一、业务背景与分表概念
1.1、业务背景
????Mysql中有一张业务表数据由于成年累月的的经累,数据量已经达到了15亿,数据大小也有150G,因数据量较大,运维对该表做了分区;业务场景使用也比较简单,读多于写,暂无性能瓶颈;线上使用了阿里云的8C/16G的RDS实例,并发能力也不错,在高峰期时CPU波动都不超过10%(配置貌似有点冗余,后面了解到是业务的连接数配置过高,而阿里云的TDS不支持调整连接数)。考虑到未来业务数据进一步的增长和目前运维的风险(DDL操作锁表、锁等待、备份时间长等)导致业务的不可控等因素,决定对该表做分片(ShardingSphere中定义为数据分片,以下也叫分表,为同一概念)。
1.2、分表概念
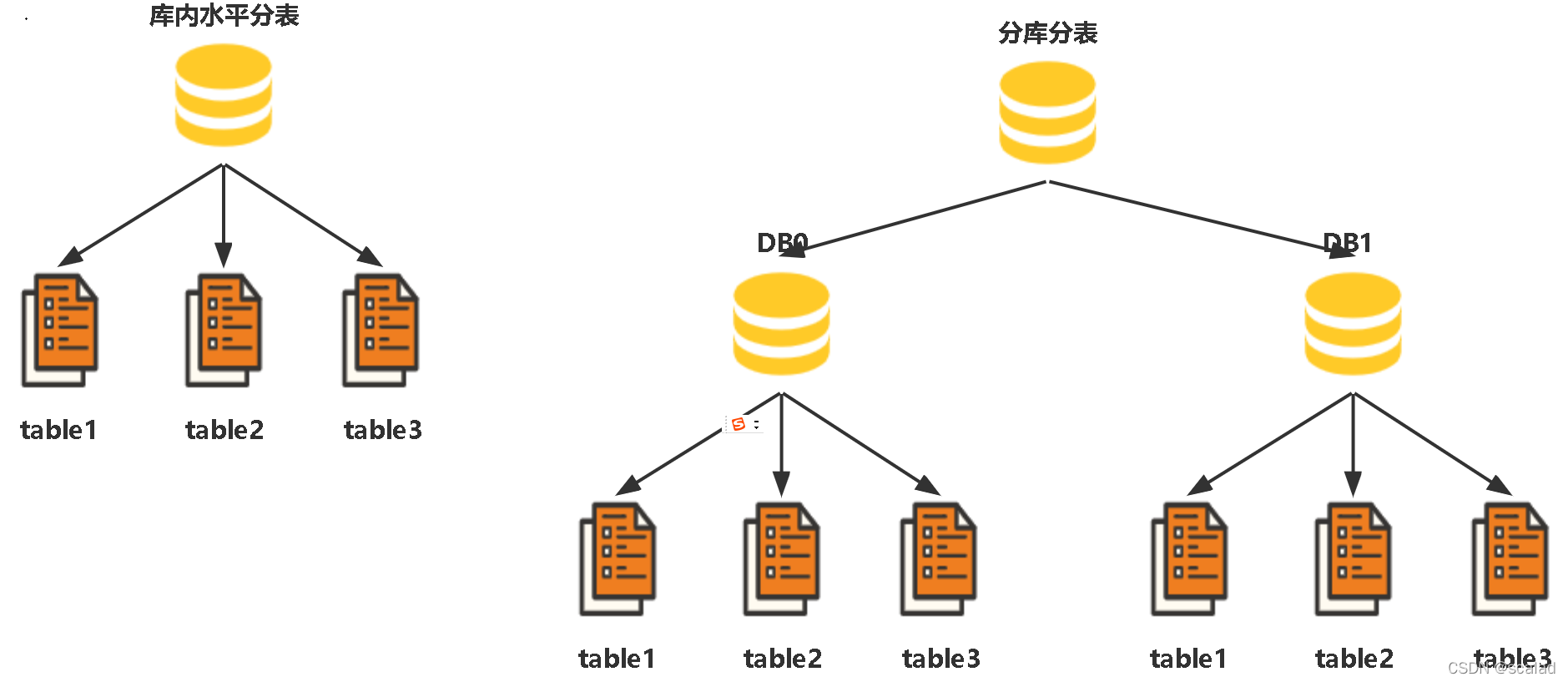
????其实分表的原理很简单,它是对数据做了水平切分,它包含分库分表和库内分表,它将一个表按不同的条件分散到多个数据库或者多个表中,每个表只包含了部分数据(但表的结构是一样的),从而使得单个表的数量变小。其实这种分的思想在大数据领域应用颇多,如分布式搜索引擎(Elasticsearch)、分布式存储(Clickhouse、HDFS)等,原理基本一致。如下图所示。从性能方面来说,由于关系型数据库大多采用B+树类型的索引,在数据量超过阈值(一般是N千万)的情况下,索引深度的增加也将使得磁盘访问的IO次数增加,进而导致查询性能的下降(这个其实需要根据自身应用来判断,如果是在索引命中率很高的点或者小范围查,像上面十几亿的表查询性能并没有太大问题)。
????与水平切分相对应的另外一种是垂直切分,包含垂直分库和垂直分表,垂直分库是根据业务模块的边界将不同的表放在不同的库中,类似于微服务架构中每个业务中独立的专库专表,垂直分表则是按数据库的列进行拆分,通过大表拆小表的方式把一些冗余、很少更新或者较大的字段拆分到扩展表中,提升读写性能。
1.3、一些问题
????从以上可以看出分库分表并不是一个技术创新,从业务逻辑上也并不是好的解决方案,因为它本身就是个与业务逻辑无关的问题,同时它对于业务层来说产生了不少弊端,如子查询支持有限、分库分表不带上分表字段,即会查询所有分表、不支持分片键like查询、分片算法的局限性(Hash算法可以较均匀的分散数据,但对于范围查询又要访问多个分片,Range算法又存在热点数据问题)、dba查询某条数据不确定在哪张表等,另外,倘若业务增速很快,原本规划的分表数量不够,这时候再增加分表是就会影响原来的分表策略,需要进行分表扩容,会涉及到数据迁移rehash的问题等。这些非业务逻辑本身的问题处理起来都比较麻烦,所以在决定做分表前我们需要综合各种因素来评估,在最后面我们会再谈下什么时候需要做分库分表。
二、环境准备
2.1、ShardingSphere
????这里简单介绍下ShardingSphere,ShardingSphere是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景,在2020成为Apache软件基金会的顶级项目,当前最新的版本是5.X(5.x 版本开始致力于可插拔架构),不过其对应的数据分片、读写分离、数据加密等基础功能在3.X和4.X版本已经相当成熟,因此本次拿了4.X的最后一个版本4.1.1进行验证。

2.2、软件版本说明
本次操作相关软件以及版本,其中Zookeeper、ShardingSphere类产品以及Canal均依赖JDK环境:
| 相关软件 | 版本 |
|---|---|
| Mysql | 5.7 |
| JDK | 1.8 |
| Zookeeper | 3.7.0 |
| Sharding-Proxy(以下简称Proxy) | 4.1.1 |
| Sharding-Scaling(以下简称Scaling) | 4.1.1(Alpha) |
| Sharding-UI | 4.1.1 |
| Canal & Canal-Adapter | 1.1.4 |
注意:ShardingSphere不同的版本间有比较大的差异,在使用时最好直接参考版本中默认的配置文件
