导读: 大家好我是胖子,我想我们大家都知道Flink是有状态的实时计算引擎,很多人不理解一个计算引擎应该怎么做呢,其实这就涉及到了Flink的核心,也就是它的应用程序抽象,我们都知道Flink会将我们编写的程序来进行转换成一个图,接着会进行优化,以及转换成一些可执行的图。可是你真的认真的理解这些问题了吗?接下来就让我带大家走进Flink的程序抽象,同时我们也会简单的根据源码来让大家理解。相信通过观看这篇文章,可以让大家理解以下几个知识点,并且为以后观看Flink源码打下坚实的基础,可以让大家更好的理解Flink,以及在面试过程中遇到的一些问题可以和面试官聊一聊。
- Flink 图的转换流程,怎么做的?
- 你的程序是如何转换成图的?
- 并行度到底代表了什么意思?
- Operator Chain是什么意思?
- Flink的数据分发策略是什么,代表了什么意思?
01 Stream Graph
我们打开Flink源码,其中有一个example是WordCount,我想大家应该都知道,我们就来看看这个WordCount做了什么,我把源码中一些不必要的部分都进行了一些删减,只要大概意思了解即可。
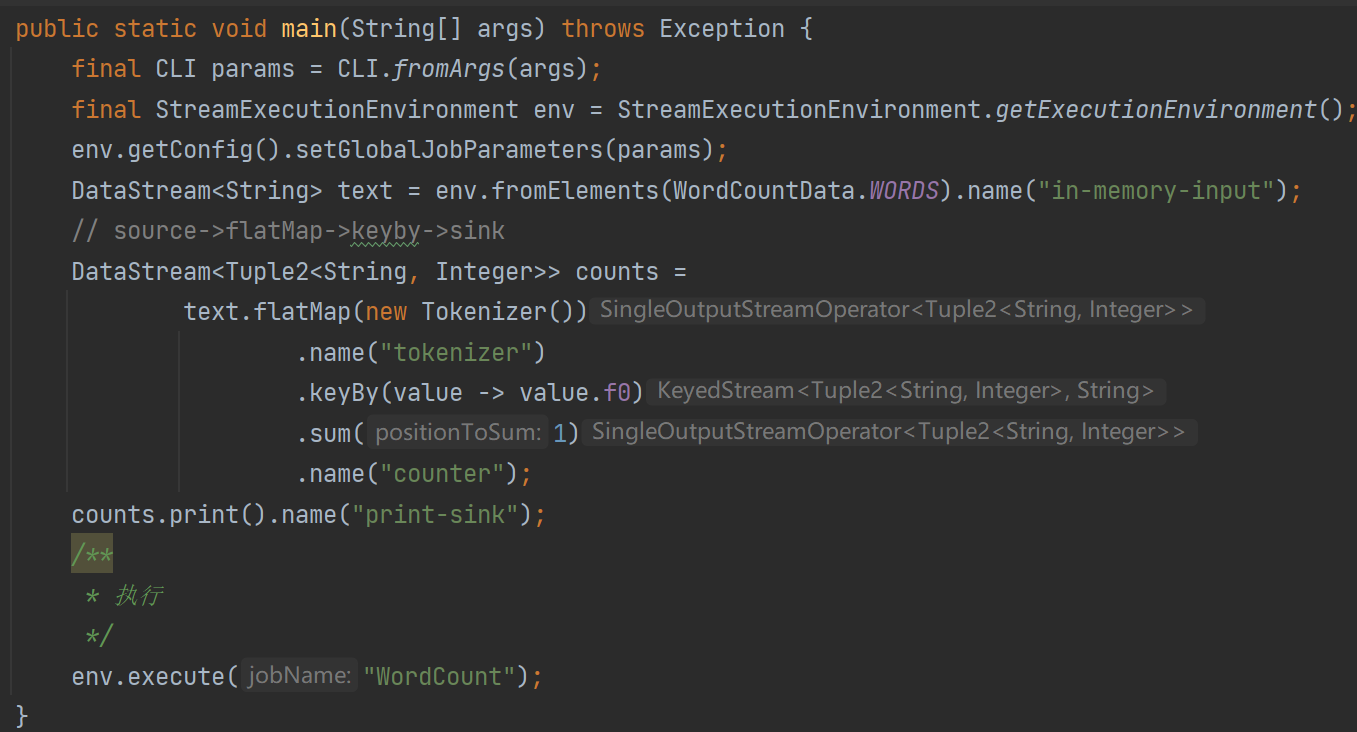
我们可以很明确的看到这里写的什么,走了那些算子,其实Flink算子有三个抽象,Source->Transformation->Sink。而上面这个程序的执行流程就是source->flatMap->keyby->sink。无非就是计算wordcount。我相信大家已经理解了这个程序,那么我们就看看Stream Graph长什么样子。

我们一看到这一张图,我们就懵逼了,这个到底啥意思啊,什么是StreamNode、什么是StreamEdge?
那么我就深入源码看一看,他是怎么生成的图。
public <R> SingleOutputStreamOperator<R> flatMap(
FlatMapFunction<T, R> flatMapper, TypeInformation<R> outputType) {
/**
* 将FlatMapFunction 转换成 StreamFlatMap
* StreamFlatMap 是什么呢?
