目录
一、流计算与批计算
一)流计算与批计算
流计算:无限数据之上的计算
批计算:有限数据之上的计算
二)流计算与批计算的比较
| 特性 | 批计算 | 流计算 |
|---|---|---|
| 数据范围 | 有界数据 | 无界数据 |
| 任务执行 | 分批执行、有终止 | 全部执行、无终止 |
| 延时 | 小时级、天级 | 秒级、分钟级 |
| 数据场景 | 数据量超大数据、无法以流的形式交付 | 数据以流的形式交付 |
| 资源消耗 | 大 | 小 |
| 数据质量 | 要求低 | 要求高 |
| 业务场景 | 清算对账、报表生成、特征生成 | 欺诈检测、实时风控、实时推荐 |
| 关注点 | 可扩展性、吞吐、容错 | 可扩展性、延迟、容错、消息一致性、消息持久性 |
| 处理语义 | 仅有一次 | 至少一次、至多一次、仅有一次 |
| 代表引擎 | MR SPARK | Storm Spark streaming Flink Kafka streaming |
三)为什么要搞流批一体
1.减少学习成本
2.减少资源消耗
3.降低架构复杂性
4.提升价值产出效率
二、流批一体的场景
一)数据集成的流批一体
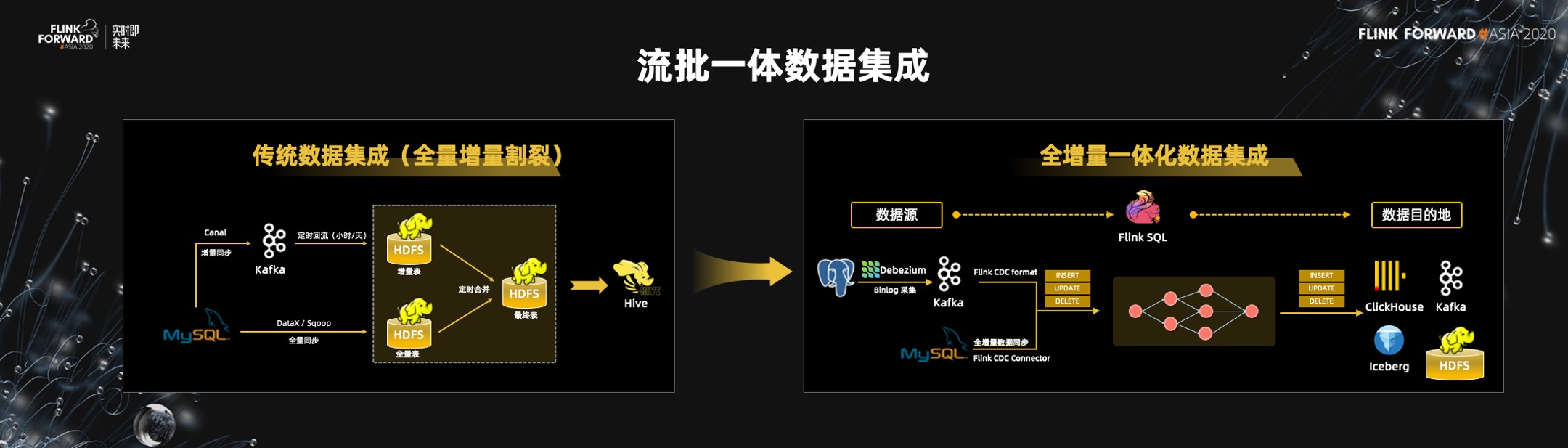
? 在大数据场景下经常需要数据同步或者数据集成,也就是将数据库中的数据同步到大数据的数仓或者其他存储中。上图中的左边是传统的经典数据集成的模式之一,全量的同步和增量的同步实际上是两套技术,需要定期将全量同步的数据跟增量同步数据做 merge,不断的迭代来把数据库的数据同步到数据仓库中。
? 基于 Flink 流批一体,整个数据集成的架构将不同。因为 Flink SQL 也支持数据库(像 MySQL 和 PG)的 CDC 语义,所以可以用 Flink SQL 一键同步数据库的数据到 Hive、ClickHouse、TiDB 等开源的数据库或开源的 KV 存储中。在 Flink 流批一体架构的基础上,Flink 的 connector 也是流批混合的,它可以先读取数据库全量数据同步到数仓中,然后自动切换到增量模式,通过 CDC 读 Binlog 进行增量和全量的同步,Flink 内部都可以自动的去协调好,这是流批一体的价值。
