һ��һ��һ
һ�ű���һ����¼һ��ֻ��������һ�ű���һ����¼���ж�Ӧ,��֮��Ȼ��
��ʱ��,Ϊ��ҵ��,���߱���һ�ű�������������,������,�ڿ����л����һ��һ��ʽ����Ʊ���

���� һ�Զ�(1��������(idΪ�����ֶ�), �������ֶ�)
һ��ʵ���ij������������һ��ʵ��Ķ�������й�����ϵ, һ�Զ�Ĺ�ϵ����Ƶ�ʱ��,��Ҫ��Ʊ��������
2.1. �༶����ѧ�������

���ű���Ա�������

image.png
2.2.�������ݿ��
constraint Լ��
foreign key���DZ����֮���ij��Լ���Ĺ�ϵ,�������ֹ�ϵ�Ĵ���,�ܹ��ñ����֮�������,���ӵ�����,�����Ը�ǿ��
foreign key����ʽ��:FOREIGN KEY(Sno) REFERENCES Student(Sno)
ע��:���������������һ�ű�������
//�����༶��
create table class(id int primary key auto_increment,name varchar(20));
//����ѧ����
create table student(id int primary key auto_increment,name varchar(20),sex varchar(20),class_id int,constraint foreign key(class_id) references class(id));
//����༶����
insert into class values(1,'ceshiban');
insert into class values(2,'kaifa');
//����ѧ������
insert into student values(1,'zhangsan','nan',1);
insert into student values(2,'lisi','nan',2);
insert into student values(3,'jingjing','nan',2);
//����
select * from student where class_id=(select id from class where id=2);��һ�������ע��(Ĭ����Լ��): ɾ��������Ϣʱ,���������ֶ�ֵ��������д���ʱ,�ü�¼�Dz���ɾ���ġ�---Ҫ��������ǵ������Ϣɾ��֮��,����ɾ����
�Ӳ�ѯ:Ƕ����������ѯ�еIJ�ѯ��
4.3����Զ�( 3����= 2��ʵ��� + 1����ϵ�� )
һ��ʵ������ݶ�Ӧ����һ��ʵ��Ķ������,����ʵ�������Ҳͬ����Ӧ��ǰʵ��Ķ�����ݡ�
һ��ѧ�������ж����ʦ,һ����ʦ���Խ̶��ѧ��
�������:����һ���м��,ר������ά�����֮��Ķ�Ӧ��ϵ,ͨ�����ܹ�Ψһ��ʶ�����ݵ��ֶ�(����)
create table teacher(id int primary key,name varchar(100));
create table student (id int primary key,name varchar(100));
create table teacher_student(teacher_id int,student_id int,constraint foreign key(teacher_id) references teacher(id),constraint foreign key(student_id) references student(id));
insert into teacher values(1,'����ʦ');
insert into teacher values(2,'����ʦ');
insert into student values(1,��������);
insert into student values(2,�����ġ�);
insert into teacher_student values(1,1);
insert into teacher_student values(1,2);
insert into teacher_student values(2,1);
insert into teacher_student values(2,2);
//��ѯ����ʦ���̵�ѧ��
select id from teacher where name=������ʦ��
select student_id from teacher_student where teacher_id=id
select * from student where id in(select student_id from teacher_student where teacher_id =(select id from teacher where name='����ʦ'));
//��ѯ������������ʦ
select * from teacher where id in(select teacher_id from teacher_student where student_id=(select id from student where name='����'));�塢 ������ѯ
����:�����ӡ������ӡ���������
5.1. ��ʼ������ṹ
create table customer(id int primary key auto_increment,name varchar(20),city varchar(20));