* 我们可以看看他的类图
*/
return transform("Flat Map", outputType, new StreamFlatMap<>(clean(flatMapper)));
}
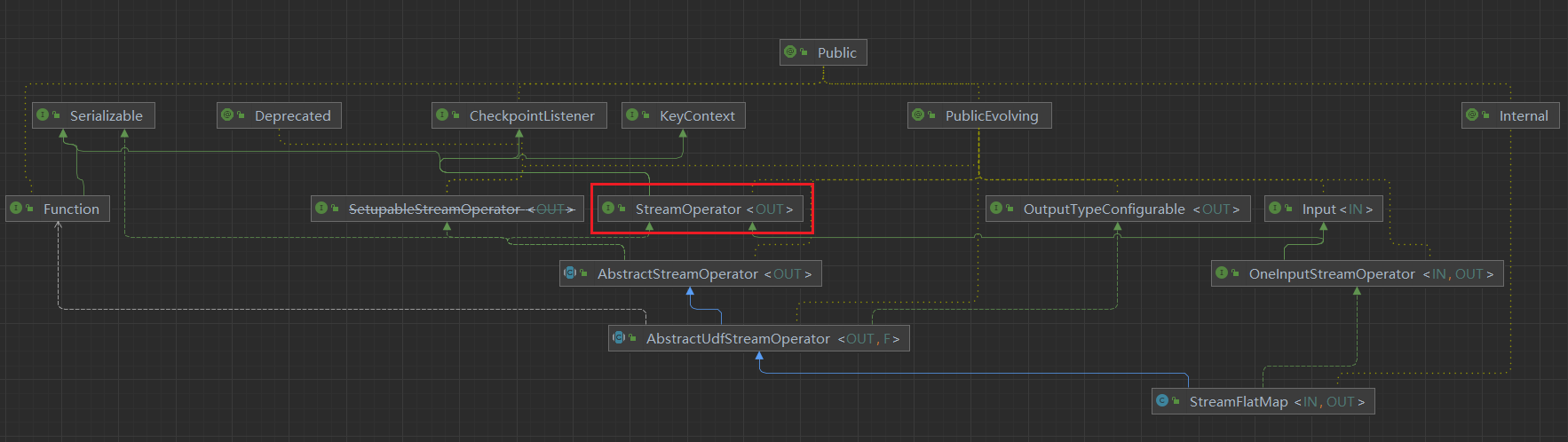
通过我们的类图也就知道了他是一个StreamOperator,这里我们已经看出来了一些东西,Flink将我们用户编写的算子代码Function->StreamOperator。
public <R> SingleOutputStreamOperator<R> transform(
String operatorName,
TypeInformation<R> outTypeInfo,
OneInputStreamOperator<T, R> operator) {
/**
* 将我们编写的算子封装成了OperatorFactory
*/
return doTransform(operatorName, outTypeInfo, SimpleOperatorFactory.of(operator));
}
此时我们可以明确的看到,将我们的算子转换成了SimpleOperatorFactory
也就有了以下的转换逻辑 User Function-> StreamOperator->OperatorFactory
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R> outTypeInfo,
StreamOperatorFactory<R> operatorFactory) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
/**
* 将operatorFactory 转换为 Transformation
*/
OneInputTransformation<T, R> resultTransform =