二)数仓架构的流批一体
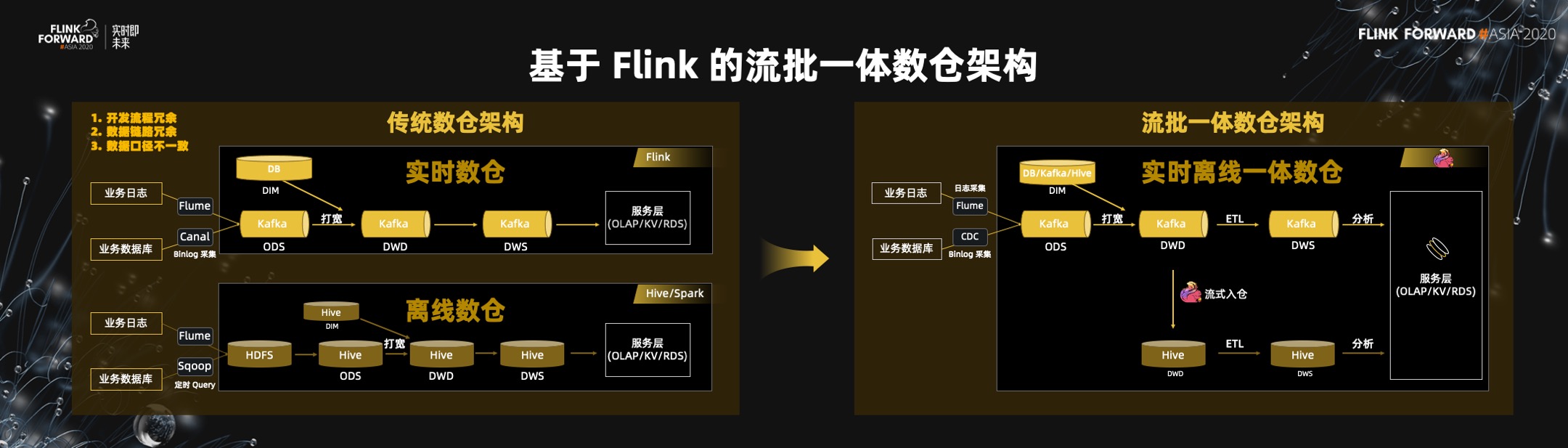
? 目前主流数仓架构都是一套典型的离线数仓和一套新的实时数仓,但这两套技术栈是分开的。在离线数仓里,还是习惯用 Hive 或者 Spark,在实时数仓中用 Flink 加 Kafka。有三个问题需要解决:两套开发流程,成本高;数据链路冗余,两套链路将数据相关的操作做了两遍;数据口径的一致性难以保证,因为它是由两套引擎算出来的。
? 用流批一体架构来解决,以上难题将极大降低。
- 首先,Flink 是一套 Flink SQL 开发,不存在两套开发成本。一个开发团队,一套技术栈,就可以做所有的离线和实时业务统计的问题。
- 第二,数据链路也不存在冗余,明细层的计算一次即可,不需要离线再算一遍。
- 第三,数据口径天然一致。无论是离线的流程,还是实时的流程,都是一套引擎,一套 SQL,一套 UDF,一套开发人员,所以它天然是一致的,不存在实时和离线数据口径不一致的问题。
三)数据湖的流批一体
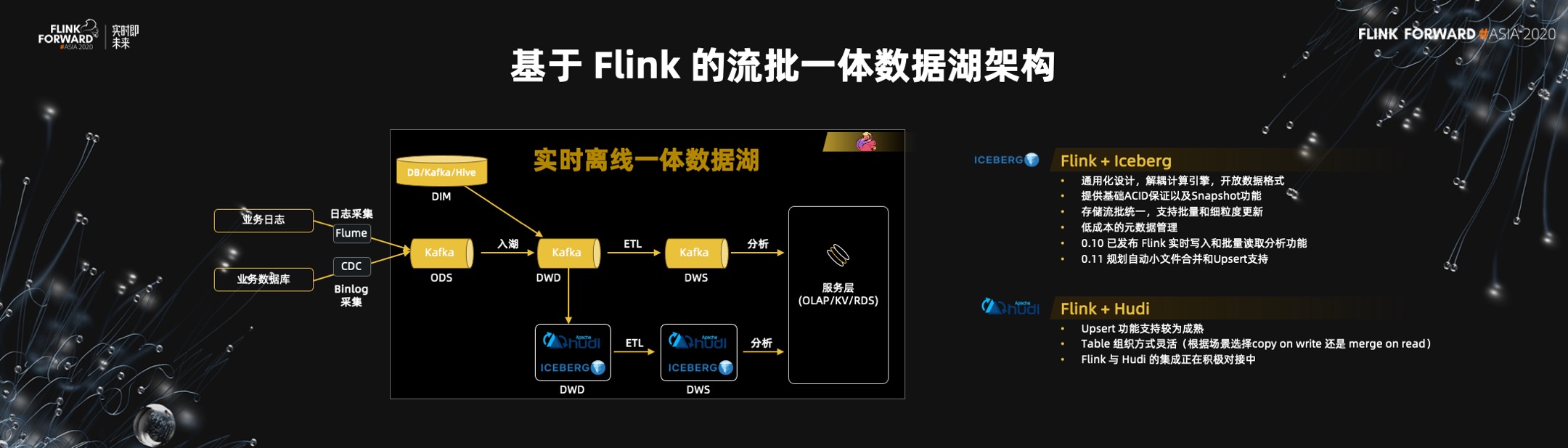
? Hive 元数据的管理是瓶颈,Hive 不支持数据的实时更新。Hive 没有办法实时,或者准实时化地提供数仓能力。现在比较新的数据湖架构,可以解决更具扩展性的元数据的问题,而且数据湖的存储支持数据的更新,是一个流批一体的存储。数据湖存储与 Flink 结合,就可以将实时离线一体化的数仓架构演变成实时离线一体化的数据湖架构。
四)存储的流批一体
1.Pulsar
Pulsar的组件架构图
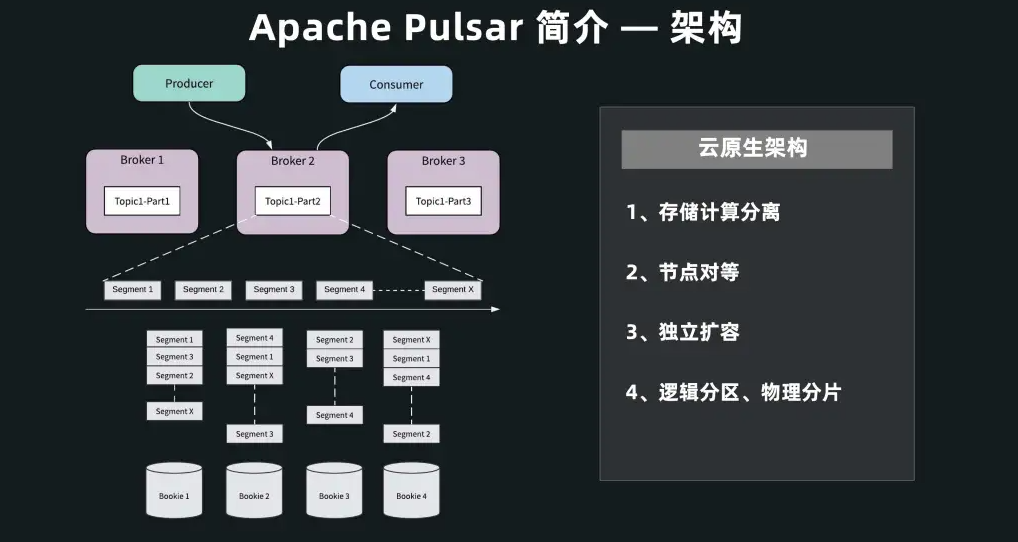
- 首先在计算层,Pulsar Broker 不保存任何状态数据、不做任何数据存储,称之为服务层。
- 其次,Pulsar 拥有一个专门为消息和流设计的存储引擎 BookKeeper,称之为数据层。
- 如果要支持更多的 Producer 和 Consumer,可扩充上面无状态的 Broker 层;
- 如果要支持更多的数据存储,可单独扩充底层存储层。
