数据湖-大数据生态杀青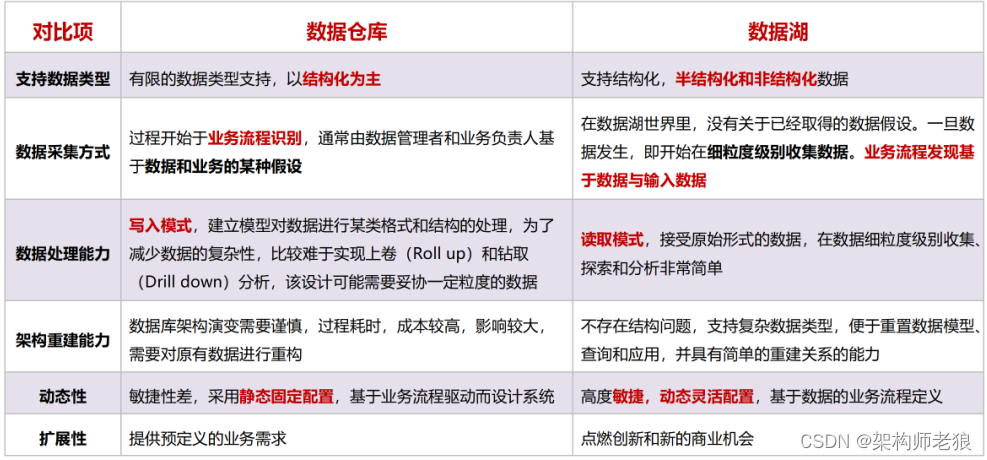
数据仓库的痛点
- 只能存储结构化数据,无法采集存储非结构化数据
- 无法存储原始数据,所有的数据须经过ETL清洗过程
- 离线数仓的数据表牵一发而动全身,数据调整工程量大
- 实时数仓存储空间有限,无法采集和存储海量实时数据
- 回溯效率低下,实时数据和离线数据计算接口难以统一
- Kafka 做实时数仓,以及日志传输。Kafka 本身存储成本很高,且数据保留时间有时效性,一旦消费积压,数据达到过期时间后,就会造成数据丢失且没有消费到
- 将实时要求不高的业务数据入湖、比如说能接受 1-10 分钟的延迟。因为 Iceberg 0.11 也支持 SQL 实时读取,而且还能保存历史数据。这样既可以减轻线上 Kafka 的压力,还能确保数据不丢失的同时也能实时读取
数据湖三剑客对比
Hudi
- Hudi:Hadoop Upserts Deletes and Incrementals(原为 Hadoop Upserts anD Incrementals),强调了其主要支持 Upserts、Deletes 和 Incremental 数据处理,其主要提供的写入工具是 Spark HudiDataSource API 和自身提供的 HoodieDeltaStreamer
- 在查询方面,Hudi 支持 Hive、Spark、Presto。
- 在性能方面,Hudi 设计了 HoodieKey ,一个类似于主键的东西。对于查询性能,一般需求是根据查询谓词生成过滤条件下推至 datasource。Hudi 这方面没怎么做工作,其性能完全基于引擎自带的谓词下推和 partition prune 功能。
Delta
- Delta定位是流批一体的 Data Lake 存储层,支持 update/delete/merge。不强调主键,因此其 update/delete/merge 的实现均是基于 spark 的 join 功能。在数据写入方面,Delta 与 Spark 是强绑定的,这一点 Hudi 是不同的:Hudi 的数据写入不绑定 Spark(可以用 Spark,也可以使用 Hudi 自己的写入工具写入)
- 在查询方面,开源 Delta 目前支持 Spark 与 Presto,但是,Spark 是不可或缺的,因为 delta log 的处理需要用到 Spark。这意味着如果要用 Presto 查询 Delta,查询时还要跑一个 Spark 作业
Iceberg
- Iceberg一个通用化设计的Table Format,高性能的分析与可靠的数据管理,Iceberg 没有类似的 HoodieKey 设计,其不强调主键。上文已经说到,没有主键,做 update/delete/merge 等操作就要通过 Join 来实现,而 Join 需要有一个 类似 SQL 的执行引擎。
- Iceberg 在查询性能方面做了大量的工作。值得一提的是它的 hidden partition 功能。Hidden partition 意思是说,对于用户输入的数据,用户可以选取其中某些列做适当的变换(Transform)形成一个新的列作为 partition 列。这个 partition 列仅仅为了将数据进行分区,并不直接体现在表的 schema 中。
总结
- Delta、Hudi、Iceberg三个开源项目中,Delta和Hudi跟Spark的代码深度绑定,尤其是写入路径。这两个项目设计之初,都基本上把Spark作为他们的默认计算引擎了。而Apache Iceberg的方向非常坚定,宗旨就是要做一个通用化设计的Table Format。它完美的解耦了计算引擎和底下的存储系统,便于多样化计算引擎和文件格式,很好的完成了数据湖架构中的Table Format这一层的实现,因此也更容易 成为Table Format层的开源事实标准
- Apache Iceberg也在朝着流批一体的数据存储层发展,manifest和snapshot的设计,有效地隔离不同transaction的变更 ,非常方便批处理和增量计算。并且,Apache Flink已经是一个流批一体的计算引擎,二都可以完美匹配,合力打造流批一体的数据湖架构。
Iceberg术语
- 数据文件 ( data files )
Iceberg 表真实存储数据的文件,一般存储在data目录下,以".parquet"结尾。 - 清单文件 ( Manifest file )
每行都是每个数据文件的详细描述,包括数据文件的状态、文件路径、分区信息、列级别的统计信息(比如每列的最大最小值、空值数等)、通过该文件、可过滤掉无关数据、提高检索速度。 - 快照( Snapshot )