create table orders(id int primary key auto_increment,good_name varchar(20),price float(8,2),customer_id int);
insert into customer (name,city) values('����ʦ','����');
insert into customer (name,city) values('����ʦ','ɽ��');
insert into customer (name,city) values('����ʦ','����');
insert into customer (name,city) values('����ʦ','���');
insert into orders(good_name,price,customer_id) values('����',59,1);
insert into orders(good_name,price,customer_id) values('�ʼDZ�',88,2);
insert into orders(good_name,price,customer_id) values('�����',99,1);
insert into orders(good_name,price,customer_id) values('��ˮ',300,3);
insert into orders(good_name,price,customer_id) values('ţ��',100,6);5.2.�����ѯ
�����ѯ,�ֽеѿ�������ѯ,�Ὣ������ұ�����Ϣ,��һ���˻���������Ϣ��ѯ����,�������ʱ��,�Ƚ�ռ���ڴ�,���ɵļ�¼��=��1 X��2

5.3. �����Ӳ�ѯ
������,inner join on ��ѯ���ű�,�趨����,�����ű��ж�Ӧ�����ݲ�ѯ����
��������ѿ�����,���������ʱ��,���ܸ�

5.4. ��������
��������? left join on �趨����,�����ű���Ӧ�����ݲ�ѯ����,ͬʱ������Լ�û�й���������Ҳ��ѯ����
ע��:joinǰ������,��������

5.5. ��������
�������� right join? on �趨����,�����ű���Ӧ�����ݲ�ѯ����,ͬʱ���ұ��Լ�û�й������������ݲ�ѯ����

5.6. ���ϲ�ѯ

����MySQLͼ�λ�����navicat
6.1.? Navicat���
Navicat��һ�������MySQL���ݿ�����Ϳ������ߡ�����SQLServer�Ĺ���������,����ѧ���á�Navicatʹ��ͼ�λ����û�����,�������û�ʹ�ú�����Ϊ����,ͬʱ֧�����ġ�
????2. ��װ����:
�����ƽ��Navicat for MySQ�����ƽ��
����:https://pan.baidu.com/s/1YK9U9opCUt1TthZvYxKBhg
��ȡ��:mjw1
��ѹ���غ���ļ�������.exe�ļ�,��navicat111_mysql_cs_x64.exe ���а�װ
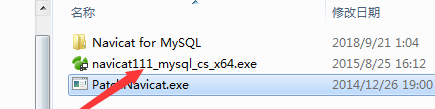
��װ���֮���PatchNavicat.exeѡ��װNavicat for MySQLĿ¼�µ�navicat.exe
���� ��ͼ�ƽ�ɹ�
????6.2 SQLyog
SQLyog���İ���һ��רҵ��ͼ�ι�������,SQLyog������,����ǿ��,�ܹ������û����ɹ����Լ���MYSQL���ݿ�,SQLyog���İ�֧�ֶ������ݸ�ʽ����,���Կ��ٰ����û����ݺͻָ�����,���ܹ����ٵ�����SQL�ű��ļ�,Ϊ�û���ʹ���ṩ��ݡ�����
3. MySQL Workbench
MySQL Workbench��һ��רΪMySQL��Ƶ�ER/���ݿ⽨ģ���ߡ��������������ݿ���ƹ���DBDesigner4�ļ����ߡ�������MySQL Workbench��ƺʹ����µ����ݿ�ͼʾ,�������ݿ��ĵ�,�Լ����и��ӵ�MySQL Ǩ�ơ�MySQL Workbench����һ���Ŀ��ӻ����ݿ���ơ������Ĺ���,��ͬʱ�п�Դ����ҵ���������汾��ͬʱ֧��Windows��Linuxϵͳ������
4. MySQL GUI Tools
MySQL GUI Tools��һ�����ӻ������MySQL���ݿ��������̨,�ṩ���ĸ��dz����õ�ͼ�λ�Ӧ�ó���,�������ݿ���������ݲ�ѯ��MySQL GUI Tools���Լ����������ݿ���������ݡ�Ǩ�ƺͲ�ѯЧ��,��ʹû�зḻ��SQL���Ի������û�Ҳ����Ӧ�����硣���ͼ�λ������������������ƵĹ��������ˡ�
5. MySQL Connector/ODBC
MySQL Connector/ODBC ��ʱҲ���Խ���MyODBC,�û�����ͨ��ODBC (Open Database Connectivity,�������ݿ⻥��)���ݿ�����Mysql�ķ�����������˵����ʹ��Windows����Unixƽ̨�е�Ӧ�ó���,������ Access��Excel��Borland��Delphiȥ�������ݿ��������MySQL Connector/ODBC ��MySQL�ٷ��ṩ��,ϵͳ��װ���������֮��,�Ϳ���ͨ��ODBC������MySQL,�����Ϳ���ʵ��SQLServer��Access��MySQL֮�������ת��,������֧��ASP����MySQL���ݿ⡣����
6. phpMyAdmin
phpMyAdmin����õ�MySQLά������,��һ����PHP�����Ļ���Web��ʽ�ܹ�����վ�����ϵ�MySQL��������,֧������,�������ݿ�dz����㡣��windows��PHP���������ı��䡣����֮�����ڶԴ����ݿ�ı��ݺͻָ���̫���㡣����
7. MySQLDumper
MySQLDumperʹ��PHP������MySQL���ݿⱸ�ݻָ�����,�����ʹ��PHP���д����ݿⱸ�ݺͻָ�������,���������ݿⶼ���Է���ı��ݻָ�,���õ�������̫�������м��жϵ�����,�dz��������á���������ǵ¹��˿�����,��û����������������
6.3. Navicat����ʹ�ò���
6.3.1. ����,mysql,�����û���,����
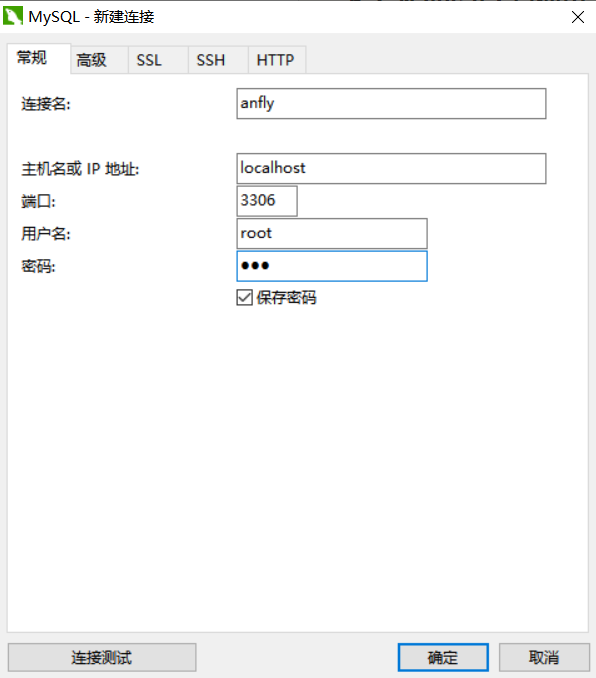
6.3.2.�½���,������Ҽ�
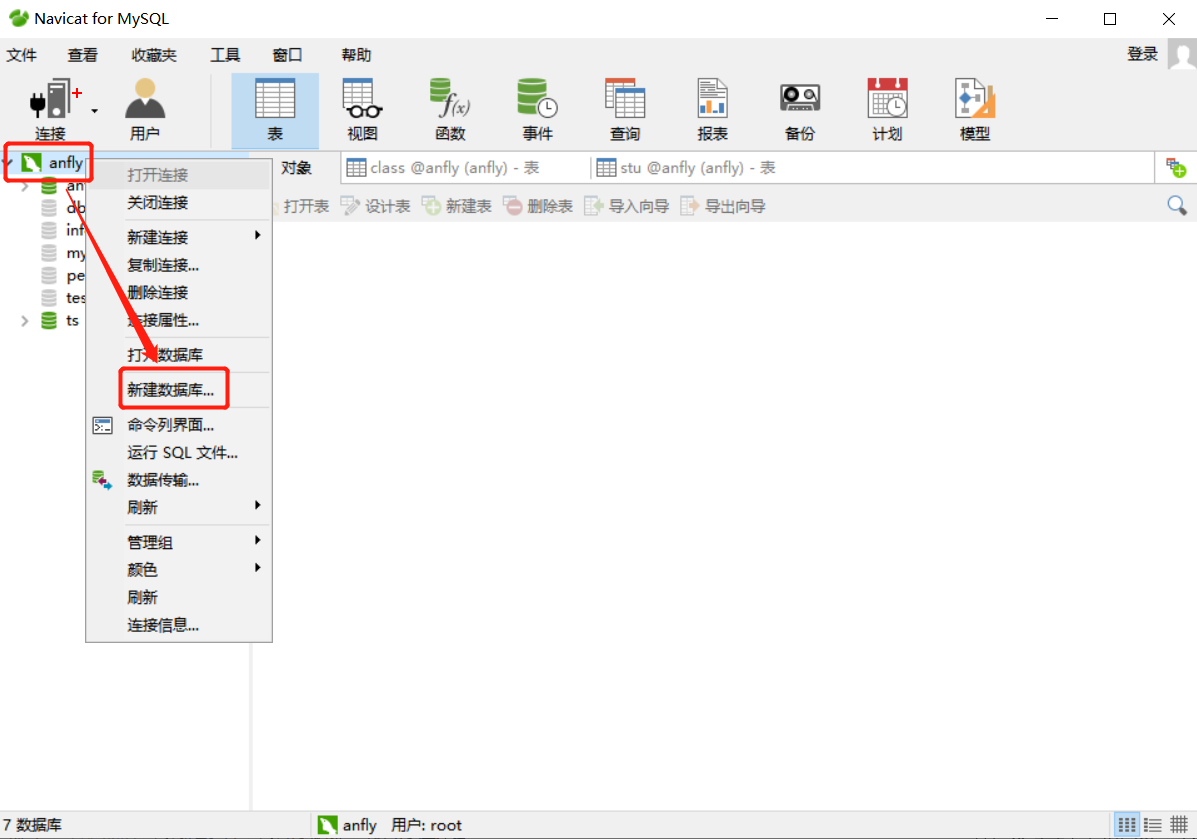
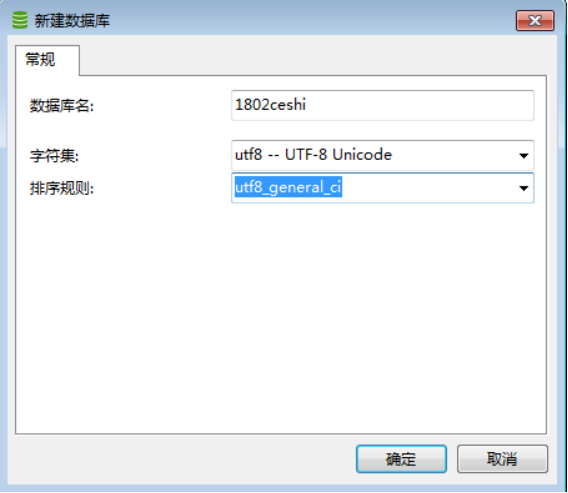
6.3.3.�½���
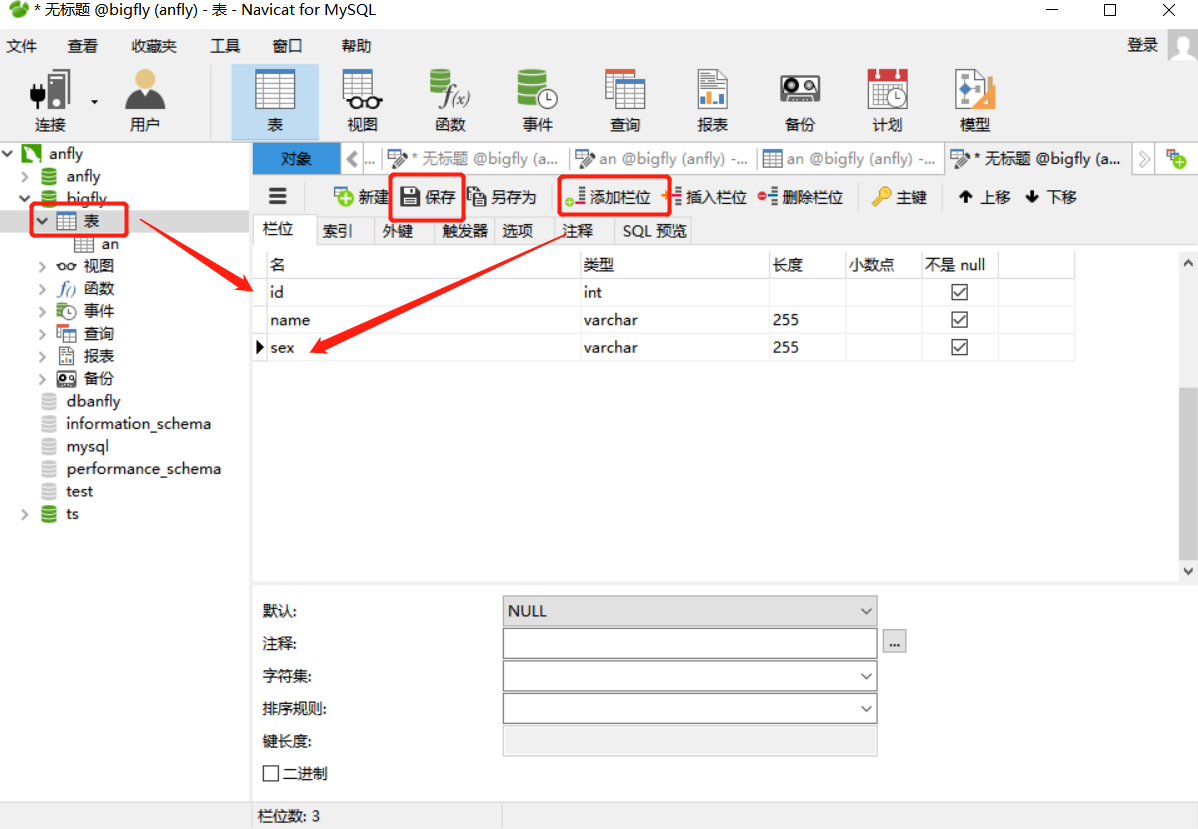
�ߡ����ݿⱸ����ָ�
1. ʹ��ͼ�ν��湤��:
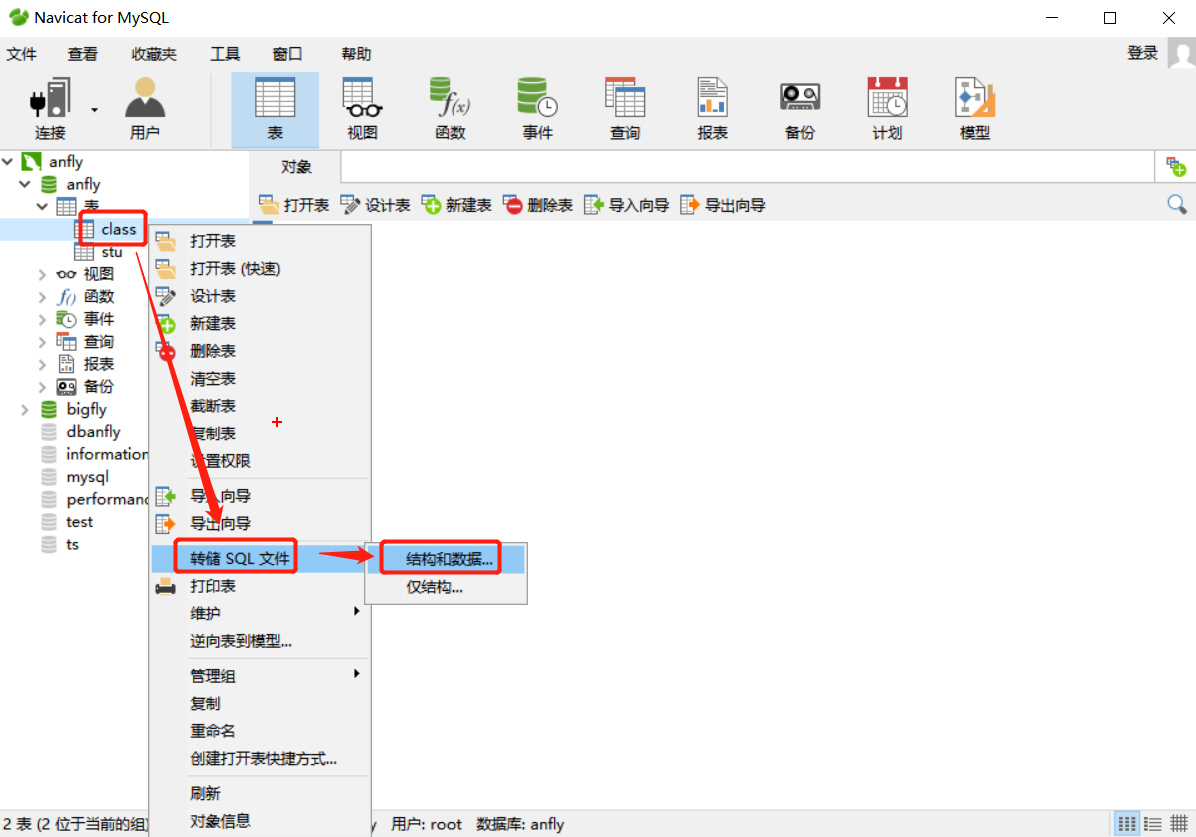
2. ʹ��doc����:
mysqldump �Cu�û��� �Cp���� ���ݿ���>���ɵĽű��ļ�·��
ע��,��Ҫ��ֺ�,��Ҫ��¼mysql,ֱ����cmd������
ע��,���ɵĽű��ļ��в�����create database���
mysqldump -uroot -proot host>C:\Users\Administrator\Deskt
op\mysql\1.sql

3. ����SQL�ļ�

�����ļ�
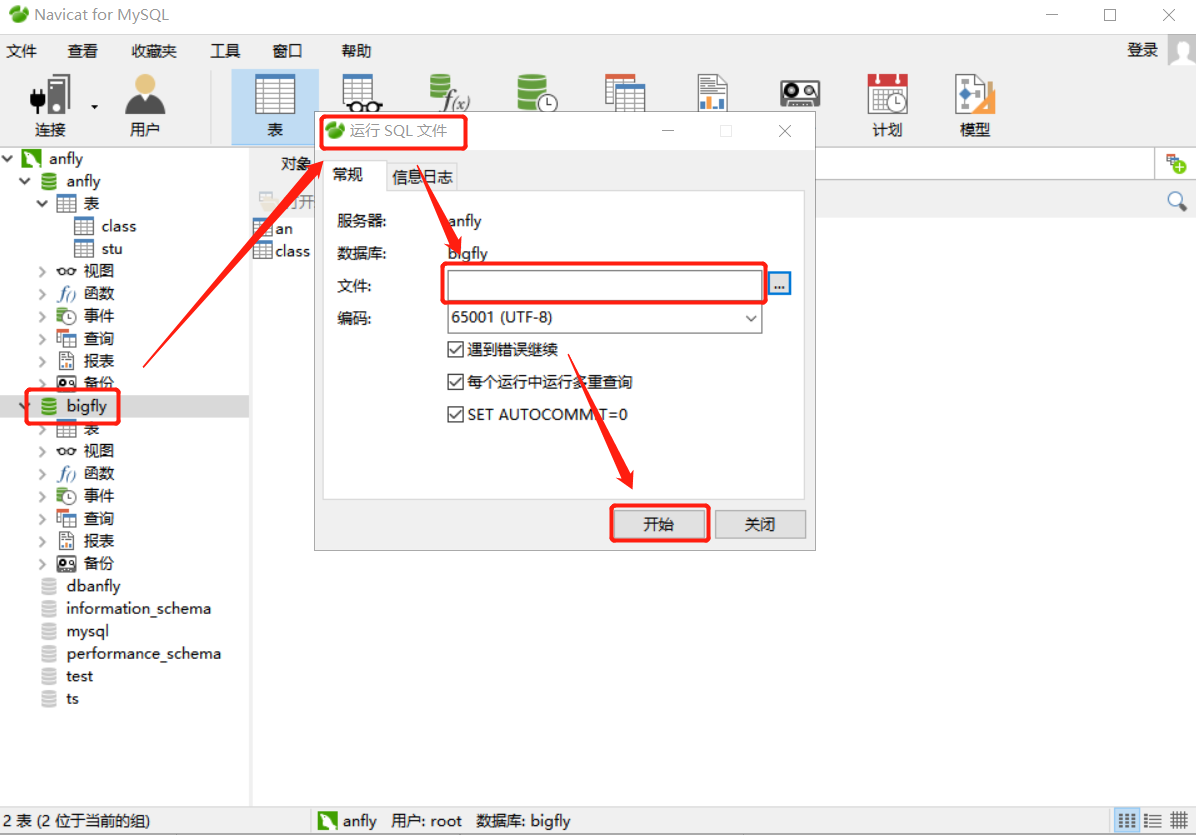
ˢ�¼���,F5ˢ��
4.�ָ�
a)ʹ��ͼ�ν��湤��:
b)ʹ��doc������:
i.����¼�ָ�
mysql -u�û��� -p���� ���ݿ�<�ű��ļ�·��
ע��,��Ҫ��ֺ�,��Ҫ��¼mysql,ֱ����cmd������

ii.��¼֮��ָ�
ѡ��� use ������
Source sql�ļ�·��

�ˡ����ݿⳣ�������Ż�(�˽�)
���ݿ������Ż����,���ǿ��DZȽ϶�Ļ��Dz�ѯ���,��������Ŀ�����ݲ�ѯ�dz�Ƶ��,��Ч��,����Ҫ��Ƚϸߡ�
��ѯ����Ż��Ļ�,��Ҫ����Ҫʹ���������ַ�ʽ,��ν�������ǽ���һ�ֿ��ٲ��ҵķ�ʽ,�������Dz��ֵ�,��һ��ABCD������.
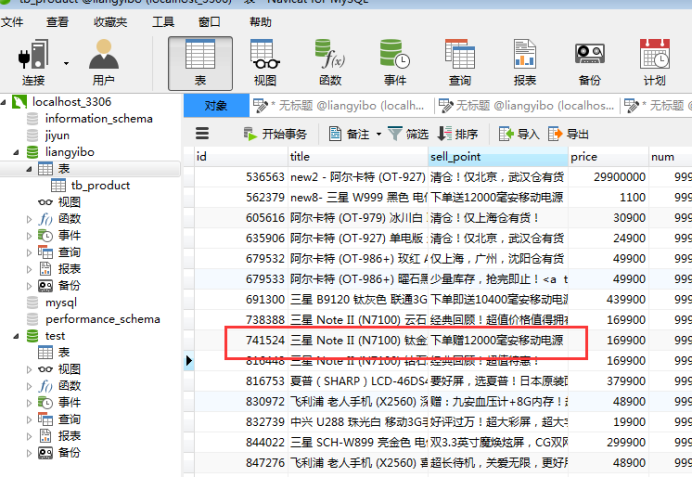
�ٸ�����,������Ǵ���һ����create table user(id integer ,name varchar(20),job varchar(20));����������ݿ�����1000��������,���Ҳ�ѯselect * from user where name=����������ʱ��,���ֲ�ѯ��ʽ���������������ݿ��ɨ��,Ч�ʷdz��͡�
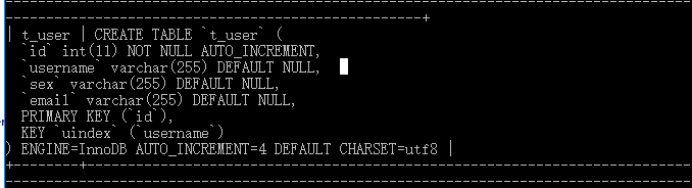
���ǿ��Ը����name����һ������create index n on user (name);��������һ����ͨ(normal)����,Ȼ�����Dz�ѯ��ʱ��,�����������,Ч�ʾͻ�������,��Ȼ��������,���ķ�ʽ��BTree���ͺ�Hash����,�����ֹ������ݿ������ķ�ʽ,�����û�������о���������ǿ����Լ����á�Ĭ����btree��
�������͵Ļ�,��normal(��ͨ����)���͡�unique(Ψһ����)��fulltextȫ�������������������ǿ��������ۼ�������
����������,primary key �����õ�ʱ��,�Ѿ�ָ����,��ʵҲ�Ƿǿ�������
�ڷǿ�������not null,�������ַ�ʽ�ĸ��ֶ������ݲ���Ϊ��,
�۾ۼ�����(��������),�������ö����ѯ������ʱ��ʹ�á����� ����һ�ű�,������,�й���,�����뾭��Ƶ�����õ����ֺ������������һ������ѯ���ݿ��б������ݡ����ʱ��,���Խ����ֺ���ָ��Ϊ�ۼ�������create index m on user(name,job); ����������ָ��select * from user where name=xxx and job=xxx��ʱ��,�ͻᰴ��������ʽ������
�����Ż���ʽ���������Ż�,��ʹ�������Ż�������ʱ��,������Ҫע������������ֶ���ʹ�����������Ȳ�����
�˽�:
Show index form orders;�鿴����
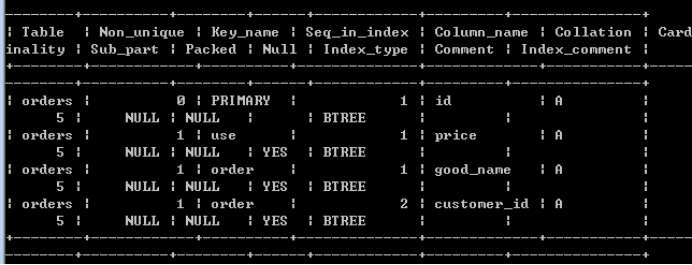
������:
ΪʲôҪ����������(�ŵ�)?
