����:IT����
����:https://itwxe.com
MySQL����ô�������������������������?�ֽ�������Щ����˼����?��ƪС����С����Ǽ�����һ��MySQL����Щ�¡�
һ��������ʲô
��������һ��SQL�����ɵ���������Ԫ,��Щ����Ҫôȫ��ִ��,Ҫôȫ����ִ��,��һ�����ɷָ�Ĺ�����λ��ͨ��������4������,Ҳ�����۳���Գ�׳Ƶ�ACID���ԡ�
- ԭ����(Atomicity):������һ��ԭ�Ӳ�����Ԫ,������ݵ���,Ҫôȫ��ִ��,Ҫôȫ����ִ�С��ٸ�����:���˽�С����Ů����ת��520��,��ôSQL��һ����������,С�����˻����
-520��,Ů�����˻����+520��,��һ��ת�˲���,����ִֻ��С�����˻�-520��,����ִֻ��Ů�����˻����+520��,ֻ�ܶ�ִ��,���߶���ִ�С� - һ����(Consistent):������ʼ�����ʱ,���ݶ����뱣��һ��״̬��һ���Ժ�ԭ����ϢϢ���,��һ��ת�˲�������С���˻����Ӧ��
-520��,Ů�����˻����+520��,����ת�˲���֮���˻��ܽ����һ�µġ� - ������(Isolation):һ�������ִ�в��ܱ������������,��ÿ�������Ƕ�����,�������������Ӱ�졣����˵����һ������(T1)�������̵��м�״̬����������(T2, T3��)�Dz��ɼ���;ͬ��,T2ͬ����T1��T3���м�״̬���ɼ��ġ���ֻҪС����ת�˲���û���,��ôŮ���Ѳ�����ô��ѯ�������ԭ�������,�������ѯ���
520�顣 - �־���(Durable):�������֮��,�����ݵ����������Ե�,�����������ݿ�ϵͳ�������ϵ������Ҳ���ᶪʧ�ύ����IJ�������ֻҪС��ת�˳ɹ���,���ݾͱ�������ˡ�
������������������������
��д���߸��¶�ʧ(Lost Update)
��������������ͬһʱ����ͬһ��,Ȼ��������ѡ����ֵ����ҵ��������¸���ʱ,����ÿ������֪����������Ĵ���,�ͻᷢ����ʧ�������⡣
����˵�������ĸ��¸��������������������ĸ�����
���(Dirty Reads)
һ��������������������Ѿ��ĵ���δ�ύ������,δ�ύ��ζ����Щ���ݿ��ܻ�ع�,Ҳ���ǿ������ղ�һ����浽���ݿ���,���Զ���������������Ч�ġ�
�����ظ���(Non-Repeatable Reads)
һ�������ڶ�ȡijЩ���ݺ��ij��ʱ���,�ٴζ�ȡ��ǰ��������������,ȴ����������������Ѿ������˸ı�,���ܻ��ܵ����������Ӱ��,����������������������ݲ��ύ�ˡ�ͨ��������ݸ���(UPDATE)��������ɾ��(DELETE)������
����˵������һ��������,��ͬ��ѯ����ڲ�ͬʱ�̲�ѯ�����Ľ����һ��,�����ǽ���ֶ�ֵ��һ��,Ҳ������������������
�ö�(Phantom Reads)
�ԱȲ����ظ���,�ö��������������(INSERT)��˵��,��ͬһ������,�ڶ�ȡijЩ���ݺ��ij��ʱ���,�ٴζ�ȡ��ǰ��������������,�ڶ��ε�SQL��䷵����֮ǰ�����ڵ�����
����˵��������A��ȡ�������������ύ������������
��������һ�¾������������ظ������ö���
- �����ظ���:˵����ԭ�����ڵļ�¼A,��¼A��A����˼�¼B��
- �ö�:������ԭ�������ڵļ�¼��
��Ȼ�������ֲ����Ե�С�����Խ���塢������������뼶����������������,���۽��ʵ��,nice~
����������뼶��
�����������������������ظ������ö��������ݿ��ȡ��һ����,����,�������ݿ��ṩ��һ����������뼶����������������⡣
| ���뼶�� | ��� | �����ظ��� | �ö� |
|---|---|---|---|
| ��δ�ύ(read-uncommitted) | �� | �� | �� |
| �����ظ���(read-committed) | �� | �� | �� |
