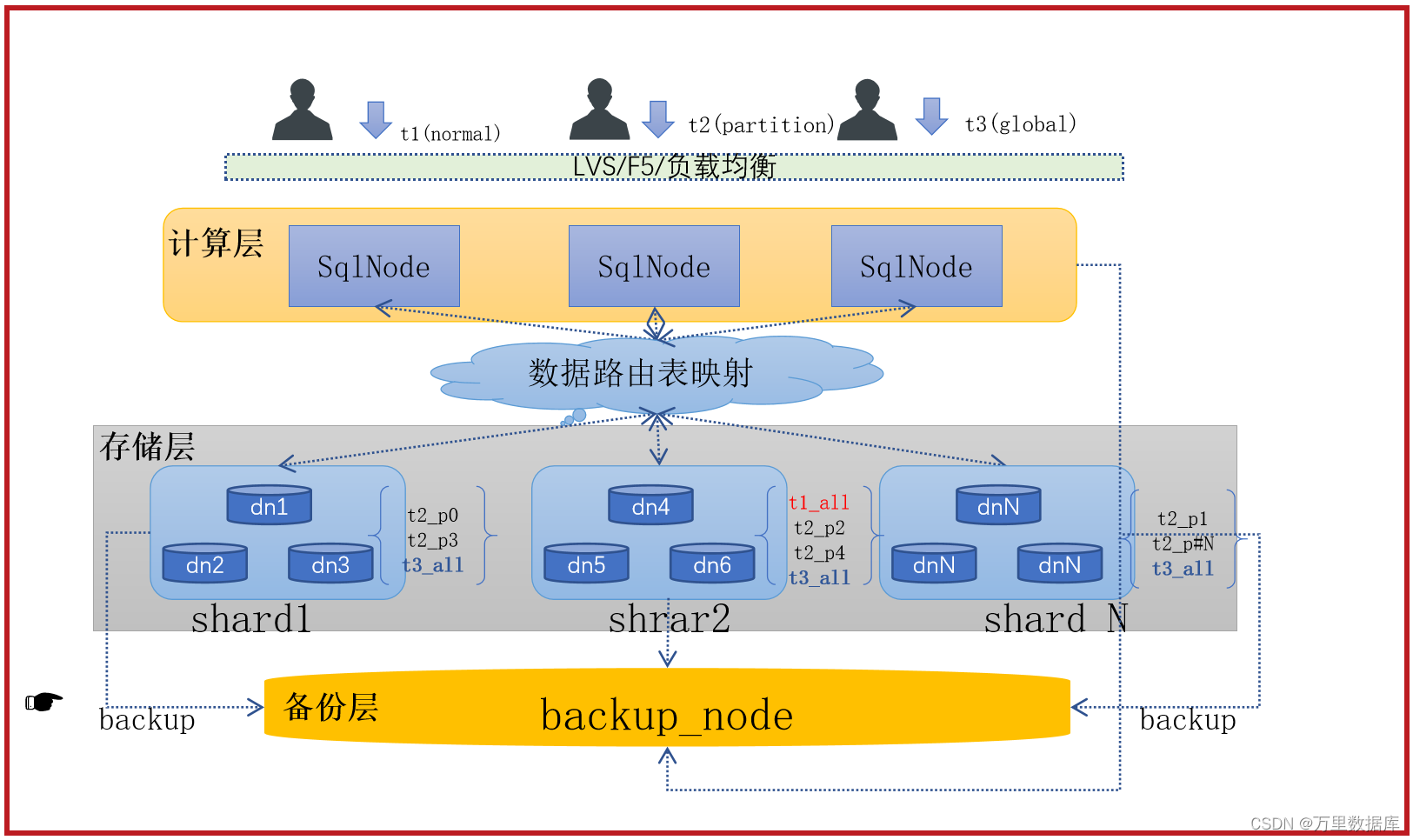
- GreatSQL: SqlNode�ڵ㡣?�ڽ��ա�����?������,ά����ȺԪ����,������Ⱥ״̬��
- GreatDB: DataNode�ڵ�,?�ڽ���SQL�ڵ������,��?�����ݴ�ȡ�IJ���;ά�����ݸ���ǿ?���ԡ�
- ��� GreatSQL����˼����,������еļ�ȺԪ����ͨ�� paxos Э���?ͬ����
- �洢���� shard ��?���ݷ�?����,ͬ?�� shard �ڵĶ��GreatDB ���?�� paxos ������,ά��ͬ?������,��ͬ�� shard ֮������?�ص���
SqlNode �ڵ�
SqlNode �ڵ��������ģ��:
- GreatDB��������,����MGR����ģʽ��
- ���ӹ���: �������?�������ӡ���½����
- SQL����: ��?�������SQL,�������ڲ�parse tree �ĸ�ʽ��
- �ƻ�?��: ���ݱ�Ԫ������Ϣ��ͳ����Ϣ,?������ִ?�ƻ���
- ִ��SQL��SQL����:����ִ?�ƻ�,����DataNode,��?���ݵĻ�ȡ��д?��
- Sequence,SqlNode/DataNode/backup_node��ɾ����,����ִ�С�
DataNode �ڵ�
?�����ݴ洢�� DataNode �ڵ�,�ڵ��ͨ�� paxos Э�鱣֤?�����ݵĶั����ǿ?���ԡ�GreatDB Cluster �� DataNode �������Ǵ洢����,��?������������ļ�����?,���Խ�?��ǿ������,�ֵ������ļ���ѹ?��
��
- ���ݽڵ�����ϲ� SqlNode �·����
- DataNode Ϊ Shard �ij�Ա,һ�� Shard ��ƬΪһ�� Paxos group �����顣
- �洢�ڵ�����һ�� Shard ��Ϊ1��2�ӽṹ��
- Shard �ڲ��洢���ͱ�����������,Shard֧���������ݡ����ݡ�
- �����ݲ������������� Shard ��ԭʼ Shard ֮����������طֲ���
- �����Զ��л�,�����߱�һ���Ľ�׳�ԡ�
GreatDB �ֲ�ʽ��ϵ�����ݿⰲװ����(���ְ�װ��ʽ,��ѡ��һ,�Ƽ�ʹ��Ansible����)
��Ӳ�������������� GreatDB
Cluster���ԺܺõIJ������?�� Intel �ܹ�������������ARM �ܹ��ķ������������������⻯����,��?�־�?����������Ӳ��?�硣��Ϊ?��?�������ݿ�ϵͳ��?��������Linux����ϵͳ��
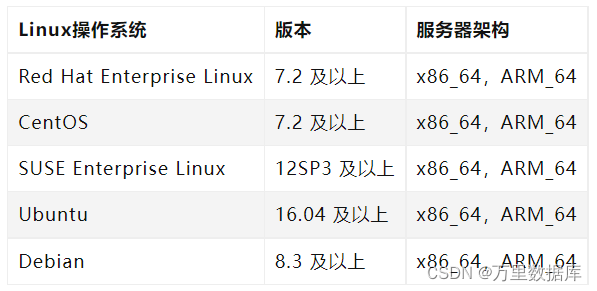
Linux ����ϵͳ�汾Ҫ��
��������������
���������Ի���

SQL�ڵ���?����Ϊ3,������ó�������,��3,5,7��
���ݽڵ��������Ϊ3����������ÿ��shard��3������
?������
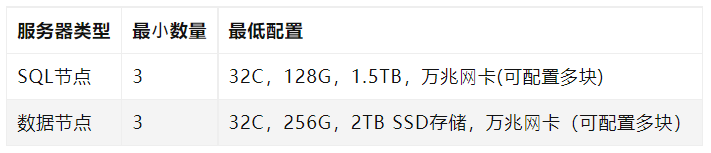
SQL�ڵ���?����Ϊ3,������ó�������,��3,5,7��SQL�ڵ�洢��ȺԪ����,ͬʱ�е�?���ּ�������,��Щ�Ż����Ի�?����ʱ��,�����?��������Ҫ���?,��������SSD��
���ݽڵ���?����Ϊ3,?��shard����?������Ϊ3,��?������Ϊ9,�Ƽ�?����shard�ڸ�������Ϊ3��
BIOS ����
- ѡ�� Performance Per Watt Optimized(DAPC) ģʽ,���� CPU �������
- �ر� C1E ��CStates ��ѡ��,Ŀ��Ҳ��Ϊ������ CPU Ч��
- Memory Frequency(�ڴ�Ƶ��)ѡ�� Maximum Performance(�������)
- �ڴ����ò˵���,���� Node Interleaving,����NUMA����
- �ر� SMMU(�����⻯����ʹ��),����������������,���� BIOS�CMISC Config�CSupport Smmu ����Ϊ Disable
- �ر�Ԥ��,����������������,����BIOS�CMISC Config�CCPU Prefetching Configuration ����ΪDisabled
- �ر� RAID ����Ԥ��һ��������Ϊ Read Policy
- �����Ե��� GreatDB,�� stripe size�� 256k ������ 64k,���ݲ����ȵIJ�ͬ,����������10%-25%
���� CPU ģʽ
���ݿ��������CPU��?ģʽ��Ҫ������ performance ģʽ,����?���ȶ������ܡ�
�� centos7 Ϊ��,ִ?��������������� cpu ��?ģʽ:
# ��鵱ǰcpuģʽ,������ powersave ģʽ
[root@greatdb-test-01 ~]# cpupower frequency-info
...
available cpufreq governors: performance powersave
...
