ϵ������Ŀ¼
- ��ʶ�Ƽ�ϵͳ��������Sparkƽ̨��Эͬ����ʵʱ��Ӱ�Ƽ�ϵͳ��Ŀϵ�в���(һ)
- �����û���Ϊ���ݡ�������Sparkƽ̨��Эͬ����ʵʱ��Ӱ�Ƽ�ϵͳ��Ŀϵ�в���(��)
- ��Ŀ��ҪЧ��չʾ��������Sparkƽ̨��Эͬ����ʵʱ��Ӱ�Ƽ�ϵͳ��Ŀϵ�в���(��)
- ��Ŀ��ϵ�ܹ���ơ�������Sparkƽ̨��Эͬ����ʵʱ��Ӱ�Ƽ�ϵͳ��Ŀϵ�в���(��)
- ����
��Ŀ��Դ����
- ��Ӱ�Ƽ�ϵͳ��վ��ĿԴ��Github��ַ(��Fork��Clone)
- ��Ӱ�Ƽ�ϵͳ��վ��ĿԴ��Gitee��ַ(��Fork��Clone)
- ��Ӱ�Ƽ�ϵͳ��վ��ĿԴ��ѹ��������(ֱ��ʹ��)
- ��Ӱ�Ƽ�ϵͳ��վ��ĿԴ������ȫ�����ߺϼ��������(spark��kafka��flume��tomcat��azkaban��elasticsearch��zookeeper)
- ��Ӱ�Ƽ�ϵͳ��վ��ĿԴ����(��ֱ��ʹ��)
- ��Ӱ�Ƽ�ϵͳ��վ��Ŀ����ԭ������
- ��Ӱ�Ƽ�ϵͳ��վ��Ŀǰ�˴���
- ��Ӱ�Ƽ�ϵͳ��վ��Ŀǰ��css����
ǰ��
??�������Ҵ���������Ŀ��ϵ�ܹ����,������Ŀϵͳ�ܹ�����Ŀ�������̡�����ģ�͵ȡ��Լ�����ϵͳ��������ģ������ô����������,���и�����������ô���ϵ�,����Ҫ�������ݿ�ģ�͵����,������ݿ���Ʋ���,��ֱ��Ӱ���������ϵͳ������,����Ϳ�ʼ�����ѧϰ��!
һ��ϵͳ�ܹ�
??��Ŀ���Ƽ�ϵͳ��������֪���ľ����Ĺ���
M
o
v
i
e
L
e
n
s
MovieLens
MovieLens���ݼ���Ϊ����,������������Ӱ�Ƽ�ϵͳ,�����������Ƽ���ʵʱ�Ƽ���ϵ,�ۺ�������Эͬ�����㷨�Լ��������ݵ��Ƽ��������ṩ����Ƽ����ṩ�˴�ǰ��Ӧ�á���̨�������㷨���ʵ�֡�ƽ̨����ȶλ�ıջ���ҵ��ʵ��

1.1 ��̨����
- �û����ӻ�:��Ҫ����ʵ�ֺ��û��Ľ����Լ�ҵ�����ݵ�չʾ,�������
A
n
g
u
l
a
r
J
S
2
AngularJS2
AngularJS2����ʵ��,������
A
p
a
c
h
e
Apache
Apache������
- �ۺ�ҵ�����:��Ҫʵ��
J
a
v
a
E
E
JavaEE
JavaEE���������ҵ����,ͨ��
S
p
r
i
n
g
Spring
Spring���й���,�Խ�ҵ����������
T
o
m
c
a
t
Tomcat
Tomcat��
1.2 ���ݴ洢����
- ҵ�����ݿ�:��Ŀ���ù㷺Ӧ�õ��ĵ����ݿ�
M
o
n
g
D
B
MongDB
MongDB��Ϊ�����ݿ�,��Ҫ����ƽ̨ҵ�������ݵĴ洢
- ����������:��Ŀ����
E
l
a
s
t
i
c
S
e
a
r
c
h
ElasticSearch
ElasticSearch��Ϊģ������������,ͨ������
E
S
ES
ESǿ���ƥ���ѯ����ʵ�ֻ������ݵ��Ƽ�����
- �������ݿ�:��Ŀ����
R
e
d
i
s
Redis
Redis��Ϊ���������,��Ҫ����֧��ʵʱ�Ƽ�ϵͳ���ֶ������ݵĸ��ٻ�ȡ����
1.3 �����Ƽ�����
- ����ͳ�Ʒ���:������ͳ����ҵ�����
S
p
a
r
k
C
o
r
e
+
S
p
a
r
k
S
q
l
Spark \quad Core \quad + \quad Spark \quad Sql
SparkCore+SparkSql����ʵ��,ʵ�ֶ�ָ�������ݵ�ͳ������
- �����Ƽ�����:�����Ƽ�ҵ�����
S
p
a
r
k
C
o
r
e
+
S
p
a
r
k
M
L
l
i
b
Spark \quad Core + Spark \quad MLlib
SparkCore+SparkMLlib����ʵ��,����ALS�㷨����ʵ�֡�
- �������ȷ���:���������Ƽ�������Ҫ��һ����ʱ��Ƶ�ʶ��㷨���е���,����
A
z
k
a
b
a
n
Azkaban
Azkaban��������ĵ���
1.4 ʵʱ�Ƽ�����
- ��־�ɼ�����:ͨ������
F
l
u
m
e
?
