�Ż���Ҫ�Ӷ��ά�Ƚ����Ż�
���а����ĸ�:SQL��估���������ṹ��ơ�ϵͳ���á�Ӳ�����á�
����SQL�����ص��Ż��ֶ�����Ϊ��Ҫ��
Ӳ������
Ӳ��������Ż��������Դ��̽������ݡ�����еӲ�̻�ΪSSD �ȵȡ�������Ż��ֶγɱ����,��ЧҲ��С��
ϵͳ����
ϵͳѡ��
ϵͳͨ��ʹ��Linux��Ϊ����˵�ϵͳ,���ؿ����Ļ��������⡣Linux ϵͳ�汾�� MySQL �汾ѡ���ȶ��İ汾���ɡ�
��֤���ڴ��ȡ
MySQL �����ڴ��б���һ��������,ͨ�� LRU(�������ʹ��)�㷨���������ʵ����ݱ�����Ӳ���ļ��С������ܵ������ڴ��е�������,�����ݱ������ڴ���,���ڴ��ж�ȡ����,�������� MySQL ���ܡ�
MySQL ʹ���Ż������ LRU �㷨:
��ͨLRU:ĩβ��̭��,�����ݴ�����ͷ������,�ͷſռ�ʱ��ĩβ��̭
�Ľ�LRU:������Ϊnew��old��������,����Ԫ��ʱ�����Ǵӱ�ͷ����,���Ǵ��м� midpointλ�ò���,������ݺܿ챻����,��ôpage�ͻ���new�б�ͷ���ƶ�,��� ����û�б�����,������oldβ���ƶ�,�ȴ���̭��ÿ�����µ�page���ݶ�ȡ��buffer poolʱ,InnoDb������ж��Ƿ��п���ҳ,�Ƿ��㹻,����оͽ�free page��free list�б�ɾ��,���뵽LRU�б��С�û�п���ҳ,�ͻ����LRU�㷨��̭LRU����Ĭ�ϵ�ҳ,���ڴ�ռ��ͷŷ�����µ�ҳ��
LRU �㷨��Ե��� MySQL �ڴ��еĽṹ,�����и������ Buffer Pool(�����) ��Ϊ���ݶ�д�Ļ�������������������Ӧ��������������,��Ȼ�������Ҫ��Է�����Ӳ����ʵ��������е�����
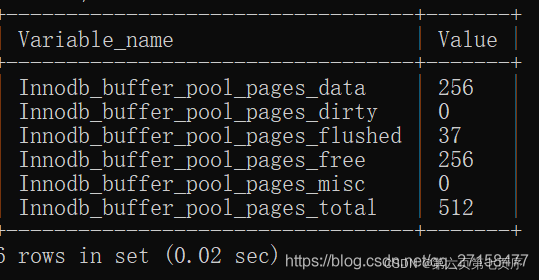
ͨ������������Բ鿴��Ӧ��BufferPool����ز���:
show global status like 'innodb_buffer_pool_pages_%'
��������������Բ鿴 BufferPool �Ĵ�С:
show variables like "%innodb_buffer_pool_size%"
���������ǿ��������������ֵ,����÷������� MySQL ר�õķ�����,���ǿ��� ��Ϊ���ڴ�� 60%~80% ,��Ȼ����Ӱ��ϵͳ��������С�
���������ֻ����,������ MySQL �������ļ�(my.cnf �� my.ini)�н����ġ�Linux �������ļ�Ϊ my.cnf��
# �Ļ���ش�СΪ750M
innodb_buffer_pool_size = 750M
����Ԥ��
����Ԥ���൱�ڽ������е�������ǰ����BufferPool �ڴ滺����ڡ�һ���̶������˶�ȡ�ٶȡ�
���� InnoDB,�����ṩһ��Ԥ�� SQL �ű�:
#mysql5.7�汾��,���DISTINCT��order byһ��ʹ�ý��ᱨ3065����,sql�����ִ�С���������5.7�汾���֮ǰ�汾�Ҫ������ϸ��µġ�
#�Ƽ���mysql�������ļ�my.cnf�ļ�(linux)/my.ini�ļ�(window) ��mysqld�����ӻ�����sql_model����ѡ��
#sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
#��������Ч
SELECT DISTINCT
CONCAT('SELECT ',rowlist,' FROM ',db,'.',tb,
' ORDER BY ',rowlist,';') selectSql
FROM
(
SELECT
engine,table_schema db,table_name tb,
index_name,GROUP_CONCAT(column_name ORDER BY seq_in_index) rowlist
FROM
(
SELECT