快照代表一张表在某个时刻的状态。每个快照版本包含某个时刻的所有数据文件列表。Data files 是存储在不同的 manifest files 里面, manifest files 是存储在一个 Manifest list 文件里面,而一个 Manifest list 文件代表一个快照。
spark + Iceberg离线数仓
-
前期准备
spark 3.0.0_scala_2.12
Iceberg 0.13.1
编译好的iceberg-spark3-runtime-0.13.1.jar拷贝到spark/jars -
DWD加载ods原始数据
>controller
val sparkConf = new SparkConf()
.set("spark.sql.catalog.hadoop_prod", "org.apache.iceberg.spark.SparkCatalog")
.set("spark.sql.catalog.hadoop_prod.type", "hadoop")
.set("spark.sql.catalog.hadoop_prod.warehouse", "hdfs://hadoop01:9820/spark/warehouse")
.set("spark.sql.catalog.catalog-name.type", "hadoop")
.set("spark.sql.catalog.catalog-name.default-namespace", "db")
.set("spark.sql.sources.partitionOverwriteMode", "dynamic")
.set("spark.sql.session.timeZone", "GMT+8")
.setMaster("local[*]")
.setAppName("dwd_app")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
DwdIcebergService.readOdsData(sparkSession)
> service
// 加载member 到dwd
def loadMember(sparkSession: SparkSession): Unit ={
sparkSession.read.json("/datasource/iceberg/member.log").drop("dn")
.withColumn("uid", col("uid").cast("int"))
.withColumn("ad_id", col("ad_id").cast("int"))
.writeTo("hadoop_prod.db.dwd_member").overwritePartitions()
}
- DWS数据宽表
def getDwsMemberData(sparkSession: SparkSession, dt: String) = {
import sparkSession.implicits._
....
val result = dwdMember.join(dwdMemberRegtype.drop("dt"), Seq("uid"), "left")
.join(dwdPcentermempaymoney.drop("dt"), Seq("uid"), "left")
.join(dwdBaseAd, Seq("ad_id", "dn"), "left")
.join(dwdBaseWebsite, Seq("siteid", "dn"), "left")
.join(dwdVipLevel, Seq("vip_id", "dn"), "left_outer")
.select("...").as[DwsMemberResult]
val resultData = result.groupByKey(item => item.uid + "_" + item.dn)
.mapGroups { case (key, iters) =>
val keys = key.split("_")
val uid = Integer.parseInt(keys(0))
val dn = keys(1)
val dwsMembers = iters.toList
val paymoney = dwsMembers.filter(_.paymoney != null)
.map(item => BigDecimal.apply(item.paymoney))
.reduceOption(_ + _)
.getOrElse(BigDecimal.apply(0.00)).toString
....
