1. 前言
我们已经知道,对于InnoDB存储引擎而言,页是磁盘和内存交互的基本单位。哪怕你要读取一条记录,InnoDB也会将整个索引页加载到内存。哪怕你只改了1个字节的数据,该索引页就是脏页了,整个索引页都要刷新到磁盘。InnoDB是基于磁盘的存储引擎,如果每次操作都去读写磁盘,那么性能将会受到很大的影响。而且绝大多数时候,程序读写的数据在磁盘上并不是连续的,这意味着需要执行大量的随机IO读写,磁盘随机IO读写效率是非常低的,尤其是传统的机械硬盘。
在解决这个问题之前,大家可以先想一想,为什么我们只想读取一条记录,而InnoDB会将整个页的数据都加载到内存?因为根据计算机的局部性原理,程序接下来大概率会访问与它相邻的记录,为了避免频繁发起磁盘IO读操作,InnoDB直接将整个页都加载到内存,下次再访问页中的其它记录时,就可以命中缓存了,减少磁盘IO操作。
问题解决的思路其实是一样的,磁盘的速度虽然很慢,但是内存的速度快啊。这些被加载到内存里的索引页,使用完毕后不要立即释放,而是将它们先缓存下来,下次再访问这些页时,就可以命中缓存了,减少磁盘IO,从而提升性能。理论上,只要内存无限大,那么MySQL几乎可以是基于内存的数据库了。
InnoDB缓存索引页的组件,就是我们今天要聊的「Buffer Pool」。
2. Buffer Pool
MySQL服务器启动时,InnoDB会向操作系统申请一块连续的内存空间用来缓存索引页,这一块连续的内存空间就是Buffer Pool。默认情况下Buffer Pool的大小是128MB,查看命令如下:
mysql> SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
+-------------------------+-----------+
| Variable_name | Value |
+-------------------------+-----------+
| innodb_buffer_pool_size | 134217728 |
+-------------------------+-----------+
理论上,Buffer Pool越大,缓存的索引页就可以更多,缓存的命中率就可以更高,对应的性能提升就越明显。如果你的机器内存够大,完全可以调大Buffer Pool的大小,在配置文件里进行修改:
[server]
innodb_buffer_pool_size=2147483648
innodb_buffer_pool_instances=2