# ����CPUΪ performance ģʽ
[root@greatdb-test-01 ~]# cpupower frequency-set -g "performance"
# performance ģʽ���
[root@greatdb-test-01 ~]# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
performance
ע:����ò����ļ�������,����Ҫ��װ kernel-tools
# CentOS ��װ kernel-tools
yum install kernel-tools -y
# Ubuntu ��װ CPU ģʽ��ͼ�λ��л���
apt install cpufrequtils
�ļ�ϵͳ
����ʹ��xfs�������ļ�ϵͳ
Linux extϵ�е��ļ�ϵͳ,Ӧ�����ļ�ϵͳʷ�Ϸdz�����Ľ�������CentOS 7֮ǰ����Ĭ�ϲ��õ���һϵ���ļ�ϵͳ�����Ǵ�CentOS 7��ʼĬ�ϵ��ļ�ϵͳ�����xfs�ļ�ϵͳ,�ڲ���ϵͳ֧�ֵ������,ѡ��˳������ xfs>ext4>ext3
io���Ȳ�������
�� /sys/block/sda/queue/scheduler ����io��������
����ǻ�еӲ�̽�������� deadline
����� SSD&PCI-E ��������� noop
�������˽ṹ
��?�������˽ṹ
��?�������˽ṹ?�ڸ�?���ٳ����¹���,���Խ����еĽڵ㲿����?̨��������,3��SQL�ڵ�,2��shard,ÿ��shard��3�����ݽڵ㡣����IJ�������ͼ����:
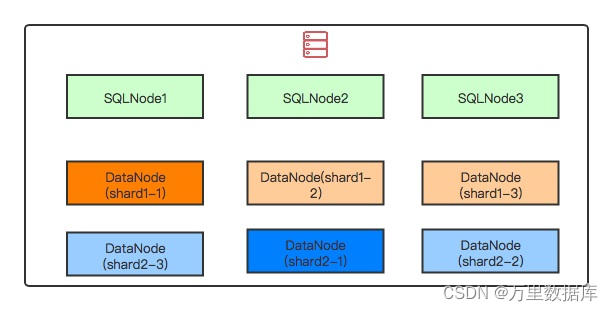
���������Ի�����������,����IJ������ʹ�õ�����������
���������Ի���?���Ŷ�?�ڿ��������Ŷ��ڲ�?�ڽ�?���ܲ��Եij���,���ʺ�?���ܳ����� ��?���ܹ�3̨������,SQL�ڵ������ݽڵ㹲?�����,������������ͼ��
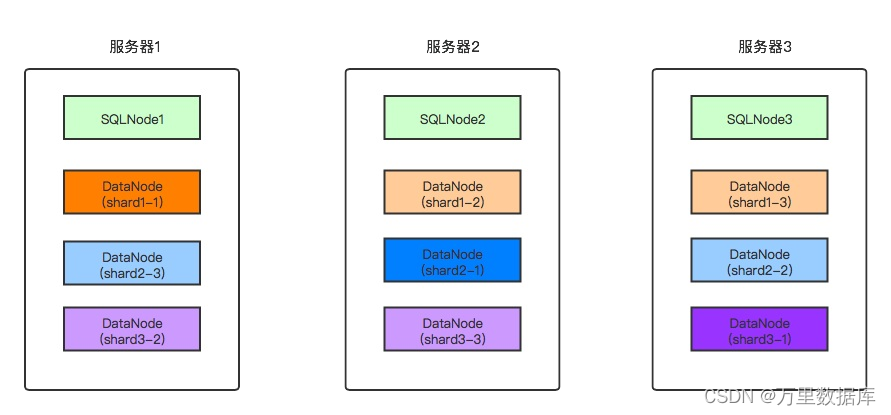
?��������������
��?���ܹ�6̨������,3̨���������,3̨�洢�������ij���,��������ܹ�ͼ��
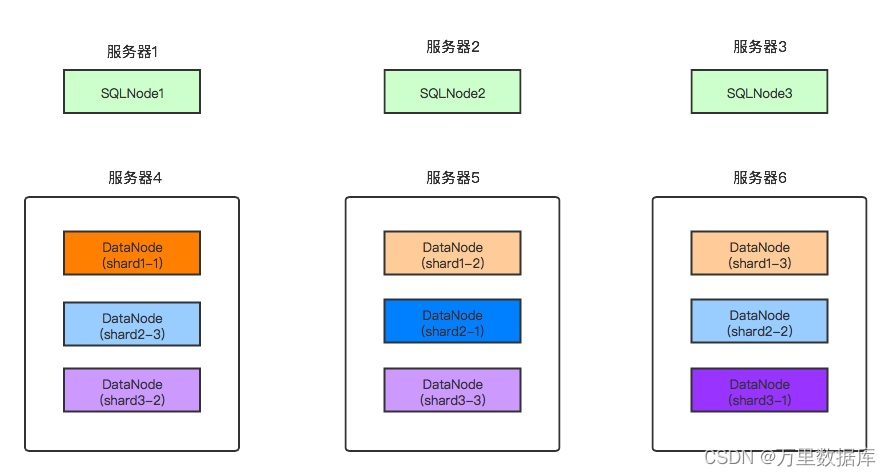
����ʵ��ܹ�ͼ
��װǰ��(���нڵ�)
�رղ���ϵͳ����ǽ��NetworkManager,ʹ��Ansible������Զ��رշ���ǽ
�رղ���ϵͳ����ǽ��NetworkManager,ʹ��Ansible������Զ��رշ���ǽ
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl stop NetworkManager.service
systemctl disable NetworkManager.service
�ر�SELINUX,ʹ��Ansible������Զ��ر�SELINUX
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
setenforce 0
����ʱ����ʱ��,������������ʱ��ͬ��,ʹ��Ansible������Զ�����ʱ��Ϊ Asia/Shanghai
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
date -s "20201021 09:43:00"
[root@enmo ~]# timedatectl
Local time: Wed 2020-10-21 09:43:04 CST
Universal time: Wed 2020-10-21 01:43:04 UTC
RTC time: Wed 2020-10-21 09:43:10
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: n/a
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
����ϵͳ�ں˲���,���������ð�
cat >> /etc/sysctl.conf << EOF
# for GreatDB
kernel.shmall = 965378 # expr `free |grep Mem|awk '{print $2 *1024}'` / `getconf PAGE_SIZE`
kernel.shmmax = 3954188288 # free |grep Mem|awk '{print $2 *1024}'
kernel.shmmni = 4096
kernel.sem = 50100 64128000 50100 1280
fs.file-max = 76724200
net.ipv4.ip_local_port_range = 9000 65000
net.core.rmem_default = 1048576
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 1048576
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_max_syn_backlog = 819200
net.core.netdev_max_backlog = 400000
net.core.somaxconn=4096
vm.overcommit_memory = 0
fs.aio-max-nr = 40960000
net.ipv4.tcp_timestamps = 0
vm.dirty_ratio=10
vm.dirty_background_ratio=10
vm.dirty_writeback_centisecs=100
vm.dirty_expire_centisecs=500
vm.swappiness=1
vm.min_free_kbytes=524288
EOF
sysctl -p
������Դ����,ʹ��Ansible������Զ����� ��greatdb - nofile 655350��
cat >> /etc/security/limits.conf << EOF
# for GreatDB
* soft nofile 1048576
* hard nofile 1048576
* soft nproc unlimited
* hard nproc unlimited
* soft core unlimited
* hard core unlimited
* soft memlock unlimited
* hard memlock unlimited
EOF
# ʹ��Ansible������Զ����� /etc/pam.d/login
cat >> /etc/pam.d/login << EOF
# for GreatDB
session required pam_limits.so
EOF
����ѡ��xfs�ļ�ϵͳ,�������Ż�
#/etc/fstab
/dev/sdb /data xfs defaults,noatime,nodiratime,nobarrier,inode64 0 0
����¼������ʡ���������ʱ�����Ϣ,������־д����ߴ��� IO ��Ч�ʡ������ļ�ϵͳ������
����CPU�������ģʽ
���ݿ��������CPU��?ģʽ��Ҫ������ performance ģʽ,����?���ȶ������ܡ�
cpupower frequency-set -g "performance" # ��������
cpupower frequency-info # ��ѯ��ȷ������
��װϵͳ������,ʹ��Ansible������Զ���װ
[root@greatdb1 ~]# yum install -y numactl-devel
GreatDB Cluster �������������� libaio ��
[root@greatdb1 ~]# yum search libaio
[root@greatdb1 ~]# yum install -y libaio-devel
GreatDB Cluster �ͻ��˳������� libncurses ��
[root@greatdb1 ~]# yum search ncurses
[root@greatdb1 ~]# yum install -y ncurses-devel
��װ��ʽһ,ͨ�� GreatDB-Ansible һ������
��װ Ansible
[root@greatdb1 ~]# rpm -Uvh http://mirrors.ustc.edu.cn/epel/epel-release-latest-7.noarch.rpm
[root@greatdb1 ~]# yum install -y epel-release
[root@greatdb1 ~]# yum install -y ansible
�ϴ���װ��
[root@greatdb1 ~]# ll
total 591188
-rw-r--r--. 1 root root 174080 Feb 25 07:08 greatdb-ansible.tar
-rw-r--r--. 1 root root 605194964 Feb 25 07:08 greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz
��ѹ greatdb-ansible.tar
[root@greatdb1 ~]# tar -xvf greatdb-ansible.tar
���� ansible
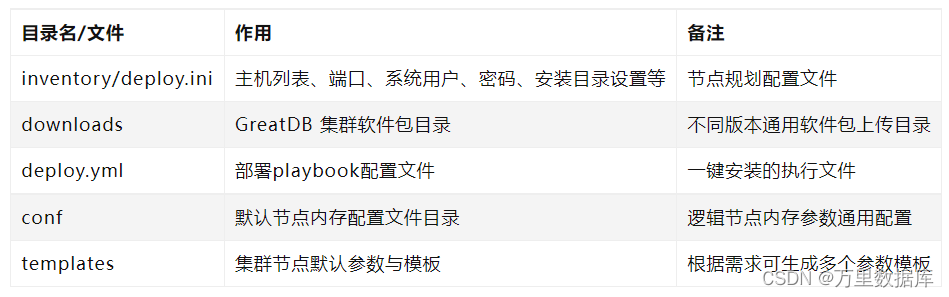
���� inventory/deploy.ini
��װ����ʱ,��� deploy.yml ʹ��;ж�����ʱ,��� clearnup.yml ʹ�á�
[root@greatdb1 ~]# cat greatdb-ansible-master/inventory/deploy.ini
[all:vars]
cluster_username = 'greatdb'
cluster_password = 'greatdb'
package_name = 'greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz'
root_dir = '/greatdb'
ansible_ssh_user=root
ansible_ssh_port=22
ansible_ssh_pass=root
ansible_sudo_pass=
close_firewall = yes
close_selinux = yes
; hosts ��Ӧ�������а�װ greatdb ������ IP
[hosts]
192.168.0.81
192.168.0.82
192.168.0.83
; define sqlnodes
[sqlnodes]
sqlnode1 ansible_host=192.168.0.81
sqlnode2 ansible_host=192.168.0.82
sqlnode3 ansible_host=192.168.0.83
[sqlnodes:vars]
port=3306
node_type='sqlnode'
; define shards group
[datanodes:children]
shard1
shard2
shard3
[datanodes:vars]
node_type='datanode'
shard_names = ['shard1', 'shard2', 'shard3']
; define shard, the 1st is the primary, others are secondary
[shard1]
datanode1 ansible_host=192.168.0.81 port=4406
datanode2 ansible_host=192.168.0.82 port=4406
datanode3 ansible_host=192.168.0.83 port=4406
[shard2]
datanode4 ansible_host=192.168.0.81 port=4407
datanode5 ansible_host=192.168.0.82 port=4407
datanode6 ansible_host=192.168.0.83 port=4407
[shard3]
datanode7 ansible_host=192.168.0.81 port=4408
datanode8 ansible_host=192.168.0.82 port=4408
datanode9 ansible_host=192.168.0.83 port=4408
����:
- cluster_username �� cluster_password :��Ⱥ���ù����˺ź�����
- package_name :��Ҫ��װ�� GreatDB Cluster ���İ汾����,ע����Ҫ��downloadsĿ¼�еİ�װ������ƥ�䡣
- root_dir :��Ⱥ��װ�ĸ�Ŀ¼,������װ��Ҫ������
- ansible_ssh_xxx :Զ��ssh�˿ڡ�root�û�����root����,�������벻ͬ,��������ansibleһ�Զ��SSH������֤�������
- close_firewall��close_selinux :�Ƿ�رշ���ǽ��selinux
- sqlnodes: ����sqlnode�ڵ�
- 3��shard,ÿ��shard�ֲ��ڲ�ͬ��������,Ϊ��ά������ʹ����ͬ�Ķ˿ڡ�
�� GreatDB Cluster ��װ��
GreatDB Cluster ��װ���ŵ� downloads Ŀ¼��
[root@greatdb1 ~]# ll greatdb-ansible-master/downloads/
total 591012
-rw-r--r--. 1 root root 605194964 Feb 25 07:08 greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz
����
# sqlnode.yml ���ڵ�������sqlnode�����ݿ�������á�
[root@greatdb1 ~]# cat greatdb-ansible-master/conf/sqlnode.yml
---
# TODO: config options for sqlnode.
max_connections: "2000"
innodb_buffer_pool_size: "128M"
innodb_log_file_size: "1G"
loose_group_replication_consistency: "BEFORE_AND_AFTER"
# datanode.yml ���ڵ�������datanode�����ݿ�������á�
[root@greatdb1 ~]# cat greatdb-ansible-master/conf/datanode.yml
---
# TODO: config options for datanode.
max_connections: "3000"
innodb_buffer_pool_size: "128M"
innodb_log_file_size: "1G"
loose_group_replication_consistency: "BEFORE_ON_PRIMARY_FAILOVER"
ʹ�� root ִ�а�װ
[root@greatdb1 ~]# cd greatdb-ansible-master/
[root@greatdb1 greatdb-ansible-master]# ansible-playbook deploy.yml -i inventory/deploy.ini -v
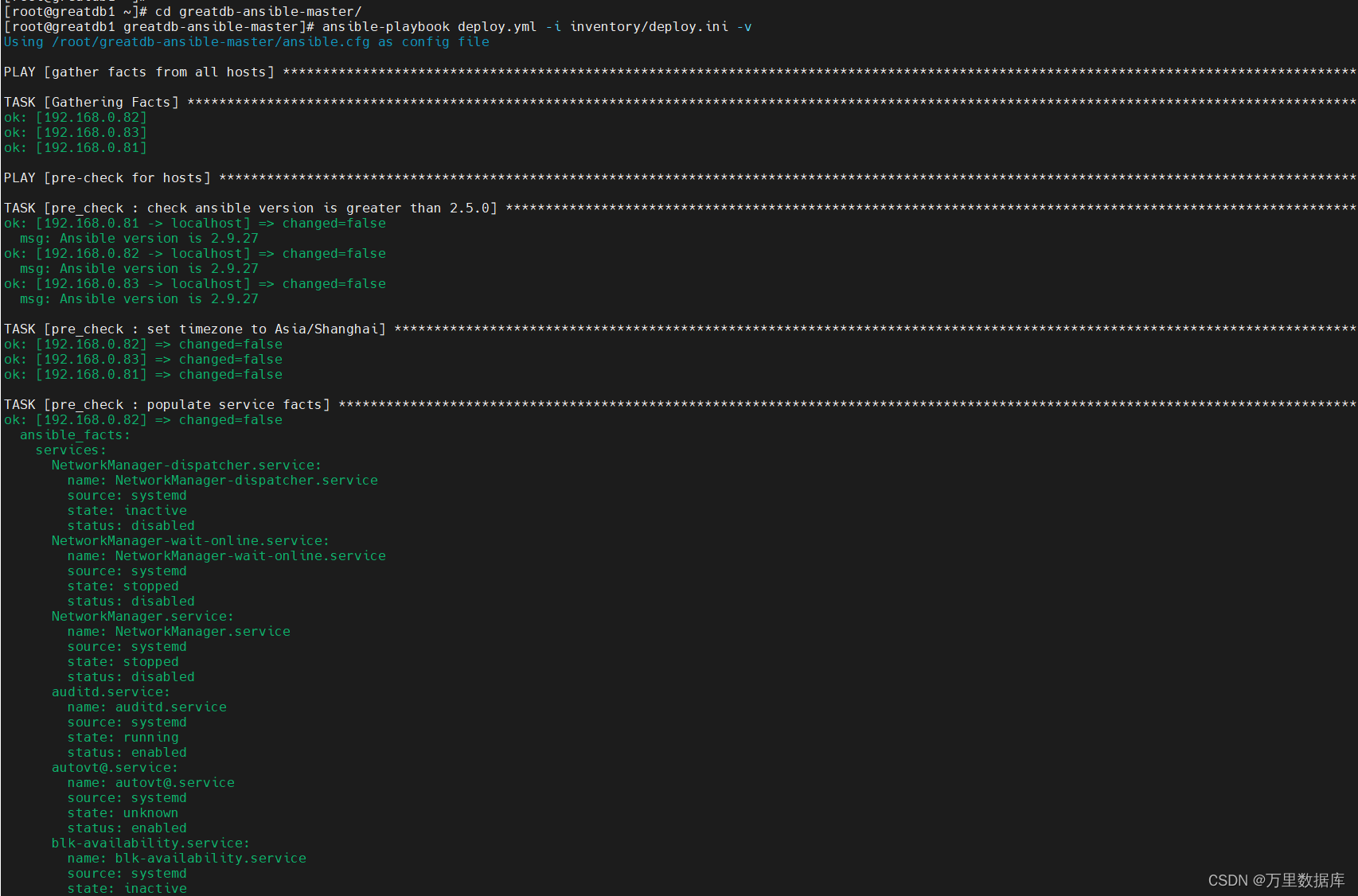
��һ�ΰ�װ�������´���:
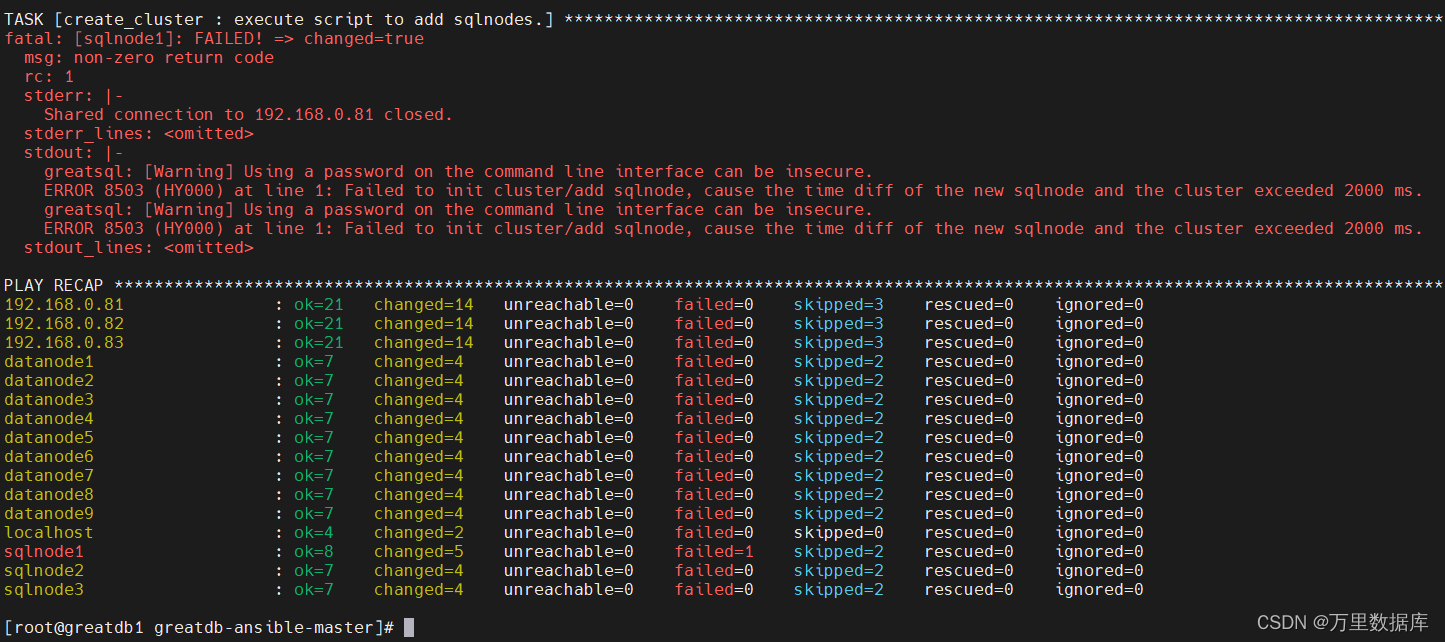
��������ʱ�����϶�,����һ��ʱ��,���������ٴ�ִ��
date -s "20210225 01:36:00"
[root@greatdb1 greatdb-ansible-master]# ansible-playbook cleanup.yml -i inventory/deploy.ini -v
[root@greatdb1 greatdb-ansible-master]# ansible-playbook deploy.yml -i inventory/deploy.ini -v
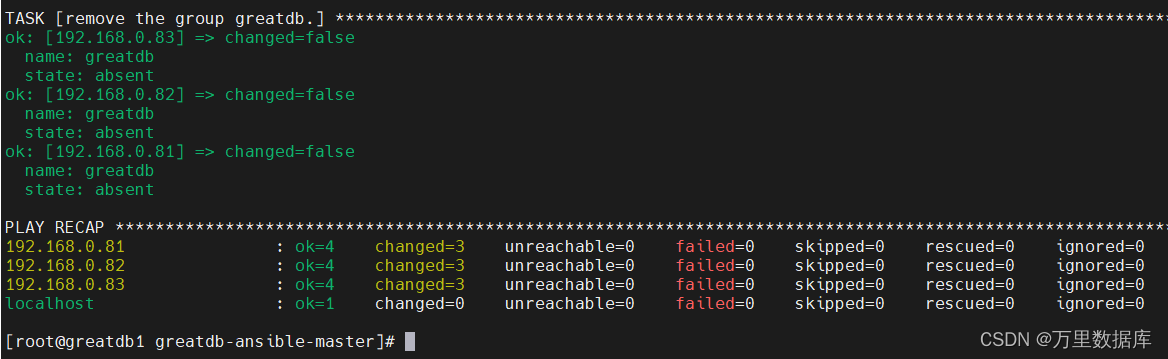
�ٴ�ִ�а�װ,�ɹ���
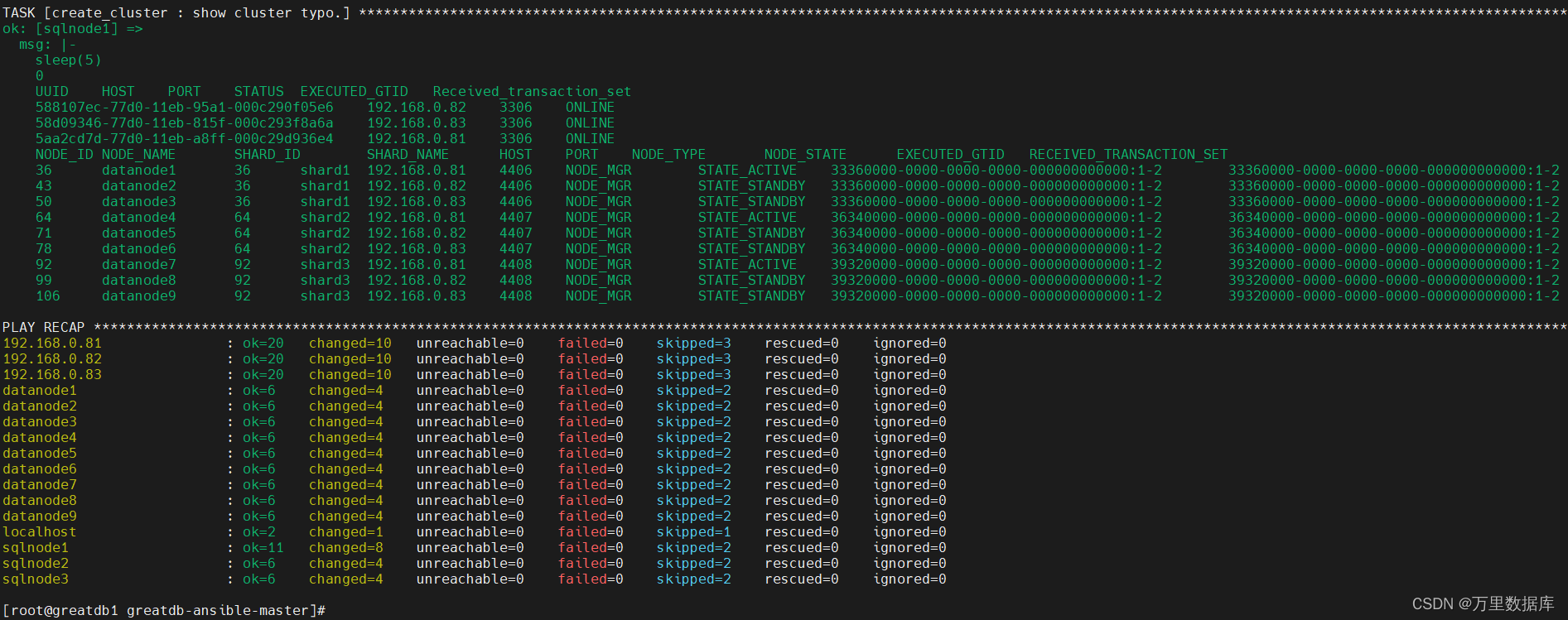
Ansible ���Զ���������
# ansible-playbook deploy.yml -i inventory/deploy.ini -v
# pre-check
1. check ansible version is greater than 2.5.0
2. set timezone to Asia/Shanghai
3. populate service facts
4. restart crond to ensure the jobs run at the right time
5. stop|disable firewalld service
6. ensure the selinux module dependency in centos
yum install libselinux-python
7. disable selinux
# ensure_dependencies
# ensure dependencies of greatdb cluster was installed.
1. install greatdb dependencies for centos systems
yum install libaio-devel ncurses-devel numactl-devel
# distribute_and_install
# distribute and install greatdb binary file.
1. create greatdb group.
2. create greatdb system user.
3. create some required directories.
mkdir /greatdb/svr
mkdir /greatdb/dbdata
mkdir /greatdb/logs
mkdir /greatdb/conf
mkdir /greatdb/sh
mkdir /greatdb/tool
mkdir /greatdb/dbbackup
chmod -R 755 /greatdb
4. copy the shell scripts under sh dir to remote host for operational controls.
scp /root/greatdb-ansible-master/sh/* 192.168.0.82:/greatdb/sh/
scp /root/greatdb-ansible-master/sh/* 192.168.0.83:/greatdb/sh/
5. add or modify nofile limit for the user greatdb
echo "greatdb - nofile 655350" >> /etc/security/limits.conf
6. config pam login option
echo "session required pam_limits.so" >> /etc/pam.d/login
7. distribute the greatdb archive file to all nodes.
scp "{{ downloads_dir }}/{{ item.file_name }}" 192.168.0.81:/greatdb/svr/greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz
scp "{{ downloads_dir }}/{{ item.file_name }}" 192.168.0.82:/greatdb/svr/greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz
scp "{{ downloads_dir }}/{{ item.file_name }}" 192.168.0.83:/greatdb/svr/greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz
8. unarchive the compressed binary executable file.
tar -zxvf /greatdb/svr/greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz -C /greatdb/svr
9. create symbolic link for greatdb binary executable file.
