1.��̬SQL
����ִ��SQL���,ͨ�����Ǹ���������ִ�еġ�Mybatis��ܵĶ�̬SQL������һ�ָ����ض�������̬ƴװSQL���Ĺ���,�����ڵ�������Ϊ�˽�� ƴ��SQL����ַ���ʱ��ʹ�����⡣
1.1 if��ǩ
if��ǩ��ͨ��test���Եı���ʽ�����ж�,������ʽ�Ľ��Ϊtrue,���ǩ�е����ݻ�ִ��;��֮��ǩ�е����ݲ���ִ��.
��Ҫע��and��λ�á�
<select id="getEmpByObject" resultType="Employees">
select * from employees where
<if test="employee_id != '' and employee_id != null">
employee_id = #{employee_id}
</if>
<if test="email != '' and email != null">
and email = #{email}
</if>
</select>
<!--
sql:
select * from employees WHERE employee_id = ? and email = ?
-->
1.2 where��ǩ
where��ifһ����ʹ��:
- ��where��ǩ�е�if������������,��where��ǩû���κι���,����������where�ؼ���
- ��where��ǩ�е�if��������,��where��ǩ���Զ�����where�ؼ���,����������ǰ�������andȥ��
ע��:where��ǩ����ȥ�������������and
<select id="getEmpByWhere" resultType="employees">
select * from employees
<where>
<if test="employee_id != '' and employee_id != null">
and employee_id = #{employee_id}
</if>
<if test="email != '' and email != null">
and email = #{email}
</if>
</where>
</select>
<!--
sql:
select * from employees WHERE employee_id = ? and email = ?
-->
1.3 trim
trim����ȥ�������ӱ�ǩ�е�����,���Խ���
- prefix:��trim��ǩ�е����ݵ�ǰ������ijЩ����
- prefixOverrides:��trim��ǩ�е����ݵ�ǰ��ȥ��ijЩ����
- suffix:��trim��ǩ�е����ݵĺ�������ijЩ����
- suffixOverrides:��trim��ǩ�е����ݵĺ���ȥ��ijЩ����
<select id="getEmpByTrim" resultType="employees">
select * from employees
<trim prefix="where" suffixOverrides="and">
<if test="employee_id != '' and employee_id != null">
employee_id = #{employee_id} and
</if>
<if test="email != '' and email != null">
email = #{email} and
</if>
</trim>
</select>
<!--
SQL���
select * from employees where employee_id = ? and email = ?
-->
1.4 choose��when��otherwise
choose��when��otherwise�൱��if��else if��else
<select id="getEmpByChoose" resultType="employees">
select * from employees
<where>
<choose>
<when test="employee_id != '' and employee_id != null">
and employee_id = #{employee_id}
</when>
<otherwise>
1 = 1
</otherwise>
</choose>
</where>
</select>
<!--
sql���:
select * from employees WHERE employee_id = ?
-->
1.5 foreach
foreach����ѭ��,���Խ���:
- collection:����Ҫѭ���������
- item:��ʾ���ϻ������е�ÿһ������
- separator:����ѭ����֮��ķָ���
- open:����foreach��ǩ�е����ݵĿ�ʼ��
- close:����foreach��ǩ�е����ݵĽ�����
<insert id="insertEmp">
insert into employees(employee_id, last_name, email) values
<foreach collection="lists" item="emp" separator=",">
(#{emp.employee_id}, #{emp.last_name}, #{emp.email})
</foreach>
</insert>
<!--
SQL���:
insert into employees(employee_id, last_name, email) values (?, ?, ?) , (?, ?, ?) , (?, ?, ?)