Buffer Pool最小是5MB,即使你配置的小于5MB,InnoDB也会分配5MB的内存。
innodb_buffer_pool_instances启动项代表Buffer Pool实例的个数。是的,你没看错,Buffer Pool支持配置多个,不同实例之间是隔离的,互不影响。配置多个的主要原因是因为Buffer Pool由多个链表组成,在维护这些链表时需要加锁保证同步,在高并发场景下会影响性能,配置多个实例就可以解决这个问题了。
每个Buffer Pool的大小是innodb_buffer_pool_size/innodb_buffer_pool_instances,InnoDB有规定,单个Buffer Pool实例的大小如果小于1GB,即使配置多个也不会生效。
2.1 Buffer Pool结构
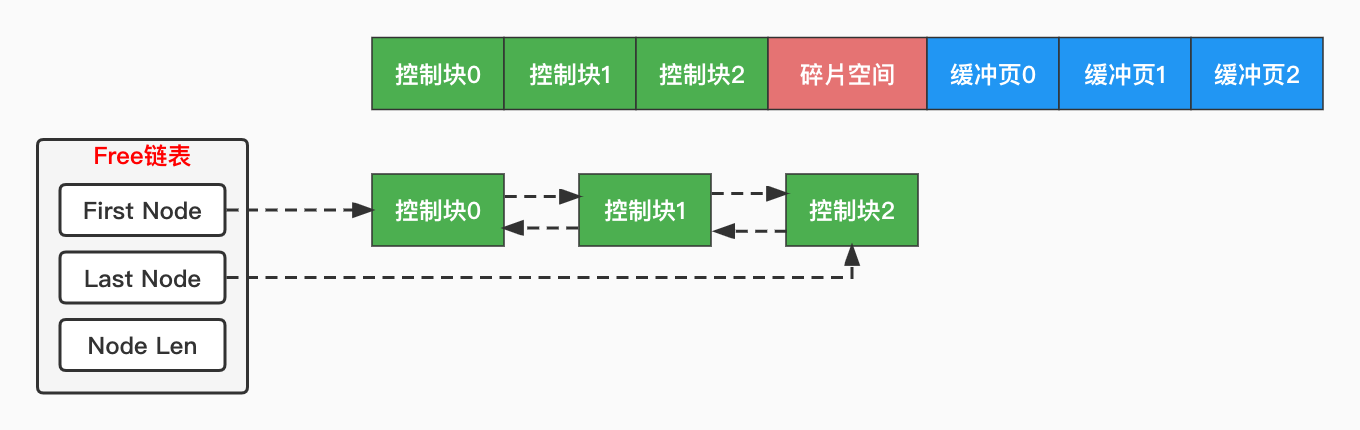
Buffer Pool是用来缓存物理磁盘上的页结构的,那它自然也是由若干个页组成。为了与磁盘上的页区分开,这里我们叫它「缓冲页」。为了更好的管理这些缓冲页,InnoDB为每个缓冲页都创建了一个「控制块」对象与之关联。所以,Buffer Pool其实是由若干对控制块和缓冲页,以及一些碎片空间组成的。
为什么会有碎片空间?如果最后剩余的空间不足以分配一对控制块和缓冲页,就会被浪费掉,也就是碎片空间。除非你把Buffer Pool的大小设置的刚好合适。另外,控制块的大小在正常模式下和DEBUG模式下占用的大小并不一样,DEBUG模式下控制块的大小约为缓冲页的5%。
缓冲页的结构和物理磁盘上的页一致,也就没什么好说的了。控制块主要记录了缓冲页所属的表空间ID、页号、缓冲页在Buffer Pool中的地址、链表节点信息等等。我们重点关注链表节点,因为Buffer Pool出于不同的目的,将这些缓冲页串联成了多条链表,后面会提到。
总之,Buffer Pool的结构其实很简单,如下图所示:

2.2 Free链表
Buffer Pool是用来缓存磁盘上的页结构的,那么第一个问题就来了。当我们要从磁盘上加载一个页的时候,这个页该放到Buffer Pool的哪个缓冲页里呢?总不能遍历整个Buffer Pool吧,哪个缓冲页是空闲的就直接使用它,这未免也太笨拙了。
InnoDB会通过控制块里的链表节点属性,将所有空闲的缓冲页都串联成一条双向链表,叫作「Free链表」。MySQL服务器刚启动时,所有的缓冲页都会加入到该链表中,因为所有的缓冲页都没有被使用。当我们要把磁盘上的页加载到内存时,就从Free链表申请一个缓冲页,并把它对应的控制块从Free链表中移除,这比遍历整个Buffer Pool可高效多了。