new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream =
new SingleOutputStreamOperator(environment, resultTransform);
/**
* 将Transformation添加到Operator中
*/
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
我们又看到了doTransform将我们的Factory转换成了一个Transformation
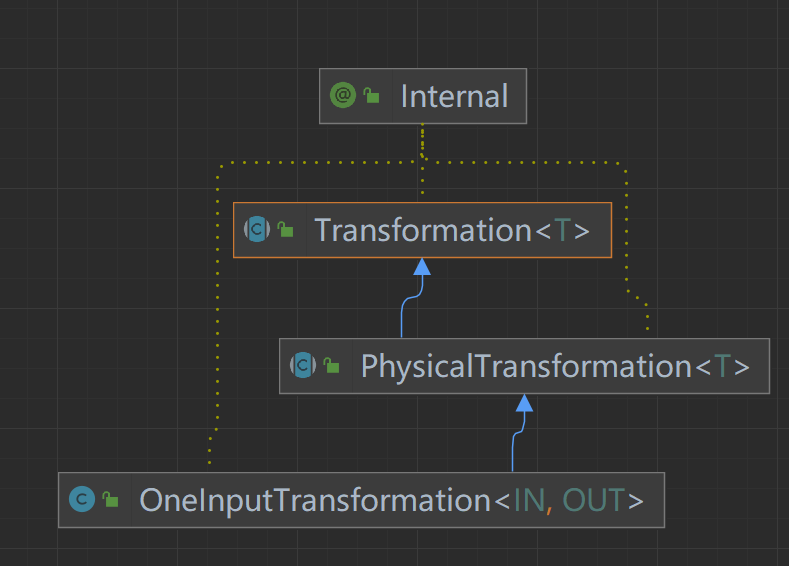
那么他把我们的算子添加到哪里去了呢
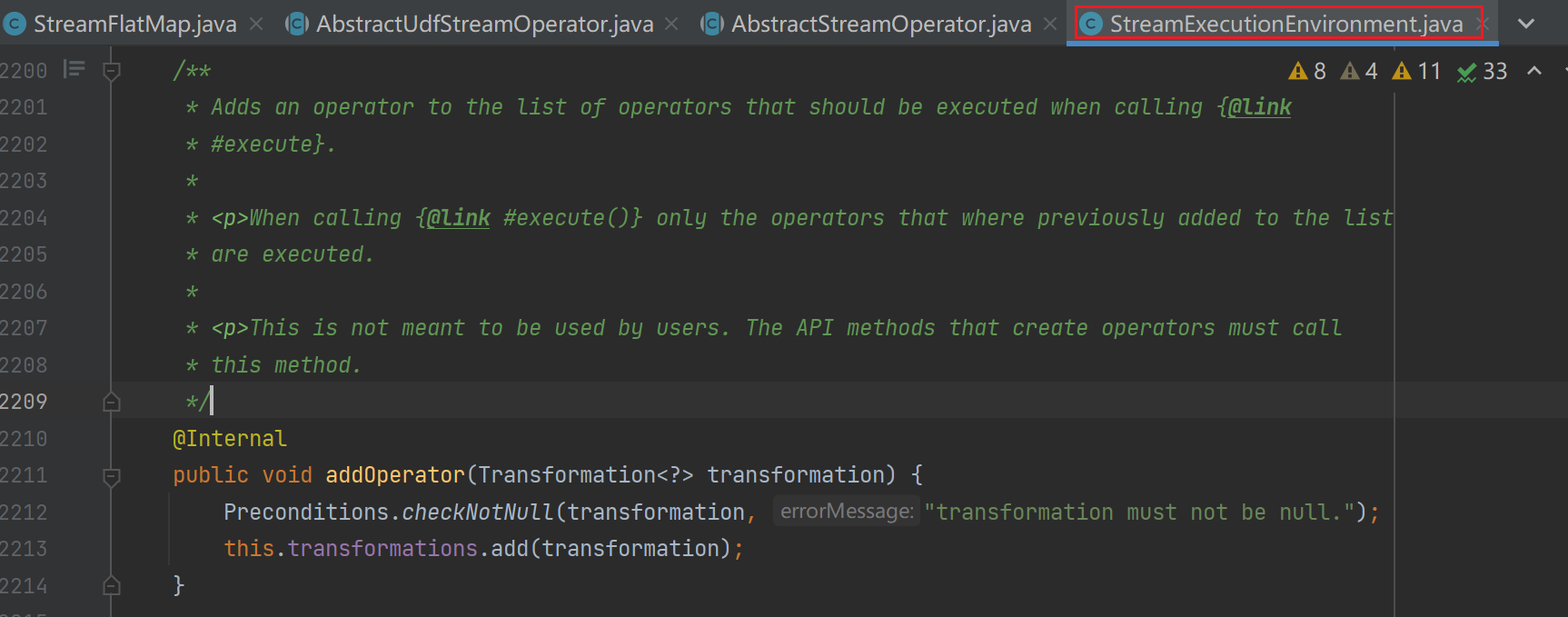
我靠,他把我们的用户代码封装成Transforamtion然后添加到env中的一个数据结构中,那么我们就看一下env.exectue();
public JobExecutionResult execute(String jobName) throws Exception {
Preconditions.checkNotNull(jobName, "Streaming Job name should not be null.");
final StreamGraph streamGraph = getStreamGraph();
streamGraph.setJobName(jobName);
return execute(streamGraph);
}
真相大白,StreamGraph实在Env中进行获取的,那么他是怎么转换成StreamNode的呢。
protected StreamNode addNode(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