ln -s greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64 /greatdb/svr/greatdb
10. remove the useless archive file.
rm -f /greatdb/svr/greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz
11. get stats of root_dir -- /greatdb
12. change owner of installed directories and files to greatdb
chown -R greatdb:greatdb /greatdb
chmod 755 /greatdb
13. change owner of installed directories and files to greatdb (symbolic link)
# initialize_node
# initialize and start up all sqlnodes.
1. include sqlnode vars
/root/greatdb-ansible-master/conf/sqlnode.yml
2. include datanode vars
/root/greatdb-ansible-master/conf/datanode.yml
3. set sqlnode dynamic variables.
start_cmd: greatsqld_safe
4. set datanode dynamic variables.
start_cmd: greatdbd_safe
5. copy the configuration file to given nodes.
/greatdb/conf/sqlnode3306.cnf
/greatdb/conf/datanode4406.cnf
/greatdb/conf/datanode4407.cnf
/greatdb/conf/datanode4408.cnf
6. create dir log, data, tmp under data_dir for current node.
mkdir -p /greatdb/dbdata/sqlnode3306/data
mkdir -p /greatdb/dbdata/sqlnode3306/log
mkdir -p /greatdb/dbdata/sqlnode3306/tmp
mkdir -p /greatdb/dbdata/datanode4406/data
mkdir -p /greatdb/dbdata/datanode4406/log
mkdir -p /greatdb/dbdata/datanode4406/tmp
mkdir -p /greatdb/dbdata/datanode4407/data
mkdir -p /greatdb/dbdata/datanode4407/log
mkdir -p /greatdb/dbdata/datanode4407/tmp
mkdir -p /greatdb/dbdata/datanode4408/data
mkdir -p /greatdb/dbdata/datanode4408/log
mkdir -p /greatdb/dbdata/datanode4408/tmp
chown -R greatdb:greatdb /greatdb/dbdata
chmod -R 755 /greatdb/dbdata
7. initialize node datadir by greatdb_init command.
su - greatdb
/greatdb/svr/greatdb/bin/greatdb_init \
--defaults-file=/greatdb/conf/sqlnode3306.cnf \
--cluster-user=greatdb \
--cluster-host=% \
--cluster-password=greatdb \
--node-type=sqlnode \
/greatdb/svr/greatdb/bin/greatdb_init \
--defaults-file=/greatdb/conf/datanode4406.cnf \
--cluster-user=greatdb \
--cluster-host=% \
--cluster-password=greatdb \
--node-type=datanode \
/greatdb/svr/greatdb/bin/greatdb_init \
--defaults-file=/greatdb/conf/datanode4407.cnf \
--cluster-user=greatdb \
--cluster-host=% \
--cluster-password=greatdb \
--node-type=datanode \
/greatdb/svr/greatdb/bin/greatdb_init \
--defaults-file=/greatdb/conf/datanode4408.cnf \
--cluster-user=greatdb \
--cluster-host=% \
--cluster-password=greatdb \
--node-type=datanode \
8. distribute start-stop scripts for operational controls.
/greatdb/sh/sqlnode3306.sh
/greatdb/sh/datanode4406.sh
/greatdb/sh/datanode4407.sh
/greatdb/sh/datanode4408.sh
# generate_scripts
# generate cluster creation scripts for all nodes.
1. check whether shells directory exists or not.
2. create a shells directory if not exists.
mkdir -p /root/greatdb-ansible-master/scripts
3. generate shell scripts
/root/greatdb-ansible-master/scripts/add_sqlnode.sh
/root/greatdb-ansible-master/scripts/add_datanode.sh
# create_cluster
1. initialize cluster.
/greatdb/svr/greatdb/bin/greatsql -S/greatdb/dbdata/sqlnode3306/data/greatdb.sock -ugreatdb -pgreatdb \
-e "call mysql.greatdb_init_cluster('greatdb_cluster', 'greatdb', 'greatdb');"
2. execute script to add sqlnodes.
/root/greatdb-ansible-master/scripts/add_sqlnode.sh
3. execute script to add datanode.