怎么找到Free链表呢?为了更好的管理这些链表,InnoDB为每条链表都创建了一个叫作「链表基节点」的结构,它的属性就三个,分别记录链表的头尾节点指针、以及链表内的节点数量。
2.3 缓冲页哈希表
第二个问题又来了,当我们要使用某个页的时候,怎么知道它有没有被加载到Buffer Pool呢?难道又要再遍历一次所有已使用的缓冲页吗?未免也太笨拙了。
在同一个表空间里,每个页都有唯一的一个页号,所以要定位一个页,只需要知道表空间ID+页号就可以了。也就是说,我们完全可以建立一个哈希表,哈希表的Key就是表空间ID+页号的组合,Value就是缓冲页。这样就可以快速判断某个页是否已经加载到Buffer Pool了。
2.4 Flush链表
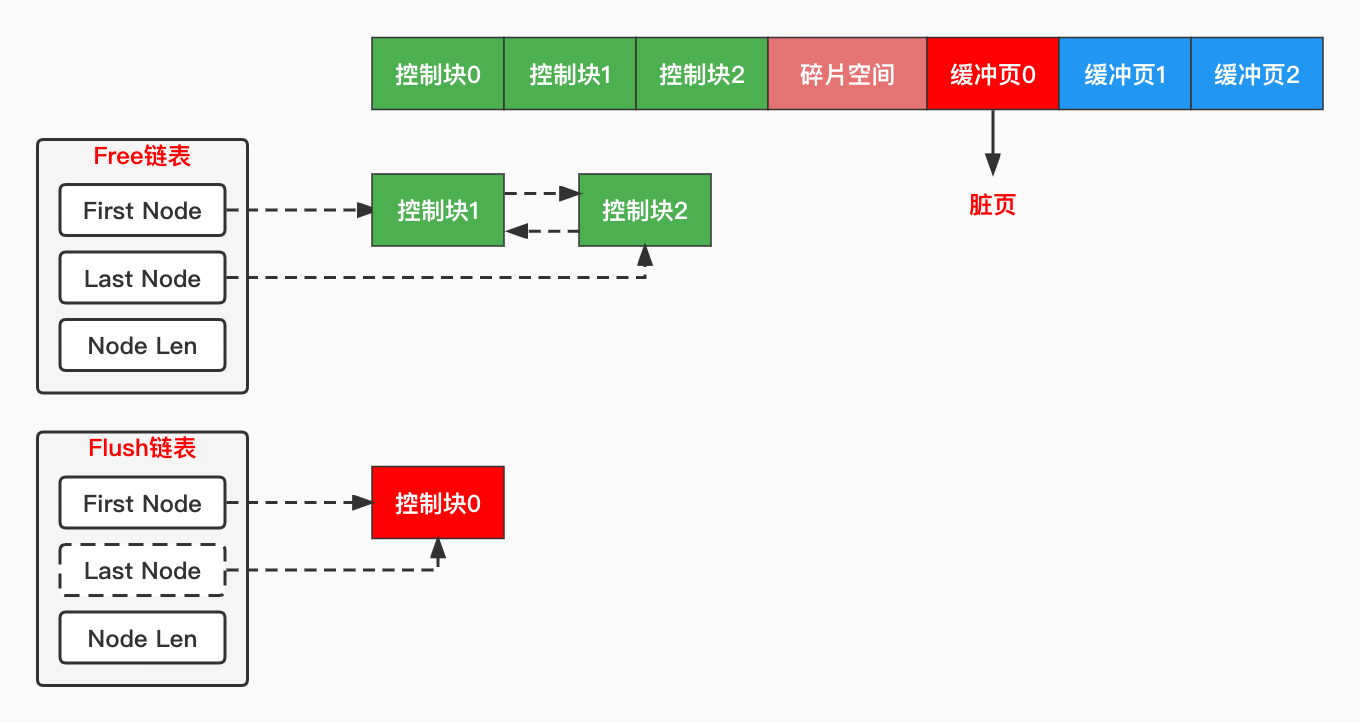
在执行增删改操作时,如果InnoDB每次都把受影响的页同步到磁盘,那么必然会导致大量的磁盘随机IO写操作,这个效率是很低的。为了提升性能,InnoDB会先在内存里修改这些受影响的页面,这些被修改过的页面称作「脏页」(Dirty Page),然后由一个额外的线程负责将这些脏页刷新到磁盘。
内存断电数据就丢失了,那些没来得及刷盘的脏页岂不是数据就丢失了?不用担心,后面聊的redo log会帮我们保证数据一致性的,这里先跳过。
第三个问题又来了,InnoDB怎么知道哪些页是脏页呢?再遍历一次Buffer Pool吗?太笨拙了,为了解决这个问题,InnoDB又引入了第二条链表:flush链表。
flush链表和free链表极其相似,也有一个链表基节点,当我们修改了缓冲页里的数据,InnoDB就会把该缓冲页对应的控制块加入到flush链表,等待后续的刷盘。
2.5 LRU链表
那些已经被使用的缓冲页,会从Free链表中移除,然后加入到一个叫作“LRU”的链表中。LRU是Least Recently Used的缩写,译为“最近最少使用”。为啥会需要LRU链表呢?说白了,相较于磁盘上海量的数据,Buffer Pool那点内存实在是杯水车薪,当Buffer Pool中的内存不够时,就不得不释放掉一些页面,来缓存新的页面。
Buffer Pool的本质是为了减少磁盘IO的访问,提高缓存命中率,正是因为它小才显得极其珍贵,InnoDB更应该要用好它。如果是你,你会在Buffer Pool里放访问频率高的页面,还是访问频率低的页面呢?