Pulsar的流批概念
? 这种分层的架构为做批流融合打好了基础。因为它原生分成了两层,可以根据用户的使用场景和批流的不同访问模式,来提供两套不同的 API。
-
如果是实时数据的访问,可以通过上层 Broker 提供的 Consumer 接口;
-
如果是历史数据的访问,可以跳过 Broker,用存储层的 reader 接口,直接访问底层存储层。
2.Hologres
1)Hologres的架构图
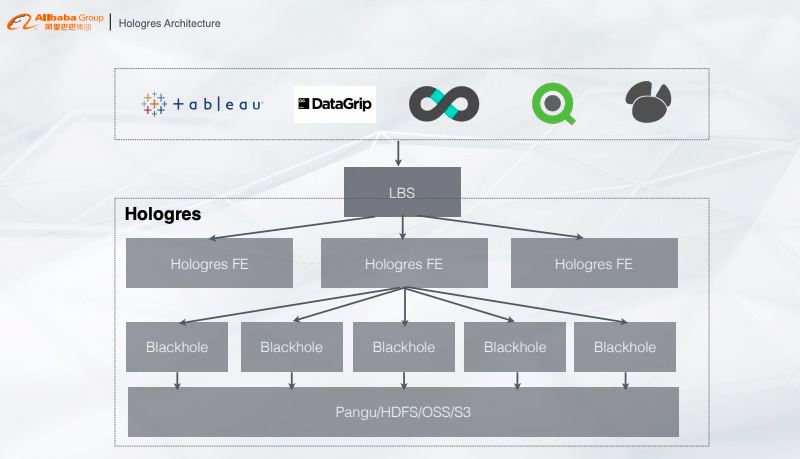
Hologres的架构从下往上看,最底层是统一的存储系统,可以是阿里云统一的Pangu、业务的HDFS或者OSS、S3等,存储上面是计算层,提供类似的MMP架构计算服务,再往上是FE层,根据查询信息将Plan分发到各个计算节点,再往上就是PostgreSQL生态的对接,只要有JDBC/ODBC Driver就能对Hologres做查询。
Hologres的架构是完全是存储计算分离,计算完全部署在K8s上,存储可以使用共享存储,可以根据业务需求选择HDFS或者云上的OSS,这样用户就能根据业务需求对资源做弹性扩缩容,完美解决资源不够带来的并发问题。
存储优势
-
全异步:支持高并发写入,能够将CPU最大化利用;
-
无锁:写入能力随资源线性扩展,直到将CPU全部写满;
-
内存管理:提供数据cache,支持高并发查询。
计算优势
-
高性能混合负载:慢查询和快查询混合一起跑,通过内部的调度系统,避免慢查询影响快查询;
-
向量化计算:列式数据通过向量化计算达到查询加速的能力;
-
存储优化:能够定制查询引擎,但是对存储在Hologres数据查询性能会更优。
问题提出
大致根据查询并发度要求或者查询Latency要求,将Patterns分为四类:
- Batch:离线计算
- Analytical:交互式分析
- Servering:高QPS的在线服务
- Transaction:与钱相关的传统数据库(绝大多数业务并不需要)
