1. 前言
MySQL属于关系型数据库,我们建的表大多也都存在业务上的关联关系,同时我们又不可能将所有的数据都冗余一份,这不符合数据库的设计范式。因此,当我们需要把多张表的数据融合在一起的时候,就需要使用到「多表连接查询」。
多表连接查询虽然用的很爽,但是常常会带来性能问题。大家可以回忆一下自己遇到的慢SQL,大多数都是多表联查导致的。有的DBA甚至会要求严格限制连接查询中表的数量,理论上来说,连接表的数量越多,效率越低。表连接最坏的情况,就是「笛卡尔积」,它没有任何限制条件,结果集中包含一张表中所有的记录与其它表所有的记录相互匹配的组合。两张各一万条记录的表,产生的笛卡尔积就有一亿条记录,如果是三张表结果更是不敢想象。
大家也不用被笛卡尔积吓到,它只是最坏的结果而已,只要使用得当,连接查询的效率也可以很高。
2. 连接查询的过程
在介绍具体的连接算法前,我们先来熟悉一下MySQL连接查询的过程。现有两张表t1、t2结构如下:
CREATE TABLE t1(
`id` INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`a` INT NOT NULL DEFAULT 0
)ENGINE=InnoDB AUTO_INCREMENT=1;
CREATE TABLE t2(
`id` INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
`b` INT NOT NULL DEFAULT 0
)ENGINE=InnoDB AUTO_INCREMENT=1;
使用存储过程向两张表格插入一些记录,然后执行下面这个SQL:
SELECT * FROM t1 INNER JOIN t2 ON t2.b=t1.id WHERE t1.id<10;
对于左外连接和右外连接,表的连接顺序是固定的,MySQL优化器能帮我们优化的点比较少,所以我们以内连接为主进行分析。对于内连接查询,表的连接顺序是可以互换的,因此MySQL优化器可以分别计算以t1为驱动表和以t2为驱动表的查询成本各是多少,然后选出执行成本更低的方案,也就是最终的执行计划。
具体执行成本的计算不在本文的讨论范围内,先跳过。
对于这个查询,我们指定了两个过滤条件:
- t1.id < 10
- t2.b = t1.id < 10
1、确定驱动表
MySQL首先需要从t1和t2中确定谁是驱动表。对于内连接,表的连接顺序是可以互换的,意味着t1和t2都可以作为驱动表,就看谁的执行成本更低了。MySQL会根据表/索引的统计数据或访问表中少量的数据来评估各自的执行成本,细节我们就先跳过。
2、驱动表获取到的每一条记录去被驱动表中进行匹配。
假设t1是驱动表,查询过程是这样的:
- 获取t1表中第一条id<10的记录。
- 拿着这个记录的id去查询t2表,条件是
t2.b=t1.id,由于t2.b没有索引,所以只能对t2做全表扫描。符合条件的记录返回,不符合条件的记录丢弃。 - 获取t1表中第二条id<10的记录,重复前面的流程,直到t1表中没有id<10的记录了。
t1表作为驱动表,只需要访问一次,且id是主键,因此t1.id<10可以使用range访问方法,效率还是很高的。问题在于对t2表的访问,由于t2.b没有索引,因此对于t1表中符合条件的每一条记录,都需要全表扫描一次t2表,这个开销是非常大的。
假设t2是驱动表,查询过程是这样的:
- 对t2进行全表扫描,取出第一条
t2.b<10的记录。 - 拿着该记录列b的值,去查询t1表,条件是