B.engine,A.table_schema,A.table_name,
A.index_name,A.column_name,A.seq_in_index
FROM
information_schema.statistics A INNER JOIN
(
SELECT engine,table_schema,table_name
FROM information_schema.tables WHERE
engine='InnoDB'
) B USING (table_schema,table_name)
WHERE B.table_schema NOT IN ('information_schema','mysql')
ORDER BY table_schema,table_name,index_name,seq_in_index
) A
GROUP BY table_schema,table_name,index_name
) AA
ORDER BY db,tb;
���ʹ��̵�д�����
(1)���� redo log,�������̴���:
redo log ��������־,���ڱ�֤���ݵ�һ��,���������൱�ڼ�����ϵͳ IO ������
innodb_log_file_size ����Ϊ 0.25 * innodb_buffer_pool_size
(2)ͨ�ò�ѯ��־������ѯ��־���Բ��� ,binlog �ɿ�����
ͨ�ò�ѯ������ѯ��־Ҳ��Ҫ���̵�,���Ը���ʵ���������,�������Ҫʹ�õĻ��Ϳ��Թص���binlog ���ڻָ������Ӹ���,������Կ�����
�鿴��ز���������:
# ����ѯ��־
show variables like 'slow_query_log%'
# ͨ�ò�ѯ��־
show variables like '%general%';
# ������־
show variables like '%log_error%'
# ��������־
show variables like '%binlog%';
(3)д redo log ���� innodb_flush_log_at_trx_commit ����Ϊ 0 �� 2
���ڲ���Ҫǿһ���Ե�ҵ��,��������Ϊ 0 �� 2��
- 0:ÿ�� 1 ��д��־�ļ���ˢ�̲���(д��־�ļ� LogBuffer --> OS cache,ˢ�� OS cache --> �����ļ�),��ඪʧ 1 ������
- 1:�����ύ,����д��־�ļ���ˢ��,���ݲ���ʧ,���ǻ�Ƶ�� IO ����
- 2:�����ύ,����д��־�ļ�,ÿ�� 1 ���ӽ���ˢ�̲���
ϵͳ���Ų���
back_log
back_logֵ����ָ����MySQL��ʱֹͣ�ش�������֮ǰ�Ķ�ʱ���ڶ��ٸ�������Ա����ڶ�ջ�С�Ҳ����˵,���MySQL���������ݴﵽmax_connectionsʱ,���������ᱻ���ڶ�ջ��,�Եȴ�ijһ�����ͷ���Դ,�ö�ջ��������back_log,����ȴ����ӵ���������back_log,����������������Դ�����Դ�Ĭ�ϵ�50����500��
wait_timeout
���ݿ���������ʱ��,�������ӻ�ռ���ڴ���Դ�����Դ�Ĭ�ϵ�8Сʱ������Сʱ��
max_user_connection
���������,Ĭ��Ϊ0������,�����һ���������ޡ�
thread_concurrency
�����߳���,��ΪCPU������������
skip_name_resolve
��ֹ���ⲿ���ӽ���DNS����,����DNS����ʱ��,����Ҫ����Զ��������IP���ʡ�
key_buffer_size
������Ļ����С,���ӻ��������������ٶ�,��MyISAM������Ӱ��������ڴ�4G����,����Ϊ256M��384M,ͨ����ѯshow status like ��key_read%��,��֤key_reads / key_read_requests��0.1%������á�
innodb_buffer_pool_size