目前市面上都在说HTAP,经过调研HTAP是个伪命题,因为A和T的优化方向不一样。为了做T,写入链路将非常复杂,QPS无法满足需求。若是对T的要求降低一点,就会发现Analytical和Severing的联系非常紧密,这两块的技术是可以共用的,所以放弃了T就相当于放弃了Transaction,于是提出新的一个架构叫做HSAP,需要做的就是把提供服务和分析的数据存储在一个系统里,通过一套分析引擎来做处理。
2)Hologres的流批一体
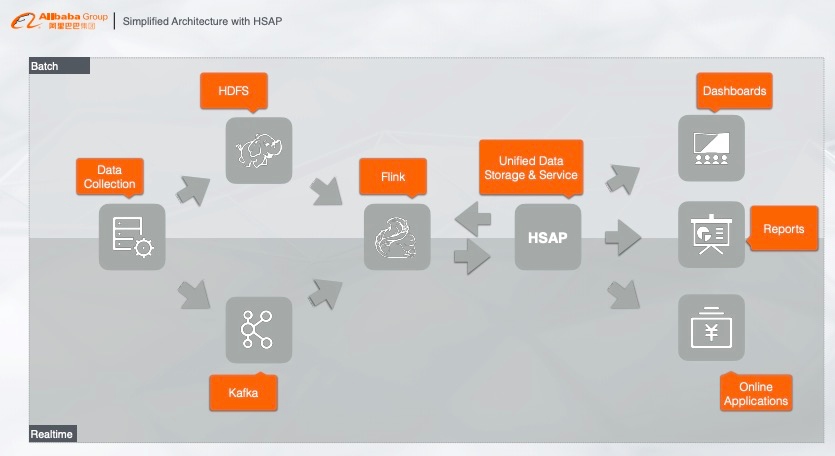
? 数据实时写入至Flink,经由Flink做实时预处理,比如实时ETL或者实时训练,把处理的结果直接写入Hologres,Hologres提供维表关联点查、结果缓存、复杂实时交互、离线查询和联邦查询等,这样整个业务系统只需要通过Hologres来做唯一的数据入口,在线系统可以通过PostgreSQL生态在Hologres中访问数据,无需对接其他系统,这样也能解决之前传统架构的各种查询、存储问题。
三、Flink中的流批一体
2020 年,Flink 在流批一体上走出了坚实的一步,可以抽象的总结为 Flink 1.10 和 1.11 这两个大的版本,主要是完成 SQL 层的流批一体化和实现生产可用性。实现了统一的流批一体的 SQL 和 Table 的表达能力,以及统一的 Query Processor,统一的 Runtime。在1.12 版本中,对 DataStream API 进行了流批一体化。在 DataStream 原生的流的算子上增加批的算子,也就是说 DataStream 也可以有两种执行模式,批模式和流模式里面也可以混合批算子和流算子。在1.13 的版本中,实现 DataStream 流批一体化的算子,整个的计算框架和 SQL 一样,完全都是流批一体化的计算能力。这样一来,原来 Flink 中的 DataSet 这套老的 API 就可以去掉,完全实现真正的流批一体的架构。
一)流批一体的DataStream
1.目前的SDK

-
Table/SQL 是一种 Relational 的高级 SDK,主要用在一些数据分析的场景中,既可以支持 Bounded 也可以支持 Unbounded 的输入。Table/SQL 可以支持 Batch 和 Streaming 两种执行模式。Relatinal SDK 功能虽然强大,但也存在一些局限:不支持对 State、Timer 的操作。