n
g
Flume-ng
Flume?ng��ҵ��ƽ̨���û��Ե�Ӱ��һ��������Ϊ���вɼ�,ʵʱ���͵�
K
a
f
k
a
Kafka
Kafka��Ⱥ
- ��Ϣ�������:��Ŀ����
K
a
f
k
a
Kafka
Kafka��Ϊ��ʽ���ݵĻ������,��������
F
l
u
m
e
Flume
Flume�����ݲɼ��������������͵���Ŀ��ʵʱ�Ƽ�ϵͳ����
- ʵʱ�Ƽ�����:��Ŀ����
S
p
a
r
k
S
t
r
e
a
m
i
n
g
Spark \quad Streaming
SparkStreaming��Ϊʵʱ�Ƽ�����,ͨ������
K
a
f
k
a
Kafka
Kafka�л��������,ͨ����Ƶ��Ƽ��㷨ʵ�ֶ�ʵʱ�Ƽ������ݴ���,�����ṹ�ϲ����µ�
M
o
n
g
o
D
B
MongoDB
MongoDB���ݿ�
������������
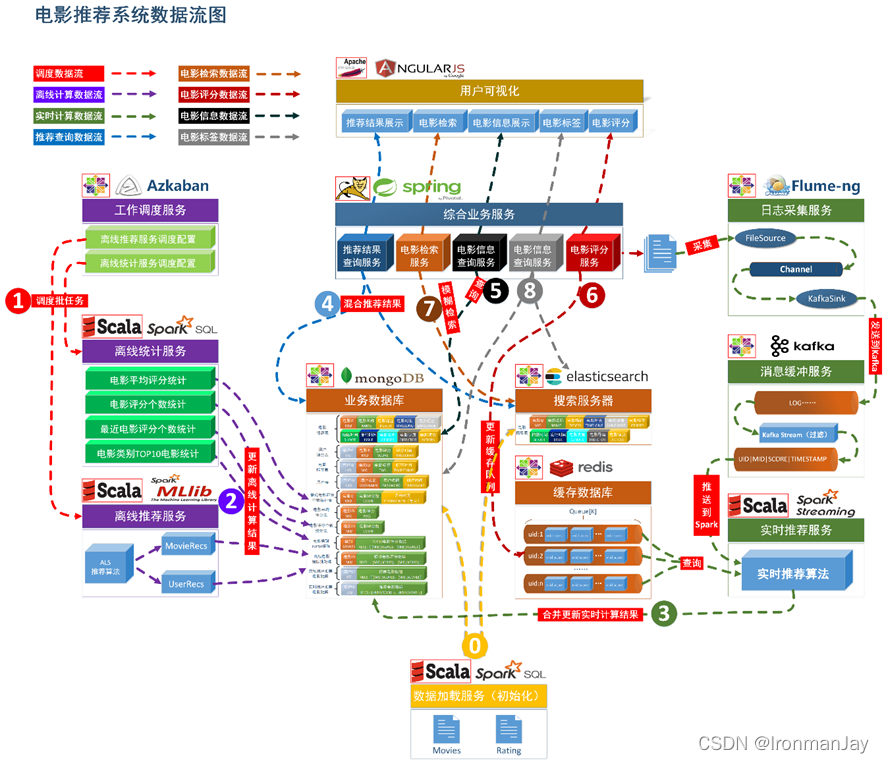
2.1 ϵͳ��ʼ������
- ͨ��
S
p
a
r
k
S
Q
L
Spark \quad SQL
SparkSQL��ϵͳ��ʼ�����ݼ��ص�
M
o
n
g
o
D
B
MongoDB
MongoDB��
E
l
a
s
t
i
c
S
e
a
r
c
h
ElasticSearch
ElasticSearch��
2.2 �����Ƽ�����
- ͨ��
A
z
k
a
b
a
n
Azkaban
Azkabanʵ�ֶ�������ͳ�Ʒ����������Ƽ�����ĵ��ȡ�ͨ���趨������ʱ����ɶ�����Ĵ���ִ��
- ����ͳ�Ʒ����
M
o
n
g
o
D
B
MongoDB
MongoDB�м�������,����Ӱƽ������ͳ�ơ���Ӱ���ָ���ͳ�ơ������Ӱ���ָ���ͳ������ͳ���㷨��������ʵ��,������������д��
M
o
n
g
o
D
B
MongoDB
MongoDB��,�����Ƽ������
M
o
n
g
o
D
B
MongoDB
MongoDB�м�������,ͨ��
A
L
S
ALS
ALS�㷨�ֱ��û��Ƽ��������ӰƬ���ƶȾ����д��
M
o
n
g
o
D
B
MongoDB
MongoDB��
2.3 ʵʱ�Ƽ�����
-
F
l
u
m
e
Flume
Flume���ۺ�ҵ������������־�ж�ȡ��־����,�������µ���־ʵʱ���͵�
K
a
f
k
a
Kafka
Kafka��,
K
a
f
k
a
Kafka
Kafka���յ���Щ��־��,ͨ��
K
a
f
k
a
S
t
r
e
a
m
KafkaStream
KafkaStream����Ի�ȡ����־��Ϣ���й��˴���,��ȡ�û�����������:
U
I
D
�O
M
I
D
�O
S
C
O
R
E
�O
T
I
M
E
S
T
A
M
P
UID|MID|SCORE|TIMESTAMP
UID�OMID�OSCORE�OTIMESTAMP,�����͵���һ��
K
a
f
k
a
Kafka
Kafka����,
S
p
a
r
k
S
t
r
e
a
m
i
n
g
Spark \quad Streaming
SparkStreaming����
K
a
f
k
a
Kafka
Kafka����,ʵʱ��ȡ
K
a
f
k
a
Kafka
Kafka���˵ij������û�����������,�ںϴ洢��
R
e
d
i
s
Redis
Redis�е��û�������ֶ�������,�ύ��ʵʱ�Ƽ��㷨,��ɶ��û��µ��Ƽ��������,������ɺ�,���µ��Ƽ������
M
o
n
g
o
D
B
MongoDB
MongoDB���ݿ��е��Ƽ�������кϲ�
2.4 ҵ��ϵͳ����
- �Ƽ����չʾ���ִ�
M
o
n
g
o
D
B
MongoDB
MongoDB��
E
l
a
s
t
i
c
S
e
a
r
c
h
ElasticSearch
ElasticSearch�н������Ƽ������ʵʱ�Ƽ�����������Ƽ�������л��,�ۺϸ������Ӧ������
- ��Ӱ��Ϣ��ѯ����ͨ���Խ�
M
o
n
g
o
D
B
MongoDB
MongoDBʵ�ֶԵ�Ӱ��Ϣ�IJ�ѯ����
- ��Ӱ���ֲ���ͨ����ȡ�û�ͨ��
U
I
UI
UI���������ֶ���,��̨����������ݿ��¼��,һ���潫�������͵�
R
e
d
i
s
Redis
Redis��,��һ����,ͨ��Ԥ�����־��������
T
o
m
c
a
t
Tomcat
Tomcat�е���־��
- ��Ŀͨ��
E
l
a
s
t
i
c
S
e
a
r
c
h
ElasticSearch
ElasticSearchʵ�ֶԵ�Ӱ��ģ������
- ��Ӱ��ǩ����,��Ŀ�ṩ�û��Ե�Ӱ���ǩ����
��������ģ��
3.1 ��Ӱ���ݱ�
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| mid | Int | ��Ӱ��ID | | | name | String | ��Ӱ������ | | | descri | String | ��Ӱ������ | | | timelong | String | ��Ӱ��ʱ�� | | | shoot | String | ��Ӱ����ʱ�� | | | issue | String | ��Ӱ����ʱ�� | | | language | String | ��Ӱ���� | | | genres | String | ��Ӱ������� | | | director | String | ��Ӱ�ĵ��� | | | actors | String | ��Ӱ����Ա | |
3.2 �û����ֱ�
-
R
a
t
i
n
g
Rating
Rating
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| uid | Int | �û���ID | | | mid | Int | ��Ӱ��ID | | | score | Double | ��Ӱ�ķ�ֵ | | | timestamp | Long | ���ֵ�ʱ�� | |
3.3 ��Ӱ��ǩ��
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| uid | Int | �û���ID | | | mid | Int | ��Ӱ��ID | | | tag | String | ��Ӱ�ı�ǩ | | | timestamp | Long | ���ֵ�ʱ�� | |
3.4 �û���
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| uid | Int | �û���ID | | | username | String | �û��� | | | password | String | �û����� | | | first | boolean | �����Ƿ��һ�ε�¼ | | | genres | List | �û�ƫ���ĵ�Ӱ���� | | | timestamp | Long | �û�������ʱ�� | |