/root/greatdb-ansible-master/scripts/add_datanode.sh
4. fetch cluster typo
/greatdb/svr/greatdb/bin/greatsql -S/greatdb/dbdata/sqlnode3306/data/greatdb.sock -ugreatdb -pgreatdb \
-e "select sleep(5);select * from information_schema.greatdb_sqlnodes;select * from information_schema.greatdb_datanodes;"
5. show cluster typo
Ansible ���Զ���������������
> # ansible-playbook cleanup.yml -i inventory/deploy.ini -v
>
> 1. Check ansible version is greater than 2.2.0
> 2. stop greatdb services. for svr in greatdbd greatdbd_safe greatsqld greatsqld_safe; do pkill -9 $svr || true; done;
> 3. remove the root directory. rm -rf /greatdb
> 4. remove greatdb system user and group. userdel -r greatdb groupdel greatdb
���� cleanup.yml playbook �رռ�Ⱥ�������װĿ¼,�ýű����Ƴ� GreatDB ��װ����ĸ�Ŀ¼,�������ǰ���ȱ��ݼ�Ⱥ����,���õ���
��װ��ʽ��,ʹ��?���ư��ֶ����� GreatDB
���нڵ㴴��ϵͳ�û�����û�
[root@greatdb1 ~]# groupadd greatdb
[root@greatdb1 ~]# useradd -g greatdb -s /bin/bash greatdb
[root@greatdb1 ~]# echo "greatdb " | passwd --stdin greatdb
���нڵ㴴��Ŀ¼
[root@greatdb1 ~]# mkdir -p /greatdb/svr
[root@greatdb1 ~]# mkdir -p /greatdb/dbdata
[root@greatdb1 ~]# mkdir -p /greatdb/logs
[root@greatdb1 ~]# mkdir -p /greatdb/conf
[root@greatdb1 ~]# mkdir -p /greatdb/sh
[root@greatdb1 ~]# mkdir -p /greatdb/tool
[root@greatdb1 ~]# mkdir -p /greatdb/dbbackup
[root@greatdb1 ~]# chmod -R 755 /greatdb
[root@greatdb1 ~]# chown -R greatdb:greatdb /greatdb
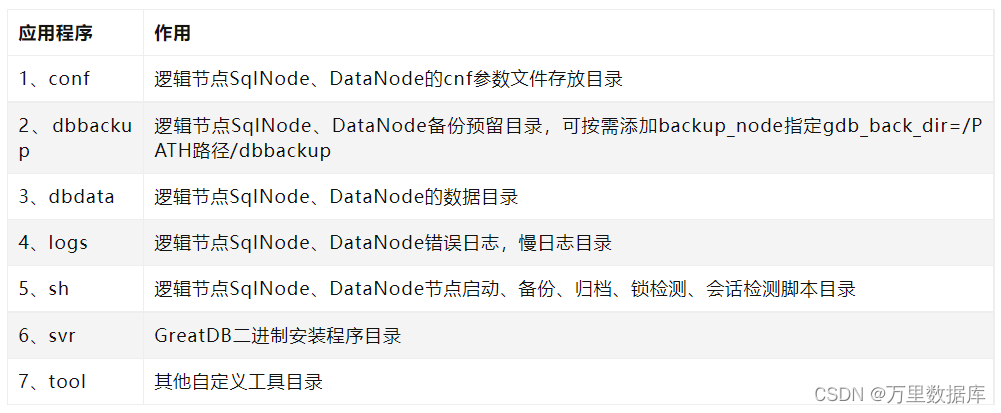
���нڵ��ϴ�����ѹ��װ��
��?��Դ�ṩ GreatDB Cluster ��?���Ʒ�����,�� tar ������ʽ����,��?�� greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz ��ѹ����Ϊ��,��?��װ˵����
[root@greatdb1 ~]# ll /opt/
total 591016
-rw-r--r--. 1 root root 605194964 Feb 25 15:28 greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz
[root@greatdb1 ~]# tar -xvf /opt/greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64.tar.gz -C /greatdb/svr
[root@greatdb1 ~]# cd /greatdb/svr
[root@greatdb1 svr]# ln -s greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64 greatdb
[root@greatdb1 svr]# chown -R greatdb:greatdb greatdb
[root@greatdb1 svr]# chown -R greatdb:greatdb greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64
[root@greatdb1 svr]# cd greatdb
[root@greatdb1 greatdb]# ll
total 628
drwxr-xr-x. 2 greatdb greatdb 4096 Sep 1 2021 bin
drwxr-xr-x. 2 greatdb greatdb 69 Sep 1 2021 cmake
-rw-r--r--. 1 greatdb greatdb 1703 Sep 1 2021 COPYING-jemalloc
drwxr-xr-x. 2 greatdb greatdb 115 Sep 1 2021 docs
drwxr-xr-x. 6 greatdb greatdb 4096 Sep 1 2021 include
drwxr-xr-x. 8 greatdb greatdb 4096 Sep 1 2021 lib
-rw-r--r--. 1 greatdb greatdb 274942 Sep 1 2021 LICENSE
-rw-r--r--. 1 greatdb greatdb 45333 Sep 1 2021 LICENSE.router
-rw-r--r--. 1 greatdb greatdb 274942 Sep 1 2021 LICENSE-test
drwxr-xr-x. 4 greatdb greatdb 30 Sep 1 2021 man
-rw-r--r--. 1 greatdb greatdb 1623 Sep 1 2021 mysqlrouter-log-rotate
-rw-r--r--. 1 greatdb greatdb 685 Sep 1 2021 README
-rw-r--r--. 1 greatdb greatdb 679 Sep 1 2021 README.router
-rw-r--r--. 1 greatdb greatdb 685 Sep 1 2021 README-test
drwxrwxr-x. 2 greatdb greatdb 6 Sep 1 2021 run
drwxr-xr-x. 28 greatdb greatdb 4096 Sep 1 2021 share
drwxr-xr-x. 2 greatdb greatdb 77 Sep 1 2021 support-files
drwxr-xr-x. 3 greatdb greatdb 17 Sep 1 2021 var
��ѹ���?����������:
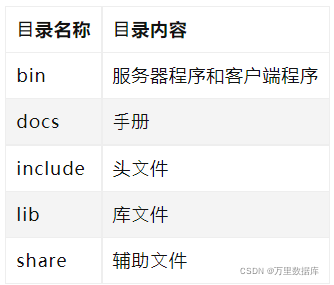
�ص�?��˵��:
- bin/greatsqld: SQL�ڵ��̨����
- bin/greatdbd: ���ݽڵ��̨����
- bin/greatsql:QL�ڵ�ͻ��˳���,?�ڵ�½SQL�ڵ�
- bin/greatsqld_safe: ����SQL�ڵ���ػ�����
- bin/greatdbd_safe: �������ݽڵ���ػ����� greatdb_init:
- greatdb_init���Զ���ʼ�����ݿ�ڵ�ʵ��,������ʵ��
- greatsqldump: ��Ⱥ���������ݹ���
����?��ģ��
bash�ű� create_config.sh