| ���ظ���(repeatable-read) | �� | �� | �� |
| ���л�(serializable) | �� | �� | �� |
MySQL���ݿ�Ĭ�ϵĸ��뼶��Ϊ���ظ���(repeatable-read),Ҳ�������dz�˵��RR����
�鿴������뼶��:show variables like 'tx_isolation';
����������뼶��,�������ø��뼶��Ϊ��δ�ύ:
- ���Ե�ǰ�Ự��Ч,������Ч:
set session transaction isolation level read uncommitted;����set tx_isolation = 'read-uncommitted'; - ��ȫ�ֻỰ��Ч,��Ҫ�˳��Ự����Ч:
set global transaction isolation level read uncommitted;
��Spring��������ʱ,��������ø��뼶��Ĭ����MySQL���õĸ��뼶��,���Spring�����˾������õĸ��뼶��
�ġ�������
���Ǽ����Э��������̻����̲߳�������ͬһ��Դ�Ļ���,���������ݿ���˵���ݾ���һ����Ҫ�û���������Դ,��ô��֤���ݵIJ�������һ���Ժ�Ч�������ݿ���Ҫ��������⡣
����ͬ���������·��ࡣ
- ������������,��Ϊ�ֹ����ͱ�������
- �ֹ����Ƚ��ֹ�,�ֹ�����������һ�����������ɳ�ͻ,���߳�ͬʱ��ͬһ�������ĵ�ʱ��,�����ݽ����ύ���µ�ʱ��,�Ż���ʽ�����ݵij�ͻ�����м��,�����ͻ,�ظ��û��쳣��Ϣ,���û��������ȥ����
- �������Ƚϱ���,���߳�ͬʱ��ͬһ�������ĵ�ʱ��,����ֻ��һ���߳��ijɹ���
- �Ӷ����ݿ���������ͷ�,��Ϊ������д��(�����ڱ�����)��
- ����(������,S��(Shared)):���ͬһ������,�������������ͬʱ���ж����ụ��Ӱ�졣
- д��(������,X��(eXclusive)):��ǰд����û�����ǰ,�����������д���Ͷ�����
- �Ӷ����ݲ��������ȷ�,��Ϊ������������
1. ����
ÿ�β�����ס���ű�������С,������,�����������,�������ȴ�,��������ͻ�ĸ������,���������,һ��������������Ǩ�Ƶij�����
��������
- �ֶ����ӱ���:
lock table ������ read/write,������2 read/write; - �鿴���ϼӹ�����:
show open tables; - ɾ������:
unlock tables;
ʵ��һ��
-- ����ʾ����
CREATE TABLE `test_myisam_lock` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE = MyISAM DEFAULT CHARSET = utf8;
-- ���뼸������
INSERT INTO `blog_test`.`test_myisam_lock` (`id`, `name`, `age`) VALUES (1, 'itwxe', 18);
INSERT INTO `blog_test`.`test_myisam_lock` (`id`, `name`, `age`) VALUES (2, 'Lee Patel', 62);
INSERT INTO `blog_test`.`test_myisam_lock` (`id`, `name`, `age`) VALUES (3, 'Sakurai Mio', 55);
INSERT INTO `blog_test`.`test_myisam_lock` (`id`, `name`, `age`) VALUES (4, 'Tan Xiuying', 42);
INSERT INTO `blog_test`.`test_myisam_lock` (`id`, `name`, `age`) VALUES (5, 'Cheng Yunxi', 47);
1���Ӷ���
���ı�������Ŵ�������session��SQL��ִ��˳��,ͬһ��Ϊ��������ִ�е���䡣ͼ���ѱ�ע��ǰʾ��SQLִ��˳��,�������ٽ�ͼ˵����
| ��� | session1 | session2 |
|---|---|---|
| 1 | lock table test_myisam_lock read; | |
| 2 | select * from test_myisam_lock; �C ���Բ�ѯ | select * from test_myisam_lock; �C ���Բ�ѯ |