三、Sharding-JDBC业务层
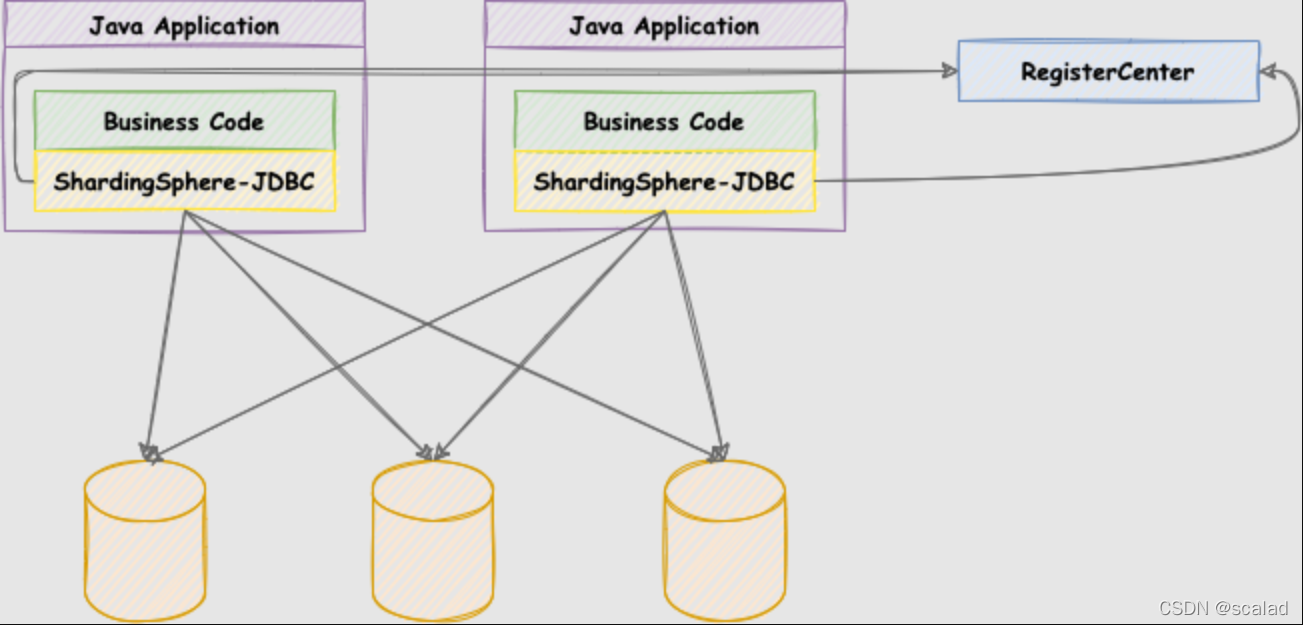
????Sharding-JDBC是ShardingSphere其中一款产品,定位为轻量级 Java 框架,用于透明的处理分库分表,而无需开发人员在业务中手动根据分片键生成SQL,它在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,它重写了JDBC规范又完全兼容JDBC规范,所以它完全兼容 JDBC 和各种 ORM 框架(这是5.0的架构图,5.0相关组件已经都更名为ShardingSphere-之类)。
3.1、准备工作
3.1.1、唯一业务ID
????在操作前,需要先确认下表中的是否有自增ID和唯一索引:
????1、如果表中使用自增ID作为业务的ID,最好先改造,虽然可以根据不同的表配置不同的自增规则,但是非常不好维护,也不利于未来比如表的再扩容。处理的方式有几种,一种是优化掉自增ID,另外也可以使用分布式主键生成策略,shardingsphere内置了uuid和snowflake两种,默认是snowflake,生成64bit整型数据;
????2、表中是否有唯一索引,一旦没有唯一索引,在做旧数据迁移过程中容易造成数据重复的风险,因此如果表中没有唯一索引的话最好先改造。
????再看下我们具体的表结构,这里做了些省略和脱敏,表中无自增ID,deviceid和name作为表的联合唯一主键,符合上述要求:
CREATE TABLE `table_name` (
`name` varchar(100) NOT NULL COMMENT '名字',
`version` varchar(100) DEFAULT NULL COMMENT '版本',
`code` bigint(10) DEFAULT NULL COMMENT '编码',
`deviceid` varchar(20) NOT NULL DEFAULT '' COMMENT '设备ID',
`update_time` datetime DEFAULT NULL '更新时间'
PRIMARY KEY (`deviceid`,`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3.1.2、分表策略
????分表策略包含分片键和分片算法:分片键是拆分的关键,比如对上面的表中按deviceid哈希取模的尾数作为该表的分片字段,要怎么去拆分需要业务方自己去梳理,除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片;分片算法是数据分片的核心配置,因为与业务紧密关联,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法,它包含了精确分片、范围分片、复合分片和Hint分片算法等,详细可参考官方文档,业务层需要根据自身SQL的特征去选择最符合的分片算法,可续并不能找到一种算法可以完全符合你所有的SQL,这种情况下可能就需要你去改你的程序逻辑。
????从SQL执行的角度看,分片算法可以看成是一种路由规则,它由路由引擎解析,并生成路由路径,把SQL路由到我们希望执行的真实的库表中,分片键结合分片算法也就形成了分片策略,目前提供了5种分片策略,包含了标准分片策略、复合分片策略、行表达式分片策略(这种策略一般用于简单的单分片,我们下面就是采用这种)、Hint分片策略和不分片策略详细可,详细可参考官方文档,最后一种不分片策略,就是假如你未给表设置分片规则,它们就会按原始的sql去执行。
3.2、项目改造
3.2.1、引入依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>4.1.1</version>
</dependency>
3.2.2、配置信息