t1.id=t2.b。因为t1.id是主键,所以可以使用const访问方法,效率是很高的。 - 取出第二条
t2.b<10的记录,重复前面的流程,直到t1表中没有b<10的记录了。
t2表作为驱动表,只需要对t2全表扫描一次,但是需要对t1表的主键做等值匹配多次,匹配的次数取决于t2表中b<10的记录数量。
综上所述,t1表作为驱动表最大的开销是需要对t2表进行多次全表扫描,全表扫描的次数取决于t1.id<10的记录数量。t2表作为驱动表需要对t2全表扫描一次,但是需要对t1表主键等值匹配多次,匹配的次数取决于t2.b<10的记录数量。除非t1.id<10的记录足够的少,否则MySQL会跟偏向于使用t2作为驱动表,因为ALL比const访问效率要低的多。
笔者实测,对于t1.id<5MySQL认为t1表过滤出的记录足够少,使用t1作为驱动表的成本更低。
mysql> EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t2.b=t1.id WHERE t1.id<5;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+-------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+-------+----------+----------------------------------------------------+
| 1 | SIMPLE | t1 | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 4 | 100.00 | Using where |
| 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 50424 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+-------+----------+----------------------------------------------------+
而对于t1.id<100MySQL担心会对t2执行太多次全表扫描,因此更偏向于使用t2作为驱动表。
mysql> EXPLAIN SELECT * FROM t1 INNER JOIN t2 ON t2.b=t1.id WHERE t1.id<100;
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+-------+----------+-------------+
| 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 50424 | 100.00 | Using where |
| 1 | SIMPLE | t1 | NULL | eq_ref | PRIMARY | PRIMARY | 4 | test.t2.b | 1 | 100.00 | NULL |
+----+-------------+-------+------------+--------+---------------+---------+---------+-----------+-------+----------+-------------+