| 3 | insert into blog_test.test_myisam_lock ( name, age) values (��xiaowu��, 18); �C ����ʧ��,���� | insert into blog_test.test_myisam_lock ( name, age) values (��xiaowu��, 18); �C �ȴ�ִ�� |
| 4 | unlock tables; | �C �ͷ�����û�г�ʱ��ִ�в������ |
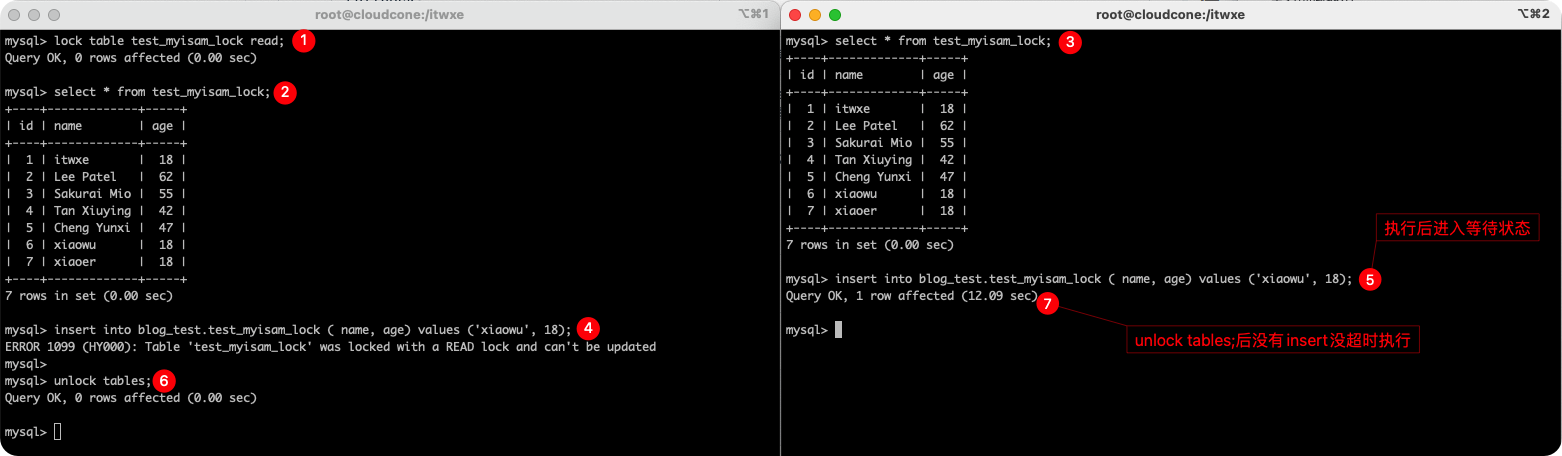
��MyISAM���Ķ�����(�Ӷ���),���������������̶�ͬһ���Ķ�����;����������ͬһ����д����,��ǰ�߳���ִ��д����,�����߳̽���ȴ�״̬,ֻ�е������ͷź�,�Ż�ִ���������̵�д������
2�����
| ��� | session1 | session2 |
|---|---|---|
| 1 | Lock table test_myisam_lock write; | |
| 2 | select * from test_myisam_lock; �C ���Բ�ѯ | select * from test_myisam_lock; �C ����ȴ�ִ��״̬,�ֶ�ȡ��(ctrl + c) |
| 3 | insert into blog_test.test_myisam_lock ( name, age) values (��xiaoer��, 18); �C ����ɹ� | insert into blog_test.test_myisam_lock ( name, age) values (��xiaoer��, 18); �C ����ȴ�ִ��״̬,�ֶ�ȡ��(ctrl + c) |
| 4 | update blog_test.test_myisam_lock set name = ��wangxiaoer�� where id = 8; �C ���³ɹ� | update blog_test.test_myisam_lock set name = ��wangxiaoer�� where id = 8; �C ����ȴ�ִ��״̬,�ֶ�ȡ��(ctrl + c) |
| 5 | delete from blog_test.test_myisam_lock where id = 8; �C ɾ���ɹ� | delete from blog_test.test_myisam_lock where id = 8; �C ����ȴ�ִ��״̬ |
| 6 | unlock tables; | �C �ͷ�����û�г�ʱ�����ɾ������ |
����˵:��MylSAM����д����(��д��),����������ǰ���̶Ա��Ķ�д����;���ǻ������������̶�ͬһ���Ķ���д����,ֻ�е�д���ͷź�,�Ż�ִ���������̵Ķ�д������
2. ����
ÿ�β�����סһ������,������,������,���������,����������С,��������ͻ�ĸ������,��������ߡ�
ͬʱInnoDB��MyISAM�������㲻ͬ����֧��������֧���м�����
��������
-- ����ʾ����
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`balance` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ���뼸������
INSERT INTO `blog_test`.`account` (`id`, `name`, `balance`) VALUES (1, 'itwxe', 1000);
INSERT INTO `blog_test`.`account` (`id`, `name`, `balance`) VALUES (2, 'Kenneth Adams', 2000);
INSERT INTO `blog_test`.`account` (`id`, `name`, `balance`) VALUES (3, 'Takada Daichi', 3000);
INSERT INTO `blog_test`.`account` (`id`, `name`, `balance`) VALUES (4, 'Anne Russell', 4000);
INSERT INTO `blog_test`.`account` (`id`, `name`, `balance`) VALUES (5, 'Jia Yuning', 5000);
Ĭ�ϵ�RR���뼶����ʾ��,�����ظ���(repeatable-read)��
| ��� | session1 | session2 |
|---|---|---|