????因为Sharding-JDBC定位为轻量级的Java框架,对应用的侵入性较小,所以在业务层改造起来比较简单,配置里面最主要的是数据源和分片规则;本次改造的项目是个较老的mvc项目,所以下面使用xml配置,SpringBoot配置参考官方文档-数据分片,考虑到当前该库暂无性能瓶颈以及未来增长不快,只做水平分表。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:sharding="http://shardingsphere.apache.org/schema/shardingsphere/sharding"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://shardingsphere.apache.org/schema/shardingsphere/sharding
http://shardingsphere.apache.org/schema/shardingsphere/sharding/sharding.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-4.0.xsd
"
default-lazy-init="false">
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="shardingDataSource" />
</bean>
<tx:annotation-driven transaction-manager="transactionManager"/>
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<property name="url" value="${spring.datasource.url}"/>
<property name="username" value="${spring.datasource.username}"/>
<property name="password" value="${spring.datasource.password}"/>
<property name="filters" value="config" />
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<!-- 数据库其他配置 -->
</bean>
<bean id="sqlSessionTemplate" class="org.mybatis.spring.SqlSessionTemplate" destroy-method="close">
<constructor-arg index="0" ref="sqlSessionFactory" />
</bean>
<!-- mybatis的SqlSessionFactoryBean用于进行数据库操作 -->
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="shardingDataSource"/>
<property name="configLocation" value="classpath:spring/mybatis-config.xml"/>
<property name="mapperLocations">
<list>
<value>classpath:com/**/dao/mapper/*.xml</value>
</list>
</property>
</bean>
<!-- 自动扫描 mybatis mapper接口 -->
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.**.dao"/>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
</bean>
<!-- 分表策略,使用行表达式对deviceid字段hash取模 -->
<sharding:inline-strategy id="tableShardingStrategy" sharding-column="deviceid"