// 分区列不能为null,spark-sql内存表null为字符串
resultData.where($"dn" =!= "null").show()
resultData.where($"dn" =!= "null")
.write.format("iceberg")
.mode("overwrite").save("hadoop_prod.db.dws_member")
}
- ADS统计分析
def queryDetails(sparkSession: SparkSession, dt: String) = {
import sparkSession.implicits._
val result = DwsIcebergDao.queryDwsMemberData(sparkSession).as[QueryResult].where(s"dt='${dt}'")
result.cache()
//统计根据url统计人数 wordcount
result.mapPartitions(partition => {
partition.map(item => (item.appregurl + "_" + item.dn + "_" + item.dt, 1))
}).groupByKey(_._1)
.mapValues(item => item._2).reduceGroups(_ + _)
.map(item => {
val keys = item._1.split("_")
val appregurl = keys(0)
val dn = keys(1)
val dt = keys(2)
(appregurl, item._2, dt, dn)
}).toDF("appregurl", "num", "dt", "dn")
.writeTo("hadoop_prod.db.ads_register_appregurlnum").overwritePartitions()
// 统计各memberlevel等级 支付金额前三的用户: mysql、oracle、hive、phoenix、iceberg对where里都不支持开窗函数,spark内存函数强大
result.withColumn("rownum", row_number().over(Window.partitionBy("memberlevel").orderBy(desc("paymoney"))))
.where("rownum<4")
.orderBy("memberlevel", "rownum")
.select("...")
.writeTo("hadoop_prod.db.ads_register_top3memberpay").overwritePartitions()
}
- yarn 上测试
最后是花了 18 分钟跑完 1000 万条数据,查询表数据观察是否有数据丢失。数据没有丢失
Flink+Iceberg 流批一体架构
- 前期准备
flink 1.13.0_scala_2.12
iceberg 0.13.1
拷贝编译好的iceberg-flink-runtime-1.13-0.13.1.jar到flink/lib
启动flink集群,运行flink sql:bin/sql-client.sh embedded shell - flink cdc采集数据到kafka,流模式写入iceberg
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(6000);
...
kafakSource.setStartFromLatest();
DataStream<RowData> result = env.addSource(kafakSource).map(item -> {
....
rowData.setField(0, uid);
rowData.setField(1, courseid);
rowData.setField(2, deviceid);
rowData.setField(3, StringData.fromString(array[3].trim()));
return rowData;
});
result.print(">>>处理完数据:");
TableLoader testtopicTable = TableLoader.fromHadoopTable("hdfs://hadoop01:9820/flink/warehouse/iceberg_db/dwd_view_log");
FlinkSink.forRowData(result).tableLoader(testtopicTable).build();
env.execute();
- 批模式初始化加载数据
DataStream<RowData> batch = FlinkSource.forRowData().env(env).tableLoader(tableLoader).streaming(false).build();
- 流模式增量处理数据
DataStream<RowData> stream = FlinkSource.forRowData().env(env).tableLoader(tableLoader).streaming(true).build();
- DataStream与Table转换写入iceberg
Table table = dwsIcbergDao.queryDwsMemberData(env, tableEnv).where($("dt").isEqual(dt));
DataStream<QueryResult> queryResultDataStream = tableEnv.toAppendStream(table, QueryResult.class);
tableEnv.createTemporaryView("tmpA", queryResultDataStream);
String sql = "select *from(select uid,memberlevel,register,appregurl" +
",regsourcename,adname,sitename,vip_level,cast(paymoney as decimal(10,4)),row_number() over" +
" (partition by memberlevel order by cast(paymoney as decimal(10,4)) desc) as rownum,dn,dt from tmpA where dt='" + dt + "') " +
" where rownum<4";
Table table1 = tableEnv.sqlQuery(sql);