-
DataStream 属于一种 Physical SDK。DataStream 是一种 Imperative SDK,所以对物理执行计划有很好的“掌控力”。
-
DataSet 是一种仅支持 Bounded 输入的 Physical SDK,会根据 Bounded 的特性对某些算子进行做一定的优化,但是不支持 EventTime 和 State 等操作。
? 利用已有的 Physical SDK ,无法写出流批一体的application。另外,两套SDK的学习和理解的成本比较高,两套SDK 在语义上有不同的地方,例如 DataStream 上有 Watermark、EventTime,而 DataSet 却没有,对于用户来说,理解两套机制的门槛也不小;并且这两 SDK 不兼容。
2.期望的SDK

-
为什么选择了 DataStream 统一 DataSet ?DataSet 在社区的影响力逐渐下降。DataSet 算子的实现,在流的场景完全无法复用,例如 Join 等。而对于 DataStream 则不然,可以进行大量的复用。
-
提升DataStream的批效率。DataStream 是给 Unbounded 的场景下使用的,而 Unounded 一个主要的特点就是乱序,解决乱序引起了大量的序列化、反序列化和随机磁盘读写;DataSet 中,数据有的,通过优化避免随机磁盘 I/O 访问,同时也对序列化和反序列化做优化。通过单 Key 的 BatchStateBackend 几乎完全避免了对所有算子重写,同时还得到了非常不错的效果。
-
DataStream一致性的兼容,DataStream 写的 Application 都采用 Streaming 的执行模式,一致性依赖 Flink Checkpoint 机制的 2PC 协议,但这种模式的弊端是资源消耗大、容错成本高。提出了一个全新 Unified Sink API,从而让开发者提供 What to commit 和 How to commit,系统应该根据不同的执行模式,选择 Where to commit 和 When to commit 来保证端到端的 Exactly Once。