Class<? extends TaskInvokable> vertexClass,
StreamOperatorFactory<?> operatorFactory,
String operatorName) {
/**
* 用户Function操作 operatorFactory
*/
StreamNode vertex =
new StreamNode(
vertexID,
slotSharingGroup,
coLocationGroup,
operatorFactory,
operatorName,
vertexClass);
streamNodes.put(vertexID, vertex);
return vertex;
}
因为中间逻辑比较多,我们就看结果就好了,我们可以明显的看到我们的operatorFactory 被翻译成了一个SteamNode。
那么这个时候真正的真相大白,StreamNode就是我们的用户算子,我们再来看看这个图。
我们再梳理一下刚才我们看到的源码逻辑,首先用户编写好Function之后,将Function转换为一个StreamOperator接着封装成一个OperatorFactory然后再到Transoformation。最后转变成上图所说的StreamNode,在StreamGraph是不是就可以理解为一个顶点就是一个算子。
那么这个StreamEdge又是干啥的。在这里呢,我们就不太深入的去看源码了,我们看看StreamNode的定义就好了。

我们可以明显的看到StreamNode中有两个List分别为入边集合和出边集合。
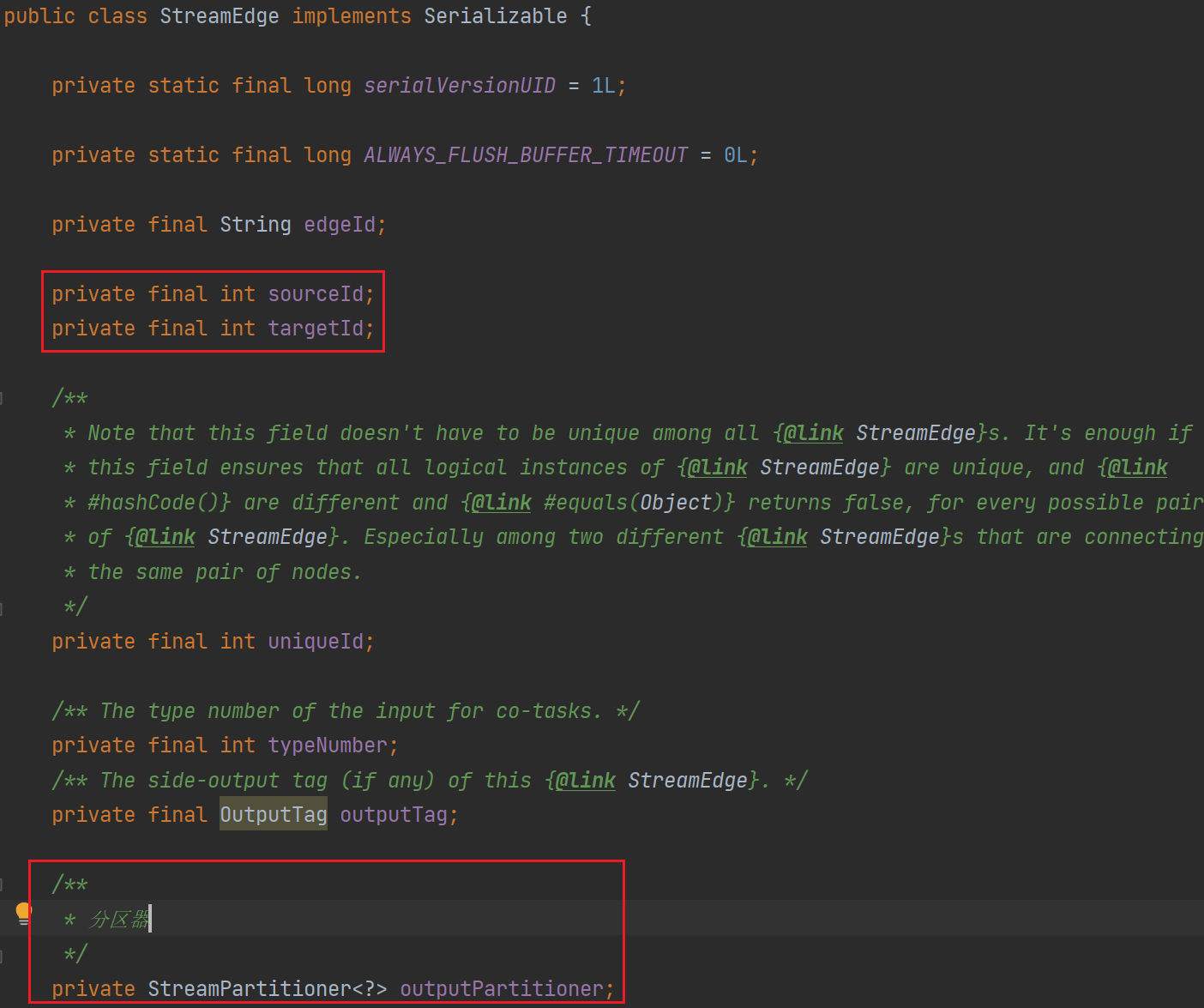
这时我们就看到了StreamEdge连接了顶点的id,同时也携带有Partitoner,这个是什么呢,就是图上的HashRebalance和Forward。
此处,我在延伸一个知识点:
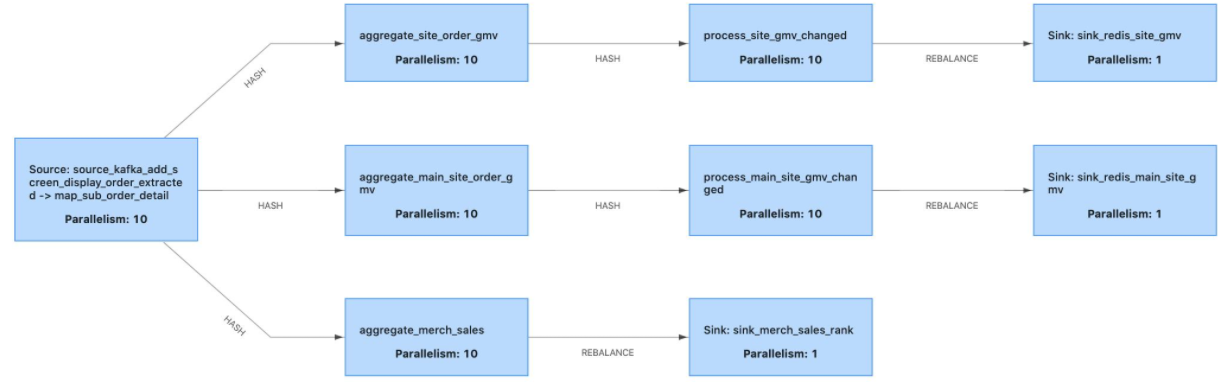
