1、SQL语句的执行过程
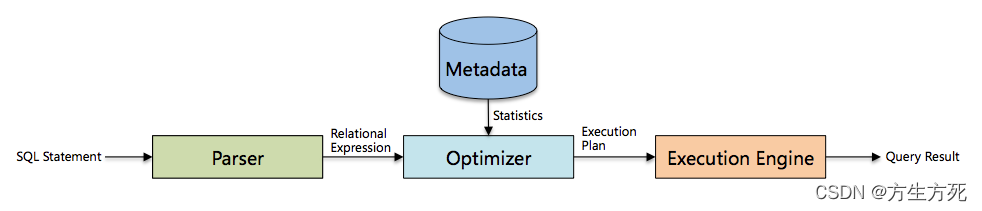
在实际的sql底层执行时:会将我们的sql语句通过解析器进行解析,判断是否有sql语法错误,语法无误则将其转换为sql查询树,通过优化器去判断是否走索引,走哪些索引比较快,最后通过我们具体的执行引擎(innodb或mysalam等)进行执行。
架构共性总结:在JVM加载类或是Mysql运行sql,首先都会去校验我们写的代码是否符合其规范,在一切符合规范的前提下,才会进行下一步的操作流程。在我们日常写代码过程中,这种先校验的方法,值得借鉴,切忌偷懒!
2、Mysql索引优化
2.1 排序在MYSQL中的优化
单路排序:所有的字段都放在sort_buffer缓存中,对sort_buffer中的数据按照指定字段进行排序;
双路排序:将主键id和排序字段放到sort_buffer中,对sort_buffer中的数据按照id和排序字段进行排序。遍历排好序的id和排序字段,按照id的值回到原表中取出所有的值返回给客户端。
区别:单路不需要回表,双路需要回表。MYSQL通过max_length_for_sort_data这个参数来控制排序,在不同场景使用不同排序,从而提高效率(一般max_length_for_sort_data<1024字节,使用单路排序)。但注意:非专业的DBA不要轻易调整,未必有MYSQL自己优化的好!
2.2 索引设计原则
1)代码先行、索引后上
并非建完表就立马建索引,一般是主体业务功能开发完,把涉及到该表相关的sql都要拿出来分析之后在建立索引。
2)联合索引尽量覆盖条件
即每一个联合索引尽量去sql语句里的where、order by、group by的字段,还要确保这些字段顺序尽量满足sql查询的最左前缀原则。
3)不要在小基数字段上建立索引
索引基数指这个字段在表里有多少个不同的值,比如一张表里有100万的数据,其中性别字段不是男就是女,那么该字段基数就是2,这种小基数建索引,还不如全表扫描来的快。
4)长字符串采用前缀索引
比如一个字段里截取前20位作为索引