| 1 | begin; �C �������� | begin; �C �������� |
| 2 | update account set balance = balance + 1000 where id = 1; �C ����id = 1����� | select * from account where id = 1; �C ��ѯ������,������ѯ |
| 3 | update account set balance = balance + 1000 where id = 1; �C ���²�������,����ȴ�ִ��״̬,���ᳬʱ���ߵȴ�session1�ύ(�ع�)�����Ż�ִ�и�����䡣 | |
| 4 | commit; �C �ύ���� | �C session1�ύ(�ع�)�����,û�г�ʱ����и��²��� |
��Ȼ��,С������д��ֻ�������Ự,����кܶ��sessionͬʱ����һ������Ҳ��һ������ȴ�״̬��
����˵:�ڷǴ��л�������뼶����,InnoDB��ִ�в�ѯ���selectʱ�������,����update��insert��delete�������������
��Ȼ,����ѯ���Ҳ��Ҫ����Ҳ�ǿ��Ե�,ʹ�� select ... for update��
select * from account where id = 1 for update;
��ʱ��ǰ�Ự����id = 1���п��Խ�����ɾ�IJ����,�����Ự���ܶ�id = 1�н��в�����ֻ�еȴ���ǰ�Ự�ͷ���(�ύ/�ع�����)����ܹ�������¼id = 1���С�
�塢������������뼶��������
����֧���������Ե�Ȼ�͵ý��������뼶��������ʵ��һ�¡�
1. ��δ�ύ
���Ƚ�ʾ���˻���ԭ��1000,update account set balance = 1000 where id = 1;��
| ��� | session1 | session2 |
|---|---|---|
| 1 | set tx_isolation = ��read-uncommitted��; �C ���õ�ǰ�ػ�������뼶��Ϊ��δ�ύ | set tx_isolation = ��read-uncommitted��; �C ���õ�ǰ�ػ�������뼶��Ϊ��δ�ύ |
| 2 | begin; �C �������� | |
| 3 | select * from account where id = 1; �C ��һ�β�ѯ���Ϊ1000 | begin; �C �������� |
| 4 | update account set balance = balance + 1000 where id = 1; �C ����id = 1����� | |
| 5 | select * from account where id = 1; �C �ڶ��β�ѯ���Ϊ2000,������������,������û���ύ������ | |
| 6 | rollback; �C �ع� | |
| 7 | select * from account where id = 1; �C �����β�ѯ���Ϊ1000 | |
| 8 | update account set balance = balance - 2000 where id = 1; �C �������5�е������Java�������жϿ��Թ����ִ���˿ۼ���� | |
| 9 | commit; �C �ύ���� |
���Կ���,��δ�ύ���뼶����,��5��session��ȡ�����˻�������2000��,���ʱ�����JavaӦ�ó���ʹ��2000��Ϊ�ж���ijЩҵ�����,�����ж��Ƿ���Թ���һ��2000����Ʒ,��ʱsession�ֻ�û�пۼ����,��ô��session2��ΪijЩԭ��ع���,��ʱidΪ1���û������� -1000 ����,�������Բ�������;����ʵ�ʿ�����һ����Ҫʹ��Java��������ֱ�ӽ�ֵ���µ����ݿ�,�����������д,����Java�������ֵ���˻����Ϊ��,��ôִ��update account set balance = 0 where id = 1;�Ļ���������ˡ�
Ϊ�˽����������Ҫ�õ������ύ�ĸ��뼶���ˡ�
2. �����ύ
���Ƚ�ʾ���˻���ԭ��1000,update account set balance = 1000 where id = 1;��
| ��� | session1 | session2 |
|---|---|---|
| 1 | set tx_isolation = ��read-committed��; �C ���õ�ǰ�ػ�������뼶��Ϊ�����ύ | set tx_isolation = ��read-committed��; �C ���õ�ǰ�ػ�������뼶��Ϊ�����ύ |
