数据集
test_db下载 :https://gitee.com/lzjcnb/test_db
数据集安装:mysql -uroot -p -t < employees.sql
深度分页问题
后端开发为了防止一次加载太多数据到内存,对内存占用和IO读取开销太大,一般使用limit 关键字进行分页加载数据(懒加载,再需要查看时再加载数据),查询employess表中第[N,N+m]条记录,先看下测试数据集大小:
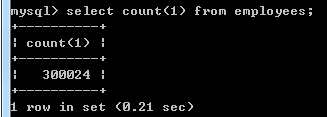
分别查询[10000,10003]三条记录和[100000,100003]三条记录,并观察执行时间。
mysql> select * from employees limit 10000,3;

发现在查询结果集数量一定的情况下,查询时间和查询深度成正比。
深度分页效率低原因: limit m,n查询过程是先回表查询m+n条记录,然后丢掉前m条,取后面n条结果返回。
深度分页优化
1 通过子查询优化
说明:在employees表中,emp_no是主键,也即聚集索引,在birth_date列创建一个普通非聚集索引。
mysql> create index birth_date_index on employees(birth_date);--在birth_date字段创建非聚集索引
查询语句1:
mysql> select * from employees
where birth_date > '1955-01-01'
order by emp_no
limit 100000,3;
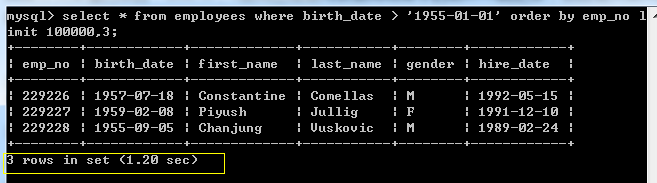
查询过程:

查询语句2:
mysql> select * from employees
where emp_no >=
(select emp_no from employees
where birth_date > '1955-01-01'
order by emp_no limit 100000,1)
limit 3;

查询过程:

小结:查询语句1和查询语句2实现同样的深度分页查询功能,观察查询效率,查询语句2是查询语句1的15倍。对比二者查询过程,查询语句2使用嵌套查询,在内层循环中只取聚簇索引列字段,确定深度分页的偏移量,此时不需要回表,在外层查询中使用聚簇索引筛偏移量之后的要查询结果集,查询语句2通过减少回表记录数,提高查询效率。
2 使用inner join优化
查询语句:
mysql> select e1.* from employees e1
inner join
(select emp_no from employees
where birth_date > '1955-01-01'
order by emp_no limit 100000,3) as e2
on e2.emp_no=e1.emp_no;

查询过程:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3N3skxXH-1647074518464)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/4c9578e0-eff9-40ff-952e-918e92183dc3/Untitled.png)]](https://img-blog.csdnimg.cn/9a141c36ba444e319aba96adff1ab9a9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbm9vZGxlc19tZWU=,size_20,color_FFFFFF,t_70,g_se,x_16)
优化原理:与基于子查询的优化方式类似,也是通过减少回表的记录数提高查询效率。
3 使用标签记录优化
查询语句:
mysql> select * from employees
where birth_date >'1955-01-01' and emp_no > 229225
order by emp_no limit 3;

优化原理:在非第一次查询之后,查询时,要记录已经读取的记录数量,效率非常快,缺点是在查询过程中数据库数据变化可能导致查询的数据不准,并且要求字段自增,并且每次查询要知道上一次查询结果中的最大Id,所以不能跳页查看,只能前后翻页。
小结
综合三种深度分页优化方式,基于标记的深度分页方式优化效果最明显,sql也最简单,针对主键索引不是自增问题,可以先使用order by进行排序解决。
mysql深度分页查询语句模板:
select * from tab_name
where 【条件1,条件2,条件3】 and id > #{lastId}
order by id
limit #{pageSize};
当数据量非常大的时候,where 查询速度也将变慢,基于ES的查询,可以提高查询效率,ES中同样存在深度分页的问题,在ES中使用了Scroll游标方式实现,具体实现原理todo…