�������ݿ��������,��InnoDB������Ӱ�����ͨ����ѯshow status like ��Innodb_buffer_pool_read%��,��֤ (Innodb_buffer_pool_read_requests �C Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requestsԽ��Խ�á�
innodb_additional_mem_pool_size
InnoDB�洢����������������ֵ���Ϣ�Լ�һЩ�ڲ����ݽṹ���ڴ�ռ��С,�����ݿ����dz����ʱ��,�ʵ������ò����Ĵ�С��ȷ���������ݶ��ܴ�����ڴ�����߷���Ч��,����С��ʱ��,MySQL���¼Warning��Ϣ�����ݿ�Ĵ�����־��,��ʱ����Ҫ�õ������������С��
innodb_log_buffer_size
InnoDB�洢�����������־��ʹ�õĻ�����,һ����˵�����鳬��32MB��
query_cache_size
����MySQL�е�ResultSet,Ҳ����һ��SQL���ִ�еĽ����,���Խ���ֻ�����select��䡣��ij�������������κα仯,���ᵼ�����������˸ñ���select�����Query Cache�еĻ�������ʧЧ������,���������ݱ仯�dz�Ƶ���������,ʹ��Query Cache���ܵò���ʧ������������(Qcache_hits/(Qcache_hits+Qcache_inserts)*100))���е���,һ�㲻����̫��,256MB�����Ѿ������,���͵������;�̬���ݿ��ʵ�������ͨ������show status like 'Qcache_%'�鿴ĿǰϵͳQuery catchʹ�ô�С��
read_buffer_size
MySQL���뻺������С���Ա�����˳��ɨ���������һ�����뻺����,MySQL��Ϊ������һ���ڴ滺����������Ա���˳��ɨ������dz�Ƶ��,����ͨ�����Ӹñ���ֵ�Լ��ڴ滺������С����������ܡ�
sort_buffer_size
MySQLִ������ʹ�õĻ����С�������Ҫ����ORDER BY���ٶ�,���ȿ��Ƿ������MySQLʹ�����������Ƕ��������Ρ��������,���Գ�������sort_buffer_size�����Ĵ�С��
read_rnd_buffer_size
MySQL���������������С����������˳���ȡ��ʱ(���簴������˳��),������һ������������������������ѯʱ,MySQL������ɨ��һ��û���,�Ա����������,��߲�ѯ�ٶ�,�����Ҫ�����������,���ʵ����߸�ֵ����MySQL��Ϊÿ���ͻ����ӷ��Ÿû���ռ�,����Ӧ�����ʵ����ø�ֵ,�Ա����ڴ濪������
record_buffer
ÿ������һ��˳��ɨ����߳�Ϊ��ɨ���ÿ�ű����������С��һ������������������ܶ�˳��ɨ��,������Ҫ���Ӹ�ֵ��
thread_cache_size
���浱ǰû�������ӹ���������Ϊ�����µ����ӷ�����߳�,���Կ�����Ӧ���ӵ��߳���������贴���µġ�
table_cache
������thread_cache _size,������������ļ�,��InnoDBЧ������,��Ҫ����MyISAM��
���ṹ���
�����
����м��,һ�������ͳ�Ʒ�������,����ʵʱ�Բ��ߵ�����(����ͳ��,���ݷ�����ϵͳ)��
��������ֶ�
Ϊ���ٹ�����ѯ,���������������ֶ�(���������ֶλ���Ҫע������һ��������)������ֿ�ֱ�ʱ��Ϊ���á�
���
�����ֶ�̫��Ĵ��,���Dz��(����һ������100����ֶ�) ���ڱ��о�������ʹ�õ��ֶλ��ߴ洢���ݱȽ϶���ֶ�,���Dz����
�����Ż�
ÿ�ű����鶼Ҫ��һ������(��������),�����������������int����,������������(�ֲ�ʽϵͳ������½���ѩ���㷨)
�ֶε����
���ݿ��еı�ԽС,��������ִ�еIJ�ѯҲ�ͻ�Խ�졣���,�ڴ�������ʱ��,Ϊ�˻�ø��õ�����,���ǿ��Խ������ֶεĿ�����þ�����С��
- ʹ�ÿ��Դ���������С����������,���ʼ���
- ����ʹ��TINYINT��SMALLINT��MEDIUM_INT��Ϊ�������Ͷ���INT,����Ǹ������UNSIGNED;
- VARCHAR�ij���ֻ����������Ҫ�Ŀռ�;
- ����ijЩ�ı��ֶ�,����"ʡ��"����"�Ա�",ʹ��ö�ٻ����������ַ�������;��MySQL��, ENUM���ͱ�������ֵ������������,����ֵ�����ݱ������������ٶ�Ҫ���ı����Ϳ�ö�
- ����ʹ��TIMESTAMP����DATETIME;
- ������Ҫ��̫���ֶ�,������20����;
- ������ʹ�� not null �����ֶ�,null ռ��4�ֽڿռ�,�����ڽ���ִ�в�ѯ��ʱ��,���ݿⲻ��ȥ�Ƚ�NULLֵ��
- ����������IP��
- �������� text ����,���ò���ʱ��ÿ��Dz��
MySQL��估����
�������SQL��ѯ�Ƚ���,���Կ�������ѯ��־�����Ų顣
# ����ȫ������ѯ��־
SET global slow_query_log = ON;
# ��������ѯ��־�ļ���
SET global slow_query_log_file = 'slow-query.log';
# ��¼δʹ��������SQL
SET global log_queries_not_using_indexes = ON;
# ����ѯ��ʱ����ֵ,Ĭ��10��
SET long_query_time = 10;
ע:����������Խ��Խ��,Ҫ���ݲ�ѯ������ԵĴ�����
����������ʹ��ԭ��
- ������ѯ:�ĸ�������ѯ����,���ڸ��д�������
- �����ѯ:left join ʱ,�������ӵ��ұ������ֶ�;right join ʱ,�������ӵ���������ֶ�
- ��Ҫ�������н����κβ���(���㡢����������ת��)
- �������в�Ҫʹ�� !=,<> �ǵ���
- �ַ��ֶ�ֻ��ǰ����,��ò�Ҫ������;
- ��������UNIQUE,�ɳ���֤Լ��
- �������,�ɳ���֤Լ��
- �����в�ҪΪ��,�Ҳ�Ҫʹ�� is null �� is not null �ж�
- �����ֶ����ַ�������,��ѯ������ֵҪ�ӡ�'������,����ײ������Զ�ת��
ʹ�� EXPLAIN ���� SQL
�����explain�Ľ�����м�˵��:
- select_type:��ѯ����
- SIMPLE ��ѯ
- PRIMARY ������ѯ
- UNION union������ѯ
- SUBQUERY �Ӳ�ѯ
- type:��ѯ����ʱ���õķ�ʽ
- ALL ȫ��(�������)
- index ����������ȫ��
- range ��Χ (< > in)
- ref ��Ψһ������ֵ��ѯ
- const ʹ����������Ψһ������ֵ��ѯ
- possible_keys:�����õ�������
- key:�����õ�������
- rows:Ԥ��ɨ������м�¼
- key_len:ʹ�����������ֽ���
- Extra:������Ϣ
- Using where �����ر�
- Using index ����ֱ����������
- Using filesort ��Ҫ����
- Using temprorary ʹ�õ���ʱ��
�������ϵļ�����,�����ص��ע����type,��ֱ�۵ķ�ӳ��SQL�����ܡ�
SQL��価���ܼ�
һ��sqlֻ����һ��cpu����;������С���,������ʱ��;һ����sql���Զ��������⡣
����������ֵ,ʹ�� BETWEEN ���� IN
SELECT id FROM t WHERE num BETWEEN 1 AND 5;
SQL ����� IN ������ֵ��Ӧ����
MySQL����IN������Ӧ���Ż�,����IN�еij���ȫ���洢��һ����������,��������������ź���ġ������ֵ�϶�,��Ҫ���ڴ�����������,����������Ҳ�DZȽϴ�ġ�
SELECT ������ָ���ֶ�����
SELECT * ���Ӻܶ��Ҫ������(CPU��IO���ڴ桢�������);������ʹ�ø��������Ŀ����ԡ�
��ֻ��Ҫһ�����ݵ�ʱ��,ʹ�� limit 1
limit �൱�ڽضϲ�ѯ��
����:����select * from user limit 1; ��Ȼ������ȫ��ɨ��,����limit�ض���ȫ��ɨ��,��0��ʼȡ��1�����ݡ�
�����ֶμ�����
������ֶν��������������ʱ��Ҳ���õ�
������������������ֶ�û������,��������or
������ union all ���� union
union��union all�IJ�������union���������һ��distinct�Ķ���,�����distanct�������ٶ���ȡ�����������ݵ�����,����Խ����ʱ��ҲԽ���������ڼ������ݼ�,Ҫȷ�����ݼ�֮������ݻ���ظ�,������O(n)���㷨���Ӷȡ�
���� in �� exists��not in �� not exists
�����exists,��ô������Ϊ������,�ȱ�����,�����IN,��ô��ִ���Ӳ�ѯ������IN�ʺ����������ڱ�С�����;EXISTS�ʺ������С���ڱ���������
ʹ�ú����ķ�ҳ��ʽ����߷�ҳ��Ч��
limit m n,���е�mƫ��������С��mԽ���ѯԽ����
����ʹ�� % ǰģ����ѯ
����:like '%name������like ��%name%��,���ֲ�ѯ�ᵼ������ʧЧ������ȫ��ɨ�衣���ǿ���ʹ��like ��name%��,���ֻ�ʹ�õ�������
������ where �Ӿ��ж��ֶν��б���ʽ����
���ֲ���ʹ�õ�����:
select user_id,user_project from user_base where age*2=36;
���Ը�Ϊ:
select user_id,user_project from user_base where age = 36/2;
�κζ��еIJ����������±�ɨ��,���������ݿ⺯�����������ʽ�ȵ�,��ѯʱҪ�����ܽ����������Ⱥ��ұߡ�
������ʽ����ת��
where �Ӿ��г��ֵ� column �ֶ�Ҫ�����ݿ��е��ֶ����Ͷ�Ӧ
��Ҫʱ����ʹ�� force index ��ǿ�Ʋ�ѯ��ij������
�е�ʱ�� MySQL �Ż�����ȡ����Ϊ���ʵ����������� SQL ���,���ǿ����������õ�����������������Ҫ�ġ���ʱ�Ϳ��Բ��� forceindex ��ǿ���Ż���ʹ�������ƶ���������
ʹ����������ʱע�ⷶΧ��ѯ
��������������˵,������ڷ�Χ��ѯ,����between��>��<������ʱ,����ɺ���������ֶ�ʧЧ��
ijЩ�����,����ʹ�����Ӵ����Ӳ�ѯ
��Ϊʹ�� join,MySQL �������ڴ��д�����ʱ����
ʹ��JOIN���Ż�
ʹ��С���������,����ʹ��inner joinʱ,�Ż�����ѡ��С����Ϊ������
С���������,��С�����ݼ�����������ݼ�
��:�� A,B ����Ϊ��,����ͨ�� id �ֶν��й�����
#�� B �������ݼ�С�� A ��ʱ,�� in �Ż� exist;ʹ�� in ,����ִ��˳�����Ȳ� B ��,�ٲ� A ��
select * from A where id in (select id from B)
#�� A �������ݼ�С�� B ��ʱ,�� exist �Ż� in;ʹ�� exists,����ִ��˳�����Ȳ� A ��,�ٲ� B ��
select * from A where exists (select 1 from B where B.id = A.id)