-->
1.6 SQLƬ��
sqlƬ��,���Լ�¼һ�ι���sqlƬ��,��ʹ�õĵط�ͨ��include��ǩ��������
<sql id="empColumns">
eid,ename,age,sex,did
</sql>
select <include refid="empColumns"></include> from t_emp
2.Mybatis�Ļ���
Mybatis�Ļ����Ϊ��������,һ��������SqlSession����,��һ����SqlSessionFactory����
2.1 MyBatis��һ������
һ��������SqlSession�����,ͨ��ͬһ��SqlSession��ѯ�����ݻᱻ����,�´β�ѯ��ͬ������,�� ��ӻ�����ֱ�ӻ�ȡ,��������ݿ����·���
@Test
public void testGetEmpByObject() {
Employees employees = new Employees();
employees.setEmployee_id(300);
employees.setEmail("sakha");
//��һ�β�ѯ
List<Employees> empByObject1 = mapper.getEmpByObject(employees);
empByObject1.forEach(list -> System.out.println(list));
//�ڶ��β�ѯ
List<Employees> empByObject2 = mapper.getEmpByObject(employees);
empByObject2.forEach(list -> System.out.println(list));
}
/**
DEBUG 03-14 13:30:20,141 ==> Preparing: select * from employees where employee_id = ? and email = ? (BaseJdbcLogger.java:137)
DEBUG 03-14 13:30:20,173 ==> Parameters: 300(Integer), sakha(String) (BaseJdbcLogger.java:137)
DEBUG 03-14 13:30:20,201 <== Total: 1 (BaseJdbcLogger.java:137)
Employees{employee_id=300, first_name='ww', last_name='hh', email='sakha'}
Employees{employee_id=300, first_name='ww', last_name='hh', email='sakha'}
*/
����־����ļ�����,���β�ѯ,ִֻ����һ��sql,�����SqlSession����Ļ��档
����һ������Ҳ��ʧЧ,�������
- ��ͬ��SqlSession��Ӧ��ͬ��һ������(������һ���Ự)
- ͬһ��SqlSession���Dz�ѯ������ͬ (������ƥ��)
- ͬһ��SqlSession���β�ѯ�ڼ�ִ�����κ�һ����ɾ�IJ��� (���ݿ���ܷ����仰)
- ͬһ��SqlSession���β�ѯ�ڼ��ֶ�����˻���
2.2 MyBatis�Ķ�������
����������SqlSessionFactory����,ͨ��ͬһ��SqlSessionFactory������SqlSession��ѯ�Ľ���ᱻ ����;�˺����ٴ�ִ����ͬ�IJ�ѯ���,����ͻ�ӻ����л�ȡ��
������������:
-
�ں��������ļ���,����ȫ����������cacheEnabled=��true��,Ĭ��Ϊtrue,����Ҫ����
-
��ӳ���ļ������ñ�ǩ
<mapper namespace="com.shang.mybatis.mappers.DynamicMapper"> <cache ></cache> <select id="getEmpByWhere" resultType="employees"> select * from employees <where> <if test="employee_id != '' and employee_id != null"> and employee_id = #{employee_id} </if> <if test="email != '' and email != null"> and email = #{email} </if> </where> </select> </mapper> -
�������������SqlSession�رջ��ύ֮����Ч
sqlSession1.close(); //�رմ˴λỰ -
��ѯ��������ת����ʵ�������ͱ���ʵ�����л��Ľӿ�
public class Employees implements Serializable
@Test
public void testCache() {
try {
InputStream is = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory build1 = new SqlSessionFactoryBuilder().build(is);
SqlSession sqlSession1 = build1.openSession(true);
DynamicMapper mapper = sqlSession1.getMapper(DynamicMapper.class);
Employees employees = new Employees();
employees.setEmployee_id(300);
employees.setEmail("sakha");
List<Employees> empByWhere = mapper.getEmpByWhere(employees);
empByWhere.forEach(list -> System.out.println(list));
sqlSession1.close(); //�رմ˴λỰ
SqlSession sqlSession2 = build1.openSession(true);
DynamicMapper mapper1 = sqlSession2.getMapper(DynamicMapper.class);
Employees employees1 = new Employees();
employees1.setEmployee_id(300);