| 2 | begin; �C �������� | |
| 3 | select * from account where id = 1; �C ��һ�β�ѯ���Ϊ1000 | begin; �C �������� |
| 4 | update account set balance = balance + 1000 where id = 1; �C ����id = 1����� | |
| 5 | select * from account where id = 1; �C �ڶ��β�ѯ���Ϊ1000 | |
| 6 | commit; �C �ύ���� | |
| 7 | select * from account where id = 1; �C �����β�ѯ���Ϊ2000 | |
| 8 | commit; �C �ύ���� |
���Կ����Ѿ���������������,������session2�ύ������˲����ظ���������,�����ظ������������ڱ�дJavaӦ�ô����ʱ����ѱ�д,�������ظ����͵ÿ����ظ����ĸ��뼶��������ˡ�
3. ���ظ���
���Ƚ�ʾ���˻���ԭ��1000,update account set balance = 1000 where id = 1;��
| ��� | session1 | session2 |
|---|---|---|
| 1 | set tx_isolation=��repeatable-read��; �C ���õ�ǰ�ػ�������뼶��Ϊ���ظ��� | set tx_isolation=��repeatable-read��; �C ���õ�ǰ�ػ�������뼶��Ϊ���ظ��� |
| 2 | begin; �C �������� | |
| 3 | select * from account; �C ��һ�β�ѯid = 1�˻����Ϊ1000 | begin; �C �������� |
| 4 | update account set balance = balance + 1000 where id = 1; �C ����id = 1����� | |
| 5 | select * from account; �C �ڶ��β�ѯid = 1�˻����Ϊ1000 | |
| 6 | commit; �C �ύ���� | |
| 7 | select * from account; �C �ڶ��β�ѯid = 1�˻����Ϊ1000,���Կ����Ѿ�����˲����ظ��������� | |
| 8 | begin; �C ���¿���һ������,��֤�ö����� | |
| 9 | insert into account (id, name, balance) values (6, ��xiaoer��, 6000); �C ����һ������ commit; �C �ύ���� | |
| 10 | select * from account; �C ��������7��չʾ�Ľ��һ��,ֻ��id = 1~5�ļ�¼ | |
| 11 | update account set balance = 6666 where id = 6; �C ����������id = 6��¼ | |
| 12 | select * from account; �C �ٴη��ֲ�ѯ���ļ�¼����id = 6�ļ�¼,��id=6���˻����Ϊ6666 | |
| 13 | commit; |
����,���Կ�����ʵMySQL��û����ȫ����ö�������,��RR�����µ�MySQL�п��ܻ���ֻö�������
��Ȼ����ʵ�ʿ���ͨ��Ҳ��������ȥ����,��Ϊid = 6����Ե�ǰsession�Dz��ɼ���,����ͨ������ֱ���ĵ�����session����ļ�¼��
����MySQLĬ�ϵ�������뼶�����RR����,���������ܽ��99.99%��ҵ����
4. ���л�
���Ƚ�ʾ���˻���ԭ��1000,update account set balance = 1000 where id = 1;��
| ��� | session1 | session2 |
|---|---|---|
| 1 | set tx_isolation=��serializable��; �C ���õ�ǰ�ػ�������뼶��Ϊ���л� | set tx_isolation=��serializable��; �C ���õ�ǰ�ػ�������뼶��Ϊ���л� |
| 2 | begin; �C �������� | begin; �C �������� |
| 3 | select * from account where id = 1; �C ��ѯid = 1��Ϣ,�˻����Ϊ1000 | select * from account where id = 2; �C id = 2�ļ�¼���Բ�ѯ |