algorithm-expression="table_name_$->{java.lang.Math.abs(deviceid.hashCode())%100}" />
<sharding:key-generator id="itemKeyGenerator" type="SNOWFLAKE" column="deviceid" />
<!-- 通过配置对象获取ShardingSphereDataSource,它实现了JDBC的标准DataSource接口,可用于原生JDBC 开发,
或使用JPA,Hibernate, MyBatis 等 ORM 类库 -->
<sharding:data-source id="shardingDataSource">
<sharding:sharding-rule data-source-names="dataSource">
<sharding:table-rules>
<sharding:table-rule logic-table="table_name"
actual-data-nodes="dataSource4.table_name_$->{0..99}"
table-strategy-ref="tableShardingStrategy" key-generator-ref="itemKeyGenerator"/>
</sharding:table-rules>
<sharding:binding-table-rules>
<sharding:binding-table-rule logic-tables="table" />
</sharding:binding-table-rules>
</sharding:sharding-rule>
</sharding:data-source>
</beans>
????从上面看业务层改造确实比较简单,如果你不需要做旧数据的迁移,到这里已经完成了。上面使用了行表达式分片策略(使用了Groovy表达式,无需用繁琐的代码来实现分片算法,是几种分片策略中最为简洁的),它根据deveiceid字段做哈希取模,分了100张表,平均下来单张表在1500W条数据,尚且在运维定义的范围内(单表小于5000W),且未来很长一段时间内单表很难达到5000W;为了方便做回滚,我们在业务代码里做了数据的双写,因为从分表库中反向同步到旧的大表库配置相对麻烦,虽然理论上可以利用阿里云DTS结合Proxy做反向同步,但如果分表数太多实际操作比较麻烦。
????大多数很多情况下,我们都是基于线上已存在业务的做优化,因为只有一些大型的应用在设计初期才考虑到了分库分表,所以我们下面讨论的是如何在不影响线上业务的情况下对数据进行平滑迁移,这里又涉及到两个场景,一是对尚未分表的单表如何平滑的实施迁移,需要做一层rehash操作;二是对已经实施了分表的系统,随着业务的增长,需要进行弹性伸缩,这个场景相对复杂,这里先不展开讨论。另外个原因,阿里云DTS不支持这种基于hash做一对多的分表的同步(可支持where表达式的数据同步,如果你是根据特定字段做的分表,你可以直接使用DTS实现同步,但需要配置多个任务),所以下面我们得自己实现这个过程。这部分内容在第五部分――在线数据同步方案
四、Sharding-Proxy代理层
4.1、Sharding-Proxy介绍
????我们先来看下Sharding-Proxy,它是ShardingSphere 的第二个产品,我们下边介绍的数据迁移都需要借助它来实现。 Proxy定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL(兼容 openGauss 等基于 PostgreSQL 的数据库)版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好,类似于其他一些开源的数据库中间件如MyCat、Atlas等,由这些中间件实现数据分片、读写分离等功能。