employees1.setEmail("sakha");
List<Employees> empByWhere1 = mapper1.getEmpByWhere(employees);
empByWhere1.forEach(list -> System.out.println(list));
} catch (IOException e) {
e.printStackTrace();
}
}
/**
DEBUG 03-14 13:46:22,990 Cache Hit Ratio [com.shang.mybatis.mappers.DynamicMapper]: 0.0 (LoggingCache.java:60)
DEBUG 03-14 13:46:23,185 ==> Preparing: select * from employees WHERE employee_id = ? and email = ? (BaseJdbcLogger.java:137)
DEBUG 03-14 13:46:23,207 ==> Parameters: 300(Integer), sakha(String) (BaseJdbcLogger.java:137)
DEBUG 03-14 13:46:23,228 <== Total: 1 (BaseJdbcLogger.java:137)
Employees{employee_id=300, first_name='ww', last_name='hh', email='sakha'}
WARN 03-14 13:46:23,239 As you are using functionality that deserializes object streams, it is recommended to define the JEP-290 serial filter. Please refer to https://docs.oracle.com/pls/topic/lookup?ctx=javase15&id=GUID-8296D8E8-2B93-4B9A-856E-0A65AF9B8C66 (SerialFilterChecker.java:46)
DEBUG 03-14 13:46:23,252 Cache Hit Ratio [com.shang.mybatis.mappers.DynamicMapper]: 0.5 (LoggingCache.java:60)
Employees{employee_id=300, first_name='ww', last_name='hh', email='sakha'}
*/
��������Կ���,һ�λỰ�ر�,�����ڶ����Ự,����Ҫִ��sql��ѯ���,ֱ�ӴӶ��������п����õ���
ʹ��������ʧЧ�����:
���β�ѯ֮��ִ�����������ɾ��,��ʹһ���Ͷ�������ͬʱʧЧ
2.3 ����������������
��mapper�����ļ������ӵ�cache��ǩ��������һЩ����:
-
eviction����:������ղ��� :
-
LRU(Least Recently Used) �C �������ʹ�õ�:�Ƴ��ʱ�䲻��ʹ�õĶ���
-
FIFO(First in First out) �C �Ƚ��ȳ�:��������뻺���˳�����Ƴ����ǡ�
-
SOFT �C ������:�Ƴ���������������״̬�������ù���Ķ���
-
WEAK �C ������:���������Ƴ����������ռ���״̬�������ù���Ķ��� Ĭ�ϵ��� LRU��
-
-
flushInterval����:ˢ�¼��,��λ����
Ĭ������Dz�����,Ҳ����û��ˢ�¼��,��������������ʱˢ��
-
size����:������Ŀ,������
�������������Դ洢���ٸ�����,̫���������ڴ����
-
readOnly����:ֻ��,true/false true:
- ֻ������;������е����߷��ػ���������ͬʵ���������Щ�����ܱ��ġ����ṩ�� ����Ҫ���������ơ�
- false:��д����;�᷵�ػ������Ŀ���(ͨ�����л�)�������һЩ,���ǰ�ȫ,���Ĭ���� false��
2.4 MyBatis�����ѯ��˳��
�Ȳ�ѯ��������,��Ϊ���������п��ܻ������������Ѿ������������,��������ֱ��ʹ�á������������û������,�ٲ�ѯһ������ ,���һ������Ҳû������,���ѯ���ݿ� ��SqlSession�ر�֮��,һ�������е����ݻ�д���������
2.5 ���ϵ���������EHCache
2.5.1 ����
<!-- Mybatis EHCache���ϰ� -->
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.1</version>
</dependency>
<!-- slf4j��־�����һ������ʵ�� -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
| jar������ | ���� |
|---|---|
| mybatis-ehcache | mybatis-ehcache |
| ehcache | EHCache���� |
| slf4j-api | SLF4J��־����� |
| logback-classic | ֧��SLF4J����ӿڵ�һ������ʵ�� |
2.5.2 ���
��resourceĿ¼������EHCache�������ļ�ehcache.xml
<?xml version="1.0" encoding="utf-8" ?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="../config/ehcache.xsd">
<!-- ���̱���·�� -->
<diskStore path="D:\ehcache"/>
<defaultCache
maxElementsInMemory="1000"
maxElementsOnDisk="10000000"
eternal="false"
overflowToDisk="true"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU">
</defaultCache>
</ehcache>