Using join buffer (Block Nested Loop)代表MySQL使用了基于块的嵌套循环连接算法,减少全表扫描的次数。
3. 连接算法
MySQL表连接查询,支持多种连接算法。
3.1 Simple Nested Loop Join
简单嵌套循环连接,最简单也最笨拙的一种算法。从t1表读取的每一条记录,都需要扫描t2表的所有记录进行匹配。
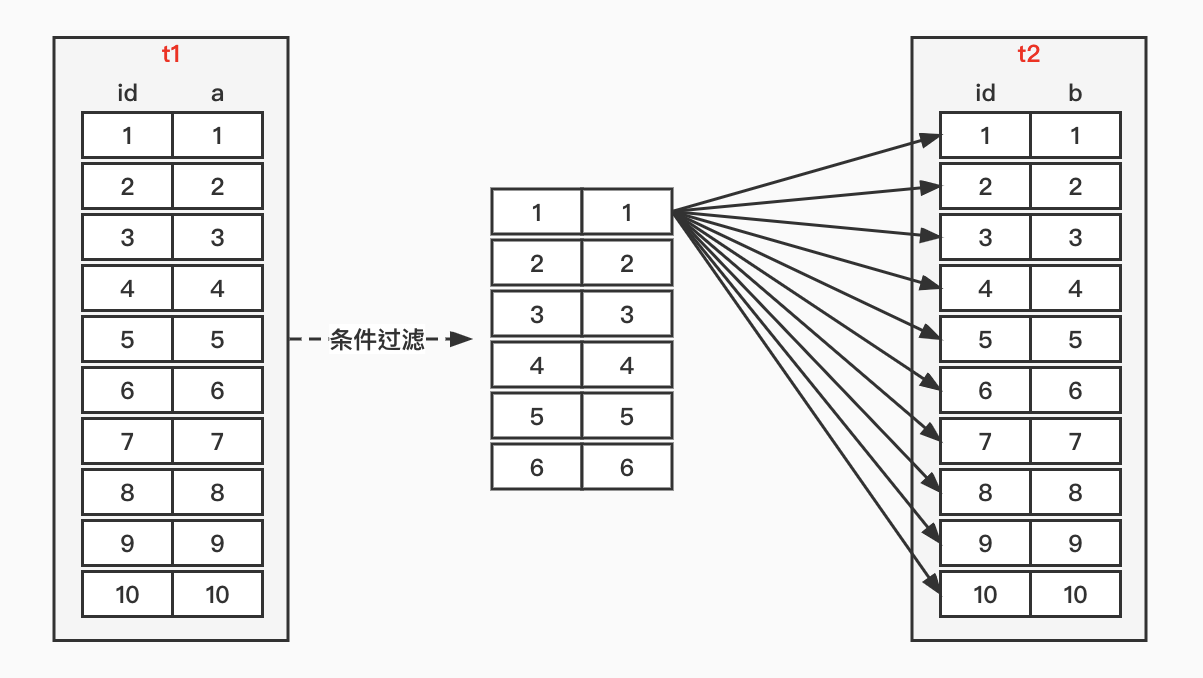
这个过程就像是一个嵌套的循环,连接的表的数量就是循环嵌套的层数,当表中数据量较大,或者连接的表的数量过多时,这种算法的效率是极低的。
对于t1表获取到的每一条记录,都会立马去t2表进行匹配查询,而不会等t1表的记录检索完成了再去查询t2。说白了,MySQL并不会使用额外的空间来保存t1表记录的检索结果。
3.2 Index Nested Loop Join
第一种算法,t1表过滤出多少条记录,就需要对t2表进行多少次全表扫描。对于t1表的每一条记录,其实都是一次针对于t2的单表查询,如果我们能优化每一次对t2的单表查询效率,也就能优化整个连接查询的效率了。
如何优化针对t2的单表查询效率?加索引啊!如果连接查询的过滤条件是t2表的列b,那么就给列b加索引。如果加的是普通索引,那么访问方法可以从ALL优化为ref,如果加的是唯一索引,更是能直接优化为const。
3.3 Block Nested Loop Join
现在我们已经知道,如果不能通过索引来加速被驱动表的查询效率,MySQL只能对被驱动表执行N次全表扫描了。如果表中的记录很少,碰巧机器的内存又很大,全表扫描尚且可以接受,因为内存可以容纳足够多的索引页,N次全表扫描的开销也只需要将聚簇索引的叶子节点加载到内存中一次,后面都可以命中缓存了。然而现实情况是表中的数据通常会很多,且内存又十分紧张。这种场景下,InnoDB加载完后面的索引页,前面的索引页缓存就不得不淘汰了,第二次全表扫描又得来一遍IO,这个开销就没法接受了。MySQL还能怎么优化呢?
MySQL提出了一个名为Join Buffer的概念,连接缓冲区,在执行连接查询前先申请一块固定大小的内存空间,然后将驱动表中的若干条记录放到Join Buffer里,访问被驱动表时就可以一次性与Join Buffer里的所有记录进行匹配了,这样可以显著减少被驱动表的访问次数。理论上Join Buffer越大越好,最好能大到可以容纳驱动表过滤出的所有记录,这样被驱动表只需要全表扫描一次就好了。这种基于Join Buffer来减少被访问表的访问次数的算法,就是Block Nested Loop Join。
Join Buffer不会存放驱动表的所有列信息,只会存储SELECT查询的列和过滤条件涉及到的列,所以查询时要尽量避免使用SELECT *
4. 总结
连接查询可以将多张表的数据汇总到一起,使用连接查询时要特别注意性能问题,最差的结果就是笛卡尔积。MySQL支持多种连接查询算法,最简单最笨拙的就是简单嵌套循环连接,驱动表只需要访问一次,被驱动表要访问多次,访问次数取决于驱动表过滤出的记录数量。
连接查询的主要开销,来自于对被驱动表的访问。驱动表过滤出的每一条记录其实都对应着被驱动表的一次单表查询,我们可以通过给被驱动表加索引的方式,来优化对被驱动表的查询效率,进而提高连接查询的效率,这就是基于索引的嵌套循环连接。
如果实在是无法通过索引来提高连接查询的效率,MySQL还可以通过Join Buffer性存储若干条驱动表的记录,访问被驱动表时就可以一次性与这些记录进行匹配了,显著减少访问被驱动表的次数。