| 4 | select * from account where id = 1; �C id = 1�˻����Ϊ1000 | |
| 5 | select * from account where id = 2; �C ����ȴ�ִ��״̬,���ᳬʱ���ߵȴ�session1�ύ������ع���Ż�ִ�в�ѯ�� | |
| 6 | commit; | �C ���û�г�ʱ��ִ�в�ѯid = 2�ļ�¼��Ϣ |
| 7 | commit; |
���Կ������л����뼶����,ʹ�õ���������,������¼����ɾ�IJ鶼���յ�Ӱ�����ȴ�ִ��״̬��
����,���л����뼶���²����лö�������,��ȻЧ��Ҳ���,ͨ��ʵ����Ŀ�����ж�����ʹ�á�
�����������
1. ��¼������϶�����ټ���
��������������,�ֱ��Ǽ�¼������϶�����ټ���,��¼��ֻ����һ�м�¼,����϶�����ټ�����������һ����Χ�ļ�¼�С�
��¼��(Record Locks)
��¼������һ�м�¼���Ѿ�������������ʾ���� id = 1 �ij���,����߶�ˡ�
��϶��(Gap Locks)
��϶��ָ��������������ֵ֮��ļ�϶,���Խ��RR������һЩ�龰�Ļö����⡣
-- �ٲ��뼸��������ʾ��϶�����ټ���
INSERT INTO `blog_test`.`account` (`id`, `name`, `balance`) VALUES (13, 'itwxe.com', 13000);
INSERT INTO `blog_test`.`account` (`id`, `name`, `balance`) VALUES (18, 'zhangsan', 18000);
INSERT INTO `blog_test`.`account` (`id`, `name`, `balance`) VALUES (25, 'lisi', 25000);
�������ݺ�id�Ͳ�����(6, 13), (13, 18), (18, 25), (25, ������) ���ĸ��ռ��϶��
����ʹ��RR������뼶��,set tx_isolation='repeatable-read';��
| ��� | session1 | session2 |
|---|---|---|
| 1 | begin; �C �������� | begin; �C �������� |
| 2 | update account set balance = balance + 1000 where id > 8 and id < 13; �C ��ѯ�����϶(8, 13) | insert into account values(6, ��jianxi��, 6000); �C ��������ִ����Ӧ���,���������Ѵ���,����ʧ�� |
| 3 | insert into account values(7, ��jianxi��, 7000); �C ����id = 10�ļ�¼�ᷢ�ֲ��벻��,����ȴ�ִ��״̬ | |
| 4 | insert into account values(10, ��jianxi��, 8000); �C ����id = 10�ļ�¼�ᷢ�ֲ��벻��,����ȴ�ִ��״̬,�ֶ�ȡ��(ctrl + c) | |
| 5 | insert into account values(13, ��jianxi��, 8000); �C ����id = 13ͬ��������,����ȴ�ִ��״̬ | |
| 6 | insert into account values(14, ��jianxi��, 8000); �C ������������ | |
| 7 | rollback; �C �ع����� | rollback; �C �ع����� |
���Կ��������в��������ķ�ΧΪ(6, 13],Ҳ����˵��϶�������ķ�Χ��С��Χ(id=8)ǰһ���м�¼(id=6)�Ŀ����䵽��Χ(id=13)�ĺ�һ����¼,���ұ����䡣
���Կ�����϶���ڼ�����ijЩ����»ö��ķ���,ͨ���Լ�϶�����ü�϶����session1�ύ(�ع�)����֮ǰ����session�������в���������κ����ݡ�
��϶�����ڿ��ظ������뼶���²Ż���Ч��
�ټ���(Next-key Locks)
�ټ�������˵������ļ�϶��,�������ͼ�϶���Ľ��,��������Ϊ��϶���а�����¼�С�
Ŀǰ����(6, 13), (13, 18), (18, 25), (25, ������) ���ĸ��ռ��϶��
����ʹ��RR������뼶��,set tx_isolation='repeatable-read';��
| ��� | session1 | session2 |
|---|---|---|
| 1 | begin; �C �������� | begin; �C �������� |
| 2 | update account set balance = balance + 1000 where id > 15 and id < 28; �C ��ѯ�����϶(8, 13) | insert into account values(13, ��linjian��, 13000); �C ��������ִ����Ӧ���,���������Ѵ���,����ʧ�� |
| 3 | insert into account values(17, ��linjian��, 17000); �C ����id = 17�ļ�¼�ᷢ�ֲ��벻��,����ȴ�ִ��״̬ | |
| 4 | insert into account values(18, ��linjian��, 18000); �C ����id = 18�ļ�¼�ᷢ�ֲ��벻��,����ȴ�ִ��״̬,����ǰ������������ֶ�ȡ��(ctrl + c) | |
| 5 | insert into account values(25, ��linjian��, 25000); �C ����id = 25ͬ��������,����ȴ�ִ��״̬ | |
| 6 | insert into account values(29, ��linjian��, 29000); �C ����id = 29ͬ��������,����ȴ�ִ��״̬ | |
| 7 | rollback; �C �ع����� | |
| 8 | �C ������ʱ��û�г�ʱ��ִ�в���id = 29�ļ�¼ | |
| 9 | rollback; �C �ع����� |
���Կ����ټ��������ķ�Χ��(13,������]��ͬ�������ұ�,ȡ����13��ȡ�õ������
2. ������������������
| ��� | session1 | session2 |
|---|---|---|
| 1 | begin; �C �������� | begin; �C �������� |
| 2 | update account set balance = balance + 1000 where name = ��itwxe��; �C ���и��²���,name��û������ | select * from account where id = 2; �C �����������Բ�ѯ |
| 3 | insert into account values(14, ��linjian��, 13000); �C ��������������,����ȴ�״̬ | |
| 4 | rollback; �C �ع�����,��Ȼ�ύҲ���� | |
| 5 | �C ������ʱ��û�г�ʱ��ִ�в���id = 14�ļ�¼ | |
| 6 | rollback; �C �ع�����,��Ȼ�ύҲ���� |
�������ﶼ�����ĵ�С�����,InnoDB����������������ӵ���,������Լ�¼�ӵ��������Ҹ���������ʧЧ,��������������Ϊ������
����,����Է������ֶθ���,�����������ɱ���,�����ɱ����������е�д������������,ֱ���������ͷš�
3. ��������
����ͨ�����innodb_row_lock״̬����������MySQL�����������
show status like 'innodb_row_lock%'
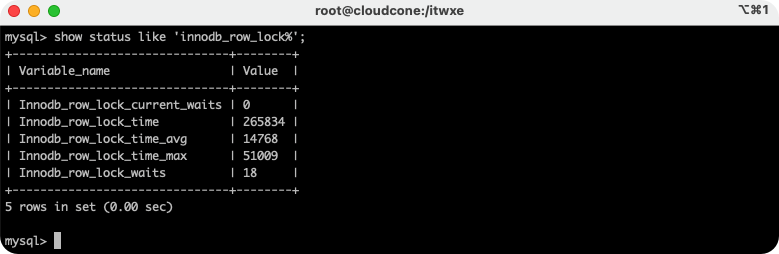
- Innodb_row_lock_current_waits:��ǰ���ڵȴ�����������
- Innodb_row_lock_time:��MySQL����������������ʱ�䳤��
- Innodb_row_lock_time_avg:ÿ�εȴ���ƽ��ʱ��
- Innodb_row_lock_time_max:MySQL�������������һ�εȴ�ʱ��
- Innodb_row_lock_waits:MySQL�����������ܹ��ȴ��Ĵ���
���ȴ������ܶ�,����ÿ�εȴ�ʱ��Ҳ�ܳ�ʱ,��Ҫ����ϵͳ��Ϊʲô������ô��ĵȴ�,Ȼ����ݷ�����������ƶ��Ż��ƻ���
4. ϵͳ��������صı�
MySQLϵͳ���м���������صı�,��ʱ������debug��������һֱ����SQL��䲻ִ��,��ʱ����ȫ�п���������С���Ҳ�ڵ�����һ������,Ȼ��һֱ��������������������͵��Բ���ȥ��,��ôզ����?