DataStream<RowData> top3DS = tableEnv.toRetractStream(table1, RowData.class).filter(item -> item.f0).map(item -> item.f1);
String sql2 = "select appregurl,count(uid),dn,dt from tmpA where dt='" + dt + "' group by appregurl,dn,dt";
Table table2 = tableEnv.sqlQuery(sql2);
DataStream<RowData> appregurlnumDS = tableEnv.toRetractStream(table2, RowData.class).filter(item -> item.f0).map(item -> item.f1);
TableLoader top3Table = TableLoader.fromHadoopTable(warehouseDir + "/ads_register_top3memberpay");
TableLoader appregurlnumTable = TableLoader.fromHadoopTable(warehouseDir + "/ads_register_appregurlnum");
FlinkSink.forRowData(top3DS).tableLoader(top3Table).overwrite(true).build();
FlinkSink.forRowData(appregurlnumDS).tableLoader(appregurlnumTable).overwrite(true).build();
优化实践
1 小文件处理
- Iceberg 0.11 以前,通过定时触发 batch api 进行小文件合并,这样虽然能合并,但是需要维护一套 Actions 代码,而且也不是实时合并的。
Table table = findTable(options, conf);
Actions.forTable(table).rewriteDataFiles()
.targetSizeInBytes(10 * 1024) // 10KB
.execute();
Iceberg 0.11 新特性,支持了流式小文件合并。通过分区/存储桶键使用哈希混洗方式写数据、从源头直接合并文件,这样的好处在于,一个 task 会处理某个分区的数据,提交自己的 Datafile 文件,比如一个 task 只处理对应分区的数据。这样避免了多个 task 处理提交很多小文件的问题,且不需要额外的维护代码,只需在建表的时候指定属性 write.distribution-mode,该参数与其它引擎是通用的,比如 Spark 等。
CREATE TABLE city_table (
province BIGINT,
city STRING
) PARTITIONED BY (province, city) WITH (
'write.distribution-mode'='hash'
);
2 排序功能
- 在 Iceberg 0.11 之前,Flink 是不支持 Iceberg 排序功能的,所以之前只能结合 Spark 以批模式来支持排序功能,0.11 新增了排序特性的支持,Iceberg也支持flink的排序
insert into Iceberg_table select days from Kafka_tbl order by days, province_id;
- 利用 Iceberg 的排序特性,将天作为分区。按天、小时、分钟进行排序,那么 manifest 文件就会记录这个排序规则,从而在检索数据的时候,提高查询效率,既能实现 Hive 分区的检索优点,还能避免 Hive metadata 元数据过多带来的压力。
总结
- flink不支持隐藏分区,不支持创建带水位线的表
- 与 hudi 相比,缺少行级更新,只能对表的数据按分区进行 overwrite 全量覆盖
- flink近实时入湖
① Iceberg 提交 Transaction 时是以文件粒度来提交。这就没法以秒为单位提交 Transaction,否则会造成文件数量膨胀;
② 没有在线服务节点。对于实时的高吞吐低延迟写入,无法得到纯实时的响应;
③ Flink 写入以 checkpoint 为单位,物理数据写入 Iceberg 后并不能直接查询,当触发了 checkpoint 才会写 metadata 文件,这时数据由不可见变为可见。checkpoint 每次执行都会有一定时间。
2022-03-16 16:09:24,486 INFO --- [ jobmanager-future-thread-2] org.apache.flink.runtime.checkpoint.CheckpointCoordinator (line: 1250) : Completed checkpoint 60 for job c7a6d8df0b422bb4c27a35b21a9142de (9169 bytes in 5 ms).
2022-03-16 16:09:30,481 INFO --- [ Checkpoint Timer] org.apache.flink.runtime.checkpoint.CheckpointCoordinator (line: 741) : Triggering checkpoint 61 (type=CHECKPOINT) @ 1647418170480 for job c7a6d8df0b422bb4c27a35b21a9142de.
2022-03-16 16:09:30,483 INFO --- [IcebergFilesCommitter -> Sink: IcebergSink hdfs://hadoop01:9820/flink/warehouse/iceberg_db/dwd_view_log (1/1)#0] org.apache.iceberg.flink.sink.IcebergFilesCommitter (line: 162) : Start to flush snapshot state to state backend, table: hdfs://hadoop01:9820/flink/warehouse/iceberg_db/dwd_view_log, checkpointId: 61
2022-03-16 16:09:30,483 INFO --- [ jobmanager-future-thread-6] org.apache.flink.runtime.checkpoint.CheckpointCoordinator (line: 1250) : Completed checkpoint 61 for job c7a6d8df0b422bb4c27a35b21a9142de (9169 bytes in 3 ms).