????如上图所示,实际上我们的应用程序不会直接接入到Porxy,其实也不建议这样做,一方面是Proxy对性能的损耗相比JDBC略高,另一方面,从运维角度上看,需要再单独维护一层Proxy服务的稳定性和可用性,是非常不可取的,看下面表格为它们的对比。JDBC 的优势在于对 Java 应用的友好度(也是其不好的方面,其他语言需要编写不同的driver),而Proxy 的优势在于对异构语言的支持、为 DBA 提供可操作入口,以及可以将数据迁移,分布式事务等纳入 Proxy 的范畴。所以我们部署Proxy只用来做旧数据迁移以及做线上实时增量同步,它也比较简单,其实就是把上面JDBC配置的规则配置到这里,由Proxy决定读写路由到哪张表。
| ShardingSphere-JDBC | ShardingSphere-Proxy | |
|---|---|---|
| 数据库 | 任意 | MySQL/PostgreSQL |
| 连接消耗数 | 高 | 低 |
| 异构语言 | 仅Java | 任意 |
| 性能 | 损耗低 | 损耗略高 |
| 无中心化 | 是 | 否 |
| 静态入口 | 无 | 有 |
4.2、部署Sharding-Proxy
4.2.1、下载安装和配置
wget https://archive.apache.org/dist/shardingsphere/4.1.1/apache-shardingsphere-4.1.1-sharding-proxy-bin.tar.gz
tar -zxvf apache-shardingsphere-4.1.1-sharding-proxy-bin.tar.gz
mv apache-shardingsphere-4.1.1-sharding-proxy-bin sharding-proxy
cd sharding-proxy
conf/server.yaml配置账号
authentication:
users:
root:
password: root
sharding:
password: sharding
authorizedSchemas: sharding_db
conf/config-sharding.yaml配置
#使用sharding-proxy登录逻辑数据库名,可以自定义
schemaName: database
dataSources:
ds_0:
url: jdbc:mysql://ip:port/database?serverTimezone=UTC&useSSL=false
username: username
password: password
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
shardingRule:
tables:
table_name:
actualDataNodes: ds_0.table_name_${0..99}
tableStrategy:
inline:
shardingColumn: machineid
algorithmExpression: table_name_${Math.abs(deviceid.hashCode())%100}
keyGenerator:
type: SNOWFLAKE
column: deviceid
bindingTables:
- table_name
defaultTableStrategy:
none:
4.2.2、 引入依赖
4.2.3、 启动并检查
./bin/start.sh
#检查日志是否正常
tail -100 ./logs/stdout.log
i.n.handler.logging.LoggingHandler - [id: 0x6a34464c] REGISTERED
i.n.handler.logging.LoggingHandler - [id: 0x6a34464c] BIND: 0.0.0.0/0.0.0.0:3307
i.n.handler.logging.LoggingHandler - [id: 0x6a34464c, L:/0.0.0.0:3307] ACTIVE