最简单的LRU链表,每当我们要访问一个页面时,就把它移动到LRU链表的表头,那么链尾的页面自然就是最近最少使用的了,当Free链表没有空闲的缓冲页时,直接把LRU链表的链尾页面释放掉即可。看似没什么问题,但是某些场景下,LRU链表会被破坏:
- 1.全表扫描:全表扫描需要加载聚簇索引B+树的所有叶子节点,当表中数据量较大时,可能一次全表扫描就会把之前访问频率很高的缓冲页全部从LRU链表中挤出,下次再访问这些页面时,又得从磁盘上重新加载一遍了。
- 2.预读:InnoDB内置了一个贴心的预读功能,它会在执行当前读请求时,判断是否还会访问其它页面,然后异步的把这些页面提前加载到Buffer Pool,从而加速读操作。预读细分为两种:
- 2.1线性预读:系统变量
innodb_read_ahead_threshold代表触发线性预读的阈值,如果顺序的访问某个区的页面数量超过该值,InnoDB就会异步的将下一个区的所有页面加载到Buffer Pool,默认值56。 - 2.2随机预读:系统变量
innodb_random_read_ahead代表触发随机预读的阈值,如果某个区的13个连续的页面被加载到Buffer Pool,InnoDB就会异步的将本区其它页面全部加载到Buffer Pool,该功能默认关闭。
- 2.1线性预读:系统变量
综上所述,全表扫描和预读可能会破坏LRU链表,本质上就是将大量可能短期不会被访问到的页面加入到LRU链表,反而导致那些访问频率很高的页面被挤掉了,导致Buffer Pool的命中率降低。
为了解决这个问题,InnoDB对LRU链表进行了优化,将LRU链表按照一定的比例分成两部分:存储访问频率很高的Young区、存储访问频率较低的Old区。系统变量innodb_old_blocks_pct控制了Old区所占的比例,默认值是37。也就是说,整个LRU链表的前约5/8部分用来存储访问频率很高的缓冲页,后约3/8部分用来存储访问频率较低的缓冲页。
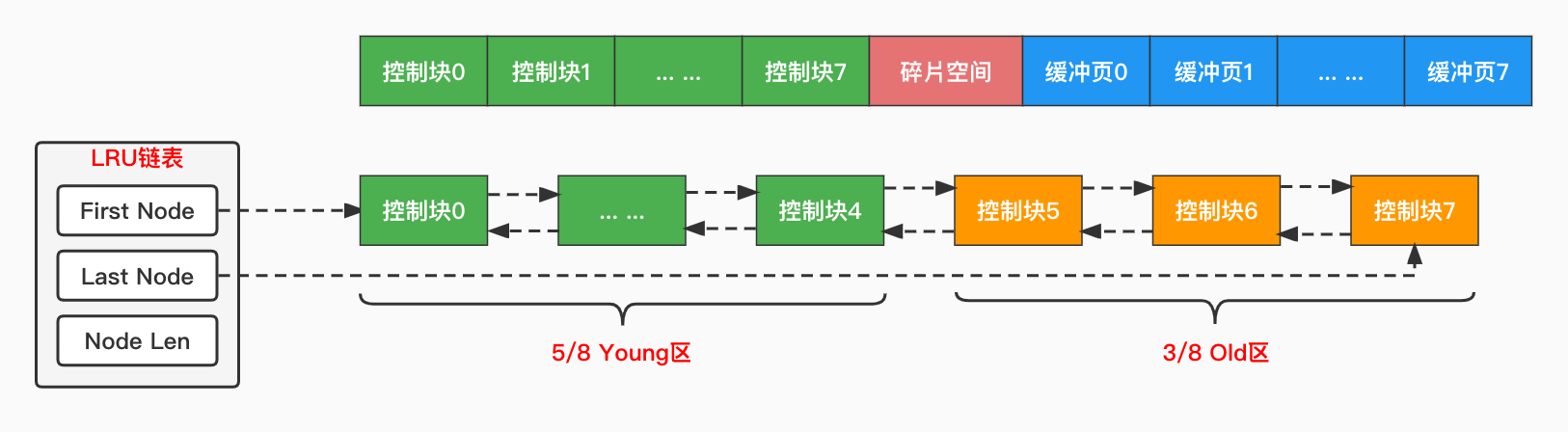
将LRU链表划分为两截后,InnoDB是这样来维护LRU链表的:首次加载的页面不会直接放到LRU链表的表头,而是Old区的头部,如果该页面后续没有继续访问,会慢慢被释放掉,而不影响Young区的页面。如果后续再次访问了该页面,判断距离上次访问的时间,只有两次访问的时间间隔超过了阈值,才会把它移动到Young区头部。
时间间隔的阈值通过系统变量innodb_old_blocks_time配置,默认是1000ms。
LRU链表经过这么一番优化后,我们看看是如何解决上面两个场景的:
- 全表扫描:全表扫描的页面首次加载只会放在Old区头部,虽然马上又会访问同一个页面,但是时间间隔很短,因此不会移动到Young区。(每一条记录都要访问一次页面)
- 预读:预读首次加载的页面只会放在Old区头部,只要后续不再继续访问,就会慢慢被释放掉。
对于Young区的缓冲页,如果每访问一次都要把它移动到LRU链表的表头,这个操作未免也太频繁了,因为Young区本来就是访问频率很高的页面,大家互相换来换去意义不大。所以InnoDB再进一步优化,如果访问的缓冲页在Young区的前1/4处,是不需要移动到表头的,只有访问的缓冲页在Young区的后3/4处才会把它移动到表头,这大大降低了链表节点移动的频率。
2.6 多个实例
现在我们知道,Buffer Pool在物理上虽然是一块连续的内存空间,但是逻辑上它由多条链表组成。在维护这些链表时,都需要加锁来保证同步,在高并发场景下,这会带来一些性能上的影响。为了解决这个问题,InnoDB支持多个Buffer Pool实例,每个实例都是独立的,会维护自己的各种链表,多线程并发访问时不会有影响,从而提高并发处理能力。