Flink有8种分区策略:
- GlobalPartitioner:永远都发给第一个
- ShufflePartitioner: random 随机发
- RebalancePartitioner: rebalance 下游多个分区的话,先随机一个,后轮训发送
- RescalePartitioner: rescale 的上游操作所发送的元素被分区到下游操作的哪些子集,依赖于上游和下游操作的并行度。例如,如果上游操作的并行度为2,而下游操作的并行度为4,那么一个上游操作会分发元素给两个下游操作,同时另一个上游操作会分发给另两个下游操作。相反的,如果下游操作的并行度为2,而上游操作的并行度为4,那么两个上游操作会分发数据给一个下游操作,同时另两个上游操作会分发数据给另一个下游操作。
- BroadcastPartitioner: broadcast 是广播流专用的分区器
- ForwardPartitioner: forward
- KeyGroupStreamPartitioner: hash 通过hash取值发送数据
- CustomPartitionerWrapper:自定义分区
相信看到这里,我们就对StreamGraph有了深入的理解,此时我们总结一下:
1、StreamNode是通过算子转化而来,也就是我们自己编写的代码处理逻辑。
2、StreamEdge是连接StreamGraph两个顶点的类,其中包含了sourceId和targetId。
3、StreamEdge携带了Partitioner分区策略。
02 JobGraph
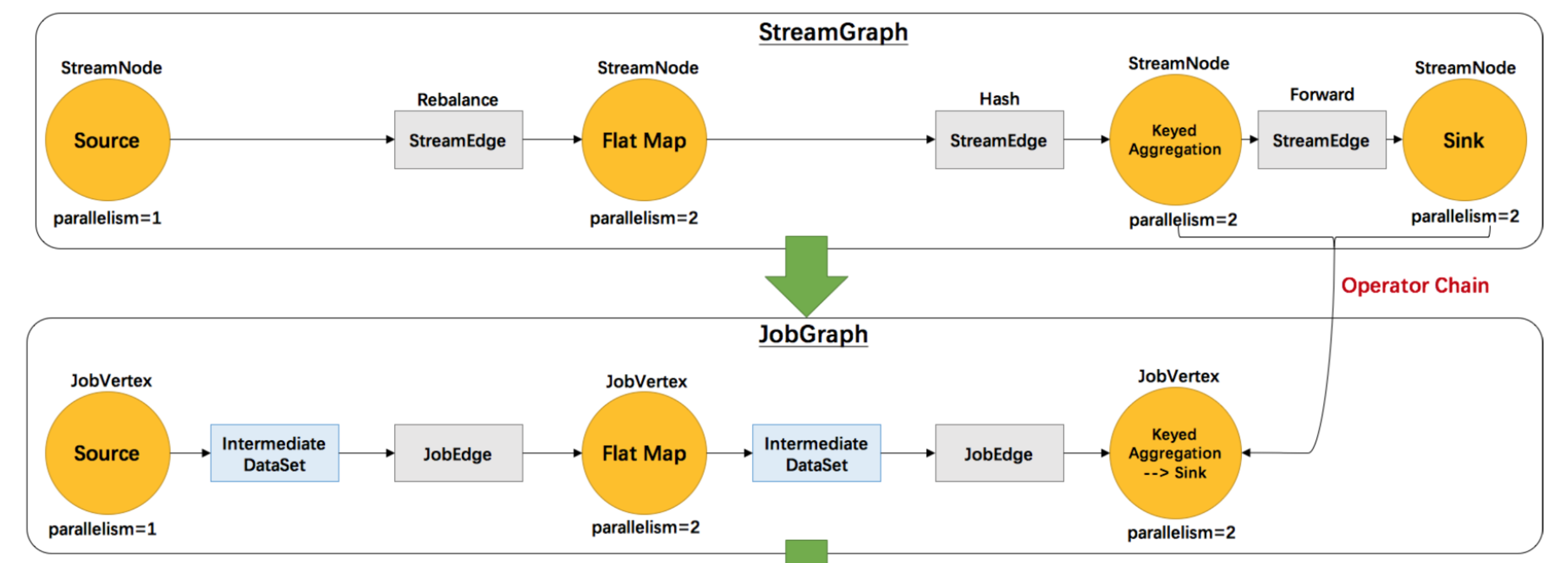
由上图我们看到StreamGraph转化成为JobGraph,为什么会这么说呢?
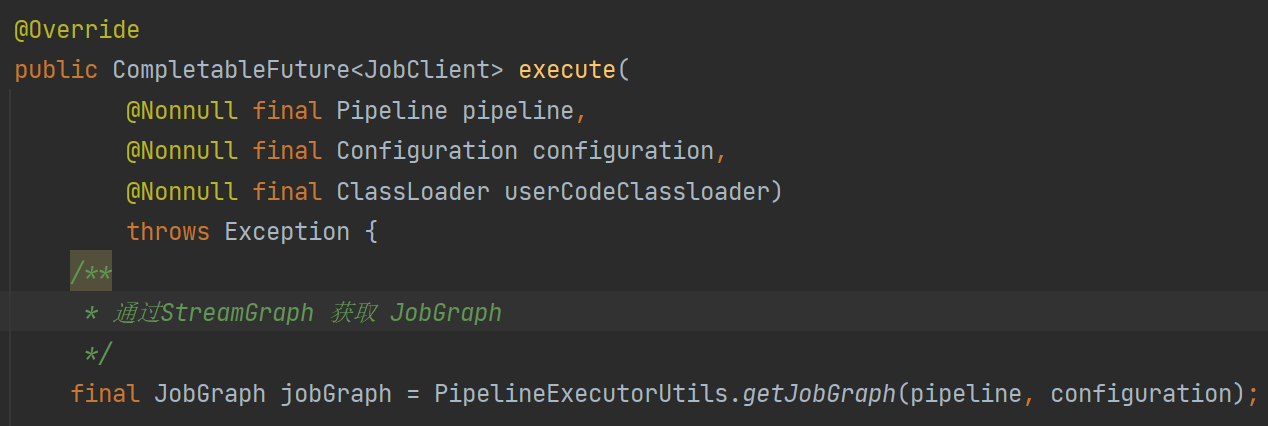
源码中传入pipeline获取JobGraph,那么Pipeline是什么?