#校验客户端是否能正常连接,3307是sharding-proxy默认端口
mysql -h 127.0.0.1 -P 3307 -u root -p root
#检查数据库,结果为你配置的schemaName,然后你就可以像平常使用mysql一样操作了
mysql> show databases;
+--------------+
| Database |
+--------------+
| database |
+--------------+
假使你在这边执行了一条创建表的操作,在真实的db中就会根据你的配置创建几张表,比如我这里是${0..99},就会创建100张表
配置中注意以下几点:
1、最好在Java的启动参数中指定项目文件编码为-Dfile.encoding=UTF-8,否则在建表时如果有中文备注会出现乱码,修改/bin/start.sh文件
JAVA_MEM_OPTS=" -server -Xmx4g -Xms4g -Xmn1g -Xss512k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -Dfile.encoding=UTF-8"
2、proxy代理层权限是继承conf/config-sharding.yaml下配置真实数据库账号的权限,如果需要在proxy层执行一些DDL或者DELETE需要原始账号配置相应的权限,最好能和业务账号区分开来
3、这里只配置了proxy的分表功能,其他如读写分离、数据脱敏等功能可以在conf文件中配置,详细信息可以参考官方配置手册
从以上可以看出,无论是Sharding-JDBC还是Sharding-Proxy,它们都帮助用户屏蔽了真实的库表,让用户只针对逻辑表操作就行了,并且不改变原本对逻辑表操作的逻辑,降低对业务的低侵入性。
五、在线数据同步方案
????以下会介绍4个方案数据同步的方案,前3种都是基于binlog和外部的中间件实现的,对业务代码无侵入,实现历史数据的全量同步和增量数据实时同步的rehash过程;另外一种是基于DTS结合业务改动来实现,逻辑也比较简单,但对业务有一定的侵入。
5.1、DTS+Proxy同步(待验证)

????一开始准备用阿里云得DTS结合Sharding-Proxy来做数据的全量迁移和实时同步的,因为Sharding-Proxy它是可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat等)操作数据。如上图所示,通过配置DTS从旧库往Proxy做全量和增量的数据同步,从而完成rehash的过程,这种方法目前看来是最简单的,理论上虽然可行,但实际操作过程中遇见了一些问题:
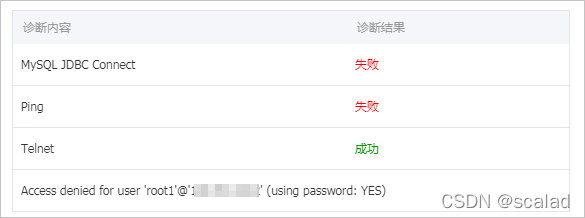
1、使用ping命令测试网络失败,使用telnet命令测试端口正常,但JDBC不通,参考了官方的解决办法,但未能修复。
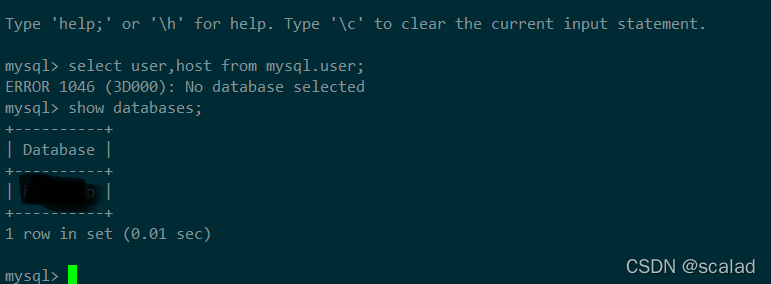
2、默认登录时,手动登录查select user,host from mysql.user报 No database selected,没选择任何库,但是其他rds和自建的mysql不会出现这种问题,所以怀疑是这个中间件有限制。
????基于这些问题与阿里云专家沟通了下,了解到当前DTS不支持直接写proxy,不过了解到一个解决方案,如下图所示,在proxy上再加上一个阿里云的数据库网关 DG,网关配置连proxy的ip和端口,当成mysql连接,DTS写数据库DG网关。因时间关系,此方案并没有再进一步验证,不过可行性较高,后续有结论再同步更新出来。

5.2、Canal+Proxy同步(可行)
????Canal是阿里巴巴开源的一个基于 MySQL 数据库增量日志解析(注意这里是增量,不是全量),提供增量数据订阅和消费的工具,根据canal的官方文档,可以看到它的实现原理是基于mysql的主从复制原理实现的,我们来看下mysql的主从复制过程:
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据“
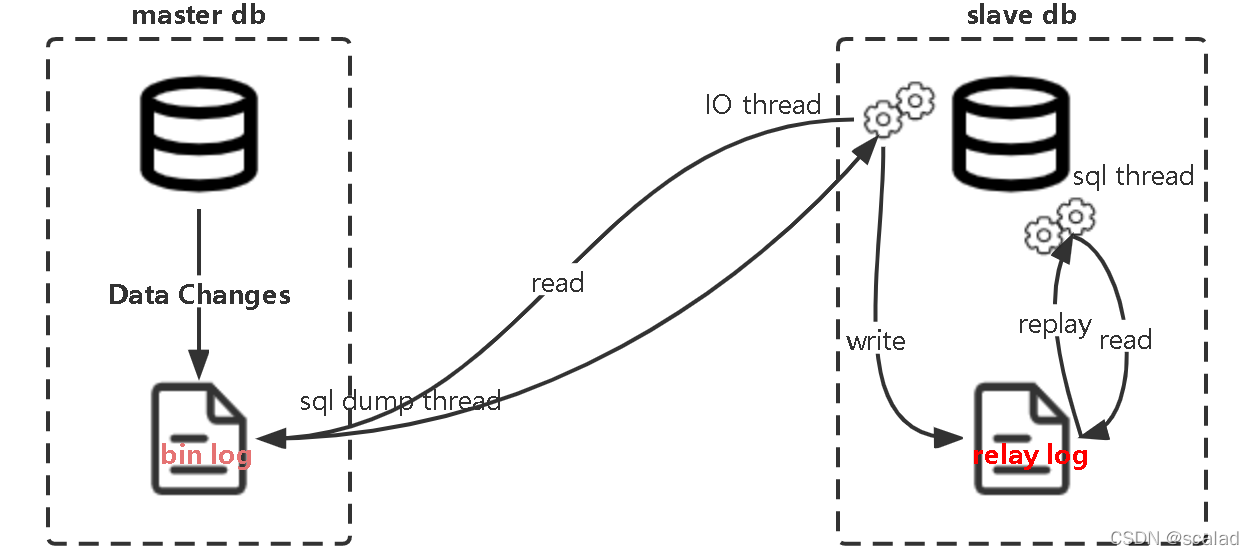
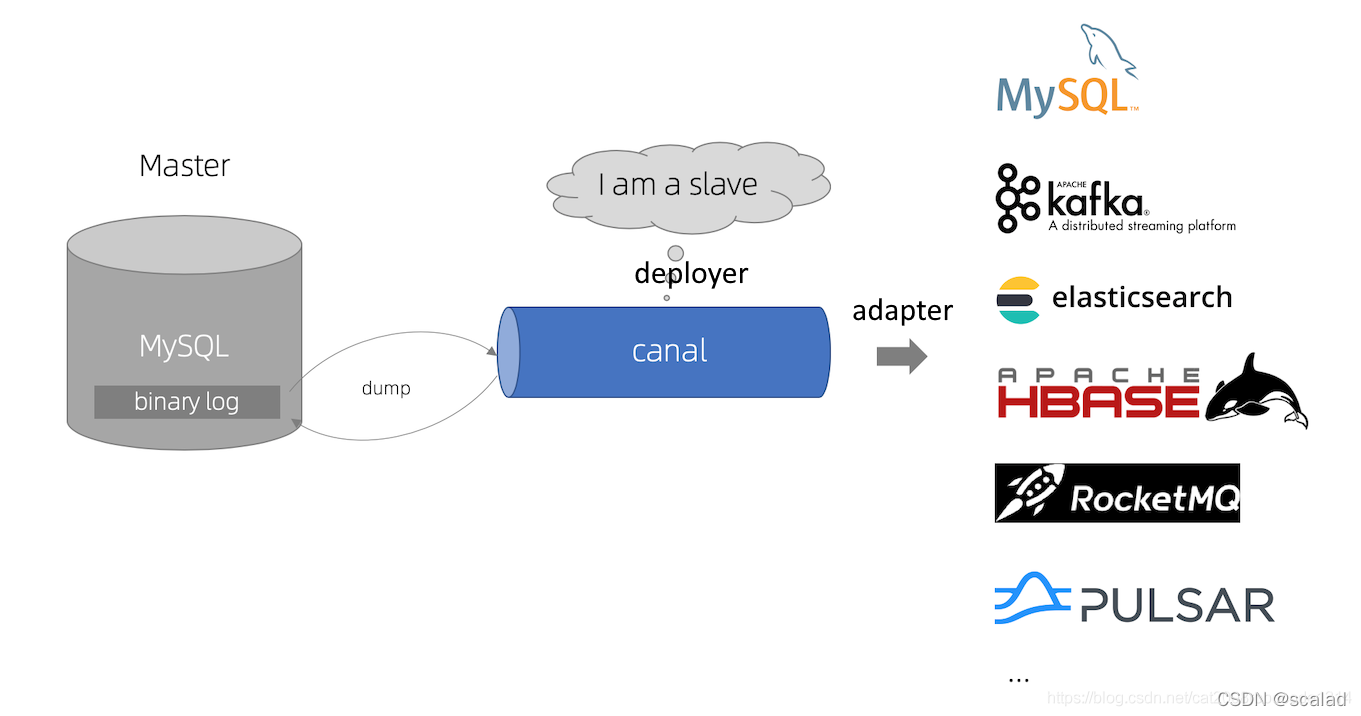
????canal从原理上模拟了 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议,MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ),canal 解析 binary log 对象(原始为 byte 流)写入下游的其他服务,比如mysql、kafka、elasticsearch等。如下图所示,deployer组件负责解析binlog日志,adapter负责适配各种存储,adapter官方有单独的示例拿来即用,开发也可以根据自己的业务场景去实现。
????所以我们结合Canal与Proxy的方案如下,从canal上游消费的数据直接写入到proxy,整个流程的方案如下:
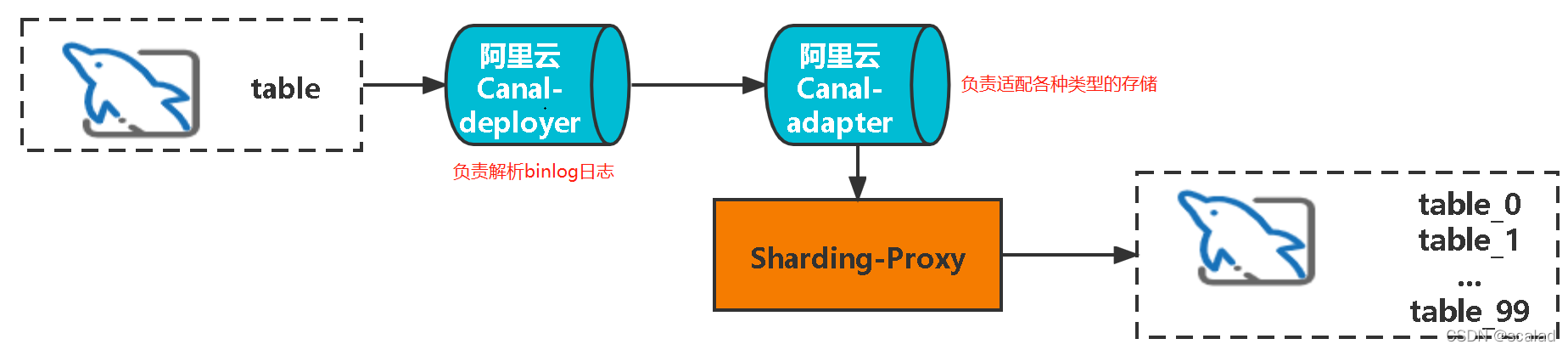
说明:Canal读取的binlog日志只保存在内存中,并且只有一个canal客户端可以进行消费,如果需要消费到多个客户端,比如同时写入到redis和hbase,则可以引入MQ
????这里我们又会碰见另外一个问题,就是我们线上的mysql的binglog是不完整的,所以我们的想法是构建一个新的具有全量数据的binlog的示例,通过DTS全量和增量的往一个新的数据库实例中同步数据,生成一份完整的binlog日志,canal再从新的实例中消费binlog,整个过程如下:
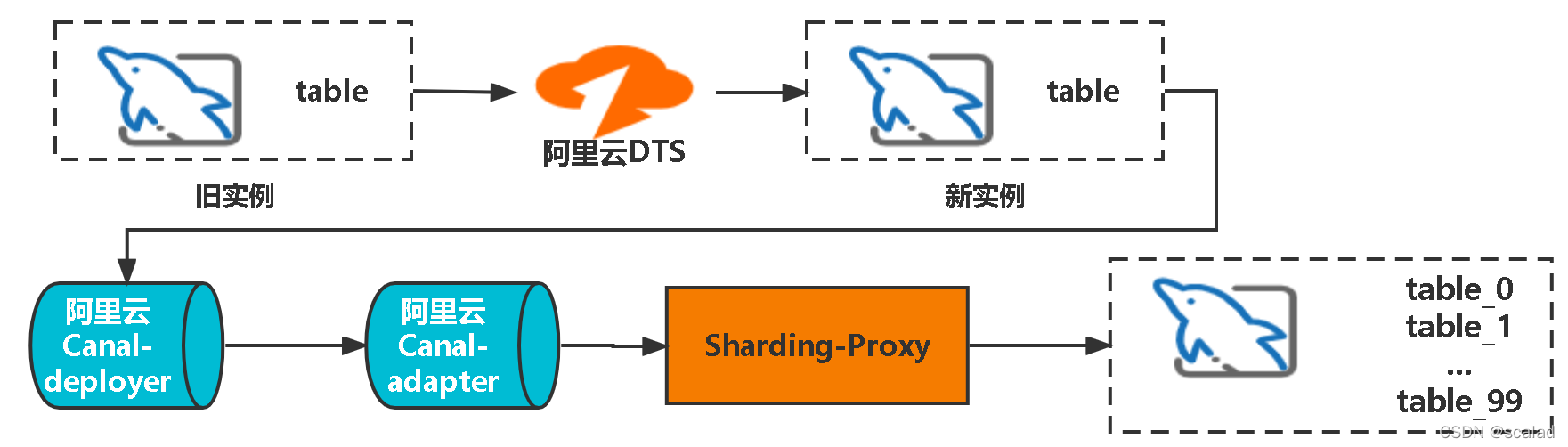
????整个过程相对曲折,涉及的中间件也较多,所以验证第一个方案的可行性就显得更加重要,为了保证数据的完整性和准确性,迁移过程中需要关注几个点:
1、binlog是否从起始位置bin.000001开始消费,启动canal-deployer时需要关注日志
2、关注canal-adapter全量同步完成和增量同步完成的一个时间,这个可以从连接数、QPS或者IOPS有一个很直观的变化
3、迁移完成后需要确保数据的完整性和准确性,完整性主要保证不要漏掉或者多了一些数据,可以用程序统计或者抽样统计;准确性要保证任何一条数据的字段值跟原先的保持一致,比如我忘记在proxy的jdbc链接加时间分区,导致同步的数据中含有时间的字段都与原本的数据差了8个小时
5.3、Sharding-Scaling结合Proxy同步(可行)
5.3.1、Sharding-Scaling
????Sharding-Scaling是一个提供给用户的通用的ShardingSphere数据接入迁移,及弹性伸缩的解决方案,我们可以结合Scaling和Proxy组件进行数据迁移+数据分片预处理,不过即使到最新版本,Scaling目前还处于Alpha阶段。

Scaling采用的是原生的JDBC连接方式以及基于Binlog日志的同步方案,Scaling一直处于监听目标数据源Binlog日志状态,把原始数据源源不断的同步到Proxy,整个过程完全自动,在完成数据迁移及重新分片前,旧服务保持持续服务,不会对线上造成影响。
#下载编译包
wget https://linux-soft-ware.oss-cn-shenzhen.aliyuncs.com/sharding-scaling-4.1.0.tar.gz
tar xf sharding-scaling-4.1.0.tar.gz
cd sharding-scaling-4.1.0
#启动服务
./bin/start.sh
#检查是否启动成功
tail -50 logs/stdout.log
sharding-scaling的增量同步基于binlog实现的, 所以账号需要拥有slave权限,RDS可以忽视此步骤, RDS默认创建的账号拥有slave权限
CREATE USER sharding_slave IDENTIFIED BY '123456';