查看Buffer Pool实例个数的命令,默认是1个。
mysql> SHOW VARIABLES LIKE 'innodb_buffer_pool_instances';
+------------------------------+-------+
| Variable_name | Value |
+------------------------------+-------+
| innodb_buffer_pool_instances | 1 |
+------------------------------+-------+
支持在配置文件中进行配置:
[server]
innodb_buffer_pool_size=2147483648
innodb_buffer_pool_instances=2
在MySQL5.7.5之前,InnoDB是不支持运行时动态调整Buffer Pool大小的,主要是因为每次调整大小,都需要向操作系统重新申请一个Buffer Pool,然后将数据拷贝一次,这个开销太大了。在之后的版本中,InnoDB引入了chunk的概念来支持运行时修改Buffer Pool大小。一个Buffer Pool实例由若干个chunk组成,里面包含了若干个控制块和缓冲页。在调整Buffer Pool大小时,InnoDB以chunk为单位来申请内存空间和数据的拷贝。
chunk的大小由系统变量innodb_buffer_pool_chunk_size控制,默认是128MB,chunk本身的大小不支持运行时修改。
mysql> SHOW VARIABLES LIKE 'innodb_buffer_pool_chunk_size';
+-------------------------------+-----------+
| Variable_name | Value |
+-------------------------------+-----------+
| innodb_buffer_pool_chunk_size | 134217728 |
+-------------------------------+-----------+
innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的整数倍大小,目的是保证没个Buffer Pool实例的chunk数量一致。
2.7 Buffer Pool状态信息
说了这么多,耳听为虚,眼见为实。如何查看MySQL运行时的Buffer Pool相关的状态信息呢?命令是SHOW ENGINE INNODB STATUS,输出的是InnoDB引擎的状态信息,其中就包含Buffer Pool的状态信息,如下:
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 268616
Buffer pool size 8191
Free buffers 7238
Database pages 953
Old database pages 371
Modified db pages 0
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s
Pages read 919, created 34, written 36
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