SQL�ڵ�����ݽڵ������?��ģ����MySQL����?ʽ?��,Ϊ�˼�?������?���ĸ��Ӷ�,�����ṩ����bash�ű� create_config.sh ,��������
[root@greatdb1 ~]# cat create_config.sh
#!/bin/bash
set -ex
echo "[mysqld]
basedir=/greatdb/svr/greatdb
datadir=/greatdb/dbdata/$1$3/data
tmpdir=/greatdb/dbdata/$1$3/tmp
pid-file=/greatdb/dbdata/$1$3/data/greatdb.pid
socket=/greatdb/dbdata/$1$3/data/greatdb.sock
mysqlx_socket=/greatdb/dbdata/$1$3/data/greatdbx.sock
user=greatdb
port=$3
server_id=$RANDOM
max_connections=1000
report-host=$2
## group replication configuration
binlog-checksum=NONE
enforce-gtid-consistency=ON
gtid-mode=ON
loose-group_replication_start_on_boot=OFF
loose_group_replication_recovery_get_public_key=ON
loose-group_replication_local_address= \"$2:1$3\""
if [ "x"$1 == "xsqlnode" ]; then
mkdir -p /greatdb/dbdata/sqlnode$3/data
mkdir -p /greatdb/dbdata/sqlnode$3/log
mkdir -p /greatdb/dbdata/sqlnode$3/tmp
elif [ "x"$1 == "xdatanode" ]; then
mkdir -p /greatdb/dbdata/datanode$3/data
mkdir -p /greatdb/dbdata/datanode$3/log
mkdir -p /greatdb/dbdata/datanode$3/tmp
fi
chown -R greatdb:greatdb /greatdb/dbdata
chmod -R 755 /greatdb/dbdata
loose-group_replication_local_address ���������Ҫ��?����,��֤��?�Ų���ͻ,�˲���?�ڼ�Ⱥ�ڲ��� group replication ������,?��ֻ��Ҫ������?���������ɡ� max_connections ���Ծ�������?��,���������?���������,����ͨ�� ulimit -n unlimited ��?������
��ģ�������������,��һ��������ʾΪ sqlnode ���� datanode ��������?��,�ڶ��������� IP ��ַ,�����������Ƕ˿ں�,��?ʹ? create_config.sh ������ͬ�ڵ������?����
�ֱ���ssh�������� sqlnode ��?�ɼ���ʵ��������?��
[root@greatdb1 ~]# bash create_config.sh sqlnode 192.168.0.81 3306 > /greatdb/conf/sqlnode3306.cnf
[root@greatdb2 ~]# bash create_config.sh sqlnode 192.168.0.82 3306 > /greatdb/conf/sqlnode3306.cnf
[root@greatdb3 ~]# bash create_config.sh sqlnode 192.168.0.83 3306 > /greatdb/conf/sqlnode3306.cnf
�� datanode1 ��?�����ݽڵ������?��
[root@greatdb1 ~]# bash create_config.sh datanode 192.168.0.81 4406 > /greatdb/conf/datanode4406.cnf
[root@greatdb1 ~]# bash create_config.sh datanode 192.168.0.81 4407 > /greatdb/conf/datanode4407.cnf
[root@greatdb1 ~]# bash create_config.sh datanode 192.168.0.81 4408 > /greatdb/conf/datanode4408.cnf
�� datanode2 ��?�����ݽڵ������?��
[root@greatdb2 ~]# bash create_config.sh datanode 192.168.0.82 4406 > /greatdb/conf/datanode4406.cnf
[root@greatdb2 ~]# bash create_config.sh datanode 192.168.0.82 4407 > /greatdb/conf/datanode4407.cnf
[root@greatdb2 ~]# bash create_config.sh datanode 192.168.0.82 4408 > /greatdb/conf/datanode4408.cnf
�� datanode3 ��?�����ݽڵ������?��
[root@greatdb3 ~]# bash create_config.sh datanode 192.168.0.83 4406 > /greatdb/conf/datanode4406.cnf
[root@greatdb3 ~]# bash create_config.sh datanode 192.168.0.83 4407 > /greatdb/conf/datanode4407.cnf
[root@greatdb3 ~]# bash create_config.sh datanode 192.168.0.83 4408 > /greatdb/conf/datanode4408.cnf
�Ż�����ѡ��
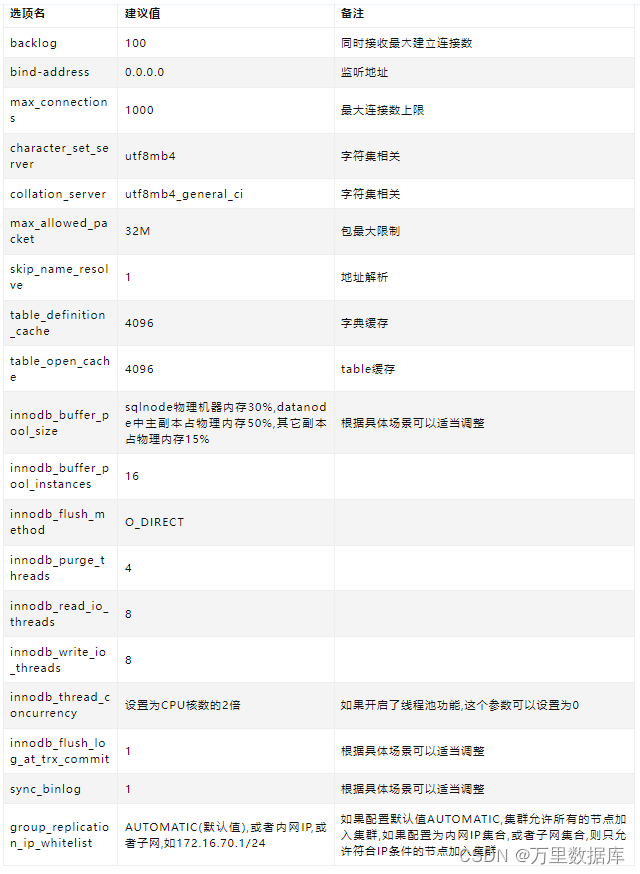
?������?����,��Ҫ���ݻ����������Լ���̨���������ϵ�ʵ����,������?���е�ѡ���?�� ������Ҫ�ص��ע����?��ѡ�������
��ʼ���ڵ㲢����ʵ��
�����ø�?������?����,ֱ��ʹ? greatdb_init ��ʼ�������ڵ�,greatdb_init ��?����ʼ�����ݿ�ڵ�ʵ��,������ʵ����
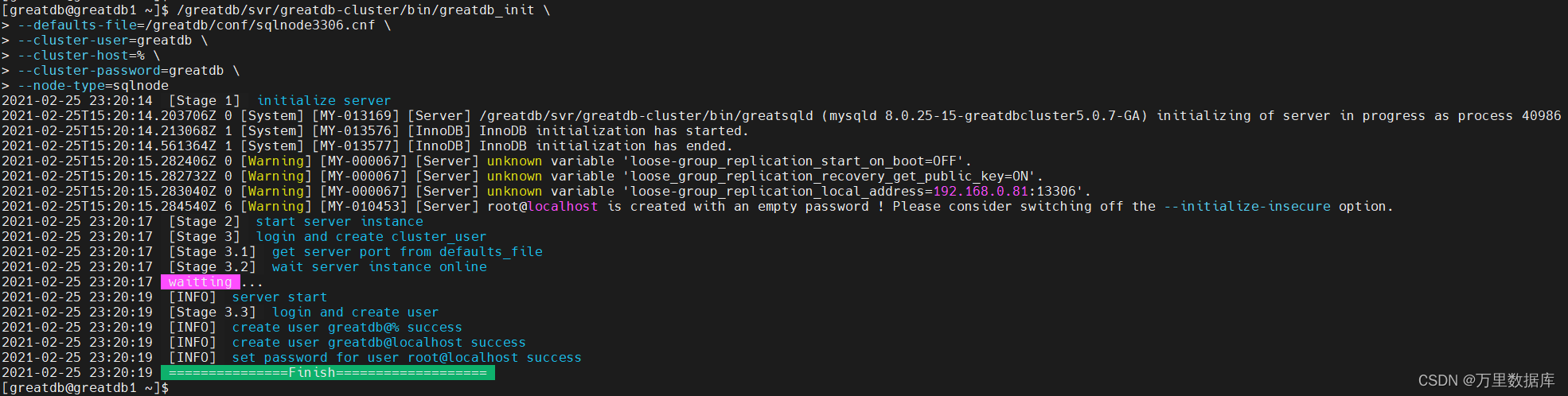
��ʼ�������� SQLNode
�ֱ�ssh������ sqlnode1,sqlnode2,sqlnode3 ��,ʹ? greatdb_init ��ʼ�������� SQLNode��
[root@greatdb1 ~]# su - greatdb
/greatdb/svr/greatdb/bin/greatdb_init \
--defaults-file=/greatdb/conf/sqlnode3306.cnf \
--cluster-user=greatdb \
--cluster-host=% \
--cluster-password=greatdb \
--node-type=sqlnode
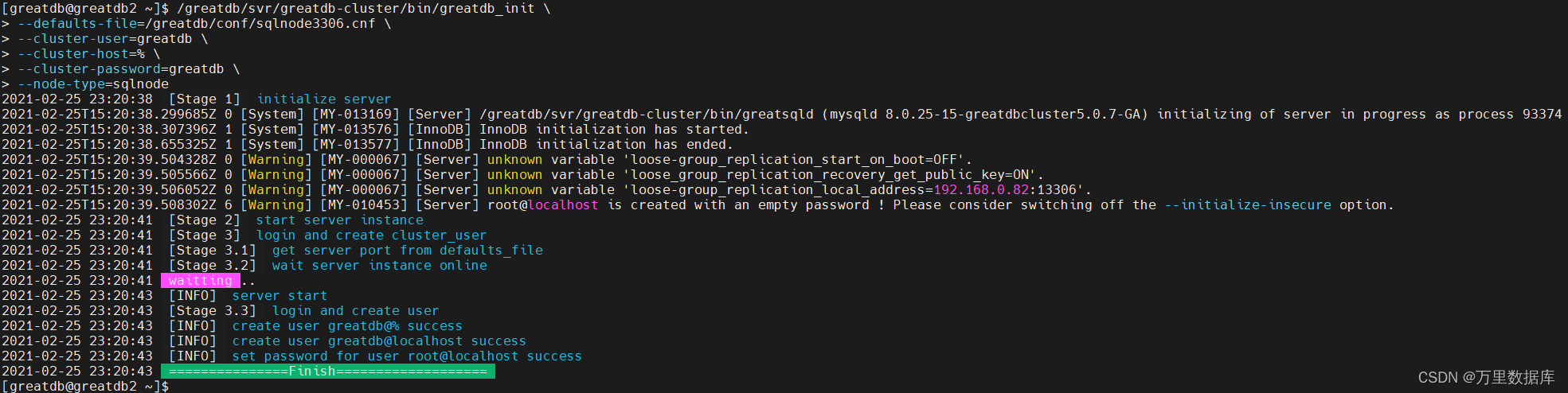
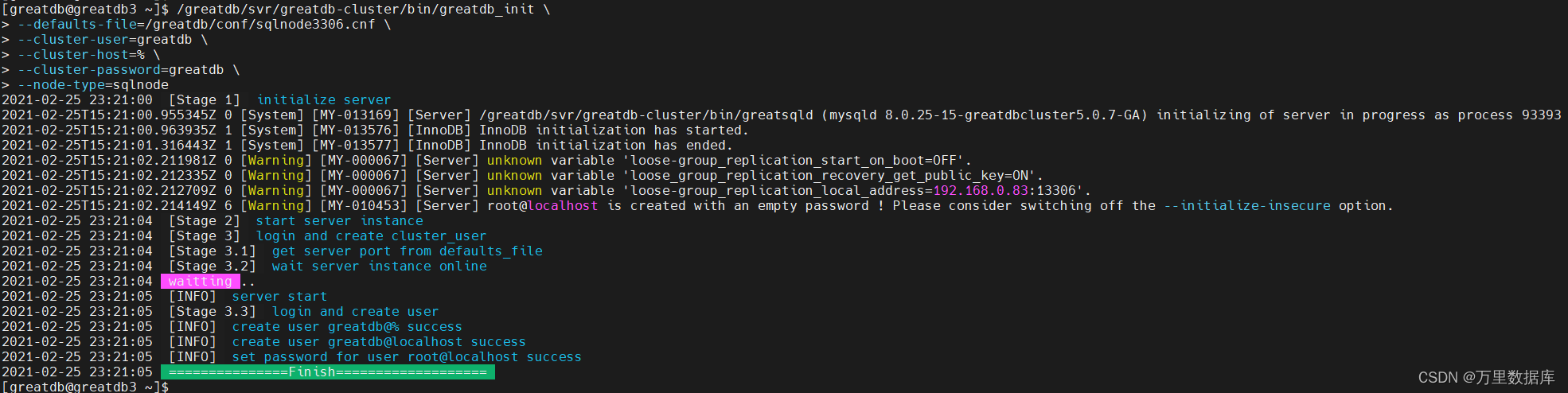
��ʼ�������� DataNode
�ֱ�ssh������ datanode1,datanode2,datanode3 ��,ʹ? greatdb_init ��ʼ�� DataNode ������?¼��
[root@greatdb1 ~]# su - greatdb