����SLF4Jʱ,��Ϊ������־��log4j��ʧЧ,��ʱ������Ҫ����SLF4J�ľ���ʵ��logback����ӡ��־��
����logback�������ļ�logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration debug="true">
<!-- ָ����־�����λ�� -->
<appender name="STDOUT"
class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!-- ��־����ĸ�ʽ -->
<!-- ����˳��ֱ���:ʱ�䡢��־�����߳����ơ���ӡ��־���ࡢ��־�������ݡ����� -
->
<pattern>[%d{HH:mm:ss.SSS}] [%-5level] [%thread] [%logger]
[%msg]%n</pattern>
</encoder>
</appender>
<!-- ����ȫ����־������־����˳��ֱ���:DEBUG��INFO��WARN��ERROR -->
<!-- ָ���κ�һ����־����ֻ��ӡ��ǰ����ͺ��漶�����־�� -->
<root level="DEBUG">
<!-- ָ����ӡ��־��appender,����ͨ����STDOUT��������ǰ�����õ�appender -->
<appender-ref ref="STDOUT" />
</root>
<!-- ������������ָ���ֲ���־���� -->
<logger name="com.atguigu.crowd.mapper" level="DEBUG"/>
</configuration>
2.5.3 ���ö������������
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
2.5.3 ����:EHCache�����ļ�˵��
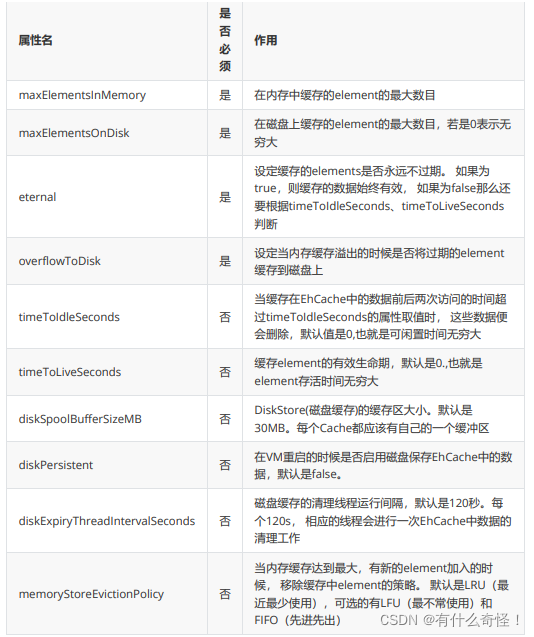
3. MyBatis������(NB)
- ����:�ȴ���Javaʵ����,�ɿ�ܸ������ʵ�����������ݿ����Hibernate��֧������ �ġ�
- ����:�ȴ������ݿ��,�ɿ�ܸ���������ݿ��,��������������Դ:
- Javaʵ����
- Mapper�ӿ�
- Mapperӳ���ļ�
3.1 ��������
3.1.1 ���������Ͳ��
<!-- ����MyBatis���� -->
<dependencies>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
</dependencies>
<!-- ����Maven�ڹ���������������� -->
<build>
<!-- �����������õ��IJ�� -->
<plugins>
<!-- ������,���̵IJ������Թ��������в����ʽ���ֵ� -->
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.0</version>
<!-- ��������� -->
<dependencies>
<!-- ���̵ĺ������� -->
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.2</version>
</dependency>
<!-- ���ݿ����ӳ� -->
<dependency>
<groupId>com.mchange</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.2</version>
</dependency>
<!-- MySQL���� -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.8</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
3.1.2 ����MyBatis�ĺ��������ļ�
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--�����������ݿ�Ļ���-->
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<!--����ӳ���ļ�-->
<mappers>
<mapper resource="org/mybatis/example/BlogMapper.xml"/>
</mappers>
</configuration>
3.1.3 �������̵������ļ�
�ļ���������:generatorConfig.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!--
targetRuntime: ִ�����ɵ����̵İ汾
MyBatis3Simple: ���ɻ�����CRUD(���¼���)
MyBatis3: ���ɴ�������CRUD(�ݻ�������)
-->
<context id="DB2Tables" targetRuntime="MyBatis3Simple">
<!-- ���ݿ��������Ϣ -->
<jdbcConnection driverClass="com.mysql.jdbc.Driver"
connectionURL="jdbc:mysql://localhost:3306/mybatis"
userId="root"
password="123456">
</jdbcConnection>
<!-- javaBean�����ɲ���-->
<javaModelGenerator targetPackage="com.atguigu.mybatis.bean"
targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
<property name="trimStrings" value="true" />
</javaModelGenerator>
<!-- SQLӳ���ļ������ɲ��� -->
<sqlMapGenerator targetPackage="com.atguigu.mybatis.mapper"
targetProject=".\src\main\resources">
<property name="enableSubPackages" value="true" />
</sqlMapGenerator>