Pipeline就是StreamGraph,这个时候我们就知道了JobGraph是通过StreamGraph转化得来的。
在JobGraph其中,将StreamNode转换为JobVertex,StreamEdge转换为了JobEdge,其中还多了一个ItermediateDataSet(中间数据集)这个代表的是每个算子处理后的结果都会生成一个这个数据集。在JobGraph中一个顶点是JobVertex,边为JobEdge。对于一个JobEdge他的生产者是Intermediate,他的消费者是JobVertex。对于JobVertex来说他的生产者是JobEdge,消费者是IntermediateDataSet。这些在源码中都是有体现的。
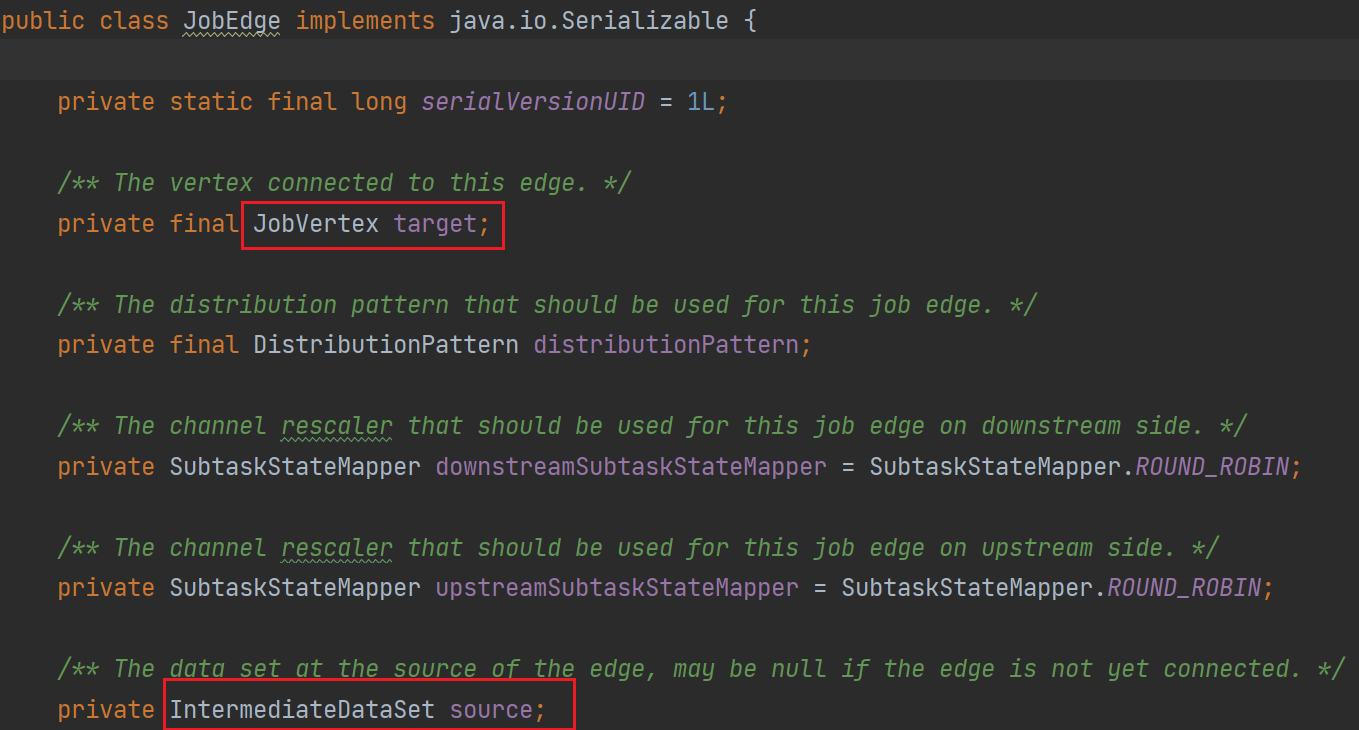
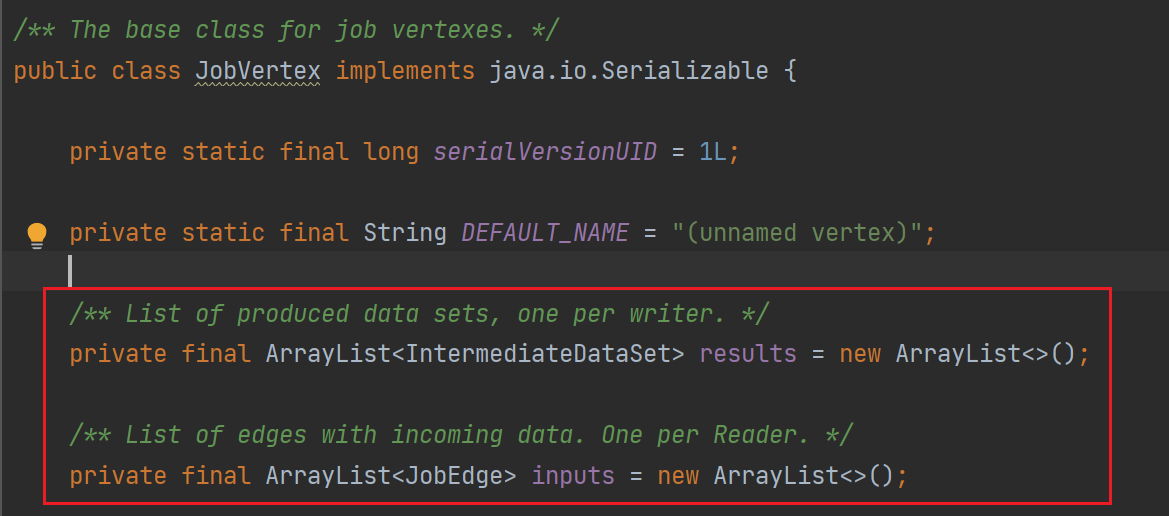
这个时候,我们就理解了其中的一些概念,例如JobEdge、JobVerex、IntermediateDataSet。
其实我们忽略一个操作,那就是JobGraph转换的过程中最主要的优化,也就是OperatorChain的优化。
他会根据每个StreamNode是否满足7个条件,其实有9个但是没必要说啊,如果满足就会合并成一个JobVertex。所以说在JobGraph中对比StreamGraph,它增加了一个优化,就是合并顶点,可以在一起执行的StreamNode我在一起执行,减少网络传输。
那么有哪些条件呢:
- 上下游的并行度一致
- 下游节点的入边为1
- 上下游节点都在同一个slot group中(可以设置,默认在一个里面)
- 下游节点的chain策略为ALWAYS
- 上游的chain策略为ALWAYS或者HEAD(Source是HEAD)
- 两个顶点数据分区方式是forward(如果并行度一致就是forward)
- 用户没有禁用chain
相信看到这里,我们就对JobGraph有了深入的理解,此时我们总结一下:
1、JobVertex是通过StreamNode转换而来,并且进行了OperatorChain的优化(满足9个条件)