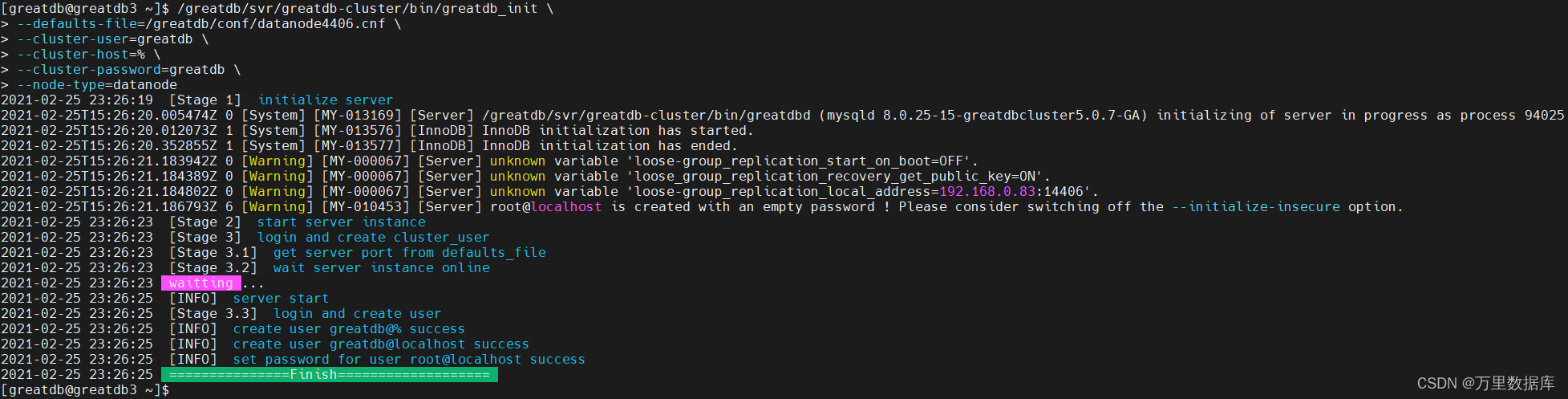
/greatdb/svr/greatdb/bin/greatdb_init \
--defaults-file=/greatdb/conf/datanode4406.cnf \
--cluster-user=greatdb \
--cluster-host=% \
--cluster-password=greatdb \
--node-type=datanode
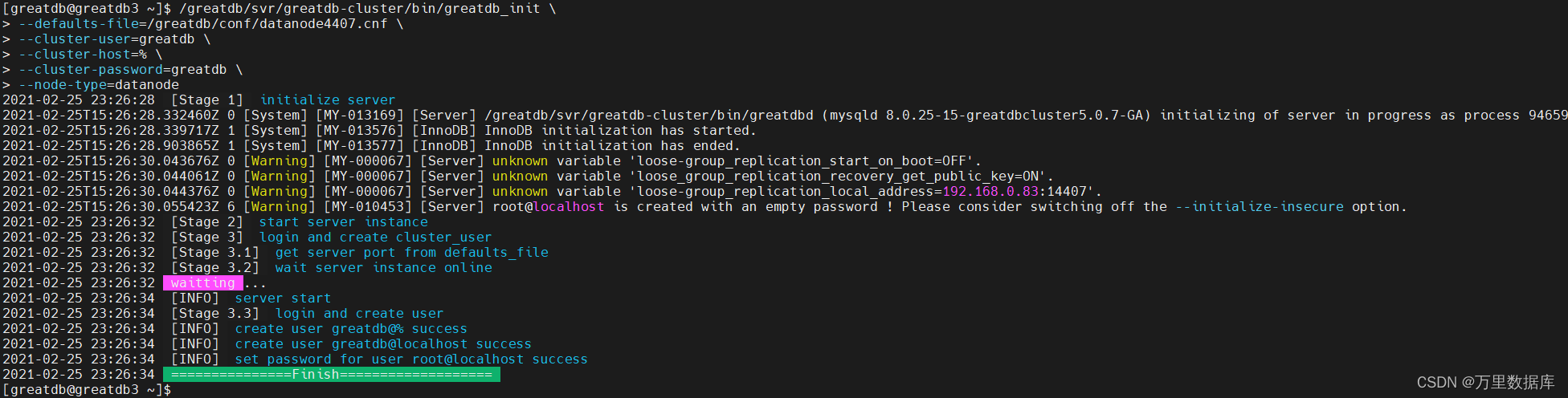
/greatdb/svr/greatdb/bin/greatdb_init \
--defaults-file=/greatdb/conf/datanode4407.cnf \
--cluster-user=greatdb \
--cluster-host=% \
--cluster-password=greatdb \
--node-type=datanode
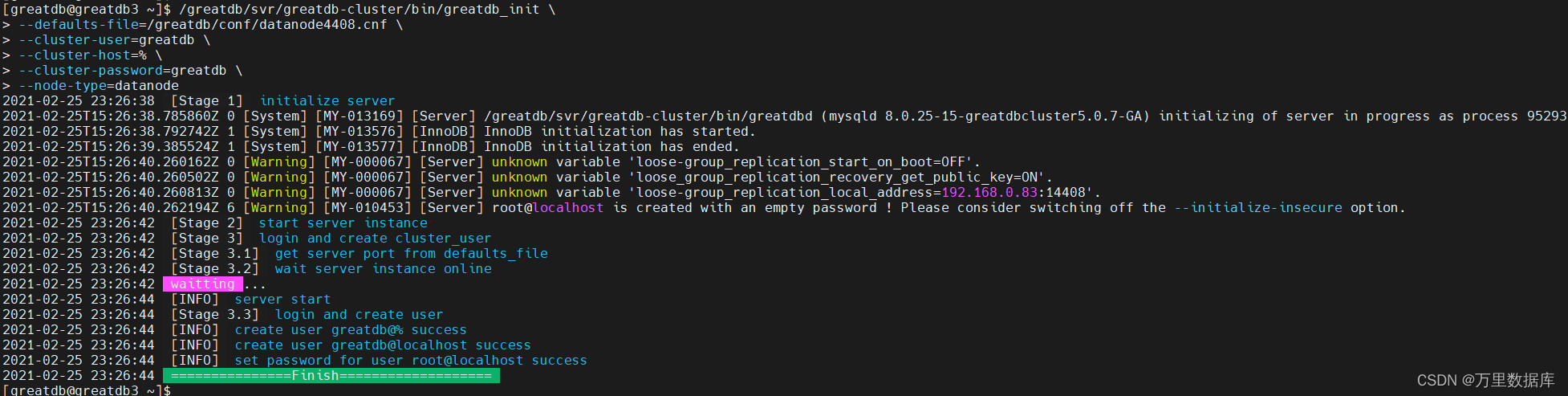
/greatdb/svr/greatdb/bin/greatdb_init \
--defaults-file=/greatdb/conf/datanode4408.cnf \
--cluster-user=greatdb \
--cluster-host=% \
--cluster-password=greatdb \
--node-type=datanode
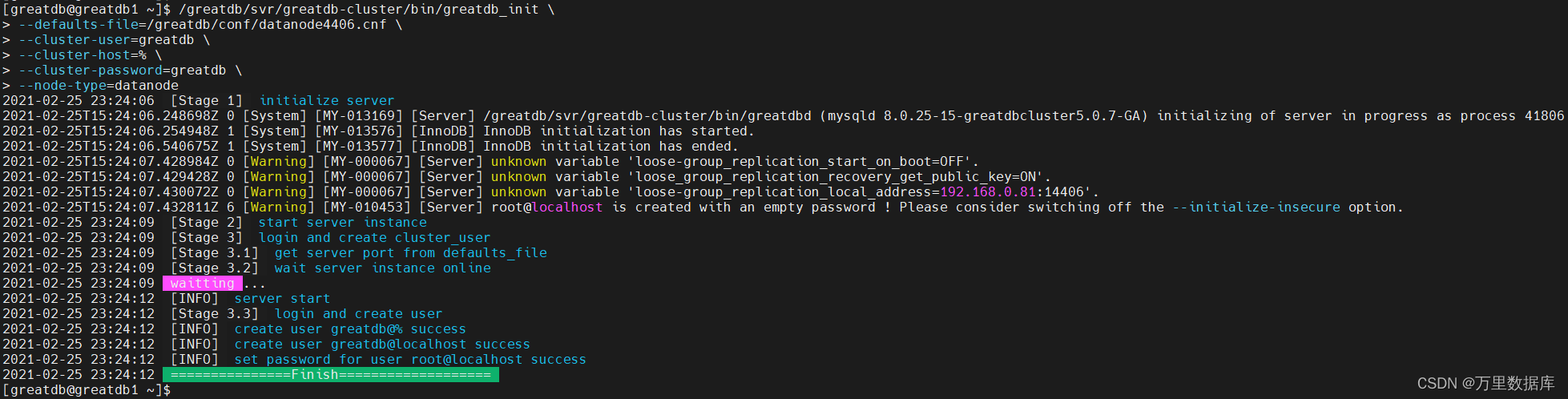
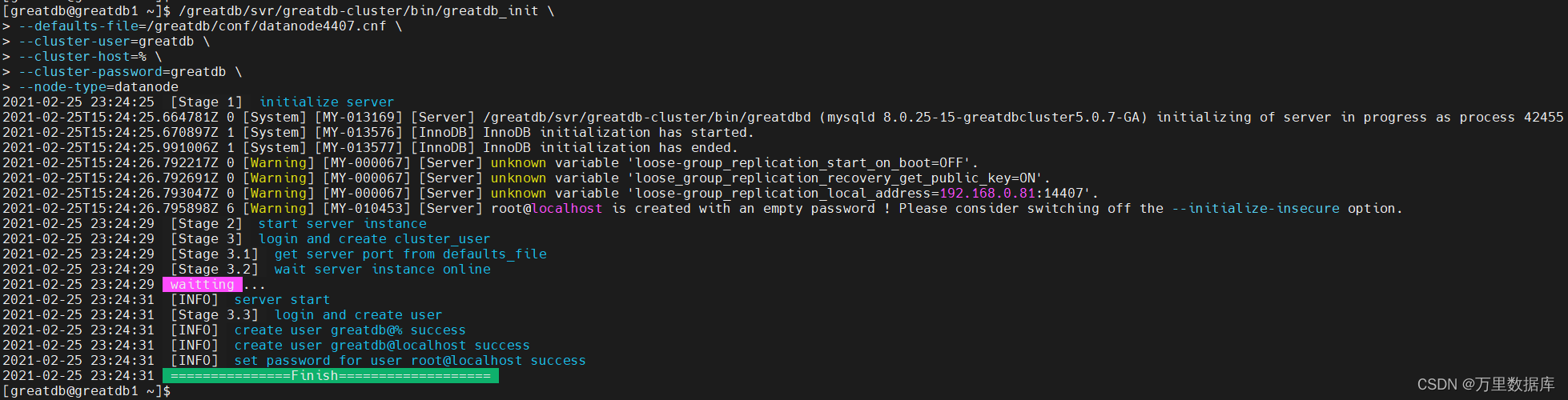
������Ⱥ
ʹ? root ��½����?�� SQLNode,��?��ʼ����Ⱥ����,����?���� SQLNode �� DataNode �IJ���,��?�� sqlnode1 ��Ϊ��ʼ���ڵ㡣
# ��½sqlnode1
[root@greatdb1 ~]# su - greatdb
[greatdb@greatdb1 ~]$ /greatdb/svr/greatdb/bin/greatsql -h127.0.0.1 -P3306 -uroot -pgreatdb
# ��ʼ����Ⱥ
GreatDB Cluster[(none)]> call mysql.greatdb_init_cluster('greatdb_cluster', 'greatdb', 'greatdb');
Query OK, 1 row affected (3.31 sec)
# ����SQLNode sqlnode2
GreatDB Cluster[(none)]> call mysql.greatdb_add_sqlnode('192.168.0.82', 3306);
Query OK, 0 rows affected (3.24 sec)
# ����SQLNode sqlnode3
GreatDB Cluster[(none)]> call mysql.greatdb_add_sqlnode('192.168.0.83', 3306);
Query OK, 0 rows affected (2.56 sec)
# ���� shard1 �����ݽڵ㲢��ʼ��
GreatDB Cluster[(none)]> call mysql.greatdb_add_datanode('shard1', 'datanode1', '192.168.0.81', 4406, 'NODE_MGR');
Query OK, 1 row affected (0.06 sec)
GreatDB Cluster[(none)]> call mysql.greatdb_add_datanode('shard1', 'datanode2', '192.168.0.82', 4406, 'NODE_MGR');
Query OK, 1 row affected (0.05 sec)
GreatDB Cluster[(none)]> call mysql.greatdb_add_datanode('shard1', 'datanode3', '192.168.0.83', 4406, 'NODE_MGR');
Query OK, 1 row affected (0.05 sec)
GreatDB Cluster[(none)]> call mysql.greatdb_init_shard('shard1');
Query OK, 1 row affected (8.30 sec)
# ����shard2�����ݽڵ㲢��ʼ��
GreatDB Cluster[(none)]> call mysql.greatdb_add_datanode('shard2', 'datanode4', '192.168.0.81', 4407, 'NODE_MGR');
Query OK, 1 row affected (0.06 sec)
GreatDB Cluster[(none)]> call mysql.greatdb_add_datanode('shard2', 'datanode5', '192.168.0.82', 4407, 'NODE_MGR');
Query OK, 1 row affected (0.06 sec)
GreatDB Cluster[(none)]> call mysql.greatdb_add_datanode('shard2', 'datanode6', '192.168.0.83', 4407, 'NODE_MGR');
Query OK, 1 row affected (0.06 sec)
GreatDB Cluster[(none)]> call mysql.greatdb_init_shard('shard2');
Query OK, 1 row affected (8.40 sec)
# ����shard3�����ݽڵ㲢��ʼ��
GreatDB Cluster[(none)]> call mysql.greatdb_add_datanode('shard3', 'datanode7', '192.168.0.81', 4408, 'NODE_MGR');
Query OK, 1 row affected (0.06 sec)
GreatDB Cluster[(none)]> call mysql.greatdb_add_datanode('shard3', 'datanode8', '192.168.0.82', 4408, 'NODE_MGR');
Query OK, 1 row affected (0.06 sec)
GreatDB Cluster[(none)]> call mysql.greatdb_add_datanode('shard3', 'datanode9', '192.168.0.83', 4408, 'NODE_MGR');
Query OK, 1 row affected (0.07 sec)
GreatDB Cluster[(none)]> call mysql.greatdb_init_shard('shard3');
Query OK, 1 row affected (8.19 sec)
?��,������Ⱥ����ɡ�
��װ��ʽ��,ͨ�� GreatRDS ����ƽ̨���ɲ���
GreatRDS ��û�еõ�ѧϰ�Ļ���,�պ��л����ٲ��䡣
GreatDB ��¼����
ʹ�� GreatDB �Դ��Ŀͻ��˳��� greatsql
���ӻ�������
vi /etc/profile
export PATH=/greatdb/svr/greatdb/bin:$PATH
source /etc/profile
ʹ�� greatsql ��¼ GreatDB
[root@greatdb1 ~]# greatsql -ugreatdb -pgreatdb -h192.168.0.81 -P3306
greatsql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 8934
Server version: 8.0.25-15-greatdbcluster5.0.7-GA GreatDB Cluster, Release GA, Revision fbb08fbed60
