主键使用自增ID还是UUID,为什么?
使用UUID作为主键会有什么问题?
为什么要尽量设定一个主键?
1. UUID作为主键的问题?
从性能的角度考虑,使用UUID来作为聚簇索引则会很糟糕,它使得聚簇索引的插入变得完全随机,这是最坏的情况,使得数据没有任何聚集特性。使用UUID主键插入行不仅花费的时间更长,而且索引占用的空间页更大。这一方面是由于主键字段更长,另一方面是由于页分裂和碎片导致的。
使用顺序主键时,因为主键的值是顺序的,所以InnoDB把每一条记录都存储在上一条记录的后面,当本页中的记录满时,下一条记录就会插入到新的页中,一旦按照这种顺序的方式加载,主键页就会按顺序的记录填满,这也正是所期望的结果。
使用uuid作为主键时,因为新行的主键值不一定比之前插入的大,所以InnoDB无法简单的总是把新行插入到索引的最后,而是需要为新的行寻找合适的位置 (通常是已有数据的中间位置),并且分配空间。这会增加很多的额外工作,并导致数据分布不够优化,下面总结一些缺点:
- 写入的目标页可能已经刷新到磁盘上并从缓存中移除,或者是还没有被加载到缓存中,InnoDB在插入数据之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机IO。
- 因为是乱序写入的,InnoDB不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂会导致移动大量数据,一次插入最少需要修改三个页而不是一个页。
- 由于频繁的页分裂,页会变得稀疏并被不规则的填充,所以最终数据会有碎片。
所以使用InnoDB时,应该尽可能的按照主键顺序插入顺序,并且尽可能的使用单调递增的聚簇键的值来插入新行。
2. 自增ID作为主键的问题?
自增ID做主键,简单易懂,几乎所有数据库都支持自增类型,只是实现上各自有所不同而已。自增ID除了简单,其他都是缺点,总体来看存在以下几方面的问题:
可靠性不高:存在自增ID回溯的问题,这个问题直到最新版本的MySQL 8.0才修复。
安全性不高:对外暴露的接口可以非常容易猜测对应的信息。比如:/User/1/这样的接口,可以非常容易猜测用户ID的值为多少,总用户数量有多少,也可以非常容易地通过接口进行数据的爬取。
性能差:自增ID的性能较差,需要在数据库服务器端生成。
交互多:业务还需要额外执行一次类似 last_insert_id() 的函数才能知道刚才插入的自增值,这需要多一次的 网络交互。在海量并发的系统中,多1条SQL,就多一次性能上的开销。
局部唯一性:最重要的一点,自增ID是局部唯一,只在当前数据库实例中唯一,而不是全局唯一,在任意服务器间都 是唯一的。对于目前分布式系统来说,这简直就是噩梦。
3. 业务字段做主键的问题?
为了能够唯一地标识一个会员的信息,需要为 会员信息表 设置一个主键。那么,怎么为这个表设置主 键,才能达到我们理想的目标呢? 这里我们考虑业务字段做主键。
表的数据结构如下:
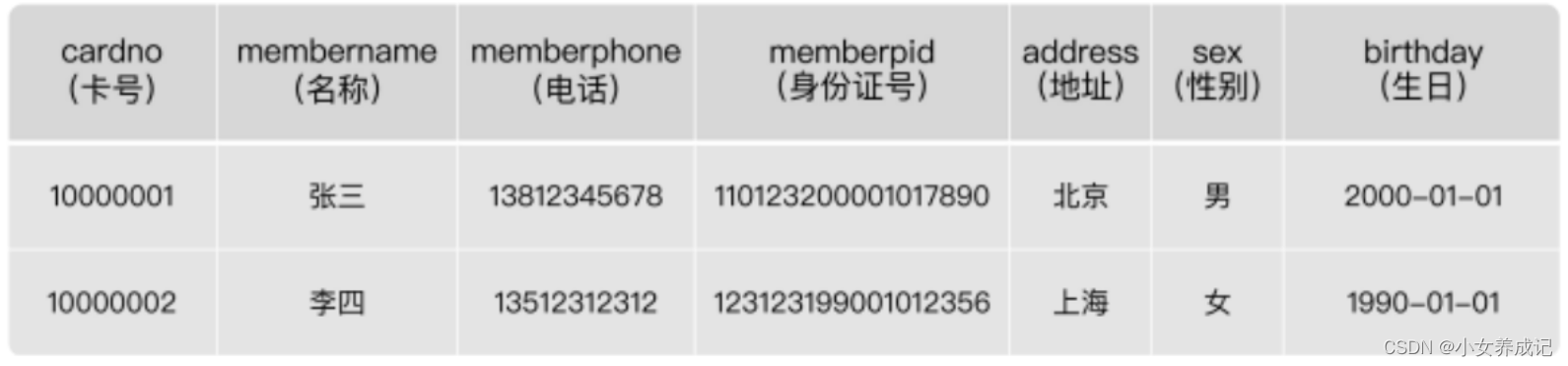
在这个表里,哪个字段比较合适呢?