二)流体一体的DAG Scheduler
? Flink 有两种调度的模式:一种是流的调度模式,在这种模式下,Scheduler 会申请到一个作业所需要的全部资源,然后同时调度这个作业的全部 Task,所有的 Task 之间采取 Pipeline 的方式进行通信。一种是批的调度模式,所有 Task 都是可以独立申请资源,Task 之间都是通过 Batch Shuffle 进行通讯。这种方式的好处是容错代价比较小,不足是Task 之间的数据都是通过磁盘来进行交互,引发了大量的磁盘 IO。
基于 Pipeline Region 的统一调度
? Unified DAG Scheduler 允许在一个 DAG 图中,Task 之间既可以通过 Pipeline 通讯,也可以通过 Blocking 方式进行通讯。这些由 Pipeline 的数据交换方式连接的 Task 被称为一个 Pipeline Region。基于以上概念,Flink 引入 Pipeline Region 的概念,不管是流作业还是批作业,都是按照 Pipeline Region 粒度来申请资源和调度任务。
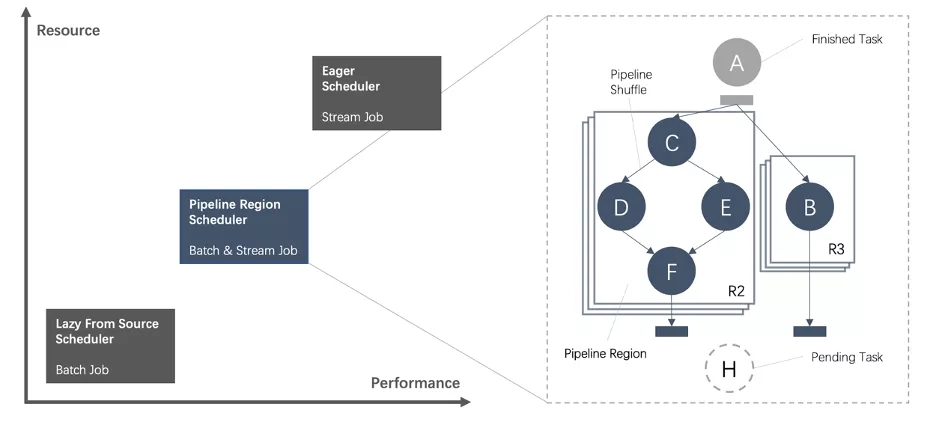
? 在 Flink 中,不同 Task 之间有两种连接方式,一种是 All-to-All 的连接方式,上游 Task 会和下游的所有的 Task 进行连接;一种是 PointWise 的链接方式,上游的 Task 只会和下游的部分 Task 进行连接。Flink Planner 可以根据实际运行场景,定制哪些 Task 之间采取 Pipeline 的传输方式,哪些 Task 之间采取 Batch 的传输方式方式。
自适应调度
? 调度的本质是给物理执行计划进行资源分配的决策过程。对于批作业来说静态生成物理执行计划存在一些问题,配置人力成本高,需要手动调整批作业的并发度,一旦业务逻辑发生变化,又要不断的重复这个过程,也可能会出现误判的情况导致无法满足用户 SLA;资源利用率低,中低优先级的作业以默认值作为并发度,造成资源的浪费;高优先级的作业不及时调低并发读,也造成大量的资源浪费现象;