3.5 �����Ӱ���ָ���ͳ�Ʊ�
-
R
a
t
e
M
o
r
e
M
o
v
i
e
s
R
e
c
e
n
t
l
y
RateMoreMoviesRecently
RateMoreMoviesRecently
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| mid | Int | ��Ӱ��ID | | | count | Int | ��Ӱ�������� | | | yeahmonth | String | ���ֵ�ʱ�� | 201507 |
3.6 ��Ӱ���ָ���ͳ�Ʊ�
-
R
a
t
e
M
o
r
e
M
o
v
i
e
s
RateMoreMovies
RateMoreMovies
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| mid | Int | ��Ӱ��ID | | | count | Int | ��Ӱ�������� | |
3.7 ��Ӱƽ�����ֱ�
-
A
v
e
r
a
g
e
M
o
v
i
e
s
S
c
o
r
e
AverageMoviesScore
AverageMoviesScore
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| mid | Int | ��Ӱ��ID | | | avg | Double | ��Ӱ��ƽ������ | |
3.8 ��Ӱ�����Ծ���
-
M
o
v
i
e
R
e
c
s
MovieRecs
MovieRecs
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| mid | Int | ��Ӱ��ID | | | recs | Array[(mid:Int,score:Double)] | �õ�Ӱ�����Ƶĵ�Ӱ���� | |
3.9 �û���Ӱ�Ƽ�����
-
U
s
e
r
R
e
c
s
UserRecs
UserRecs
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| uid | Int | �û���ID | | | recs | Array[(mid:Int,score:Double)] | �Ƽ������û��ĵ�Ӱ���� | |
3.10 �û�ʵʱ��Ӱ�Ƽ�����
-
S
t
r
e
a
m
R
e
c
s
StreamRecs
StreamRecs
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| uid | Int | �û���ID | | | recs | Array[(mid:Int,score:Double)] | ʵʱ�Ƽ������û��ĵ�Ӱ���� | |
3.11 ��Ӱ���
T
o
p
10
Top10
Top10
-
G
e
n
r
e
s
T
o
p
M
o
v
i
e
s
GenresTopMovies
GenresTopMovies
| �ֶ��� | �ֶ����� | �ֶ����� | �ֶα�ע |
|---|
| genres | String | ��Ӱ���� | | | recs | Array[(mid:Int,score:Double)] | TOP10��Ӱ | |
�ܽ�
??��ƪ����Ҳ���ڽ�����,��ƪ������Ҫ���ܵ�������ϵͳ�ļܹ�����Լ�����ϵͳ���������̺�����ģ��,ֻ����ƺ���Щ,����ϵͳ�Ĵ���ܱȽ�˳��,�����Ҫ�浶��ǹ��������ϵͳ��,��һƪ���»����Ҵ�����Ŀ�Ļ��������!
|