Buffer pool hit rate 740 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 959, unzip_LRU len: 0
I/O sum[0]:cur[0], unzip sum[0]:cur[0]
- Total large memory allocated:Buffer Pool向操作系统申请的总内存大小,包括控制块大小。
- Dictionary memory allocated:给数据字典分配的内存大小,不包含在Buffer Pool总内存大小中。
- Buffer pool size:Buffer Pool可以容纳多少缓冲页。
- Free buffers:Free链表的页面数。
- Database pages:LRU链表的页面数。
- Old database pages:LRU链表Old区域的页面数。
- Modified db pages:脏页数量,即Flush链表的页面数。
- Pending reads:等待从磁盘加载到Buffer Pool的页面数。
- Pending writes.LRU:等待从LRU链表中刷新到磁盘的页面数。
- Pending writes.flush list:等待从Flush链表中刷新到磁盘的页面数。
- Pending writes.single page:等待以单个页面的形式刷新到磁盘的页面数。
- Pages made young:LRU链表曾经从Old区移动到Young区的节点数。
- Pages made not young:再次访问Old区的节点因为时间问题不能移动到Young区的节点数。
- youngs/s:每秒从Old移动到Young区的节点数。
- non-youngs/s:每秒由于时间限制不能从Old移动到Young区的节点数。
- Pages read/created/written:读取/创建/写入了多少页面,下一行是对应的速率。
- Buffer pool hit rate:过去平均每访问一千次页面,有多少次页面已经被缓存到Buffer Pool。
- young-making rate:过去平均每访问一千次页面,有多少次使页面移动到Young区头部。
- not young-making rate:过去平均每访问一千次页面,有多少次没有使页面移动到Young区头部。
- LRU len:LRU链表的节点数。
- I/O sum:最近50秒,读取磁盘的总页数。
- I/O cur:现在正在读取磁盘页的数量。
- I/O unzip sum:最近50秒解压的页面数。
- I/O unzip cur:正在解压的页面数。
3. 总结
磁盘速度太慢了,如果每次读取页面都从磁盘加载,会导致大量的磁盘IO随机读,MySQL的性能势必会受到严重影响。为了解决这个问题,InnoDB引入了Buffer Pool,它会在MySQL服务器启动时申请一块连续的内存空间,用来缓存对应的磁盘里的页结构。每个缓冲页都有一个与之关联的控制块,InnoDB为了不同的目的,将这些控制块串联成多条双向链表,例如:Free链表、LRU链表、Flush链表等等。为了提高Buffer Pool的命中率,防止一些特殊的操作破坏LRU链表,InnoDB将LRU链表按照一定的比例划分成两截,分别是存放访问频率很高的页的Young区,和访问频率较低的页的Old区。Buffer Pool逻辑上由这些链表组成,维护这些链表都需要加锁保证同步,高并发下会影响性能,所以InnoDB支持配置多个Buffer Pool实例。为了在运行时支持调整Buffer Pool的大小,InnoDB又引入了chunk的概念,最后通过命令我们可以查看Buffer Pool的状态信息。