������Ϊ,�����������Դ�����ϵͳ�����ܡ�
�ٹ�����Ψһ������,���Ա�֤���ݿ����ÿһ�����ݵ�Ψһ�ԡ�
�ڿ��Դ��ӿ����ݵļ����ٶ�,��Ҳ�Ǵ�������������Ҫ��ԭ��
�ۿ��Լ��ٱ��ͱ�֮�������,�ر�����ʵ�����ݵIJο������Է����ر������塣
����ʹ�÷���������Ӿ�������ݼ���ʱ,ͬ�������������ٲ�ѯ�з���������ʱ�䡣
��ͨ��ʹ������,�����ڲ�ѯ�Ĺ�����,ʹ���Ż�������,���ϵͳ�����ܡ�
�������������IJ�������(ȱ��)
Ҳ��������Ҫ��:������������˶���ŵ�,Ϊʲô���Ա��е�ÿһ���д���һ��������?�����뷨��Ȼ���������,Ȼ��Ҳ����Ƭ���ԡ���Ȼ,�����������ŵ�,����,Ϊ���е�ÿһ���ж���������,�Ƿdz������ǵġ�������Ϊ,��������Ҳ���������һ�����档
�ٴ���������ά������Ҫ�ķ�ʱ��,����ʱ�����������������Ӷ����ӡ�
��������Ҫռ�����ռ�,�������ݱ�ռ���ݿռ�֮��,ÿһ��������Ҫռһ���������ռ�,���Ҫ�����۴�����,��ô��Ҫ�Ŀռ�ͻ����
�۵��Ա��е����ݽ������ӡ�ɾ�����ĵ�ʱ��,����ҲҪ��̬��ά��,�����ͽ��������ݵ�ά���ٶȡ�
����������������
�����ǽ��������ݿ���е�ijЩ�е����档���,�ڴ���������ʱ��,Ӧ����ϸ��������Щ���Ͽ��Դ�������,����Щ���ϲ��ܴ���������
һ����˵,Ӧ������Щ���ϴ���������
���ھ�����Ҫ����������,���Լӿ��������ٶ�;
������Ϊ����������,ǿ�Ƹ��е�Ψһ�Ժ���֯�������ݵ����нṹ;
���ھ����������ӵ�����,��Щ����Ҫ��һЩ���,���Լӿ����ӵ��ٶ�;
���ھ�����Ҫ���ݷ�Χ�������������ϴ�������,��Ϊ�����Ѿ�����,��ָ���ķ�Χ��������;
�� �ھ�����Ҫ��������ϴ�������,��Ϊ�����Ѿ�����,������ѯ������������������,�ӿ������ѯʱ��;
���ھ���ʹ����WHERE�Ӿ��е������洴������,�ӿ��������ж��ٶȡ�
ͬ��,������Щ�в�Ӧ�ô���������һ����˵,��Ӧ�ô��������ĵ���Щ�о��������ص�:
�ٶ�����Щ�ڲ�ѯ�к���ʹ�û��߲ο����в�Ӧ�ô���������������Ϊ,��Ȼ��Щ�к���ʹ�õ�,�������������������,��������߲�ѯ�ٶȡ��෴,��������������,����������ϵͳ��ά���ٶȺ������˿ռ�����
�ڶ�����Щֻ�к�������ֵ����Ҳ��Ӧ������������������Ϊ,������Щ�е�ȡֵ����,�������±����Ա���,�ڲ�ѯ�Ľ����,�������������ռ�˱��������еĺܴ����,����Ҫ�ڱ��������������еı����ܴ���������,���������Լӿ�����ٶȡ�
�۶�����Щ����Ϊtext, image��bit�������͵��в�Ӧ������������������Ϊ,��Щ�е�������Ҫô�൱��,Ҫôȡֵ���١�
�ܵ�������ԶԶ���ڼ�������ʱ,��Ӧ�ô���������������Ϊ,�����ܺͼ��������ǻ���ì�ܵġ�����������ʱ,�����������,���ǻή�������ܡ�����������ʱ,�����������,���ͼ������ܡ����,��������ԶԶ���ڼ�������ʱ,��Ӧ�ô���������
�š����ݿ����ܼ�ⷽʽ(�˽�)
�����SQL��ʱ��,����һ���ʹ��explain���sql,���Ƿ�ʹ�õ�����,�����������������ʽ��ѯ[filesort(������������ʽ�ļ���,���ǽ���filesort)](�������ű��а�gender���ó�normal����,nameû���κ�����)
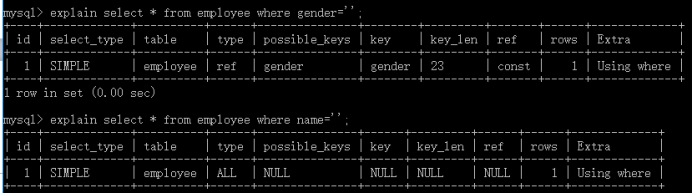
�Աȿ���,�����������ֶ�,�ڼ���ʱ��,����ʾ��һ�����õ�key��
explain select*from tb_product where title='';
������ʹ��profiling��ʽ������ݿ�ִ�еķ�ʽ,���Բ�ѯsql������ʱ�䡣http://www.jb51.net/article/31870.htm
ע��:�鿴profiling��Ϣ,show variables like '%profiling%';
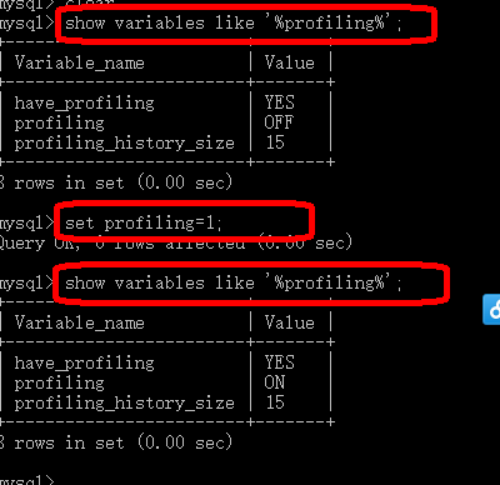
��һ��:set profiling=1;(����profiling)
�ڶ�������:select title from tb_product ;
������:�鿴����ʱ��show profiles;
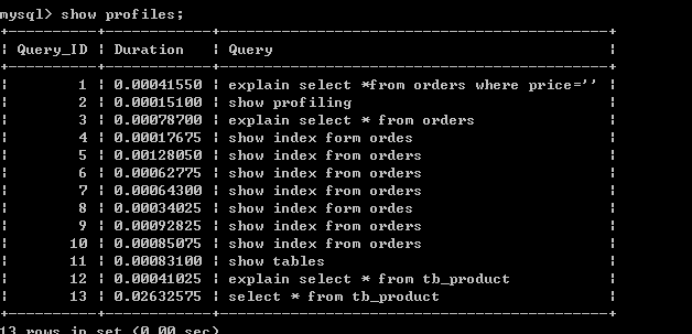
Duration:����ʱ��,�¼����ѵ�ʱ���ܼ�(�Ժ���Ϊ��λ?)
ʮ�����ݿ���ͼ
10.1 ���
��ͼ�Ǵ�һ����������(����ͼ)�����ı���
�����������ͬ,��һ����������ݿ�ֻ�����ͼ�Ķ���,���������ͼ��Ӧ������,��Щ�����Դ����ԭ���Ļ������С�
���Ի������е����ݷ����仯,����ͼ�в�ѯ��������Ҳ����֮�ı��ˡ�
����������Ͻ�,��ͼ����һ������,�������Կ������ݿ����Լ�����Ȥ�����ݼ���仯��
��ͼֻ����ѯ,���ݲ��ɸ���
10.2 ��ͼ������:
1����ͼ�����˵ײ�ı��ṹ,�������ݷ��ʲ���,�ͻ��˲�����Ҫ֪���ײ���Ľṹ����֮��Ĺ�ϵ��
2����ͼ�ṩ��һ��ͳһ�������ݵĽӿڡ�(�����������û�ͨ����ͼ�������ݵİ�ȫ����,���������û�ֱ�ӷ��ʵײ����Ȩ��)
3���Ӷ���ǿ�˰�ȫ��,ʹ�û�ֻ�ܿ�����ͼ����ʾ�����ݡ�
4����ͼ�����Ա�Ƕ��,һ����ͼ�п���Ƕ����һ����ͼ��
�ܽ�:ʹ����ͼ,��Ҫ��������Ϊһ�ű�,��������ͽ���һ��ʵ���������ͬ,
��ͼ�����������ֻ�ܽ��в鿴,������ɾ�ġ�
�����˸��ӵ�sql���,ֻ��ʾ��IJ�ѯ����