2、当JobVertex处理完数据后输出的数据放到IntermediateDataSet中
3、JobEdge的生产者是IntermediateDataSet,消费者是JobVertex
4、JobVertex的生产者是JobEdge,消费者是IntermediateDataSet
03 Execution Graph
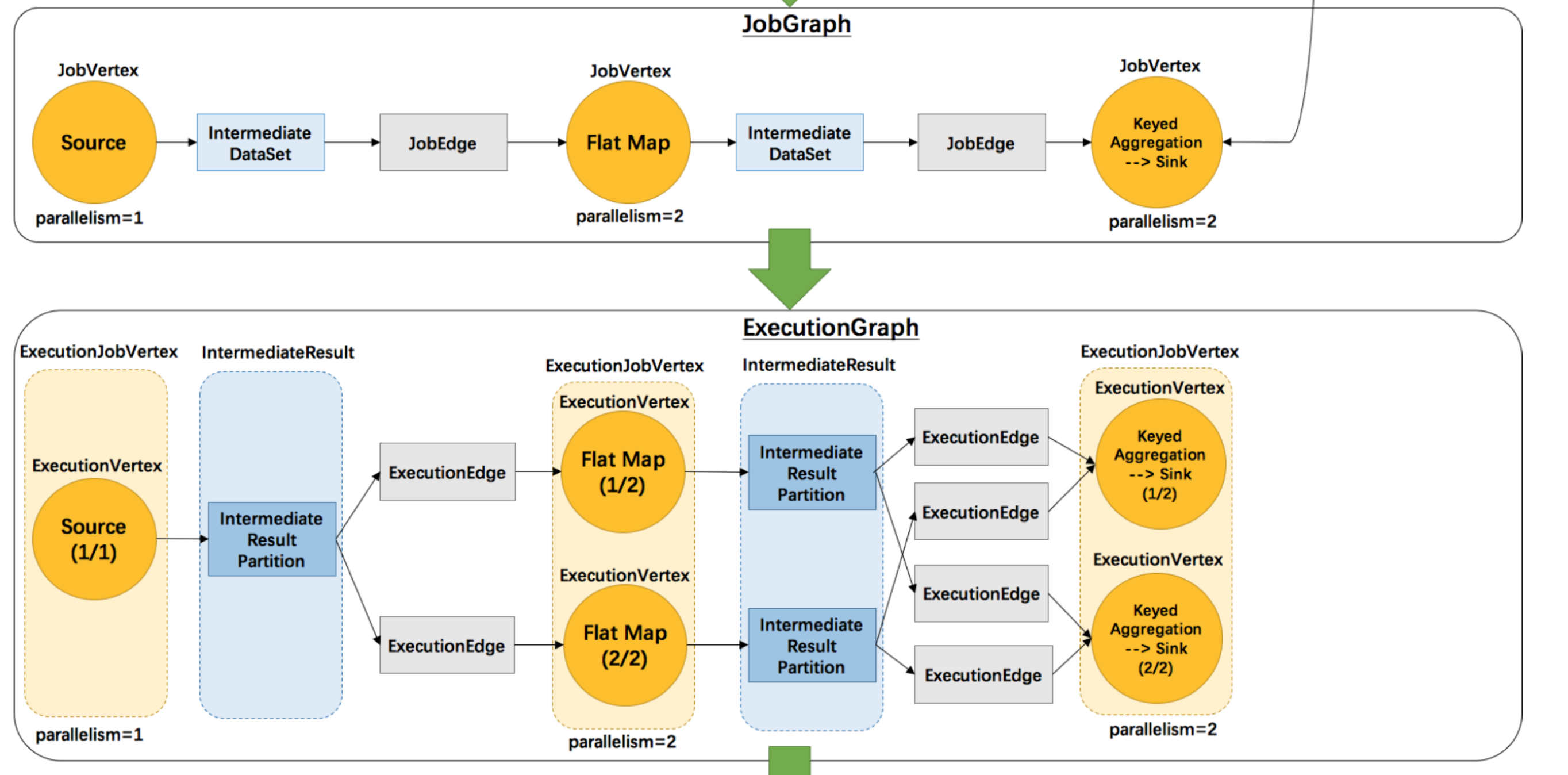
由上图我们看到,一个JobVertex生成一个ExecutionJobVertex,一个IntermediateDataSet生成一个IntermediateResult。JobEdge会生成多个ExecutionEdge。
一个ExecutionJobVertex中会生成多个ExecutionVertex,一个IntermediateReulst会生成多个Intermediate Result Partition。那么根据什么生成的呢,其实在JobGraph和ExecutionGraph中最大的区别就是加入了并行度的概念。
我们简单的分析一下这个ExecutionGraph,我们简单的将ExecutionJobVertex是算子。那么算子根据并行度生成多个子算子来进行处理数据,当子算子处理数据结束后,会将结果放到对应的子算子的结果分区中,然后每个子结果分区根据下游有多少个子算子来生成多少个ExecutionEdge,以此来组成了一张图,这个时候我们就可以结合我们上面分享的数据分区策略来思考一下。
相信看到这里,我们就对ExecutionGraph有了深入的理解,此时我们总结一下:
1、JobGraph和ExecutionGraph中最大的区别就是加入了并行度的概念。
2、当算子加入并行度概念后,会根据并行度的不同,生成不同的边和节点,例如一个Map算子有2个并行度,那么就会生成两个ExecutionVertex同时生成两个Partition,然后根据下游的算子并行度生成1个或者多个ExecutionEdge,然后整个ExecutionGraph构建出来。
04 物理执行图