选择卡号(cardno)
会员卡号(cardno)看起来比较合适,因为会员卡号不能为空,而且有唯一性,可以用来 标识一条会员记录。
不同的会员卡号对应不同的会员,字段“cardno”唯一地标识某一个会员。如果都是这样,会员卡号与会 员一一对应,系统是可以正常运行的。 但实际情况是, 会员卡号可能存在重复使用 的情况。比如,张三因为工作变动搬离了原来的地址,不再 到商家的门店消费了 (退还了会员卡),于是张三就不再是这个商家门店的会员了。但是,商家不想让 这个会 员卡空着,就把卡号是“10000001”的会员卡发给了王五。
从系统设计的角度看,这个变化只是修改了会员信息表中的卡号是“10000001”这个会员 信息,并不会影响到数据一致性。也就是说,修改会员卡号是“10000001”的会员信息, 系统的各个模块,都会获取到修改后的会员信息,不会出现“有的模块获取到修改之前的会员信息,有的模块获取到修改后的会员信息, 而导致系统内部数据不一致”的情况。因此,从 信息系统层面 上看是没问题的。
但是从使用 系统的业务层面 来看,就有很大的问题 了,会对商家造成影响。
会员电话可以做主键吗?
不行的。在实际操作中,手机号也存在 被运营商收回 ,重新发给别人用的情况。
那身份证号行不行呢?
好像可以。因为身份证决不会重复,身份证号与一个人存在一一对 应的关系。可 问题是,身份证号属于 个人隐私 ,顾客不一定愿意给你。要是强制要求会员必须登记身份证号,会把很 多客人赶跑的。其实,客户电话也有这个问题,这也是我们在设计会员信息表的时候,允许身份证号和 电话都为空的原因。
所以,建议尽量不要用跟业务有关的字段做主键。毕竟,作为项目设计的技术人员,我们谁也无法预测在项目的整个生命周期中,哪个业务字段会因为项目的业务需求而有重复,或者重用之类的情况出现。
4. 淘宝的主键设计
在淘宝的电商业务中,订单服务是一个核心业务。请问, 订单表的主键 淘宝是如何设计的呢?是自增ID 吗? 打开淘宝,看一下订单信息:
1550672064762308113
1481195847180308113
1431156171142308113
1431146631521308113
订单号不是自增ID!我们详细看下上述4个订单号: 订单号是19位的长度,且订单的最后5位都是一样的,都是08113。且订单号的前面14位部分是单调递增的。 大胆猜测,淘宝的订单ID设计应该是:
订单ID = 时间 + 去重字段 + 用户ID后6位尾号
这样的设计能做到全局唯一,且对分布式系统查询及其友好。
5. 推荐的主键设计
非核心业务 :对应表的主键自增ID,如告警、日志、监控等信息。
核心业务 :主键设计至少应该是全局唯一且是单调递增。全局唯一保证在各系统之间都是唯一的,单调递增是希望插入时不影响数据库性能。
这里推荐最简单的一种主键设计:UUID。
UUID的特点: 全局唯一,占用36字节,数据无序,插入性能差。