MySQL�������ṩ�˱�����ѯ,ֻҪkill������С����������Ȼ��Ϳ��Ե�����,�������ײ�Ҫ����,��Ϊ��kill���Ǹ����������С������û��������ô�Ͱ�����,���Ա�����С���Ų�����😂
�\�\ �鿴����
select * from INFORMATION_SCHEMA.INNODB_TRX;
�\�\ �鿴��
select * from INFORMATION_SCHEMA.INNODB_LOCKS;
�\�\ �鿴���ȴ�
select * from INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
�\�\ �ͷ���,trx_mysql_thread_id��INNODB_TRX���в�ѯ����Ϣ��ֵ,����`kill 394`,kill�����������ύҲ���ع�,���ERROR����
kill trx_mysql_thread_id;
�\�\ �鿴���ȴ���ϸ��Ϣ
show engine innodb status\G;
5. ����
| ��� | session1 | session2 |
|---|---|---|
| 1 | set tx_isolation=��repeatable-read��; �C ���õ�ǰ�ػ�������뼶��Ϊ���ظ��� | set tx_isolation=��repeatable-read��; �C ���õ�ǰ�ػ�������뼶��Ϊ���ظ��� |
| 2 | begin; �C �������� | begin; �C �������� |
| 3 | select * from account where id = 1 for update; �C ������ѯ | select * from account where id = 2 for update; �C ������ѯ |
| 4 | select * from account where id = 2 for update; �C ����ȴ�״̬ | select * from account where id = 1 for update; �C ����,������,������������ �C ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
| 5 | �C ��Ϊsession��������,����id = 2���������ͷ�,����û�г�ʱ�������ִ�в�ѯ | rollback; |
| 6 | rollback; |
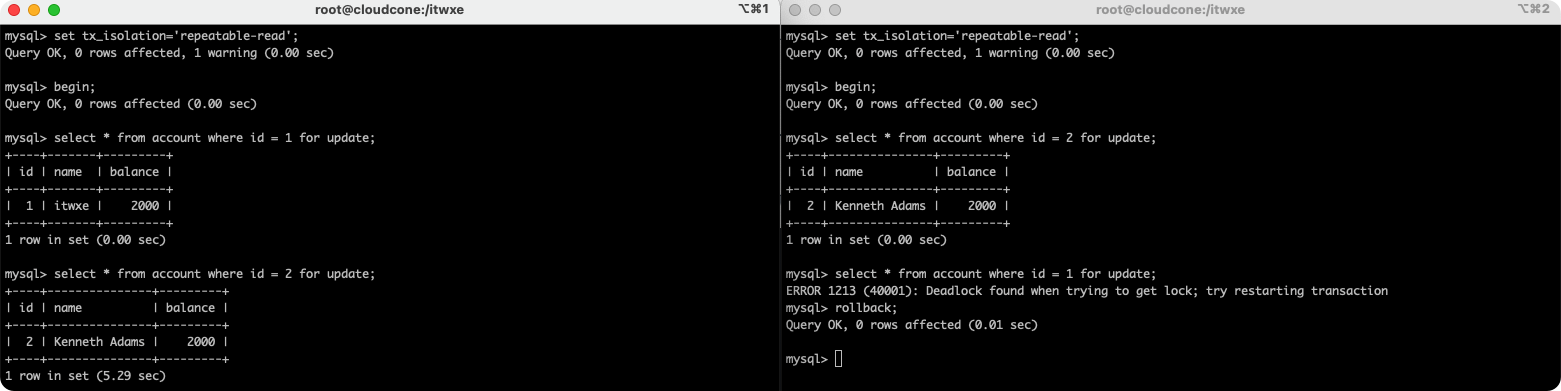
����������MySQL�����Զ�����������ع������������Ǹ�����,������Щ���MySQLû���Զ����������
6. ���Ż�����
- ���������������ݼ�����ͨ�����������,������������������Ϊ������
- �����ܼ��ټ���������Χ,�����϶����
- �������������С,����������Դ����ʱ�䳤��,�漰���������sql���������������ִ�С