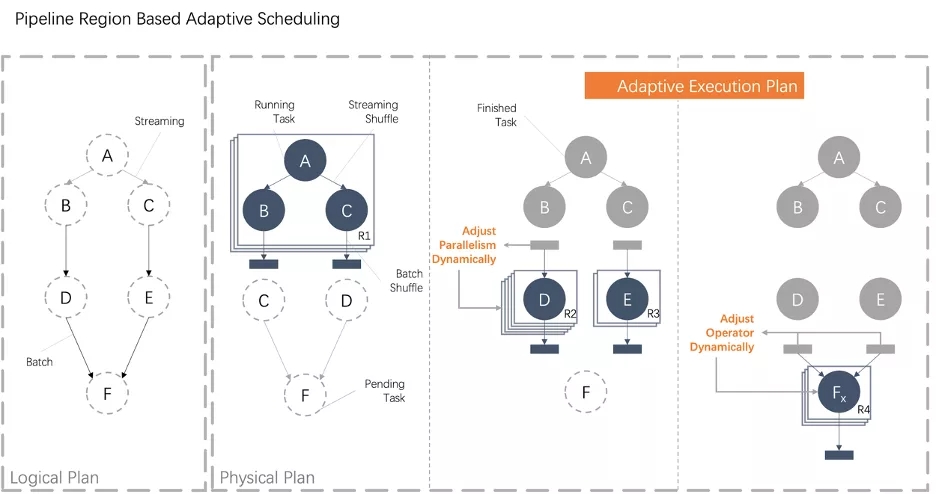
? 为批作业引入了自适应调度功能,和原来的静态物理执行计划相比,利用这个特性可以大幅提高用户资源利用率。 Adaptive Scheduler 可以根据一个 JobVertex 的上游 JobVertex 的执行情况,动态决定当前 JobVertex 的并发度。未来,也可以根据上游 JobVertex 产出的数据,动态决定下游采用什么样的算子。
三)流批一体的Shuffle
? Shuffle 本质上是为了对数据进行重新划分(re-partition),目标是提供一套统一的 Shuffle 架构,既可以满足不同 Shuffle 在策略上的定制,同时还能避免在共性需求上进行重复开发。批作业和流作业的 Shuffle 有差异也有共性,共性主要体现在:数据的 Meta 管理,所谓 Shuffle Meta 是指逻辑数据划分到数据物理位置的映射;数据传输,在分布式系统中,对数据的重新划分都涉及到跨线程、进程、机器的数据传输。
流批一体的 Shuffle 架构
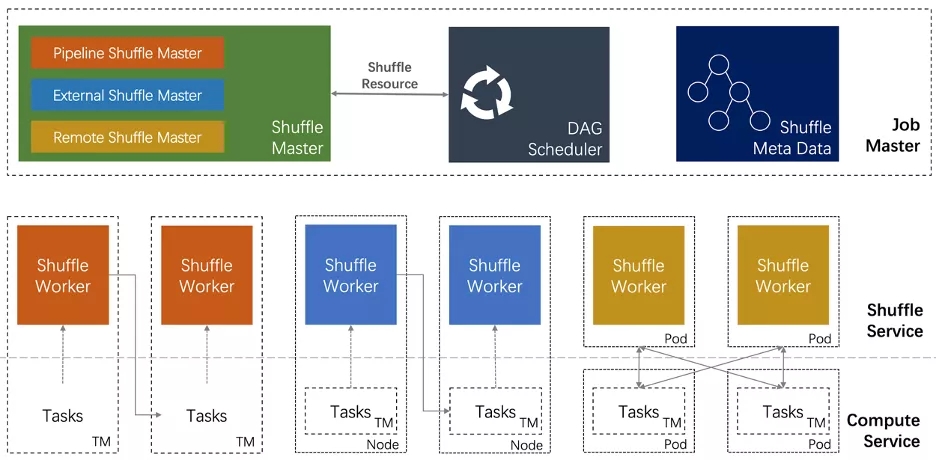
? Unified Shuffle 架构抽象出三个组件: Shuffle Master、Shuffle Reader、Shuffle Writer。Flink通过和这三个组件交互完成算子间的数据的重新划分。通过这三个组件可以满足不同Shuffle插件在具体策略上的差异:
- Shuffle Master 资源申请和资源释放。也就是说插件需要通知框架 How to request/release resource。而由 Flink 来决定 When to call it;
- Shuffle Writer 上游的算子利用 Writer 把数据写入 Shuffle Service――Streaming Shuffle 会把数据写入内存;External/Remote Batch Shuffle 可以把数据写入到外部存储中;
- Shuffle Reader 下游的算子可以通过 Reader 读取 Shuffle 数据;