Copyright (c) 2009-2021 BEIJING GREAT OPENSOURCE SOFTWARE TECHNOLOGY CO.,LTD.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
GreatDB Cluster[(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.05 sec)
���� MySQL �ͻ���
��װmysql�ͻ���
[root@db1 ~]# yum -y install mysql
ʹ�� mysql ��¼ GreatDB
[root@greatdb1 ~]# mysql -ugreatdb -pgreatdb -h192.168.0.81 -P3306
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 9026
Server version: 8.0.25-15-greatdbcluster5.0.7-GA GreatDB Cluster, Release GA, Revision fbb08fbed60
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.02 sec)
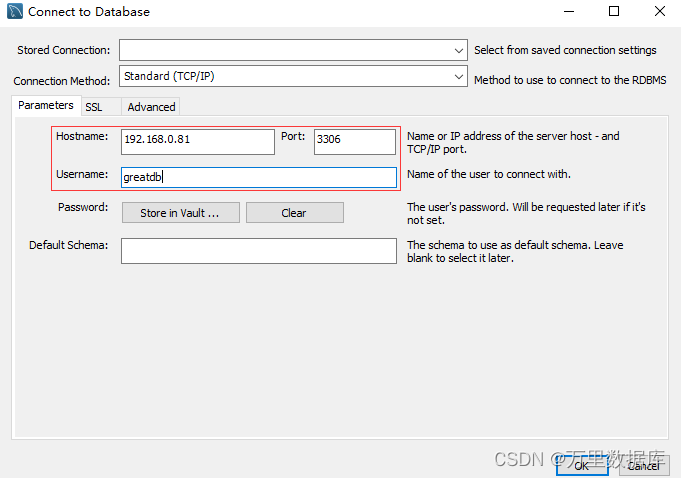
ʹ�� GUI �������� GreatDB ���ݿ�

ʹ�� MySQL Workbench �ͻ������� GreatDB ���ݿ�
��֤��Ⱥ״̬
�鿴�汾��Ϣ
ͨ�� greatsqld --version �鿴�汾
[root@greatdb1 ~]# greatsqld --version
/greatdb/svr/greatdb-cluster-5.0.7-fbb08fbed60-Linux-glibc2.17-x86_64/bin/greatsqld Ver 8.0.25-15-greatdbcluster5.0.7-GA for Linux on x86_64 (GreatDB Cluster, Release GA, Revision fbb08fbed60)
ͨ��ȫ�ֱ����鿴�汾
[root@greatdb1 ~]# greatsql -ugreatdb -pgreatdb -h192.168.0.81 -P3306
GreatDB Cluster[(none)]> show global variables like 'greatdb_version';
+-----------------+---------+
| Variable_name | Value |
+-----------------+---------+
| greatdb_version | 5.0.7.3 |
+-----------------+---------+
1 row in set (0.01 sec)
�鿴SQL�ڵ�״̬
[root@greatdb1 ~]# greatsql -ugreatdb -pgreatdb -h192.168.0.81 -P3306
GreatDB Cluster[(none)]> select * from information_schema.GREATDB_SQLNODES;

�鿴���ݽڵ�״̬
[root@greatdb1 ~]# greatsql -ugreatdb -pgreatdb -h192.168.0.81 -P3306
GreatDB Cluster[(none)]> select * from information_schema.GREATDB_DATANODES;

�鿴 SHARD ״̬
[root@greatdb1 ~]# greatsql -ugreatdb -pgreatdb -h192.168.0.81 -P3306
GreatDB Cluster[(none)]> select * from information_schema.GREATDB_SHARDS;
+----------+------------+--------------+---------+
| SHARD_ID | SHARD_NAME | SHARD_STATE | SUSPEND |
+----------+------------+--------------+---------+
| 36 | shard1 | SHARD_ONLINE | OFF |
| 64 | shard2 | SHARD_ONLINE | OFF |
| 92 | shard3 | SHARD_ONLINE | OFF |
+----------+------------+--------------+---------+
3 rows in set (0.00 sec)
�鿴 GreatDB ��ǰ�ڵ���Ϣ
GreatDB Cluster[(none)]> select * from performance_schema.replication_group_members;

GreatDB ������
�����ֲ�ʽ������
GreatDB Cluster[(none)]> create database test;
Query OK, 1 row affected (0.02 sec)
GreatDB Cluster[(none)]> create table test.t_hash(c1 int primary key, c2 int) partition by hash(c1) partitions 8;
Query OK, 0 rows affected (0.12 sec)
SqlNode �ϲ鿴���ֲ���Ϣ
GreatDB Cluster[(none)]> select * from information_schema.GREATDB_TABLE_DISTRIBUTION where table_name='t_hash';
+-------------+------------+----------------+-----------------+------------+----------------+--------------+
| SCHEMA_NAME | TABLE_NAME | BACKEND_ENGINE | DISTRIBUTE_MODE | SHARD_NAME | PARTITION_NAME | PARTITION_ID |
+-------------+------------+----------------+-----------------+------------+----------------+--------------+
| test | t_hash | InnoDB | PARTITION | shard1 | p0 | 0 |
| test | t_hash | InnoDB | PARTITION | shard1 | p4 | 4 |
| test | t_hash | InnoDB | PARTITION | shard2 | p1 | 1 |
| test | t_hash | InnoDB | PARTITION | shard2 | p3 | 3 |
| test | t_hash | InnoDB | PARTITION | shard2 | p5 | 5 |
| test | t_hash | InnoDB | PARTITION | shard2 | p7 | 7 |
| test | t_hash | InnoDB | PARTITION | shard3 | p2 | 2 |
| test | t_hash | InnoDB | PARTITION | shard3 | p6 | 6 |
+-------------+------------+----------------+-----------------+------------+----------------+--------------+
8 rows in set (0.00 sec)
����ת���ԡ�ī������������,ID�˺�:������ ,ԭ������:https://www.modb.pro/u/14816��