<!-- Mapper�ӿڵ����ɲ��� -->
<javaClientGenerator type="XMLMAPPER"
targetPackage="com.atguigu.mybatis.mapper" targetProject=".\src\main\java">
<property name="enableSubPackages" value="true" />
</javaClientGenerator>
<!-- ��������ı� -->
<!-- tableName����Ϊ*��,���Զ�Ӧ���б�,��ʱ��дdomainObjectName -->
<!-- domainObjectName����ָ�����ɳ�����ʵ��������� -->
<table tableName="t_emp" domainObjectName="Emp"/>
<table tableName="t_dept" domainObjectName="Dept"/>
</context>
</generatorConfiguration>
3.1.4 ִ��MBG�����generateĿ��
maven���ߵ��
2.QBC��ѯ
@Test
public void testMBG() throws IOException {
InputStream is = Resources.getResourceAsStream("mybatis-config.xml");
SqlSession sqlSession = new
SqlSessionFactoryBuilder().build(is).openSession(true);
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
EmpExample empExample = new EmpExample();
//������������,ͨ��andXXX����ΪSQL���Ӳ�ѯ����,ÿ������֮����and��ϵ
empExample.createCriteria().andEnameLike("a").andAgeGreaterThan(20).andDidIsNot
Null();
//��֮ǰ���ӵ�����ͨ��orƴ����������
empExample.or().andSexEqualTo("��");
List<Emp> list = mapper.selectByExample(empExample);
for (Emp emp : list) {
System.out.println(emp);
}
}
4.��ҳ���
4.1 ����
4.1.1 ����
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>5.2.0</version>
</dependency>
4.1.2 ���÷�ҳ���
��MyBatis�ĺ��������ļ������ò��
<plugins>
<!--���÷�ҳ���-->
<plugin interceptor="com.github.pagehelper.PageInterceptor"></plugin>
</plugins>
4.2 ʹ��
- �ڲ�ѯ����֮ǰʹ��PageHelper.startPage(int pageNum, int pageSize)������ҳ����
pageNum:��ǰҳ��ҳ�� pageSize:ÿҳ��ʾ������
- �ڲ�ѯ��ȡlist����֮��,ʹ��PageInfo pageInfo = new PageInfo<>(List list, int navigatePages)��ȡ��ҳ�������
list:��ҳ֮������� navigatePages:������ҳ��ҳ����
- ��ҳ�������
PageInfo{
pageNum=8, pageSize=4, size=2, startRow=29, endRow=30, total=30, pages=8,
list=Page{count=true, pageNum=8, pageSize=4, startRow=28, endRow=32, total=30,
pages=8, reasonable=false, pageSizeZero=false},
prePage=7, nextPage=0, isFirstPage=false, isLastPage=true, hasPreviousPage=true,
hasNextPage=false, navigatePages=5, navigateFirstPage4, navigateLastPage8,
navigatepageNums=[4, 5, 6, 7, 8]
}
pageNum:��ǰҳ��ҳ��
pageSize:ÿҳ��ʾ������
size:��ǰҳ��ʾ����ʵ����
total:�ܼ�¼��
pages:��ҳ��
prePage:��һҳ��ҳ��
nextPage:��һҳ��ҳ��
isFirstPage/isLastPage:�Ƿ�Ϊ��һҳ/���һҳ
hasPreviousPage/hasNextPage:�Ƿ������һҳ/��һҳ
navigatePages:������ҳ��ҳ����
navigatepageNums:������ҳ��ҳ��,[1,2,3,4,5]
@Test
public void test(){
try {
InputStream is = Resources.getResourceAsStream("mybatis-config.xml");
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(is);
SqlSession sqlSession = sqlSessionFactory.openSession();
EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);
System.out.println("\n��ѯ����ǰ������ҳ");
PageHelper.startPage(2, 4);
List<Emp> emps = mapper.selectByExample(null);
emps.forEach(emp -> System.out.println(emp));
System.out.println("\n");
PageInfo<Emp> pages = new PageInfo<>(emps, 5);
System.out.println("PageInfo----->"+pages);
} catch (IOException e) {
e.printStackTrace();
}
}