? 同时,为流批 Shuffle 的共性――Meta 管理、数据传输、服务部署――提供了架构层面的支持,从而避免对复杂组件的重复开发。高效稳定的数据传输,是分布式系统最复杂的子系统之一,例如在传输中都要解决上下游反压、数据压缩、内存零拷贝等问题。
四)流批一体的容错
? Flink 现有容错策略以检查点为前提,无论是单个 Task 出现失败还是JobMaster 失败, 都会按照最近的检查点重启整个作业。Flink Batch 运行模式下不会开启检查点,一旦出现任何错误,整个作业都要从头执行。以下两个改进就主要为了提升批作业的容错能力。
Task的改进 Pipeline Region Failover
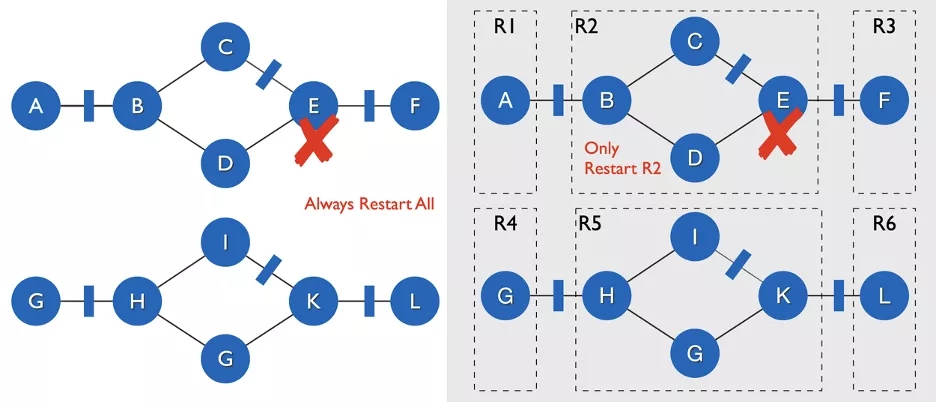
? Batch 执行模式下,Flink允许 Task 之间通过 Blocking Shuffle 进行通信。对于读取 Blocking Shuffle 的 Task 发生失败之后,由于 Blocking Shuffle 中存储了这个 Task 所需要的全部数据,所以只需要重启这个 Task 以及通过 Pipeline Shuffle 与其相连的全部下游任务即可,而不需要重启整个作业。
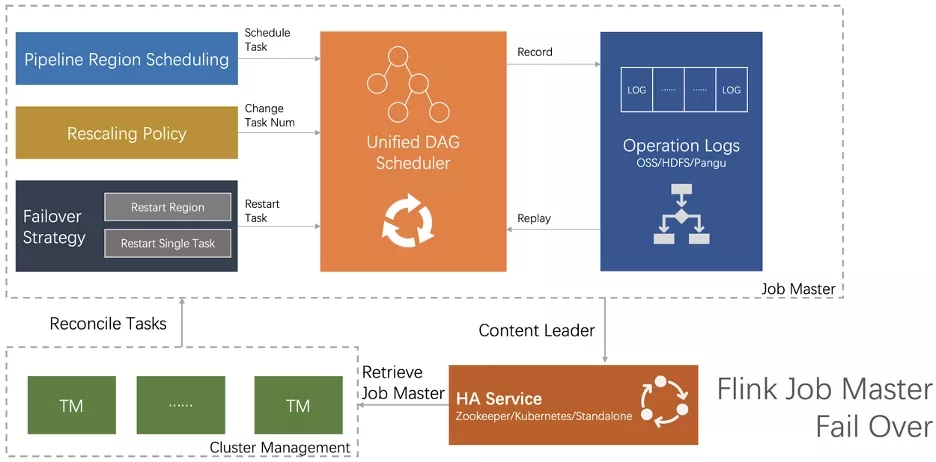
JM的改进 Operation Log
? JM 是一个作业的控制中心,包含了作业的各种执行状态,一旦 JM 发生错误之后,新 JM 无法判断现有的状态是否满足调度下游任务的条件――所有的输入数据都已经产生。JM Failover 的关键就是如何让一个 JM“恢复记忆”,通过基于 Operation Log 机制恢复 JM 的关键状态。
五)流批一体的总图
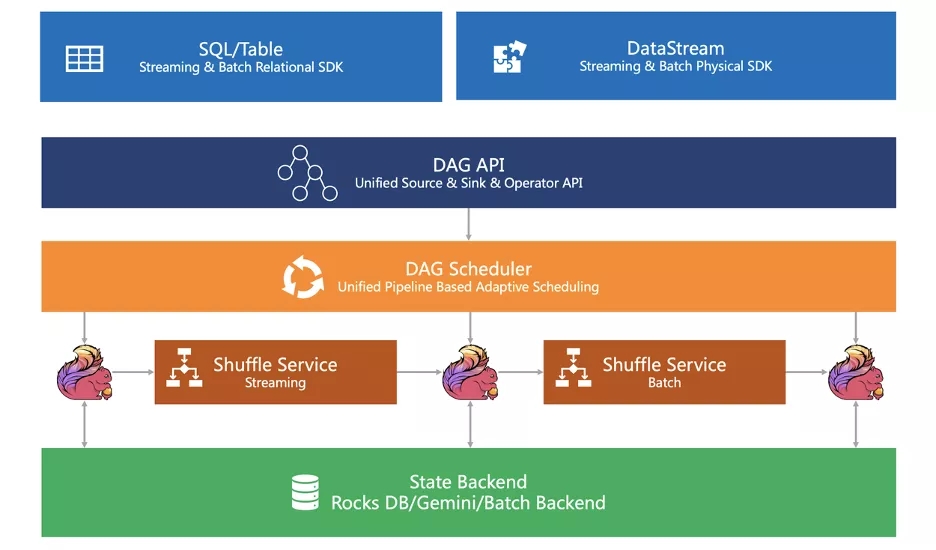
? 上图是一个Flink为了实现流批一体的引擎层所规划的框架图,其中很多还是规划和开发当中,在目前Flink最新版本1.14中,还没有完全实现上述的架构,但相信继续经过几个版本的迭代,Flink就可以在引擎层面完成流批一体的统一。