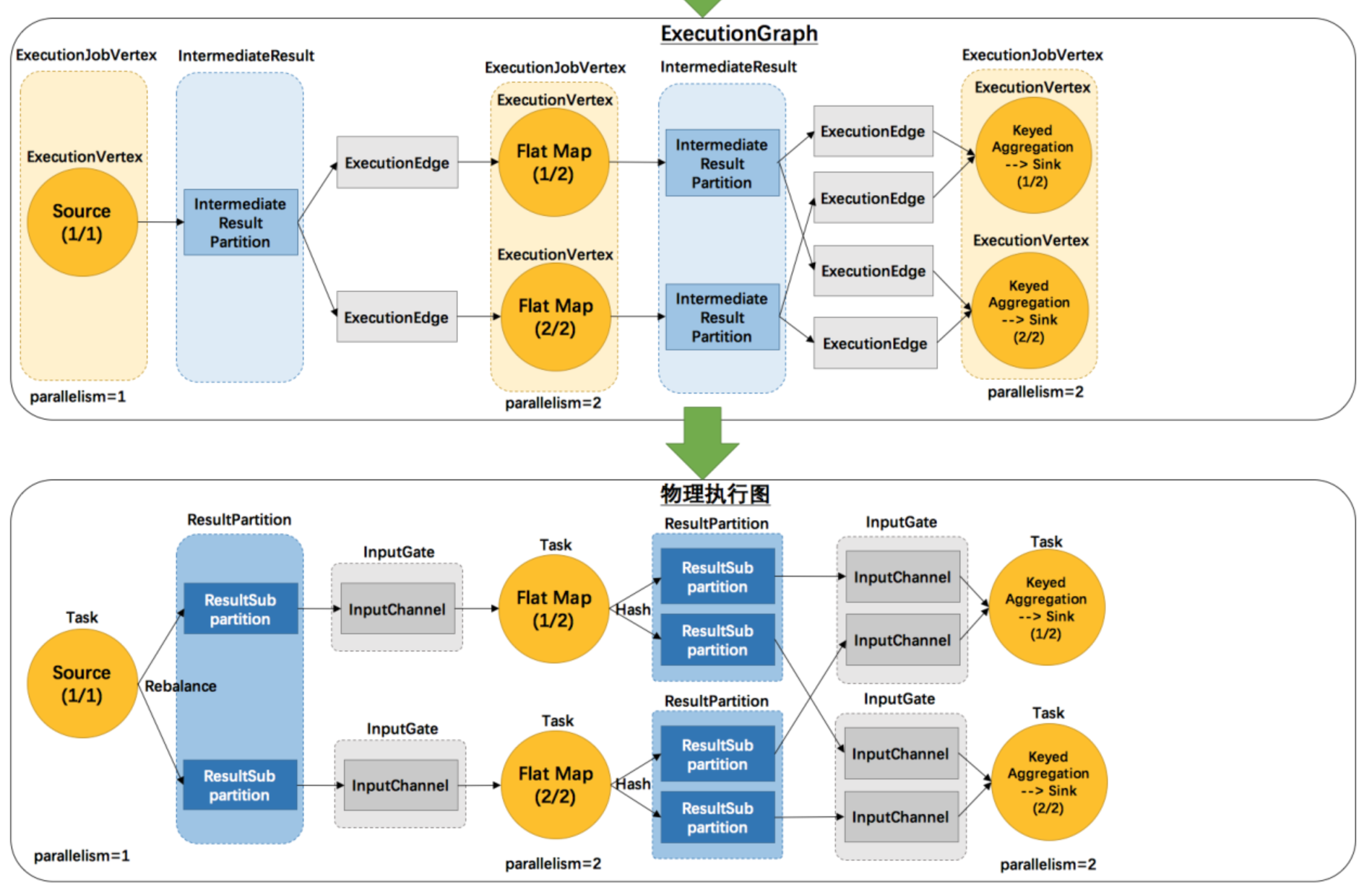
物理执行图:JobManager根据ExecutionGraph对Job进行调度后,在各个TaskManager上部署Task后形成的“图”,并不是一个具体的数据结构。
我们根据物理执行图可以看出来,一个Task有一个输入的InputGate,一个InputGate有多个InputChannle组成。并且一个Task一个对应一个ResultParition,并且他还和InputGate中的InputChannle做数据分发。这个时候我们就知道了,一个InputGate中InputChannel的多少,取决于上游的task的多少,ResultPartition中的SubPartition的数量取决于下游Task的多少。根据这些关系,形成了一张Task可以部署的图。
05 总结
好了,看到这里,我相信大家对于Flink Graph有了一些了解,为什么会分为四层图结构呢?
1、StreamGraph 是对用户逻辑的映射
2、JobGraph在StreamGraph的基础上进行了一些优化,例如operatorChain的优化,大家还记得7大条件吗,并行度一致、下游入边为1、在同一个slotGroup中、上游chain策略为ALWAYS或者HEAD、下游chain策略为ALWAYS、没有禁用chain策略、两个顶点的数据分区策略是forward。
3、ExecutionGraph是为了调度存在的,并且假如了并行度的概念
4、物理执行图是调度ExecutionGraph后的结果,其中一个task对应一个InputGate。一个ResultParition中的subPartition的数量和下游task数量相关。一个InputGate中的InputChannel和上游有多少个task相关
假如现在让你手绘wordcount的StreamGraph、JobGraph、ExecutionGraph、物理执行图,你会了吗?
这些知识都是我学习来的一些东西,我也是一个菜鸡,只是想把自己学到的东西记录一下,生成自己的一些知识做一些记录以后找的时候方便,现在分享给大家,谢谢大家的观看。