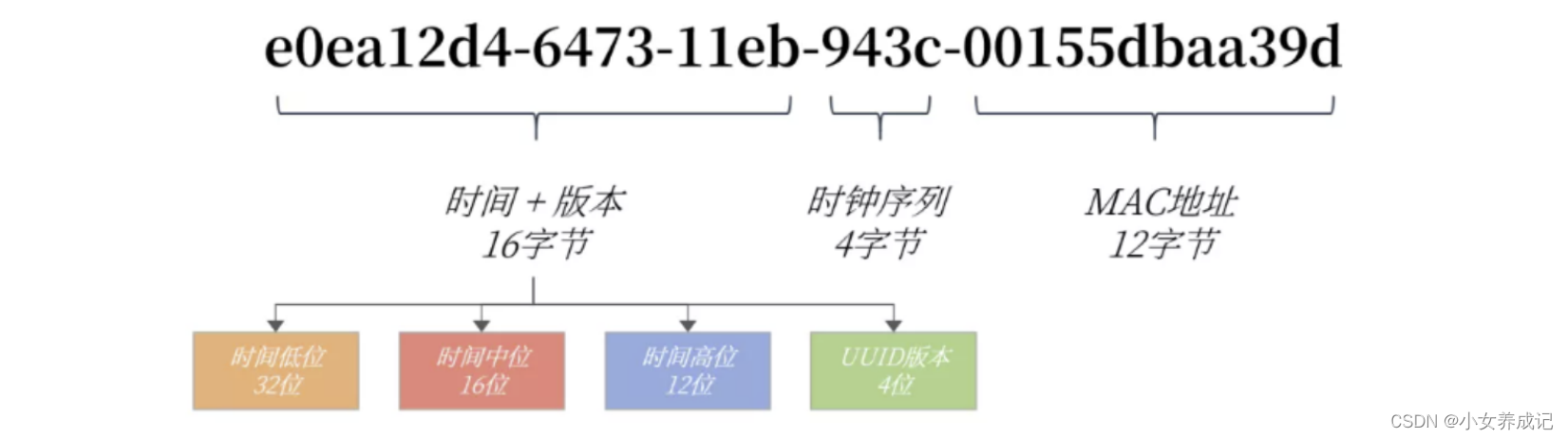
MySQL数据库的UUID组成如下所示:
UUID = 时间+UUID版本(16字节)- 时钟序列(4字节) - MAC地址(12字节)
我们以UUID值e0ea12d4-6473-11eb-943c-00155dbaa39d举例:
1、为什么UUID是全局唯一的?
在UUID中时间部分占用60位,存储的类似TIMESTAMP的时间戳,但表示的是从1582-10-15 00:00:00.00 到现在的100ns的计数。可以看到UUID存储的时间精度比TIMESTAMPE更高,时间维度发生重复的概率降低到1/100ns。 时钟序列是为了避免时钟被回拨导致产生时间重复的可能性。MAC地址用于全局唯一。
2、为什么UUID占用36个字节?
UUID根据字符串进行存储,设计时还带有无用"-"字符串,因此总共需要36个字节。
3、为什么UUID是随机无序的呢?
因为UUID的设计中,将时间低位放在最前面,而这部分的数据是一直在变化的,并且是无序。
4、改造UUID
若将时间高低位互换,则时间就是单调递增的了,也就变得单调递增了。
MySQL 8.0可以更换时间低位和 时间高位的存储方式,这样UUID就是有序的UUID了。 MySQL 8.0还解决了UUID存在的空间占用的问题,除去了UUID字符串中无意义的"-"字符串,并且将字符 串用二进制类型保存,这样存储空间降低为了16字节。
可以通过MySQL8.0提供的uuid_to_bin函数实现上述功能,同样的,MySQL也提供了bin_to_uuid函数进行 转化:
SET @uuid = UUID();
SELECT @uuid,uuid_to_bin(@uuid),uuid_to_bin(@uuid,TRUE);
通过函数uuid_to_bin(@uuid,true)将UUID转化为有序UUID了。全局唯一 + 单调递增,这不就是我们想要 的主键!
在当今的互联网环境中,非常不推荐自增ID作为主键的数据库设计。更推荐类似有序UUID的全局唯一的实现。 另外在真实的业务系统中,主键还可以加入业务和系统属性,如用户的尾号,机房的信息等。这样 的主键设计就更为考验架构师的水平了。
5、如果不是MySQL8.0 肿么办?
手动赋值字段做主键! 比如,设计各个分店的会员表的主键,因为如果每台机器各自产生的数据需要合并,就可能会出现主键重复的问题。
可以在总部 MySQL 数据库中,有一个管理信息表,在这个表中添加一个字段,专门用来记录当前会员编号的最大值。
门店在添加会员的时候,先到总部 MySQL 数据库中获取这个最大值,在这个基础上加 1,然后用这个值 作为新会员的“id”,同时,更新总部 MySQL 数据库管理信息表中的当 前会员编号的最大值。
这样一来,各个门店添加会员的时候,都对同一个总部 MySQL 数据库中的数据表字段进行操作,就解决了各门店添加会员时会员编号冲突的问题。