GRANT SELECT,INSERT,UPDATE,DELETE, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'sharding_slave'@'%';
FLUSH PRIVILEGES;
5.3.2、Sharding-UI
????Sharding-UI是ShardingSphere的一个简单而有用的web管理控制台。它用于帮助用户更简单的使用ShardingSphere的相关功能,目前提供注册中心管理、动态配置管理、数据库编排等功能。主要配合Scaling一起使用,让Scaling等操作可视化,这里需要配合zookeeper一起使用,详细可参考官方文档。
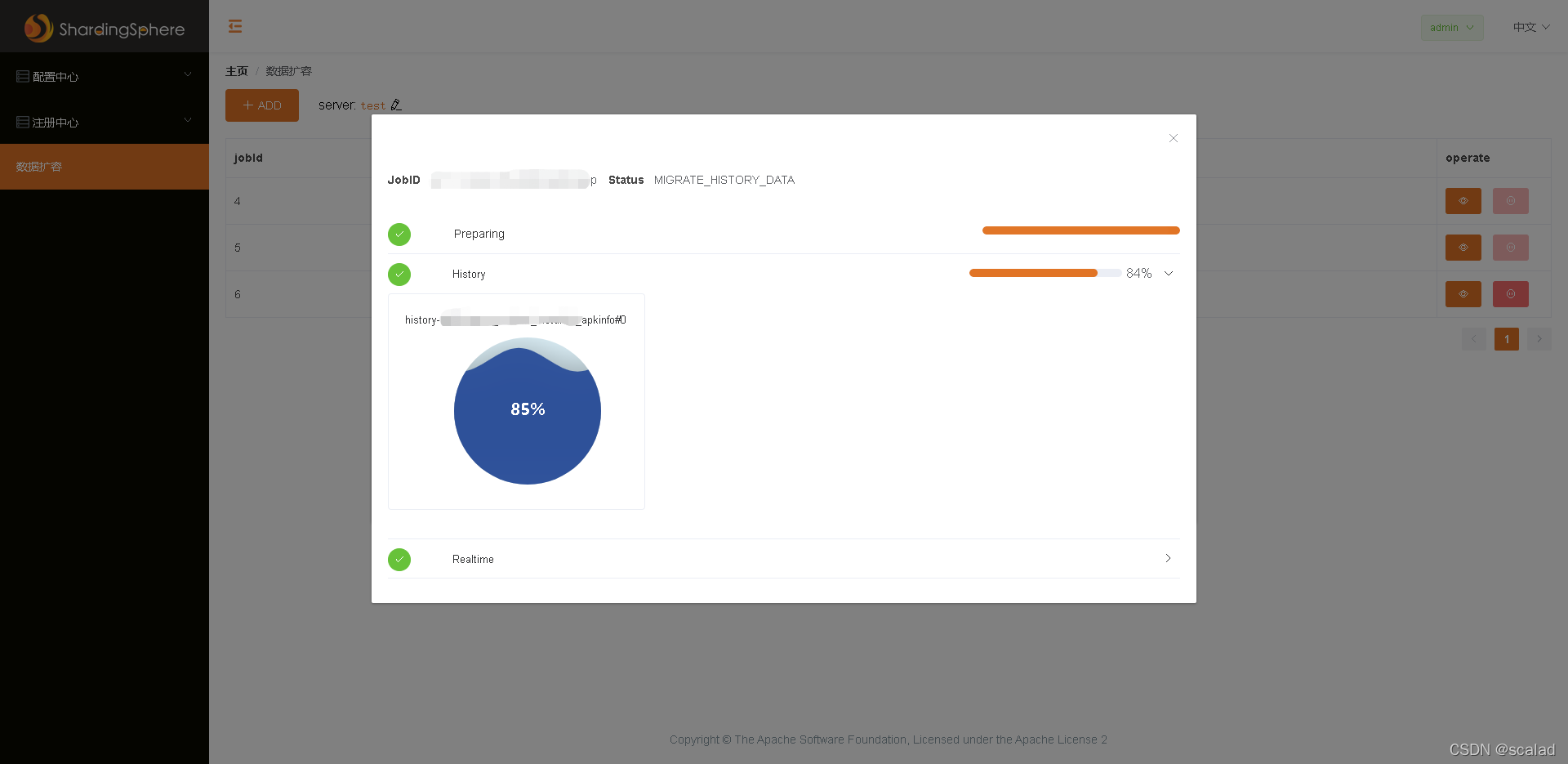
5.4、DTS+业务改动
????这种方法就需要业务层去做改动了,做法就是在我们要拆分的表中增加一列,这一列用来存储hashcode的值,也就是标识这一行的数据应该放置在哪张表中,旧数据可以通过脚本去批量的更新这一列数据,同时业务代码需要改动保证新增的数据的这一列也有值,这样子我们就可以区分出原始表中的每一行数据应该属于哪张分表了。
????然后就是我们的数据同步了,上面提到,TDS是可以基于SQL条件进行全量和增量的数据同步的,我们就可以根据新增的这一列进行筛选同步,有一点不好的是,假如你的分表有多少个,那么就要配置多少个任务,分表太多的话就比较不可取。
六、总结
6.1、再谈下什么时候需要做分库分表
????从上面可以看出,如果业务一开始没有考虑分库分表,在线上DB遇见瓶颈的情况下再来重构,对于业务是件很麻烦的事情。但是对于绝大多数非中大型的互联网企业来说,业务之初体量和流量都较小的情况下很难做出完善的设计,这并不能完全怪罪于开发者或者架构师,因为对于业务的发展其实是很难看到两三年之后的规模,业务初期的“过度设计”只会给业务带来更高的复杂度。从另一方面来说,当你遇见了这类问题,说明你当前的业务增长得还不错。
????阿里巴巴的开发规范中说明单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表,如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表。但其实在我们的业务库中,超过千万的表已经随处可见(运维给我们的标准是单表不超过5000万),也没什么性能问题,那么我们根据什么条件来判断是否去做分表呢?我的建议是能不做分表就别做,因为分库分表为了解决一个问题而引入很多其他的问题,如子查询支持有限、分库分表不带上分表字段,即会查询所有分表、不支持分片键like查询、分片算法的局限性(Hash算法可以较均匀的分散数据,但对于范围查询又要访问多个分片,Range算法又存在热点数据问题)、dba查询某条数据不确定在哪张表等,从长久来看这并不是一个好的处理方案,所以请在考虑做分表前先考虑如以下方式:
- 1、数据是否能够做定期的清理或者归档,
- 2、是否索引能够优化
- 3、是否能做分区
- 4、是否能够做垂直分表,表中是否有大字段、频繁更新的字段,是否能够独立拆分出来
- 5、是否做了数据的读写分离
- 6、是否能够升级硬件
????这些复杂度较低的优化所带来的性能提升也是显而易见的。如果业务数据增长速度很快,并且无法通过以上的操作处理的,我们仍可以考虑其他的方案:
- 1、业界上一些真正的分布式数据库,如阿里云的云原生分布式数据库 PolarDB-X,还有像Google的代表产品的 Spanner & F1和TiDB等,不需要让业务层去做分库分表,并且对于SQL可以做分布式计算,提升查询性能。
- 2、业务场景是否可以用像elasticsearch、clickhouse、mongodb等这种天生是分布式的存储引擎,虽然已经脱离了关系型数据库的范畴,但在一些业务场景也相当实用。
6.2、参考文档
2、【架构修炼之道-亿级网关、开放平台、分布式、微服务、容错等核心技术修炼实践】――王新栋
3、阿里云DTS服务